YOLO系列的NMS算法大致相同,本文介绍的 NMS算法 是基于 YOLOv3 实现的,根据YOLOv3架构图所示,test过程将所有的预测框拼接成一个张量进行输出预测,Prediction:[batch, num_anchor, 85] ,其中 85 的构成 [x, y, w, h, confidence, classes]



for img_i, img_pred in prediction:
img_pred = img_pred [confidence] >= conf_thres # [10467,85] -> [2709,85]
score = confidence * max(classes) # 2709 score 得分
img_pred.sorted() # 根据score降序排列
class_confs, class_preds = image_pred[:, 5:].max(1, keepdim=True) # 获得当前pred的最大类别概率、对应类别
detections = [x, y, w, h, confidence, class_confs, class_preds]
for
计算最大score 与其他pred的 bbox_iou,保留超过 nms_thres的 preds
根据 class 信息 与 nsm_thres 判断是否进行抑制
enumerate() 是python的内置函数,用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
返回 enumerate(枚举对象) 下标号 、成员。
采用的COCO数据集,80个类别 +
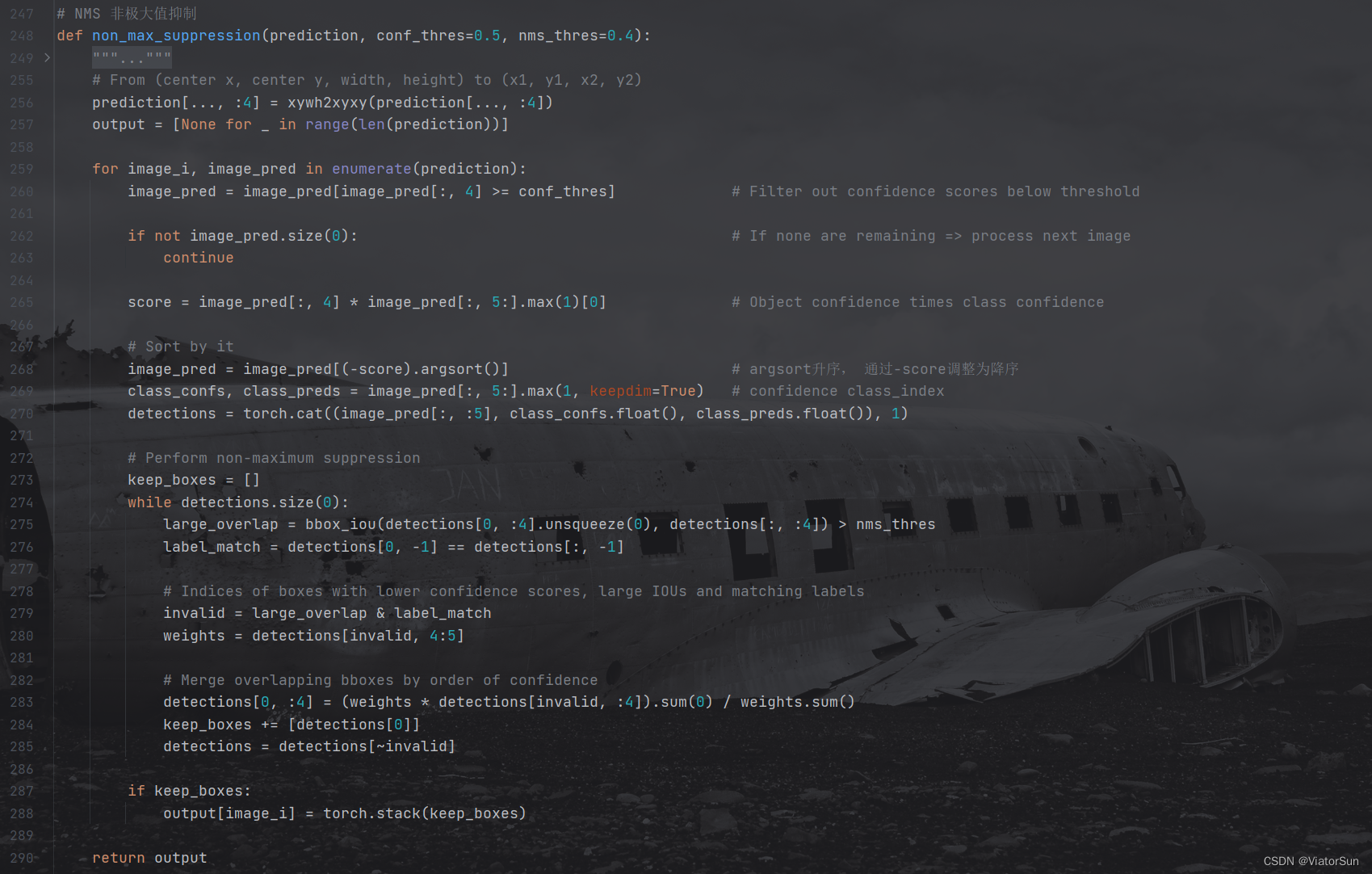
NMS 完整代码
def non_max_suppression(prediction, conf_thres=0.5, nms_thres=0.4):
"""
Removes detections with lower object confidence score than 'conf_thres' and performs
Non-Maximum Suppression to further filter detections.
Returns detections with shape:
(x1, y1, x2, y2, object_conf, class_score, class_pred)
"""
# From (center x, center y, width, height) to (x1, y1, x2, y2)
prediction[..., :4] = xywh2xyxy(prediction[..., :4])
output = [None for _ in range(len(prediction))]
for image_i, image_pred in enumerate(prediction):
# Filter out confidence scores below threshold
image_pred = image_pred[image_pred[:, 4] >= conf_thres]
# If none are remaining => process next image
if not image_pred.size(0):
continue
score = image_pred[:, 4] * image_pred[:, 5:].max(1)[0] # Object confidence times class confidence
# Sort by it
image_pred = image_pred[(-score).argsort()]
class_confs, class_preds = image_pred[:, 5:].max(1, keepdim=True)
detections = torch.cat((image_pred[:, :5], class_confs.float(), class_preds.float()), 1)
# Perform non-maximum suppression
keep_boxes = []
while detections.size(0):
large_overlap = bbox_iou(detections[0, :4].unsqueeze(0), detections[:, :4]) > nms_thres
label_match = detections[0, -1] == detections[:, -1]
# Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match
weights = detections[invalid, 4:5]
# Merge overlapping bboxes by order of confidence
detections[0, :4] = (weights * detections[invalid, :4]).sum(0) / weights.sum()
keep_boxes += [detections[0]]
detections = detections[~invalid]
if keep_boxes:
output[image_i] = torch.stack(keep_boxes)
return output

a = torch.randn(4, 4)
a
tensor([[ 0.0785, 1.5267, -0.8521, 0.4065],
[ 0.1598, 0.0788, -0.0745, -1.2700],
[ 1.2208, 1.0722, -0.7064, 1.2564],
[ 0.0669, -0.2318, -0.8229, -0.9280]])
torch.argsort(a, dim=1)
tensor([[2, 0, 3, 1],
[3, 2, 1, 0],
[2, 1, 0, 3],
[3, 2, 1, 0]])
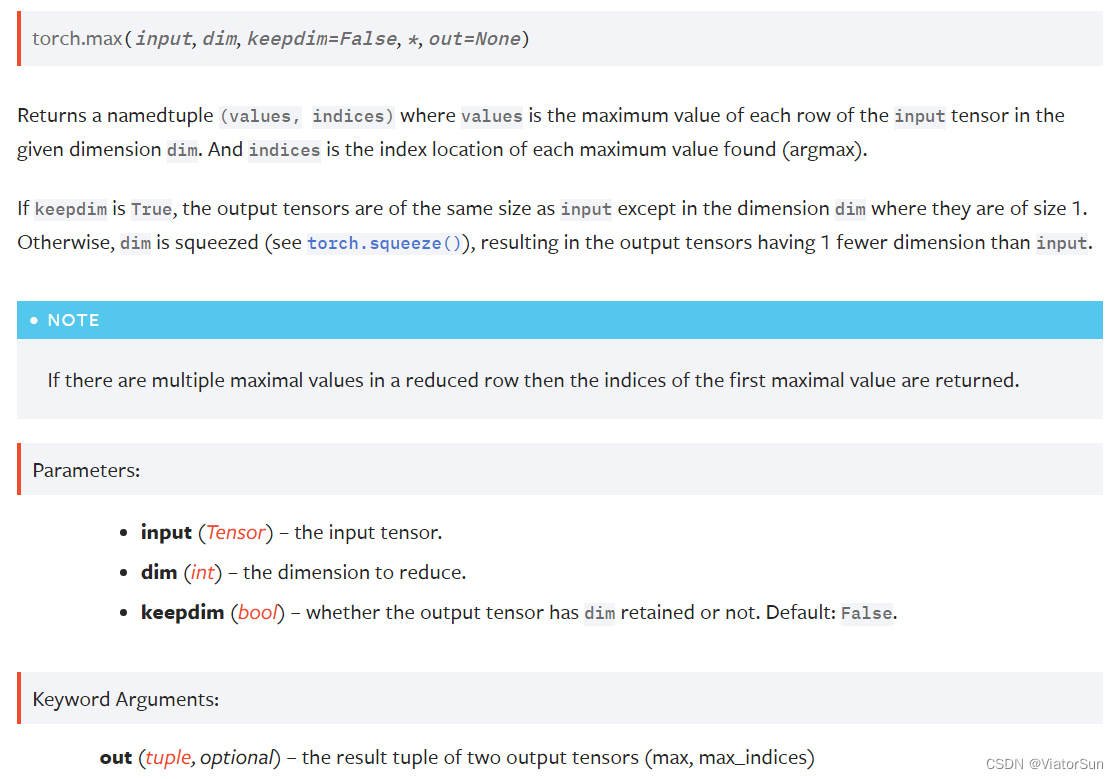
>>> a = torch.randn(4, 4)
>>> a
tensor([[-1.2360, -0.2942, -0.1222, 0.8475],
[ 1.1949, -1.1127, -2.2379, -0.6702],
[ 1.5717, -0.9207, 0.1297, -1.8768],
[-0.6172, 1.0036, -0.6060, -0.2432]])
>>> torch.max(a, 1)
torch.return_types.max(values=tensor([0.8475, 1.1949, 1.5717, 1.0036]), indices=tensor([3, 0, 0, 1]))