Explication détaillée de JS Reverse Complementary Environment Overpass
"Ruishu" est une grande montagne sur la route inverse, un mur que de nombreux inverseurs JS ne peuvent éviter, et c'est aussi un point lumineux sur le CV de job-hopping. Nous devons le surmonter avant le prochain job-hopping ! ! Heureusement, il existe de nombreux articles sur Internet qui expliquent le Ruishu, et ils nous apprennent pas à pas à analyser le processus du Ruishu et à en déduire la logique du Ruishu, dans une tentative de nous apprendre (tête de chien manuelle ) . Cependant, il existe peu d'articles qui expliquent en détail comment passer Ruishu en complétant purement l'environnement. Aujourd'hui, c'est ici !
Afin de permettre à chacun de bien manier le grand frère Ruishu, cet article décrira à partir des quatre parties suivantes :
- La logique de processus de rs
- Parler du code de déduction pass rs
- Expliquer en détail le processus de supplémentation de l'environnement
- Comparaison du code de déduction et de l'environnement supplémentaire
- Dépassement de courbe
C'est long, alors asseyez-vous bien et commencez!
Remarque : Le contenu de cet article prend pour exemple un site Web rs4 convivial pour les nouveaux arrivants : l'immobilier en ligne ;
Un : la logique de processus de rs
Quand on fait de la rétro-ingénierie, il faut d'abord analyser ce 加密参数qu'il faut inverser, puis inverser ces paramètres. Bien sûr, il en va de même pour Ruishu.
Donc notre première étape est 明确逆向的目标:
- Phénomène : le site Web sur rs demandera page_url deux fois, et le contenu correct de la page ne peut être obtenu qu'en demandant page_url pour la deuxième fois ;
- Analyse : analysez le corps de la requête et constatez que cookie_s et cookie_t sont inclus dans la deuxième requête à page_url, et que cookies_s provient de l'en-tête de réponse défini lorsque page_url est demandé pour la première fois ;
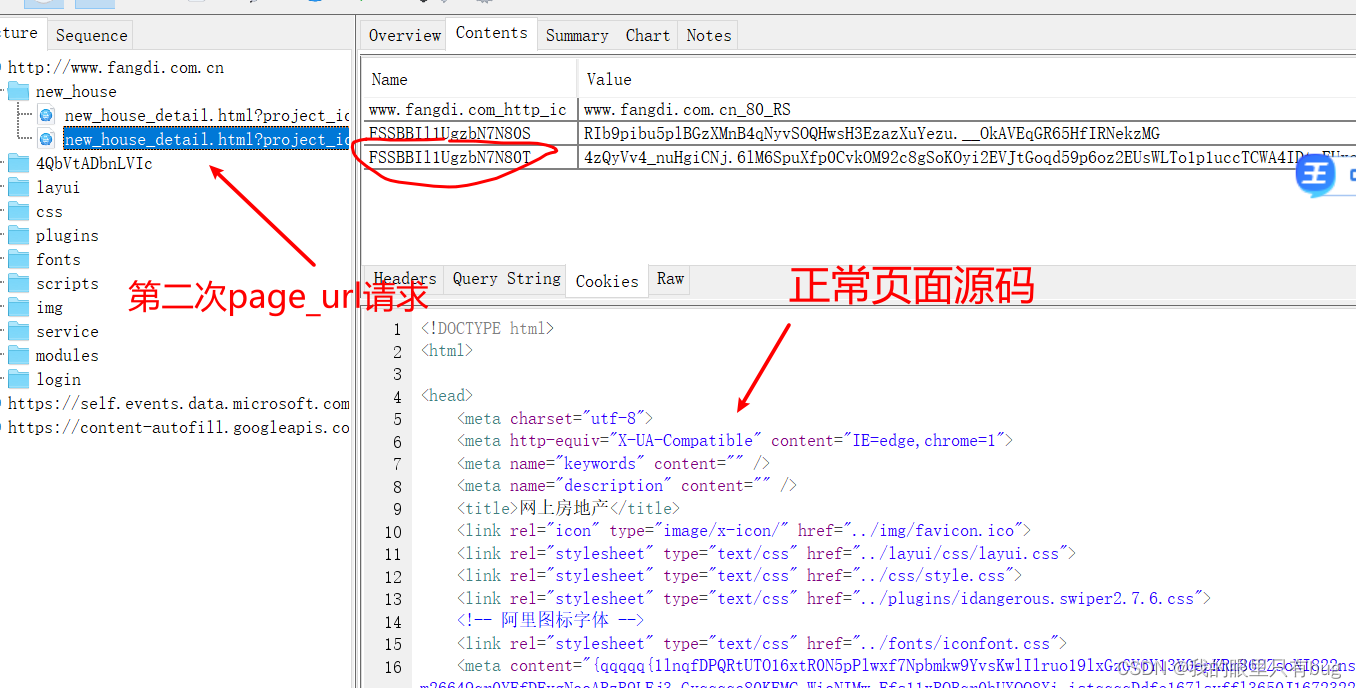
- Conclusion : Alors notre objectif est déterminé - craquer
cookie_t的生成逻辑;
Maintenant, nous savons que le paramètre de cryptage qui doit être inversé est cookie_t, alors d'où vient cookie_t, analysons d'abord la demande du site Web
Analyse du processus de demande de site Web Ruishu :
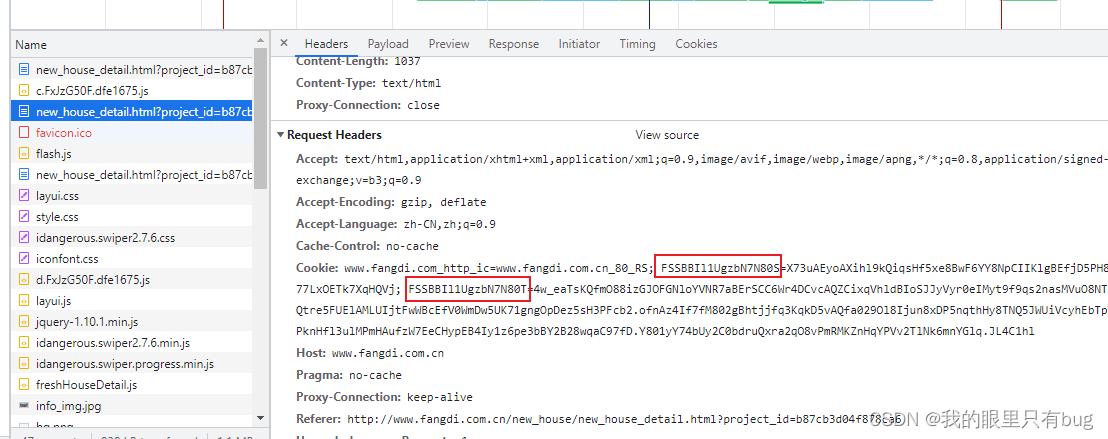
第一次请求:Page_url de la requête, le code d'état de la réponse est 202, cookie_s est défini dans l'en-tête de la réponse ;

le corps de la réponse est le code source HTML, qui peut être divisé en quatre parties de haut en bas : Permettez-moi de le gâcher d'abord它们的作用
- Une balise meta dont le contenu est long et constant
动态(change à chaque requête), sera utilisée lors de l'exécution par eval de la deuxième couche de code JS ; - Un fichier js externe , dont le contenu est généralement dans la même page
固定, la fonction auto-exécutable suivante déchiffrera le contenu du fichier pour générer le code source JS requis pour l'exécution d'eval, qui est la deuxième couche de code vm ; - Une grande fonction auto-exécutable
动态(la page d'accueil changera à chaque fois qu'elle sera demandée ), principalement pour décrypter le contenu JS du lien externe, et ajouter quelques attributs à la fenêtre comme $_ts, qui sera utilisé dans vm ; - Les appels de fonction dans les deux balises de script à la fin
更新cookiele rendront plus long. Nous pouvons ignorer cela ici.![[Le transfert d'image du lien externe a échoué, le site source peut avoir un mécanisme de lien antivol, il est recommandé d'enregistrer l'image et de la télécharger directement (img-5Y95CH4R-1673156546278)(https://note.youdao.com/yws/ res/26818/WEBRESOURCE8752b7a5f31959082ecd992b3c0c4ace)]](https://img-blog.csdnimg.cn/523685f406cd4edb9a12cf977cea1d4b.png)
第二次请求:Demander un lien externe js, le contenu général est fixe ;
第三次请求:Demander page_url, renvoyer 200 et transporter cookie_s, cookie_T pour demander normalement ;
Alors, que se passe-t-il exactement lorsque nous visitons ce site Web dans un navigateur ? Qu'est-ce qui mérite notre attention ?
Simulons 浏览器加载page_url源码d'abord ce qui se passe :
- Le navigateur charge les méta ;
- Le navigateur demande
外链jset exécute le contenu js ; - Exécutez le code source page_url
自执行函数, il外链js解密convertira les dizaines de milliers de lignes de chaînes js requises par eval et ajoutera de nombreux attributs à window.$_ts, puis appellera la fonction eval进入VMpour exécuter le js déchiffré, générera des cookies , après eval est exécuté, continuer à exécuter la fonction d'auto-exécution ; - Exécutez le code dans la balise de script à la fin, ce qui mettra à jour cookie_t ( vous pouvez l'ignorer )
- Exécutez setTimeout, fonction de rappel eventlistener ( vous pouvez l'ignorer )
瑞数执行流程图解comme suit:
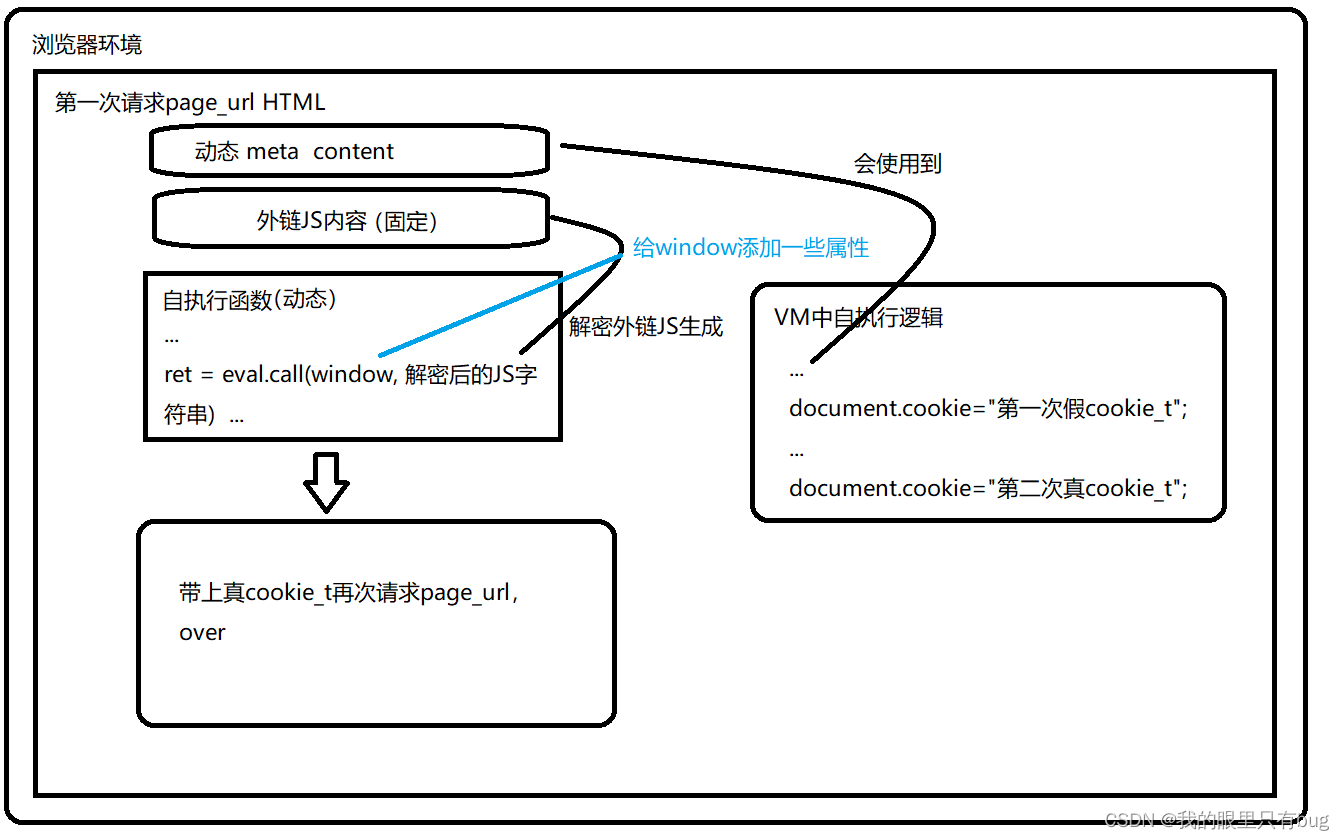
Ici, nous devons nous concentrer sur eval调用l'emplacement (c'est-à-dire VM的入口), l'emplacement où le cookie est généré .
Remarque : Lorsque le navigateur v8 appelle eval pour exécuter du code, il ouvre une machine virtuelle (VM+numéro) pour exécuter le code JS.
Nous pouvons localiser directement hook evalou 搜索.calldirectement la position où eval est appelé
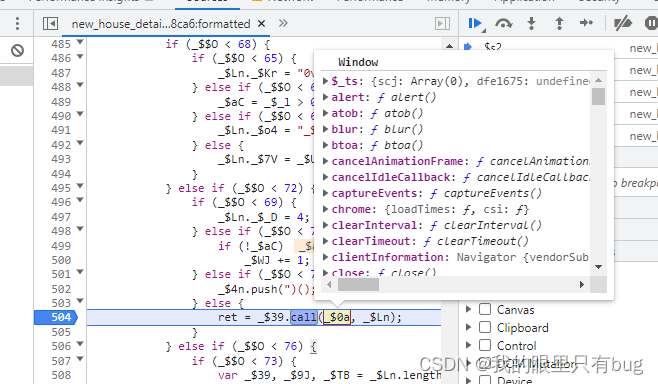
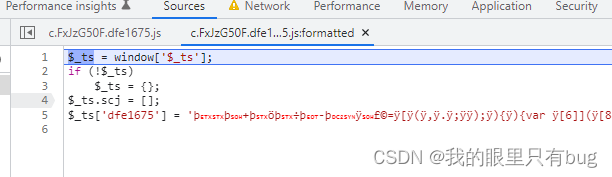
_$Ln est 解密后la chaîne de code js; entrer vm est une fonction auto-exécutable, qui a 生成cookieune certaine logique, et le cookie de localisation peut être directement accroché ou recherché dans le code vm ( 5)
crochet cookie code:
// hook 指定cookie赋值
(function () {
'use strict';
Object.defineProperty(document, 'cookie', {
set: function (cookie) {
if(cookie.indexOf("FSSBBIl1UgzbN7N80T")!= -1){
debugger;
}
return cookie;
}
});
})();
Eh bien, ce qui précède est la logique de processus globale de Ruishu, alors comment pouvons-nous 扣代码passer Ruishu en générant cookie_t ?
2. Parler de déduire le code pour passer le numéro suisse
Étant donné que le code source de Ruishu page_url est 动态modifié à chaque fois qu'il est demandé, VM代码il est également modifié dynamiquement, nous devons donc enregistrer un code statique pour un débogage facile ;
comme le montre la figure, corrigez simplement la réponse page_url,
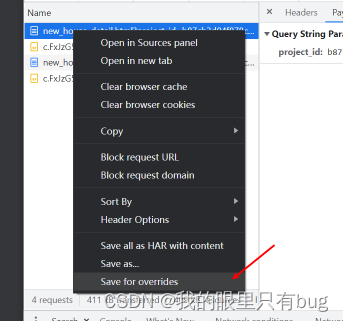
Lors d'une demande de cette manière, la page_url 外链JSest fixe, 自执行函数fixe VM中的代码et fixe, donc le cookie_t généré à chaque fois par ce code fixe est-il également fixe ?
Réponse : Non , car la génération de cookie_t utilise des nombres aléatoires , des horodatages et des valeurs dans localStorage (la valeur sera +1 à chaque fois qu'il est appelé), nous accrochons également les deux variables de nombres aléatoires et d'horodatages , puis chacune time Ouvrez un nouveau navigateur sans trace à exécuter, et le cookie_t généré final est corrigé.
À ce stade, nous pouvons commencer la déduction de ce code statique. Si la déduction est cohérente avec celle générée par node cookie_tet le code statique généré par le navigateur, cookie_tcela signifie que la déduction est réussie.
Le code de déduction doit déduire deux parties, la partie de code source page_url et la partie cookie_t générée dans la VM.
D'après notre analyse précédente, c'est le code de la VM qui sera utilisé window.$_ts, il faut donc d'abord s'assurer que le code déduit du code source page_url pourra être généré normalement lors de son exécution à eval window.$_ts.
Nous déduisons d'abord la somme de page_url 自执行函数et 外链JS内容du métacontenu, puis complétons simplement l'environnement en fonction du rapport d'erreur d'exécution, de sorte que lorsque le code déduit est exécuté pour eval, la window.$_tssomme déchiffrée VM JS代码est cohérente avec celle générée par le code statique local.
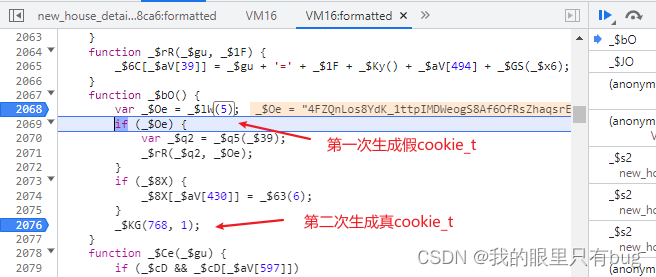
Cela signifie que nous avons déduit la partie du code source page_url, puis nous pouvons déduire la partie qui génère cookie_t dans la VM.
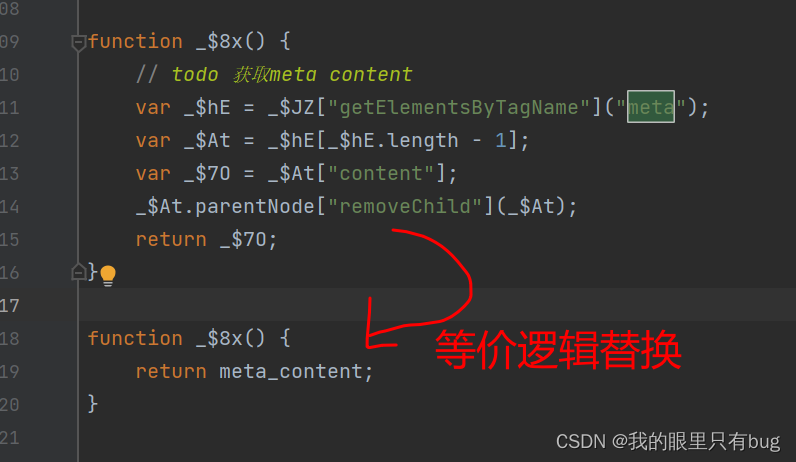
De l'analyse ci-dessus cookie的定位, nous pouvons savoir que le cookie_t secondaire est généré dans la fonction _$bO, alors c'est nous 扣代码的起点, bouclez la fonction jusqu'à la fin du fichier, exécutez-la directement, puis rattrapez ce qui manque BOM、DOM api. rencontrant le code utilisé, nous pouvons Use 等价逻辑替换, par exemple, la logique d'origine ici est d'obtenir le contenu du contenu dans la balise meta, puis de supprimer la balise meta, nous pouvons directement la remplacer par return meta_content de manière équivalente. Comme indiqué sur l'image :
Si à la fin, le cookie_t généré par node est incohérent avec celui généré par le code statique local , cela signifie que le code que nous avons déduit n'a pas réussi certains tests environnementaux . Nous pouvons le localiser en fonction de la différence entre l'exécution du nœud et du navigateur , par exemple en tant qu'exécution de nœud à un certain endroit La valeur est différente de celle obtenue par le navigateur exécutant le code statique, indiquant qu'il y a une différence dans la logique précédente. Continuez à avancer et répétez ce processus pour trouver toutes les détections d'environnement manquantes et compléter la déduction de la partie VM.
À ce stade, nous avons terminé la déduction du code rs statique et réussi, mais le code du site Web rs est 动态oui, window.$_tset VM jsil changera à chaque fois qu'il sera demandé. Devons-nous déduire chaque copie ? Non, en fait, nous ne sommes plus qu'à un mapping du vrai succès, bien que
les dizaines de milliers de lignes de code js de la VM changent à chaque fois, seul le nom de la variable change, et tout le reste reste inchangé.
Le mappage consiste à faire correspondre les noms d'attributs dans le JS avec les noms d'attributs fixes 动态window.$_tsutilisés dans le JS dans la VM que nous avons déduite .window.$_ts
Donc, dans le processus de déduction, nous devons faire attention à quels endroits de la VM sont utilisés 外部变量(c'est-à-dire quelles variables d'une fonction proviennent d'autres portées, même des variables externes), nous devons faire attention à l'endroit où ces variables externes proviennent de , si la VM elle-même Si elle est définie dans la fonction d'exécution, alors ne vous inquiétez pas. Si elle provient de window.$_ts, vous devez l'enregistrer. C'est ce qui doit être mappé.
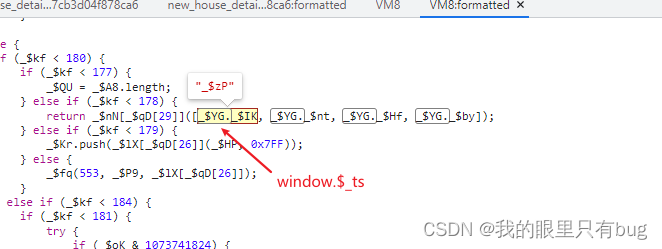
La logique de calcul ici est utilisée window.$_ts._$IK, nous devons donc transmettre cette valeur lorsque nous effectuons le mappage ;window.$_ts={_$IK:对应的动态属性名}
Après avoir résolu le mappage, le code sera déduit avec succès via rs.
Eh bien, c'est tout pour le code de déduction, et la prochaine étape est au centre de notre article.
3. Expliquez en détail le processus de complémentation de l'environnement
Les camarades qui ne connaissent pas le principe d'environnement supplémentaire peuvent se référer à mon article précédent : JS逆向之浏览器补环境详解;
En fait 纯补环境, le principe de Ruishu est très simple. Observons le schéma du flux d'exécution de Ruishu . Exécuter ces JS dynamiques en fonction de l'environnement du navigateur peut générer cookie_t utilisable. Donc, tant que l'environnement du navigateur que nous complétons est suffisamment parfait pour que ces JS dynamiques nous ressemblent 补的环境===浏览器环境, alors l'environnement que nous complétons exécute ces JS dynamiques et peut également générer un cookie_t utilisable, puis nous extrayons cookie_t via document.cookie
Exprimé en pseudocode est :
// 补的环境头
window = this;
... 省略大量环境头
// 模拟meta标签及其content
document.createElement('meta');
Meta$content = "{qYnKTJPAw84QfF5jm0I2_1IqhgTvRw8Y0yCBPxIVn6od8AeJE6CBz8ZSU6U...省略";
// 固定的外链js
$_ts=window['$_ts'];if(!$_ts)$_ts={
};$_ts.scj=[];$_ts['dfe1675']='þþ+...省略';
// page_url动态自执行函数
(function(){
var _$CK=0,_$WI=[[9,3,6,0,4,1; ...ret = _$su.call(_$fr, _$WR); 很长...省略}}}}}}}})();;
// 获取cookie
function get_cookie(){
return document.cookie;
}
// 获取MmEwMD参数
function get_mme(){
{
XMLHttpRequest.prototype.open("GET","http://脱敏/",true);
return XMLHttpRequest.prototype.uri;
}}
Ceci est le dernier fichier que nous allons compléter. Étant donné que les fonctions auto-exécutables dynamiques Meta$content et page_url changent dynamiquement, nous devons utiliser des expressions régulières pour extraire ces deux chaînes chaque fois que nous demandons page_url, puis les insérer dans le fichier. , puis python pyexecjs appelle get_cookie pour obtenir le cookie_t disponible ;
Il est également mentionné dans la déduction de code ci-dessus que le cookie_t généré est modifié en raison de nombres aléatoires et d'horodatages impliqués dans l'opération de génération de cookie_t. Nous pouvons fixer l'horodatage et les nombres aléatoires afin que le même statique Le cookie_t généré par JS soit corrigé.静态JS代码hook
// 固定定随机数和时间戳
Date.prototype.getTime = function(){
return 1672931693};
Math.random = function(){
return 0.5};
补的环境Nous pouvons également juger si nous sommes === à travers le cookie_t final généré 浏览器环境.
Le principe est très simple, la prochaine étape est de savoir comment le mettre en pratique : il faut constituer un en-tête d'environnement parfait pour que le cookie_t obtenu par cette 静态JSexécution soit cohérent avec celui obtenu par le navigateur.
Parce que compléter l'environnement est un travail systématique et qu'il existe des routines générales , on peut utiliser la méthode évoquée dans l'article précédent 补环境框架pour compléter systématiquement l'environnement, ce qu'il faut faire c'est log输出améliorer en permanence ce framework en fonction des problèmes qui se posent.
Comme le montre la figure, démarrez le framework, ce qui précède est l'en-tête d'environnement que nous avons ajouté, et ce qui suit est le code que nous avons déduit.

Continuez à déboguer. Lorsque nous Proxy拦截器interceptons BOM、DOM apil'utilisation, le débogueur vivra. Nous pouvons vérifier quelle ligne de code utilise l'environnement du navigateur en fonction de la pile d'appels
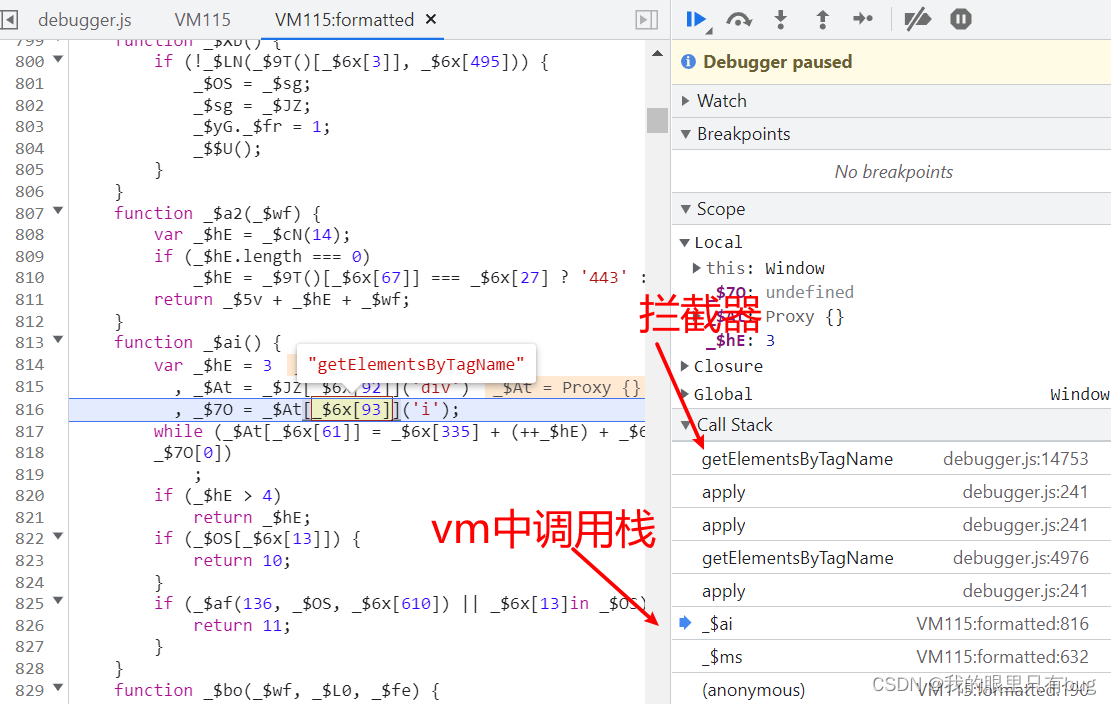
Un tel environnement supplémentaire alternatif jusqu'à ce qu'il puisse être généré à la fin cookie_t, jugez s'il est cohérent avec la génération locale du navigateur, sinon, utilisez la dichotomie pour localiser, voyez quel environnement de navigateur n'a pas été complété, jusqu'à ce que vous obteniez enfin le bon, postez ici pour la cookie_tfin Rendu d'exécution :
Ceci fait partie de l'impression finale 环境检测点:
Voici à quoi aboutit la récupérationcookie_t :
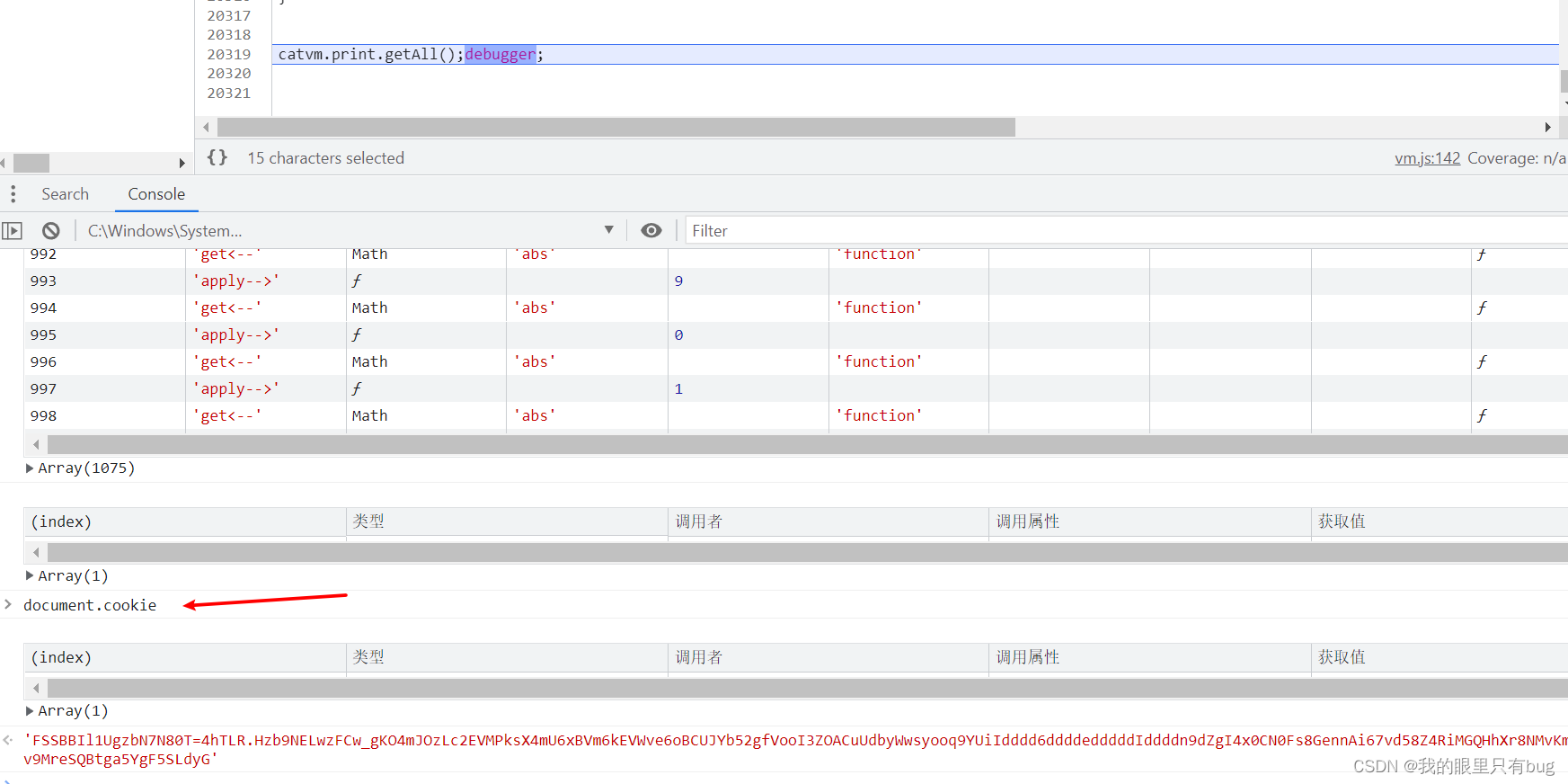
De la même manière, MmEwMDla même logique s'applique à l'environnement de complément de paramètre. Lorsque l'en-tête de l'environnement est parfait, exécutez le fichier de résultat final en python pour obtenir les résultats suivants :
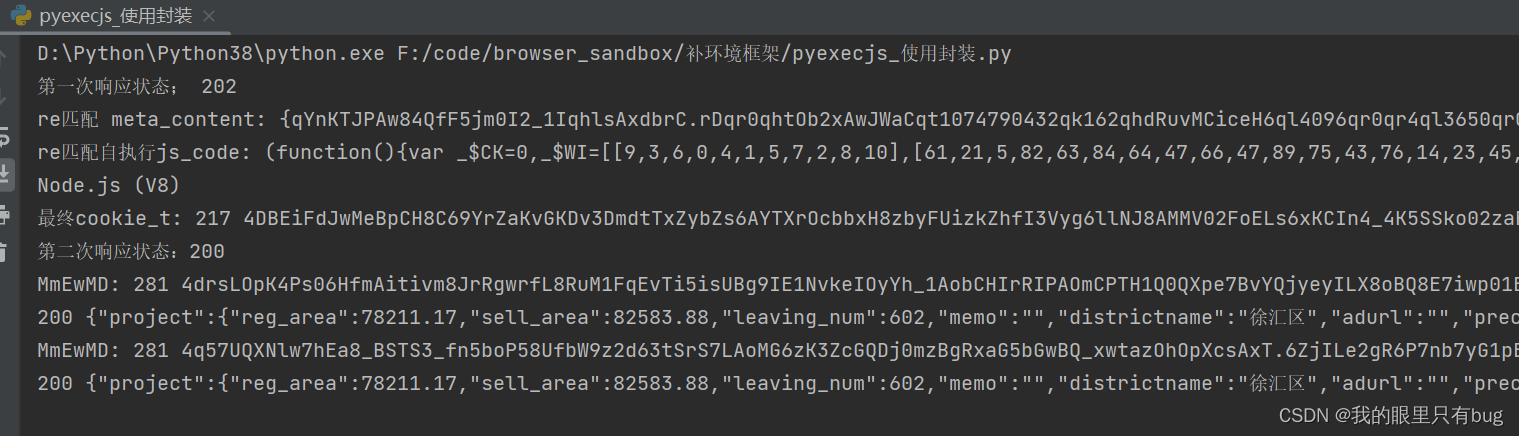
4. Résumé de l'environnement supplémentaire et du code de retenue :
Pour js逆向moi, ce sont deux moyens conventionnels et pratiques, et chacun a ses avantages et ses inconvénients ;
Quelle que soit la méthode utilisée, nous déduisons d'abord le code JS crypté du site Web, puis choisissons de continuer à déduire le code et de remplacer la 浏览器环境apilogique utilisée ; ou d'utiliser l'environnement supplémentaire pour que le code JS crypté semble être dans le navigateur environnement rodé.
- Le code de déduction et l'environnement supplémentaire dépendent tous deux de la maîtrise de JS, le code de déduction est davantage axé sur la syntaxe js et la logique du code, et l'environnement supplémentaire est davantage axé sur la simulation de la chaîne de prototypes et des objets BOM et DOM.
- La maîtrise de la déduction de code dépend de l'expérience inverse, et l'environnement supplémentaire dépend presque uniquement de la maîtrise de JS.
- Le code de déduction doit déboguer et suivre beaucoup de logique. Pour rs, si vous ne comprenez pas la confusion, vous aurez des hémorroïdes dans les fesses ;
- Le code de déduction doit remplacer la logique de détection d'environnement, il doit donc également savoir où l'environnement du navigateur est utilisé ; le cadre d'environnement supplémentaire ne peut être utilisé que pour surveiller l'utilisation de l'environnement du navigateur et peut être utilisé comme outil auxiliaire pour code de déduction.
- Puisque Ruishu est dynamique, le code de déduction ne peut en déduire qu'un statique, il est donc nécessaire de trouver tous les attributs dynamiques utilisés dans la vm pour le mappage. L'environnement complémentaire est universel, plus il est complémentaire, plus il y a de sites Web qui peuvent être tués.
- Déduire des codes est plus efficace que compléter l'environnement. Après tout, le nombre de codes pour compléter l'environnement est bien plus que les codes de déduction. L'écart peut être réduit en éliminant les environnements inutiles ;
- Le temps manuel du code de déduction est beaucoup plus élevé que celui de l'environnement supplémentaire.
Dans l'ensemble, 扣代码il se concentre sur la syntaxe js et la logique du code, et sa maîtrise dépend de l'expérience inverse. Il est différent pour différents sites Web, il est difficile à utiliser universellement et l'efficacité du travail est faible, mais l'efficacité d'exécution du programme est élevée .
补环境Il se concentre sur la chaîne de prototypes et la simulation de l'environnement du navigateur. La compétence dépend presque uniquement de la maîtrise des principes JS. Plus les sites Web sont complétés, plus les sites Web peuvent être tués. L'efficacité manuelle est extrêmement élevée, mais l'efficacité d'exécution du programme est pas haut.
5. Lien de dépassement de courbe
Passer Ruishu est le petit objectif de presque tous les inverseurs novices, et c'est aussi un point d'interrogation commun pour les enquêteurs. A travers cet article, nous avons appris 瑞数的流程及破解思路que l'on peut essayer d'implémenter un framework d'environnement complémentaire complet à partir de zéro, 纯环境黑盒过瑞数mais cela prendra beaucoup de temps à développer, et il y a beaucoup de tâches répétitives qui sont ennuyeuses (comparaison copier-coller, etc.).
Prenez la voie rapide : le cadre d'environnement supplémentaire
de cette version de cet article est systématiquement amélioré sur la base du cadre de l'article précédent. À l'heure actuelle, on peut dire qu'il est assez complet et a complété de nombreux environnements. Si vous voulez pour économiser Si vous passez beaucoup de temps, directement , vous pouvez me contacter sur WeChat : dengshengfeng666 Référence de code source payante ; prix fixe 199, après paiement, envoyez directement le code source du projet framework (vous pouvez directement vous lancer avec la dernière readme graphique), et si vous avez des questions à l'avenir, vous pouvez me les poser directement. Ou envoyez-moi un message privé directement sur CSDN.极大提高效率弯道超车
Améliorations entre cette version et la version précédente :
- Optimiser les types d'intercepteurs Proxy13, atteindre la limite de Proxy et en faire un proxy récursif, prendre en charge la détection de profondeur de niveau abcde... ;
- Améliorer le mécanisme d'appel du fichier de résultat final.js, afin qu'il puisse être directement utilisé pour les appels V8 et de nœud sans modification ;
- Ajoutez des objets BOM et DOM, tels que : XMLHttpRequest, XMLHttpRequestEventTarget, etc. ;
- Terminez toutes les méthodes d'environnement de navigateur utilisées par rs, afin qu'elles puissent passer rs dans une boîte noire ;
- Optimisez la méthode de débogage, vous pouvez casser le point lorsque vous voulez casser et ignorer la détection lorsque vous ne voulez pas casser ;
- Ajoutez le cas où py appelle directement le fichier de résultat, qui peut être appelé par v8 et node en utilisant python ;
- Optimisez le fichier readme et présentez la configuration et l'utilisation de l'environnement avec des images et des textes.
Dépassement de courbe, partez de moi
Le répertoire framework de cette version :
