Table des matières
Importation d'ensembles de données
Le jeu de données MINST est un jeu de données classique dans le domaine de l'apprentissage automatique, qui comprend 70 000 échantillons, dont 60 000 échantillons d'apprentissage et 10 000 échantillons de test.
Importation d'ensembles de données
À l'aide tensorflowdu cadre, kerasobtenez l'ensemble de données MNIST en :
mnist = tf.keras.datasets.mnist
À travers load_data()la méthode pour charger les données dans le jeu de données
Les données acquises tuplesont stockées au format :
(训练样本数据集,训练标签数据集),(测试样本数据集,测试标签数据集)
Utilisez donc le tuple correspondant pour recevoir les données :
(x_train, y_train), (x_test, y_test) = mnist.load_data()
Format du jeu de données
Le format des quatre ensembles de données ci-dessus est : numpy.ndarray, ndarray est un objet de type tableau à N dimensions, et vous pouvez imprimer les attributs pertinents de l'ensemble de données pour les afficher :
print("训练样本的维度为:",x_train.ndim)
print("训练样本的形状为:",x_train.shape)
print("训练样本的元素数量为:",x_train.size)
print("训练样本的数据类型为:",x_train.dtype)
Le résultat est le suivant :

On peut voir à partir de sa forme que l'ensemble de données d'échantillon d'apprentissage stocke 60 000 images numériques de 28*28 pixels ;
Contenu du jeu de données
Les images qui y sont stockées peuvent être imprimées et visualisées via le code suivant :
for i in range(0,28):
for j in range(0,28):
print("%.1f" % x_train[0][i][j] , end=" ")
print()
Le résultat est le suivant :
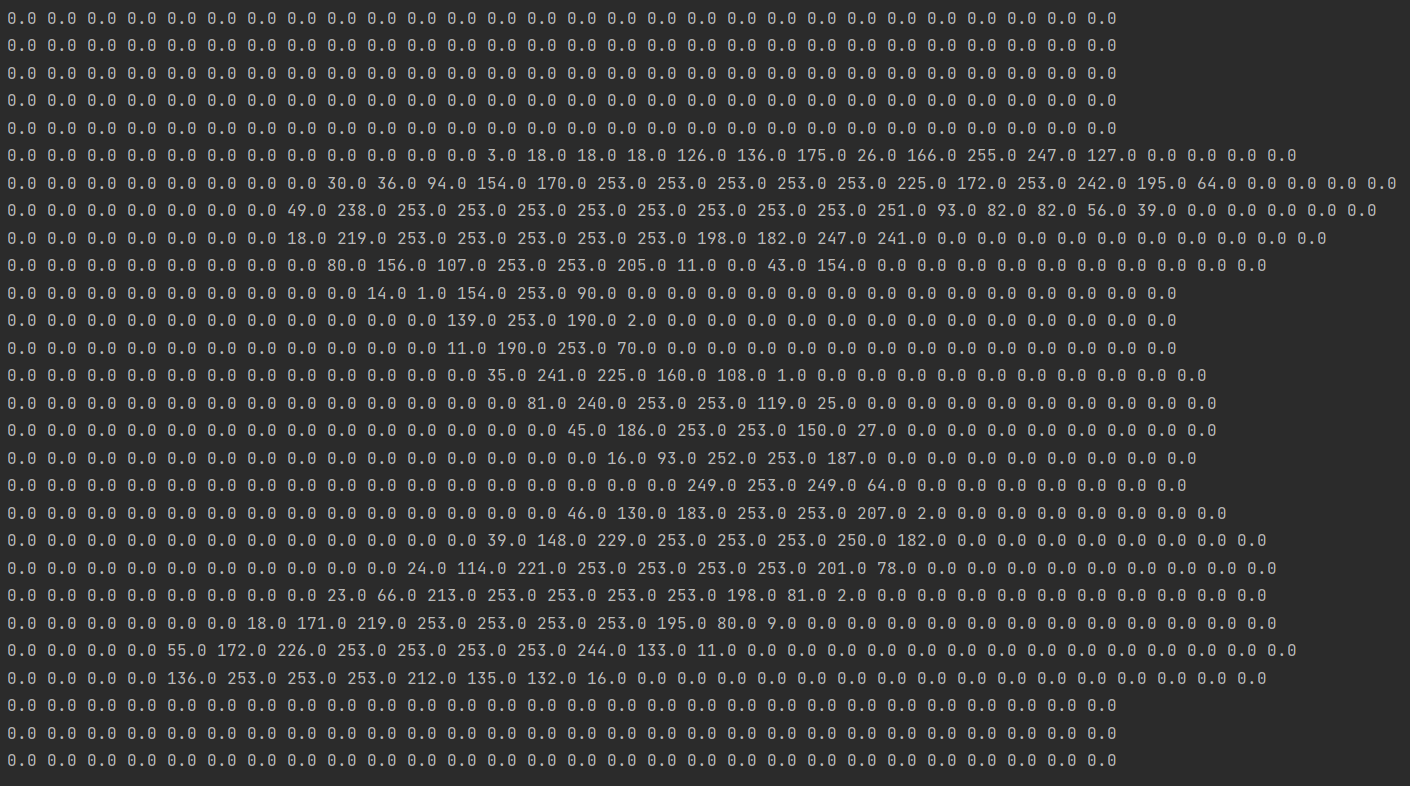
C'est évident que c'est un nombre5
Étant donné que la valeur de chaque pixel de l'ensemble de données se situe dans 0-255la plage, nous normalisons les données et les convertissons en un 0-1nombre à virgule flottante entre :
x_train, x_test = x_train / 255.0, x_test / 255.0
Comme vous pouvez le voir, le type de données a changé après le traitement :

Imprimez à nouveau l'image stockée, et on voit vaguement qu'il s'agit d'un nombre 5:
