Présentation du graphique de connaissances
Cet article résume principalement la lecture de l'article Knowledge Graphs. ACM Comput. Surv., 54(4): 1–37. 2021. Il implique une connaissance relativement superficielle des principes et vise à aider à une compréhension plus complète du graphe de connaissances. S'il y a des erreurs, n'hésitez pas à me le dire.
1. Introduction
L'origine du concept moderne de « knowledge graph » : annonce 2012 du Google Knowledge Graph
Références associées :

Exemples liés aux graphes de connaissances https://github.com/knowledge-graphs-tutorial/examples .
le terme
- Graphe de connaissances : un graphe de données destiné à accumuler et à transmettre des connaissances sur le monde réel, dont les nœuds représentent des entités d'intérêt et dont les bords représentent des relations potentiellement différentes entre ces entités. Où le graphe de données est conforme au modèle de données basé sur un graphe (bord dirigé graphe étiqueté, graphes hétérogènes, graphes d'attributs, etc.).
- Connaissance : « connaissance explicite », quelque chose qui est connu et peut être écrit.
- Graphiques de connaissances ouverts ou d'entreprise : différenciés selon l'organisation ou la communauté
2. Graphiques de données
La modélisation des données graphiques est la base de la construction de tout graphe de connaissances
Des modèles
Le modèle de données graphiques le plus couramment utilisé
-
Graphique étiqueté à arêtes dirigées (graphe del ou graphe multi-relationnel) : nœuds et arêtes étiquetées dirigées entre les nœuds. Les nœuds représentent des entités et les arêtes représentent des relations binaires entre entités.
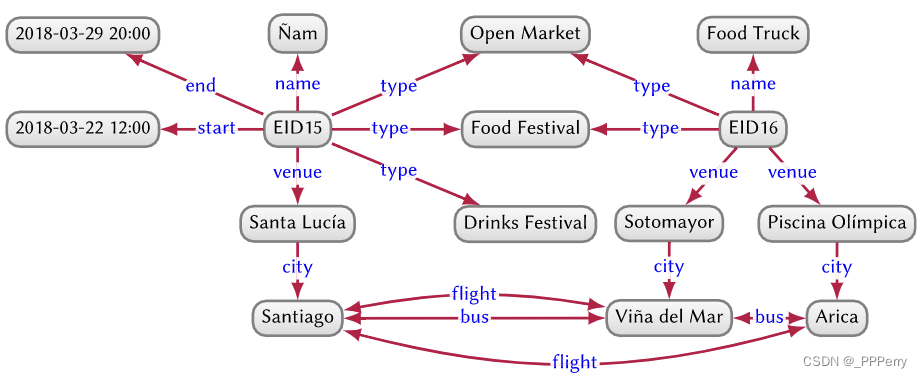
Caractéristiques : Flexible, pas besoin d'organiser les données de manière hiérarchique comme un arbre, et peut également représenter des boucles -
Graphique hétérogène : chaque nœud et chaque arête se voit attribuer un type.

-
Arête homogène : située entre deux nœuds du même type ; sinon, c'est une arête hétérogène. Permet le partitionnement des nœuds en fonction du type, qui peut être utilisé pour les tâches d'apprentissage automatique. Mais contrairement au graphe del, les nœuds et les types ne peuvent être que individuels.
-
Graphique d'attribut : les nœuds et les arêtes peuvent être associés à des valeurs d'attribut et à des étiquettes, ce qui rend la modélisation et la modification plus flexibles que le graphique d'attribut.

-
Ensemble de données graphiques : gère plusieurs graphiques, y compris un ensemble de graphiques nommés et un graphique par défaut.
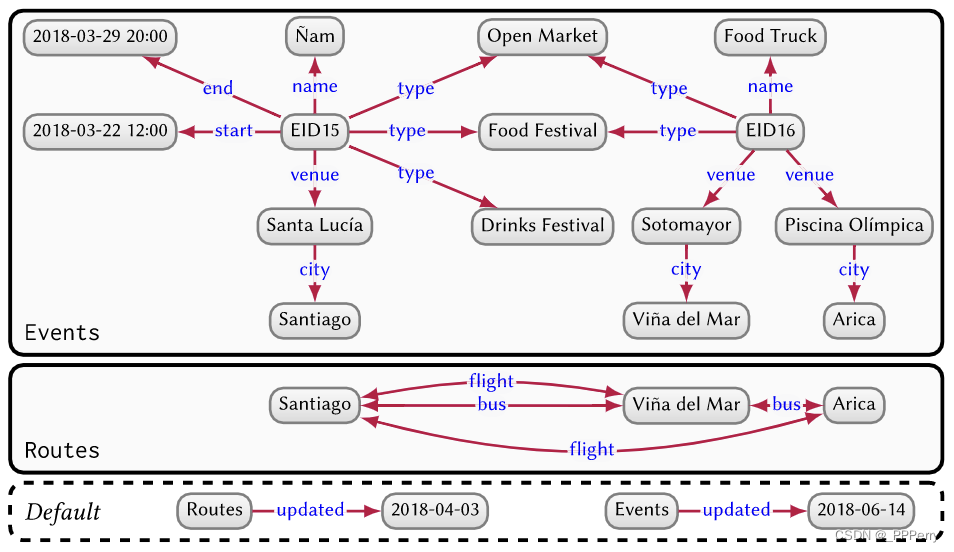
Le graphique par défaut n'a pas d'ID et gère les métadonnées du graphique nommé. Les ensembles de données graphiques peuvent être généralisés à tout type de graphique, sans se limiter aux graphiques del.
Interrogation
Langages d'interrogation de graphes : SPARQL pour les graphes del, Cypher, Gremlin, G-CORE pour les graphes de propriétés, etc.
Modèles de graphique : structure de graphique utilisée pour les requêtes, y compris les constantes et les variables. Les variables sont les variables utilisées pour la correspondance dans les requêtes. 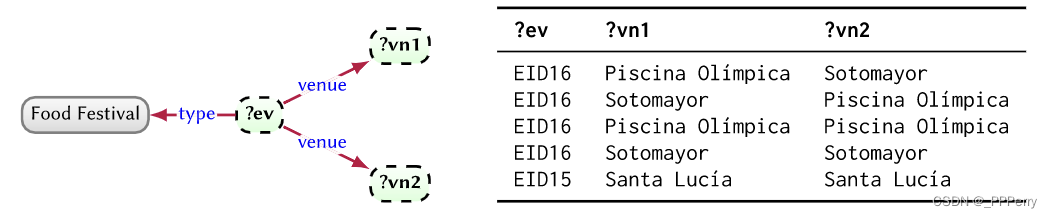
L'image de gauche montre le modèle graphique et l'image de droite montre le mappage du modèle graphique aux données graphiques. Autrement dit, le mode graphique convertit les données graphiques en un tableau de résultats mappé.
Dans les trois dernières lignes de l'image de droite, le contenu de vn1 et vn2 est le même. Ce type de résultat de requête n'est peut-être pas ce que nous souhaitons. Par conséquent, une variété de sémantiques pour évaluer les modèles de graphiques sont nées, dont les deux plus importantes sont la sémantique basée sur l'homomorphisme, qui permet à différentes variables d'être mappées sur le même terme, c'est-à-dire que tous les mappages dans la figure de droite sont renvoyés comme un résultat (SPARQL adopte cette sémantique) ; sur la base d'une sémantique basée sur l'isomorphisme, différentes variables ne peuvent pas être mappées au même terme.
De plus, il existe des modes graphiques complexes qui prennent en charge divers opérateurs SQL ou langages de requête graphique, ainsi que des modes graphiques de navigation pour les requêtes de chemin classiques, etc.
En bref, la fonction consiste à trouver un moyen de concevoir le modèle de graphique et de renvoyer la table de mappage requise à partir des données du graphique.
Validation
Bien que les graphiques fournissent des représentations flexibles pour une variété de données incomplètes à grande échelle, nous souhaiterons peut-être vérifier que nos graphiques de données suivent une structure spécifique ou sont « complets » dans un certain sens. Par exemple, nous pourrions vouloir nous assurer que tous les événements ont au moins un nom, un lieu, une date de début et de fin. Un mécanisme de vérification consiste à utiliser des tracés de forme.
Un graphe de formes se compose d'un ensemble de formes interdépendantes qui ciblent un ensemble de nœuds dans le graphe de données et spécifient des contraintes sur ces nœuds. Similaire au diagramme de classes UML.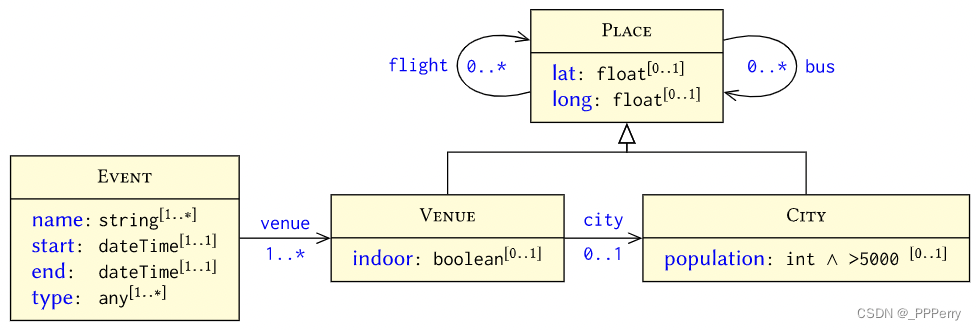
Contexte
Le contexte contient des informations implicites sur les données, telles que le moment et le lieu où elles se sont produites, permettant aux données d'être interprétées sous différents angles.
Pour les informations contextuelles des données, vous pouvez utiliser directement le contexte comme nœud de données, ou vous pouvez définir des informations de bord, etc., comme le montre la figure ci-dessous, e est utilisé comme bord plutôt que comme nœud de données dans une représentation directe .
3. Connaissance déductive
Cette partie contient de nombreuses spécifications et normes, et peu d’entre elles sont impliquées dans des scénarios d’application réels. Elles sont brièvement résumées ici.
Nous pouvons déduire plus de connaissances à partir du graphique de données. Par exemple, dans le premier graphique, nous déduisons que le festival de musique a lieu à San Diego, etc. Étant donné les données comme prémisses et certaines règles a priori que nous pourrions connaître sur le monde, nous pouvons utiliser un processus déductif pour dériver de nouvelles données.
En donnant à la machine des résultats logiques formalisés, un raisonnement automatisé peut être réalisé. Bien que nous puissions utiliser de nombreux cadres logiques pour atteindre ces objectifs, tels que la logique du premier ordre, le Datalog, le Prolog, la programmation d'ensembles de réponses, etc., nous nous concentrons sur la connaissance elle-même (ontologies), qui peut être considérée comme un graphe de connaissances avec une signification claire. .
Ontologies
L'ontologie de la connaissance est une forme de représentation, une méthode de représentation spécifique et formelle des termes de connaissance. Le langage d’ontologie le plus populaire est le langage d’ontologie Web (OWL).
En ontologie, les nœuds et les bords peuvent être mappés au sens d'interprétation de notre vie réelle. La carte d'interprétation résultante est appelée un graphe de domaine, qui doit être complètement cohérent avec la structure originale du graphe de données.
Pour des explications, il existe également des normes pour diverses hypothèses, telles que l'hypothèse d'un monde fermé (CWA)/l'hypothèse d'un monde ouvert (OWA), l'hypothèse d'un nom unique (UNA)/l'hypothèse d'un nom unique (NUNA) (par exemple, la même entité peut y sont des noms différents, etc.) etc.
En plus des hypothèses, nous pouvons également définir certains modèles dans le graphique de données et les explications associées qui satisfont ce modèle. Par exemple, des modèles spécifiques peuvent être définis pour des entités, des attributs et même des classes, afin que des informations d'interprétation cohérentes puissent être découvertes sur la base du modèle.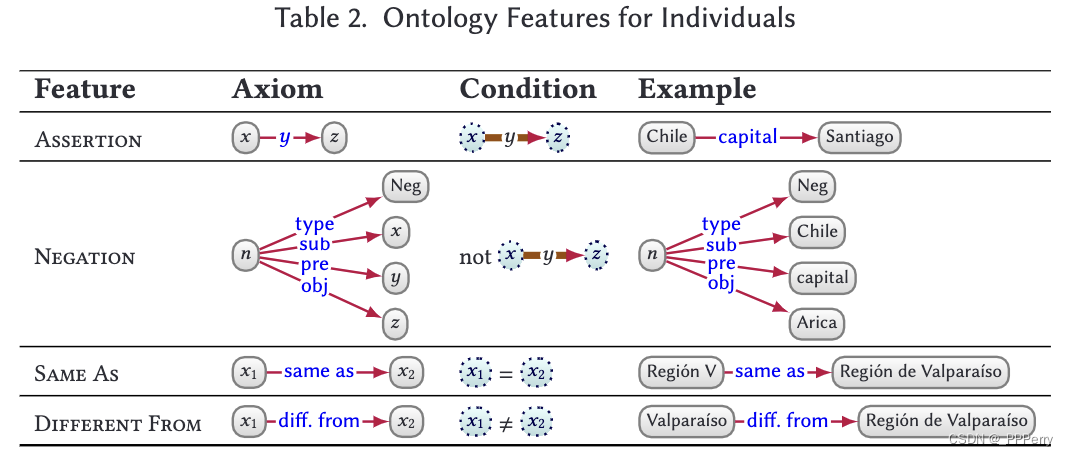
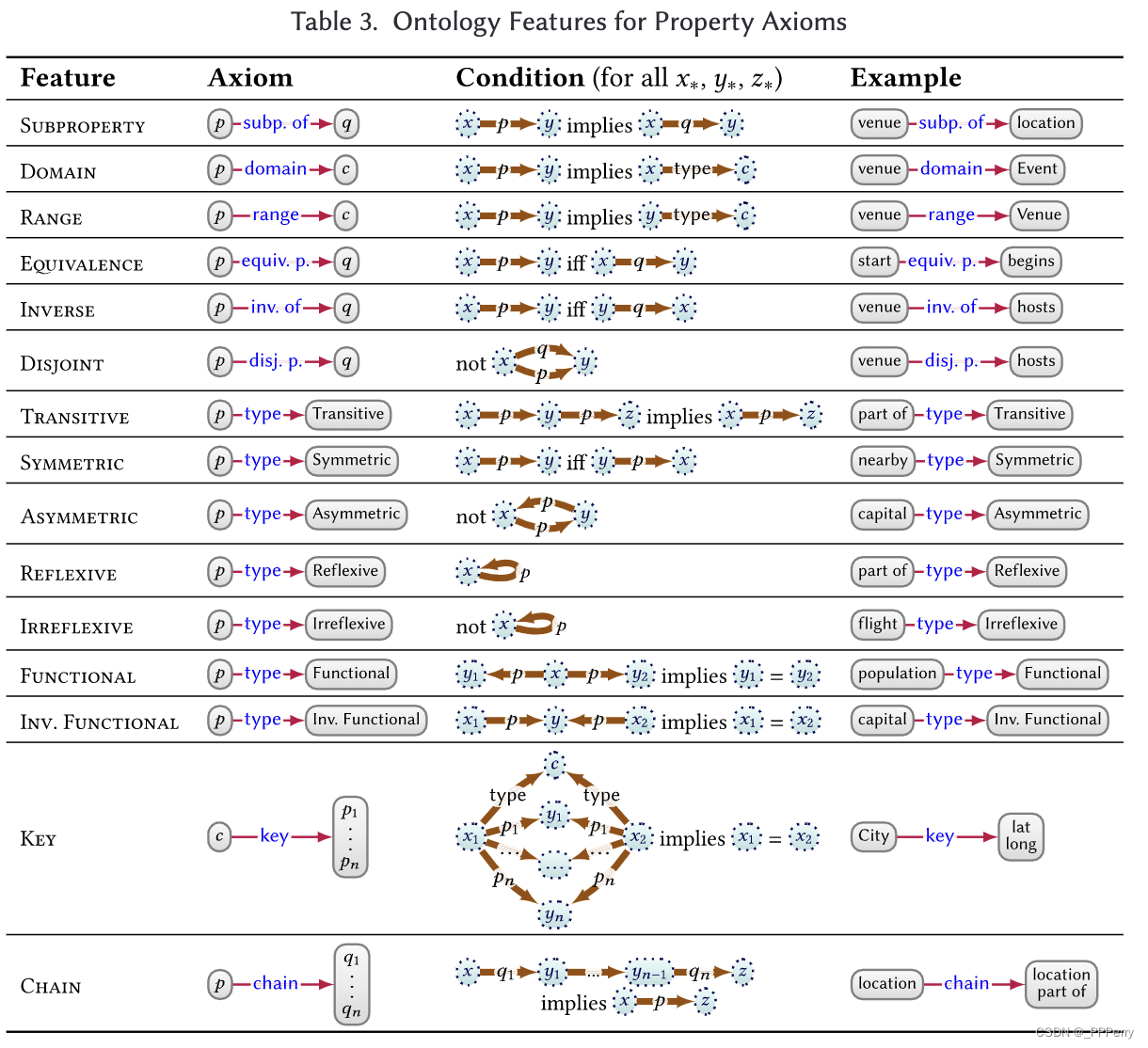
Raisonnement
La norme OWL définit également des règles d'inférence et propose diverses façons de mettre en œuvre l'inférence. La norme OWL est également influencée par des descriptions plus logiques, les Description Logics (DL), qui peuvent être considérées comme le prédécesseur des graphes de connaissances.
4. CONNAISSANCES INDUCTIVES
Le raisonnement inductif peut généraliser des modèles à partir de données d’entrée, et ces modèles peuvent être utilisés pour générer des prédictions nouvelles mais potentiellement imprécises.
Par exemple, à partir du graphique contenant des informations géographiques et de vol, nous pouvons observer que presque toutes les capitales des pays ont des aéroports internationaux, et donc prédire que puisque Santiago est la capitale, elle peut aussi avoir un aéroport international ; cependant, certaines capitales (comme Vaduz ) ne possède pas d'aéroport international. Il est donc possible que les prévisions ne soient pas tout à fait exactes. Si l’on constate que 187 des 195 capitales disposent d’aéroports internationaux, alors on peut attribuer un niveau de confiance de 0,959 aux prédictions faites à l’aide de ce modèle.
Nous appelons connaissances inductives les connaissances obtenues par induction, incluant les modèles généralisés et les prédictions faites par ces modèles.
L'apprentissage supervisé et non supervisé est souvent utilisé dans les techniques d'induction pour les graphiques de connaissances, comme le montre la figure. 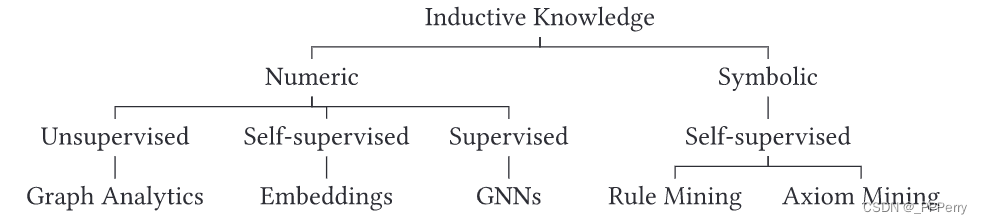
Dans l'analyse de graphes, une grande quantité de travail utilise des méthodes non supervisées, telles que la détection de communautés ou de clusters, la recherche de nœuds centraux et d'arêtes dans les graphiques, etc. L'intégration de graphiques utilise l'autosupervision pour apprendre des modèles numériques de faible dimension dans des graphiques de connaissances. Les structures graphiques peuvent également être utilisées directement pour l’apprentissage supervisé via des réseaux neuronaux graphiques. L'apprentissage symbolique peut apprendre des modèles symboliques à partir de graphiques de manière auto-supervisée, c'est-à-dire des formules logiques sous forme de règles ou d'axiomes, etc.
Analyse graphique
Les algorithmes graphiques sont généralement utilisés pour analyser la topologie des graphiques, comme la façon dont les nœuds et les groupes sont connectés, etc. Dans cette section, nous présentons les algorithmes de graphes courants appliqués aux graphes de connaissances, ainsi que les frameworks de traitement de graphes qui peuvent implémenter de tels algorithmes.
Algorithmes graphiques
-
Analyse de centralité : identification des points et des bords les plus importants du graphique. Les mesures spécifiques de centralité des nœuds incluent le degré, l'intermédiarité, la proximité, le vecteur de caractéristiques, le PageRank, les HITS, Katz, etc. La centralité de la mesure d’intermédiarité peut également être appliquée aux bords, par exemple en prédisant les sections de trafic les plus fréquentées en trouvant les bords les plus dépendants sur des itinéraires courts.
-
Détection de communauté : identifiez les sous-graphes qui sont davantage connectés en interne. Y compris l'algorithme de coupe minimale, la propagation d'étiquettes, la modularisation de Louvain , etc.
-
Analyse de connectivité : estimation de la connectivité et de l'élasticité d'un graphique. Y compris la mesure de la densité graphique ou de la connectivité k, la détection des composants fortement/faiblement connectés, le calcul des arbres couvrants ou des coupes minimales, etc.
-
Similitude des nœuds : recherchez des nœuds similaires grâce à la manière dont les nœuds sont connectés dans le quartier. Y compris l'utilisation de l'équivalence structurelle, de la marche aléatoire, du noyau de diffusion et d'autres méthodes pour mesurer la similarité. Ces méthodes peuvent nous aider à mieux comprendre ce qui relie les nœuds et en quoi ils sont similaires.
-
Résumé de graphiques : extraction d'une structure de haut niveau à partir de graphiques, souvent utilisée dans les graphiques de quotient. Une telle approche permet de fournir une vue d’ensemble des graphiques à grande échelle. Un exemple est montré dans la figure.
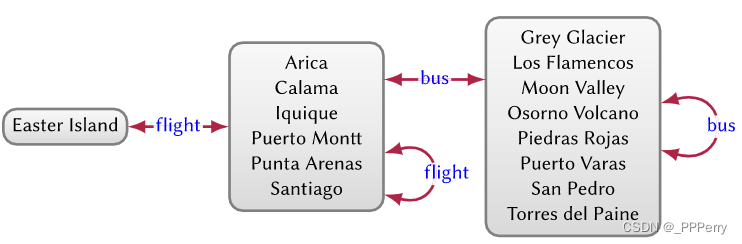
Dans ce cas, les nœuds quotients sont définis en termes d'étiquettes de bords sortants, par exemple, nous généralisons de gauche à droite pour représenter respectivement les îles, les villes et les villages.
De nombreux algorithmes de graphes de ce type ont été proposés et étudiés pour des graphes simples ou des graphes orientés sans étiquettes d'arêtes. Dans le contexte des graphes de connaissances, l’un des défis consiste à savoir comment appliquer ces algorithmes à des modèles de graphes de connaissances tels que les graphes del, les graphes hétérogènes ou les graphes d’attributs.
Cadres de traitement de graphiques
Pour les tâches de traitement à grande échelle, de nombreux frameworks de graphes parallèles ont été proposés, tels qu'Apache Spark (GraphX), GraphLab, Pregel, Signal–Collect, Shark, etc. Ces frameworks utilisent le calcul itératif, où chaque nœud lit le message du front entrant (et éventuellement son état précédent), effectue le calcul puis envoie le résultat au bord sortant.
Un exemple de l'algorithme itératif PageRank sur un cadre de graphes parallèles est présenté dans la figure. 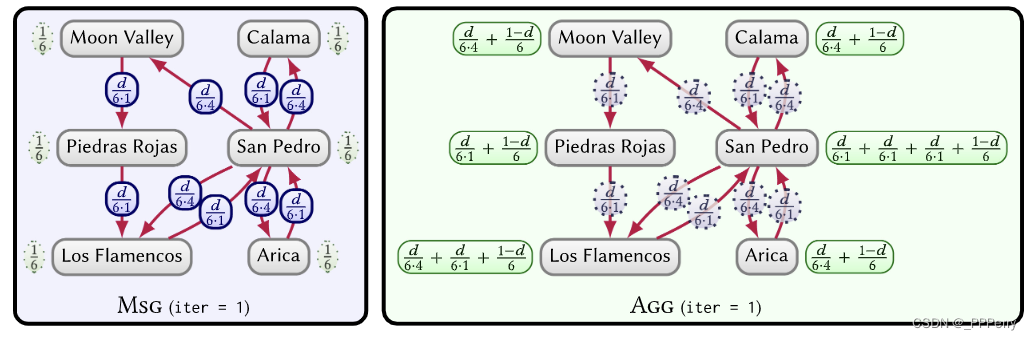
Les algorithmes de ce cadre sont constitués de fonctions qui calculent les valeurs des messages (MSG) et les messages accumulés (AGG).
Intégrations de graphes de connaissances
L'apprentissage automatique peut être directement utilisé pour affiner les graphes de connaissances ; ou il peut être utilisé pour des tâches en aval des graphes de connaissances, telles que la recommandation, l'extraction d'informations, la réponse à des questions, la relaxation de requêtes, l'approximation de requêtes, etc. Cependant, les techniques d’apprentissage automatique utilisent souvent des représentations numériques (par exemple des vecteurs), qui sont souvent différentes des représentations graphiques. Alors, comment encoder numériquement des graphiques pour l’apprentissage automatique ?
La tentative initiale consistait à utiliser des codes uniques pour créer un L × VL\times V pour chaque nœud.L×matrice de V , LLL représente le nombre de types d'étiquettes de bord,VVV représente le nombre de points.
Pourquoi ne pas utiliser ici une matrice de points ? Parce que contrairement aux modèles de graphiques courants, il peut y avoir plusieurs bords d'étiquettes entre différents points du graphe de connaissances.
Cependant, une telle représentation aboutit à une matrice clairsemée et trop grande, trop complexe pour la plupart des modèles d'apprentissage automatique.
L'objectif principal de la technologie d'intégration de graphes de connaissances est de créer une représentation dense du graphe (c'est-à-dire un graphe d'intégration) dans un espace vectoriel continu de faible dimension (fixe, généralement très faible), qui peut être utilisé pour des tâches d'apprentissage automatique.
Afin d'obtenir un modèle d'intégration, selon une fonction de notation donnée, nous devons maximiser la plausibilité des arêtes positives (généralement des arêtes dans le graphe) et minimiser la plausibilité des exemples négatifs (généralement des changements dans les étiquettes de nœuds ou d'arêtes dans le graphe, comme (c'est-à-dire les arêtes qui ne sont plus dans le graphique). Les intégrations résultantes peuvent alors être considérées comme un apprentissage auto-supervisé d'un modèle qui code les caractéristiques (latentes) du graphique, mappant les bords d'entrée aux scores de plausibilité.
Les intégrations peuvent être utilisées pour de nombreuses tâches en aval. Les fonctions de notation de plausibilité peuvent être utilisées pour attribuer la confiance aux arêtes ou prédire les connexions manquantes. De plus, les intégrations attribuent souvent des vecteurs similaires à des termes similaires et peuvent donc également être utilisées pour des mesures de similarité.
Nous aborderons ensuite certaines des techniques d’intégration de graphiques les plus couramment utilisées.
Modèles translationnels
Le modèle de traduction interprète les étiquettes de bord comme des transitions des nœuds de tête aux nœuds de queue. Par exemple 
, considérez l'étiquette de bus comme convertissant San Pedro en Moon Valley.
L’approche pionnière des modèles de traduction est TransE. Pour le front montant ci-dessus, TransE apprendra le vecteur e S \boldsymbol{e}_SeS,rb \boldsymbol{r}_brbet e M \boldsymbol{e}_MeM, et fait e S + rb \boldsymbol{e}_S + \boldsymbol{r}_beS+rbAussi proche que possible de e M \boldsymbol{e}_MeM. Pour le côté négatif, laissez la somme des deux vecteurs être aussi éloignée que possible. La figure ci-dessous est la représentation intégrée de TransE des relations et des entités dans un graphique bidimensionnel. 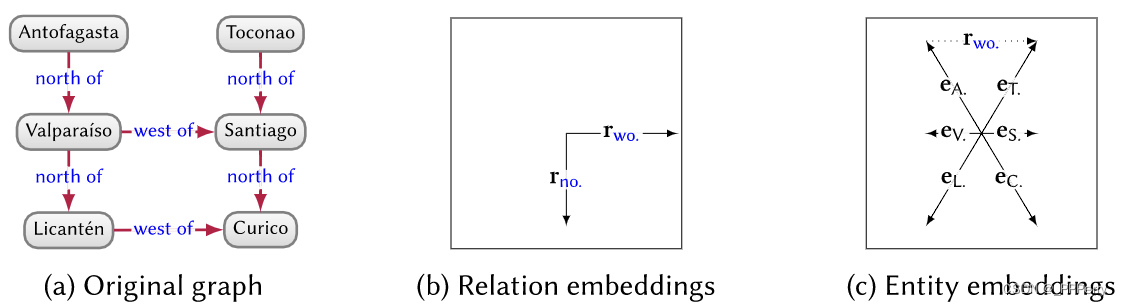
Afin d'empêcher l'algorithme TransE d'attribuer des vecteurs similaires à différentes arêtes, il existe également de nombreuses techniques qui utilisent des hyperplans ou des espaces vectoriels différents pour améliorer l'algorithme.
Modèles de décomposition tensorielle
Le tenseur est un champ numérique multidimensionnel qui peut généraliser les scalaires (tenseurs d'ordre 0), les vecteurs (tenseurs d'ordre 1) et les matrices (tenseurs d'ordre 2) à n'importe quelle dimension. La décomposition tensorielle implique la décomposition d'un tenseur en tenseurs de plus basse dimension, et le tenseur d'origine peut être recombiné (ou approché) par une séquence d'opérations de base fixées par ces tenseurs de basse dimension. Ces tenseurs peuvent être considérés comme capturant les facteurs latents dans les tenseurs d’origine. Il existe de nombreuses approches de la décomposition tensorielle, nous allons maintenant présenter brièvement l'idée principale derrière la décomposition tensorielle.
Étant donné a × ba\times bun×bmatrixCC __C , où chaque élémentC ij C_{ij}Cjereprésente le iije villejjLa température moyenne pendant j mois. On peut décomposer la matrice en une matrice de longueuraavecteurxx d' unx (les villes situées à des latitudes inférieures ont des températures plus basses) et la longueur estbbvecteuryy de by (la température est plus basse en automne et en hiver), siC = x × y C=x\times yC=X×y , alorsCCC est une matrice de rang 1. Sinon, le rang est la matrice de représentationCCLe nombre de sommes minimales de produits vectoriels requises par C , c'est-à-dire C = x 1 × y 1 + ⋯ + xr × yr C=x_1\times y_1 + \cdots + x_r \times y_rC=X1×oui1+⋯+Xr×ouir. Ce dernier produit vectoriel peut correspondre à la correction de l’altitude urbaine, aux changements de température plus élevés et à d’autres facteurs. La décomposition des rangs d'une matrice consiste à fixer une limite ddd , calculerjjLa somme des produits de d vecteurs donne le ddde la meilleure matriceapproximation du rang d . Nous étendons cette idée à la décomposition de tenseurs de bas rang, qui est laméthode Canonical Polyadic (CP).
Pour le graphe de connaissances, nous pouvons définir une matrice de codage tridimensionnelle à chaud, représentant point-étiquette bord-point, puis la décomposer en la somme de plusieurs produits à trois vecteurs, comme le montre la figure ci-dessous. 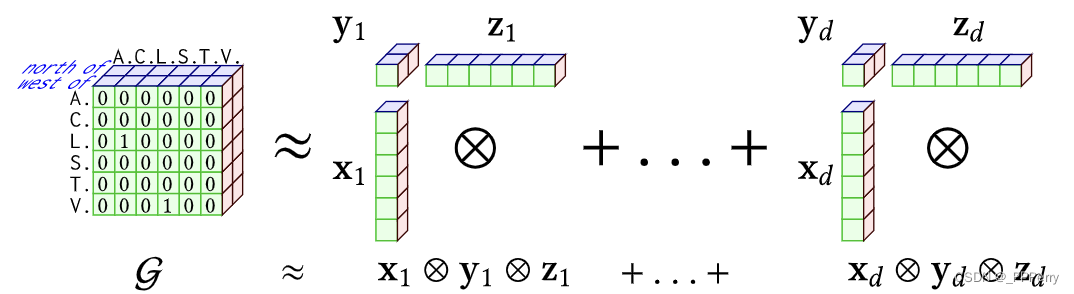
Cependant, l’objectif de notre intégration de graphes de connaissances est généralement d’attribuer un vecteur à chaque entité.
DisMult est une méthode pionnière pour calculer l'intégration de graphes de connaissances basée sur la décomposition des rangs, où chaque entité et relation est associée à une dimension de dd .Le vecteur de d est associé, donc pour l'arête
, concevoir une fonction de notation de plausibilité∑ i = 1 d ( es ) i ( rp ) i ( eo ) i \sum_{i=1}^{d}\left(\mathbf { e}_{\mathrm{s}}\right)_{i}\left(\mathbf{r}_{\mathrm{p}}\right)_{i}\left(\mathbf{e}_ { \mathrm{o}}\right)_{i}∑je = 1ré( es)je( rp)je( eo)je, le but est d'apprendre le vecteur de chaque nœud et arête pour maximiser la plausibilité des arêtes positives et minimiser la plausibilité des arêtes négatives. Mais cette méthode a un inconvénient, sss -orientéooLa fonction de notation de o etooo pointe versssLa fonction de notation de s est la même, c'est-à-dire qu'il n'existe aucun moyen de capturer les informations de direction du bord.
RESCAL utilise des matrices au lieu de vecteurs comme plongements relationnels, conservant ainsi la directionnalité des arêtes, mais l'espace et le temps de calcul vont bien au-delà de la méthode DistMult. ComplEx utilise des vecteurs complexes et HolE utilise des facteurs de corrélation circulaire (nombres réels) pour préserver les directions des bords. D'autres méthodes de décomposition incluent SimplE et TuckER . Parmi elles, TuckER est la méthode SOTA actuellement sur les benchmarks.
Modèles neuronaux
De nombreuses méthodes utilisent des réseaux de neurones pour apprendre les intégrations de graphes de connaissances avec des fonctions de notation non linéaires.
En plus de MLP , il existe également des méthodes de convolution telles que ConvE et HypER qui apprennent en permanence les poids pour générer une méthode de représentation intégrée pour les vecteurs de code one-hot basée sur les paramètres de poids.
Modèles de langage
La méthode de représentation du langage naturel est la méthode d'intégration classique, telle que word2vec et GloVe .
De même, les méthodes d’intégration de langage peuvent également être appliquées aux graphiques. RDF2Vec effectue une marche aléatoire biaisée sur le graphique et enregistre les chemins parcourus sous forme de « phrases », qui sont ensuite introduites dans le modèle word2vec en entrée. KGloVe est basé sur le modèle GloVe. Tout comme le modèle GloVe original considère les mots qui apparaissent fréquemment dans une fenêtre de texte comme étant plus pertinents, KGloVe utilise le PageRank personnalisé pour déterminer quels nœuds sont les plus pertinents pour un nœud donné, puis alimente les résultats dans le modèle GloVe.
Modèles prenant en compte les implications
Jusqu’à présent, les intégrations n’ont pris en compte que les graphiques de données. Mais que se passe-t-il si une connaissance a priori d’un ensemble de règles est fournie ? On peut dans un premier temps envisager d’utiliser des règles de contraintes pour affiner les prédictions faites par le plongement. Par exemple, si nous définissons qu'un événement peut avoir au plus une valeur de lieu, il devient moins raisonnable d'attribuer plusieurs lieux à un bord pour un événement.
Les méthodes récentes préfèrent proposer des plongements conjoints qui prennent en compte à la fois les graphiques de données et les règles, comme FSL et KALE .
Réseaux de neurones graphiques
Au lieu de représenter les graphiques sous forme de vecteurs mathématiques, une alternative consiste à définir une architecture d’apprentissage automatique personnalisée pour le graphique. La plupart de ces architectures sont basées sur des réseaux de neurones. Cependant, les réseaux de neurones traditionnels ont tendance à avoir une topologie plus homogène, tandis que la topologie des graphes est généralement plus hétérogène.
Le **réseau de neurones graphiques (GNN)** est un type de réseau de neurones qui, contrairement aux intégrations, prend en charge l'apprentissage supervisé de bout en bout pour une tâche spécifique : étant donné un ensemble d'exemples étiquetés, un GNN peut être utilisé pour effectuer des tâches sur éléments d'un graphique ou sur le graphique lui-même. Classification. GNN a été utilisé pour classer des composés codés sous forme de graphiques, des objets dans des images, des documents, etc., ainsi que pour prédire le trafic, créer des systèmes de recommandation, vérifier des logiciels, etc. À partir d'exemples étiquetés, les GNN peuvent même remplacer les algorithmes de graphes. Par exemple, les GNN ont été utilisés pour trouver des nœuds centraux dans des graphes de connaissances de manière supervisée.
Nous présenterons deux types de GNN : récursifs et convolutifs.
Réseaux de neurones graphiques récursifs
Les réseaux de neurones graphiques récursifs (RecGNN) sont des travaux pionniers dans les réseaux de neurones graphiques. Il prend en entrée un graphe orienté avec des nœuds et des arêtes associés à des vecteurs de caractéristiques statiques qui capturent les étiquettes de nœuds et d'arêtes, les poids, etc. Chaque nœud du graphique possède également un vecteur d'état qui est mis à jour de manière récursive à l'aide d'une fonction de transformation paramétrique basée sur les informations provenant des voisins du nœud (c'est-à-dire les caractéristiques et les vecteurs d'état des nœuds et des bords adjacents). La fonction de sortie paramétrique calcule ensuite la sortie finale du nœud en fonction de ses propres caractéristiques et vecteur d'état. Ces fonctions sont appliquées récursivement à un point fixe. Étant donné un ensemble de nœuds partiellement étiquetés dans un graphe, un réseau de neurones peut être utilisé pour apprendre ces deux fonctions paramétriques. Par conséquent, les résultats peuvent être considérés comme des architectures de réseaux neuronaux récursives (voire récurrentes).
Un exemple est montré dans la figure. 
Dans le graphique, les nœuds sont représentés par des vecteurs de caractéristiques nx n_xnx(codage à chaud des types de nœuds) et ttÉtat caché hx (t) h_x^{(t)}au temps thX( t )Les annotations sont faites, tandis que les arêtes sont annotées avec des vecteurs de caractéristiques a_{xy}unx y(Encodage à chaud du type de balise) Commentaire. ff à droitef etggLa fonction g correspond respectivement à la fonction de conversion de paramètres et à la fonction de sortie de paramètres. Pour former le réseau, nous pouvons étiqueter les lieux qui ont des offices de tourisme et ceux qui n'en ont pas. Ces étiquettes peuvent provenir du knowledge graph ou peuvent être étiquetées manuellement. Ensuite, GNN apprend deux paramètreswww sommew ′ w'w′ , qui peut ensuite être utilisé pour marquer d'autres nœuds.
Réseaux de neurones à graphes convolutifs
Les GNN et les CNN fonctionnent sur les régions locales des données d'entrée : les GNN opèrent sur les nœuds du graphique et leurs voisins. Suivant cette intuition, de nombreux réseaux de neurones à graphes convolutifs ( ConvGNN ), également connus sous le nom de réseaux convolutifs à graphes ( GCN ), ont été proposés, dans lesquels la fonction de transformation est implémentée par convolution.
Un avantage de CNN est que le même noyau peut être appliqué à toutes les zones de l'image, mais ce n'est pas le cas de ConvGNN, car contrairement au cas des images, les pixels de l'image ont un nombre prévisible de voisins, mais les nœuds dans le graphique peut être divers. Les approches pour relever ces défis impliquent l'utilisation de représentations spectrales de graphiques pour induire des structures plus régulières à partir des graphiques. Une autre approche consiste à utiliser un mécanisme d'attention pour apprendre les nœuds dont les fonctionnalités sont les plus importantes pour le nœud actuel.
Outre les aspects architecturaux, il existe deux différences principales entre RecGNN et ConvGNN.
- RecGNN agrège de manière récursive les informations des voisins vers un point fixe, tandis que ConvGNN applique généralement un nombre fixe de couches convolutives.
- RecGNN utilise généralement les mêmes fonctions/paramètres dans une étape unifiée, tandis que différentes couches convolutives de ConvGNN peuvent appliquer différents noyaux/poids à chaque étape différente.
Apprentissage symbolique
L’apprentissage supervisé discuté jusqu’à présent rend difficile l’interprétation des modèles numériques, et les raisons pour faire des prédictions raisonnables sont implicites dans la matrice complexe des paramètres appris. Dans le même temps, les intégrations souffrent également de problèmes de vocabulaire et ne parviennent souvent pas à fournir des résultats pour les entrées de nœuds ou de bords inédits. Une solution consiste à utiliser l’apprentissage symbolique pour expliquer les hypothèses des côtés positifs et négatifs dans un langage logique (symbolique). De telles hypothèses sont sujettes à interprétation. De plus, ils sont quantifiables (par exemple « Tous les aéroports sont nationaux ou internationaux »), résolvant en partie le problème du vocabulaire.
Il existe deux formes principales d'apprentissage symbolique pour les graphes de connaissances : l'exploration de règles pour l'apprentissage de règles et l'exploration d'axiomes pour l'apprentissage d'autres formes d'axiomes logiques. Cette partie correspond principalement aux règles et au langage logique du chapitre 3, avec moins d'application pratique.
Exploration de règles
L'exploration de règles fait généralement référence à la découverte de modèles significatifs sous la forme de règles à partir d'une vaste collection de connaissances de base.
Bien que des tâches similaires pour les paramètres relationnels aient été explorées à l'aide de la programmation logique inductive (ILP), il n'est pas clair comment définir des bords négatifs lorsqu'il s'agit de graphes de connaissances incomplets (sous OWA). Une heuristique courante consiste à utiliser l'hypothèse d'exhaustivité partielle (ACP) .
Un système d'exploration de règles de graphes influent est AMIE , qui adopte la mesure de confiance PCA et construit des règles de manière descendante. Des travaux ultérieurs se sont appuyés sur ces techniques pour extraire des règles à partir de graphiques de connaissances.
Une autre direction de recherche concerne l'exploration de règles différenciables, qui permet un apprentissage de bout en bout des règles en utilisant la multiplication matricielle pour coder les connexions dans le corps des règles.
Axiome minier
En plus des règles, des formes d'axiomes plus générales — exprimées dans des langages logiques (tels que les DL) — peuvent être extraites des graphes de connaissances. Nous pouvons diviser ces méthodes en deux catégories : les méthodes qui exploitent des axiomes spécifiques (comme les axiomes de disjonction, etc.) ou des axiomes généraux (DL-Learner, etc.).
5. Résumé et conclusion
Un graphe de connaissances est un fondement commun de connaissances au sein d'une organisation ou d'une communauté qui permet la représentation, l'accumulation, la gestion et la diffusion des connaissances au fil du temps. Les graphes de connaissances ont été utilisés dans divers cas d'utilisation, allant des applications commerciales impliquant la recherche sémantique, les recommandations des utilisateurs, les agents conversationnels, la publicité ciblée, l'automatisation des transports, etc., jusqu'aux graphes de connaissances ouverts pour le bien public. Les tendances générales comprennent :
- Utilisez des graphiques de connaissances pour intégrer et exploiter des données provenant de sources disparates à grande échelle
- Déduction combinée (règles, ontologie, etc.)
- Techniques inductives (machine learning, analytique, etc.) pour représenter et accumuler des connaissances
Au-delà de sujets spécifiques, les défis plus généraux des graphes de connaissances incluent l'évolutivité, en particulier pour le raisonnement déductif et inductif ; la qualité, non seulement en termes de données mais aussi en termes de modèles dérivés des graphes de connaissances ; la diversité, comme la gestion du contexte ou des données multimodales ; le dynamisme. , en tenant compte du temps ou du streaming des données ; et enfin de la convivialité, qui est essentielle pour accroître l'adoption. Bien que des technologies soient constamment proposées pour résoudre avec précision ces défis, il est peu probable qu’elles soient complètement résolues ; elles servent plutôt d’indicateurs dimensionnels indiquant que le graphe de connaissances et ses technologies, outils, etc. continueront à mûrir.