Artikelverzeichnis
G1s NUMA-Speicherzuordnungsoptimierung
Einführung in NUMA
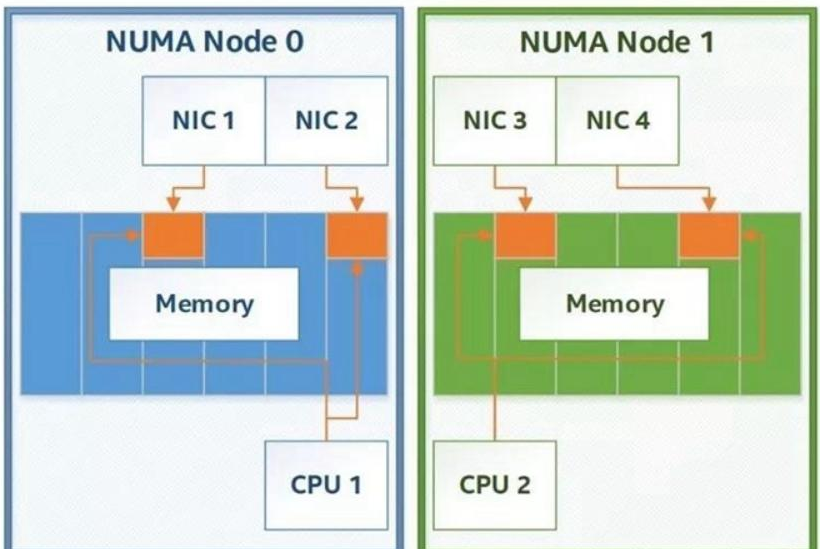
NUMA ist eine nicht einheitliche Speicherzugriffsarchitektur (englisch: Non-Uniform Memory Access, kurz NUMA). Es handelt sich um eine Speicherarchitektur, die für Computer mit mehreren Prozessoren entwickelt wurde. Die Speicherzugriffszeit hängt von der Position des Speichers relativ zum Prozessor ab. Unter NUMA kann ein Prozessor schneller auf seinen eigenen lokalen Speicher zugreifen als auf nicht-lokalen Speicher (Speicher, der sich auf einem anderen Prozessor befindet oder von Prozessoren gemeinsam genutzter Speicher). Wie in der folgenden Abbildung dargestellt, greift die CPU in Knoten0 auf den Speicher in Knoten0 zu, wenn sie auf den lokalen Speicher zugreift. Wenn sie auf den Speicher in Knoten1 zugreift, handelt es sich um einen Fernzugriff mit schlechter Leistung:
Die Merkmale der uneinheitlichen Speicherzugriffsarchitektur sind:
Der gemeinsam genutzte Speicher ist physisch verteilt und die Sammlung all dieser Speicher ist der globale Adressraum. Daher ist die Zeit, die der Prozessor benötigt, um auf diese Speicher zuzugreifen, unterschiedlich. Offensichtlich ist der Zugriff auf den lokalen Speicher schneller als der Zugriff auf den globalen gemeinsam genutzten Speicher oder der Fernzugriff auf den Fremdspeicher. Darüber hinaus kann der Speicher in NUMA hierarchisch sein: lokaler Speicher, gemeinsam genutzter Speicher innerhalb der Gruppe und globaler gemeinsam genutzter Speicher.
Ziel
JEP345 hofft, die G1-Leistung auf Mainframes durch die Implementierung einer NUMA-fähigen Speicherzuweisung zu verbessern.
Immer mehr moderne Multi-Socket-Server verfügen über NUMA, was bedeutet, dass der Abstand vom Speicher zu jedem Socket ungleich ist und es Leistungsunterschiede beim Speicherzugriff auf verschiedene Sockets gibt. Je länger der Abstand, desto geringer die Latenz. Je größer sie ist , desto schlechter wird die Leistung sein!
Der Heap von G1 ist als Sammlung von Bereichen fester Größe organisiert. Eine Region besteht normalerweise aus einer Reihe physischer Seiten. Bei Verwendung großer Seiten (über -XX:+UseLargePages) können jedoch mehrere Regionen eine physische Seite bilden.
Wenn die Option +XX:+UseNUMA angegeben ist, werden die Regionen bei der Initialisierung der JVM gleichmäßig über die Gesamtzahl der verfügbaren NUMA-Knoten verteilt.
Das Einklemmen von NUMA-Knoten pro Zone am Anfang ist etwas unflexibel, kann aber durch die folgenden Verbesserungen gemildert werden. Um neue Objekte für den Mutator-Thread zuzuweisen, muss G1 möglicherweise einen neuen Bereich zuweisen. Dies geschieht durch die bevorzugte Auswahl eines freien Bereichs aus dem NUMA-Knoten, der an den aktuellen Thread gebunden ist, sodass das Objekt in der neuen Generation auf demselben NUMA-Knoten bleibt. Wenn während des Zuweisungsprozesses einer Region für eine Variable keine freie Region auf demselben NUMA-Knoten vorhanden ist, löst G1 die Speicherbereinigung aus. Eine weitere zu bewertende Idee besteht darin, nach freien Bereichen in anderen NUMA-Knoten in der Reihenfolge ihrer Entfernung zu suchen, beginnend mit dem nächstgelegenen NUMA-Knoten.
Diese Funktion versucht nicht, Objekte in der alten Generation auf demselben NUMA-Knoten zu halten.
JEP 345 wurde speziell für die Implementierung der NUMA-Unterstützung für den G1-Garbage Collector entwickelt, nur für die Speicherverwaltung (Speicherzuweisung) und nur unter Linux. Ob diese Unterstützung für NUMA-Architekturen auch für andere Garbage Collectors oder andere Teile (wie Task Queue Stealing) gilt, ist unklar.
Serial+CMS, ParNew+Serial Old verwerfen
Aufgrund der Kosten für Wartung und Kompatibilitätstests wurden die beiden Kombinationen Serial+CMS und ParNew+Serial Old in JDK8 (JEP173) für veraltet erklärt und die Unterstützung für diese Kombinationen wurde in JDK9 (JEP214) vollständig eingestellt.
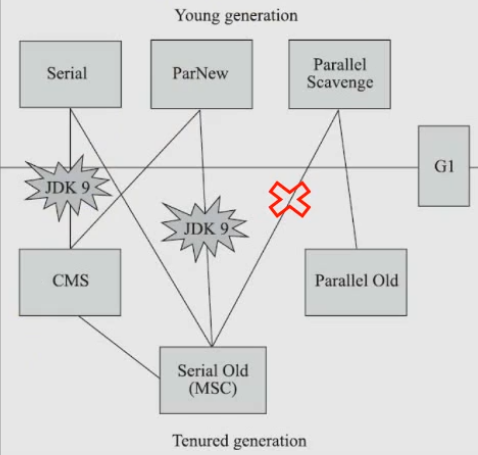
Die GC-Kombination aus ParallelScavenge+SerialOld GC wird als veraltet markiert
Grund
Diese GC-Kombination erfordert viel Code-Wartungsarbeit und wird selten verwendet, da ihr Verwendungsszenario ein großer Young-Bereich und ein kleiner Old-Bereich sein sollte. In diesem Fall wird der Old-Bereich mithilfe von SerialOld GC erfasst. Die Ausfallzeit beträgt kaum akzeptabel.
;Die Kombination von Parallelyoung generationGC und SerialOldGC (-XX:+UseParallelGC und -XX:-UseParallelOldGC werden zusammen aktiviert) wird aufgegeben. Verwenden Sie jetzt -XX:+UseParallelGC -XX:-UseParallelOldGC oder verwenden Sie -XX:-UseParallelOldGC. Folgendes Es erscheint eine Warnung.

CMS löschen
Seit der Einführung von G1 wurde CMS in JDK9 als veraltet markiert
CMS-Nachteile
- Es kommt zu einer Speicherfragmentierung, was dazu führt, dass nach dem gleichzeitigen Löschen nicht mehr genügend Speicherplatz für Benutzer-Threads zur Verfügung steht (wird durch den Markierungslöschalgorithmus erzeugt und muss vom Endbearbeitungsalgorithmus gelöst werden).
- Da der CMS-Kollektor den Schwerpunkt auf Parallelität legt, reagiert er sehr empfindlich auf CPU-Ressourcen, was zu einem verringerten Durchsatz führt
- Der CMS-Kollektor kann schwebenden Müll nicht verarbeiten (Benutzer-Thread und Garbage-Collection-Thread werden gleichzeitig ausgeführt, und der Benutzer-Thread generiert beim Recycling neuen Müll).
Wenn CMS nicht mehr funktioniert, wird Serial Old GC als Alternative verwendet und stellt die Garbage-Collection-Methode mit der schlechtesten Leistung in der JVM dar. Sie kann einige Sekunden oder sogar zehn Sekunden anhalten.
Der CMS-Garbage Collector wurde entfernt. Wenn Sie weiterhin -XX:+UseConcMarkSweepGC in JDK14 verwenden, wird kein Fehler gemeldet, sondern nur eine Warnung ausgegeben.
warning: Ignoring option UseConcMarkSweepGC; support was removed in 14.0
Andere Müllsammler
Der G1 Collector HotSpot wird seit mehreren Jahren standardmäßig verwendet. Wir haben auch zwei neue GCs gesehen: ZGC in JAVA11 und Shenandoah in openJDK12. Die Hauptmerkmale der beiden letzteren sind: geringe Pausenzeit
Shenandoah wird nicht offiziell von Oracle veröffentlicht, sondern von OpenJDK in JAVA12
| Name des Sammlers | Öffnungszeiten | Gesamtpausenzeit | maximale Pausenzeit | durchschnittliche Pausenzeit |
|---|---|---|---|---|
| Shenandoah | 387,602s | 320 ms | 89,79 ms | 53,01 ms |
| G1 | 312,052s | 11,7 Sekunden | 1,24p | 450,12 ms |
| CMS | 286,264 Sekunden | 12,78 Sekunden | 4,39s | 852,26 ms |
| ParallelScavenge | 260,092s | 6,59s | 3,04 Sekunden | 823,75 ms |
ZGC auf macOS und Windows
Vor JAVA14 unterstützte ZGC nur Linux
Aufgrund einiger Entwicklungs-, Bereitstellungs- und Testanforderungen wird ZGC in JDK14 auf macOS und Windows unterstützt, sodass viele Desktop-Anwendungen von ZGC profitieren können. Es handelt sich noch um eine experimentelle Version, die unter macOS und Windows verwendet werden kann.
Die Ziele von ZGC und Shenandoah sind sehr ähnlich. Sie sollen eine niedrige Latenz erreichen, die die Pausenzeit des Garbage Collectors auf weniger als 10 Millisekunden für jede Heap-Größe (TB-Ebene) begrenzen und gleichzeitig den Durchsatz minimieren kann.
Der ZGC-Kollektor ist ein Garbage Collector, der auf dem Speicherlayout der Region basiert. Derzeit gibt es keine Generierung. Er verwendet Technologien wie Lesebarrieren, gefärbte Zeiger und Speichermehrfachzuordnung, um gleichzeitige Markierungskomprimierungsalgorithmen zu implementieren. Es ist Müll Kollektor mit geringer Latenz als Hauptziel. Kollektor. Jetzt möchte ich ZGC unter macOS und Windows verwenden. Die Methode ist wie folgt
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
Einige Testdaten über ZGC
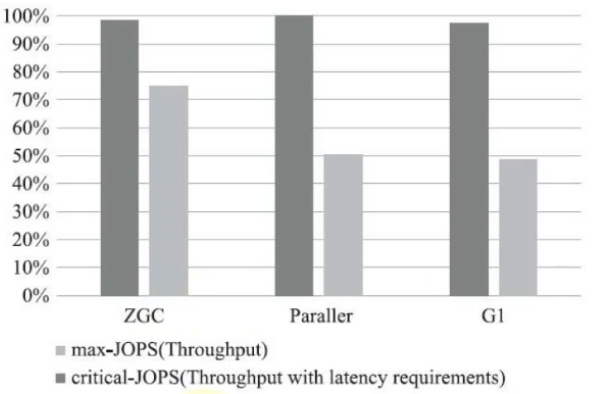
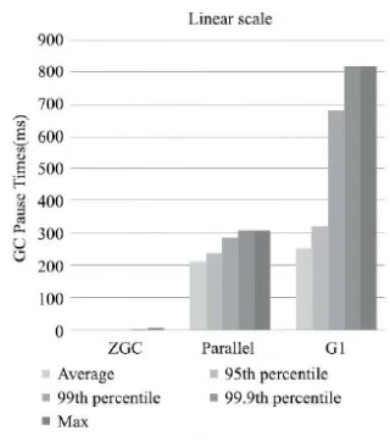
ZGC befindet sich noch im experimentellen Zustand, aber seine Leistung ist sehr beeindruckend und wird in Zukunft der bevorzugte Garbage Collector für serverseitige Anwendungen mit großem Speicher und geringer Latenz sein.