
Sur la base des questions courantes d'Apache Doris sur le processus de lecture et d'écriture, le mécanisme de cohérence des copies, le mécanisme de stockage, le mécanisme de haute disponibilité, etc., il est trié et répondu sous forme de questions et réponses. Avant de commencer, expliquons d’abord les termes liés à cet article :
-
FE : Frontend, le nœud front-end de Doris. Principalement responsable de la réception et du renvoi des demandes des clients, des métadonnées, de la gestion des clusters, de la génération du plan de requête, etc.
-
BE : Backend, le nœud backend de Doris. Principalement responsable du stockage et de la gestion des données, de l'exécution du plan de requête, etc.
-
BDBJE : Oracle Berkeley DB Java Edition. Dans Doris, BDBJE est utilisé pour compléter la persistance des journaux d'opérations de métadonnées, la haute disponibilité FE et d'autres fonctions.
-
Tablette : La tablette est l'unité de stockage physique réelle d'une table. Une table est stockée en unités de tablettes dans la couche de stockage distribuée formée par BE selon des partitions et des buckets. Chaque tablette comprend des méta informations et plusieurs RowSets consécutifs.
-
RowSet : RowSet est une collection de données d'une modification de données dans la tablette. Les modifications de données incluent l'importation, la suppression, la mise à jour de données, etc. Enregistrements RowSet par informations de version. Chaque modification générera une version.
-
Version : se compose de deux attributs : Début et Fin, et conserve les informations d'enregistrement des modifications de données. Généralement utilisé pour représenter la plage de versions de RowSet. Après une nouvelle importation, un RowSet avec un début et une fin égaux est généré. Après le compactage, une version de RowSet à distance est générée.
-
Segment : représente des segments de données dans RowSet. Plusieurs segments constituent un RowSet.
-
Compactage : Le processus de fusion de versions consécutives de RowSet est appelé Compactage, et les données seront compressées pendant le processus de fusion.
-
Colonne clé, colonne Valeur : Dans Doris, les données sont décrites logiquement sous la forme d'un tableau. Un tableau comprend des lignes (Ligne) et des colonnes (Colonne). La ligne est une ligne de données utilisateur et la colonne est utilisée pour décrire différents champs dans une ligne de données. La colonne peut être divisée en deux catégories : Clé et Valeur. D'un point de vue commercial, Clé et Valeur peuvent correspondre respectivement aux colonnes de dimension et aux colonnes d'indicateur. La colonne Clé de Doris est la colonne spécifiée dans l'instruction de création de table. La colonne qui suit le mot-clé clé unique ou clé d'agrégation ou clé en double dans l'instruction de création de table est la colonne Clé. En plus de la colonne Clé, le reste est la valeur. colonne.
-
Modèle de données : le modèle de données de Doris est principalement divisé en trois catégories : Agrégé, Unique et Dupliqué.
-
Table de base : Dans Doris, nous appelons la table créée par l'utilisateur via l'instruction de création de table la table de base. La table de base stocke les données de base stockées de la manière spécifiée par l'instruction de création de table de l'utilisateur.
-
Table ROLLUP : En plus de la table de base, les utilisateurs peuvent créer n'importe quel nombre de tables ROLLUP. Ces données ROLLUP sont générées sur la base de la table de base et sont physiquement stockées indépendamment. La fonction de base de la table ROLLUP est d'obtenir des données agrégées plus grossières basées sur la table de base, similaire à une vue matérialisée.
Q1 : Quelle est la différence entre le partitionnement et le bucketing Doris ?
Doris prend en charge deux niveaux de partitionnement des données :
-
La première couche est Partition, qui prend en charge les méthodes de division Range et List (similaire au concept de table de partition de MySQL). Plusieurs partitions forment une table et la partition peut être considérée comme la plus petite unité logique de gestion. Les données ne peuvent être importées et supprimées que pour une seule partition.
-
La deuxième couche est Bucket (la tablette est également appelée bucketing), qui prend en charge les méthodes de division Hash et Random. Chaque tablette contient plusieurs lignes de données, et les données entre les tablettes n'ont aucune intersection et sont physiquement stockées indépendamment. La tablette est la plus petite unité de stockage physique pour des opérations telles que le déplacement et la copie de données.
Vous pouvez également utiliser un seul niveau de partitionnement. Si vous n'écrivez pas d'instruction de partitionnement lors de la création d'une table, Doris générera une partition par défaut, transparente pour l'utilisateur.
L'indication est la suivante :
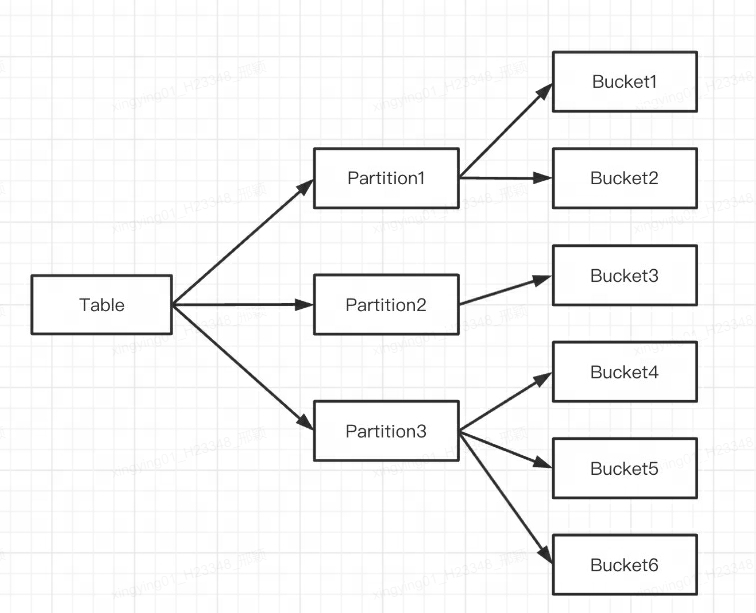
Plusieurs tablettes appartiennent logiquement à différentes partitions (partition). Une tablette n'appartient qu'à une seule partition et une partition contient plusieurs tablettes. La Tablette étant physiquement stockée de manière indépendante, on peut considérer que la Partition est également physiquement indépendante.
Logiquement parlant, la plus grande différence entre le partitionnement et le bucketing est que le bucketing divise la base de données de manière aléatoire, tandis que le partitionnement divise la base de données de manière non aléatoire.
Comment garantir plusieurs copies de données ?
Afin d'améliorer la fiabilité du stockage des données et les performances de calcul, Doris réalise plusieurs copies de chaque table à des fins de stockage. Chaque copie de données est appelée une copie. Doris utilise Tablet comme unité de base pour stocker des copies de données. Par défaut, un fragment a 3 copies. Lors de la création d'un tableau, vous pouvez PROPERTIESdéfinir le nombre de copies dans :
PROPERTIES
(
"replication_num" = "3"
);
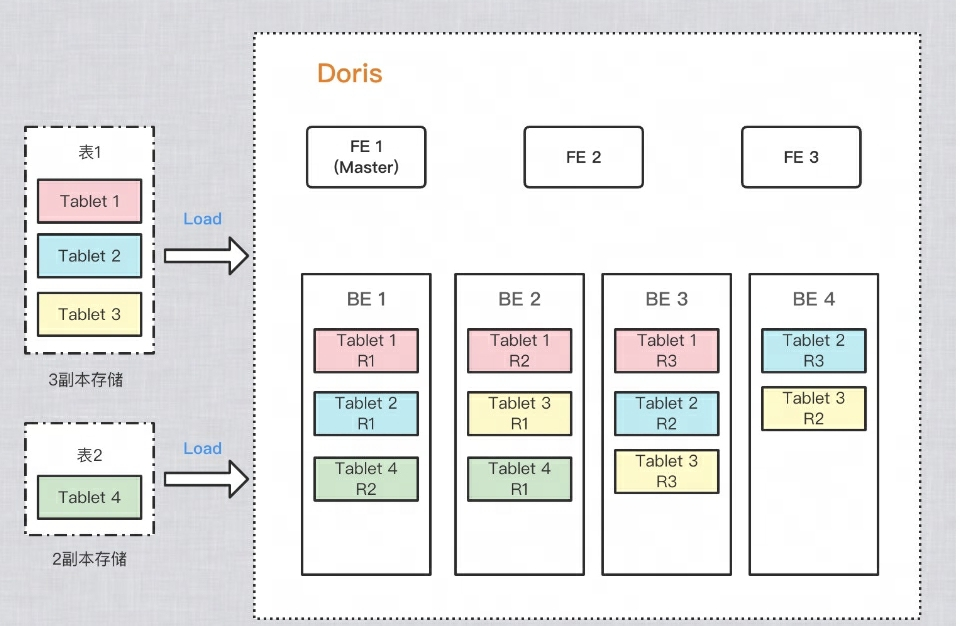
À titre d'exemple dans la figure ci-dessous, deux tables sont importées respectivement dans Doris. La table 1 est stockée en 3 copies après l'importation et la table 2 est stockée en 2 copies après l'importation. La répartition des données est la suivante :
Q2 : Pourquoi avez-vous besoin d’un bucketing ?
Afin de diviser en compartiments et d'éviter le biais des données, ainsi que de disperser les E/S de lecture et d'améliorer les performances des requêtes, différentes copies de la tablette peuvent être dispersées sur différentes machines, afin que les performances d'E/S des différentes machines puissent être pleinement utilisées lors des requêtes.
Q3 : Quelle est la structure de stockage et le format des fichiers physiques ?
Chaque import de Doris peut être considéré comme une transaction et un RowSet sera généré. Et RowSet comprend plusieurs segments, c'est-à-dire Tablet-->Rowset-->Segment. Alors, comment BE stocke-t-il ces fichiers ?
La structure de rangement de Doris
Doris storage_root_pathconfigure le chemin de stockage via , et les fichiers de segments sont stockés dans tablet_idle répertoire et gérés par SchemaHash. Il peut y avoir plusieurs fichiers de segments, qui sont généralement divisés en fonction de leur taille. La valeur par défaut est de 256 Mo. Les règles de dénomination du répertoire de stockage et des fichiers de segments sont :
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
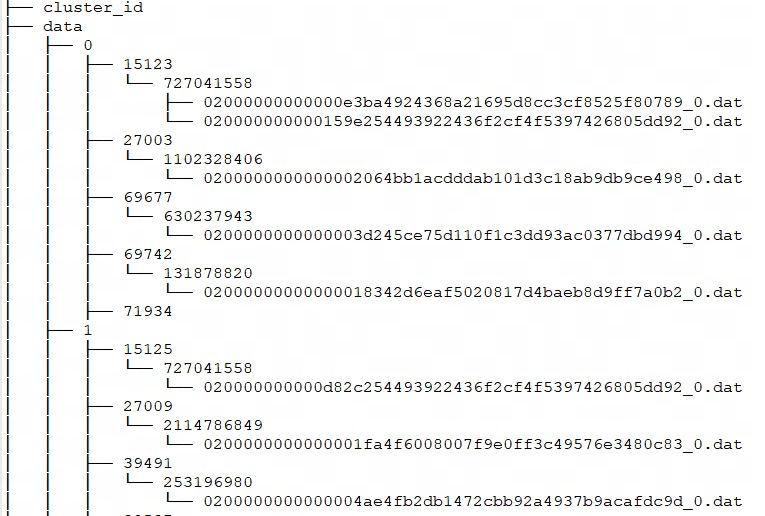
Entrez dans storage_root_pathle répertoire et vous pouvez voir la structure de stockage suivante :
-
${shard}: C'est 0, 1 dans la figure ci-dessus. Il est créé automatiquement par BE dans le répertoire de stockage et est aléatoire. Cela augmentera avec l’augmentation des données. -
${tablet_id}: C'est-à-dire 15123, 27003, etc. dans la figure ci-dessus, qui est l'ID du bucket mentionné ci-dessus. -
${schema_hash}: C'est-à-dire 727041558, 1102328406, etc. dans l'image ci-dessus. Étant donné que la structure d'une table peut être modifiée, une table est générée pour chaque version du schémaSchemaHashafin d'identifier les données sous cette version. -
${segment_id}.dat: Le premier estrowset_id, c'est-à-dire 02000000000000e3ba4924368a21695d8cc3cf8525f80789 dans la figure ci-dessus ;${segment_id}c'est le RowSet actuelsegment_id, commençant à 0 et augmentant.
Format de stockage des fichiers de segments
Le format de fichier global de Segment est divisé en trois parties : zone de données, zone d'index et pied de page, comme le montre la figure suivante :

-
Région de données : utilisée pour stocker les informations de données de chaque colonne. Les données ici sont chargées dans des pages à la demande. Les pages contiennent les données de la colonne et chaque page fait 64 Ko.
-
Région d'index : Doris stocke les données d'index de chaque colonne dans la région d'index. Les données ici seront chargées en fonction de la granularité de la colonne, elles sont donc stockées séparément des informations sur les données de la colonne.
-
Informations de pied de page : contient des informations sur les métadonnées du fichier, la somme de contrôle du contenu, etc.
Q4 : Quelles sont les limitations DML des différents modèles de table de Doris ?
-
Mise à jour : l'instruction Update ne prend actuellement en charge que le modèle UNIQUE KEY et prend uniquement en charge la mise à jour de la colonne Value.
-
Supprimer : 1) Si le modèle de table utilise une classe d'agrégation (AGGREGATE, UNIQUE), l'opération Supprimer ne peut spécifier que les conditions sur la colonne Clé ; 2) Cette opération supprimera également les données de l'Index Rollup liées à cet Index de Base.
-
Insérer : tous les modèles de données peuvent être insérés.
Comment implémenter Insert ? Comment interroger les données après leur insertion ?
-
Modèle AGGREGATE : dans la phase d'insertion, les données incrémentielles sont écrites dans le RowSet dans la méthode Append, et dans la phase de requête, la méthode Merge on Read est utilisée pour la fusion. C'est-à-dire que les données sont d'abord écrites dans un nouveau RowSet lors de l'importation et que la déduplication ne sera pas effectuée après l'écriture. Le tri simultané multidirectionnel ne sera effectué que lorsqu'une requête est lancée. Lors d'un tri par fusion multidirectionnel, dupliquez les données seront triées. Les clés sont disposées ensemble et agrégées. La clé de version supérieure écrasera la clé de version inférieure et, finalement, seul l'enregistrement avec la version la plus élevée sera renvoyé à l'utilisateur.
-
Modèle DUPLICATE : Ce modèle est écrit de la même manière que celui ci-dessus, et il n'y aura aucune opération d'agrégation dans la phase de lecture.
-
Modèle UNIQUE : Avant la version 1.2, ce modèle était essentiellement un cas particulier du modèle agrégé, avec un comportement cohérent avec le modèle AGGREGATE. Étant donné que le modèle d'agrégation est implémenté par Merge on Read , les performances de certaines requêtes d'agrégation sont médiocres. Doris a introduit une nouvelle implémentation du modèle Unique après la version 1.2, Merge on Write , qui marque et supprime les données écrasées et mises à jour lors de l'écriture. Lors de la requête, toutes les données marquées et supprimées sont supprimées. Les données seront filtrées au niveau du fichier, et les données lues seront les données les plus récentes, éliminant le processus d'agrégation des données lors de la fusion au moment de la lecture, et peuvent prendre en charge la suppression de plusieurs prédicats dans de nombreux cas.
En termes simples, le flux de traitement de Merge on Write est :
-
Pour chaque clé, recherchez sa position dans les données de base (RowSetid + Segmentid + numéro de ligne) [L'arborescence des intervalles de clé primaire au niveau du segment est conservée en mémoire pour accélérer les requêtes]
-
Si la clé existe, marquez la ligne de données à supprimer. Les informations marquées pour suppression sont enregistrées dans le bitmap de suppression, où chaque segment possède un bitmap de suppression correspondant.
-
Écrivez les données mises à jour dans le nouveau RowSet, terminez la transaction et rendez les nouvelles données visibles, c'est-à-dire qu'elles peuvent être interrogées par l'utilisateur.
-
Lors de l'interrogation, lisez le bitmap de suppression, filtrez les lignes marquées pour suppression et renvoyez uniquement des données valides [Pour tous les segments touchés, interrogez en fonction de la version de haut en bas]
Ce qui suit présente la mise en œuvre du processus d'écriture et du processus de lecture.
Processus d'écriture : lors de l'écriture des données, l'index de clé primaire de chaque segment sera créé en premier, puis le bitmap de suppression sera mis à jour.
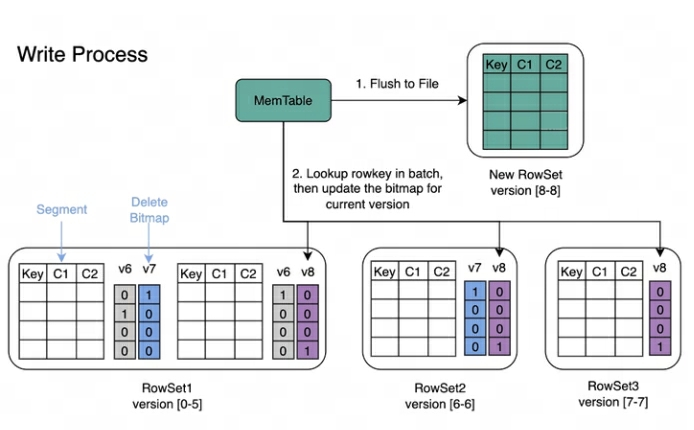
Processus de lecture : Le processus de lecture de Bitmap est illustré dans la figure ci-dessous. À partir de l'image, nous pouvons savoir :
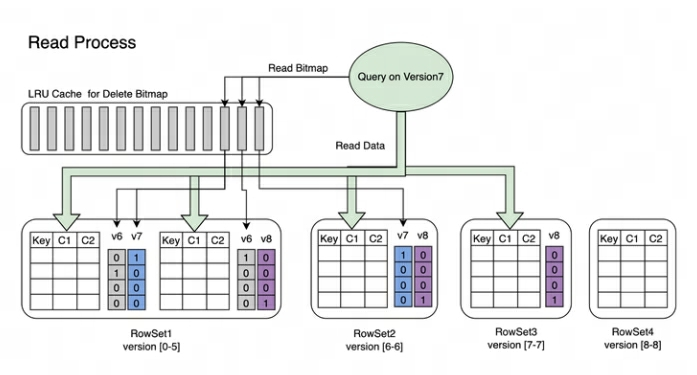
-
Une requête qui demande la version 7 ne verra que les données correspondant à la version 7.
-
Lors de la lecture des données de RowSet5, les Bitmaps générés par les modifications V6 et V7 seront fusionnés pour obtenir le DeleteBitmap complet correspondant à la version 7, qui est utilisé pour filtrer les données.
-
Dans l'exemple ci-dessus, l'import de la version 8 couvre une donnée du Segment2 de RowSet1, mais la requête demandant la version 7 peut toujours lire les données.
Comment la mise à jour est-elle implémentée ?
Le processus de mise à jour du modèle UNIQUE est essentiellement Select+Insert.
-
Update utilise la propre logique de filtrage Where du moteur de requête pour filtrer les lignes qui doivent être mises à jour de la table à mettre à jour et, sur cette base, conserver le bitmap de suppression et générer les données nouvellement insérées.
-
Exécutez ensuite la logique d'insertion.Le processus spécifique est similaire à la logique d'écriture de modèle UNIQUE mentionnée ci-dessus.
Q5 : Comment la suppression de Doris est-elle implémentée ? Un RowSet sera-t-il également généré ? Comment supprimer les données correspondantes ?
-
La suppression de Doris générera également un RowSet. En mode DELETE, les données ne sont pas réellement supprimées, mais les conditions de suppression des données sont enregistrées. Stocké dans les méta-informations. Lors de l'exécution de Base Compaction, les conditions de suppression seront fusionnées dans la version de base.
-
Doris prend également en charge LOAD_DELETE sous le modèle UNIQUE KEY, qui permet la suppression de données par importation par lots des clés à supprimer, et peut prendre en charge des capacités de suppression de données à grande échelle. L'idée générale est d'ajouter un identifiant d'état de suppression à l'enregistrement de données, et la clé supprimée sera compressée pendant le processus de compactage. Le compactage est principalement responsable de la fusion de plusieurs versions de RowSet.
Q6 : Quels indices Doris possède-t-elle ?
Actuellement, Doris prend principalement en charge deux types d'index :
-
Index intelligents intégrés, y compris les index de préfixe et les index ZoneMap.
-
Les index secondaires créés manuellement par les utilisateurs incluent les index inversés, les index Bloomfilter, les index Ngram Bloomfilter et les index Bitmap.
L'index ZoneMap est une information d'index automatiquement conservée pour chaque colonne au format de stockage de colonne, y compris Min/Max, le nombre de valeurs Null, etc. Cette indexation est transparente pour l'utilisateur.
Quel est le niveau de l'indice ?
-
Désormais, tous les index de Doris sont locaux au niveau BE, tels que l'index inversé, l'index Bloomfilter, l'index Ngram Bloomfilter et l'index Bitmap, l'index préfixe et l'index ZoneMap, etc.
-
Doris n'a pas d'indice global. Au sens large, les partitions + clés de compartiment peuvent également être considérées comme globales, mais elles sont relativement grossières.
Quel est le format de stockage de l'index ?
Dans Doris, les données d'index de chaque colonne sont stockées uniformément dans la région d'index du fichier de segment. Les données ici sont chargées en fonction de la granularité de la colonne, elles sont donc stockées séparément des informations sur les données de la colonne. Ici, nous prenons l’index de préfixe Short Key Index comme exemple.
L'index de préfixe Short Key Index est une méthode d'indexation basée sur le tri par clé (AGGREGATE KEY, UNIQ KEY et DUPLICATE KEY) pour interroger rapidement des données en fonction d'une colonne de préfixe donnée. L'index Short Key Index adopte également ici une structure d'index clairsemée.Pendant le processus d'écriture des données, un élément d'index sera généré tous les certains nombres de lignes. Ce nombre de lignes correspond à la granularité de l'index, qui est par défaut de 1 024 lignes et est configurable. Le processus est illustré ci-dessous :
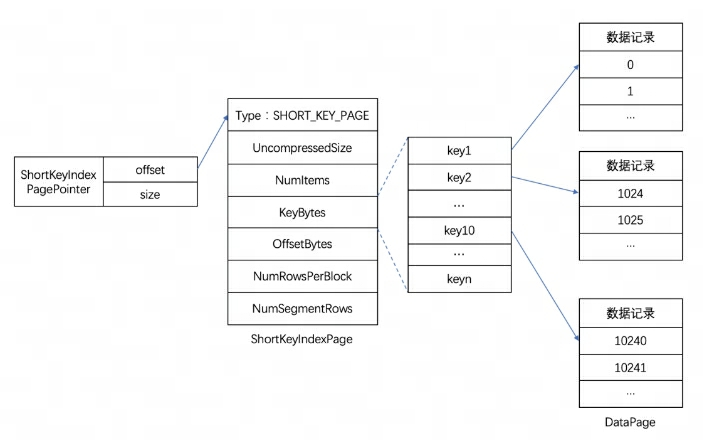
Parmi eux, KeyBytes stocke les données de l'élément d'index et OffsetBytes stocke le décalage de l'élément d'index dans KeyBytes.
Short Key Index utilise les 36 premiers octets comme index de préfixe de cette ligne de données. Lorsqu'un type VARCHAR est rencontré, l'index du préfixe est directement tronqué. Short Key Index utilise les 36 premiers octets comme index de préfixe de cette ligne de données. Lorsqu'un type VARCHAR est rencontré, l'index du préfixe est directement tronqué.
Comment le processus de lecture atteint-il l'index ?
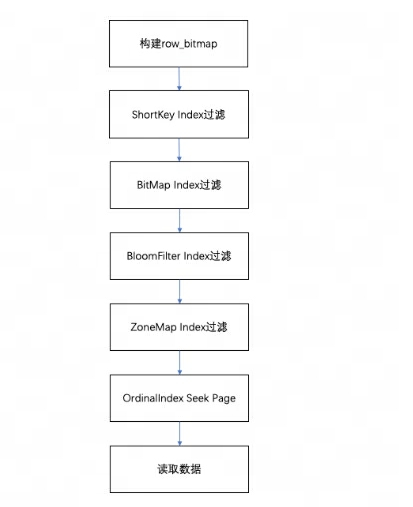
Lors de l'interrogation des données dans un segment, selon les conditions de requête exécutées, les données seront d'abord filtrées en fonction de l'index du champ. Lisez ensuite les données, le processus global de requête est le suivant :
-
Tout d’abord, un sera construit en fonction du nombre de lignes du segment
row_bitmappour indiquer quelles données doivent être lues. Toutes les données doivent être lues sans utiliser d'index. -
Lorsque la clé est utilisée dans les conditions de requête conformément à la règle d'index de préfixe, l'index ShortKey sera filtré en premier et la plage de numéros de ligne ordinales pouvant correspondre dans l'index ShortKey sera combinée en
row_bitmap. -
Lorsqu'il y a un index d'index BitMap dans le champ de colonne dans la condition de requête, le numéro de ligne ordinale qui remplit les conditions sera directement découvert en fonction de l'index BitMap et recoupé avec le row_bitmap pour le filtrage. Le filtrage ici est précis. Si la condition de requête est supprimée ultérieurement, ce champ ne sera pas filtré pour les index suivants.
-
Lorsque le champ de colonne dans la condition de requête a un index BloomFilter et que la condition est équivalente (eq, in, is), il sera filtré en fonction de l'index BloomFilter. Ici, tous les index seront parcourus, le BloomFilter de chaque page sera être filtré et les conditions de requête peuvent être trouvées.Toutes les pages.
row_bitmapFiltrez l'intersection de la plage de numéros de lignes ordinales dans les informations d'index et . -
Lorsqu'il y a un index ZoneMap dans le champ de colonne dans la condition de requête, il sera filtré en fonction de l'index ZoneMap. Ici, tous les index seront également parcourus pour trouver toutes les pages que la condition de requête peut croiser avec le ZoneMap.
row_bitmapFiltrez l'intersection de la plage de numéros de lignes ordinales dans les informations d'index et . -
Après avoir généré
row_bitmap, recherchez la page de données spécifique via l'OrdinalIndex de chaque colonne par lots. -
Lisez les données de la page de données de colonne de chaque colonne par lots. Lors de la lecture, pour les pages avec des valeurs Null, déterminez si la ligne actuelle est Null en fonction du bitmap de valeur Null. Si elle est Null, remplissez-la directement.
Q7 : Comment Doris effectue-t-elle le compactage ?
Doris utilise Compaction pour agréger progressivement les fichiers RowSet afin d'améliorer les performances. Les informations de version de RowSet sont conçues avec deux champs, Début et Fin, pour représenter la plage de versions du Rowset fusionné. Les versions Start et End d’un RowSet cumulatif non fusionné sont égales. Pendant le compactage, les RowSets adjacents seront fusionnés pour générer un nouveau RowSet, et les informations de début et de fin de version seront également fusionnées pour former une version plus grande. D'un autre côté, le processus de compactage réduit considérablement le nombre de fichiers RowSet et améliore l'efficacité des requêtes.
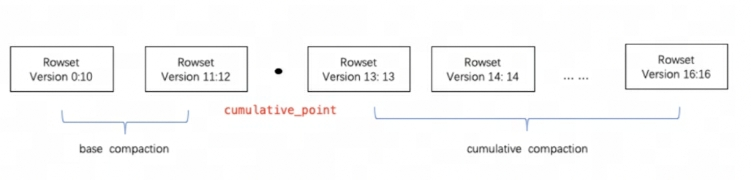
Comme le montre la figure ci-dessus, les tâches de compactage sont divisées en deux types : le compactage de base et le compactage cumulatif. cumulative_pointC’est la clé pour séparer les deux stratégies.
Cela peut être compris ainsi :
-
cumulative_pointSur la droite se trouve un RowSet incrémentiel qui n'a jamais été fusionné, et les versions de début et de fin de chaque RowSet sont égales ; -
cumulative_pointSur la gauche se trouve le RowSet fusionné, la version Start et la version End sont différentes. -
Les processus de tâches de compactage de base et de compactage cumulatif sont fondamentalement les mêmes. La seule différence réside dans la logique de sélection de l'InputRowSet à fusionner.
Sur quelle clé le compactage est-il basé ?
-
Dans un segment, les données sont toujours stockées dans l'ordre de tri de la clé (AGGREGATE KEY, UNIQ KEY et DUPLICATE KEY). Autrement dit, le tri de la clé détermine la structure physique du stockage des données et détermine l'ordre de la structure physique des données de colonne.
-
Le processus de compactage Doris est donc basé sur AGGREGATE KEY, UNIQ KEY et DUPLICATE KEY.
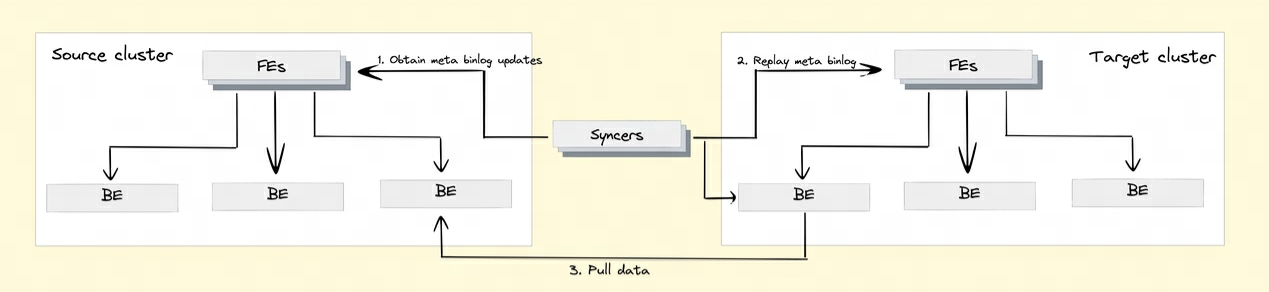
Q8 : Comment Doris implémente-t-elle la réplication des données entre clusters ?
Afin de réaliser la fonction de réplication des données entre clusters, Doris a introduit le mécanisme Binlog. Les enregistrements et les opérations de modification des données sont automatiquement enregistrés via le mécanisme Binlog pour assurer la traçabilité des données. La relecture et la récupération des données peuvent également être réalisées sur la base du mécanisme de lecture Binlog.
Comment Binlog est-il enregistré ?
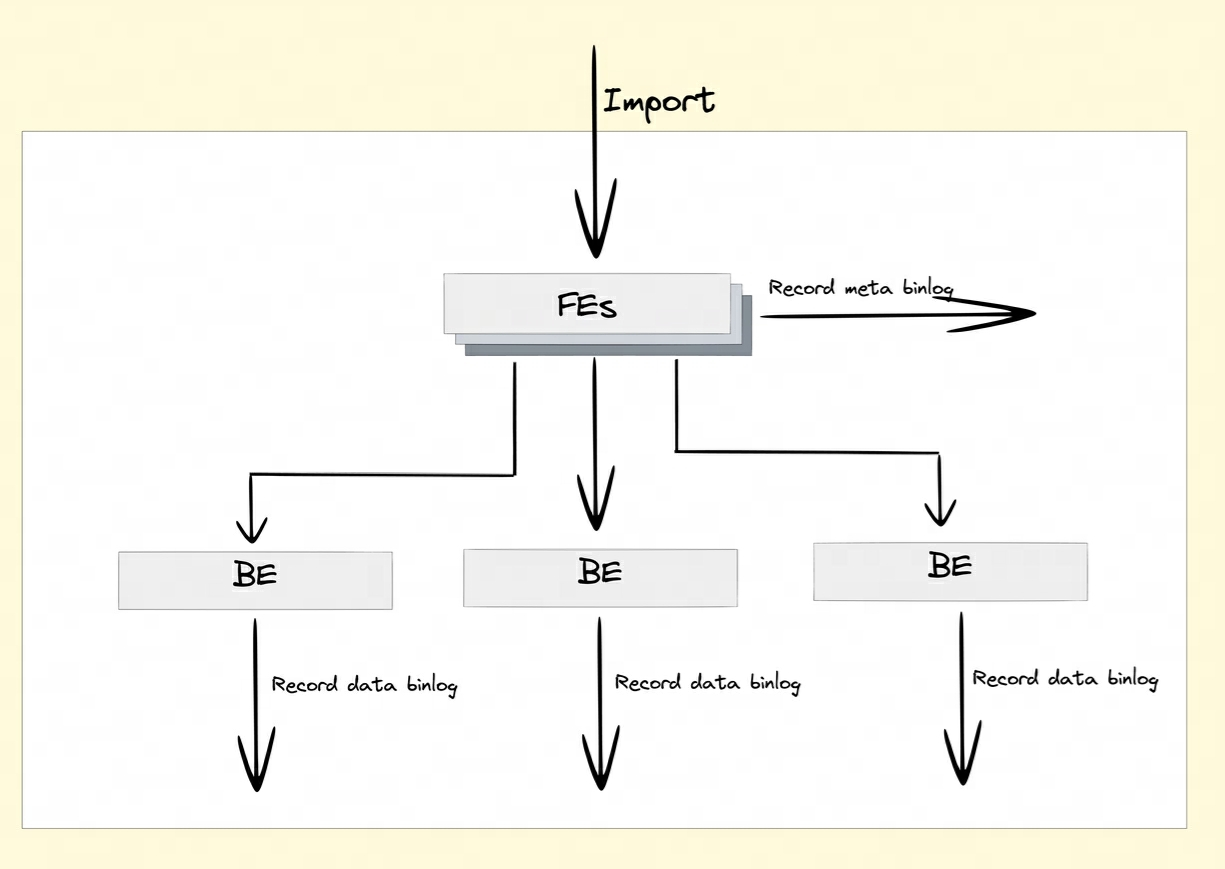
Après avoir activé l'attribut Binlog, FE et BE conserveront les enregistrements de modification des opérations DDL/DML dans Meta Binlog et Data Binlog.
-
Meta Binlog : Doris a amélioré la mise en œuvre d'EditLog pour garantir l'ordre du journal. En construisant une séquence croissante de LogID, chaque opération est enregistrée avec précision et conservée dans l'ordre. Ce mécanisme de persistance ordonnée permet de garantir la cohérence des données.
-
Binlog de données : lorsque FE lance une transaction de publication, BE effectuera l'opération de publication correspondante. BE écrira les informations de métadonnées de cette transaction impliquant RowSet dans le KV préfixé
rowset_metapar et les conservera dans le méta-stockage. Après la soumission, les fichiers de segments importés seront lié au dossier Binlog.
Génération de binlog :
Lecture des données BInlog :
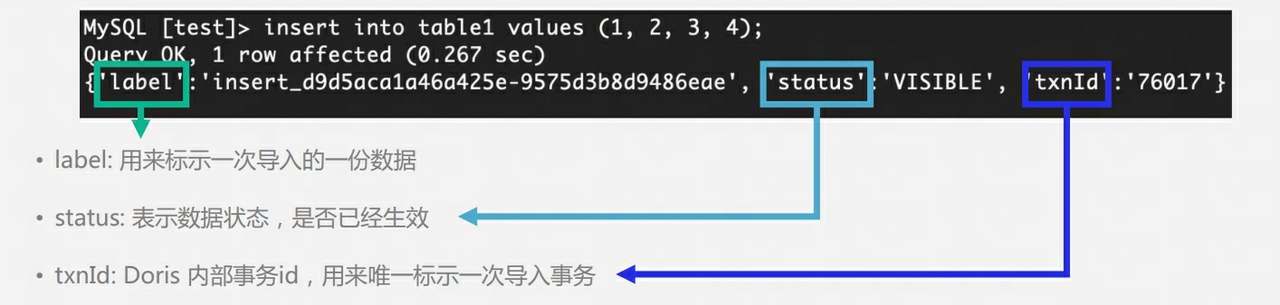
Q9 : La table de Doris comporte plusieurs copies. Comment assurer plusieurs copies lors de la phase d'écriture ? Y a-t-il un concept maître-esclave ? Est-il nécessaire de renvoyer le succès d'écriture après la majorité ?
-
Les 3 exemplaires de Doris BE n'ont pas la notion de maître-esclave et utilisent l'algorithme Quorum pour assurer une écriture multi-exemplaires.
-
Au cours du processus d'écriture, FE déterminera si le nombre de copies de chaque tablette qui écrit avec succès des données dépasse la moitié du nombre total de copies de la tablette. Si le nombre de copies de chaque tablette qui écrit avec succès des données dépasse la moitié du nombre total de copies de la tablette. copies (plus de succès), alors la transaction de validation est réussie et le statut de la transaction est défini sur COMMITTED ; le statut COMMITTED indique que les données ont été écrites avec succès, mais les données ne sont pas encore visibles et la tâche de publication de version doit être poursuivie. Après cela, la transaction ne peut plus être annulée.
-
FE aura un thread distinct pour exécuter la version de publication pour la transaction de validation réussie. Lorsque FE exécute la version de publication, il enverra des demandes de publication de version à tous les nœuds Executor BE liés à la transaction via Thrift RPC. La tâche de publication de version est exécutée de manière asynchrone sur chaque Nœud Executor BE. Importez les données dans le RowSet généré et faites-en une version de données visible.
Pourquoi existe-t-il un mécanisme de publication : Semblable à MVCC, s'il n'y a pas de mécanisme de publication, les utilisateurs peuvent lire les données qui n'ont pas encore été soumises.
Que se passera-t-il si la table comporte 3 copies et qu'une seule copie est écrite avec succès : A ce moment, la transaction sera ABORTÉE
Que se passera-t-il si la table comporte 3 copies et que seulement 2 copies sont écrites avec succès : A ce moment, la transaction sera COMMITTED, et Doris FE effectuera régulièrement un suivi et des inspections de la tablette. Si une anomalie dans la copie de la tablette est trouvée, un Clone une tâche sera générée pour cloner une nouvelle copie.
Pourquoi l'utilisateur exécute-t-il la requête immédiatement après avoir exécuté Insert Into et le résultat peut-il être vide ? La raison est que la transaction n'a pas encore été publiée.
Q10 : Comment le FE de Doris assure-t-il la haute disponibilité ?
Au niveau des métadonnées, Doris utilise le protocole Paxos et le mécanisme Memory + Checkpoint + Journal pour garantir des performances élevées et une grande fiabilité des métadonnées.
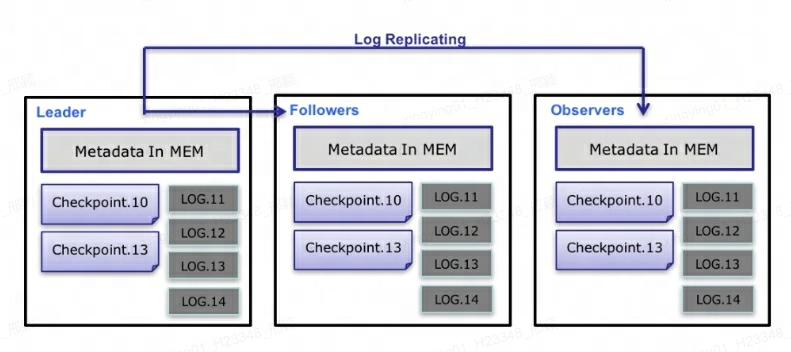
Le processus spécifique du flux de données de métadonnées est le suivant :
-
Seul Leader FE peut écrire des métadonnées. Une fois que l'opération d'écriture a modifié la mémoire du Leader, celle-ci sera sérialisée dans un journal et
key-valueécrite dans BDBJE sous la forme de . La clé est un entier continu etlog idla valeur est le journal des opérations sérialisé. -
Une fois le journal écrit dans BDBJE, BDBJE copiera le journal sur d'autres nœuds FE non leaders conformément à la politique (majorité d'écriture/toutes les écritures). Le nœud FE non-Leader modifie sa propre image mémoire de métadonnées en relisant les journaux pour terminer la synchronisation des métadonnées avec le nœud Leader.
-
Le nombre de journaux sur le nœud Leader atteint le seuil (100 000 par défaut) et respecte le cycle d'exécution du thread Checkpoint (60 secondes par défaut). Checkpoint lira le fichier image existant et les journaux suivants, et rejouera une nouvelle copie d'image de métadonnées dans la mémoire. La copie est ensuite écrite sur le disque pour former une nouvelle image. La raison pour laquelle il faut régénérer une copie de l'image au lieu d'écrire l'image existante en tant qu'image est principalement due au fait que l'écriture dans l'image et l'ajout d'un verrou en lecture bloqueront l'opération d'écriture. Par conséquent, chaque point de contrôle occupera le double de l’espace mémoire.
-
Une fois le fichier image généré, le nœud Leader informera les autres nœuds non-Leader que la nouvelle image a été générée. Non-Leader extrait activement le dernier fichier image via HTTP pour remplacer l'ancien fichier local.
-
Pour les journaux dans BDBJE, les anciens journaux seront supprimés régulièrement une fois l'image terminée.
expliquer :
-
Chaque mise à jour des métadonnées est d'abord écrite dans le fichier journal sur le disque, puis écrite dans la mémoire et enfin périodiquement vérifiée sur le disque local.
-
Cela équivaut à une structure de mémoire pure, ce qui signifie que toutes les métadonnées seront mises en cache en mémoire, garantissant ainsi que FE puisse restaurer rapidement les métadonnées après un crash sans perdre de métadonnées.
-
Les trois Leader, Follower et Observer constituent un service fiable. Lorsqu'un seul nœud tombe en panne, trois suffisent en gros, car après tout, le nœud FE ne stocke qu'une seule copie des métadonnées, et sa pression n'est pas grande, donc si quand il y a trop de FE, cela consommera des ressources machine, donc dans la plupart des cas, trois suffisent pour obtenir un service de métadonnées hautement disponible.
-
Les utilisateurs peuvent utiliser MySQL pour se connecter à n'importe quel nœud FE pour accéder en lecture et en écriture aux métadonnées. Si la connexion s'effectue vers un nœud non leader, le nœud transmettra l'opération d'écriture au nœud leader.
A propos de l'auteur
Invisible (Xing Ying) est ingénieur senior en noyau de base de données chez NetEase. Elle est engagée dans le développement du noyau de base de données depuis l'obtention de son diplôme. Elle est actuellement principalement impliquée dans le développement, la maintenance et le support commercial de MySQL et Apache Doris. En tant que contributeur du noyau MySQL, il a signalé plus de 50 bogues et éléments d'optimisation pour MySQL, et plusieurs soumissions ont été intégrées à la version MySQL 8.0. Rejoignant la communauté Apache Doris depuis 2023, Apache Doris Active Contributor, a soumis et fusionné des dizaines de commits pour la communauté.
Un collège a acheté un "appareil de catharsis interactif intelligent" - ce qui est en fait le cas de la Nintendo Wii. Langage de programmation de l'année TIOBE 2023 : C# Kingsoft WPS crashé L'expérience Rust de Linux a été réussie, Firefox peut-il saisir l'opportunité... 10 prédictions sur open source Suite à l'incident de licenciements d'employés par des femmes cadres : le président de l'entreprise a qualifié les employés de "récidivistes" et a mis en doute les "faux curriculum vitae". L'artefact open source LSPosed a annoncé qu'il cesserait de se mettre à jour. L'auteur a déclaré qu'il avait subi un grand nombre d'attaques malveillantes. 2024 "La bataille de l'année" dans le cercle front-end : React ne peut pas creuser de trous. Faut-il le remplir de documents ? Le noyau Linux 6.7 est officiellement publié. L'ère du "post-open source" est arrivée : la licence est invalide et ne peut pas servir le grand public. Des femmes cadres ont été illégalement licenciées. Des employés se sont exprimés et ont été ciblés pour s'être opposés à l'utilisation d'outils EDA piratés pour puces de conception.