Le 17 janvier, la conférence de presse de Scholar Puyuan 2.0 (InternLM2) et la cérémonie de lancement du Scholar Puyuan Large Model Challenge ont eu lieu à Shanghai. Le Laboratoire d'intelligence artificielle de Shanghai et SenseTime, en collaboration avec l'Université chinoise de Hong Kong et l'Université Fudan, ont officiellement lancé la nouvelle génération du grand modèle de langage Puyu 2.0 (InternLM2) .

Adresse open source
- Github:https://github.com/InternLM/InternLM
- HuggingFace :https://huggingface.co/internlm
- ModelScope:https://modelscope.cn/organization/Shanghai_AI_Laboratory
Selon les rapports, InternLM2 a été formé sur un corpus de haute qualité de 2,6 billions de jetons. Suivant les paramètres du chercheur de première génération Puyu (InternLM), InternLM2 comprend deux spécifications de paramètres 7B et 20B ainsi que des versions de base et de dialogue pour répondre aux besoins de différents scénarios d'application complexes. Adhérant au concept de « favoriser l'innovation grâce à un open source de haute qualité », le Shanghai AI Laboratory continue de fournir une licence commerciale gratuite pour InternLM2.
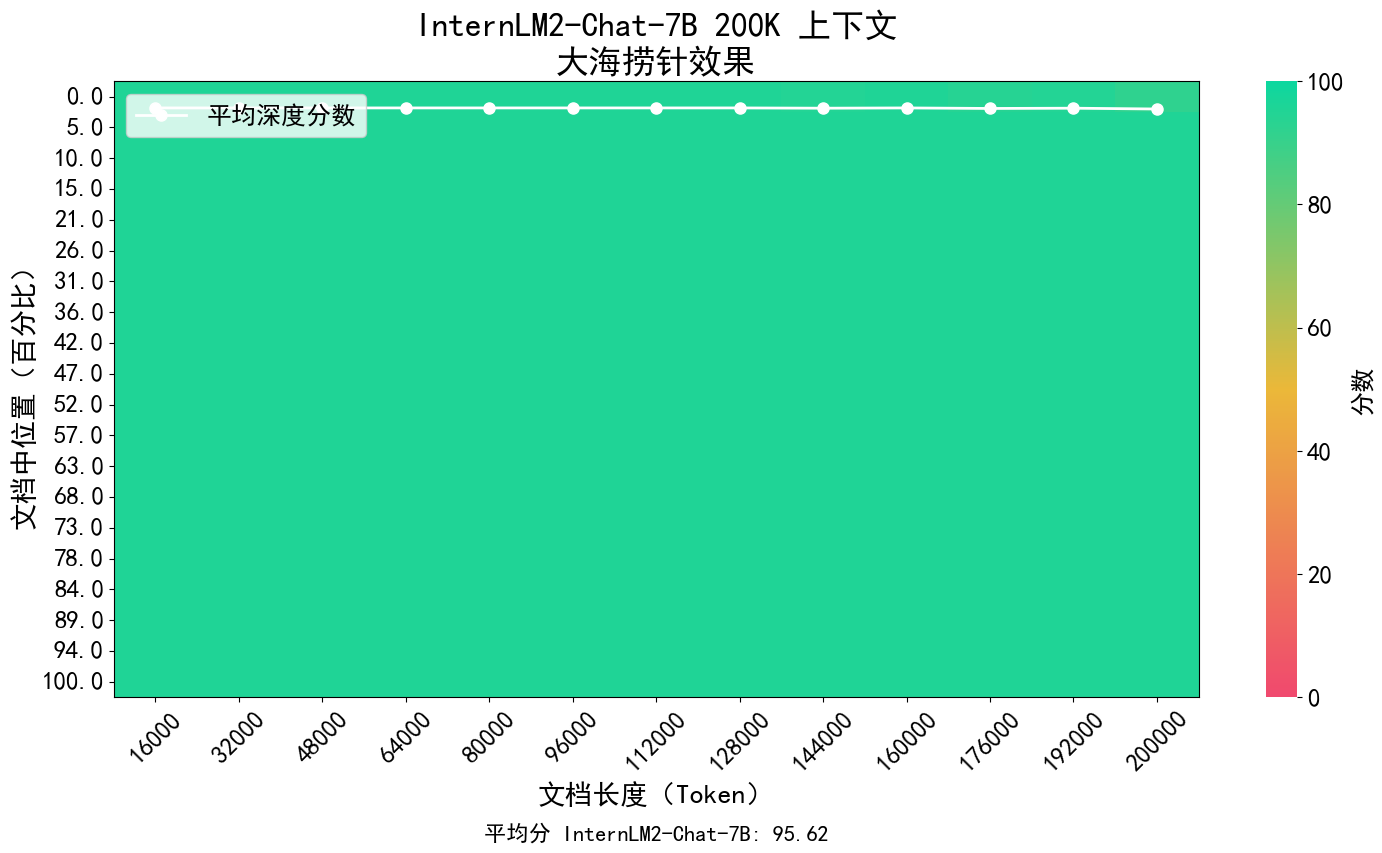
Le concept principal d'InternLM2 est de revenir à l'essence de la modélisation du langage et s'engage à réaliser une amélioration qualitative des capacités de modélisation du langage de la base du modèle en améliorant la qualité du corpus et la densité de l'information, puis à faire de grands progrès en mathématiques, codage, dialogue, création, etc. Des progrès ont été réalisés et les performances globales ont atteint le premier niveau des modèles open source de même ampleur. Il prend en charge le contexte de 200 000 jetons, reçoit et traite le contenu d'entrée d'environ 300 000 caractères chinois à la fois, extrait avec précision les informations clés et parvient à « trouver l'aiguille dans la botte de foin » d'un texte long.
De plus, InternLM2 a fait des progrès considérables dans diverses capacités.Par rapport à l'InternLM de première génération, ses capacités de raisonnement, de mathématiques, de codage, etc. ont été considérablement améliorées et ses capacités globales sont en avance sur le même niveau de modèles open source.
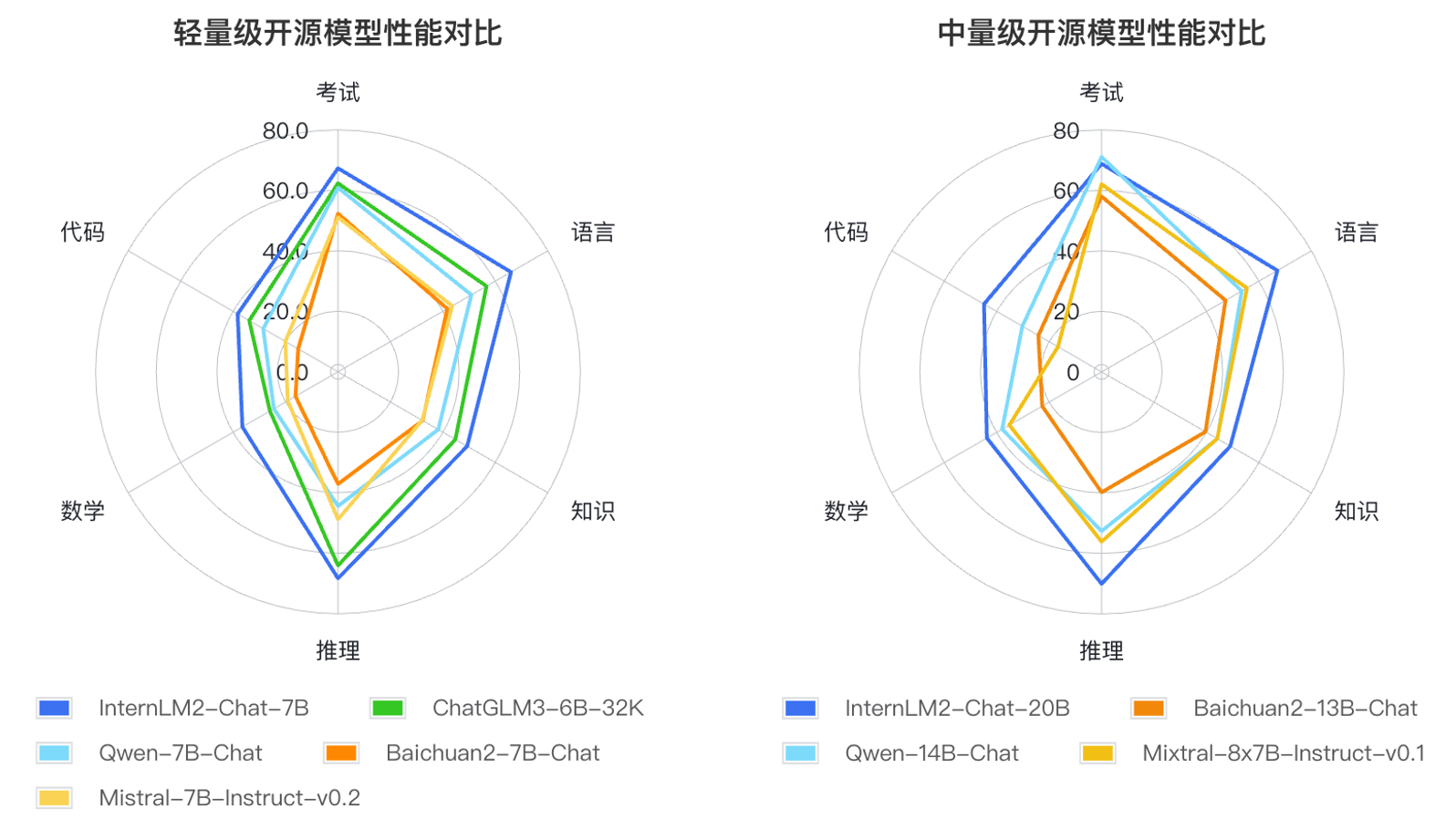
Sur la base des méthodes d'application de grands modèles de langage et des principaux domaines de préoccupation des utilisateurs, les chercheurs ont défini six dimensions de compétence telles que le langage, la connaissance, le raisonnement, les mathématiques, le code et l'examen, et ont testé les performances de plusieurs modèles de même ampleur sur 55 ensembles d'évaluation traditionnels. La performance a été évaluée de manière exhaustive. Les résultats de l'évaluation montrent que les versions légères (7B) et moyennes (20B) d'InternLM2 fonctionnent bien parmi les modèles de même taille.