1. Présentation de la plateforme
La facturation financière autonome assure principalement la fonction de transfert des données autonomes de JD de l'extrémité C à l'extrémité B de l'ensemble de la chaîne d'approvisionnement. Il s'agit d'une étape ultérieure dans l'ensemble de la chaîne d'approvisionnement. La fonction principale du système est la facturation et agrégation à l’extrémité B.
2. Description du problème
Ces dernières années, la quantité de données de facturation auto-exploitées a considérablement augmenté, avec plus de 10 milliards de volumes de données, et le résumé représente la moitié des ressources de la base de données en une journée.
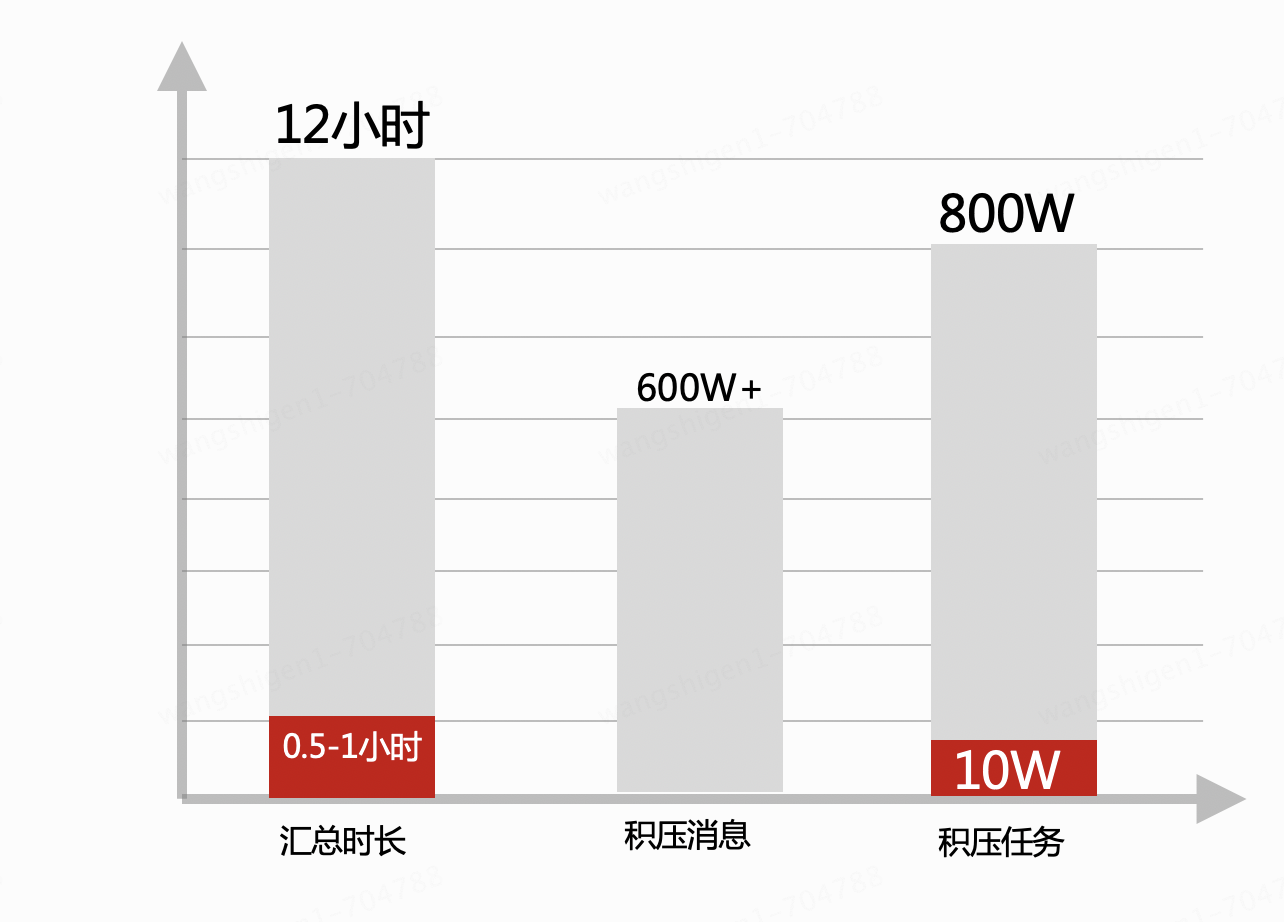
1. Localisez chaque jour des dizaines de milliers de données provenant de dizaines de millions de W+ dans une seule table pour effectuer un résumé, c'est-à-dire effectuer une opération groupe par opération sur toutes les bases de données et toutes les tables, 32 bases de données * 32 tables, ce qui prend 12 heures à traiter tous les jours.
2. Pendant la période d'agrégation, le système a pratiquement stagné, ce qui a entraîné un traitement lent des messages et des tâches, un retard important et l'incapacité de facturer les données en temps opportun.
3. La base de données est soumise à une forte pression et risque de planter à tout moment.
4. Cela affecte l'expérience des fournisseurs.Pendant la grande période de promotion, les fournisseurs doivent vérifier les données de vente et les rapports de bataille en temps réel, et le système ne peut pas répondre à temps.
3. Introduction à la technologie originale
Le cœur du résumé du système repose sur la machine physique MySQL pour effectuer le regroupement dans chaque base de données et chaque table. Le résumé est divisé et conquis par type de dépense. Chaque type de dimension récapitulative est différent. Chaque fois qu'une nouvelle dimension récapitulative est introduite, il doit être écrit d'avant en arrière. La nouvelle logique récapitulative consiste principalement à verrouiller la plage de données de la nouvelle dimension et à déterminer le nouveau groupe par champ. La logique précédente devait être testée par régression, ce qui est stupide, je pense.
4. Idées et méthodes pour résoudre les problèmes
Sur la base du contexte et des problèmes ci-dessus, déterminez une solution approximative au problème.
1. Tout d'abord, il faut s'éloigner du résumé MySQL. La base de données est très fragile. Il faut protéger la base de données, sinon l'ampleur continuera à augmenter et le ciel nous tombera un jour.
2. Résoudre incidemment les inconvénients du développement répété de nouvelles exigences.
5. Description du processus pratique
En raison du volume important, le traitement T+1 est autorisé dans l'entreprise. Puisqu'il s'agit d'un traitement de données hors ligne, on peut généralement penser à Spark, Spring Batch, Finlk, etc.. Au stade de la recherche technique, la maturité et l'activité communautaire sont principalement pris en compte, et la technologie des étincelles est principalement utilisée. Divisez le processus de résumé en 4 étapes. Afin de faciliter la compréhension, le contenu suivant simplifie la logique et la décrit brièvement.
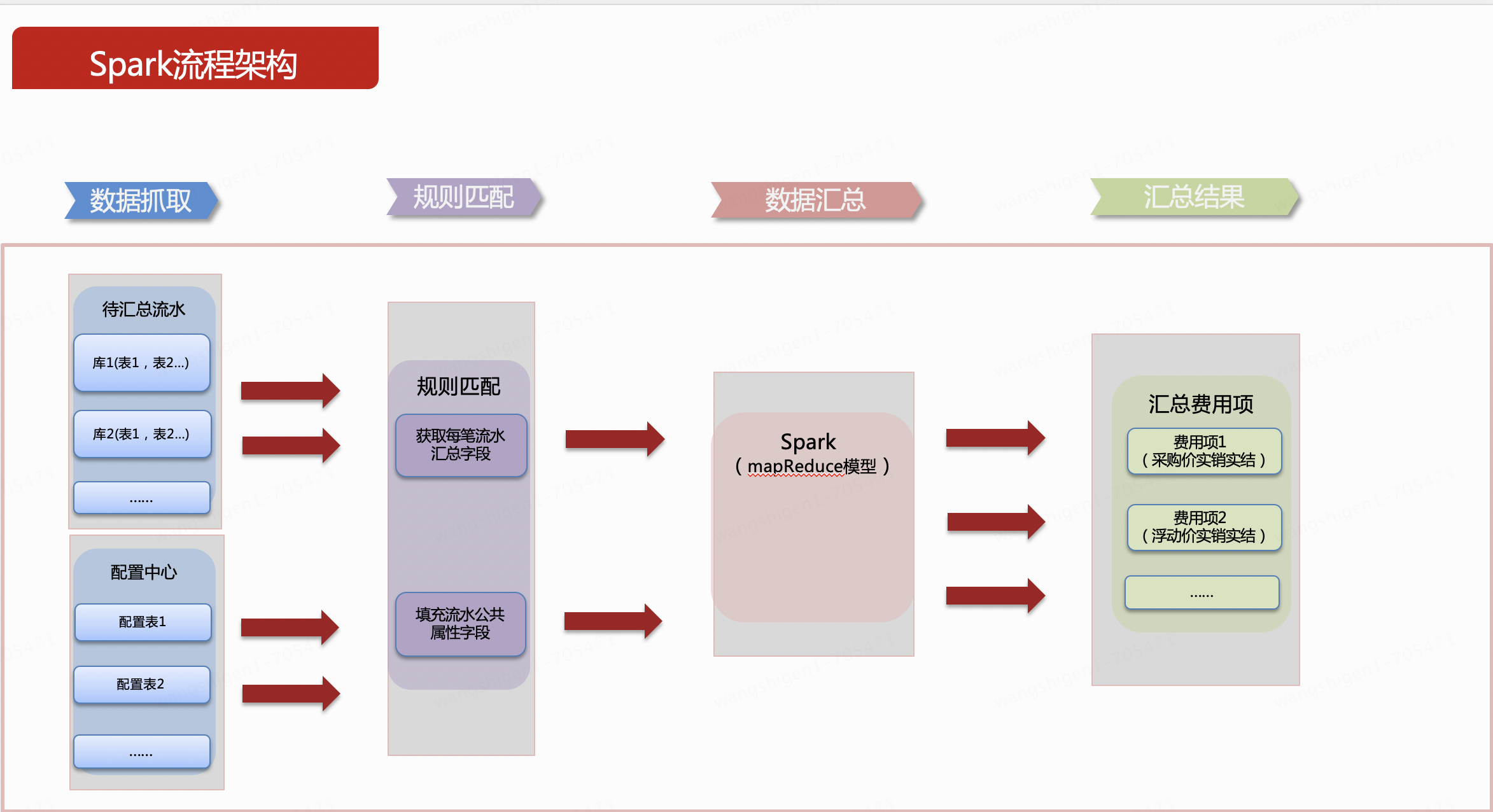
1. Saisie des données
Les données avant agrégation sont des données métiers. Type fait généralement référence au champ qui divise le type de coût des données dans les données métiers. ou et dept font généralement référence aux dimensions des données sources, qui peuvent être un ou plusieurs autres champs. Montant est le champ à résumer et à additionner.Exprimé ici est le montant.
La table de configuration est dérivée des données source. Il peut y avoir plusieurs données de configuration, ce qui est un terme général. Ce système n'utilise qu'une seule table. type indique que le type de dépense est utilisé pour l'association avec les données source. L'association peut être associée à un ou plusieurs champs. Ici, un champ est utilisé à titre d'exemple. merge_key est un champ récapitulatif et la valeur du champ est un ou plusieurs à partir de la structure du tableau des données sources. Composition des champs. bill_type représente les champs publics qui doivent être remplis dans l'ensemble de résultats agrégés et est généralement appelé ici type de facture. Il peut être développé en fonction des champs remplis. S'il est développé, il suffit d'ajouter des colonnes plus tard dans le tableau de configuration. L’exemple de diagramme suivant exprime cette signification dans un seul champ.
2. Correspondance des règles
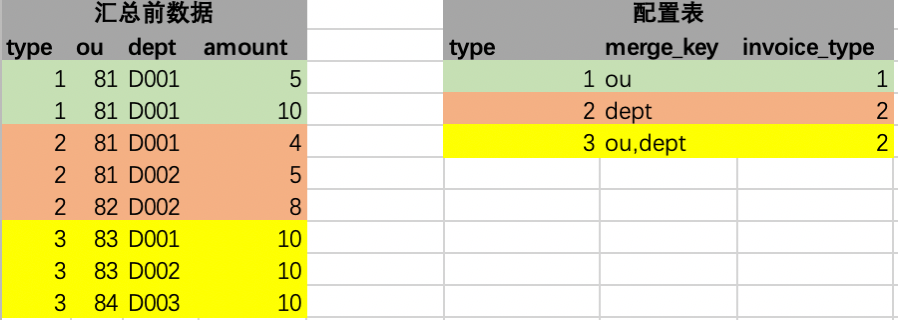
Le premier traitement est effectué, c'est-à-dire que chaque ligne des données source est associée à la seule ligne de la table de configuration, comme le montre la figure ci-dessous. Sous des instructions spéciales, chaque ligne de données source peut être associée à une seule ligne de configuration dans la table de configuration. C'est-à-dire une jointure gauche, qui ne peut pas être associée, c'est-à-dire qui n'a pas de configuration, est filtrée et n'est pas résumée . La première étape du traitement est réalisée en mémoire.

Passez ensuite à la deuxième étape du traitement. Dans cette étape, nous devons analyser davantage le champ merge_key extrait de la table de configuration dans la valeur spécifique du champ correspondant à la ligne de jointure gauche actuelle. Le résultat analysé est le suivant. Sous l'explication de cette étape, selon le champ de merge_key, tel que la première ligne ou, la valeur du champ de la colonne correspondante de cette ligne est obtenue, qui est 81. Le principe est mis en œuvre Grâce à la réflexion Java.Il existe désormais divers outils open source Le package peut être utilisé directement, comme les expressions Spring et d'autres outils. Par analogie, les valeurs de plusieurs champs peuvent également être obtenues. Plusieurs champs peuvent être épissés selon certains symboles de connexion. Ce chiffre est épissé avec _. Les champs remplis sont également ajoutés simultanément.
3. Résumé des données
Une fois les données de correspondance de règle traitées, il nous suffit de résumer le champ merge_key traité. Le moteur de résumé n'a besoin que de suivre le champ de résumé fixe (l'exemple ici est le champ merge_key après le traitement de la deuxième étape), et la logique de résumé est Il peut être solidifié, et un seul SQL général est nécessaire pour implémenter le résumé de tous les types de dépenses, et le résultat récapitulatif final est généré.
4. Résumé des résultats
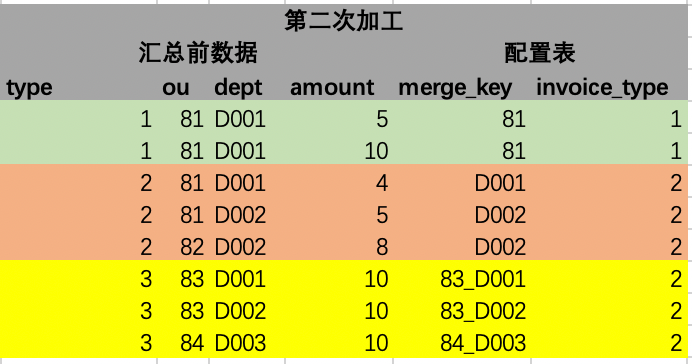
Les données agrégées peuvent conserver les mêmes résultats que les données agrégées via la technologie d'origine, et en même temps, certains champs communs peuvent être remplis. Comme le montre la figure ci-dessous, les 2 lignes vertes de données sources sont résumées par ou et deviennent 1 ligne dans le tableau de résultats ; les 3 lignes oranges de données sources sont résumées par département et deviennent 2 lignes dans le tableau de résultats ; la source jaune les données sont résumées par les champs ou et dept. Le résumé devient 3 lignes.

Enfin, réécrivez les résultats récapitulatifs dans MySQL.
6. Réflexion pratique sur les processus et évaluation des effets
1. Pendant le processus de vérification de l'environnement de test, la table de test et la table en ligne ont des niveaux numériques différents. Lors de la première mise en ligne, la lecture des données est extrêmement lente. Étant donné que Spark lit une seule table très rapidement, l'efficacité de la lecture des données des sous-bases de données et des sous-tables s'effondre. Ici, une méthode multithread est utilisée pour lire les données non résumées qui remplissent les conditions, et résume finalement un grand ensemble.
2. Après avoir été en ligne et avoir fonctionné de manière stable pendant un certain temps, le tableau de comparaison des performances montre qu'en supprimant le groupe par opération dans MySQL, le temps de résumé a été réduit, les performances de la base de données se sont améliorées et la capacité de traiter les messages et les tâches asynchrones se sont également améliorées et affectent la situation globale.
3. Lorsque de nouvelles exigences récapitulatives seront mises en ligne à l'avenir, la nouvelle fonction de résumé dimensionnel peut être mise en œuvre via la configuration, ce qui simplifie le travail de recherche et développement et améliore la rapidité de livraison de la demande. Il existe également des inconvénients : à l'heure actuelle, les champs des dimensions récapitulatives doivent être extraits de la table principale, car Spark ne lit que la table principale lors de la lecture des données métier, et ne lit pas la table étendue. Si vous êtes sûr de la qualité des données de la table ruche à l'avenir, vous pouvez la modifier en spark pour lire directement la table ruche, ou lire à partir de es, ck et d'autres bibliothèques.
4. Grâce à l'introduction du framework Spark, le résumé de la base de données volumineuse passe d'en ligne à hors ligne, ce qui soulage la pression sur la base de données. Une fois les performances de la base de données améliorées, l'efficacité de la facturation est également améliorée. Cela augmente également la stabilité de le système et améliore l'expérience du fournisseur.
Auteur : Wang Shigen
Source : Communauté de développeurs JD Cloud Veuillez indiquer la source lors de la réimpression
npm est abusé - quelqu'un a téléchargé plus de 700 vidéos de tranches de Wulin Gaiden "Linux Chine" La communauté open source a annoncé qu'elle cesserait ses activités Microsoft a formé une nouvelle équipe pour aider à réécrire la bibliothèque principale de Windows avec l'assistant d'IA fourni avec Rust JetBrain qui a provoqué le mécontentement des utilisateurs Deutsche Bahn recrute des personnes familiarisées avec MS - Les administrateurs informatiques de DOS et Windows 3.11 VS Code 1.86 entraîneront l'indisponibilité de la fonction de développement à distance. FastGateway : une passerelle qui peut être utilisée pour remplacer Nginx. Sortie de Visual Studio Code 1.86 . Sept départements dont le Le ministère de l'Industrie et des Technologies de l'information a publié conjointement un document : Développer le système d'exploitation de nouvelle génération et promouvoir la technologie open source. , Construire un écosystème open source Windows Terminal Preview 1.20 publié