
Dans l'esprit de l'auteur, la file d'attente des messages , le cache , la sous-base de données et la sous-table sont les trois épéistes des solutions à haute concurrence.
Au cours de ma carrière, j'ai utilisé des files d'attente de messages bien connues telles que ActiveMQ, RabbitMQ, Kafka et RocketMQ.
Dans cet article, l'auteur combine sa propre expérience réelle pour partager avec vous sept scénarios classiques d'application des files d'attente de messages.
1 Asynchrone et découplage
L'auteur était autrefois responsable du service utilisateur d'une société de commerce électronique, qui assurait des fonctions de base telles que l'enregistrement, la requête et la modification des utilisateurs. Une fois l'utilisateur inscrit avec succès, un message texte doit être envoyé à l'utilisateur.
Sur l'image, l'ajout de nouveaux utilisateurs et l'envoi de messages texte sont tous inclus dans le service du centre utilisateur. Les inconvénients de cette méthode sont très évidents :
-
Le canal SMS n'est pas assez stable et l'envoi d'un message texte prend environ 5 secondes, ce qui rend l'interface d'enregistrement des utilisateurs très longue et affecte l'expérience utilisateur frontale ;
-
Si l'interface du canal SMS change, le code du centre utilisateur doit être modifié. Mais User Center est le système de base. Vous devez être prudent chaque fois que vous allez en ligne. Cela semble très gênant, car les fonctions non essentielles affectent le système principal.
Afin de résoudre ce problème, l’auteur a utilisé la file d’attente des messages pour la reconstruire.

-
asynchrone
Une fois que le service du centre utilisateur a enregistré avec succès les informations utilisateur, il envoie un message à la file d'attente des messages et renvoie immédiatement le résultat au front-end, ce qui peut éviter le problème de prendre beaucoup de temps et d'affecter l'expérience utilisateur.
-
découplage
Lorsque le service de tâches reçoit le message, il appelle le service SMS pour envoyer le SMS, ce qui sépare les services principaux des fonctions non essentielles et réduit considérablement le couplage entre les systèmes.
2 Élimination du pic
Dans les scénarios à forte concurrence, des pics soudains de requêtes peuvent facilement rendre le système instable. Par exemple, un grand nombre de requêtes d'accès à la base de données exerceront une forte pression sur la base de données, ou les ressources du système, CPU et E/S, peuvent devenir un goulot d'étranglement. .
L'auteur a déjà servi l'équipe de commande de voitures privées de Shenzhou. Pendant le cycle de vie des passagers de la commande, l'opération de modification de commande modifie d'abord le cache de commande, puis envoie le message à MetaQ. Le service de passation de commande consomme le message et détermine si la commande Les informations sont normales (par exemple si elles sont en panne), si les données de commande sont correctes, elles seront stockées dans la base de données.

Face à un pic de demande, étant donné que la concurrence des consommateurs se situe dans une plage seuil et que la vitesse de consommation est relativement uniforme, cela n'aura pas un grand impact sur la base de données. En même temps, les producteurs du système de commande qui sont réellement confrontés au pic de demande. le front-end deviendra également plus stable.
Bus à 3 messages
Le soi-disant bus est comme le bus de données de la carte mère, avec la capacité de transmettre et d'interagir des données. Les parties ne communiquent pas directement et utilisent le bus comme interface de communication standard .
L'auteur a déjà travaillé dans l'équipe de commande d'une société de loterie. Au cours du cycle de vie d'une commande de loterie, celle-ci est passée par de nombreuses étapes telles que la création, le fractionnement des sous-commandes, l'émission des billets et le calcul du prix. Chaque lien nécessite un traitement de service différent, chaque système possède sa propre table indépendante et les fonctions métier sont relativement indépendantes. Si chaque application devait modifier les informations de la table principale des commandes, cela serait assez déroutant.
Par conséquent, l'architecte de l'entreprise a conçu le service du <font color="red"> Dispatch Center </font>. Le Dispatch Center conserve les informations sur les commandes, mais il ne communique pas avec les sous-services, mais via des files d'attente de messages et des passerelles de billetterie. tels que les services de calcul de prix, transmettent et échangent des informations.
La conception architecturale du bus de messages peut rendre le système plus découplé et permettre à chaque système d'accomplir ses propres tâches.
4 tâches retardées
Lorsqu'un utilisateur passe une commande sur l'application Meituan et ne paie pas immédiatement, un compte à rebours s'affichera lors de la saisie des détails de la commande. Si le délai de paiement est dépassé, la commande sera automatiquement annulée.
Une manière très élégante consiste à utiliser les messages retardés de la file d'attente des messages .
Une fois que le service de commande a généré la commande, il envoie un message retardé à la file d'attente des messages. La file d'attente de messages transmet le message au consommateur lorsque le message atteint l'heure d'expiration du paiement. Une fois que le consommateur a reçu le message, il détermine si le statut de la commande est payé. Si elle n'est pas payée, la logique d'annulation de la commande est exécutée.

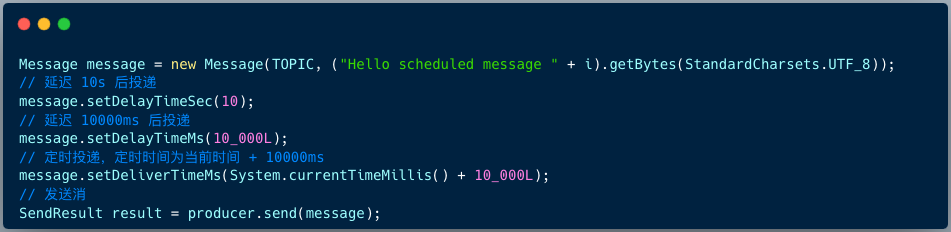
Le code permettant au producteur RocketMQ 4.X d'envoyer des messages retardés est le suivant :
Message msg = new Message();
msg.setTopic("TopicA");
msg.setTags("Tag");
msg.setBody("this is a delay message".getBytes());
//设置延迟level为5,对应延迟1分钟
msg.setDelayTimeLevel(5);
producer.send(msg);
La version RocketMQ 4.X prend en charge 18 niveaux de messages retardés par défaut, qui sont déterminés par l'élément de configuration messageDelayLevel côté courtier.

La version RocketMQ 5.X prend en charge le retard des messages à tout moment. Le client fournit 3 API pour spécifier le temps de retard ou le temps de synchronisation lors de la construction du message.
5 Consommation radio
Consommation de diffusion : lors de l'utilisation du mode de consommation de diffusion, chaque message est transmis à tous les consommateurs du cluster, garantissant que le message est consommé par chaque consommateur au moins une fois.
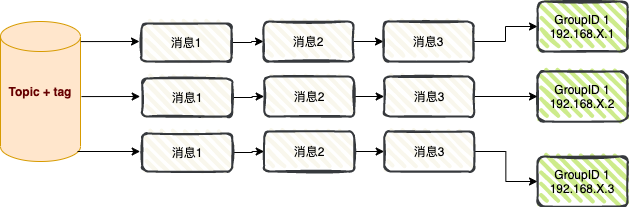
La consommation de diffusion est principalement utilisée dans deux scénarios : le transfert de messages et la synchronisation du cache .
01 Message poussé
La figure ci-dessous montre le mécanisme de poussée côté conducteur d'une voiture privée. Une fois que l'utilisateur a passé une commande, le système de commande génère une commande de voiture spéciale. Le système de répartition enverra la commande à un conducteur sur la base de l'algorithme correspondant, et au conducteur. -end recevra le message push de répartition.
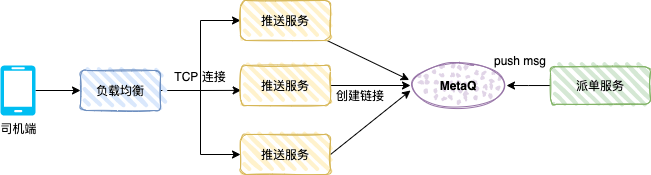
Le service push est un service TCP (protocole personnalisé) et un service consommateur. Le mode message est une consommation de diffusion.
Une fois que le pilote ouvre l'application du pilote, l'application créera une longue connexion via l'équilibrage de charge et le service push, et le service push enregistrera la référence de connexion TCP (telle que le numéro du pilote et la référence du canal TCP).
Le service de répartition est le producteur et envoie les données de répartition à MetaQ. Chaque service push consommera le message. Le service push détermine si le canal TCP du pilote existe dans la mémoire locale. S'il existe, les données sont poussées vers le serveur. via la connexion TCP.
02 Synchronisation du cache
Dans les scénarios à forte concurrence, de nombreuses applications utilisent le cache local pour améliorer les performances du système.
Le cache local peut être HashMap, ConcurrentHashMap ou le framework de mise en cache Guava Cache ou le cache Caffeine.

Comme le montre la figure ci-dessus, après le démarrage de l'application A, en tant que consommateur RocketMQ, le mode message est défini sur la consommation de diffusion. Afin d'améliorer les performances de l'interface, chaque nœud d'application charge la table du dictionnaire dans le cache local.
Lorsque les données de la table du dictionnaire changent, un message peut être envoyé à RocketMQ via le système d'entreprise, et chaque nœud d'application consommera le message et actualisera le cache local.
6 Transactions distribuées
En prenant comme exemple le scénario de transaction de commerce électronique, l'opération de base du paiement des commandes par les utilisateurs impliquera également des changements dans plusieurs sous-systèmes tels que la livraison logistique en aval, les changements de points et la compensation de l'état du panier.
![]()
1. Solution de transaction XA traditionnelle : performances insuffisantes
Afin d'assurer la cohérence des résultats d'exécution des quatre branches ci-dessus, une solution typique est implémentée par un système de transactions distribuées basé sur le protocole XA. Encapsulez les quatre branches d'appel dans une transaction volumineuse contenant quatre branches de transaction indépendantes. La solution basée sur les transactions distribuées XA peut garantir l'exactitude des résultats du traitement métier, mais le plus gros inconvénient est que dans un environnement multi-branches, la plage de verrouillage des ressources est large et la concurrence est faible. À mesure que le nombre de branches en aval augmente, le nombre de branches en aval augmente. les performances du système deviendront de pire en pire.
2. Basé sur un schéma de message ordinaire : difficulté à assurer la cohérence
![]()
Dans cette solution, la branche aval du message et la branche principale du changement du système de commande sont sujettes à des incohérences, par exemple :
- Le message a été envoyé avec succès, mais la commande n'a pas été exécutée avec succès et l'intégralité de la transaction doit être annulée.
- La commande a été exécutée avec succès, mais le message n'a pas été envoyé avec succès et une compensation supplémentaire a été nécessaire pour découvrir l'incohérence.
- Le délai d'expiration du message est inconnu et il est impossible de déterminer si la commande doit être annulée ou si les modifications de commande doivent être soumises.
3. Basé sur les messages de transaction distribués RocketMQ : prend en charge la cohérence éventuelle
Dans la solution de message ordinaire mentionnée ci-dessus, la raison pour laquelle la cohérence des messages ordinaires et des transactions de commande ne peut pas être garantie est essentiellement parce que les messages ordinaires ne peuvent pas avoir la capacité de validation, d'annulation et de coordination unifiée comme les transactions de base de données autonomes.
La fonction de message de transaction distribuée implémentée sur la base de RocketMQ prend en charge des capacités de soumission en deux étapes basées sur des messages ordinaires. Liez la soumission en deux phases aux transactions locales pour assurer la cohérence des résultats de soumission globale.
Les messages de transaction RocketMQ prennent en charge la cohérence éventuelle de la production de messages et des transactions locales dans les scénarios distribués . Le processus d'interaction est illustré dans la figure ci-dessous :
![]()
1. Le producteur envoie le message au courtier.
2. Une fois que le courtier a réussi à conserver le message, il renvoie un accusé de réception au producteur pour confirmer que le message a été envoyé avec succès. À ce stade, le message est marqué comme « temporairement non remis ». Le message dans cet état est un semi-. message de transaction .
3. Le producteur commence à exécuter la logique de transaction locale .
4. Le producteur soumet un résultat de confirmation secondaire (Commit ou Rollback) au serveur en fonction du résultat de l'exécution de la transaction locale. Une fois que le courtier a reçu le résultat de la confirmation, la logique de traitement est la suivante :
- Le résultat secondaire de la confirmation est Commit : le courtier marque le message de semi-transaction comme livrable et le remet au consommateur.
- Le résultat secondaire de la confirmation est Rollback : le courtier annulera la transaction et ne transmettra pas le message de semi-transaction au consommateur.
5. Dans des circonstances particulières où le réseau est déconnecté ou l'application du producteur est redémarrée, si le courtier ne reçoit pas le résultat de la confirmation secondaire soumis par l'expéditeur, ou si le résultat de la confirmation secondaire reçu par le courtier est dans le statut Inconnu, après un délai fixe. Pendant une période de temps, le service Le terminal lancera une révision des messages .
- Une fois que le producteur a reçu la révision du message, il doit vérifier le résultat final de l'exécution de la transaction locale correspondant au message.
- Le producteur soumet à nouveau une confirmation secondaire basée sur le statut final de la transaction locale qui est vérifiée , et le serveur traite toujours le message de demi-transaction selon l'étape 4.
7 Centre de transfert de données
Au cours des 10 dernières années, des systèmes spéciaux tels que le stockage KV (HBase), la recherche (ElasticSearch), le traitement de streaming (Storm, Spark, Samza), la base de données de séries chronologiques (OpenTSDB) et d'autres systèmes spéciaux ont vu le jour. Ces systèmes ont été créés avec un seul objectif en tête, et leur simplicité rend plus facile et plus rentable la création de systèmes distribués sur du matériel standard.
Souvent, le même ensemble de données doit être injecté dans plusieurs systèmes spécialisés.
Par exemple, lorsque les journaux d'application sont utilisés pour l'analyse des journaux hors ligne, la recherche d'enregistrements de journaux individuels est également indispensable. Il est évidemment peu pratique de créer des flux de travail indépendants pour collecter chaque type de données, puis de les importer dans leurs propres systèmes dédiés. sert de hub de transfert de données et les mêmes données peuvent être importées dans différents systèmes dédiés.
La synchronisation des journaux comprend principalement trois éléments clés : le client de collecte de journaux, la file d'attente de messages Kafka et l'application de traitement des journaux back-end.
- Le client de collecte de journaux est responsable de la collecte des données de journaux de divers services d'application utilisateur et envoie les journaux « par lots » et « de manière asynchrone » au client Kafka sous forme de messages. Le client Kafka soumet et compresse les messages par lots, ce qui a très peu d'impact sur les performances des services applicatifs.
- Kafka stocke les journaux dans des fichiers de messages, assurant ainsi la persistance.
- Les applications de traitement des journaux, telles que Logstash, s'abonnent et consomment les messages de journaux dans Kafka. Finalement, le service de recherche de fichiers récupère les journaux, ou Kafka transmet les messages à d'autres applications Big Data telles que Hadoop pour un stockage et une analyse systématiques.

Si mon article vous est utile, aimez- le, lisez-le et transmettez -le. Votre soutien m'encouragera à produire des articles de meilleure qualité. Merci beaucoup !
