arrière-planintroduire
Les GPU sont actuellement largement utilisés dans la plateforme d'apprentissage en profondeur iQiyi. Le GPU possède des centaines ou des milliers de cœurs de traitement et peut exécuter un grand nombre d'instructions en parallèle, ce qui le rend très approprié pour les calculs liés au deep learning. Les GPU ont été largement utilisés dans les modèles CV (vision par ordinateur) et NLP (traitement du langage naturel). Par rapport aux processeurs, ils peuvent généralement effectuer la formation et l'inférence de modèles plus rapidement et de manière plus économique.
Le modèle CTR (Click Trough Rate) est largement utilisé dans les scénarios de recommandation, de publicité, de recherche et autres pour estimer la probabilité qu'un utilisateur clique sur une publicité ou une vidéo. Les GPU ont été largement utilisés dans le scénario de formation du modèle CTR, ce qui améliore la vitesse de formation et réduit les coûts de serveur requis.
Mais dans le scénario d'inférence, lorsque nous déployons directement le modèle entraîné sur le GPU via Tensorflow-serving, nous constatons que l'effet d'inférence n'est pas idéal. apparaît dans :
-
La latence d'inférence est élevée. Les modèles de type CTR sont généralement orientés vers l'utilisateur final et sont très sensibles à la latence d'inférence.
-
L'utilisation du GPU est faible et la puissance de calcul n'est pas pleinement utilisée.
Analyse des causes
outil d'analyse
-
Tensorflow Board, un outil officiellement fourni par tensorflow, peut visualiser visuellement le temps pris à chaque étape du graphique de flux de calcul et résumer le temps total des opérateurs.
-
Nsight est une suite d'outils de développement fournie par NVIDIA pour les développeurs CUDA. Elle peut effectuer un suivi, un débogage et une analyse des performances de niveau relativement bas des programmes CUDA.
Conclusion de l'analyse
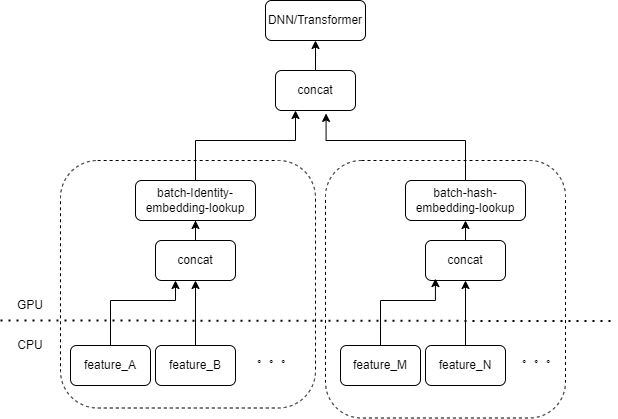
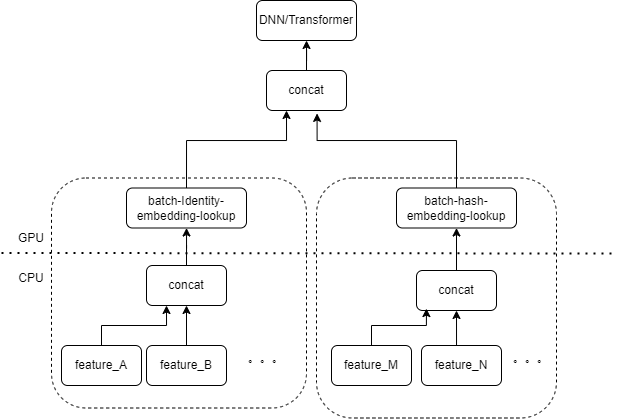
L'entrée typique du modèle CTR contient un grand nombre de fonctionnalités éparses (telles que l'ID de l'appareil, l'ID de la vidéo récemment visionnée, etc.). FeatureColumn de Tensorflow traitera ces fonctionnalités. Tout d'abord, des opérations d'identité/hachage sont effectuées pour obtenir l'index de la table d'intégration. Après les opérations de recherche et de moyenne d'intégration, le tenseur d'intégration correspondant est obtenu. Après avoir épissé les tenseurs d'intégration correspondant à plusieurs caractéristiques, un nouveau tenseur est obtenu, puis entre dans le DNN/Transformer suivant et d'autres structures.
Par conséquent, chaque fonctionnalité clairsemée activera plusieurs opérateurs dans la couche d’entrée du modèle. Chaque opérateur correspondra à un ou plusieurs calculs GPU, c'est-à-dire le noyau cuda. Chaque noyau cuda comprend deux étapes : le lancement du noyau cuda (la surcharge nécessaire au démarrage du noyau) et l'exécution du noyau (effectuant réellement des calculs matriciels sur le noyau cuda). L'opérateur correspondant à la recherche d'identité/hachage/intégration de fonctionnalité clairsemée nécessite une petite quantité de calcul, et le lancement du noyau prend souvent plus de temps que le temps d'exécution du noyau. De manière générale, le modèle CTR contient des dizaines, voire des centaines de fonctionnalités éparses, et théoriquement, il y aura des centaines de noyaux de lancement, ce qui constitue actuellement le principal goulot d'étranglement des performances.
Ce problème n'a pas été rencontré lors de l'utilisation du GPU pour entraîner le modèle CTR. Étant donné que la formation elle-même est une tâche hors ligne et ne tient pas compte des retards, la taille du lot pendant la formation peut être très importante. Bien que le lancement du noyau soit toujours effectué plusieurs fois, tant que le nombre d'échantillons calculé lors de l'exécution du noyau est suffisamment grand, le temps moyen passé sur chaque échantillon du lancement du noyau sera très faible. Pour les scénarios d'inférence en ligne, si Tensorflow Serving doit recevoir suffisamment de requêtes d'inférence et fusionner des lots avant d'effectuer des calculs, la latence d'inférence sera très élevée.
Optimisation
Notre objectif est d'optimiser les performances sans changer fondamentalement le code de formation ou le cadre de service. Nous pensons naturellement à deux méthodes, réduire le nombre de noyaux démarrés et améliorer la vitesse de démarrage du noyau.
Fusion d'opérateurs
L'opération de base consiste à fusionner plusieurs opérations ou opérateurs consécutifs en un seul opérateur. D'une part, cela peut réduire le nombre de démarrages du noyau cuda. D'autre part, certains résultats intermédiaires pendant le processus de calcul peuvent être stockés dans des registres ou partagés. mémoire, et uniquement dans le calcul A la fin de la sous-section, les résultats du calcul sont écrits dans la mémoire globale cuda.
Il existe deux méthodes principales
-
Fusion automatique basée sur un compilateur d'apprentissage profond
-
Fusion d'opérateurs manuels pour les entreprises
fusion automatique
Nous avons essayé une variété de compilateurs d'apprentissage profond, tels que TVM/TensorRT/XLA, et des tests réels peuvent réaliser la fusion d'un petit nombre d'opérateurs dans DNN, tels que MatrixMat/ADD/Relu continu. Étant donné que TVM/TensorRT doit exporter des formats intermédiaires tels que onnx, le processus en ligne du modèle d'origine doit être modifié. Nous utilisons donc tf.ConfigProto() pour activer le XLA intégré de tensorflow pour la fusion.
Cependant, la fusion automatique n'a pas un bon effet de fusion sur les opérateurs liés aux fonctionnalités clairsemées.
Fusion manuelle par opérateur
Nous pensons naturellement que s'il existe plusieurs entités traitées par le même type de combinaison FeatureColumn dans la couche d'entrée, nous pouvons alors implémenter un opérateur pour regrouper l'entrée de plusieurs entités dans un tableau en tant qu'entrée de l'opérateur. La sortie de l'opérateur est un tenseur, et la forme de ce tenseur est cohérente avec la forme du tenseur obtenu en calculant les caractéristiques d'origine séparément, puis en les concaténant.
En prenant comme exemple la combinaison originale IdentityCategoricalColumn + EmbeddingColumn, nous avons implémenté l'opérateur BatchIdentiyEmbeddingLookup pour obtenir la même logique de calcul.
Afin de faciliter l'utilisation des étudiants en algorithmique, nous avons encapsulé un nouveau FusedFeatureLayer pour remplacer le FeatureLayer natif en plus d'inclure l'opérateur de fusion, la logique suivante est également implémentée :
-
La logique fusionnée prend effet lors de l'inférence et la logique originale est utilisée pendant la formation.
-
Les fonctionnalités doivent être triées pour garantir que les fonctionnalités du même type peuvent être organisées ensemble.
-
Étant donné que l'entrée de chaque fonctionnalité est de longueur variable, nous générons ici un tableau d'index supplémentaire pour marquer à quelle fonctionnalité appartient chaque élément du tableau d'entrée.
Pour les entreprises, seul le FeatureLayer d'origine doit être remplacé pour obtenir l'effet d'intégration.
Le noyau de lancement qui a été initialement testé des centaines de fois a été réduit à moins de 10 fois après une fusion manuelle. La surcharge liée au démarrage du noyau est considérablement réduite.
MultiStream améliore l'efficacité du lancement
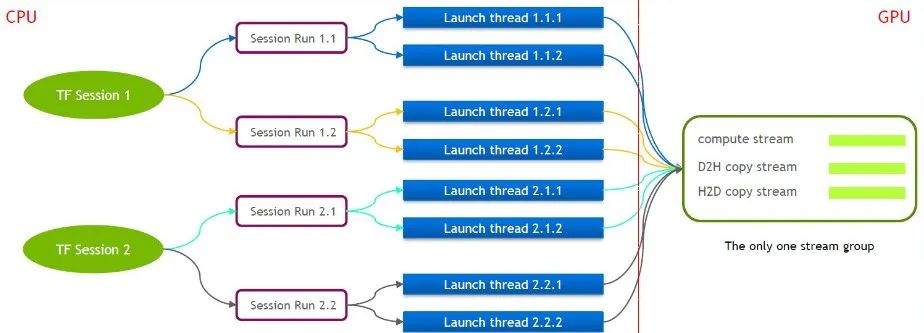
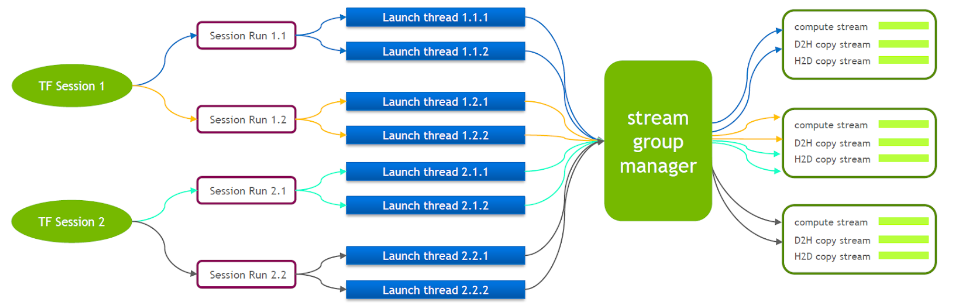
TensorFlow lui-même est un modèle à flux unique, contenant un seul groupe de flux Cuda (composé de Compute Stream, H2D Stream, D2H Stream et D2D Stream). Plusieurs noyaux ne peuvent s'exécuter qu'en série sur le même Compute Stream, ce qui est inefficace. Même si le noyau cuda est lancé via plusieurs sessions Tensorflow, la mise en file d'attente est toujours requise côté GPU.
Pour cette raison, l'équipe technique de NVIDIA maintient sa propre branche de Tensorflow pour prendre en charge l'exécution simultanée de plusieurs groupes de flux. Ceci est utilisé pour améliorer l’efficacité du lancement du noyau cuda. Nous avons porté cette fonctionnalité dans notre service Tensorflow.
Lorsque Tensorflow Serving est en cours d'exécution, Nvidia MPS doit être activé pour réduire les interférences mutuelles entre plusieurs contextes CUDA.
Optimisation de la copie de petites données
Sur la base de l'optimisation précédente, nous avons encore optimisé la petite copie de données. Une fois que Tensorflow Serving a désérialisé les valeurs de chaque fonctionnalité de la requête, il appelle cudamemcpy plusieurs fois pour copier les données de l'hôte vers l'appareil. Le nombre d'appels dépend du nombre de fonctionnalités.
Pour la plupart des services CTR, on mesure en fait que lorsque la taille du lot est petite, il sera plus efficace de fusionner d'abord les données du côté hôte, puis d'appeler cudamemcpy d'un seul coup.
Fusionner des lots
Dans le scénario GPU, la fusion par lots doit être activée. Par défaut, Tensorflow Serving ne fusionne pas les requêtes. Afin de mieux utiliser les capacités de calcul parallèle du GPU, davantage d'échantillons peuvent être inclus dans un seul calcul direct. Nous avons activé l'option activate_batching de Tensorflow Serving au moment de l'exécution pour fusionner par lots plusieurs requêtes. Dans le même temps, vous devez fournir un fichier de configuration par lots, en vous concentrant sur la configuration des paramètres suivants. Voici quelques-unes de nos expériences.
-
max_batch_size : nombre maximum de requêtes autorisées dans un lot, qui peut être légèrement plus grand.
-
batch_timeout_micros : Le temps maximum d'attente pour la fusion d'un lot. Même si le numéro du lot n'atteint pas max_batch_size, il sera calculé immédiatement (l'unité est en microsecondes). Théoriquement, plus le délai requis est élevé, plus le paramètre ici est petit. Il est préférable de définir moins de 5 millisecondes.
-
num_batch_threads : nombre maximal de threads d'inférence simultanés après avoir activé MPS, il peut être défini sur 1 à 4. Tout nombre supplémentaire augmentera le délai.
Il convient de noter ici que la plupart des fonctionnalités clairsemées entrées dans le modèle de classe CTR sont des fonctionnalités de longueur variable. Si le client ne conclut pas d'accord particulier, la durée d'une certaine fonctionnalité peut être incohérente dans plusieurs demandes. Tensorflow Serving a une logique de remplissage par défaut, qui complète les fonctionnalités correspondantes avec des zéros pour les requêtes plus courtes. Pour les fonctionnalités de longueur variable, -1 est utilisé pour représenter null. Le remplissage par défaut de 0 modifiera en fait la signification de la requête d'origine.
Par exemple, l'identifiant de la vidéo la plus récemment regardée par l'utilisateur A est [3,5], et l'identifiant de la vidéo la plus récemment regardée par l'utilisateur B est [7,9,10]. Si elle est complétée par défaut, la requête devient [[3,5,0], [7,9,10]]. Lors du traitement ultérieur, le modèle pensera que A a récemment regardé 3 vidéos avec les ID 3, 5, 0. .
Par conséquent, nous avons modifié la logique d'achèvement de la réponse de Tensorflow Serving. Dans ce cas, la logique d'achèvement sera [[3,5,-1], [7,9,10]]. La première ligne signifie toujours que les vidéos 3 et 5 ont été visionnées.
effet final
Après diverses optimisations mentionnées ci-dessus, la latence et le débit ont répondu à nos besoins et ont été implémentés dans les services de streaming push et cascade personnalisés recommandés. Les résultats commerciaux sont les suivants :
-
Le débit est augmenté de plus de 6 fois par rapport au conteneur GPU natif Tensorflow.
-
La latence est fondamentalement la même que celle du processeur, répondant aux besoins de l'entreprise
-
En prenant en charge le même QPS, le coût est réduit de plus de 40 %
Peut-être que tu veux aussi voir
Cet article est partagé à partir du compte public WeChat - Équipe produit technologique iQIYI (iQIYI-TP).
En cas d'infraction, veuillez contacter [email protected] pour suppression.
Cet article participe au « Plan de création de sources OSC ». Vous qui lisez, êtes invités à vous joindre et à partager ensemble.