En tant que solution permettant d'améliorer l'utilisation des ressources et de réduire les coûts, la colocalisation est généralement reconnue par l'industrie. Dans le processus de natif du cloud, de réduction des coûts et d'amélioration de l'efficacité, iQiyi a réussi à combiner l'informatique hors ligne Big Data, le traitement de contenu audio et vidéo et d'autres charges de travail avec les activités en ligne, et a réalisé des gains progressifs. Cet article se concentre sur le Big Data comme exemple pour présenter le processus pratique de mise en œuvre d'un système à déploiement mixte de 0 à 1.
arrière-plan
Le big data iQIYI prend en charge des scénarios importants tels que la prise de décision opérationnelle, la croissance des utilisateurs, la distribution de publicités, les recommandations vidéo, la recherche et l'adhésion au sein de l'entreprise, fournissant ainsi un moteur basé sur les données pour l'entreprise. À mesure que les demandes des entreprises augmentent, la quantité de ressources informatiques requises augmente de jour en jour, et le contrôle des coûts et l'approvisionnement en ressources sont confrontés à une pression toujours plus forte.
Le calcul Big Data d'iQIYI est divisé en deux maillons de traitement de données : le calcul hors ligne et le calcul en temps réel, parmi lesquels :
-
L'informatique hors ligne comprend le traitement des données basé sur Spark, la construction d'un entrepôt de données horaire ou même journalier basé sur Hive ainsi que l'interrogation et l'analyse des rapports correspondants. Ce type de calcul commence généralement tôt le matin de chaque jour pour calculer les données de la veille et se termine dans. le matin. . De 0 à 8 heures chaque jour est la période de pointe de demande de ressources informatiques. Les ressources totales du cluster sont souvent insuffisantes et les tâches sont souvent mises en file d'attente et en retard. Au cours de la journée, il y a une grande quantité de temps d'inactivité, ce qui entraîne. un gaspillage de ressources.
-
L'informatique en temps réel comprend le traitement des flux de données en temps réel représenté par Kafka + Flink, qui nécessite des ressources relativement stables.
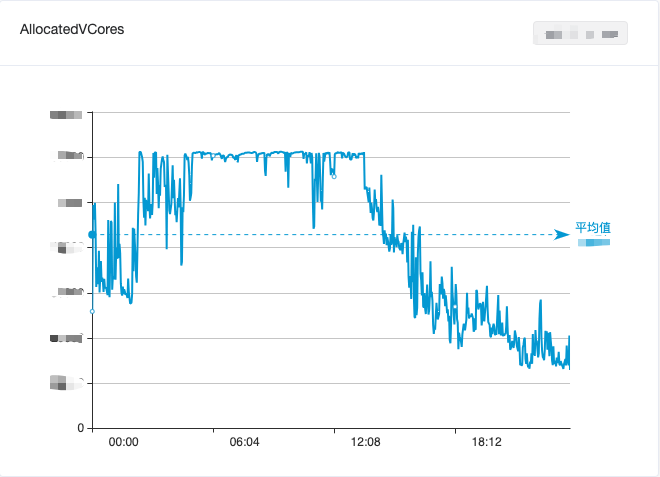
Afin d'équilibrer l'utilisation des ressources du Big Data, nous avons mélangé l'informatique hors ligne et l'informatique en temps réel, ce qui a réduit dans une certaine mesure le gaspillage de ressources inutilisées pendant la journée, mais il n'a toujours pas été en mesure de réduire efficacement les pics et de combler les creux. et l'utilisation globale des ressources informatiques du Big Data montrait toujours " Le phénomène de marée de « creux diurne et pic tôt le matin » est illustré dans la figure 1.
Figure 1. Modifications de l'utilisation du processeur du cluster de calcul Big Data en une journée
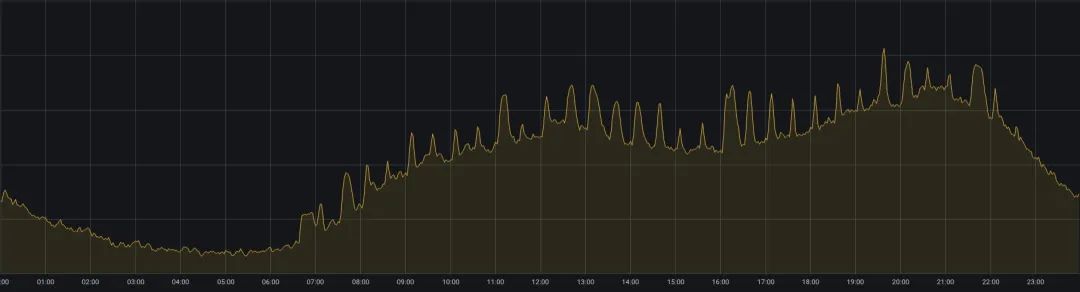
L’activité en ligne d’iQiyi est confrontée à un autre problème : l’équilibre entre la qualité du service et l’utilisation des ressources. Le commerce en ligne sert principalement à des scénarios tels que la lecture de vidéos iQiyi. Il y a plus d'utilisateurs qui regardent des vidéos à midi et le soir, et l'utilisation des ressources présente un phénomène de marée de « pics pendant la journée et de creux tôt le matin » (comme le montre la figure 2). . Afin de garantir la qualité du service pendant les périodes de pointe, les entreprises en ligne réservent généralement plus de ressources, ce qui rend leur utilisation très insatisfaisante.
Figure 2. Modifications de l'utilisation du processeur du cluster d'entreprise en ligne en une journée
Afin d'améliorer l'utilisation, la plate-forme de conteneurs de génération précédente développée par iQiyi a adopté une stratégie de surréservation statique du processeur. Bien que cette méthode ait un effet significatif sur l'amélioration de l'utilisation, elle est limitée par des facteurs tels que les capacités de base et ne peut pas éviter les interruptions entre les services sur un seul. Des problèmes occasionnels de concurrence entre les ressources ont également conduit à une qualité instable des services commerciaux en ligne, et ce problème n'a jamais été correctement résolu.
Avec l'avancement de la nativeisation du cloud, la plate-forme de conteneurs iQiyi s'est progressivement transformée en pile technologique Kubernetes (ci-après dénommée « K8s »). Ces dernières années, de nombreux projets open source liés au co-déploiement sont apparus dans la communauté K8, et il existe également des pratiques de co-déploiement dans l'industrie [1] . Dans ce contexte, l'équipe de la plateforme informatique a ajusté son orientation de travail de « surréservation statique » à « surréservation dynamique + déploiement mixte ».
En tant qu'activité hors ligne la plus typique, le Big Data est un pionnier dans la mise en œuvre de la colocalisation. D'une part, le Big Data a un volume important et des besoins en ressources informatiques relativement stables ; d'autre part, le Big Data et le commerce en ligne peuvent produire des effets complémentaires dans de nombreux domaines, et l'utilisation des ressources peut être pleinement améliorée grâce à la colocalisation.
Sur la base de l'analyse ci-dessus, l'équipe de la plateforme informatique iQiyi et l'équipe Big Data ont commencé à explorer la colocalisation.
Conception de plans d'implantation mixtes
Le système Big Data iQiyi est construit sur l'écosystème open source Apache Hadoop et utilise YARN comme système de planification des ressources informatiques. Le commerce en ligne est basé sur K8. Comment connecter deux systèmes de planification des ressources différents est la première chose à résoudre. la solution de colocalisation.
Il existe généralement deux solutions colocalisées dans l’industrie :
-
Option 1 : Exécutez directement des tâches Big Data (Spark, Flink, etc., MapReduce n'est pas pris en charge) sur les K8 et utilisez son planificateur natif
-
Option 2 : Exécutez NodeManager de YARN (ci-après dénommé « NM ») sur les K8, et les tâches Big Data sont toujours planifiées via YARN.
Après mûre réflexion, nous avons choisi la deuxième option pour les deux raisons principales suivantes :
-
À l'heure actuelle, la grande majorité des tâches informatiques Big Data de l'entreprise sont planifiées sur la base de YARN. YARN dispose de puissantes fonctions de planification (file d'attente multi-locataires, prise en compte des racks), d'excellentes performances de planification (plus de 5 000 conteneurs/s) et de mécanismes de sécurité complets. (Kerberos, jetons de délégation) et prend en charge presque tous les frameworks informatiques Big Data tels que MapReduce, Spark et Flink. Depuis l'introduction de YARN en 2014, l'équipe Big Data d'iQiyi a construit autour de lui une série de plates-formes pour le développement, l'exploitation et la maintenance, la gouvernance informatique, etc., offrant aux utilisateurs internes un processus de développement Big Data pratique. Par conséquent, la compatibilité avec l’API YARN est l’une des considérations importantes lors de la sélection d’une solution hybride.
-
Bien que K8s dispose d'un planificateur par lots, celui-ci n'est pas suffisamment mature et il existe un goulot d'étranglement dans les performances de planification (<1 000 conteneurs/s), ce qui n'est pas suffisant pour répondre aux besoins des scénarios Big Data.
Au niveau K8, les deux parties ont besoin d'un ensemble d'interfaces standards pour gérer et utiliser les ressources de colocalisation. Il existe de nombreux excellents projets dans la communauté, tels que le projet open source Koordinator d'Alibaba [2], le projet open source FinOps de Tencent Crane [3], le projet open source Katalyst de ByteDance [4], etc. Parmi eux, Koordinator a une adaptabilité « naturelle » avec le système d'exploitation Dragon Lizard (l'une des alternatives CentOS qu'iQiyi essaie) et peut collaborer pour réaliser une surveillance de la charge commerciale en ligne, un surengagement des ressources inutilisées, une planification hiérarchique des tâches et une garantie de qualité de service de la charge de travail hors ligne. , etc., répondent aux besoins d'iQiyi.
Sur la base de la sélection technologique ci-dessus, grâce à une transformation en profondeur, nous avons conteneurisé YARN NM et l'avons exécuté dans le pod K8, et pouvons détecter les ressources informatiques hyper-résolution changeantes de Koordinator en temps réel, réalisant ainsi une expansion et une contraction horizontales et verticales automatiques, et maximiser l’utilisation des ressources mixtes.
Evolution de la stratégie de planification colocalisée
La colocalisation du Big Data et du commerce en ligne a traversé plusieurs étapes d’évolution technologique, que nous présenterons en détail ci-dessous.
Étape 1 : Multiplexage en temps partagé la nuit
Afin de vérifier rapidement la solution, nous avons d'abord terminé la transformation de conteneurisation de NM sur le pod K8 (Koordinator n'a pas été utilisé à ce stade) et l'avons étendu au cluster Hadoop existant en tant que nœud élastique. Au niveau du Big Data, ces NM K8 sont planifiés uniformément par YARN avec les NM sur d'autres machines physiques. Ces nœuds élastiques démarrent et s'arrêtent régulièrement chaque jour et ne fonctionnent qu'entre 0 et 9 heures.
À ce stade, nous avons réalisé plus de 20 rénovations. Voici les 5 principaux points de rénovation :
Point d'amélioration 1 : Pool d'IP fixe
Le NM traditionnel est déployé sur une machine physique, et l'adresse IP et le nom de domaine de la machine sont fixes. La liste blanche des nœuds (fichier des esclaves) est configurée sur le YARN ResourceManager (ci-après dénommé « RM ») pour permettre au nœud de rejoindre le. grappe. Dans le même temps, le cluster YARN utilise Kerberos pour implémenter l'authentification de sécurité. Avant le déploiement, le fichier keytab doit être généré dans le KDC Kerberos et distribué au nœud NM.
Afin de nous adapter à la liste blanche et au mécanisme d'authentification de sécurité de YARN, nous utilisons la fonction IP statique auto-développée pour les clusters auto-construits. Chaque IP statique aura une ressource StaticIP K8s correspondante pour enregistrer la relation correspondante entre le pod et l'IP. temps, il est basé sur le cloud public. Nous déploierons également le CRD StaticIP auto-développé dans le cluster et créerons des ressources StaticIP pour chaque IP statique, fournissant ainsi à YARN un pool d'IP fixe qui a le même usage que le cluster auto-construit. . Créez à l'avance des enregistrements DNS et des fichiers keytab en fonction de l'adresse IP dans le pool d'adresses IP fixes, afin que la configuration requise puisse être rapidement obtenue au démarrage de NM.
Point de transformation 2 : opérateur Elastic YARN
Afin d'ignorer les utilisateurs de l'introduction des nœuds élastiques, nous avons ajouté Elastic NM au cluster Hadoop YARN existant. Compte tenu de la complexité des ressources dynamiques dans les déploiements mixtes ultérieurs, nous avons choisi l'opérateur Elastic YARN auto-développé pour mieux gérer le cycle de vie de la NM élastique.
À ce stade, les stratégies prises en charge par l'opérateur Elastic YARN sont :
-
按需启动:应对离线任务的突发流量,包括寒暑假、节假日、重要活动等场景
-
周期性上下线:利用在线服务每天凌晨的资源利用率低谷期,运行大数据任务
改造点 3:Node Label - 弹性与固定资源隔离
由于 Flink 等大数据实时流计算任务是 7x24 小时不间断常驻运行的,对 NM 的稳定性的要求比批处理更高,弹性 NM 节点的缩容或资源量调整会使得流计算任务重启,导致实时数据波动。为此,我们引入了 YARN Node Label 特性 [5],将集群分为固定节点(物理机 NM)和弹性节点(K8s NM)。批处理任务可以使用任意节点,流任务则只能使用固定节点运行。
此外,批处理任务容错的基础在于 YARN Application Master 的稳定性。我们的解决方案是,给 YARN 新增了一个配置,用于设置 Application Master 默认使用的 label,确保 Application Master 不被分配到弹性 NM 节点上。这一功能已经合并到社区:
YARN-11084
、
YARN-11088
。
改造点 4:NM Graceful Decommission
我们采用了弹性节点固定时间上下线,来对在离线资源进行削峰填谷。弹性 NM 的上线由 YARN Operator 来启动,一旦启动完成,任务就可被调度上。弹性 NM 的下线则略微复杂些,因为任务仍然运行在上面,我们需要尽可能保证任务在下线的时间区间内已经结束。
例如我们周期性部署策略为:0 - 8 点弹性 NM 上线,8 - 9 点为下线时间区间,9 - 24 点为节点离线状态。通过使用 YARN graceful decommission [6] 的机制,将增量 container 请求避免分配到 decommissioning 的节点上,在下线时间区间内等待任务缓慢结束即可。
但是在我们集群中,批处理任务大部分是 Spark 3.1.1 版本,因为 Spark 申请的 YARN container 是作为 task 的 executor 来使用,在大部分情况下,1 个小时的下线区间往往是不够的。因此我们引入了 SPARK-20624 的一系列优化 [7],通过 executor 响应 YARN decommission 事件来将 executor 尽可能快速退出。
改造点 5:引入 Remote Shuffle Service - Uniffle
Shuffle 作为离线任务中的重要一环,我们采用 Spark ESS on NodeManager 的部署模式。但在引入弹性节点后,因为弹性 NM 生命周期短,无法保证在 YARN graceful decommmission 的时间区间内,任务所在节点的 shuffle 数据被消费完,导致作业整体失败。
基于这一点,我们引入了 Apache Uniffle (incubating) [8] 实现 remote shuffle service 来解耦 Spark shuffle 数据与 NM 的生命周期,NM 被转变为单纯的计算,不存储中间 shuffle 数据,从而实现 NM 快速平滑下线。
另外一方面,弹性 NM 挂载的云盘性能一般,无法承载高 IO 和高并发的随机读写,同时也会对在线服务产生影响。通过独立构建高性能 IO 的 Uniffle 集群,提供更快速的 shuffle 服务。
爱奇艺作为 Uniffle 的深度参与者,贡献了 100+ 改进和 30+ 特性,包括 Spark AQE 优化 [9] 、Kerberos 的支持 [10] 和超大分区优化 [11] 等。
阶段二:资源超分
在阶段一,我们仅使用 K8s 资源池剩余未分配资源实现了初步的混部。为了最大限度地利用空闲资源,我们引入 Koordinator 进行资源的超分配。
我们对弹性 NM 的资源容量采用了固定规格限制:10 核 batch-cpu、30 GB batch-memory(batch-cpu 和 batch-memory 是 Koordinator 超分出来的扩展资源),NM 保证离线任务使用的资源总量不会超过这些限制。
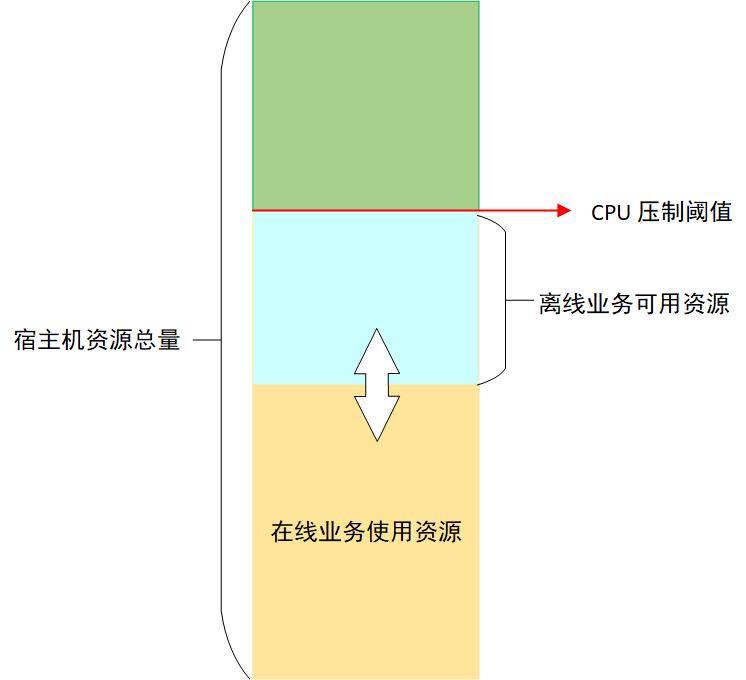
为了保证在线业务的稳定性,Koordinator 会对节点上离线任务能够使用的 CPU 进行压制 [12],压制结果由压制阈值和在线业务 CPU 实际用量(不是 request 请求)的差值决定,这个差值就是离线业务能够使用的最大 CPU 资源,由于在线业务 CPU 实际使用量不断变化,所以离线业务能够使用的 CPU 也在不断变化,如图 3 所示:
对离线任务的 CPU 压制保证了在线业务的稳定性,但是离线任务执行时间就会被拉长。如果某个节点上离线任务被压制程度比较严重,就可能会导致等待的发生,从而拖慢整体任务的运行速度。为了避免这种情况,Koordinator 提供了基于 CPU 满足度的驱逐功能 [13],当离线任务使用的 CPU 被压制到用户指定的满足度以下时,就会触发离线任务的驱逐。离线任务被驱逐后,可以调度到其他资源充足的机器上运行,避免等待。
在经过一段时间的测试验证后,我们发现在线业务运行稳定,集群 CPU 7 天平均利用率提升了 5%。但是节点上的 NM Pod 被驱逐的情况时有发生。NM 被驱逐之后,RM 不能及时感知到驱逐情况的发生,会导致失败的任务延迟重新调度。为了解决这个问题,我们开发了 NM 动态感知节点离线 CPU 资源的功能。
阶段三:从夜间分时复用到全天候实时弹性
与其触发 Koordinator 的驱逐操作,不如让 NM 主动感知节点上离线资源的变化,在离线资源充足时,调度较多任务,离线资源不足时,停止调度任务,甚至主动杀死一些离线 container 任务,避免 NM 被 Koordinator 驱逐。
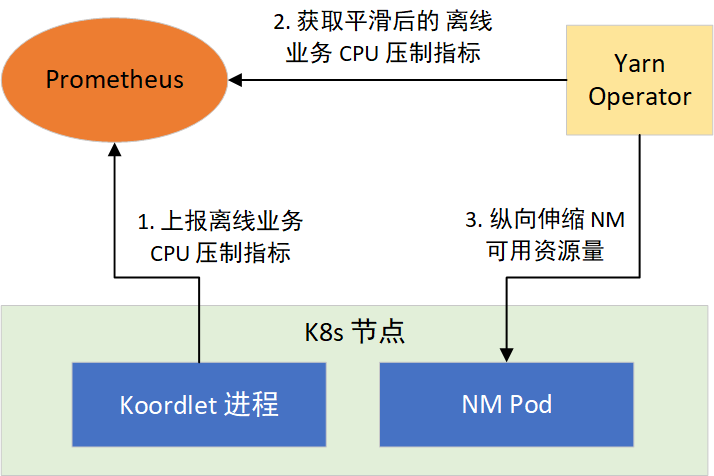
根据这个思路,我们通过 YARN Operator 动态感知节点所能利用的资源,来纵向伸缩 NM 可用资源量。分两步实现:1)提供离线任务 CPU 压制指标;2)让 NM 感知 CPU 压制指标,采取措施。如图 4 所示:
CPU 压制指标
Koordinator 的 Koordlet 组件,运行于 K8s 的节点上,负责执行离线任务 CPU 压制、Pod 驱逐等操作,它以 Prometheus 格式提供了 CPU 压制指标,经过采集后就可以通过 Prometheus 对外提供。CPU 压制指标默认每隔 1 秒更新 1 次,会随着在线业务负载的变化而变化,波动较大。而 Prometheus 的指标抓取周期一般都大于 1 秒,这会造成部分数据的丢失,为了平滑波动,我们对 Koordlet 进行了修改,提供了 1 min、5 min、10 min CPU 压制指标的均值、方差、最大值和最小值等指标供 NM 选择使用。
YARN Operator 动态感知和纵向伸缩
在 NM 常驻的部署模式下,YARN Operator 提供了新的策略。通过在 YARN Operator 接收到当前部署的节点 10 min 内可利用的资源指标,用来决策是否对所在宿主机上的 NM 进行纵向伸缩。
对于扩容,一旦超过 3 核,则向 RM 进行节点的资源更新。扩容过程如图 5 所示:
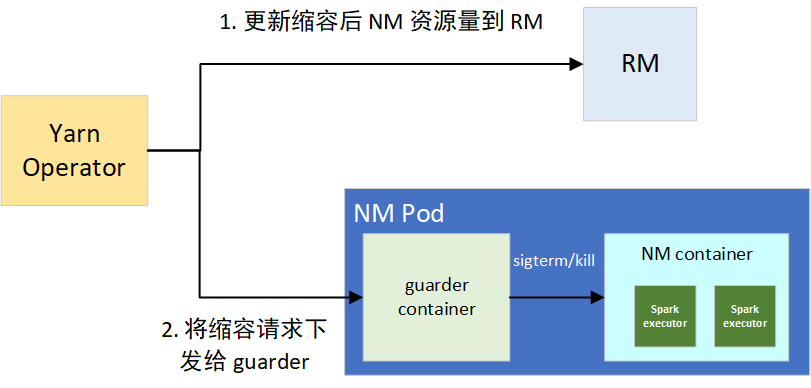
缩容的话,如果抑制率控制在 10% 以内的波动,我们默认忽略。一旦超过阈值,则会触发缩容操作,分为两个步骤:1)更新节点在 RM 上的可用资源,用来堵住增量的 container 分配需求;2)将缩容请求下发给 NM 的 guarder sidecar 容器,来对部分资源超用的 container 的平滑和强制下线,避免因占用过多 CPU 资源导致整个 NM 被驱逐。
guarder 在拿到目标可用资源后,会对当前所有的 YARN container 进程进行排序,包括框架类型、运行时长、资源使用量三者,决策拿到要 kill 的进程。在 kill 前,会进行 SIGPWR 信号的发送,用来平滑下线任务,Spark Executor 接收到此信号,会尽可能平滑退出。缩容过程如图 6 所示:
通常节点的资源量变动幅度不是很大,且 NM 可使用的资源量维持在较高的水平(平均有 20 core),部分 container 的存活周期为 10 秒级,因此很快就能降至目标可用资源量值。涉及到变动幅度频繁的节点,通过 guarder 的平滑下线和 kill 决策,container 失败数非常低,从线上来看,按天统计平均 force kill container 数目为 5 左右,guarder 发送的平滑下线信号有 500+,可以看到效果比较好。
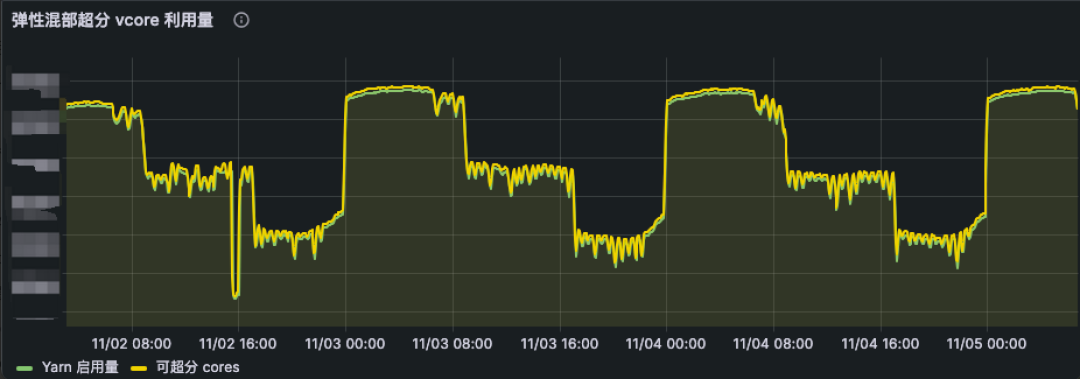
在离线 CPU 资源感知功能全面上线后,NM Pod 被驱逐的情况基本消失。因此,我们逐步将混部时间由凌晨的 0 点至 8 点,扩展到全天 24h 运行,并根据在线业务负载分布情况,在一天的不同时段采用不同的 CPU 资源超分比,从而实现全天候实时弹性调度策略。伴随着全天 24h 的稳定运行,集群 CPU 利用率再度提升了 10%。从线上混部 K8s 集群来看(如图 7 所示),弹性 NM 的 vcore 使用资源量(绿线)也是动态贴合可超分的资源(黄线)。
阶段四:提升资源超分率
为了提供更多的离线资源,我们开始逐步调高 CPU 资源的超分比,而 NM Pod 被驱逐的情况再次发生了,这一次的原因是内存驱逐。我们将物理机器的内存超分比设置为 90%,从集群总体情况看,物理机器上的内存资源比较充足,刚开始我们只关注了 CPU 资源,没有关注内存资源。而 NM 的 CPU 和内存按照 1:4 的比例来使用,随着 CPU 超分比的提高,YARN 任务需要的内存也在提升,最终当 K8s 节点内存使用量超过设定的阈值时,就会触发 Koordinator 的驱逐操作。
经过观察,我们发现内存驱逐在某些节点上发生的概率特别高,这些节点的内存比其他节点内存小,而 CPU 数量是相同的,因此这些节点在 CPU 超分比相同的情况下,更容易因为内存原因被驱逐,它们能提供的离线内存更少。因此,guarder 容器也需要感知节点的离线内存资源用量,并根据资源用量采取相应的措施,这个过程与 CPU 离线资源的感知一样的,不再赘述。
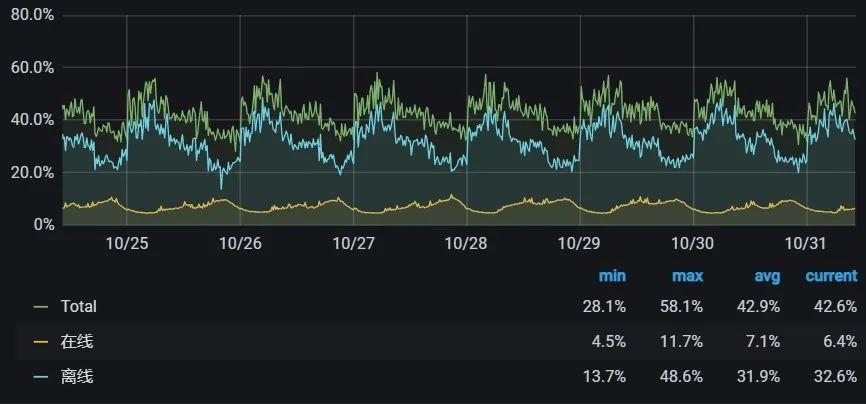
内存感知功能上线后,我们又逐步提升了 CPU 的超分比,当前在线业务集群的 CPU 利用率已经提升到全天平均 40%+、夜间 58% 左右。
效果
通过大数据离线计算与在线业务的混部,我们将在线业务集群 CPU 平均利用率从 9% 提升到 40%+,在不增加机器采购的同时满足了部分大数据弹性计算的资源需求,每年节省数千万元成本。
同时,我们也将这套框架应用到大数据 OLAP 分析场景,实现了 Impala/Trino on K8s 弹性架构,满足数据分析师日常动态查询需求,支持了寒暑假、春晚直播、广告 618 与双 11 等重要活动期间临时大批量资源扩容需求,保障了广告、BI、会员等数据分析场景的稳定、高效。
未来计划
当前,大数据离在线混部已稳定运行一年多,并取得阶段性成果,未来我们将基于这套框架进一步推进大数据云原生化:
-
完善离在线混部可观测性:建立精细化的 QoS 监控,保障在线服务、大数据弹性计算任务的稳定性。
-
加大离在线混部力度:K8s 层面,继续提高宿主机资源利用率,提供更多的弹性计算资源供大数据使用。大数据层面,进一步提升通过离在线混部框架调度的弹性计算资源占比,节省更多成本。
-
大数据混合云计算:目前我们主要使用爱奇艺内部的 K8s 进行混部,随着公司混合云战略的推进,我们计划将混部推广到公有云 K8s 集群中,实现大数据计算的多云调度。
-
探索云原生的混部模式:尽管复用 YARN 的调度器能让我们快速利用混部资源,但它也带来了额外的资源管理和调度开销。后续我们也将探索云原生的混部模式,尝试将大数据的计算任务直接使用 K8s 的离线调度器进行调度,进一步优化调度速度和资源利用率。
参考资料
[1] 一文看懂业界在离线混部技术. https://www.infoq.cn/article/knqswz6qrggwmv6axwqu
[2] Koordinator: QoS-based Scheduling for Colocating on Kubernetes. https://koordinator.sh/
[3] Crane: Cloud Resource Analytics and Economics in Kubernetes clusters. https://gocrane.io/
[4] Katalyst: a universal solution to help improve resource utilization and optimize the overall costs in the cloud. https://github.com/kubewharf/katalyst-core
[5] Apache Hadoop YARN - Node Labels. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
[6] Apache Hadoop YARN - Graceful Decommission of YARN Nodes. https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html
[7] Apache Spark - Add better handling for node shutdown. https://issues.apache.org/jira/browse/SPARK-20624
[8] Apache Uniffle: Remote Shuffle Service. https://uniffle.apache.org/
[9] Apache Uniffle - Support getting memory data skip by upstream task ids. https://github.com/apache/incubator-uniffle/pull/358
[10] Apache Uniffle - Support storing shuffle data to secured dfs cluster. https://github.com/apache/incubator-uniffle/pull/53
[11] Apache Uniffle - Huge partition optimization. https://github.com/apache/incubator-uniffle/issues/378
[12] Koordinator - CPU Suppress. https://koordinator.sh/docs/user-manuals/cpu-suppress/
[13] Koordinator - Eviction Strategy based on CPU Satisfaction. https://koordinator.sh/docs/user-manuals/cpu-evict/

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。