
Cet article est basé sur un discours prononcé par Shao Wei, ingénieur R&D senior de Volcano Engine, lors de la conférence QCon Global Software Development. Intervenant|Heure du discours de Shao Wei|QCon Guangzhou en mai 2023
PPT | Katalyst : Pratique d'optimisation des coûts natifs de ByteDance Cloud
1. Origines
Byte a commencé à transformer ses services en services cloud natifs depuis 2016. À l'heure actuelle, le système de services de Byte comprend principalement quatre catégories : les microservices traditionnels sont principalement des services Web RPC basés sur Golang ; exigences; en plus Il existe également des services d'apprentissage automatique, de Big Data et de stockage .
Le problème principal qui doit être résolu après le cloud natif est de savoir comment améliorer l'efficacité de l'utilisation des ressources du cluster ; en prenant comme exemple l'utilisation des ressources d'un service en ligne typique, la partie bleu foncé est la quantité de ressources réellement utilisées par l'entreprise. , et la partie bleu clair est le tampon de sécurité fourni par le domaine d'activité, même si la zone tampon est augmentée, de nombreuses ressources ont encore été demandées mais non utilisées par l'entreprise. L’objectif d’optimisation est donc d’utiliser autant que possible ces ressources inutilisées d’un point de vue architectural.
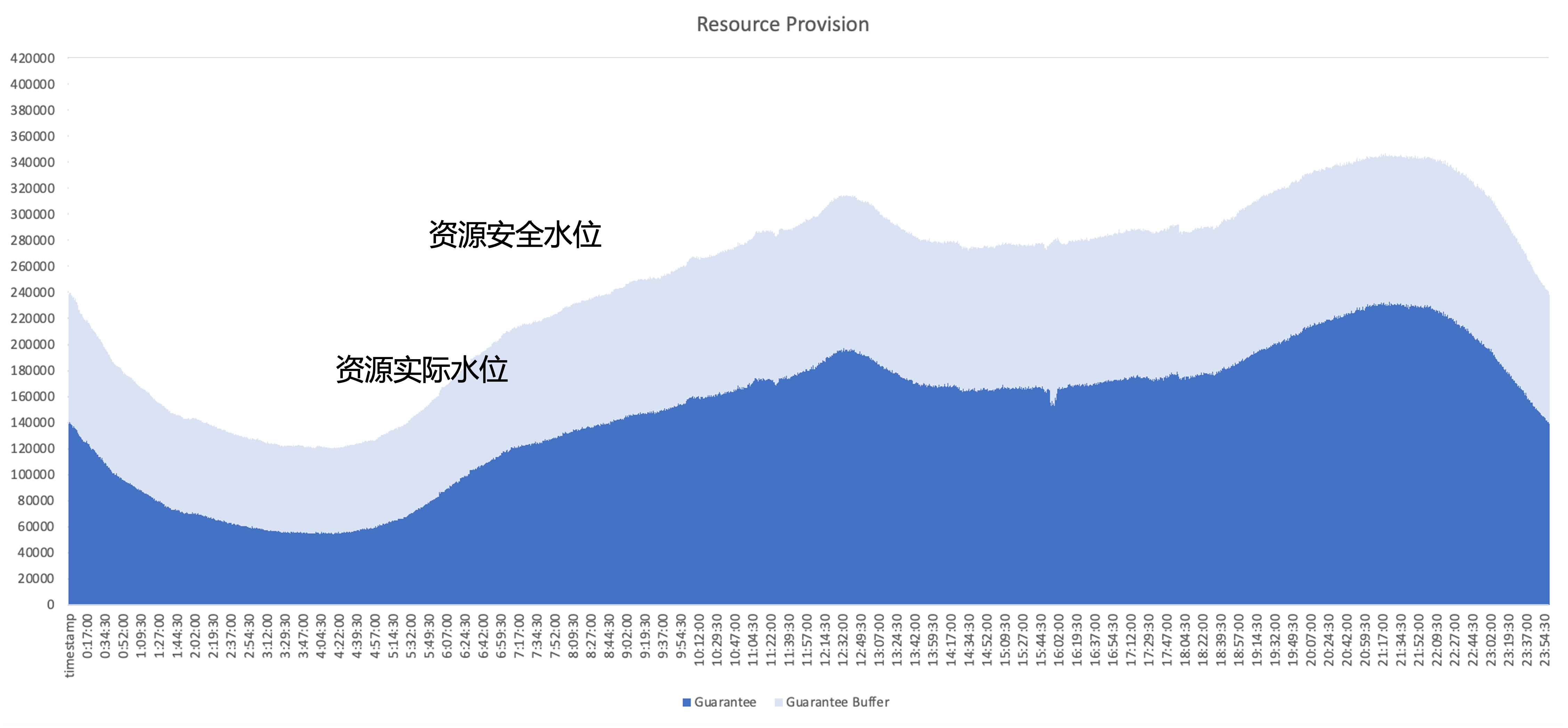
plan de gestion des ressources
Byte a essayé plusieurs types de solutions de gestion des ressources en interne, notamment
- Exploitation des ressources : aider régulièrement l'entreprise à gérer l'état d'utilisation des ressources et à promouvoir la gestion des applications de ressources. Le problème est que la charge d'exploitation et de maintenance est lourde et que le problème d'utilisation ne peut pas être résolu.
- Surréservation dynamique : évaluez la quantité de ressources commerciales côté système et réduisez de manière proactive le quota. Le problème est que la stratégie de surréservation n'est pas nécessairement précise et peut entraîner un risque.
- Mise à l'échelle dynamique : le problème est que si vous ciblez uniquement la mise à l'échelle des services en ligne, étant donné que les pics et les creux du trafic dans les services en ligne sont similaires, vous ne pourrez pas améliorer pleinement l'utilisation tout au long de la journée.
Par conséquent, en fin de compte, Byte adopte un déploiement hybride, fonctionnant simultanément en ligne et hors ligne sur le même nœud, exploitant pleinement les caractéristiques complémentaires entre les ressources en ligne et hors ligne pour obtenir une meilleure utilisation des ressources. Nous espérons finalement obtenir l'effet suivant : , c'est-à-dire que les ventes secondaires se font en ligne. Les ressources inutilisées peuvent être bien remplies par des charges de travail hors ligne afin de maintenir l'efficacité de l'utilisation des ressources à un niveau élevé tout au long de la journée.
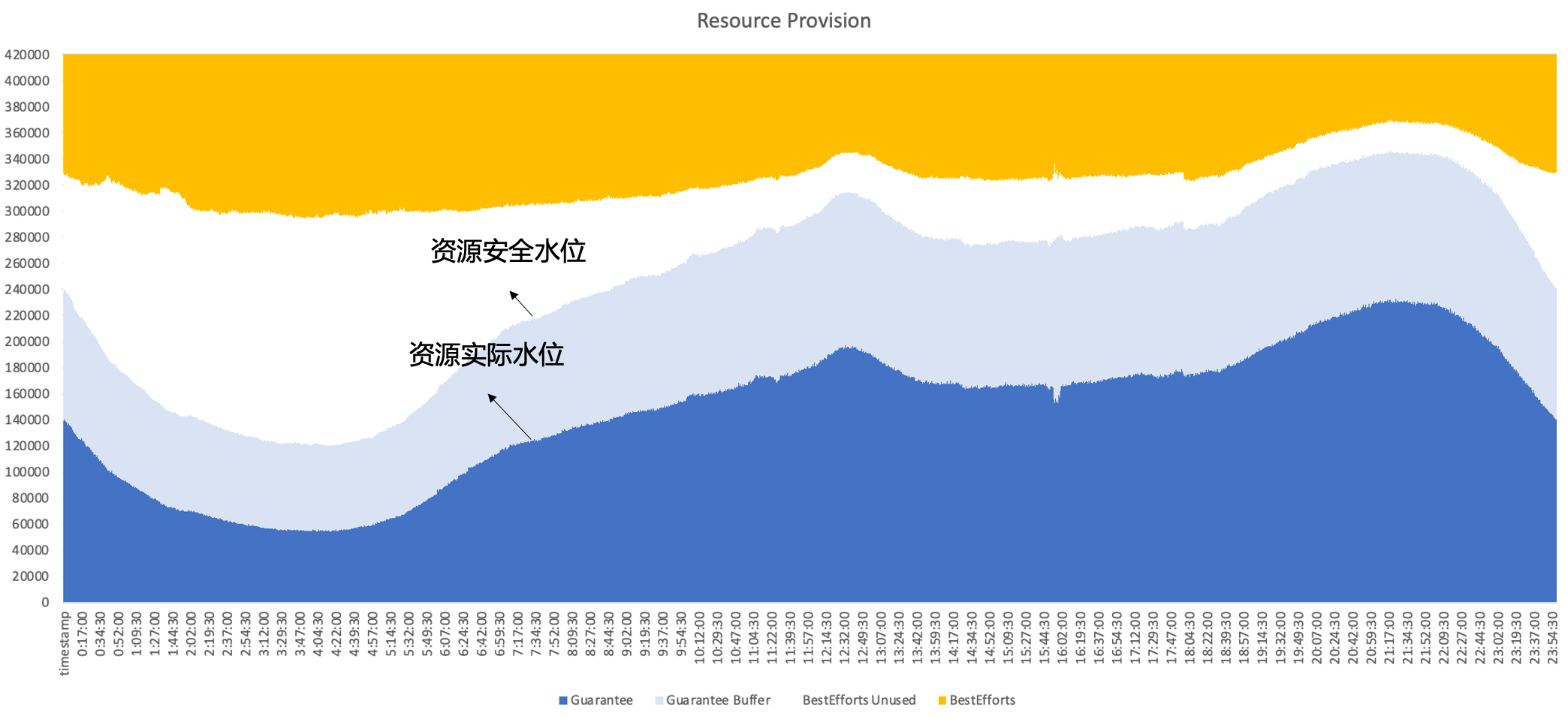
2. Historique de développement du déploiement hybride d'octets
À mesure que Byte Cloud devient natif, nous choisissons des solutions de déploiement hybride appropriées en fonction des besoins commerciaux et des caractéristiques techniques à différentes étapes, et continuons à itérer notre système hybride au cours du processus.
2.1 Phase 1 : Mixage en temps partagé hors ligne
La première étape concerne principalement le déploiement hybride en temps partagé en ligne et hors ligne.
- En ligne : à ce stade, nous avons construit une plate-forme d'élasticité des services en ligne. Les utilisateurs peuvent configurer des règles de mise à l'échelle horizontale basées sur des indicateurs commerciaux ; par exemple, si le trafic professionnel diminue tôt le matin et que l'entreprise réduit de manière proactive certaines instances, le système exécutera des ressources. bing emballage sur la base du retrait de l'instance. Cela libère toute la machine ;
- Pour hors ligne : à ce stade, les services hors ligne peuvent obtenir un grand nombre de ressources de type spot, et parce que leur approvisionnement est instable, ils peuvent en même temps bénéficier d'une certaine réduction sur le coût, pour la vente en ligne de ressources inutilisées vers hors ligne ; obtenir une certaine remise sur le coût.
L'avantage de cette solution est qu'elle ne nécessite pas de mécanisme complexe d'isolation côté machine unique et que la mise en œuvre technique est relativement faible. Cependant, elle présente également certains problèmes, tels que :
- L'efficacité de la conversion n'est pas élevée et des problèmes tels que la fragmentation peuvent survenir pendant le processus de bing packaging ;
- L'expérience hors ligne peut ne pas être bonne non plus. Lorsque le trafic en ligne fluctue occasionnellement, l'utilisateur hors ligne peut être tué de force, ce qui entraîne de fortes fluctuations des ressources.
- Cela entraînera des changements d'instance dans l'entreprise. Dans les opérations réelles, l'entreprise configure généralement une politique élastique relativement conservatrice, ce qui se traduit par une limite supérieure basse pour l'amélioration des ressources.
2.2 Phase 2 : Déploiement conjoint Kubernetes/YARN
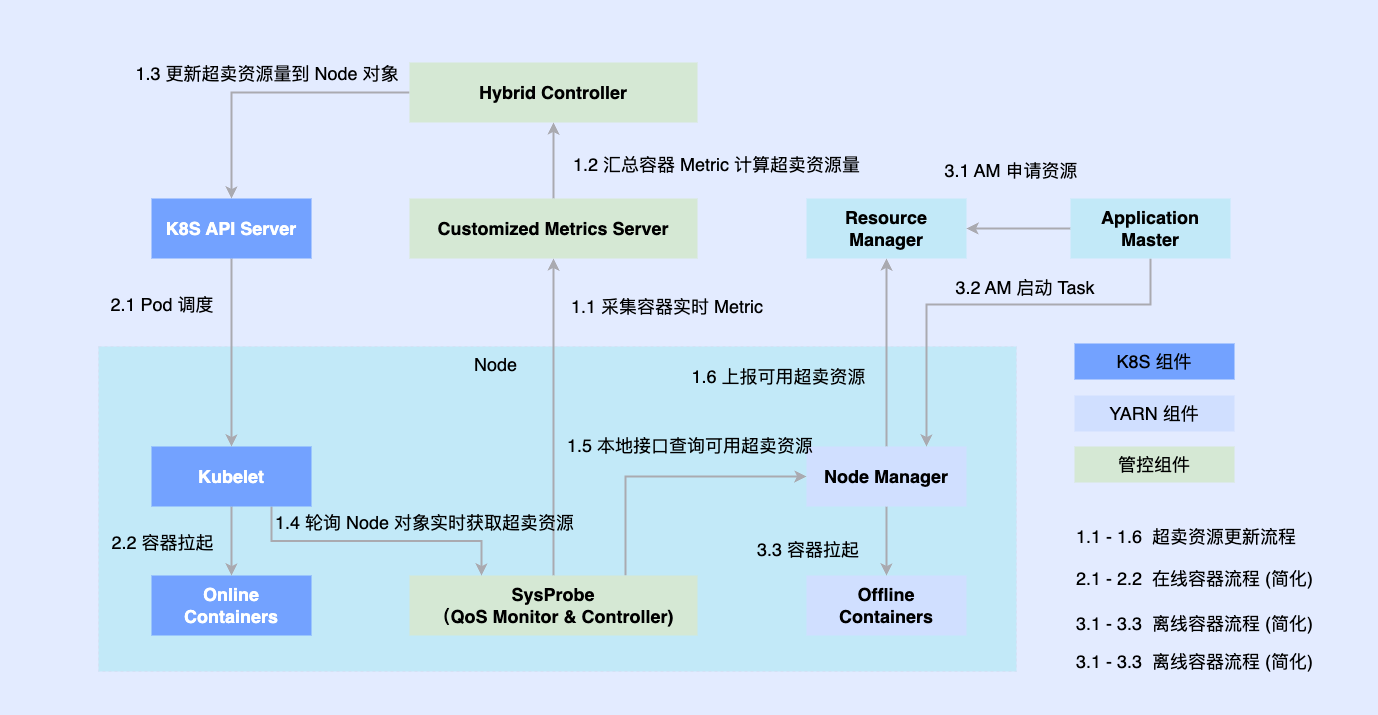
Afin de résoudre les problèmes ci-dessus, nous sommes entrés dans la deuxième étape et avons essayé de fonctionner hors ligne et en ligne sur un seul nœud.
Étant donné que la partie en ligne a été transformée nativement sur la base de Kubernetes plus tôt, la plupart des tâches hors ligne sont toujours exécutées sur la base de YARN. Afin de promouvoir le déploiement hybride, nous introduisons des composants tiers sur une seule machine pour déterminer la quantité de ressources coordonnées en ligne et hors ligne, et les connectons simultanément à des composants autonomes tels que Kubelet ou Node Manager ; Les charges de travail en ligne et hors ligne sont planifiées sur les nœuds, elles sont également coordonnées par Le composant de coordination met à jour de manière asynchrone les allocations de ressources pour les deux charges de travail.
Ce plan nous permet de compléter l'accumulation de réserves de capacités de colocalisation et d'en vérifier la faisabilité, mais il reste encore quelques problèmes.
- Les deux systèmes sont exécutés de manière asynchrone, de sorte que le conteneur hors ligne ne peut que contourner la gestion et le contrôle, et il y a une course et il y a trop de perte de ressources dans les liens intermédiaires ;
- La simple abstraction des charges de travail hors ligne nous empêche de décrire des exigences complexes en matière de QoS.
- La fragmentation des métadonnées hors ligne rend difficile une optimisation extrême et ne permet pas d'optimiser la planification globale.
2.3 Phase 3 : Planification unifiée et déploiement mixte hors ligne
Afin de résoudre les problèmes de la deuxième étape, dans la troisième étape, nous avons complètement réalisé un déploiement hybride hors ligne unifié.
En rendant les tâches hors ligne natives du cloud, nous permettons de les planifier et de gérer leurs ressources sur la même infrastructure. Dans ce système, la couche supérieure est une fédération de ressources unifiée pour réaliser une gestion des ressources multicluster. Dans un seul cluster, il existe un planificateur unifié central et un gestionnaire de ressources unifié autonome. Ils travaillent ensemble pour obtenir des capacités de gestion des ressources intégrées hors ligne. .
Dans cette architecture, Katalyst sert de couche principale de gestion et de contrôle des ressources et est responsable de la réalisation de l'allocation et de l'estimation des ressources en temps réel côté machine unique.
- Standardisation de l'abstraction : ouvrez les métadonnées hors ligne, rendez l'abstraction de la QoS plus complexe et plus riche et répondez mieux aux exigences de performances de l'entreprise ;
- Synchronisation de gestion et de contrôle : la politique de gestion et de contrôle est émise au démarrage du conteneur pour éviter la correction asynchrone des ajustements de ressources après le démarrage, tout en prenant en charge l'expansion libre de la politique ;
- Stratégie intelligente : en créant des portraits de services, vous pouvez détecter à l'avance les demandes en ressources et mettre en œuvre des stratégies de gestion et de contrôle des ressources plus intelligentes ;
- Automatisation de l'exploitation et de la maintenance : grâce à la livraison intégrée, l'automatisation et la standardisation de l'exploitation et de la maintenance sont obtenues.
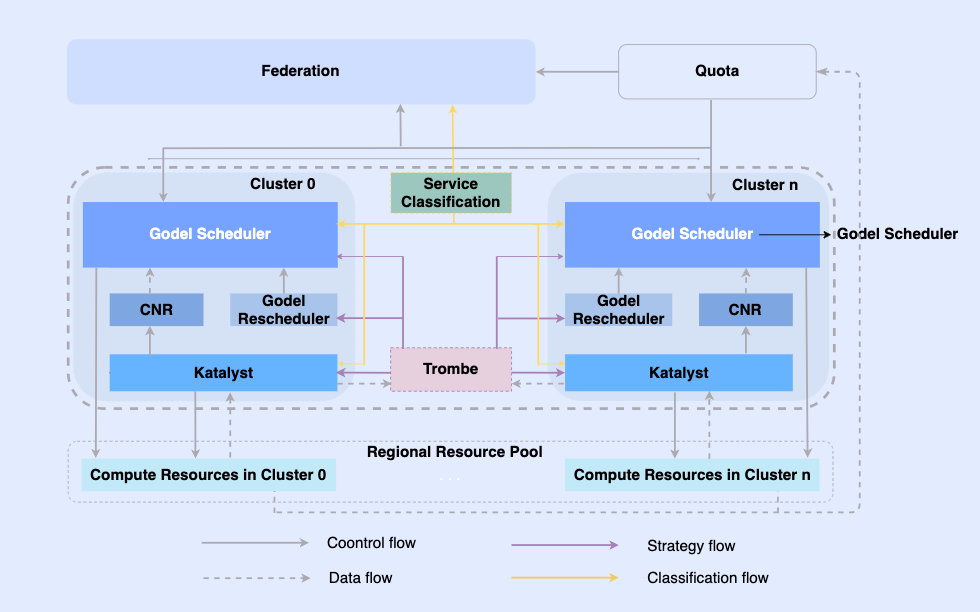
3. Introduction du système Katalyst
Katalyst est dérivé du mot anglais catalyseur, qui signifie à l'origine catalyseur. La première lettre est remplacée par K, ce qui signifie que le système peut fournir des capacités de gestion automatisée des ressources plus puissantes pour toutes les charges exécutées dans le système Kubernetes.
3.1 Présentation du système Katalyst
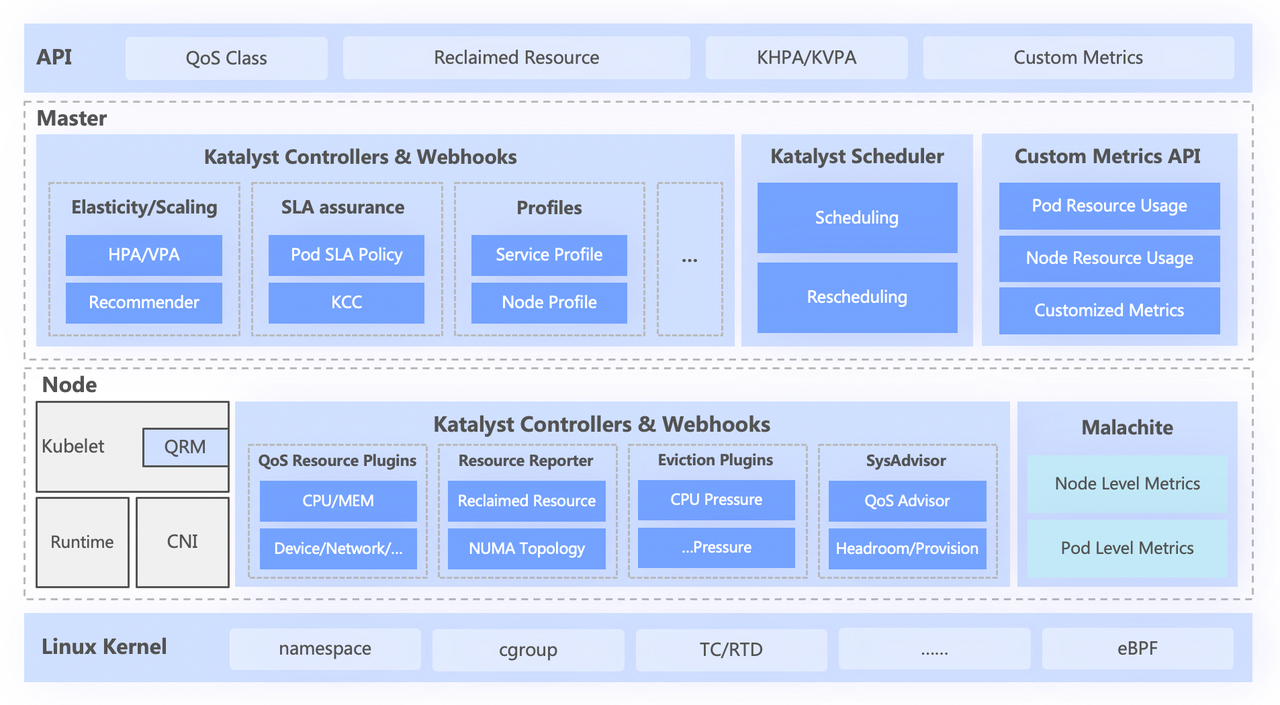
Le système Katalyst est grossièrement divisé en quatre couches, dont
- L'API standard de haut niveau résume différents niveaux de QoS pour les utilisateurs et fournit de riches capacités d'expression de ressources ;
- La couche centrale est responsable des fonctionnalités de base telles que la planification unifiée, la recommandation de ressources et la création de portraits de services ;
- La couche autonome comprend un système de surveillance des données auto-développé et un répartiteur de ressources responsable de l'allocation en temps réel et de l'ajustement dynamique des ressources ;
- La couche inférieure est un noyau personnalisé en octets, qui résout le problème des performances d'une seule machine lors de l'exécution hors ligne en améliorant le correctif du noyau et le mécanisme d'isolation sous-jacent.
3.2 Normalisation abstraite : classe QoS
La qualité de service de Katalyst peut être interprétée d'un point de vue macro et micro.
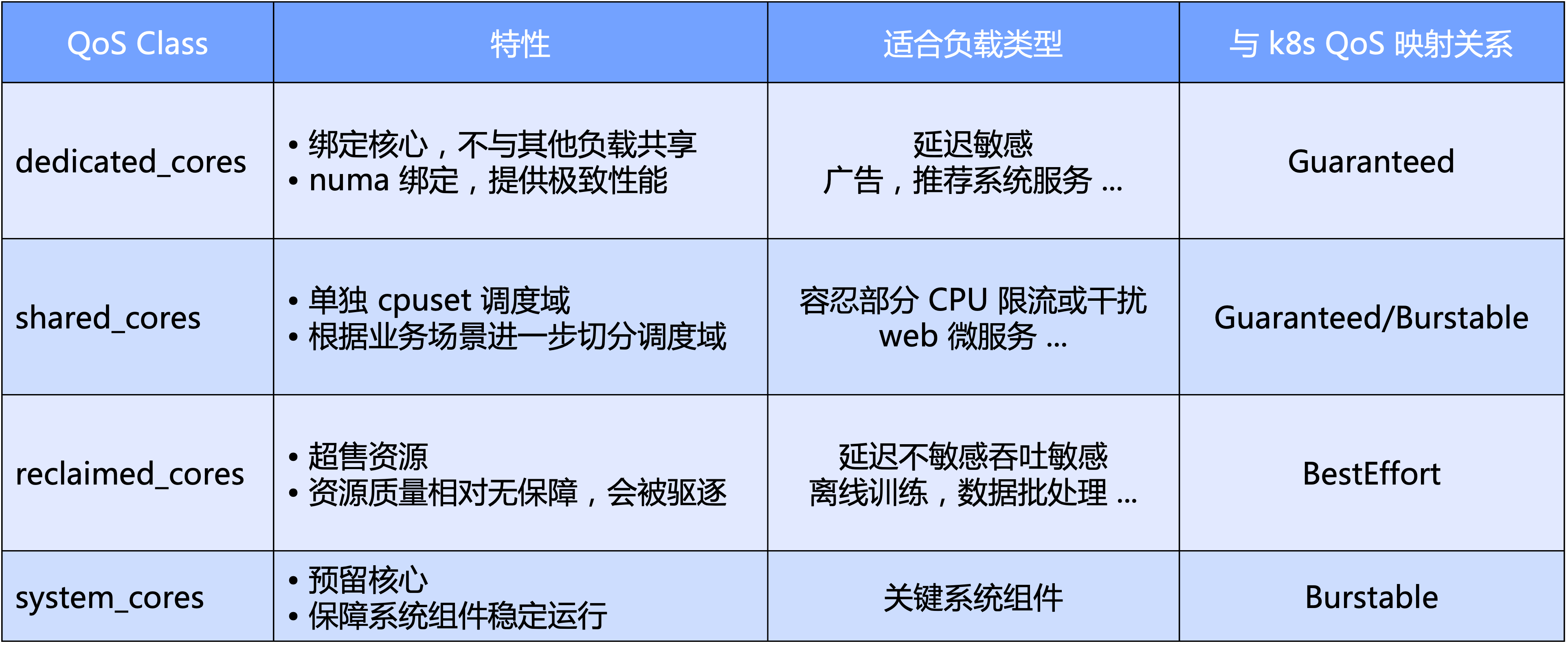
- Au niveau macro, Katalyst définit les niveaux de QoS standard basés sur la dimension principale du processeur ; plus précisément, nous divisons la QoS en quatre catégories : exclusive, partagée, recyclage et type de système réservé aux composants clés du système ;
- D'un point de vue micro, l'attente finale de Katalyst est que quel que soit le type de charge de travail, elle puisse être exécutée dans un pool sur le même nœud sans qu'il soit nécessaire d'isoler le cluster par une coupe dure, obtenant ainsi une meilleure efficacité du trafic et une meilleure utilisation des ressources. efficacité.
Sur la base de la QoS, Katalyst fournit également une multitude d'améliorations d'extension pour exprimer d'autres besoins en ressources en plus des cœurs de processeur.
- Amélioration de la qualité de service : expression étendue des exigences commerciales pour les ressources multidimensionnelles telles que la liaison NUMA/carte réseau, l'allocation de bande passante de la carte réseau, la pondération des E/S, etc.
- Amélioration des pods : étend l'expression de la sensibilité de l'entreprise à divers indicateurs du système, tels que l'impact du retard de planification du processeur sur les performances de l'entreprise.
- Amélioration des nœuds : exprimez les exigences combinées de la micro-topologie parmi plusieurs dimensions de ressources en étendant la TopologyPolicy native.
3.3 Synchronisation de gestion et de contrôle : QoS Resource Manager
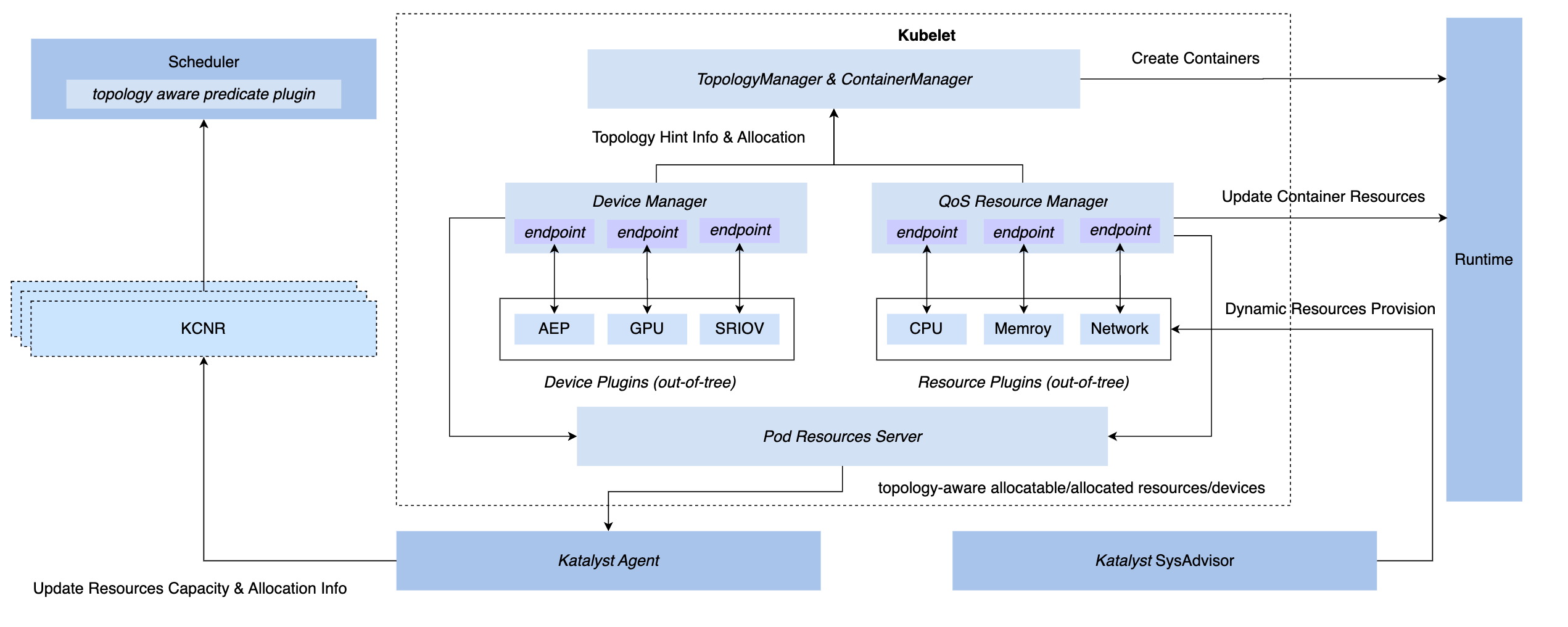
Afin d'obtenir des capacités de gestion et de contrôle synchrones sous le système K8s, nous disposons de trois méthodes de hook : l'insertion de la couche CRI, la couche OCI et la couche Kubelet. En fin de compte, Katalyst a choisi d'implémenter la gestion et le contrôle côté Kubelet, c'est-à-dire. pour implémenter un gestionnaire de ressources QoS au même niveau que le gestionnaire de périphériques natif. Les avantages de ce programme incluent.
- Mettez en œuvre l’interception pendant la phase d’admission, éliminant ainsi le besoin de recourir à des mesures secrètes pour obtenir le contrôle lors des étapes suivantes.
- Connectez les métadonnées à Kubelet, rapportez les informations de microtopologie d'une seule machine au nœud CRD via une interface standard et réalisez l'amarrage avec le planificateur.
- Sur la base de ce cadre, des plugins enfichables peuvent être implémentés de manière flexible pour répondre à des besoins personnalisés de gestion et de contrôle.
3.4 Stratégie intelligente : portrait des services et estimation des ressources
Habituellement, il est plus intuitif de choisir d'utiliser des indicateurs métier pour dresser un portrait du service, tels que le délai P99 du service ou le taux d'erreur en aval. Mais il y a aussi quelques problèmes.Par exemple, par rapport aux indicateurs système, il est généralement plus difficile d'obtenir des indicateurs commerciaux ; les entreprises intègrent généralement plusieurs cadres, et la signification des indicateurs commerciaux qu'elles produisent n'est pas exactement la même. Si l'on s'appuie fortement sur ces indicateurs, l'ensemble de la mise en œuvre du contrôle deviendra très compliqué.
Par conséquent, nous espérons que le contrôle final des ressources ou le portrait du service sera basé sur des indicateurs système plutôt que sur des indicateurs commerciaux ; le plus critique est de savoir comment trouver les indicateurs système qui préoccupent le plus l'entreprise. Notre approche consiste à utiliser un ensemble d'indicateurs hors ligne. pipelines pour découvrir les indicateurs commerciaux et les indicateurs système. Par exemple, pour le service illustré, l'indicateur principal de l'activité est le délai P99. Grâce à l'analyse, il s'avère que l'indicateur système avec la corrélation la plus élevée est le délai de planification du processeur. Nous continuerons d'ajuster l'offre de ressources du service pour nous en rapprocher. son objectif autant que possible.
Sur la base de portraits de services, Katalyst fournit de riches mécanismes d'isolation pour le processeur, la mémoire, le disque et le réseau, et personnalise le noyau si nécessaire pour fournir des exigences de performances plus élevées. Toutefois, pour différents scénarios et types d'entreprise, ces moyens ne sont pas nécessairement applicables. il faut souligner que l'isolement est plus un moyen qu'une fin. Dans le processus d'entreprise, nous devons choisir différentes solutions d'isolement en fonction de besoins et de scénarios spécifiques.
3.5 Automatisation de l'exploitation et de la maintenance : gestion de configuration dynamique multidimensionnelle
Bien que nous espérons que toutes les ressources se trouvent sous un système de pool de ressources, dans un environnement de production à grande échelle, il est impossible de placer tous les nœuds dans un cluster. De plus, un cluster peut avoir à la fois des machines CPU et GPU, bien que le plan de contrôle puisse le faire. être partagé, mais une certaine isolation est requise sur le plan de données ; au niveau du nœud, nous devons souvent modifier la configuration des dimensions du nœud pour la vérification en niveaux de gris, ce qui entraîne des différences dans les SLO des différents services exécutés sur le même nœud.
Pour résoudre ces problèmes, nous devons considérer l'impact des différentes configurations de nœuds sur les services lors du déploiement métier. À cette fin, Katalyst fournit des capacités de gestion de configuration dynamique pour une livraison standard, évaluant les performances et la configuration des différents nœuds via des méthodes automatisées et sélectionnant le nœud le plus approprié pour le service en fonction de ces résultats.
4. Application de colocalisation Katalyst et analyse de cas
Dans cette section, nous partagerons quelques bonnes pratiques basées sur des cas internes de Byte.
4.1 Effet d'utilisation
En termes d'effets de mise en œuvre de Katalyst, sur la base des pratiques commerciales internes de Byte, nos ressources peuvent être maintenues à un état relativement élevé au cours du cycle trimestriel ; dans un seul cluster, l'utilisation des ressources montre également un niveau relativement élevé à différentes périodes de chaque jour. Distribution stable ; dans le même temps, l'utilisation de la plupart des machines du cluster est également relativement concentrée et notre système de déploiement hybride fonctionne de manière relativement stable sur tous les nœuds.
| Algorithme de prévision des ressources | Ratio de ressources récupérées | Utilisation moyenne du processeur au niveau journalier | Utilisation maximale du processeur au niveau journalier |
|---|---|---|---|
| Utilisation du tampon fixe | 0,26 | 0,33 | 0,58 |
| algorithme de clustering k-means | 0,35 | 0,48 | 0,6 |
| Algorithme PID de l'indicateur système | 0,39 | 0,54 | 0,66 |
| Estimation du modèle d'indicateur système + algorithme PID | 0,42 | 0,57 | 0,67 |
4.2 Pratique : accès insensé hors ligne
Après être entré dans la troisième étape, nous devons effectuer la transformation cloud native hors ligne. Il existe deux méthodes principales de transformation : l'une concerne les services déjà présents dans le système K8s. Nous connecterons directement le pool de ressources basé sur Virtual Kubelet. L'autre concerne les services sous l'architecture YARN si le service est directement connecté au système Kubernetes. Une transformation complète du framework sera très coûteuse pour l'entreprise et conduira théoriquement à des mises à niveau progressives pour toutes les entreprises. Ce n'est évidemment pas un état idéal.
Afin de résoudre ce problème, Byte fait référence à la couche de colle de Yodel, c'est-à-dire que l'accès métier utilise toujours l'API Yarn standard, mais dans cette couche de colle, nous allons nous interfacer avec la sémantique K8 sous-jacente et résumer la demande de ressources de l'utilisateur dans quelque chose comme Pod ou Description du conteneur. Cette méthode nous permet d'utiliser une technologie K8 plus mature au niveau inférieur pour gérer les ressources, réaliser une transformation cloud native hors ligne et en même temps assurer la stabilité de l'entreprise.
4.3 Pratique : Gouvernance de l'exploitation des ressources
Au cours du processus de colocalisation, nous devons adapter et transformer le cadre de big data et de formation, et effectuer diverses tentatives, points de contrôle et évaluations pour nous assurer qu'après avoir réduit ces tâches de big data et de formation à l'ensemble du pool de ressources de colocalisation, L'expérience de leur utilisation n'est pas trop mauvaise.
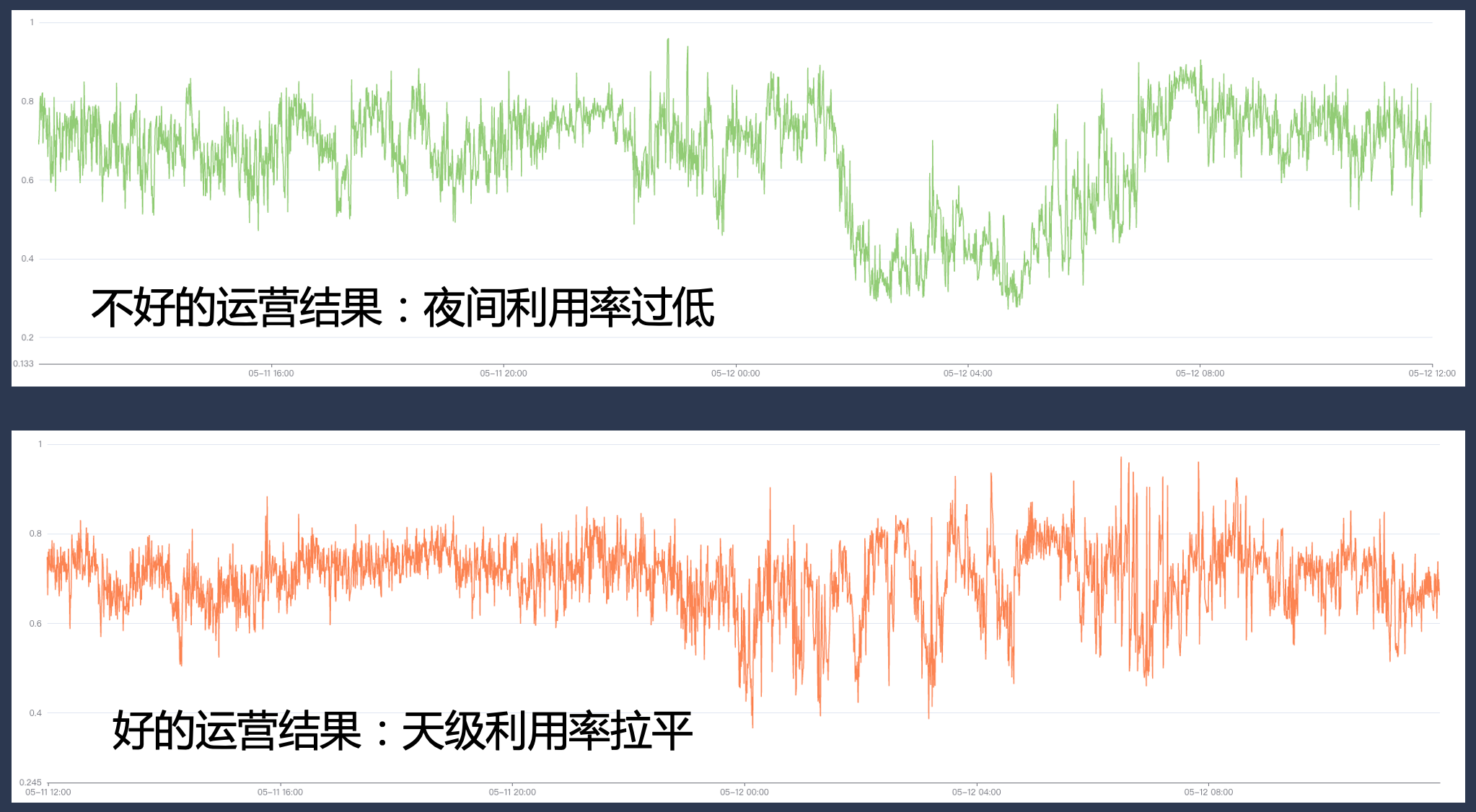
Dans le même temps, nous devons disposer de capacités de base complètes dans le système en matière de ressources, de classification des entreprises, de gouvernance opérationnelle et de gestion des quotas. Si l'opération n'est pas bien menée, le taux d'utilisation peut être très élevé pendant certaines périodes de pointe, mais il peut y avoir un déficit de ressources important pendant d'autres périodes, ce qui fait que le taux d'utilisation ne répond pas aux attentes.
4.4 Pratique : Maximiser l'amélioration de l'efficacité des ressources
Lors de l'élaboration de portraits de services, nous utilisons des indicateurs système pour la gestion et le contrôle. Cependant, les indicateurs système statiques basés sur une analyse hors ligne ne peuvent pas suivre les changements du côté commercial en temps réel. Il est nécessaire d'analyser les changements dans les performances de l'entreprise sur une certaine période. il est temps d’ajuster les valeurs statiques.
À cette fin, Katalyst introduit des modèles pour affiner les métriques du système. Par exemple, si nous pensons que le délai de planification du processeur peut être de x millisecondes et qu'après un certain temps, nous calculons via le modèle que le délai de l'objectif commercial peut être de y millisecondes, nous pouvons ajuster dynamiquement la valeur de la cible pour mieux évaluer performance de l'entreprise.
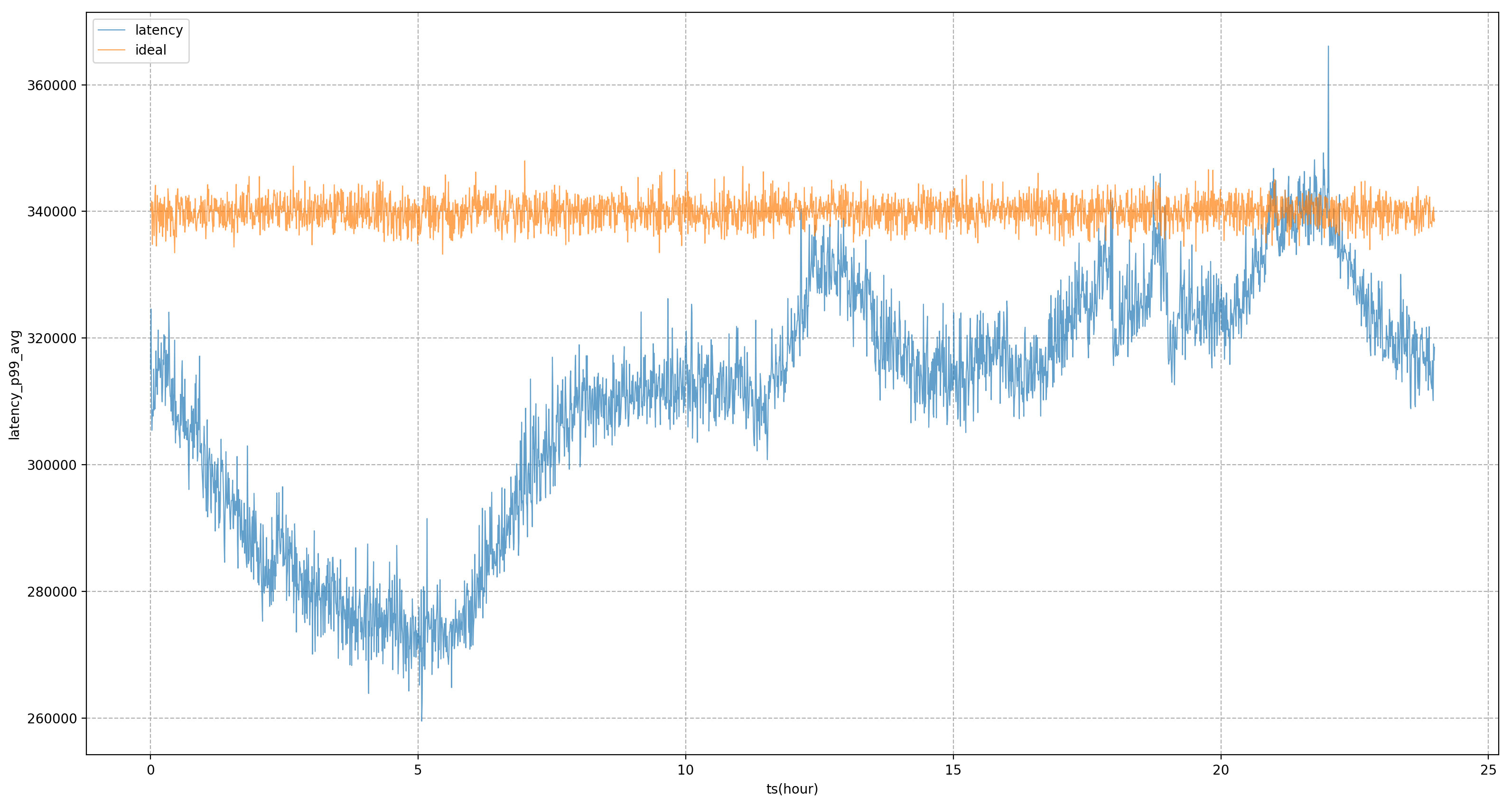
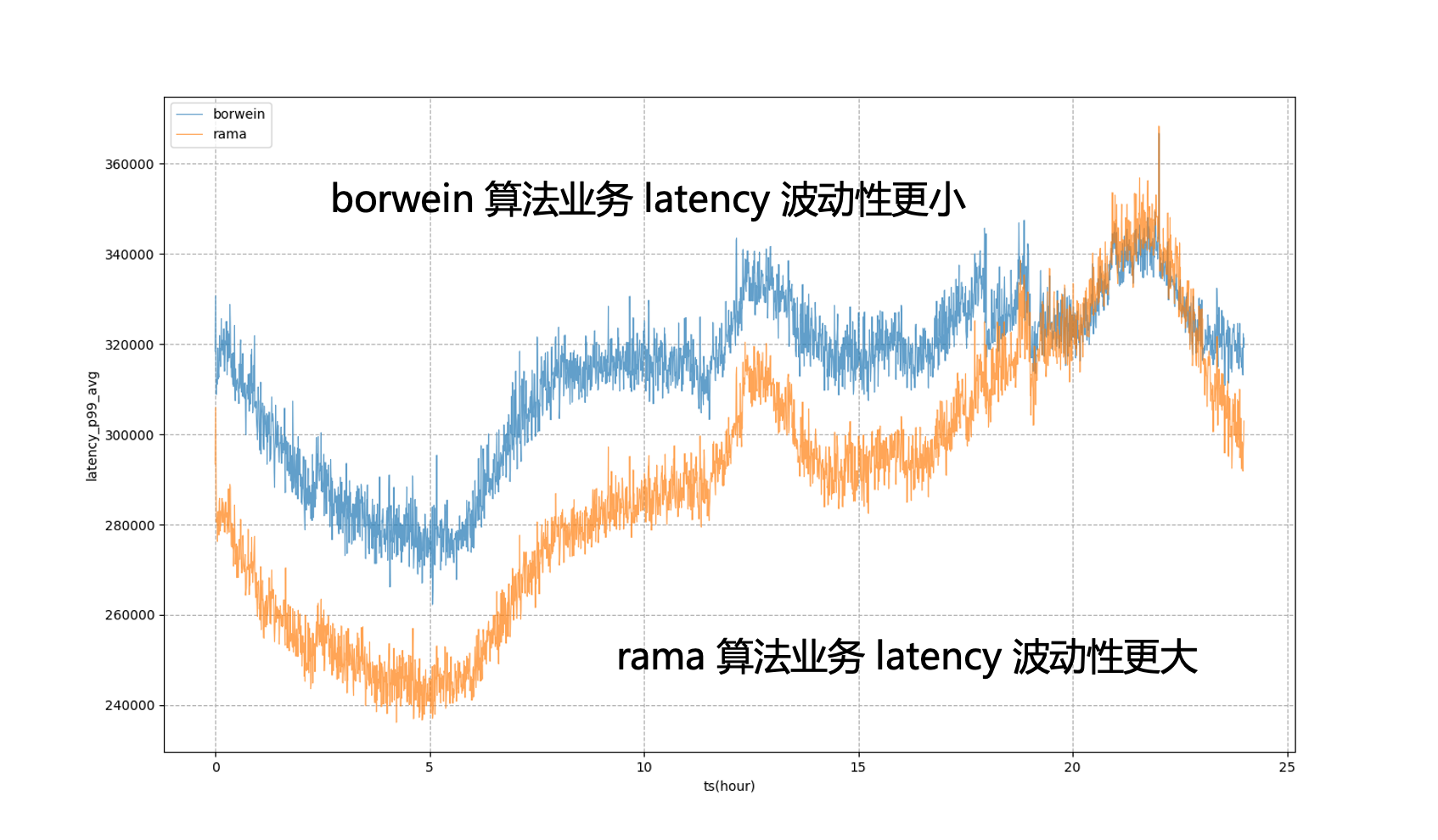
Par exemple, dans la figure ci-dessous, si les objectifs statiques du système sont entièrement utilisés pour la régulation, le P99 de l'entreprise sera dans un état de forte fluctuation, ce qui signifie que pendant les heures de pointe en dehors du soir, nous ne pouvons pas réduire l'utilisation des ressources de l'entreprise à un niveau plus élevé. état extrême pour le rapprocher de l'entreprise Le montant qui peut être toléré pendant les heures de pointe du soir ; après l'introduction du modèle, nous pouvons voir que le retard commercial sera plus stable, nous permettant de niveler la performance commerciale à un niveau relativement stable. tout au long de la journée et obtenir des bénéfices en ressources.
4.5 Pratique : résoudre des problèmes sur une seule machine
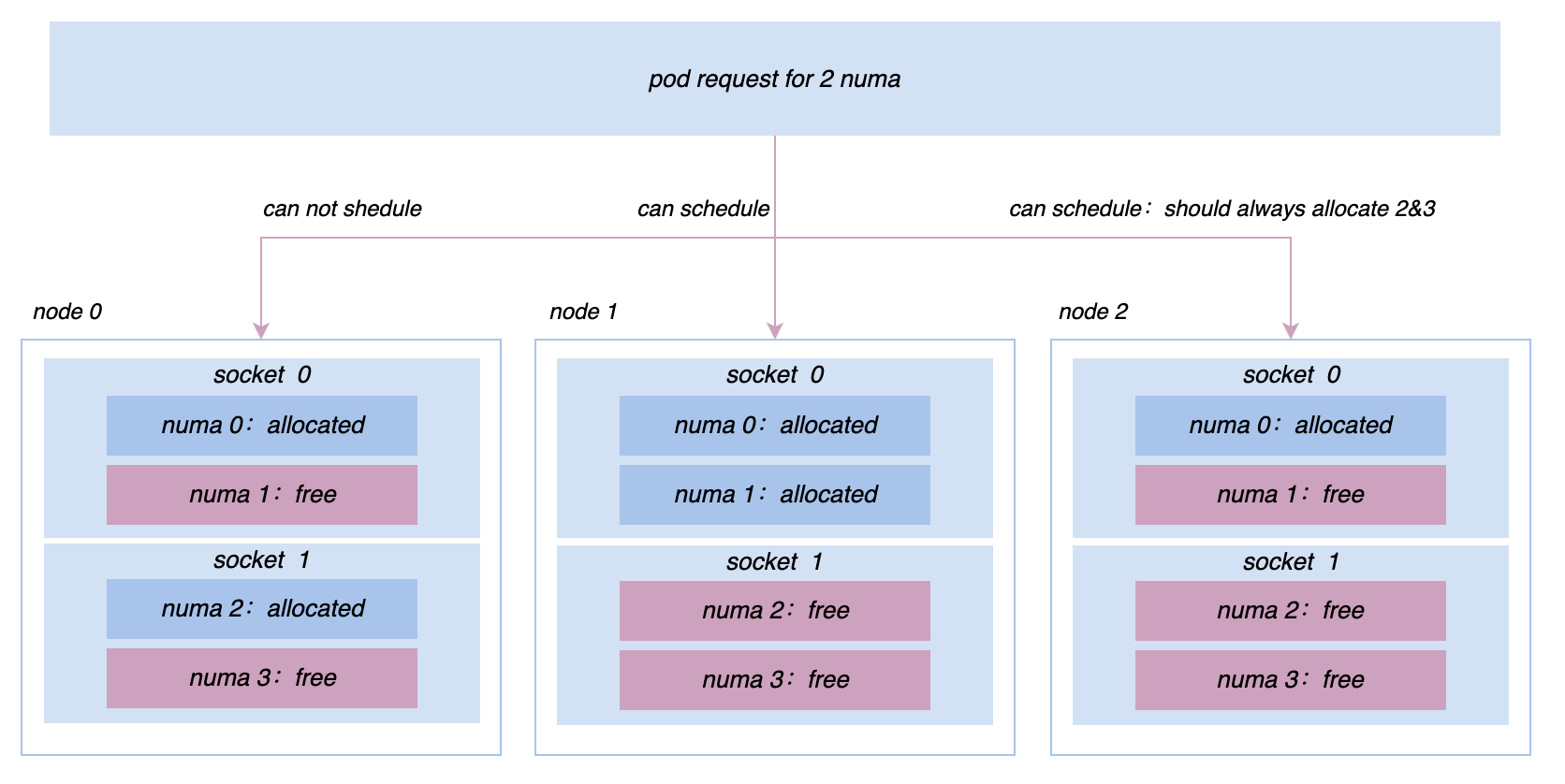
Dans le processus de promotion de la colocalisation, nous continuerons à rencontrer divers problèmes de performances en ligne et hors ligne et des demandes en matière de gestion de la micro-topologie. Par exemple, au départ, toutes les machines étaient gérées et contrôlées sur la base du groupe de contrôle V1. Cependant, en raison de la structure de la V1, le système doit parcourir une arborescence de répertoires très profonde et consommer beaucoup de CPU en mode noyau pour résoudre ce problème. , nous basculons les nœuds de l'ensemble du cluster vers cgroup V1. L'architecture cgroup V2 nous permet d'isoler et de surveiller les ressources plus efficacement ; pour des services tels que la recherche de promotion, afin d'obtenir des performances plus extrêmes, nous devons implémenter une affinité plus complexe ; et stratégies d'anti-affinité au niveau Socket/NUMA, etc. Etc., ces exigences de gestion des ressources plus avancées peuvent être mieux réalisées dans Katalyst.
5 Résumé et perspectives
Katalyst est officiellement open source et a publié la version v0.3.0, et continuera à investir plus d'énergie dans l'itération ; la communauté développera des capacités et des améliorations du système en matière d'isolation des ressources, de profilage du trafic, de stratégies de planification, de stratégies élastiques, de gestion des appareils hétérogènes, etc. , tout le monde est invité à prêter attention, à participer à ce projet et à donner son avis.
Un camarade de poulet "open source" deepin-IDE et a finalement réalisé l'amorçage ! Bon gars, Tencent a vraiment transformé Switch en une « machine d'apprentissage pensante » Examen des échecs de Tencent Cloud le 8 avril et explication de la situation Reconstruction du démarrage du bureau à distance RustDesk Client Web La base de données de terminal open source de WeChat basée sur SQLite WCDB a inauguré une mise à niveau majeure Liste d'avril TIOBE : PHP est tombé à un plus bas historique, Fabrice Bellard, le père de FFmpeg, a sorti l'outil de compression audio TSAC , Google a sorti un gros modèle de code, CodeGemma , est-ce que ça va vous tuer ? C'est tellement bon qu'il est open source - outil d'édition d'images et d'affiches open sourceVidéo du discours de la conférence : Katalyst : Bytedance Cloud Native Cost Optimization Practice |