
Équipe source|Plateforme d'opérations en direct BytedanceDans la construction continue de services d'agrégation de données inter-domaines basés sur ES, nous avons constaté que de nombreuses fonctionnalités d'ES sont assez différentes des bases de données couramment utilisées telles que MySQL. Cet article partagera les principes de mise en œuvre d'ES et les suggestions de sélection d'entreprise dans les plateformes de diffusion en direct. , et les problèmes rencontrés dans la pratique et la réflexion.
Introduction à ES et scénarios d’application
Elasticsearch est un moteur de stockage, de récupération et d'analyse de données massives distribué en temps quasi réel. Ce que nous appelons souvent « ELK » fait référence à un système de données composé d'Elasticsearch, Logstash/Beats et Kibana, capable de collecter, de stocker, de récupérer et de visualiser. ES joue un rôle dans le stockage et l'indexation des données, la récupération et l'analyse des données dans des systèmes de données similaires.
Fonctionnalités ES
Chaque sélection technologique a ses propres caractéristiques, et les caractéristiques globales d'ES sont également affectées par la mise en œuvre sous-jacente. La deuxième partie de cet article détaillera les causes profondes des caractéristiques suivantes.
Avantages:
-
Distribué : grâce au partitionnement, il peut prendre en charge des données jusqu'au niveau PB et protéger les détails du partitionnement de l'extérieur. Les utilisateurs n'ont pas besoin d'être conscients du routage de lecture et d'écriture ;
-
Évolutif : facile à développer horizontalement, pas besoin de diviser manuellement les bases de données et les tables comme MySQL ou d'utiliser des composants tiers ;
-
Vitesse rapide : calcul parallèle de chaque fragment, vitesse de récupération rapide ;
-
Récupération de texte intégral : plusieurs optimisations ciblées, telles que la prise en charge de la récupération de texte intégral multilingue via divers plug-ins de segmentation de mots et l'amélioration de la précision grâce au traitement sémantique ;
-
Fonctions d'analyse de données riches.
Les inconvénients:
-
Les transactions ne sont pas prises en charge : le processus de calcul de chaque fragment est parallèle et indépendant ;
-
Temps quasi réel : il y a un délai de plusieurs secondes entre le moment où les données sont écrites et le moment où les données peuvent être interrogées ;
-
Le langage DSL natif est relativement complexe et a un certain coût d'apprentissage.
Utilisations courantes
Les fonctionnalités affecteront les scénarios d'application des composants.Dans la partie récupération et analyse de documents, la plate-forme d'exploitation de diffusion en direct utilise ES pour regrouper diverses informations de centaines de millions d'ancres et les utilise pour afficher diverses listes sur la plate-forme correspondante. est utilisé pour détecter les erreurs Argos.
Implémentation et architecture ES
Ensuite, comprenez comment les avantages ES mentionnés ci-dessus sont réalisés et comment les inconvénients sont causés. Lorsque nous parlons d'ES, nous devons parler de Lucene est une bibliothèque Java de recherche en texte intégral qui utilise Lucene comme composant sous-jacent pour tout implémenter. Fonctions. Ce qui suit présente principalement les fonctionnalités de Lucene. Quelles fonctions et quelles nouvelles capacités ES a-t-il par rapport à Lucene ?
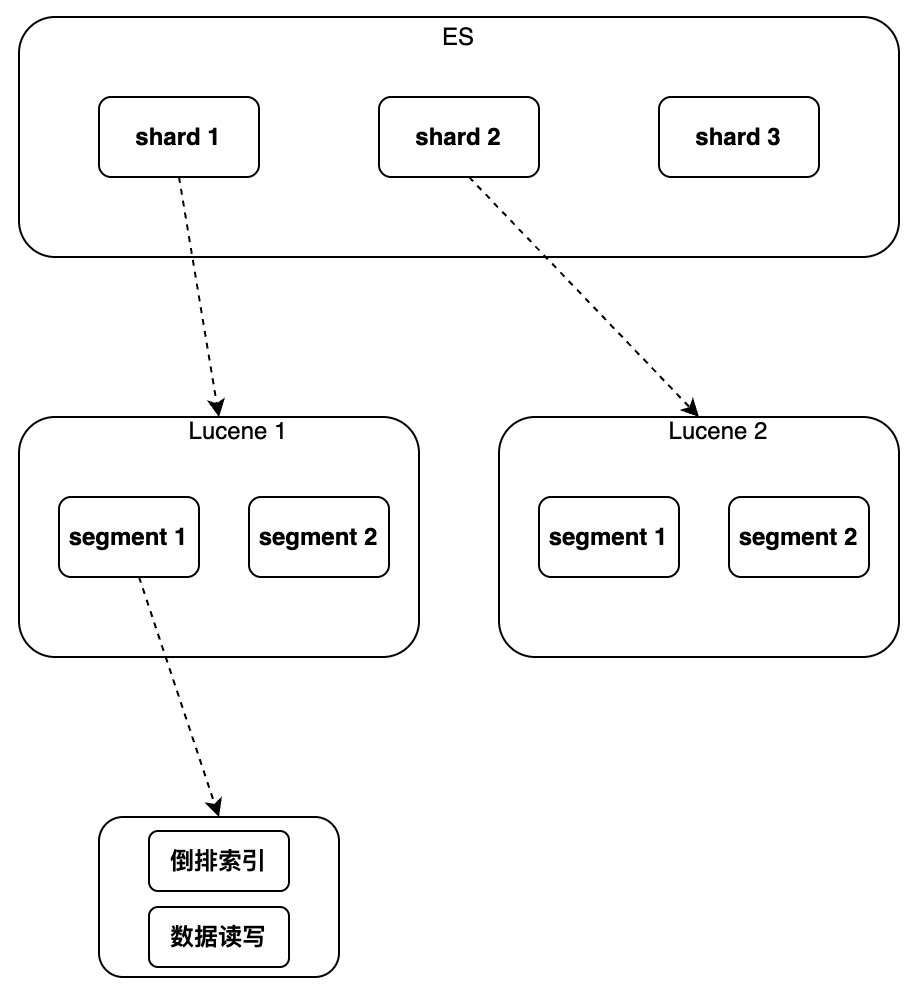
Lucene implémente l'indexation et la récupération des données sur une seule instance. Il peut prendre en charge l'index inversé et l'écriture séquentielle des données, mais il ne prend pas en charge la modification et la suppression. Il n'existe pas de concept de clé primaire globale. ne peut pas prendre en charge le fonctionnement de la distribution.
Par conséquent, ES a ajouté de nouvelles fonctionnalités par rapport à Lucene
,
notamment le nouveau champ de clé primaire globale "_id", qui rend possible la modification/suppression de données et le routage de fragments et l'utilisation d'un fichier séparé pour marquer le document supprimé pour "écrire un nouveau document ; L'opération de mise à jour est implémentée par « Document, marquant l'ancien document supprimé » ; en ajoutant un nouveau numéro de version au document, la concurrence est prise en charge sous la forme d'un verrouillage optimiste ; le processus de réalisation de la distribution consiste à exécuter plusieurs instances Lucene pour acheminer la lecture et écrire des requêtes et fusionner en fonction des résultats de la requête d'ID de clé primaire ; une analyse d'agrégation a également été ajoutée, qui peut implémenter le tri, les statistiques, etc., l'analyse des résultats de la requête. Les détails spécifiques de la mise en œuvre seront présentés ci-dessous dans l'ordre de l'instance unique au cluster.
seule instance
indice
Le but de l'indexation est d'accélérer le processus de récupération. La sélection d'index est un problème inévitable pour toutes les bases de données. Le scénario cible initial de la conception ES est la récupération de texte intégral, il prend donc en charge « l'index inversé » et a fait de nombreuses optimisations pour cela. De plus, il prend également en charge d'autres index tels que Block Kd Tree. ES fera automatiquement correspondre le type d'index correspondant en fonction du type de champ et créera des index pour les champs qui doivent être indexés.
L'index inversé et l'arbre Block Kd sont également des types d'index couramment utilisés pour l'analyse. Pour les chaînes, il existe deux situations courantes : le texte utilise la segmentation de mots + index inversé, tandis que le mot clé utilise la segmentation de non-mots + index inversé. Pour les types numériques, tels que Long/Float, Block Kd Tree est généralement utilisé.
Index inversé
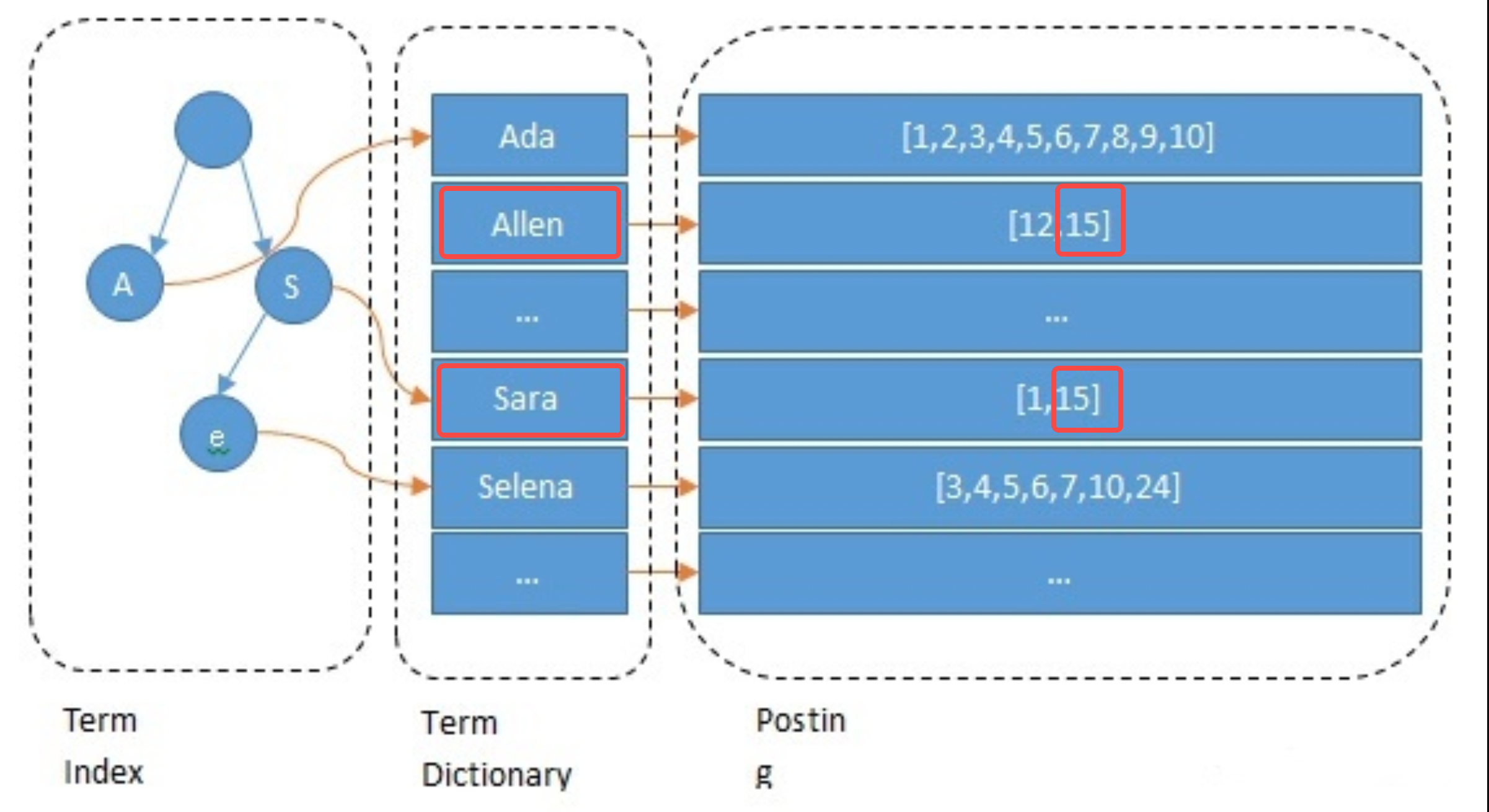
Lors de la création de l'index, ES indexera chaque champ par défaut. Ce processus comprend la segmentation des mots, le traitement sémantique et la construction de tables de mappage. Tout d'abord, le texte sera segmenté en mots. La méthode de segmentation des mots est liée à la langue, comme le découpage par espaces en anglais. Ensuite, les mots dénués de sens sont supprimés et une normalisation sémantique est effectuée. Enfin, construisez la table de mappage. L'exemple suivant montre brièvement le processus de traitement du champ Nom de l'ancre 15 : il est segmenté en allen et sara ; converti en minuscules et autres opérations et les mappages de allen->15 et sara->15 sont construits ;
// 主播1 { "id": 1 "name":"ada sara" ... // 其他字段 } // 主播15 { "id": 15 "name":"allen sara" }
Processus de requête
Prenons comme exemple la requête pour l'ancre nommée "allen sara". Selon les résultats de la segmentation des mots, deux listes [12, 15] et [1, 15] sont trouvées respectivement (dans les applications réelles, la requête sera également basée sur). synonymes) ; pour fusionner les listes et les scores, appuyez sur La priorité est d'obtenir les résultats [15, 12, 1] (c'est l'étape de rappel dans la recherche, et elle sera également affinée selon l'algorithme).
Éléments d'optimisation
Afin d'accélérer la récupération et de réduire la pression sur la mémoire/le disque dur, ES effectue les optimisations suivantes sur l'index inversé, ce qui constitue également l'avantage d'ES par rapport aux autres composants. Ce qu'il faut noter ici, c'est que l'utilisation finale de l'espace de stockage peut être une caractéristique commune à toutes les bases de données. Redis économise également de l'espace mémoire de la même manière : les données sont stockées avec le moins de bits possible, et les petits ensembles et les grands ensembles le sont. stockés de différentes manières.
-
Index des termes : utilisez des arbres de préfixes pour accélérer le positionnement des mots « Termes » et résoudre le problème de la vitesse de récupération lente causée par un trop grand nombre de mots ;
-
Dictionnaire de termes : placez les mots avec le même préfixe dans un bloc de données et ne conservez que le suffixe, tel que [hello, head] -> [lo, ad] ;
-
Publication : Ordonné + codage incrémentiel + stockage par blocs, tel que [9, 10, 15, 32, 37] -> [9, 1, 5, 17, 5], chaque élément peut utiliser un stockage de 5 bits ;
-
Optimisation de la fusion des publications : utilisez Roaring Bitmap pour économiser de l'espace. Lorsque vous utilisez des requêtes multiconditions, vous devez fusionner plusieurs publications ;
-
Traitement sémantique : un contenu ayant une sémantique similaire peut être interrogé.
Caractéristiques de l'index inversé :
-
Prise en charge de la recherche en texte intégral : prend en charge plusieurs langues avec différents plug-ins de segmentation de mots, tels que le plug-in de segmentation de mots IK pour mettre en œuvre la recherche en texte intégral en chinois ;
-
Petite taille d'index : l'arborescence des préfixes compresse considérablement l'espace et l'index peut être placé en mémoire pour accélérer la récupération ;
-
Mauvaise prise en charge de la recherche par plage : limitée par la sélection de l'arborescence des préfixes ;
-
Scénarios applicables : recherche par mot, recherche sans plage. Les champs ES non numériques utilisent ce type d'index.
Blocage
K d Index
de
l'arbre
L'index Block Kd Tree est très convivial pour les recherches de plage telles que les valeurs ES, la géo et la plage utilisent tous ce type d'index. Dans la sélection d'entreprises, les champs numériques qui nécessitent une recherche par plage doivent utiliser des types numériques tels que Long. Pour les index inversés, les champs qui ne nécessitent pas de recherche en texte intégral doivent utiliser le type Mot-clé.
En raison de l'espace limité, cet article ne présentera pas grand-chose ici. Les amis intéressés par BKd Tree peuvent se référer au contenu suivant :
-
https://www.shenyanchao.cn/blog/2018/12/04/lucene-bkd/
-
https://www.elastic.co/cn/blog/lucene-points-6-0
stockage de données
Cette partie explique principalement comment les données d'une seule instance sont stockées en mémoire et sur le disque dur.
Segment de stockage segmenté
Les données d’une seule instance peuvent atteindre des centaines de Go, et les stocker dans un fichier est évidemment inapproprié. Comme Kafka, Pulsar et d'autres composants qui doivent stocker des données Append Only, ES choisit de diviser les données en segments pour le stockage.
-
Segment : chaque segment possède son propre fichier d'index et les résultats sont fusionnés après des requêtes parallèles ;
-
Calendrier de génération des segments : génération programmée ou basée sur la taille du fichier, la durée est configurable, généralement quelques secondes ;
-
Fusion de segments : étant donné que les segments sont générés régulièrement et sont généralement relativement petits, ils doivent être fusionnés en segments plus grands.
Risque de latence et de perte de données
-
Délai de récupération : la récupération conditionnelle dépend de l'index, et l'index n'est disponible que lorsque le segment est généré, il y a donc généralement un délai de plusieurs secondes entre l'écriture et la récupération ;
-
Risque de perte de données : les segments nouvellement générés prendront des dizaines de minutes à être vidés par défaut, et il existe un risque de perte de données ;
-
Réduisez le risque de perte de données : Translog est également utilisé pour enregistrer les événements d'écriture. Par défaut, le disque est vidé toutes les 5 secondes, mais il existe toujours un risque de perdre plusieurs secondes de données.
Comment implémenter la suppression/mise à jour
-
Supprimer : chaque segment correspond à un fichier del, enregistrant l'ID supprimé, et les résultats de la recherche doivent être filtrés ;
-
Mise à jour : rédigez de nouveaux documents et supprimez les anciens documents.
grappe
Les bases de données sur une seule machine présentent des problèmes tels qu'une capacité et un débit limités et de faibles capacités de reprise après sinistre. Ces problèmes sont généralement résolus par le partitionnement et la redondance des données. Cependant, ces deux opérations introduisent généralement les problèmes suivants. Voyons d'abord comment ES fragmente et sauvegarde les données, puis comment résoudre les trois questions suivantes : Comment les requêtes de lecture et d'écriture sont-elles acheminées vers chaque fragment ? Comment fusionner les résultats de recherche de chaque fragment ? Comment choisir le maître entre les instances actives et en veille ?
Fragment distribué
Le nombre de fragments pour chaque index peut être configuré indépendamment. La figure suivante prend comme exemple un index avec trois fragments. La capacité de stockage globale est augmentée grâce à l'expansion horizontale et la vitesse de récupération est améliorée grâce au calcul parallèle de chaque fragment.
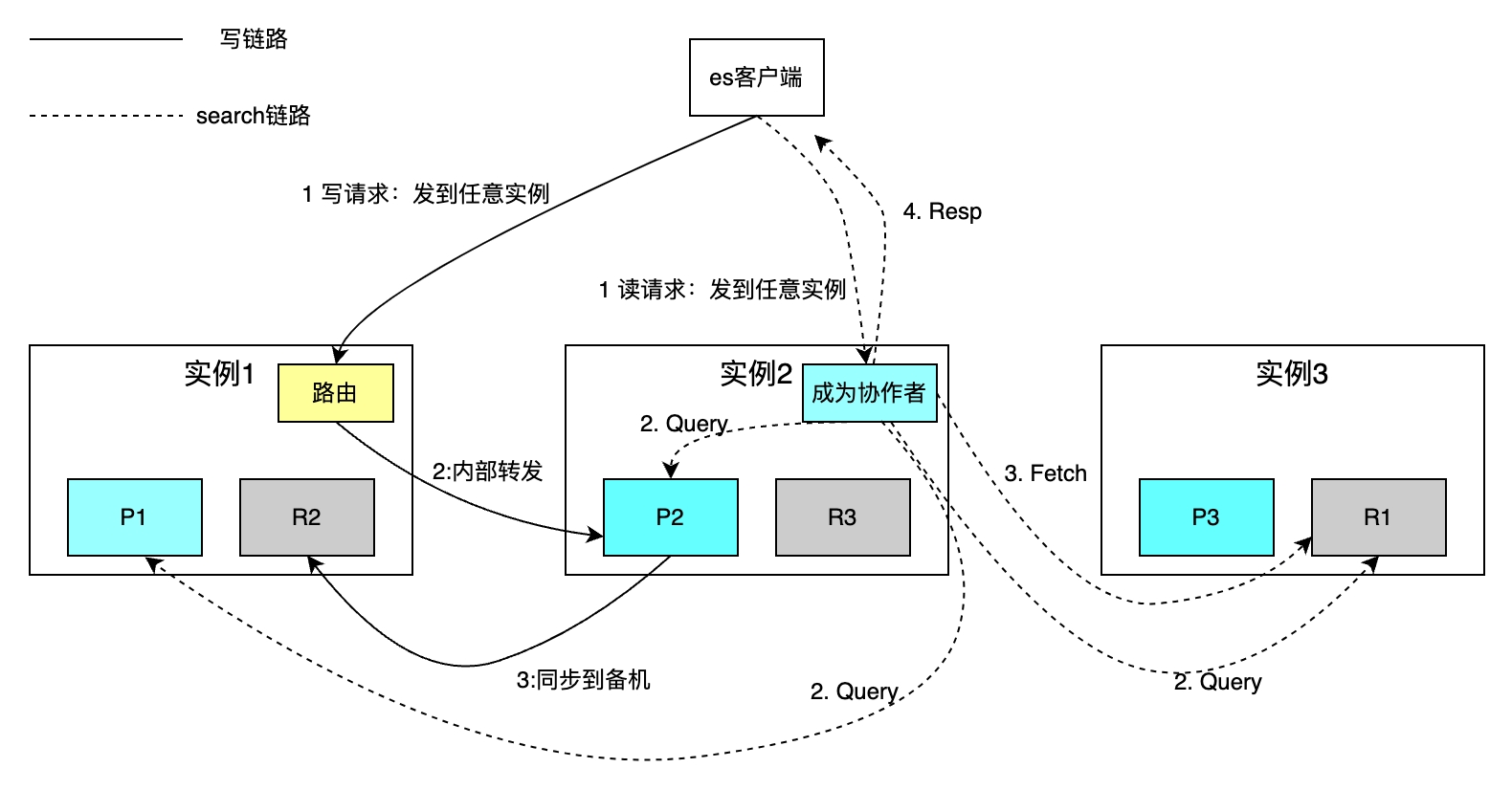
La politique de routage lit et écrit un seul document basé sur la clé primaire. Le routage de hachage utilise l'ID comme clé primaire par défaut pour les opérations d'écriture, si la partie commerciale ne spécifie pas l'ID de clé primaire, ES utilise l'algorithme Guid pour le générer automatiquement. En raison des restrictions de la politique de routage, l'augmentation ou la diminution du nombre de partitions nécessite la migration de toutes les données. Les requêtes de recherche basées sur la récupération conditionnelle sont mises en œuvre en deux étapes : les phases de requête des phases de coordination et de requête du collaborateur et la phase d'acquisition de la phase de récupération. Le collaborateur envoie une demande de lecture à n'importe quelle instance, et l'instance envoie la demande à chaque partition en parallèle. Chaque partition exécute du SQL local et renvoie 2 000 + 100 données au collaborateur, chaque donnée comprenant l'identifiant et l'uid. Le collaborateur trie toutes les données fragmentées, obtient les ID de 100 documents, puis obtient les données par ID et les renvoie au client.
L'inconvénient est que la méthode de récupération ci-dessus protège le client du concept de partitionnement, ce qui facilite grandement les opérations de lecture et d'écriture. Il n'est pas nécessaire de connaître les sous-bases de données et les tables comme MySQL. Cependant, chaque instance doit également s'ouvrir. un espace de taille à partir de+limite. Lorsqu'un changement de page profond se produit, une grande quantité d'espace est nécessaire pour trier les documents de fragmentation* (à partir de+limite) et d'autres problèmes.
En réponse aux problèmes ci-dessus, en pratique, nous ajoutons des paramètres tels que uid>2200 qui changent à chaque requête aux éléments conditionnels de Search After, ce qui peut réduire le nombre de tri de from+limit à Limit pour une autre forme de Scroll ; Rechercher après, conserver les éléments de condition de chaque demande en interne dans ES et prendre en charge la concurrence.
Revenu de synchronisation maître-esclave
Les avantages incluent principalement une haute disponibilité grâce à la redondance des données et un débit système accru. La méthode de synchronisation des données comprend une synchronisation maître-esclave au sein du cluster, qui est généralement déployée dans différentes salles informatiques de la même région pour accélérer les opérations d'écriture. La cohérence synchrone ou asynchrone peut être sélectionnée : Une, Toutes ou Quorum. De plus, il existe une synchronisation entre clusters (CCR), qui est utilisée pour la reprise après sinistre multicluster et l'accès à proximité dans différentes régions. Elle adopte une méthode asynchrone et le niveau d'index peut être une réplication unidirectionnelle ou bidirectionnelle des données. .
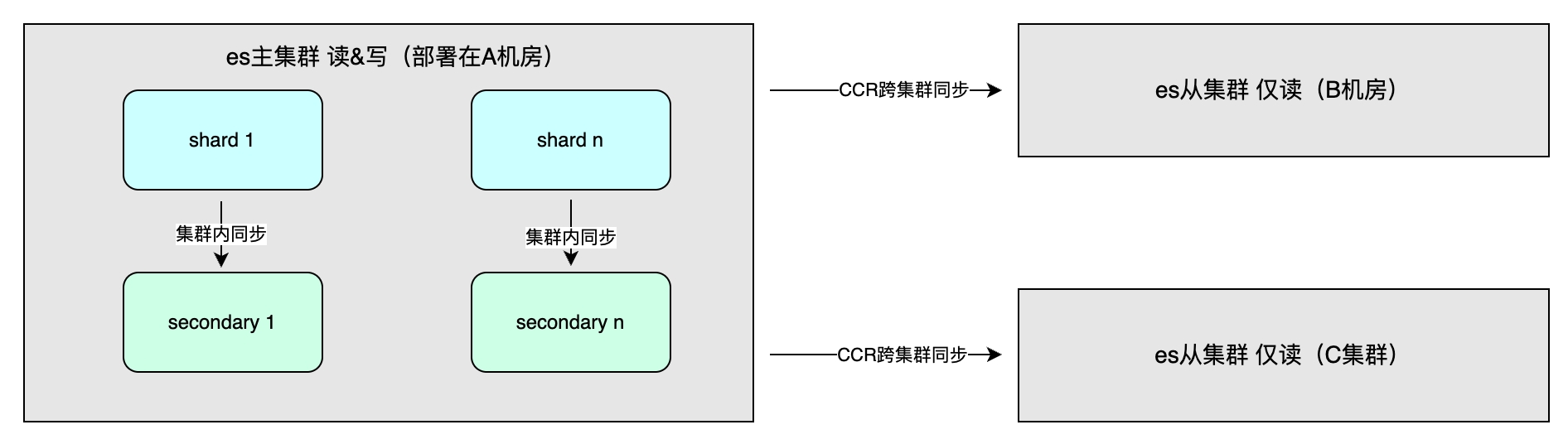
Scène applicable
Les détails de mise en œuvre d’ES déterminent ses caractéristiques globales, qui à leur tour affectent les scénarios applicables. Les scénarios applicables incluent : un volume de données important, inférieur au niveau PB ; récupération de texte intégral, indexation et tri flexibles multi-champs requis ; aucune exigence pour les transactions ; faible exigence de latence de requête après l'écriture. Cependant, il n'est pas recommandé d'utiliser ES comme seul stockage pour les données importantes, car il y a un délai de plusieurs secondes et un risque de perte de données, et contrairement à MySQL, la haute disponibilité est soigneusement optimisée dans les moindres détails.
Pratique du système d'agrégation de données inter-domaines pour la plate-forme d'exploitation de diffusion en direct
Scénarios d'application
Sur la plateforme d'exploitation des guildes et présentateurs de diffusion en direct, il existe de nombreux scénarios de visualisation et d'analyse des données, tels que les listes d'ancres, les tâches d'ancrage et de guilde, etc. Ce type de données présente généralement les caractéristiques suivantes : grand volume de données, nombreux champs et à partir de nombreuses sources. Par exemple, le nombre de champs d'index pour les ancres est proche de 200, les sources de données peuvent atteindre plus de 10 (telles que les plateformes de données, les plateformes de sécurité, les portefeuilles, etc.) et des opérations telles que la récupération et le tri. par plusieurs champs sont pris en charge.
Lorsque les utilisateurs consultent les données, il faut beaucoup de temps pour obtenir les données de chaque partie commerciale en temps réel, et il est difficile d'effectuer des requêtes et des tris conditionnels basés sur plusieurs champs, de sorte que les données doivent être agrégées à l'avance dans une seule base de données. . Il est difficile pour les bases de données telles que MySQL et Redis de répondre aux caractéristiques ci-dessus, et ES peut mieux les prendre en charge. Par conséquent, nous avons construit un système de service d'agrégation de données inter-domaines basé sur ES : consommer les modifications dans les sources de données en amont et les écrire dans le. Grand index ES pour répondre aux besoins des requêtes. Prenons « Anchor Index » comme exemple pour illustrer le mode d'agrégation de données :
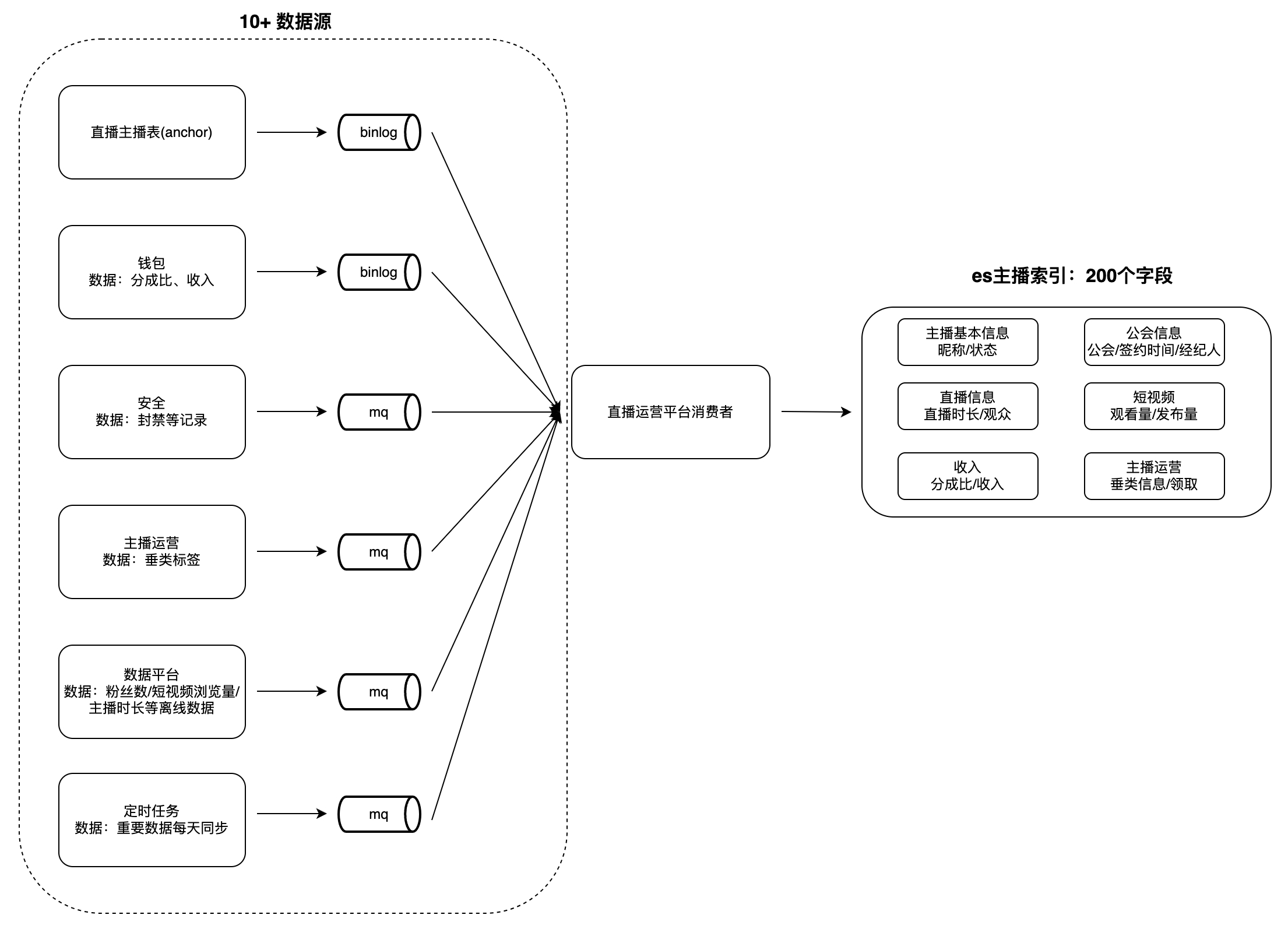
défi
La première version de l'implémentation utilisait un seul PSM comme consommateur pour lire les données en amont et les écrire dans ES. Étant donné que les écritures n'étaient pas isolées, de nombreux problèmes survenaient. Premièrement, toutes les parties à l'accès écrivent une logique de consommation de données dans le même PSM, ce qui entraîne un couplage élevé de la logique de traitement des données et des difficultés de maintenance. Deuxièmement, il existe un risque que plusieurs parties commerciales écrivent dans le même champ, ce qui pourrait entraîner des exceptions commerciales. De plus, le mode d'écriture de données ES à couverture complète entraîne une vitesse de traitement des données lente et une faible vitesse de consommation MQ. Dans le même temps, il existe toujours des problèmes tels que la concurrence entre les ressources et la lenteur des requêtes qui ne peuvent pas être associés à des amonts spécifiques. Avec environ 5 nouveaux champs ajoutés tous les deux mois et des données qui continuent de croître, si ces problèmes ne sont pas résolus, les défis seront plus grands à l'avenir.
L'analyse des problèmes ci-dessus peut être divisée en trois catégories : la logique de traitement de chaque source de données est fortement couplée et l'ensemble est facilement affecté par une seule partie commerciale ; la vitesse de traitement des données est lente, ce qui intensifie la concurrence en matière de ressources ; et capacités de gouvernance d'écriture : isolation en écriture, statistiques de requêtes lentes.
solution
La figure ci-dessous présente la structure globale après la gouvernance. Sur cette base, nous analyserons un par un les problèmes et les considérations rencontrés dans le processus de gouvernance.
Ce contenu ne peut pas être affiché en dehors des documents Feishu pour le moment.
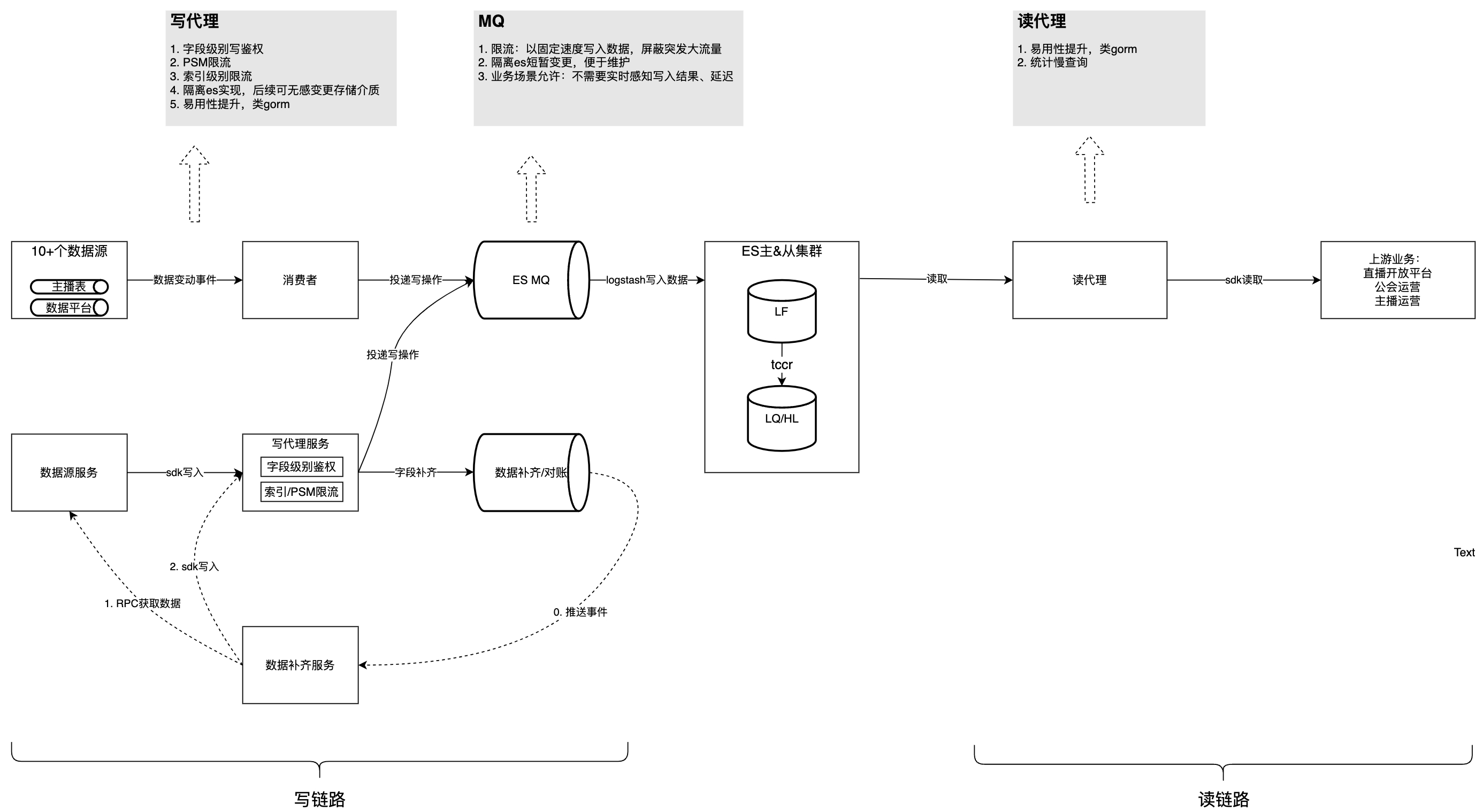
Problème 1 : Les logiques de consommation de chaque source de données sont fortement couplées, difficiles à maintenir, s'influencent mutuellement et accaparent les ressources.
La manifestation spécifique de ce problème est que plus de 10 logiques de consommation de données MQ sont implémentées dans le même PSM. La logique de traitement des données partagées et des modifications mineures peuvent affecter d'autres traitements MQ, ce qui rend la maintenance peu pratique, et il y a des problèmes. La concurrence entre les ressources et la répartition inégale des partitions d'un seul événement MQ entraînent une utilisation inégale des ressources sur une seule machine, ce qui ne peut pas être résolu par une expansion horizontale de la machine. Par conséquent, l'instabilité du code d'un seul MQ affectera la consommation de tous les sujets MQ. La répartition inégale des partitions des sujets MQ individuels entraînera une montée en flèche du processeur des instances de consommateur individuelles, affectant ainsi la consommation des autres sujets.
Stratégie d'optimisation :
-
Améliorer la vitesse de consommation d'un seul événement : mise à jour partielle de l'ES ; revoir la configuration limite actuelle de tous les sujets ;
-
Créez davantage de méthodes d'écriture de données et répartissez l'écriture des champs non essentiels entre les différents côtés de l'entreprise. Par exemple, il fournit un SDK d’écriture et introduit Dsyncer.
Problème 2 : la consommation de données
MQ
est lente et les mises à jour des données commerciales sont retardées
Le traitement d'un seul message MQ prend du temps. En prenant comme exemple le mode d'écriture de données ES à couverture complète, la mise à jour d'un champ nécessite l'écriture des champs restants qui n'ont pas besoin d'être mis à jour ensemble, car près de 200 données de champ doivent être obtenues. en temps réel via RPC Dans l'ensemble, cela prend beaucoup de temps et la vitesse de consommation de MQ est lente ; certains sujets MQ consomment 1 travailleur dans une seule instance. Le principal impact est que le délai de mise à jour des données est élevé et qu'il faut un certain temps pour que les informations utilisateur s'affichent sur les plates-formes en aval après les modifications. Et chaque mise à jour nécessite l'obtention de près de 200 champs auprès de plusieurs parties commerciales. Des anomalies dans une seule source de données entraîneront l'échec de la consommation complète des événements MQ et une nouvelle tentative.
Stratégie d'optimisation :
-
Changez le mode d'écriture des données du cluster ES de couverture complète à mise à jour partielle : un seul champ peut être mis à jour à la demande, et le consommateur n'a plus besoin d'obtenir près de 200 champs auprès de plusieurs parties commerciales, ce qui non seulement réduit le temps de traitement des données, mais réduit également le code Difficulté de maintenance ;
-
Configurez toutes les rubriques MQ pour avoir plusieurs Workers, et celles qui nécessitent une consommation séquentielle sont configurées pour être acheminées vers le même Worker en fonction de l'ID de clé primaire.
Problème 3 : L’écriture n’est pas isolée/authentifiée/limitée
L'écriture sur le terrain manque d'isolation et d'authentification, et il existe un risque que plusieurs parties commerciales écrivent dans le même champ, ce qui peut entraîner des anomalies commerciales. La raison principale est que les parties qui rédigent partagent les ressources. Si une partie écrit trop rapidement, elle occupera les ressources des autres parties, ce qui entraînera une augmentation du délai d'écriture. Par conséquent, il est nécessaire de contrôler strictement les mises à jour des champs principaux du stockage ES pour éviter de déclencher une grande quantité de commentaires de la part des utilisateurs.
Stratégie d'optimisation :
-
Ajout d'une authentification en écriture au niveau du champ, permettant uniquement aux PSM autorisés d'écrire certaines données de champ ;
-
Pour mettre en œuvre des stratégies de limitation du trafic dans les deux dimensions PSM et index, des composants configurables dynamiquement sur la plateforme générale de gestion du trafic sont utilisés.
Problème 4 : manque de statistiques de requêtes lentes et de méthodes d'optimisation
Comme MySQL et d’autres bases de données, le SQL non standard entraînera des analyses inutiles et des retards de requête importants. ES offre la possibilité d'interroger du SQL qui prend beaucoup de temps, mais il ne peut pas corréler les informations PSM, Logid et autres en amont, ce qui rend le dépannage difficile.
Stratégie d'optimisation : l'agent de lecture enregistre les messages SQL, PSM en amont, Logid et autres qui dépassent le seuil sous la forme d'une couche intermédiaire vers l'ES, et signale chaque jour les conditions de requête lentes.
Question 5 : Facilité d'utilisation
Stratégie d'optimisation :
-
Activez le plug-in ES SQL dans le cluster ES Étant donné que la syntaxe ES SQL est légèrement différente de MySQL SQL, une prise en charge supplémentaire est fournie via le service d'agent de lecture : le côté utilisateur utilise la syntaxe MySQL et l'agent de lecture utilise des expressions régulières pour réécrire. Normes SQL vers ES SQL ; injectez ScrollID dans ES SQL, le côté utilisateur n'a pas besoin de se soucier de la façon d'exprimer la requête Scroll en SQL ;
-
Aidez les utilisateurs à désérialiser les données de requête en structures.
// es dsl查询样例 GET twitter/_search { "size": 10, "query": { "match" : { "title" : "Elasticsearch" } }, "sort": [ {"date": "asc"} ] } // 使用读sdk的等价sql select * from twitter where title="Elasticsearch" order by date asc limit 10
Résultats de la gouvernance
Grâce à la gouvernance ci-dessus, l'accumulation de liens d'écriture a été complètement éliminée et la capacité de consommation a augmenté de 150 %, ce qui se reflète spécifiquement dans l'augmentation du QPS de l'entreprise de 4 000 à 10 000, sans atteindre la limite supérieure des performances du système. Le QPS de lecture maximal est de 1 500 et le SLA est stable à 99,99 % sur le long terme. Actuellement, plusieurs parties commerciales utilisent le SDK et elles ont signalé que le temps d'accès a été réduit de 2 jours à l'origine à 0,5 jour.
Planification du suivi
La planification de suivi comprend principalement l'extension des capacités de réconciliation MVP des scénarios individuels à tous les scénarios ; la promotion de l'optimisation commerciale en amont de SQL basée sur des statistiques de requêtes lentes et la fourniture de davantage de méthodes d'écriture de données, telles que FaaS ;
Basé sur l'expérience interne des meilleures pratiques à grande échelle de ByteDance, Volcano Engine fournit
des produits
ES
cohérents en externe - des produits cloud de service de recherche cloud au niveau de l'entreprise. Le service de recherche cloud est compatible avec Elasticsearch, Kibana et d'autres logiciels et plug-ins open source couramment utilisés. Il fournit une récupération multi-conditions, des statistiques et des rapports de texte structuré et non structuré. Il peut réaliser un déploiement en un clic, une mise à l'échelle élastique et des rapports. opération et maintenance simplifiées, et création rapide d'analyses de journaux, de récupération et d'analyse d'informations et d'autres fonctionnalités commerciales.
{{o.name}}
{{m.nom}}