

Cet article présente la prise en charge du moteur de format tabulaire ouvert Databend, y compris les avantages et les inconvénients, les méthodes d'utilisation et la comparaison avec la solution Catalog. De plus, un atelier simple est inclus pour présenter comment utiliser Databend Cloud pour analyser la table Delta située dans le stockage d'objets.
Databend a récemment publié deux moteurs de table, Apache Iceberg et Delta Table, pour prendre en charge les deux formats de table ouverte les plus populaires afin de répondre aux besoins d'analyse avancée des solutions de lac de données modernes basées sur différentes piles technologiques.
Grâce à une solution unique basée sur Databend/Databend Cloud, vous pouvez obtenir des informations sur les données tabulaires ouvertes et simplifier l'architecture de déploiement et le processus d'analyse sans activer de services Spark/Databricks supplémentaires. De plus, grâce à la solution d'accès aux données de Databend / Databend Cloud basée sur Apache OpenDAL™, vous pouvez facilement accéder à des dizaines de services de stockage, notamment le stockage objet, HDFS et même IPFS, et pouvez facilement l'intégrer aux piles technologiques existantes.
Avantage
-
Lorsque vous utilisez le moteur de format de table ouvert, il vous suffit de spécifier le type (
DeltaouIceberg) du moteur de table et l'emplacement où le fichier de données est stocké, et vous pouvez accéder directement à la table correspondante et utiliser Databend pour interroger. -
Grâce au moteur de format tabulaire ouvert de Databend, vous pouvez facilement gérer des scénarios dans lesquels vous mélangez différentes sources de données et données dans différents formats tabulaires :
- Sous le même objet de base de données, interrogez et analysez des tableaux de données résumés dans différents formats.
- Grâce à la riche intégration du backend de stockage de Databend, vous pouvez gérer les besoins d'accès aux données dans différents backends de stockage.
insuffisant
- Actuellement, les moteurs Apache Iceberg et Delta Lake ne prennent en charge que les opérations en lecture seule, c'est-à-dire qu'ils peuvent uniquement interroger les données mais ne peuvent pas écrire de données dans la table.
- Le schéma de la table est déterminé lors de la création de la table. Si le schéma de la table d'origine est modifié, afin de garantir la cohérence et la synchronisation des données, la table doit être recréée dans Databend.
Instructions
-- Set up connection
CREATE [ OR REPLACE ] CONNECTION [ IF NOT EXISTS ] <connection_name>
STORAGE_TYPE = '<type>'
[ <storage_params> ]
-- Create table with Open Table Format engine
CREATE TABLE <table_name>
ENGINE = [Delta | Iceberg]
LOCATION = '<location_to_table>'
CONNECTION_NAME = '<connection_name>'
Astuce : utilisez-le dans Databend
CONNECTIONpour gérer les détails nécessaires à l'interaction avec les services de stockage externes, tels que les informations d'identification d'accès, les URL des points de terminaison et les types de stockage. En spécifiantCONNECTION_NAME, vous pouvez le réutiliser lors de la création de ressourcesCONNECTION, simplifiant ainsi la gestion et l'utilisation des configurations de stockage.
Comparaison avec la solution Catalogue
Databend prenait auparavant en charge Iceberg et Hive via Catalog. Comparé aux moteurs de table, Catalog est plus adapté à l'écologie complète liée à l'amarrage et au montage de plusieurs bases de données et tables en même temps.
Le nouveau moteur de format de table ouvert est plus flexible en termes d'expérience, prenant en charge l'agrégation et le mélange de données provenant de différentes sources de données et de différents formats de table dans la même base de données, ainsi qu'une analyse et des informations efficaces.
Atelier : Utiliser Databend Cloud pour analyser les données dans Delta Table
Cet exemple montrera comment utiliser Databend Cloud pour charger et analyser une table Delta située dans le stockage d'objets.
Nous utiliserons l'ensemble de données classique sur les caractéristiques du corps des pingouins (pingouins), le convertirons en une table Delta et le placerons dans un stockage d'objets compatible S3. Cet ensemble de données contient un total de 8 variables, dont 7 variables caractéristiques et 1 variable catégorielle, avec un total de 344 échantillons.
- Les variables catégorielles sont les espèces (espèces) de manchots, qui appartiennent à trois sous-genres du genre Hard-tailed Penguin , à savoir Adélie, Chinstrap et Gentoo.
- Les six caractéristiques des trois manchots inclus sont l'île (île), la longueur du bec (bill_length_mm), la profondeur du bec (bill_degree_mm), la longueur des nageoires (flipper_length_mm), le poids corporel (body_mass_g) et le sexe (sexe).
Si vous n'avez pas encore de compte Databend Cloud, veuillez visiter https://app.databend.cn/register pour vous inscrire et obtenir un quota gratuit. Ou vous pouvez vous référer à https://docs.databend.com/guides/deploy/ pour déployer Databend localement.
Cet article couvre également l'utilisation du stockage objet, et vous pouvez également essayer de créer un bucket à l'aide de Cloudflare R2 avec un quota gratuit.
Écrire des données dans le stockage d'objets
Nous devons installer le package Python correspondant, seabornqui est chargé de fournir les données brutes, deltalakede convertir les données en table Delta et de les écrire dans S3 :
pip install deltalake seaborn
Ensuite, modifiez le code ci-dessous, configurez les identifiants d'accès correspondants et enregistrez-le souswritedata.py :
import seaborn as sns
from deltalake.writer import write_deltalake
ACCESS_KEY_ID = '<your-key-id>'
SECRET_ACCESS_KEY = '<your-access-key>'
ENDPOINT_URL = '<your-endpoint-url>'
storage_options = {
"AWS_ACCESS_KEY_ID": ACCESS_KEY_ID,
"AWS_SECRET_ACCESS_KEY": SECRET_ACCESS_KEY,
"AWS_ENDPOINT_URL": ENDPOINT_URL,
"AWS_S3_ALLOW_UNSAFE_RENAME": 'true',
}
penguins = sns.load_dataset('penguins')
write_deltalake("s3://penguins/", penguins, storage_options=storage_options)
Exécutez le script Python ci-dessus pour écrire des données dans le stockage d'objets :
python writedata.py
Accéder aux données à l'aide du moteur de table Delta
Créez les informations d'identification d'accès correspondantes dans Databend :
--Set up connection
CREATE CONNECTION my_r2_conn
STORAGE_TYPE = 's3'
SECRET_ACCESS_KEY = '<your-access-key>'
ACCESS_KEY_ID = '<your-key-id>'
ENDPOINT_URL = '<your-endpoint-url>';
Créez une table de données alimentée par le moteur de table Delta :
-- Create table with Open Table Format engine
CREATE TABLE penguins
ENGINE = Delta
LOCATION = 's3://penguins/'
CONNECTION_NAME = 'my_r2_conn';
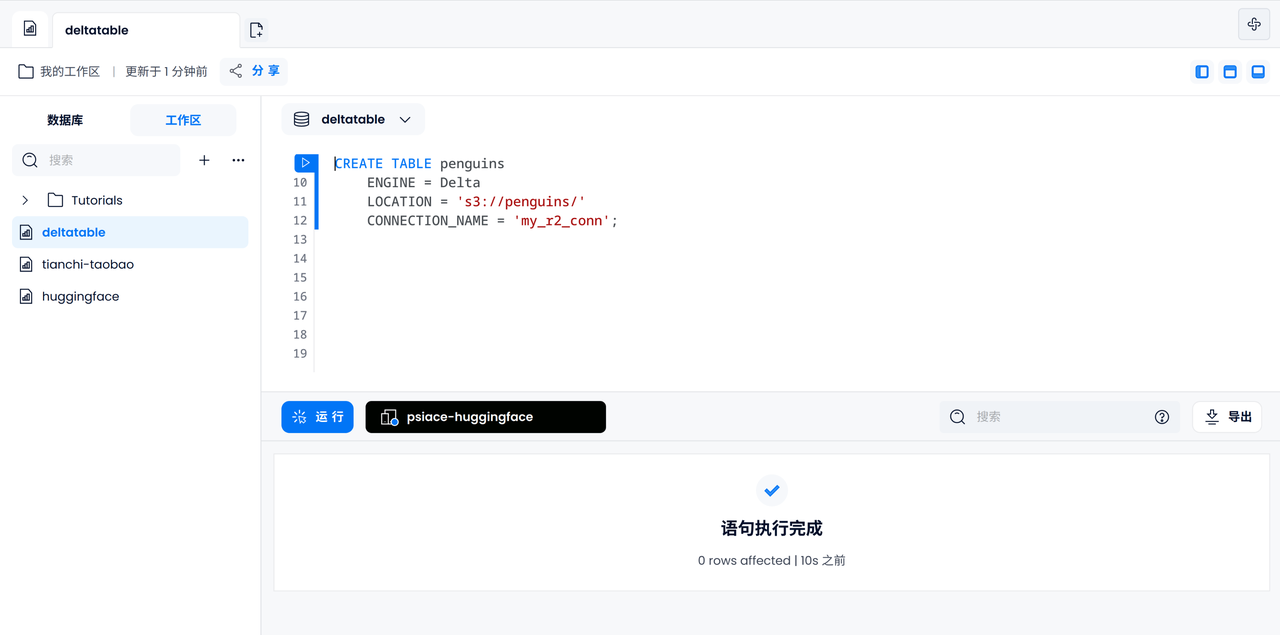
Utiliser SQL pour interroger et analyser les données dans des tableaux
Vérifier l'accessibilité des données
Commençons par afficher les types et les îles des 5 pingouins pour vérifier si les données de la table Delta sont accessibles correctement.
SELECT species, island FROM penguins LIMIT 5;
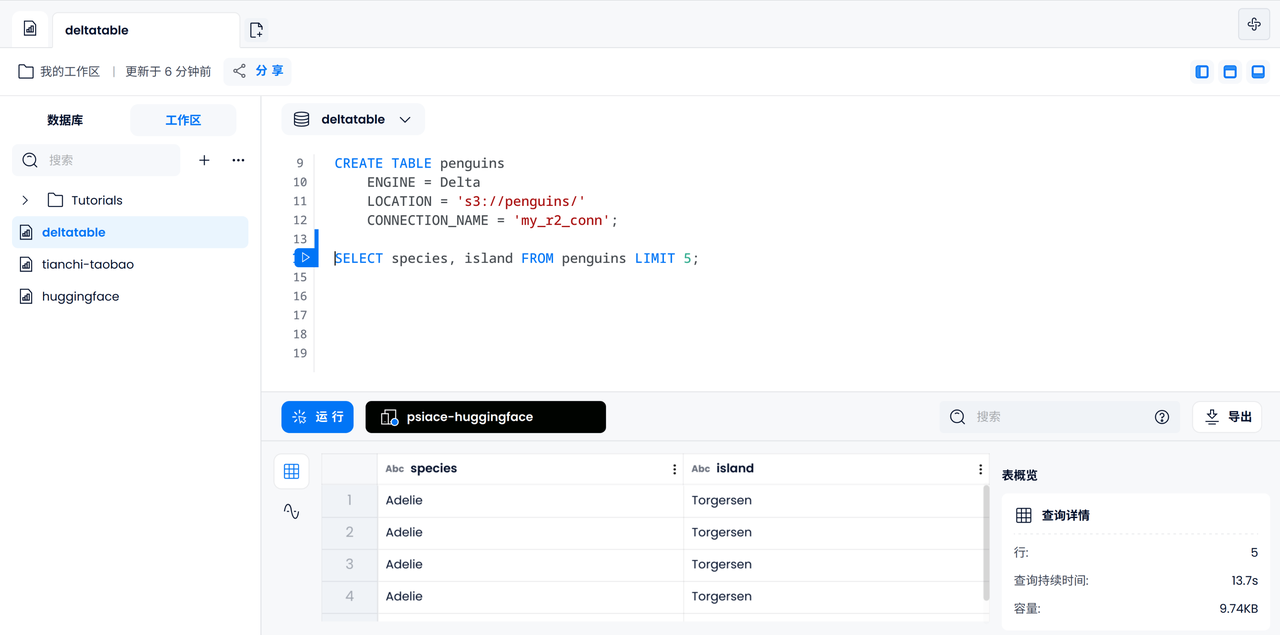
Filtrage des données
Ensuite, vous pouvez effectuer certaines opérations de filtrage de données de base, telles que découvrir à quel sous-genre les manchots mâles avec des longueurs de nageoires supérieures à 210 mm peuvent appartenir.
SELECT DISTINCT species
FROM penguins
WHERE sex = 'Male'
AND flipper_length_mm > 210;
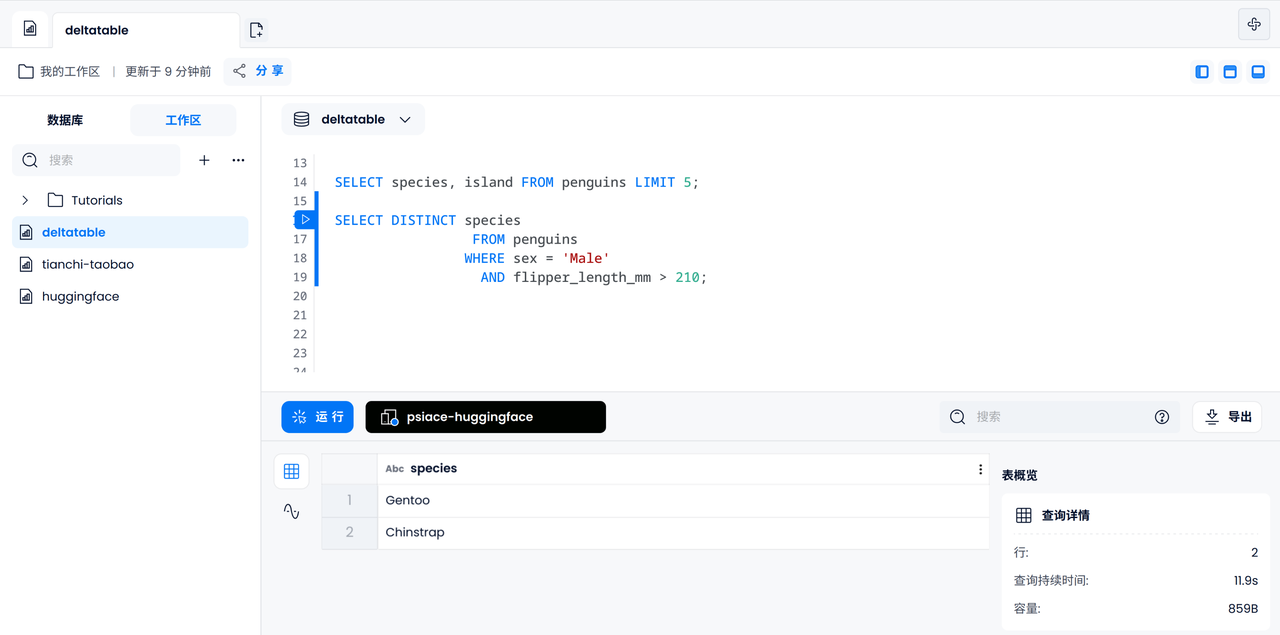
l'analyse des données
De même, nous pourrions essayer de calculer le rapport entre la longueur et la profondeur du bec pour chaque pingouin et extraire les cinq plus grands.
SELECT bill_length_mm / bill_depth_mm AS length_to_depth
FROM penguins
ORDER BY length_to_depth DESC
LIMIT 5;
Cas de sources de données mixtes : journal d'observation des manchots
Nous allons maintenant aborder une partie intéressante : supposons que nous trouvions un enregistrement d'observation provenant d'une station de recherche scientifique, essayons de saisir ces données dans la même base de données et essayons de procéder à une analyse simple des données : un oiseau d'un sexe spécifique. probabilité qu'un pingouin soit marqué par un scientifique.
Créer un tableau de journal d'observation
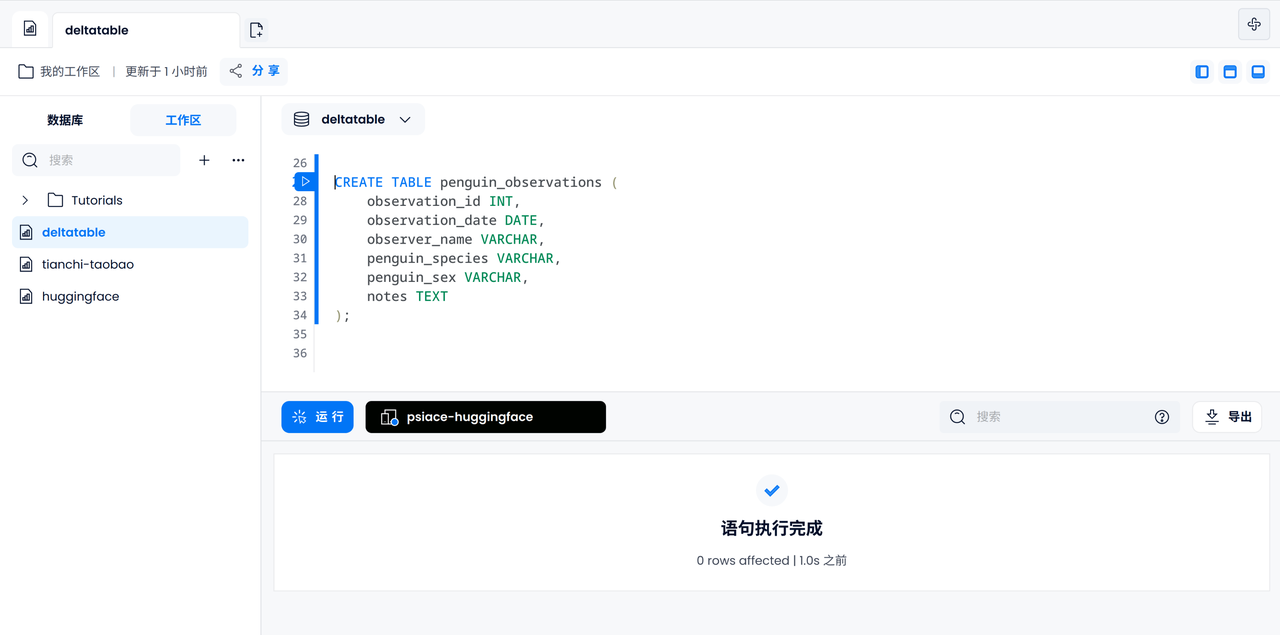
Utilisez le moteur FUSE par défaut pour créer penguin_observationsun tableau comprenant l'ID, la date, le nom, l'espèce et le sexe du manchot, des remarques et d'autres informations.
CREATE TABLE penguin_observations (
observation_id INT,
observation_date DATE,
observer_name VARCHAR,
penguin_species VARCHAR,
penguin_sex VARCHAR,
notes TEXT,
);
Entrer le journal d'observation
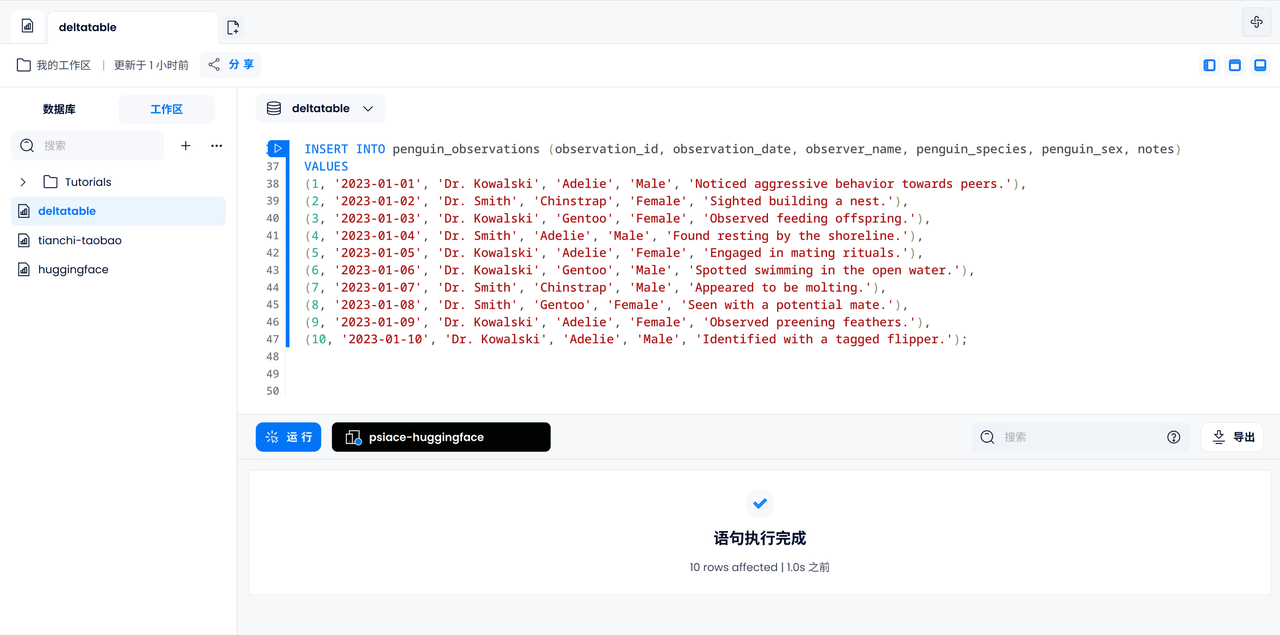
Essayons de saisir manuellement les 10 journaux. Les manchots apparaissant dans les journaux de bord sont connus pour être différents les uns des autres.
INSERT INTO penguin_observations (observation_id, observation_date, observer_name, penguin_species, penguin_sex, notes)
VALUES
(1, '2023-01-01', 'Dr. Kowalski', 'Adelie', 'Male', 'Noticed aggressive behavior towards peers.'),
(2, '2023-01-02', 'Dr. Smith', 'Chinstrap', 'Female', 'Sighted building a nest.'),
(3, '2023-01-03', 'Dr. Kowalski', 'Gentoo', 'Female', 'Observed feeding offspring.'),
(4, '2023-01-04', 'Dr. Smith', 'Adelie', 'Male', 'Found resting by the shoreline.'),
(5, '2023-01-05', 'Dr. Kowalski', 'Adelie', 'Female', 'Engaged in mating rituals.'),
(6, '2023-01-06', 'Dr. Kowalski', 'Gentoo', 'Male', 'Spotted swimming in the open water.'),
(7, '2023-01-07', 'Dr. Smith', 'Chinstrap', 'Male', 'Appeared to be molting.'),
(8, '2023-01-08', 'Dr. Smith', 'Gentoo', 'Female', 'Seen with a potential mate.'),
(9, '2023-01-09', 'Dr. Kowalski', 'Adelie', 'Female', 'Observed preening feathers.'),
(10, '2023-01-10', 'Dr. Kowalski', 'Adelie', 'Male', 'Identified with a tagged flipper.');
Calculer la probabilité de marquage
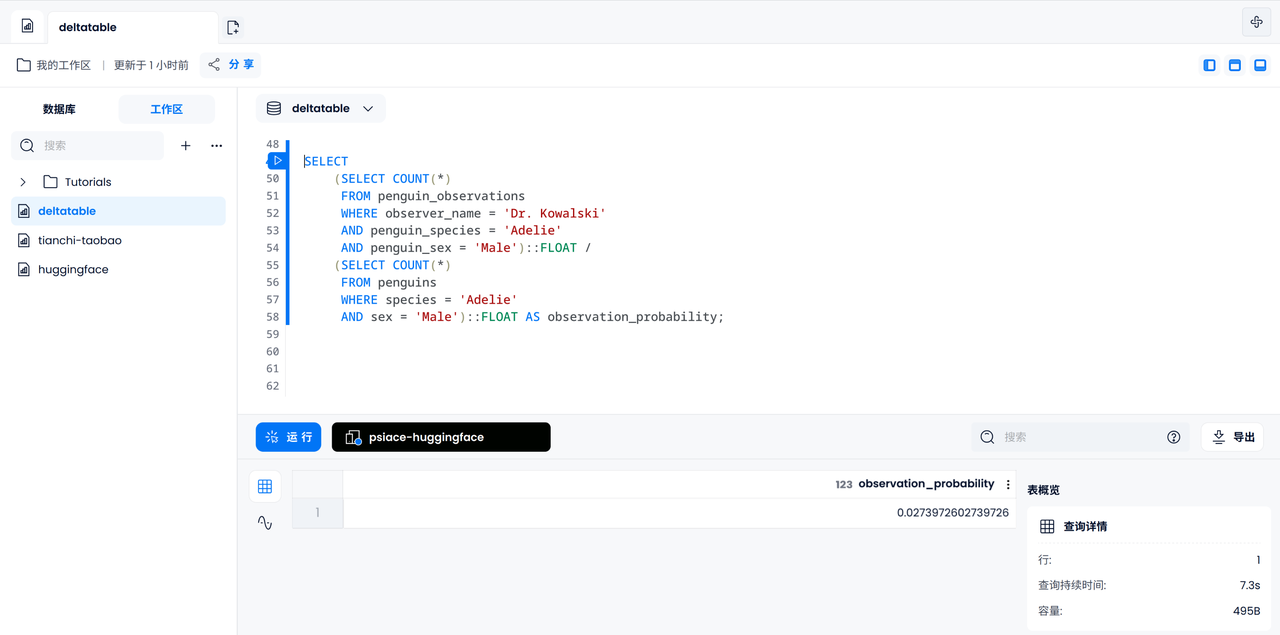
Calculons maintenant la probabilité qu'un certain manchot Adélie mâle soit observé par le Dr Kowalski parmi tous les manchots. Nous devons d’abord compter le nombre de manchots Adélie mâles observés par le Dr Kowalski, puis compter le nombre de manchots Adélie mâles enregistrés et enfin diviser pour obtenir le résultat.
SELECT
(SELECT COUNT(*)
FROM penguin_observations
WHERE observer_name = 'Dr. Kowalski'
AND species = 'Adelie'
AND sex = 'Male')::FLOAT /
(SELECT COUNT(*)
FROM penguins
WHERE species = 'Adelie'
AND sex = 'Male')::FLOAT AS observation_probability;
Résumer
En combinant différents moteurs de table pour les requêtes, Databend / Databend Cloud peut prendre en charge le mélange de tables de différents formats sous la même base de données pour l'analyse et les requêtes. Cet article fournit uniquement un atelier de base permettant à chacun de découvrir les fonctions et l'utilisation. Vous êtes invités à développer la base de ce cas et à explorer davantage de scénarios de combinaison d'Iceberg et de Delta Table pour l'analyse de données, ainsi que d'autres applications potentielles dans le monde réel.
Lecture recommandée
- Documents | Moteur de table Apache Iceberg
- Documents | Moteur de table Delta Lake
- Documents | Connexion