
Spark est un moteur de calcul Big Data rapide, polyvalent et évolutif . Il présente les avantages de hautes performances, de facilité d'utilisation, de tolérance aux pannes, d'intégration transparente avec l'écosystème Hadoop et d'activité communautaire élevée. En utilisation réelle, il offre un large éventail de scénarios d’application :
· Nettoyage et prétraitement des données : dans les scénarios d'analyse du Big Data, les données nécessitent généralement des opérations de nettoyage et de prétraitement pour garantir la qualité et la cohérence des données. Spark fournit une API riche qui peut nettoyer, filtrer, transformer et d'autres opérations sur les données.
· Analyse de traitement par lots : Spark convient aux tâches de traitement par lots dans divers scénarios d'application, notamment l'analyse statistique, l'exploration de données, l'extraction de fonctionnalités, etc. Les utilisateurs peuvent utiliser la puissante API de Spark et les bibliothèques intégrées pour effectuer un traitement et une analyse de données complexes pour extraire des données. valeur intrinsèque dans
· Requête interactive : Spark fournit le module Spark SQL qui prend en charge les requêtes SQL . Les utilisateurs peuvent utiliser des instructions SQL standard pour des requêtes interactives et des analyses de données à grande échelle.
L'utilisation de Spark dans Kangaroo Cloud
Dans la plateforme de développement hors ligne Kangaroo Cloud Stack , nous proposons trois façons d'utiliser Spark :
● Créer des tâches Spark SQL
Les utilisateurs peuvent implémenter leur propre logique métier directement en écrivant du SQL. Cette méthode est actuellement la méthode la plus largement utilisée pour utiliser Spark sur la plate-forme hors ligne de la pile de données, et c'est également la méthode la plus recommandée.
● Créer une tâche Spark Jar
Les utilisateurs doivent utiliser le langage Scala ou Java pour implémenter la logique métier sur IDEA, puis compiler et empaqueter le projet, télécharger le package Jar résultant sur la plate-forme hors ligne, puis référencer ce package Jar lors de la création d'une tâche Spark Jar et enfin soumettre la tâche. accédez à l'exécution planifiée.
Pour les exigences difficiles à atteindre ou à exprimer à l'aide de SQL, ou pour les utilisateurs ayant d'autres exigences plus profondes, les tâches Spark Jar offrent sans aucun doute aux utilisateurs une manière plus flexible d'utiliser Spark.
● Créer des tâches PySpark
Les utilisateurs peuvent écrire directement le code Python correspondant . Parmi notre clientèle, il existe un certain nombre de clients pour lesquels, en plus de SQL, Python peut être le langage principal. Surtout pour les utilisateurs disposant de certaines bases d'analyse de données et d'algorithmes, ils effectuent souvent une analyse plus approfondie des données traitées. À l'heure actuelle, les tâches PySpark sont naturellement leur meilleur choix.
Spark joue un rôle important dans la plate-forme de développement hors ligne Kangaroo Cloud Data Stack . Par conséquent, nous avons apporté de nombreuses optimisations internes à Spark pour permettre aux clients de soumettre plus facilement des tâches à l'aide de Spark. Nous avons également créé des outils basés sur Spark pour améliorer les fonctionnalités de l'ensemble de la plateforme de développement hors ligne de la pile de données.
De plus, Spark joue également un rôle très important dans le scénario du lac de données. Le module Lake et Warehouse intégré de Kangaroo Cloud prend déjà en charge deux lacs de données majeurs, Iceberg et Hudi. Les utilisateurs peuvent utiliser Spark pour lire et écrire des tables Lake. La couche inférieure de gestion des tables Lake est également implémentée en utilisant Spark pour appeler différentes procédures stockées.
Ce qui suit expliquera l'optimisation effectuée dans Kangaroo Cloud, à la fois du côté du moteur et de Spark lui-même.
Optimisation côté moteur
Les fonctions du moteur interne de Kangaroo Cloud sont principalement utilisées pour la soumission de tâches, l'acquisition de l'état des tâches, l'acquisition du journal des tâches, l'arrêt des tâches, la vérification de la syntaxe, etc. Nous avons optimisé chaque point de fonction à des degrés divers. Ce qui suit est une brève introduction à travers deux exemples.
Vitesse de soumission de Spark on Yarn améliorée
Avec le développement et l'amélioration continus de nouvelles fonctions sur le plug-in Spark côté moteur, le temps nécessaire au côté moteur pour soumettre les tâches Spark augmente également en conséquence. Par conséquent, le code lié à la soumission des tâches Spark doit être optimisé pour. Réduisez le délai de soumission des tâches Spark. Améliorez l'expérience utilisateur.
À cette fin, nous avons effectué le travail suivant pour certains fichiers de configuration courants, tels que core-site.xml, fil-site.xml, fichier keytab, spark-sql-application.jar, etc., il s'avère que chacun. Chaque fois que vous soumettez une tâche, vous devez la télécharger à partir du serveur. Le serveur télécharge et soumet ces fichiers de configuration. Désormais, après l'optimisation, le fichier ci-dessus ne doit être téléchargé qu'une seule fois lorsque le client SparkYarnClient est initialisé, puis téléchargé sur le chemin HDFS spécifié. La soumission ultérieure des tâches Spark ne doit être spécifiée que sur le chemin HDFS correspondant via les paramètres. De cette manière, le temps de soumission de chaque tâche Spark est considérablement raccourci.
Dans la nouvelle version de la pile de données, pour les requêtes temporaires , nous jugerons également de la complexité du SQL à exécuter en fonction de règles personnalisées, et enverrons le SQL le moins complexe au SparkSQLEngine démarré côté moteur pour accélérer l'opération. Ce SparkSQLEngine interne n'était utilisé que pour la vérification de la syntaxe dans le passé, mais il assume désormais également une partie de la fonction d'exécution SQL, et SparkSQLEngine peut également étendre et contracter dynamiquement les ressources en fonction de la situation d'exécution globale pour obtenir une utilisation efficace des ressources.
Vérification grammaticale
Dans les anciennes versions de la pile de données, pour la vérification de la syntaxe du SQL, le moteur enverra d'abord le SQL au Spark Thrift Server. Ce Spark Thrift Server est déployé en mode local et n'est pas uniquement utilisé pour la vérification de la syntaxe. Toutes les métadonnées sur d'autres plates-formes sont obtenues en envoyant du SQL à ce Spark Thrift Server pour exécution. Cette méthode présente des inconvénients majeurs, nous avons donc procédé à quelques optimisations. Une tâche Spark est démarrée en mode local côté moteur . Lors de la vérification de la syntaxe, le SQL n'est plus envoyé au Spark Thrift Server. Au lieu de cela, une SparkSession est maintenue en interne pour effectuer directement la vérification de la syntaxe sur le SQL.
Bien que cette méthode ne nécessite pas une connexion solide avec le serveur Spark Thrift externe, elle exercera une certaine pression sur le composant de planification, et la complexité globale des Engine-Plugins augmentera également considérablement au cours du processus de mise en œuvre.
Afin d'optimiser les problèmes ci-dessus, nous avons procédé à une optimisation supplémentaire. Lorsque le composant de planification est démarré, il soumet une tâche Spark SparkSQLEngine à Yarn. Il peut être compris comme un serveur Spark Thrift distant fonctionnant sur Yarn. Le côté moteur surveille à tout moment l'état de santé de SparkSQLEngine . De cette manière, chaque fois qu'une vérification de la syntaxe est effectuée, le moteur envoie du SQL à SparkSQLEngine via JDBC pour la vérification de la syntaxe.
Grâce à l'optimisation ci-dessus, la plate-forme de développement hors ligne est découplée du Spark Thrift Server. EasyManager n'a pas besoin de déployer un Spark Thrift Server supplémentaire, ce qui rend le déploiement plus léger. Il n’est pas nécessaire de maintenir un processus résident Spark en mode local du côté de la planification. Il ouvre également la voie à l'amélioration interactive des requêtes des tâches Spark SQL sur la plateforme de développement hors ligne.
Le découplage de la plateforme de développement hors ligne du Spark Thrift Server déployé par EasyManager apportera les avantages suivants :
· Capable de véritablement réaliser la coexistence de plusieurs clusters Spark et de plusieurs versions
· Le déploiement standard d'EasyManager peut supprimer Spark Thrift Server et réduire la charge sur l'exploitation et la maintenance de première ligne
· La vérification de la syntaxe Spark SQL devient plus légère, pas besoin de mettre en cache SparkContext, ce qui réduit l'utilisation des ressources du moteur
Optimisation de la fonction Spark
Au fur et à mesure que l'entreprise se développe, nous constatons que Spark open source ne dispose pas d'implémentations fonctionnelles correspondantes dans certains scénarios. Par conséquent, nous avons développé davantage de nouveaux plug-ins basés sur l'open source Spark pour prendre en charge des applications plus fonctionnelles de la pile de données.
Diagnostic des missions
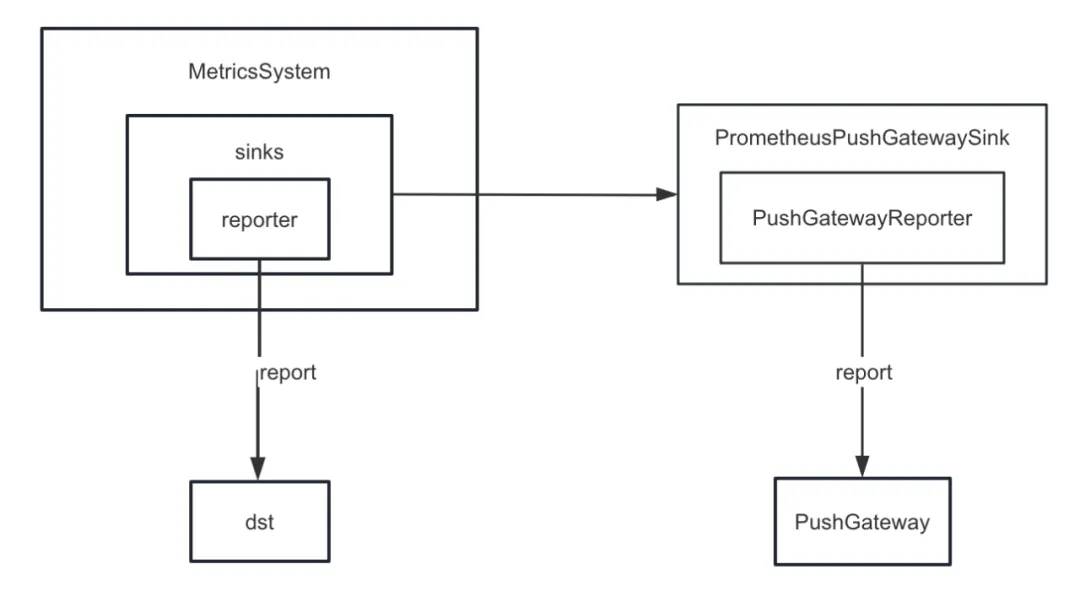
Tout d’abord, nous avons amélioré le récepteur métrique de Spark. Spark fournit divers récepteurs en interne En plus de ConsoleSink, il existe également CSVSink, JmxSink, MetricsServlet, GraphiteSink, Slf4jSink, StatsdSink, etc. PrometheusServlet a également été ajouté après Spark3.0, mais ceux-ci ne peuvent pas répondre à nos besoins.
Lors du développement de la fonction de diagnostic des tâches , nous devons pousser les indicateurs internes de Spark vers PushGateway de manière unifiée, et le serveur Prometheus extrait périodiquement les indicateurs de PushGateway. Enfin, en appelant l'interface de requête fournie par Prometheus, nous pouvons interroger l'interne. indicateurs de Spark en temps quasi réel.

Mais Spark n’implémente pas d’indicateurs internes descendants dans PushGateway. Par conséquent, nous avons ajouté le plug-in spark-prometheus-sink et personnalisé PrometheusPushGatewaySink pour transmettre les indicateurs internes de Spark à PushGateway.
De plus, nous avons également personnalisé un nouvel indicateur pour décrire la progression de l'exécution des tâches d'affichage des requêtes temporaires Spark SQL. Les étapes spécifiques sont les suivantes :
· Ajoutez un indicateur pour décrire la progression des tâches hors ligne en personnalisant JobProgressSource et enregistrez l'indicateur dans le système de gestion des indicateurs du système de gestion interne de Spark.
· Personnalisez le JobProgressListener et enregistrez le JobProgressListener auprès du ListenerBus dans le système de gestion interne Spark. Parmi eux, la logique de la méthode onJobStart de JobProgressListener consiste à calculer le nombre de toutes les tâches sous le travail actuel ; la logique de la méthode onTaskEnd consiste à calculer et à mettre à jour la progression actuelle de la tâche hors ligne une fois la logique terminée ; La méthode onJobEnd consiste à calculer et à mettre à jour la progression actuelle de la tâche hors ligne une fois chaque tâche terminée. Mettre à jour la progression actuelle de la tâche hors ligne.
Connexion à la version commerciale du cluster Hadoop
À mesure que le nombre de clients Kangaroo Cloud augmente, leurs environnements varient également. Certains clients utilisent la version open source des clusters Hadoop, et un nombre considérable de clients utilisent HDP, CDH, CDP, TDH, etc. Lorsque nous nous connectons aux clusters de ces clients, le côté développement doit souvent procéder à de nouvelles adaptations, et le côté exploitation et maintenance doit également configurer des paramètres supplémentaires ou effectuer d'autres opérations supplémentaires à chaque fois qu'il est déployé et mis à niveau.
En prenant HDP comme exemple, lors de la connexion à HDP, le Spark que nous utilisons est Spark2.3 fourni avec HDP, et nous devons également ajouter quelques paramètres du côté de l'exploitation et de la maintenance et déplacer tous les packages Jar de Spark fournis avec HDP. pour spécifier le répertoire. Ces opérations entraîneront en fait une certaine confusion et des problèmes dans l'exploitation et la maintenance. Différents types de clusters doivent conserver différents documents d'exploitation et de maintenance, et le processus de déploiement est également plus sujet aux erreurs. Et nous avons en fait apporté des améliorations fonctionnelles et des corrections de bugs au code source de Spark. Si vous utilisez le Spark fourni avec HDP, vous ne pourrez pas profiter de tous les avantages de notre Spark maintenu en interne.
Afin de résoudre les problèmes ci-dessus, notre Spark interne a été adapté aux éditeurs existants et courants sur le marché existant. En d’autres termes, notre Spark interne peut fonctionner sur tous les différents clusters Hadoop. De cette façon, quel que soit le type de cluster Hadoop connecté, l'exploitation et la maintenance n'ont besoin que de déployer le même Spark, ce qui réduit considérablement la pression du déploiement de l'exploitation et de la maintenance. Plus important encore, les clients peuvent utiliser directement notre version stable interne de Spark pour profiter de davantage de nouvelles fonctionnalités et de plus grandes améliorations de performances.
Nouvelles fonctionnalités de Spark3.2-AQE
Dans les anciennes versions de Data Stack, la version par défaut de Spark est 2.1.3. Plus tard, nous avons mis à niveau la version de Spark vers 2.4.8. À partir de Data Stack 6.0, Spark 3.2 peut également être utilisé. Ici, nous nous concentrons sur AQE , qui est également la nouvelle fonctionnalité la plus importante de Spark3.x.
AQE - Vue d’ensemble
Avant Spark3.2, AQE était désactivé par défaut. Vous devez définir spark.sql.adaptive.enabled sur true pour activer AQE. Après Spark3.2, AQE est activé par défaut Tant que la tâche remplit les conditions de déclenchement d'AQE pendant le fonctionnement, vous pouvez profiter de l'optimisation apportée par AQE.
Il convient de noter que l'optimisation d'AQE ne se produira que dans la phase de lecture aléatoire. Si l'opération de lecture aléatoire n'est pas impliquée dans le processus en cours d'exécution de SQL, AQE ne jouera pas de rôle même si la valeur de spark.sql.adaptive.enabled est égale à . vrai. Plus précisément, l'AQE ne prendra effet que si le plan d'exécution physique contient un nœud d'échange ou contient une sous-requête.
Pendant le fonctionnement, AQE collecte les informations des fichiers intermédiaires générés lors de l'étape de lecture aléatoire, collecte des statistiques sur ces informations et ajuste dynamiquement le plan logique optimisé et le plan Spark qui n'ont pas encore été exécutés sur la base des règles existantes, modifiant ainsi l'original. Instruction SQL. Optimisation de l'exécution.
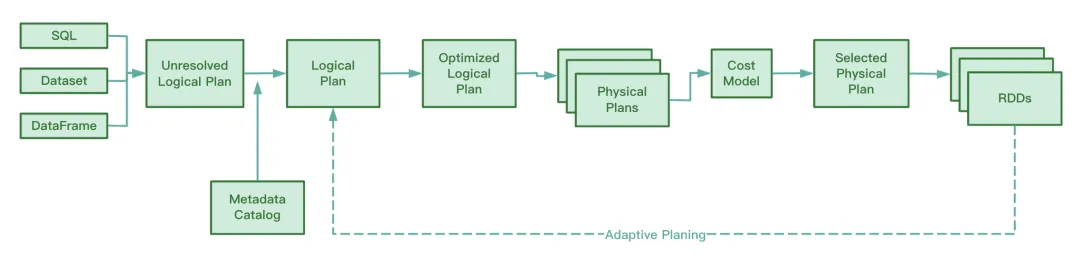
À en juger par le code source de Spark, AQE implique les quatre règles d'optimisation suivantes :

Nous savons que RBO optimise SQL en fonction d'une série de règles, notamment le refoulement des prédicats, l'élagage des colonnes, le remplacement constant, etc. Ces règles statiques elles-mêmes ont été intégrées à Spark Lorsque Spark exécute SQL, ces règles seront appliquées au SQL une par une.
Avantages de l'AQE
Cette fonctionnalité de CBO n'est disponible qu'après Spark2.2. Par rapport à RBO, CBO combinera les informations statistiques du tableau et sélectionnera un plan d'exécution plus optimisé en fonction de ces informations statistiques et du modèle de coût.
Cependant, CBO ne prend en charge que les tables enregistrées sur Hive Metastore. CBO ne prend pas en charge les fichiers tels que parquet et orc stockés dans des systèmes de fichiers distribués. De plus, si la table Hive ne dispose pas d'informations de métadonnées, CBO ne pourra pas collecter de statistiques lors de la collecte de statistiques, ce qui pourrait entraîner l'échec de CBO.
Un autre inconvénient de CBO est que CBO doit exécuter ANALYZE TABLE COMPUTE STATISTICS pour collecter des informations statistiques avant l'optimisation. Si cette instruction rencontre une table volumineuse lors de l'exécution, cela prendra plus de temps et l'efficacité de la collecte sera faible.
Qu'il s'agisse de CBO ou de RBO, ce sont des optimisations statiques. Une fois le plan d'exécution physique soumis, si le volume et la distribution des données changent pendant l'exécution de la tâche, CBO n'optimisera pas le plan d'exécution physique existant.
Différent du CBO et du RBO, pendant le processus en cours, AQE analysera les fichiers intermédiaires générés pendant le processus de lecture aléatoire, et ajustera et optimisera dynamiquement le plan d'exécution logique et le plan d'exécution physique qui n'ont pas encore commencé l'exécution par rapport au CBO optimisé statiquement. , Par rapport à RBO, le traitement AQE permet d'obtenir un plan d'exécution physique plus optimisé .
AQE trois fonctionnalités majeures
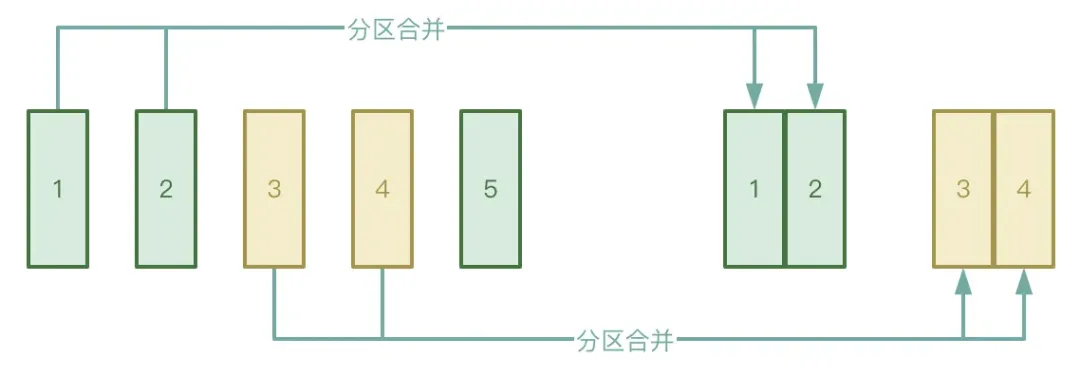
● Fusion automatique des partitions
Le processus Shuffle est divisé en deux étapes : l'étape Map et l'étape Réduire. L'étape Réduire extraira les fichiers temporaires intermédiaires générés lors de l'étape Map vers l'exécuteur correspondant. Si les données traitées par l'étape Map sont très inégalement réparties, il y en a beaucoup. clés. En fait, il n'y a que quelques clés, les données peuvent former un grand nombre de petits fichiers après traitement.
Afin d'éviter la situation ci-dessus, vous pouvez activer la fonction de fusion automatique de partitions d'AQE pour éviter de démarrer trop de tâches de réduction pour extraire les petits fichiers générés lors de l'étape Map.
● Traitement automatique du biais de données
Le scénario d'application concerne principalement les jointures de données. Lorsqu'une asymétrie des données se produit, AQE peut détecter automatiquement la partition asymétrique et diviser la partition asymétrique selon certaines règles. Actuellement, dans Spark3.2, le traitement automatique de l'asymétrie des données est pris en charge pour SortMergeJoin et ShuffleHashJoin.
● Rejoignez l'ajustement de la stratégie
AQE rétrogradera dynamiquement la jointure de hachage et la jointure de fusion de tri en jointure de diffusion.
Nous savons qu'une fois qu'une tâche Spark commence à s'exécuter, le degré de parallélisme est déterminé. Par exemple, dans l'étape shuffle map , le parallélisme est le nombre de partitions ; dans l'étape shuffle reduction, le parallélisme est la valeur de spark.sql.shuffle.partitions, qui est par défaut 200. Si la quantité de données diminue pendant l'exécution de la tâche Spark, entraînant une diminution de la taille de la plupart des partitions, cela entraînera un gaspillage de ressources si autant de threads sont encore démarrés pour traiter le petit ensemble de données.
Pendant le processus d'exécution, AQE fusionnera automatiquement les partitions en fonction des résultats temporaires intermédiaires générés après la lecture aléatoire, et sous certaines conditions, en appliquant les règles CoalesceShufflePartitions et en combinant les paramètres fournis par l'utilisateur, ce qui ajuste en fait le nombre de réducteurs. À l'origine, un thread de réduction n'extrait que les données d'une partition traitée. Désormais, un thread de réduction extraira les données de plusieurs partitions en fonction de la situation réelle, ce qui peut réduire le gaspillage de ressources et améliorer l'efficacité de l'exécution des tâches. Adresse de téléchargement du « Livre blanc sur le système d'indicateurs industriels » : https://www.dtstack.com/resources/1057?src=szsm
Adresse de téléchargement du « Livre blanc sur les produits Dutstack » : https://www.dtstack.com/resources/1004?src=szsm
Adresse de téléchargement du « Livre blanc sur les pratiques de l'industrie de la gouvernance des données » : https://www.dtstack.com/resources/1001?src=szsm
Pour ceux qui souhaitent en savoir ou en savoir plus sur les produits Big Data, les solutions industrielles et les cas clients, visitez le site officiel de Kangaroo Cloud : https://www.dtstack.com/?src=szkyzg
J'ai décidé d'abandonner l'open source Hongmeng Wang Chenglu, le père de l'open source Hongmeng : L'open source Hongmeng est le seul événement logiciel industriel d'innovation architecturale dans le domaine des logiciels de base en Chine - OGG 1.0 est publié, Huawei contribue à tout le code source. Google Reader est tué par la "montagne de merde de code" Fedora Linux 40 est officiellement publié Ancien développeur Microsoft : les performances de Windows 11 sont "ridiculement mauvaises" Ma Huateng et Zhou Hongyi se serrent la main pour "éliminer les rancunes" Des sociétés de jeux bien connues ont publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans Ubuntu 24.04 LTS officiellement publié Pinduoduo a été condamné pour concurrence déloyale Indemnisation de 5 millions de yuans