
En tant que moteur de recherche distribué, ES est inégalé en termes de capacités d'extension et de fonctionnalités de recherche. Cependant, en tant que système de stockage en temps quasi réel, ses principes de conception de partitionnement et de réplication le rendent également incapable de rivaliser avec OLTP. (Online Transaction Processing) en termes de latence et de cohérence des données.
Pour cette raison, ses données sont généralement synchronisées à partir d’autres systèmes de stockage à des fins de filtrage et d’analyse secondaires. Ceci introduit un nœud clé, c'est-à-dire la méthode d'écriture synchrone des données ES. Cet article présente la méthode ES synchrone MySQL.
Lors de l'écriture de données MySQL sur ES, la première chose qui vient à l'esprit doit être de consommer Binlog et d'écrire directement sur ES. Cependant, si vous considérez plus de dimensions, vous découvrirez certains inconvénients de cette méthode. Par conséquent, il existe une autre méthode, à savoir l'écologie intégrée
[RocketMQ
+ Flink Consumer + ES Bulk]. Nous évaluerons ces deux méthodes d'accès sous quatre aspects : le délai de synchronisation, les caractéristiques de consommation, les performances d'écriture ES et la tolérance aux catastrophes du système Cela inspirez tout le monde et choisissez la méthode de synchronisation qui convient à votre entreprise.
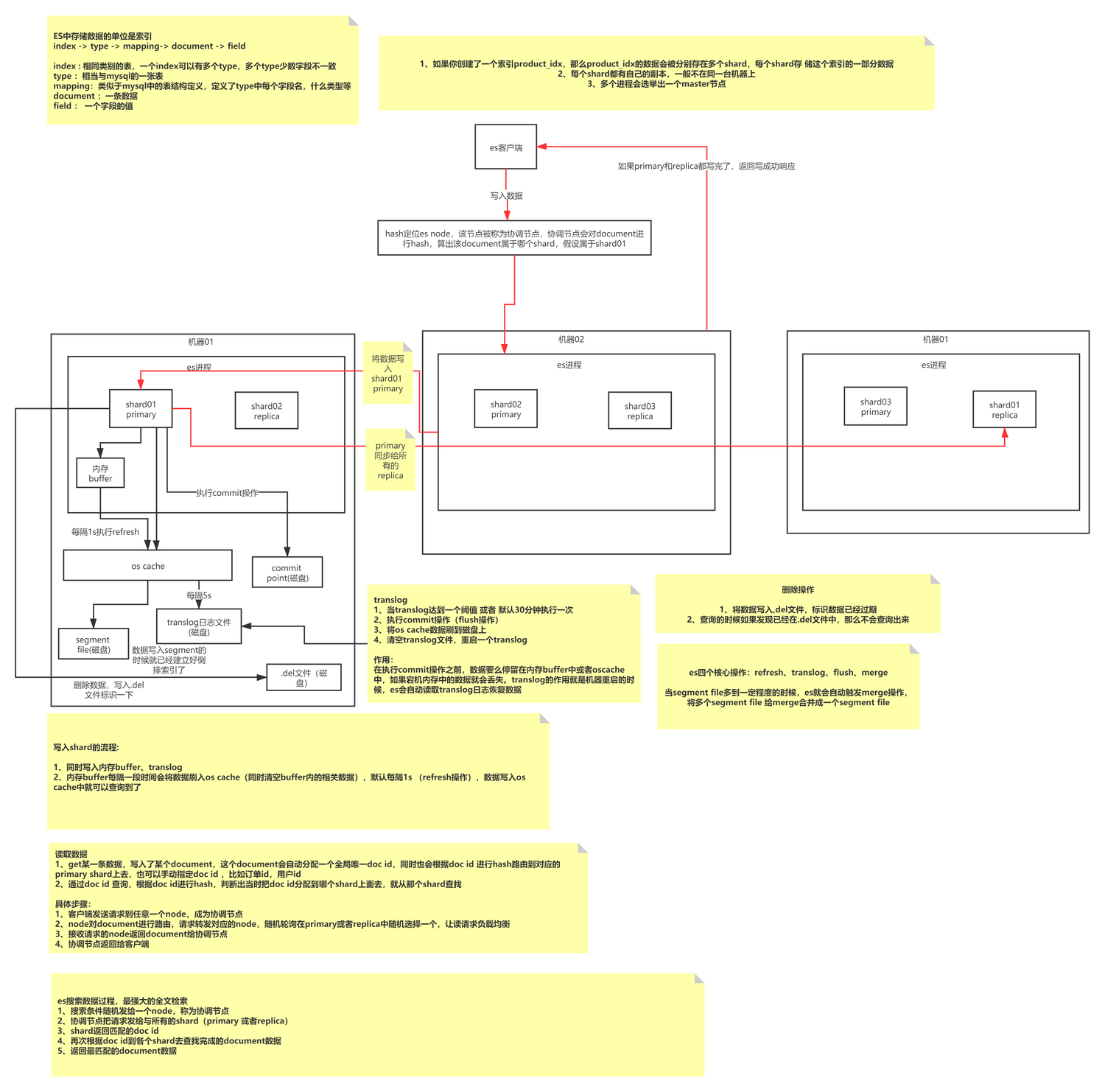
Principes d'écriture de base ES
L'écriture ES est un processus d'écriture de type ajout qui forme d'abord des segments d'une taille spécifique, puis fusionne périodiquement de petits segments de données en grands segments de données pour réduire la fragmentation de la mémoire et améliorer l'efficacité des requêtes. Un index se compose de N fragments et de leurs copies. Il stocke des documents du même type. Sa méthode d'indexation est définie par mappage. Chaque fragment est composé de N segments. Chaque fragment est un index Lucene entièrement fonctionnel et complet. l'unité de traitement de ES ; le segment est la plus petite unité de traitement de données de ES, et chaque segment est un index inversé indépendant.
L'écriture ES écrit en continu des données sur le même segment (mémoire), puis déclenche l'actualisation pour actualiser le segment dans le cache du système d'exploitation (1 s par défaut). À ce stade, les données peuvent être interrogées et le cache du système d'exploitation déclenchera le vidage par le système d'exploitation. . Les opérations sont conservées sur le disque.
Cela vous fait réfléchir : comment ES garantit-il que les données ne sont pas perdues ? Quels sont les avantages et les inconvénients de l’écriture en annexe ? Comment l’écriture d’ajout gère-t-elle les problèmes de mise à jour des données ? À quelle méthode d’écriture MySQL appartient-il ? L’objet de cet article n’est pas ici, vous pouvez lire l’article séparément.

Concepts de base ES
ES écriture directe

L'avantage de l'utilisation de l'écriture à connexion directe ES est que le chemin est court et qu'il y a peu de composants dépendants. De plus, Dsyncer (système de conversion de stockage hétérogène) fournit généralement un mécanisme complet de nouvelle tentative de limitation de courant, de sorte que le délai de consommation et l'intégrité des données de consommation sont tous deux. Garanti.
défaut:
-
Il n'est pas facile d'accéder au déploiement de reprise après sinistre dans plusieurs salles informatiques. Actuellement, les salles informatiques de reprise après sinistre ES sont toutes déployées indépendamment et en mode lecture et écriture indépendant. Par conséquent, si cette méthode est adoptée, il sera difficile de contrôler les écritures. plusieurs salles informatiques en même temps, et l'effet de reprise après sinistre ne sera pas obtenu. Binlog-->Dsyncer Habituellement, une table MySQL correspond à une tâche de conversion. Si vous démarrez plusieurs tâches de conversion répétées afin d'écrire dans plusieurs salles informatiques, cela semble un peu stupide.
-
Si votre propre scénario commercial implique l'écriture simultanée du même enregistrement, mais que les écritures ne proviennent pas toutes de Binlog, il est plus probable que vous rencontriez des conflits d'écriture si vous envisagez l'écriture directe sur ES de manière globale, car il n'y a aucune garantie d'une file d'attente ordonnée.
Construire un système intégré ES via Flink

Flink construit un système intégré ES, ce qui signifie que toutes les écritures ES sont effectuées par des tâches Flink surveille les flux de données en temps réel de RocketMQ, ce qui garantit non seulement l'ordre des partitions de données, mais utilise également pleinement les capacités d'écriture par lots d'ES. La capacité d'écriture par lots est plusieurs fois supérieure aux performances d'écriture unique. Dans le même temps, grâce à la tolérance aux pannes de Flink lui-même, la cohérence ultime des données peut être garantie même dans des scénarios anormaux.
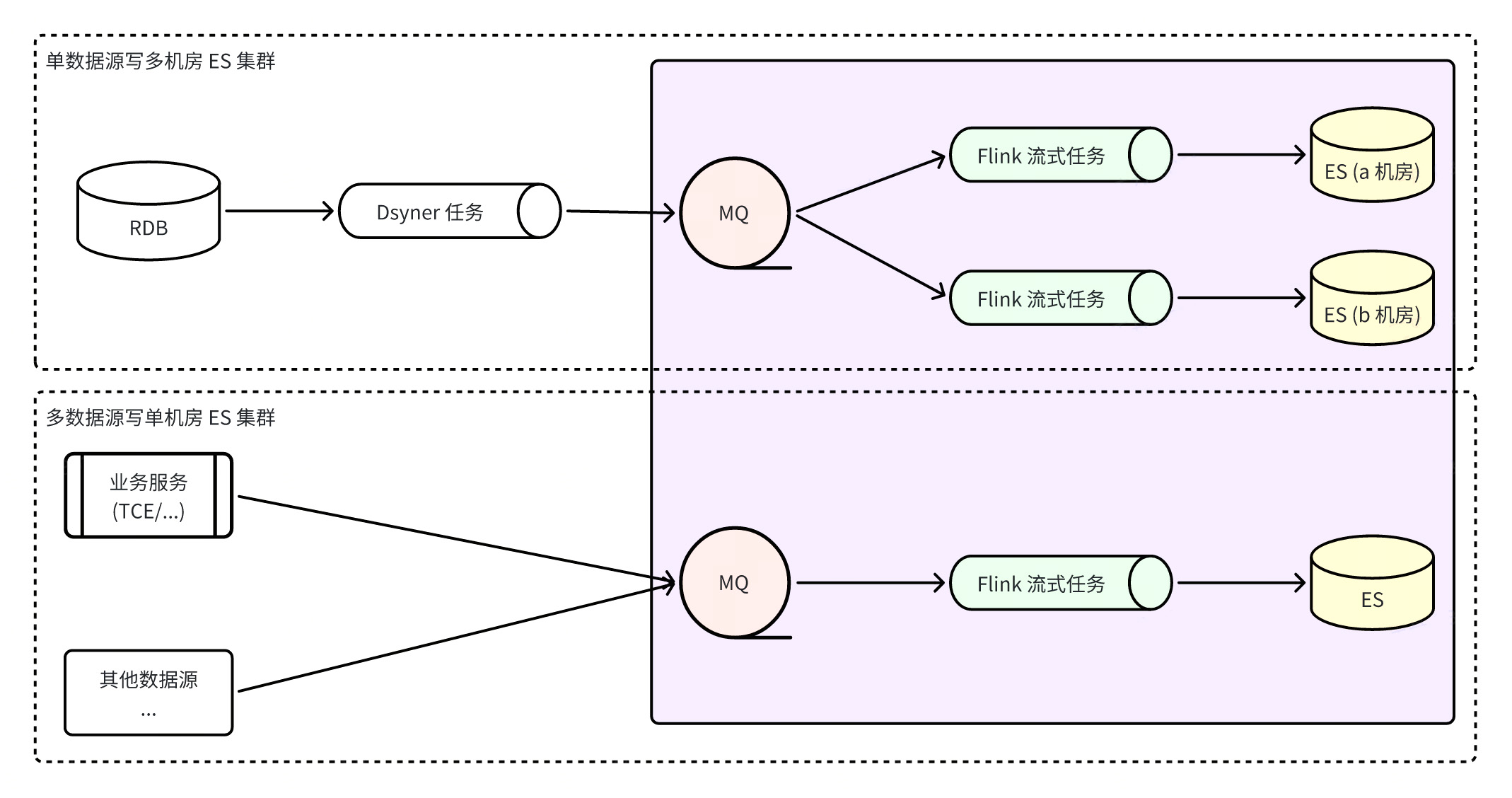
avantage
:
-
MQ peut être utilisé pour accéder plus rapidement aux clusters ES multi-salles informatiques et les écritures sont découplées. Les consommateurs des trois salles informatiques écrivent les données indépendamment les uns des autres . Lorsqu'une seule salle informatique tombe en panne, tant qu'il y a une salle informatique disponible, le trafic de lecture sera directement coupé. Oui, le plan de reprise après sinistre est simple et clair ;
-
Lorsque des problèmes tels que la gigue du réseau entraînent l'échec temporaire de l'écriture d'ES, RocketMQ stockera temporairement le message sans affecter l'écriture des autres clusters, et Flink enregistrera l'instantané de consommation et continuera à réessayer jusqu'au succès, ce qui garantit mieux la cohérence finale des données. .le sexe ;
-
L'écriture à partir de plusieurs sources de données peut garantir la cohérence globale des partitions.
lacune
:
-
S'appuyer sur plus de composants augmentera le délai de synchronisation des données de l'ensemble du lien, et la fréquence de rafraîchissement par défaut d'ES est d'une fois par seconde. Après les tests, le retard des données du lien dans des circonstances normales est de deuxième niveau, ce qui n'est pas complètement inacceptable ;
-
Il repose sur davantage de composants et a des exigences plus élevées en matière de stabilité des composants de base. Les exceptions RocketMQ ou les exceptions de tâches Flink entraîneront des problèmes de lien de synchronisation et augmenteront le risque d'exceptions métier.
Un problème qui mérite attention ici est que certaines personnes peuvent envisager de se connecter à un cluster ES multi-salles de machines. Comment garantir le succès de plusieurs salles informatiques en même temps et comment garantir que les données peuvent être interrogées après une écriture réussie ? À l'heure actuelle, ces deux points ne peuvent pas être atteints car plusieurs salles informatiques écrivent indépendamment sans s'influencer mutuellement, et le cluster ES est un cluster à faible cohérence des données, il n'y a donc aucune garantie que les écritures réussies puissent être trouvées immédiatement.
Conditions préalables à la création et à l'exécution d'un programme grand public ES Flink :
-
Environnement d'exécution Flink : Tout d'abord, vous devez disposer d'un environnement d'exécution pour les tâches Flink. Habituellement, les tâches Flink au niveau de l'entreprise seront planifiées en tant que tâche YARN dans le système distribué et alloueront des ressources pour l'exécution, mais en même temps, Flink. peut également être utilisé comme processus autonome ou pour créer une opération de cluster indépendante.
-
Format de message ES : Il est nécessaire de se mettre d'accord sur un format de transmission de message ES et une méthode de sérialisation. Un ensemble de paradigmes peuvent résoudre tous les scénarios de synchronisation. La méthode de sérialisation actuellement populaire est le format pb ou le format json. . Format des données Définition du schéma :
|
Nom de domaine
|
type de valeur
|
Obligatoire/Facultatif
|
décrire
|
|
_indice
|
chaîne
|
requis
|
Le nom ou l'alias du document à indexer
|
|
_taper
|
chaîne
|
Obligatoire/Facultatif
|
Type de document
|
|
_sur_type
|
chaîne
|
requis
|
Type d'opération d'écriture de document
, plage de valeurs :
index, création, mise à jour,
insertion
, suppression
|
|
_identifiant
|
chaîne
|
Facultatif
|
ID du document
. S'il n'est pas spécifié, il sera
automatiquement généré
lors de l'écriture dans ES . Cependant, si les mêmes données sont consommées et écrites à plusieurs reprises dans ES, plusieurs documents seront générés.
|
|
_routage
|
chaîne
|
Facultatif
|
Routage
du document Si non spécifié, la valeur du champ _id routage sera utilisée par défaut.
|
|
_version
|
int64
|
Facultatif
|
Version du document
. Lorsqu'il est spécifié, il est supérieur à 0
et n'est valable que pour les opérations d'indexation/suppression
. Le type de version
external_gte
est utilisé par défaut.
|
|
_source
|
objet
|
Obligatoire/Facultatif
|
Contenu du document
, il n'est pas nécessaire de le préciser lorsque le type d'opération est supprimer.
|
|
_scénario
|
objet
|
Facultatif
|
Script de document
, valide lorsque le type d'opération est update/upsert, mais ne peut pas exister avec _source en même temps
|
syntax = "proto3";
message ESIndexInfo {
string Name = 1; // 文档要写入索引的名称或别名
}
enum ESOPType { // 文档写入操作类型
DELETE = 0; // 删除文档
INDEX = 1; // 创建新文档或更新老文档,只能全量更新 (替换老文档)
UPDATE = 2; // 更新老文档,支持部分更新 (合并老文档)
UPSERT = 3; // 创建新文档或更新老文档,支持部分更新 (合并老文档)
CREATE = 4; // 创建新文档,存在时报错丢弃
}
message ESDocAction {
ESIndexInfo IndexInfo = 1; // 索引信息 (必需)
ESOPType OPType = 2; // 操作类型 (必需)
string ID = 3; // 文档 ID (可选)
string Doc = 4; // 文档内容 (JSON 格式, 删除操作时不需要)
int64 Version = 5; // 文档版本 (可选, 大于 0 且操作为 index/create/delete 有效)
string Routing = 6; // 文档路由 (可选, 非空有效)
string Script = 7; // 文档脚本 (JSON 格式, 操作类型为 update/upsert 有效,但和 Doc 不能同时存在)
}-
Configuration nécessaire pour les tâches Flink : surveillance des informations sur le sujet RocketMQ, écriture des informations sur le cluster ES ;
-
Fonction d'exécution Flink : Flink traite les messages en streaming de deux manières : le streaming SQL et les applications personnalisées sont soumis à certaines limitations, telles que la non-prise en charge de plusieurs messages d'index dans le même MQ, tandis que la programmation personnalisée est plus flexible. comme l'ajout de diverses gestions, journaux, traitement des codes d'erreur, etc., cette méthode est recommandée ;
-
Configuration des ressources Flink : configuration des ressources JobManager, configuration des ressources TaskManager, etc. ;
-
Configuration des paramètres personnalisés Flink : Vous pouvez personnaliser certaines configurations dynamiques étroitement liées à l'application pour faciliter l'ajustement dynamique des capacités de consommation de Flink, telles que :
|
le nom du paramètre
|
utiliser
|
valeur par défaut
|
|
job.writer.connector.bulk-flush.max-actions
|
Le nombre maximum de documents dans un seul lot, s'il dépasse le nombre, un vidage sera effectué (c'est-à-dire qu'une demande groupée d'ES sera exécutée)
|
Par défaut 300
|
|
job.writer.connector.bulk-flush.max-size
|
Le nombre maximum d'octets dans un seul volume, s'il dépasse la limite, un vidage sera effectué (c'est-à-dire qu'une requête groupée d'ES sera exécutée)
|
Par défaut10 Mo
|
|
job.writer.connector.bulk-flush.intervalle
|
L'intervalle maximum entre deux lots, s'il y a plus d'un vidage (c'est-à-dire exécuter une requête groupée ES)
|
Par défaut 1000 ms
|
|
job.writer.connector.global-rate-limit
|
Valeur limite globale de vitesse d’écriture
|
Par défaut -1, aucune limite de vitesse
|
|
job.writer.connector.failure-handler
|
Spécifiez un gestionnaire d'échec personnalisé, tel que la gestion des erreurs 4xx, des erreurs 5xx de différentes manières, 429 en réessayant toujours à l'infini, etc. ;
|
|
|
global_parallelism_num
|
concurrence globale de la tâche flink
|
rmq est la file d'attente/4, bmq/kafka est la partition/3
|
|
max_parallelism_num
|
Concurrence maximale des tâches flink
|
Le nombre de files d'attente/partitions de mq
|
|
checkpoint_interval
|
L'intervalle de création du point de contrôle, unité ms (5min=300000)
|
Par défaut 15min
|
|
checkpoint_timeout
|
Délai d'expiration pour la création d'un point de contrôle, unité ms (5min=300000)
|
Par défaut 10min
|
|
rééquilibrer_enable
|
Activer la consommation hors service
|
Faux par défaut
|
Suggestions de comparaison
|
Méthode d'écriture
|
Délai de synchronisation
|
Écrire des propriétés
|
Performances d'écriture ES
|
consommateur
|
Tolérance aux catastrophes
|
|
connexion directe
|
Moins de composants dépendants et une faible latence
|
Clé unique Binlog commandée
|
écriture groupée
|
FaaS
|
Pauvre
|
|
RocketMQ+Flink+ES
|
Il existe de nombreux composants dépendants et le délai est de niveau élevé/deuxième
|
Commande mondiale de clé unique
|
écriture groupée
|
Considérable
|
bien
|
Après l'introduction ci-dessus, si l'entreprise peut accepter des retards de deuxième niveau, l'utilisation de RocketMQ+Flink peut mieux assurer l'ordre et les capacités de reprise après sinistre. Flink est également bien supérieur à FaaS en termes de capacités de traitement des tâches de streaming, mais la méthode de connexion directe a évidemment. des liens plus simples, une architecture plus légère et des coûts d'intégration et de maintenance du système inférieurs. Par conséquent, il est toujours nécessaire de choisir celui qui convient le mieux en fonction des caractéristiques de l'entreprise.
Équipe source|Plateforme commerciale de commerce électronique ByteDance
{{o.name}}
{{m.name}}