
Note de l'éditeur : lorsque l'auteur essayait d'apprendre à sa mère à utiliser le LLM pour effectuer des tâches professionnelles, elle s'est rendu compte que l'optimisation des mots d'invite n'était pas aussi simple qu'on l'imaginait. L'optimisation automatique des mots d'invite est précieuse pour les rédacteurs de mots d'invite inexpérimentés qui n'ont pas suffisamment d'expérience pour ajuster et améliorer les mots d'invite fournis au modèle , ce qui a déclenché une exploration plus approfondie des outils automatisés d'optimisation des mots d'invite.
L'auteur de cet article analyse la nature de l'ingénierie des mots rapides sous deux angles : elle peut être considérée comme faisant partie de l'optimisation des hyperparamètres, ou elle peut être considérée comme un processus d'exploration, d'essais et d'erreurs et de correction qui nécessite des tentatives et des ajustements constants. .
L'auteur estime que pour les tâches avec des entrées et des sorties de modèle relativement claires, telles que la résolution de problèmes mathématiques, la classification des émotions et la génération d'instructions SQL, etc. L'auteur estime que l'ingénierie des mots rapides dans ce cas s'apparente davantage à l'optimisation d'un « paramètre », tout comme à l'ajustement des hyperparamètres dans l'apprentissage automatique. Nous pouvons utiliser des méthodes automatisées pour essayer constamment différents mots d’invite afin de voir lequel fonctionne le mieux. Pour des tâches relativement subjectives et vagues, comme la rédaction d'emails, de poèmes, de résumés d'articles, etc. Puisqu'il n'existe pas de norme en noir et blanc pour juger si le résultat est « correct », l'optimisation des mots d'invite ne peut pas être effectuée de manière simple et mécanique.
Le lien de l'article original : https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
Lien du profil LinkedIn : https://linkedin.com/in/ianhojy
Lien de profil moyen pour les abonnements : https://ianhojy.medium.com/
Auteur |
Compilé | Yue Yang
Au cours des derniers mois, j'ai essayé de créer diverses applications basées sur LLM. Pour être honnête, je passe une bonne partie de mon temps à améliorer Prompt pour obtenir le résultat que j'attends de LLM.
Il y a eu de nombreuses fois où j'étais coincé dans le vide et la confusion, me demandant si j'étais juste un ingénieur d'invite glorifié. Compte tenu de l’état actuel de l’interaction humaine avec les LLM (Large Language Models), j’ai encore tendance à conclure « pas encore » et je suis capable de surmonter mon syndrome de l’imposteur la plupart des soirs. (Note du traducteur : il s'agit d'un phénomène psychologique qui fait référence aux individus qui sont sceptiques quant à leurs propres réalisations et capacités. Ils se sentent souvent des menteurs, croient qu'ils ne sont pas dignes d'avoir ou d'atteindre les réalisations qu'ils ont accomplies et sont craignant d'être exposé.) Actuellement, nous ne discuterons pas de cette question en profondeur pour l'instant.
Mais je me demande encore souvent si un jour, le processus d’écriture de Prompt pourra être fondamentalement automatisé. La réponse à cette question dépend de votre capacité à comprendre la véritable nature de l’ingénierie rapide.
Bien qu'il existe d'innombrables manuels d'ingénierie rapide sur le vaste Internet, je n'arrive toujours pas à décider si l'ingénierie rapide est un art ou une science.
D'une part, cela ressemble à un art lorsque je dois apprendre et peaufiner à plusieurs reprises les invites que j'écris en fonction de ce que j'observe à partir de la sortie du modèle . Au fil du temps, j'ai découvert que les petits détails comptent (comme utiliser « doit » au lieu de « devrait » ou ajouter des recommandations ou des spécifications de lignes directrices) à la fin du mot d'invite plutôt qu'au milieu. En fonction de la tâche, il existe tellement de façons d'exprimer une série d'instructions et de lignes directrices que cela ressemble parfois à un essai et une erreur constants et à commettre des erreurs.
D’un autre côté, on pourrait penser que les mots d’invite ne sont que des hyper-paramètres. En fin de compte, LLM (Large Language Model) ne traite en fait que les mots d'invite que nous écrivons comme des intégrations, tout comme tous les hyperparamètres. Si nous disposons d'un ensemble de données préparé et approuvé pour la formation et le test des modèles d'apprentissage automatique, nous pouvons ajuster les mots d'invite et évaluer objectivement leurs performances. Récemment, j'ai vu un article de Moritz Laurer, ingénieur ML chez HuggingFace[1] :
Chaque fois que vous testez une invite différente sur vos données, vous devenez moins sûr si le LLM se généralise réellement à des données invisibles… Utiliser une division de validation distincte pour régler l'hyperparamètre principal des LLM (l'invite) est tout aussi important que train-val-test fractionnement pour un réglage fin. La seule différence est que vous n'avez plus d'ensemble de données de formation et que cela semble différent car il n'y a pas de formation / pas de mise à jour des paramètres. Il est facile de vous faire croire qu'un LLM fonctionne bien dans votre tâche, alors que vous avez en fait surajusté l'invite sur vos données. Tout bon article « zeroshot » devrait préciser qu'il a utilisé une division de validation pour trouver son invite avant le test final.
À mesure que nous testons de plus en plus de mots d'invite différents (invites) sur ces ensembles de données, nous deviendrons de plus en plus incertains si LLM peut réellement généraliser à des données invisibles... Isoler une partie de l'ensemble de données Définir comme ensemble de validation pour ajuster les principaux hyperparamètres (Invite) de LLM et utilisez la méthode de fractionnement train-val-test (Note du traducteur : divisez l'ensemble de données disponible en trois parties : ensemble d'entraînement, ensemble de validation et ensemble de test.) Le réglage fin est tout aussi important. La seule différence est que ce processus n'implique pas la formation du modèle (pas de formation) ni la mise à jour des paramètres du modèle (pas de mise à jour des paramètres), mais uniquement l'évaluation des performances de différents mots d'invite sur l'ensemble de validation. Il est facile de se tromper en croyant que le LLM fonctionne bien sur la tâche cible, alors qu'en fait les mots de repère ajustés peuvent très bien fonctionner sur cet ensemble de données actuel, mais peuvent ne pas fonctionner correctement sur un ensemble de données plus large ou invisible, sans objet. Tout bon article "zeroshot" doit clairement indiquer qu'il utilise un ensemble de validation pour aider à trouver les meilleures invites avant le test final.
Après réflexion, je pense que la réponse se situe quelque part entre les deux. Que l'ingénierie rapide soit une science ou un art dépend de ce que nous voulons que LLM fasse. Nous avons vu LLM faire beaucoup de choses étonnantes au cours de la dernière année, mais j'ai tendance à classer les intentions des gens concernant l'utilisation de grands modèles en deux grandes catégories : résoudre des problèmes et accomplir des tâches créatives (créer).
Du côté de la résolution de problèmes , nous avons des LLM qui résolvent des problèmes mathématiques, classifient des sentiments, génèrent des instructions SQL, traduisent du texte, etc. D'une manière générale, je pense que ces tâches peuvent toutes être regroupées, car elles peuvent avoir des paires entrée-sortie relativement claires (Note du traducteur : l'association entre les données d'entrée et les données de sortie du modèle correspondantes) (par conséquent, nous pouvons avoir vu de nombreux cas où l'utilisation seul un petit nombre d'invites peut très bien accomplir la tâche cible). Pour ce type de tâche avec des données d'entraînement bien définies (Note du traducteur : la relation entre l'entrée et la sortie dans l'ensemble de données d'entraînement est claire et claire), l'ingénierie rapide me semble plus une science. Par conséquent, la première moitié de cet article discutera de l'invite en tant qu'hyperparamètre , en explorant spécifiquement les progrès de la recherche sur l'ingénierie des invites automatisées (Note du traducteur : utilisation de méthodes ou de technologies automatisées pour concevoir, optimiser et ajuster les mots d'invite).
En termes de tâches créatives , les tâches requises du LLM sont plus subjectives et ambiguës. Écrivez des e-mails, des rapports, des poèmes, des résumés. C’est ici que nous rencontrons plus d’ambiguïté : le contenu des écrits de ChatGPT est-il impersonnel ? (Sur la base des milliers d'articles que j'ai écrits à ce sujet, mon opinion actuelle est oui) Et, comme il nous manque souvent un critère plus objectif sur la façon dont nous voulons que les LLM répondent, la nature et les exigences des tâches créatives ne sont souvent pas appropriées. considérer les mots indicateurs comme des paramètres qui peuvent être réglés et optimisés comme des hyperparamètres.
À ce stade, certains pourraient dire que pour les tâches créatives, il suffit de faire preuve de bon sens. Pour être honnête, je le pensais aussi, jusqu'à ce que j'essaye d'apprendre à ma mère comment utiliser ChatGPT pour l'aider à générer des e-mails professionnels. Dans ces cas-là, puisque l’ingénierie de Prompt consiste toujours principalement en une amélioration par l’expérimentation et un ajustement continus plutôt qu’une réalisation ponctuelle, comment pouvez-vous utiliser vos propres idées pour améliorer Prompt tout en conservant l’universalité de Prompt (comme mentionné dans la citation précédente ? ), n’est pas toujours évident.
Quoi qu'il en soit, j'ai cherché un outil capable d'améliorer automatiquement les invites en fonction des commentaires des utilisateurs sur des exemples générés par de grands modèles, mais je n'ai rien trouvé. Par conséquent, j'ai construit un prototype d'un tel outil pour explorer s'il existait une solution réalisable. Plus loin dans cet article, je partagerai avec vous un outil que j'ai expérimenté et qui améliore automatiquement les mots d'invite en fonction des commentaires des utilisateurs en temps réel.
01 Partie 1 - Les LLM comme solveurs : traitez l'ingénierie rapide dans le cadre de l'optimisation des hyperparamètres
De nombreuses personnes dans l'industrie connaissent la célèbre terminologie « Zero-Shot-COT » dans l'article « Les grands modèles de langage sont des raisonneurs zéro-shot » [2] (Note du traducteur : le modèle n'a pas appris de données d'entraînement explicites pour une tâche spécifique. . Ensuite, résolvez de nouveaux problèmes en combinant les connaissances existantes). Zhou et al. (2022) ont décidé d'explorer plus en profondeur dans l'article « Les grands modèles de langage sont des ingénieurs d'invite au niveau humain » [3] Quelle est sa version améliorée ? —— "Résolussons cela étape par étape pour être sûrs d'avoir la bonne réponse". Ce qui suit est un aperçu de la méthode Automatic Prompt Engineer qu’ils ont proposée :
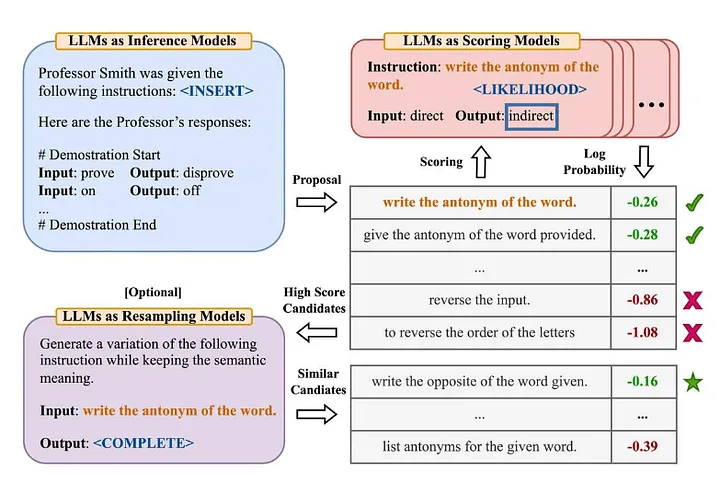
Source : Les grands modèles de langage sont des ingénieurs d'invite au niveau humain[3]
Pour résumer cet article :
- Utilisez LLM pour générer des invites d'orientation des candidats en fonction de paires d'entrées-sorties données (Note du traducteur : l'association entre les données d'entrée et les données de sortie du modèle correspondantes).
- Utilisez LLM pour noter chaque invite pédagogique, soit en fonction de la mesure dans laquelle la réponse générée à l'aide de l'instruction correspond à la réponse attendue, soit en fonction de la réponse du modèle obtenue avec l'instruction pour évaluer la probabilité logarithmique.
- De nouveaux mots d'invite de guidage de candidat sont générés de manière itérative sur la base de mots d'invite de guidage de candidat (instructions) ayant obtenu un score élevé.
Quelques conclusions intéressantes ont été découvertes :
- En plus de démontrer les performances supérieures des algorithmes (ingénieurs à invite humaine) et proposés précédemment, les auteurs notent : « De manière contre-intuitive, l'ajout d'exemples en contexte nuit aux performances du modèle… parce que tous les mots d'instruction sélectionnés surajustent le scénario d'apprentissage zéro et fonctionnent donc mal. dans le cas de petits échantillons (quelques coups) " .
- L'effet de l'algorithme itératif de recherche de Monte Carlo (Recherche de Monte Carlo) s'affaiblira progressivement dans la plupart des cas, mais lorsque l'espace de proposition d'origine (Note du traducteur : peut faire référence à l'algorithme de recherche de Monte Carlo, initialement utilisé pour générer des candidats, il fonctionne bien lorsque le la portée initiale ou la solution du problème n’est pas suffisamment adaptée ou efficace.
Puis en 2023, certains chercheurs de Google DeepMind ont lancé une méthode baptisée « Optimisation by Prompting (OPRO) ». Semblable à l'exemple précédent, la méta-invite contient une série de paires d'entrées/sorties (Note du traducteur : l'entrée et les attentes qui décrivent une combinaison de tâche ou de sortie de problème spécifique). La principale différence ici est que la méta-invite contient également des échantillons de mots d'invite préalablement formés et leurs réponses ou solutions correctes et la précision avec laquelle le modèle a répondu à ces mots d'invite, ainsi que le détail des différences entre les différentes parties de la méta-invite. Mots d'orientation pour les relations.
Comme l'expliquent les auteurs, chaque étape d'optimisation des mots indicateurs dans le travail de recherche génère de nouveaux mots indicateurs, visant à référencer les trajectoires d'apprentissage précédentes afin que le modèle puisse mieux comprendre la tâche en cours et produire des résultats de sortie plus précis.
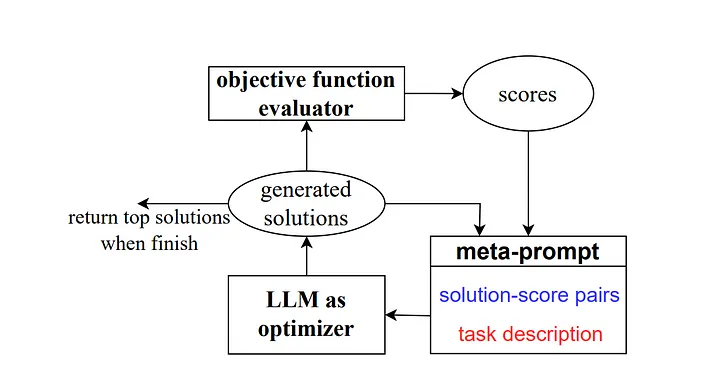
Source : Grands modèles de langage comme optimiseurs[4]
Pour le scénario Zero-Shot-COT, ils ont proposé la méthode d'optimisation des mots rapides « Prenez une profonde respiration et travaillez sur ce problème étape par étape » et ont obtenu de bons résultats.
J'ai quelques réflexions à ce sujet :
- « Les styles d'invites pédagogiques générés par différents types de modèles de langage varient considérablement. Certains modèles, tels que PaLM 2-L-IT et text-bison, génèrent des invites pédagogiques très concises et claires, tandis que d'autres, comme les instructions GPT, sont longues et claires. assez détaillé. "Cela mérite notre attention. Actuellement, de nombreuses méthodes d'ingénierie rapide sur le marché sont écrites en utilisant le modèle de langage d'OpenAI comme objet de référence. Cependant, à mesure que de plus en plus de modèles provenant de différentes sources commencent à être utilisés, nous devons prêter attention à ces directives d'ingénierie courantes qui peuvent ne pas fonctionner. si bien. Un exemple est donné dans la section 5.2.3 de l'article, qui démontre la grande sensibilité des performances du modèle à de petits changements dans les instructions. Nous devons y prêter davantage attention.
Par exemple, lors de l'utilisation de PaLM 2-L pour évaluer le modèle sur l'ensemble de test GSM8K, la précision de « Pensons étape par étape » a atteint 71,8 % et la précision de « Résolvons le problème ensemble » était de 60,5 %. tandis que les deux premiers La combinaison sémantique de mots d'instruction, "Travaillons ensemble pour résoudre ce problème étape par étape." a une précision de seulement 49,4 %.
Ce comportement augmente à la fois la variation entre les instructions en une seule étape et les fluctuations qui se produisent au cours du processus d'optimisation, nous incitant à générer plusieurs instructions en une seule étape à chaque étape) pour améliorer la stabilité du processus d'optimisation.
Un autre point important est mentionné dans la conclusion de l'article : « Une des limites de notre application actuelle des algorithmes aux problèmes du monde réel est que les grands modèles de langage utilisés pour optimiser les mots indicateurs n'exploitent pas efficacement les cas erronés dans l'ensemble d'entraînement pour déduire. prometteur Dans l'expérience, nous avons essayé d'ajouter des cas d'erreur survenus lors de la formation ou du test du modèle dans la méta-invite, au lieu d'un échantillonnage aléatoire à partir de l'ensemble de formation à chaque étape d'optimisation, mais les résultats étaient similaires, ce qui a montré que seul le La quantité d'informations dans ces cas d'erreur n'est pas suffisante pour que l'optimiseur LLM (un grand modèle de langage utilisé pour optimiser les mots d'invite) comprenne les raisons des prédictions incorrectes. « Cela mérite en effet d'être souligné, car même si ces méthodes fournissent des preuves solides de cette erreur. processus d'optimisation des mots d'invite. Semblable au processus d'optimisation des hyperparamètres dans le ML/AI traditionnel, mais nous avons tendance à préférer utiliser des exemples positifs et positifs, qu'il s'agisse du type de contenu que nous souhaitons fournir à LLM ou de la manière dont nous guidons LLM. améliorer les mots d'invite. Cependant, dans le ML/AI traditionnel, cette préférence n'est généralement pas si évidente, et nous nous concentrons davantage sur la manière d'utiliser les informations d'erreur pour optimiser le modèle, plutôt que de prêter trop d'attention à la direction ou au type de l'erreur elle-même (c'est-à-dire, nous nous concentrons sur les erreurs -5 et +5 qui sont pour la plupart traitées de la même manière).
Si vous êtes intéressé par APE (Automated Prompt Engineering), vous pouvez vous rendre sur https://github.com/keirp/automatic_prompt_engineer pour le télécharger et l'utiliser.
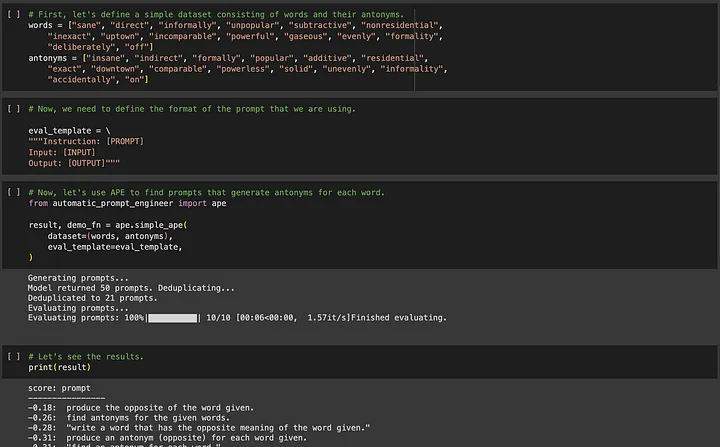
Source : Capture d'écran d'un exemple de bloc-notes pour APE[5]
Une exigence clé dans les deux méthodes, APE et OPRO, est qu'il doit y avoir des données de formation pour aider à l'optimisation, et que l'ensemble de données doit être suffisamment grand pour garantir l'universalité des mots de repère optimisés.
Maintenant, je veux parler d'un autre type de tâche LLM pour laquelle nous ne disposons peut-être pas de données facilement disponibles.
02 Partie 2 - Les LLM en tant que créateurs : considérez l'ingénierie rapide comme un processus d'amélioration progressive en essayant et en ajustant constamment
Supposons que nous devions maintenant inventer quelques nouvelles.
Nous n'avons tout simplement pas de nouveaux exemples de texte sur lesquels former le modèle, et il prendrait trop de temps pour écrire de nouveaux exemples de texte qualifiés. De plus, je ne vois pas clairement s'il est logique qu'un grand modèle génère une réponse « dite correcte », car il peut exister de nombreux types de résultats de modèle acceptables. Par conséquent, pour ce type de tâche, il est presque impossible d’utiliser des méthodes telles que l’APE pour automatiser l’ingénierie des mots d’invite.
Cependant, certains lecteurs peuvent se demander pourquoi avons-nous même besoin d'automatiser le processus d'écriture de mots d'invite ? Vous pouvez commencer par n'importe quel simple mot d'invite, tel que "fournissez-moi 3 idées d'histoires courtes sur {{issue}} " {{country}}, remplir {{issue}} par "inégalité", remplacer {{country}} par "Singapour" et observer le modèle Répondre aux résultats, découvrez les problèmes, ajustez les mots d'invite, puis observez si l'ajustement est efficace et répétez ce processus.
Mais dans ce cas, qui bénéficiera le plus de l’ingénierie des mots indicateurs ? Ce sont précisément les débutants qui n'ont pas l'expérience de l'écriture de mots d'invite. Ils n'ont pas suffisamment d'expérience pour ajuster et améliorer les mots d'invite fournis au modèle . J'en ai fait l'expérience lorsque j'ai appris à ma mère à utiliser ChatGPT pour effectuer des tâches professionnelles.
Ma mère n'est peut-être pas très douée pour canaliser son mécontentement à l'égard des résultats de ChatGPT vers de nouvelles améliorations des mots d'invite, mais j'ai réalisé que peu importe la qualité de nos compétences en ingénierie de mots d'invite, ce pour quoi nous sommes vraiment bons, c'est d'articuler les problèmes que nous voir (c'est-à-dire la capacité de se plaindre). Par conséquent, j'ai essayé de créer un outil pour aider les utilisateurs à exprimer leurs plaintes et à laisser LLM améliorer les mots d'invite pour nous. Pour moi, cela semble être une manière plus naturelle d'interagir et semble faciliter la tâche pour ceux d'entre nous qui essaient d'utiliser le LLM pour des tâches créatives.
Il faut préciser à l'avance qu'il ne s'agit que d'une preuve de concept, donc si les lecteurs ont de bonnes idées, n'hésitez pas à les partager avec l'auteur !
Tout d’abord, écrivez le mot d’invite avec {{}} variables. L'outil détectera ces espaces réservés pour que nous les remplissions plus tard, toujours en utilisant l'exemple ci-dessus, en demandant au grand modèle de produire des histoires créatives sur les inégalités à Singapour.
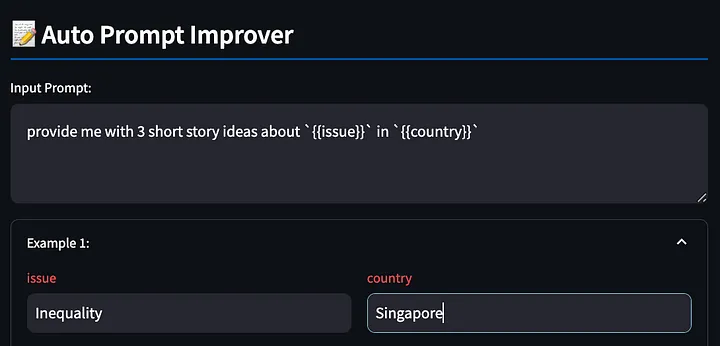
Ensuite, l'outil génère une réponse modèle basée sur les mots d'invite remplis.

Donnez ensuite nos commentaires (plaintes concernant la sortie du modèle) :
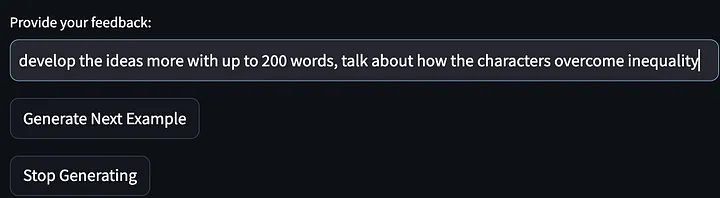
Il a ensuite été demandé au modèle de cesser de générer d’autres exemples d’idées d’histoire et de mots indicateurs de sortie améliorés par rapport à la première itération. Veuillez noter que les invites données ci-dessous ont été affinées et généralisées pour exiger « décrire les stratégies… pour surmonter ou relever ces défis ». Et mes commentaires sur le premier résultat du modèle étaient "parler de la façon dont le protagoniste de l'histoire résout les inégalités".

Nous avons ensuite demandé au grand modèle de concevoir à nouveau la nouvelle, en utilisant les mots-guides modifiés.
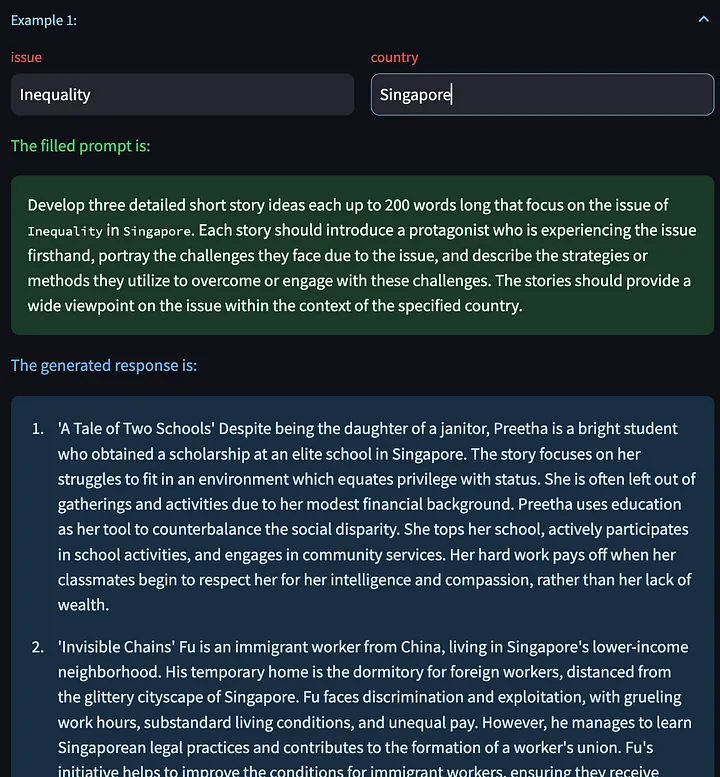
Nous avons également la possibilité de cliquer sur « Générer l'exemple suivant », ce qui nous permet de générer une nouvelle réponse de modèle basée sur d'autres variables d'entrée. Voici quelques histoires créatives générées sur le problème des licenciements en Chine :
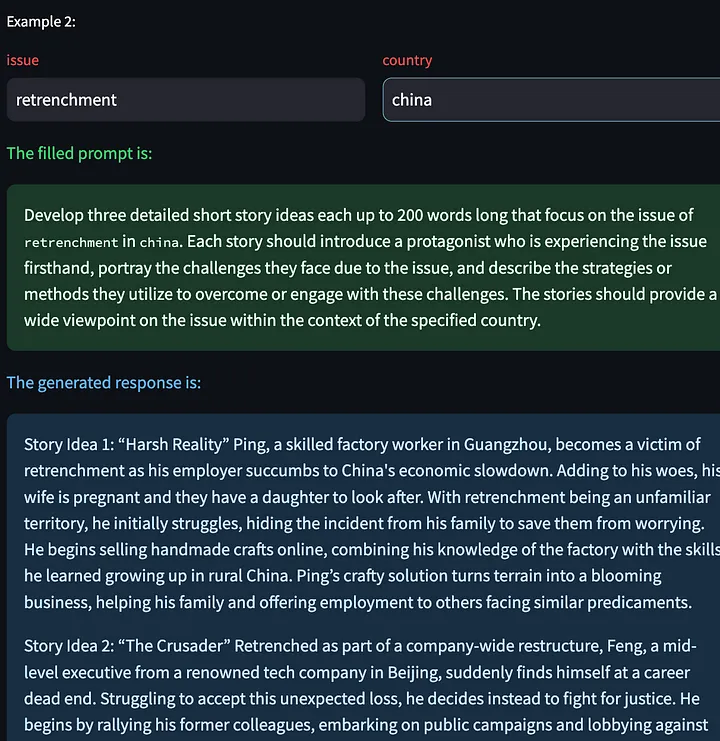
Donnez ensuite votre avis sur la sortie du modèle ci-dessus :
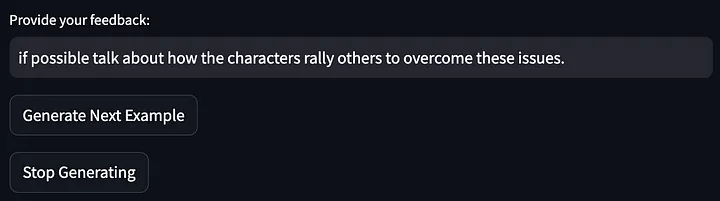
Ensuite, les mots d’invite ont été encore optimisés :

Les résultats d'optimisation cette fois semblent plutôt bons. Après tout, il ne s'agissait au début que d'un simple mot d'invite. Après moins de deux minutes de commentaires (quoique quelque peu occasionnels), le mot d'invite optimisé a été obtenu après trois itérations. Désormais, nous pouvons continuer à optimiser les mots d'invite en nous asseyant simplement et en exprimant notre mécontentement à l'égard du résultat du LLM.
L'implémentation interne de cette fonction consiste à partir d'une méta-invite, à optimiser et à générer en permanence de nouveaux mots d'invite basés sur les commentaires dynamiques de l'utilisateur. Cela n’a rien d’extraordinaire et il y a certainement place à des améliorations supplémentaires, mais c’est un bon début.
prompt_improvement_prompt = """
# Context #
You are given an original prompt.
The original prompt was used to generate some example responses. For each response, feedback was provided on how to improve the desired response.
Your task is to review all the feedback and then return an improved prompt that addresses the feedback, making it better at generating responses when prompted against the GPT language model.
# Guidelines #
- The original prompt will contain placeholders within double curly brackets. These are values for input that you will see in the examples.
- The improved prompt should not exceed 200 words
- Just return the improved prompt and nothing else before and after. Remember to include the same placeholders with double curly brackets.
- When generating the improved prompt, refrain from writing the entire prompt as one paragraph. Instead, you should use a combination of task descriptions, guidelines (in point form), and other sections to the prompt as appropriate.
- The guidelines should be in point form, and should not be a repetition of the task. The guidelines should also be distinct from one another.
- The improved prompt should be written in normal English that is best understood by the language model.
- Based on the feedback provided, you must rephrase the desired behavior of the response into `must`, imperative statements, instead of `should` suggestive statements.
- Improvements made to the prompt should not be overly specific to one single example.
# Details #
The original prompt is:
```
{original_prompt}
```
These are the examples that were provided and the feedback for each:
```
{examples}
```
The improved prompt is:
```
"""
Quelques observations lors de l'utilisation de cet outil :
- GPT4 a tendance à utiliser un grand nombre de mots lors de la génération de texte (la fonctionnalité « polyglotte »). Pour cette raison, il peut y avoir deux effets. Premièrement, cette propriété « verbeuse » peut encourager le surajustement à des exemples spécifiques . ** Si LLM reçoit trop de mots, il les utilisera pour corriger les commentaires spécifiques donnés par l'utilisateur. Deuxièmement, cette caractéristique « verbale » peut nuire à l'efficacité des mots d'invite, en particulier dans les mots d'invite longs, certaines informations d'orientation importantes peuvent être obscurcies. Je pense que le premier problème peut être résolu en écrivant de bonnes méta-invites pour encourager le modèle à se généraliser en fonction des commentaires des utilisateurs. Mais le deuxième problème est plus complexe. Dans d’autres cas d’utilisation, les invites instructives sont souvent ignorées lorsque le mot d’invite est trop long. Nous pouvons ajouter certaines restrictions dans la méta-invite (telles que limiter le nombre de mots dans l'exemple d'invite fourni ci-dessus) , mais cela est vraiment arbitraire et certaines restrictions ou règles dans les mots d'invite peuvent être affectées par le grand modèle sous-jacent. L’impact d’un attribut ou d’un comportement spécifique.
- Les mots d’invite améliorés oublient parfois les optimisations précédentes du mot d’invite. Une façon de résoudre ce problème consiste à fournir au système un historique d'amélioration plus long, mais cela rend les mots d'invite d'amélioration trop longs.
- L'un des avantages de cette approche dans la première itération est que le LLM peut fournir des conseils pour des améliorations qui ne font pas partie des commentaires des utilisateurs. Par exemple, dans le premier mot optimisation ci-dessus, l'outil a ajouté « Fournir une perspective plus large sur le problème discuté… » même si j'ai fourni. Les commentaires sont simplement une demande de statistiques pertinentes provenant de sources fiables.
Je n'ai pas encore déployé cet outil car je travaille toujours sur la méta-invite pour voir ce qui fonctionne le mieux et contourner certains des problèmes du framework rationalisé, puis gérer d'autres erreurs ou exceptions qui peuvent survenir dans le programme. Mais l’outil devrait être bientôt opérationnel !
03 En conclusion
L'ensemble du domaine de l'ingénierie rapide se concentre sur la fourniture des meilleurs mots rapides pour résoudre les tâches. L'APE et l'OPRO sont les exemples les plus importants et les plus remarquables dans ce domaine, mais ils ne représentent pas tous. Nous sommes enthousiasmés et attendons avec impatience les progrès que nous pourrons réaliser dans ce domaine à l'avenir. L'évaluation des effets de ces techniques sur différents modèles peut révéler les tendances de fonctionnement ou les caractéristiques de fonctionnement de ces modèles, et peut également nous aider à comprendre quelles techniques de méta-invite sont efficaces. Par conséquent, je pense que ce sont des tâches très importantes qui nous aideront à utiliser le LLM. dans notre pratique de production quotidienne.
Cependant, ces méthodes peuvent ne pas convenir à ceux qui souhaitent utiliser le LLM pour des tâches créatives. Pour l’instant, il existe de nombreux manuels d’apprentissage qui peuvent nous aider à démarrer, mais rien ne vaut les essais et les erreurs. Par conséquent, à court terme, je pense que la chose la plus précieuse est de savoir comment nous pouvons terminer efficacement ce processus expérimental qui correspond à nos forces humaines (donner du feedback) et laisser LLM faire le reste (améliorer les mots d'invite).
Je travaillerai également davantage sur mon POC (Proof of Concept). Si cela vous intéresse, n'hésitez pas à me contacter ( https://www.linkedin.com/in/ianhojy/) !
Merci d'avoir lu!
FIN
Les références
[1] https://www.linkedin.com/in/moritz-laurer/?originalSubdomain=de
[2] https://arxiv.org/pdf/2205.11916.pdf
[3] https://arxiv.org/pdf/2211.01910.pdf
[4] https://arxiv.org/pdf/2309.03409.pdf
[5] https://github.com/keirp/automatic_prompt_engineer
[6] https://arxiv.org/abs/2104.08691
[7] https://medium.com/mantisnlp/automatic-prompt-engineering-part-i-main-concepts-73f94846cacb
[8] https://www.promptingguide.ai/techniques/ape
Cet article a été compilé par Baihai IDP avec l'autorisation de l'auteur original. Si vous devez réimprimer la traduction, veuillez nous contacter pour obtenir une autorisation.
Lien d'origine :
https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
J'ai décidé d'abandonner l'open source Hongmeng Wang Chenglu, le père de l'open source Hongmeng : L'open source Hongmeng est le seul événement logiciel industriel d'innovation architecturale dans le domaine des logiciels de base en Chine - OGG 1.0 est publié, Huawei contribue à tout le code source. Google Reader est tué par la "montagne de merde de code" Fedora Linux 40 est officiellement publié Ancien développeur Microsoft : les performances de Windows 11 sont "ridiculement mauvaises" Ma Huateng et Zhou Hongyi se serrent la main pour "éliminer les rancunes" Des sociétés de jeux bien connues ont publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans Ubuntu 24.04 LTS officiellement publié Pinduoduo a été condamné pour concurrence déloyale Indemnisation de 5 millions de yuans