Introduction au contexte
Range (partitionnement) est une technologie de gestion de bases de données et d'organisation des données. Dans un système distribué, nous pouvons organiser les données en plusieurs plages selon certaines règles et réaliser une gestion dynamique grâce au fractionnement et à la fusion pour optimiser les performances des requêtes et contribuer à améliorer l'évolutivité et la disponibilité du système ainsi que l'équilibrage de charge. Le contenu principal de cette diffusion en direct est : le fractionnement et la fusion de la plage dans le système distribué KaiwuDB.
Ce qui suit est un extrait d'une partie du contenu. Pour le contenu complet, cliquez pour afficher le contenu de la version complète >> Lecture vidéo de la version complète.
Répartition de la plage KaiwuDB
Introduction à la scission
splitQueue est responsable du fractionnement de plage. Les conditions qui déclenchent le fractionnement de plage sont les suivantes :
- Créez une nouvelle base de données ou une nouvelle table.
- La taille de la plage dépasse range_max_bytes.
- Le QPS de Range est trop élevé, dépassant kv.range_split.load_qps_threshold (valeur par défaut 250, configurable).
- Modifiez la zone Configurer de l'index ou de la partition pour la rendre indépendante du niveau parent. Dans des cas particuliers, le fractionnement adminSplit sera appelé directement sans passer par splitQueue.
- Lors de l’importation d’une grande quantité de données, une plage est automatiquement divisée en plusieurs plages.
- Lors de l'importation de données, une plage vide est pré-divisée pour les données qui pourront être importées ultérieurement.
- Fractionnement manuel : modifiez la table nom_table divisée en valeurs (clé1, clé2,…); où Valeurs représente la valeur de la clé primaire commune, vous pouvez écrire plusieurs valeurs et elle ne peut pas dépasser le nombre de. colonnes de clé primaire.
Organigramme de l'algorithme divisé
Un certain nœud dans KaiwuDB a un thread/travailleur distinct s'exécutant en arrière-plan pour gérer le fractionnement des plages associées. Le fractionnement de la plage est divisé en 2 phases : Phase 1 - Préparation des paramètres de fractionnement de la plage Phase 2 - Mise à jour de la plage et de sa structure d'index ;

Comme le montre la figure, le processus de gauche est principalement la préparation au fractionnement de la plage :
Verrouillez d’abord la valeur clé de la clé de la plage divisée. Après avoir trouvé cette valeur de clé, le système ajustera la plage de plage actuelle et utilisera la valeur de clé de clé divisée comme valeur de clé de fin de la partition.
Le processus créera une nouvelle plage pour la droite, sa valeur de clé de début est la valeur de clé utilisée pour le fractionnement et sa valeur de clé de fin est la valeur de clé de fin de la plage d'origine. Dans le même temps, une fois la plage d'origine divisée, sa version sera mise à jour de manière itérative de 1 et la version mise à jour sera appliquée simultanément aux plages divisées gauche et droite.
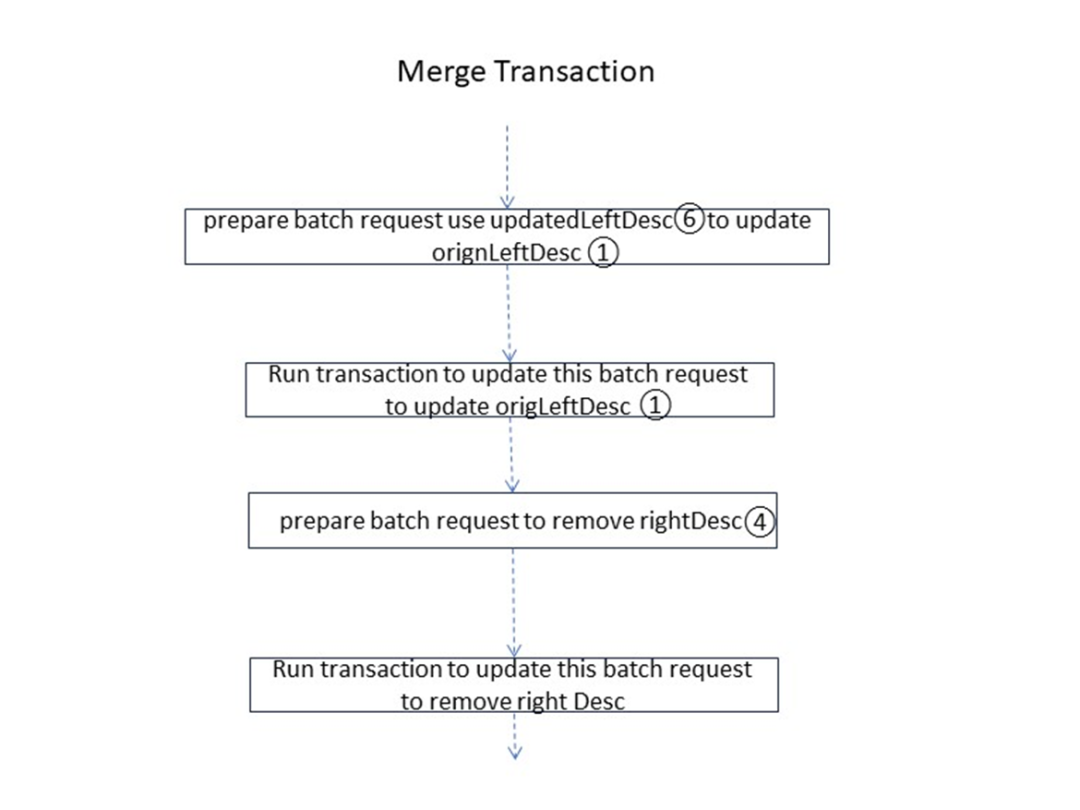
Lorsque les paramètres de fractionnement sur les côtés gauche et droit de la plage sont prêts, le processus entre dans la phase de mise à jour des données système. En résumé, il est nécessaire de préparer les demandes d'écriture et les demandes de processus. Ce processus est associé à une transaction, et à l'ensemble. la transaction doit compléter les éléments suivants :
Démarrer une nouvelle transaction, le statut est en attente
- Mettre à jour la plage gauche
- Écrire une nouvelle plage à droite
- Mettre à jour le chemin de recherche correspondant de l'arborescence à deux niveaux de l'index Big Mac sur la plage de gauche
- Insérez le chemin de recherche correspondant de l'arborescence à deux niveaux de l'index Big Mac dans la plage de droite
- Le statut de la transaction de mise à jour est Engagé
- Mettre à jour le MVCC de la plage gauche et droite
- Nettoyer l'intention d'écriture
À ce stade, le fractionnement de l’ensemble du Range est terminé.
Exemple de déclencheur fractionné
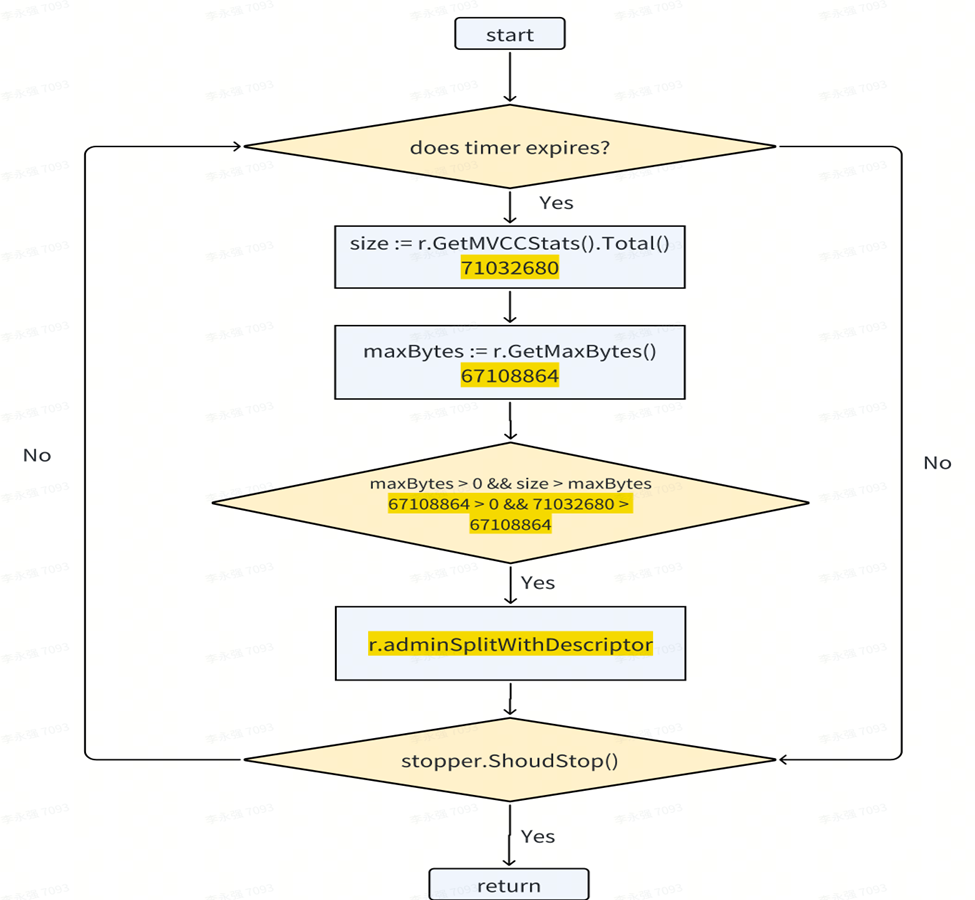
Le scénario de déclenchement de débogage suivant se produit une fois que la taille de la plage dépasse une valeur critique prédéterminée. Chaque plage est traitée selon une minuterie en attente en série. Après le réveil de l'horloge, la taille de la plage sera vérifiée. S'il s'avère que la taille de la plage est d'environ 70 Mo et dépasse la plage prédéterminée de 64 Mo, le système déclenchera la fonction de division de la plage pour diviser la plage qui dépasse la limite de capacité.
Le thread ou le travailleur d'arrière-plan vérifiera en permanence toutes les plages pour le traitement en boucle.
Fusion de plages KaiwuDB (Fusion)
Exemple de fusion
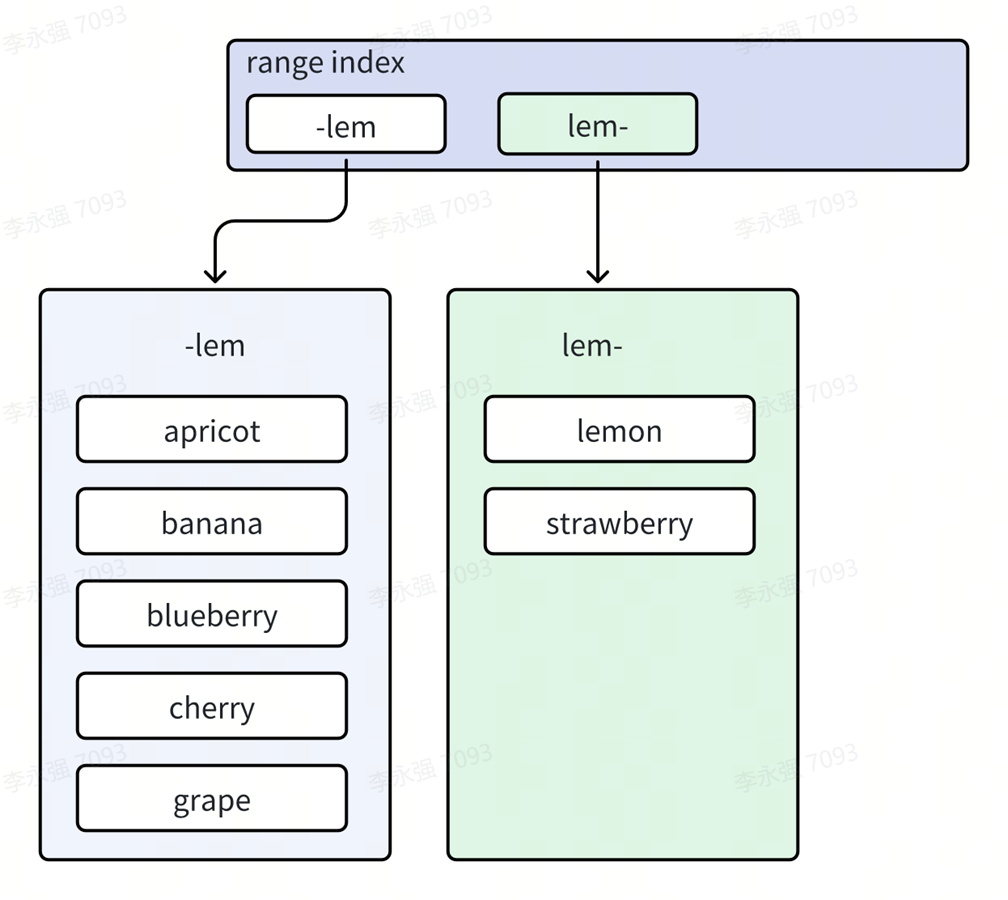
Comme le montre la figure, lorsque l'utilisateur supprime une grande quantité de données, la taille des deux plages adjacentes diminue fortement et le système les fusionne.

La figure suivante montre l'effet après la fusion. Après les deux plages précédentes : lem-str, str- ont été fusionnées, str- a disparu, ne laissant que lem-. Les valeurs clés des deux plages d'origine ont été fusionnées dans la même plage lem. .-. En conséquence, la structure des données de deuxième niveau de l'index Big Mac a également été ajustée et le pois dans la structure de l'index arborescent de premier niveau a disparu.
Conditions de fusion
Les conditions de fusion des plages sont relativement strictes, notamment : La fusion n'est pas désactivée Il existe une plage suivante et la même zone de configuration La taille des deux plages à fusionner est inférieure à range_min_bytes La division de plage de QPS ne sera pas déclenchée après la fusion
Le dernier signifie que si la plage où se trouvent les données contient des données chaudes, la fusion ne sera pas effectuée, car la fusion déclenchera une scission, ce qui empêchera le système de fonctionner normalement.
Organigramme de l'algorithme de fusion
Comme le montre la figure, la fusion, comme la division, est également divisée en deux étapes : la première étape - préparation des paramètres de plage ; la deuxième étape - permettant les transactions pour le traitement de la mise à jour de la plage ; Pour le contenu complet, veuillez cliquer pour afficher le contenu de la version complète >> [Lecture vidéo de la version complète] ( https://www.bilibili.com/video/BV11y421z7jH/?spm_id_from=333.999.0.0 )
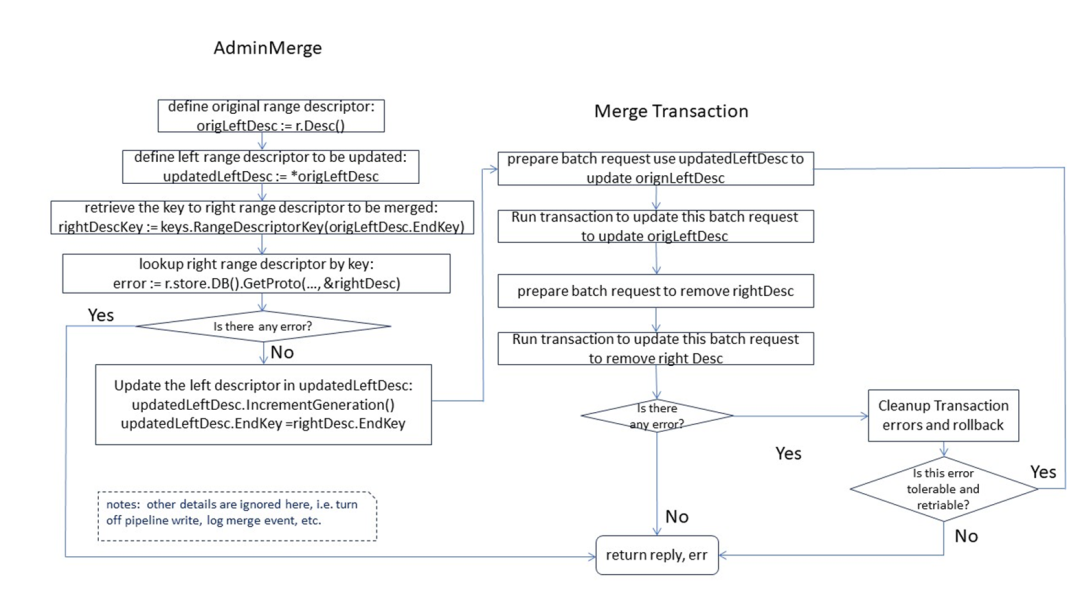
Exemple de débogage de fusion Les deux diagrammes schématiques suivants montrent le processus spécifique de débogage de la fusion de plages et les paramètres liés à la plage correspondants.