
1. Origines
Lorsque la base de données de secours lit des transactions, plusieurs transactions indépendantes les unes des autres peuvent être lues simultanément. Cette méthode est principalement utilisée pour résoudre le problème de la lecture simultanée de plusieurs transactions pouvant être lues simultanément. Grâce à plusieurs threads d'analyse simultanés, la file d'attente de lecture d'objets est analysée simultanément, plusieurs éléments pouvant être lus simultanément sont générés et le thread de lecture est notifié pour une lecture simultanée.
2. Conception de la structure des données
Les données de transaction de la base de données de secours sont segmentées et stockées dans la file d'attente des données de transaction de la base de données de secours en fonction de l'ID de transaction. Veuillez vous référer à la figure 1 ci-dessous. Selon la nature complètement désordonnée de l'ID de transaction UUID, l'UUID peut être analysé simultanément. par segments d’ID de transaction. Après avoir segmenté l'ID d'objet UUID, il est transmis à plusieurs coroutines de thread d'analyse. Chaque thread d'analyse est responsable d'une certaine partition UUID pour effectuer une analyse simultanée par plusieurs threads d'analyse et analyser les éléments qui peuvent être lus.
3. Cycle de vie des fils
Lorsque le thread d'analyse trouve quelque chose qui peut être lu, il ajoute l'ID d'objet à txnList et effectue l'opération de mise en file d'attente. Après avoir ajouté l'ID d'objet, le thread d'analyse effectue l'opération de notification et réveille le thread de lecture en veille pour effectuer l'opération. opération de lecture de transaction. Pour un diagramme schématique, reportez-vous à la figure 2 ci-dessous.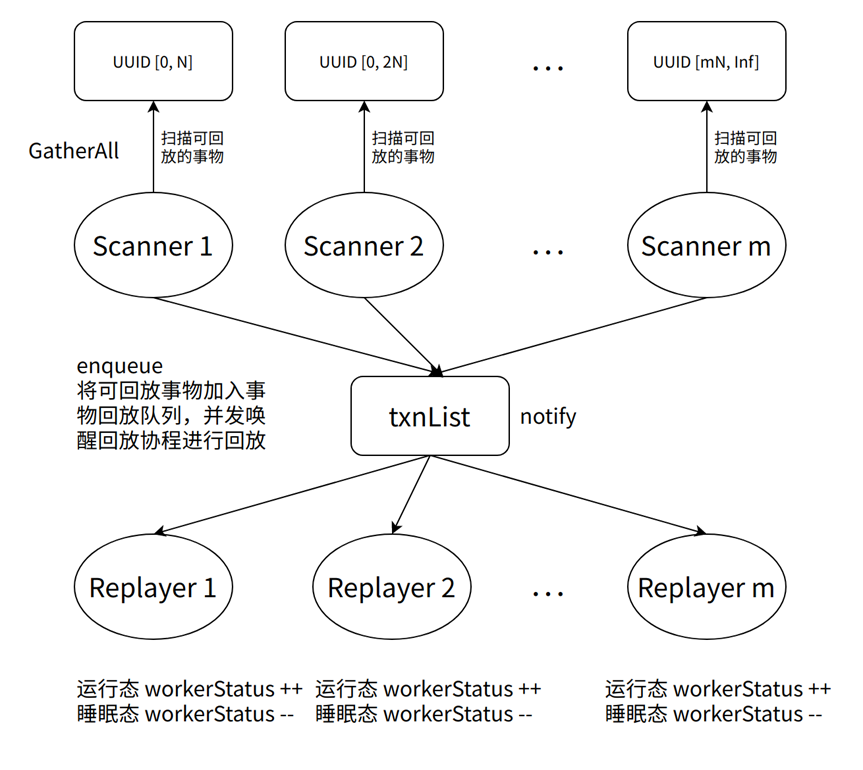
Le cycle de vie de la coroutine du thread de lecture est tel qu'illustré dans la figure 3. Le thread de lecture est en état de veille juste après son démarrage. Lorsqu'il y a une lecture de transaction, il sera réveillé de manière aléatoire. La coroutine du thread de relecture réveillée effectuera des tâches de relecture de transaction et nettoiera les dépendances de transaction.
Lorsqu'une transaction rejouable est trouvée, si le nombre de transactions rejouables s'avère égal à 1, la coroutine actuelle effectuera la lecture pour réduire le coût d'un commutateur de CPU lorsque plus d'une transaction rejouable est trouvée, la coroutine du thread de lecture le fera ; supprimez le premier Pour une transaction rejouable, ajoutez txnList pour réveiller d'autres coroutines pour la lecture des transactions afin d'obtenir de meilleures performances de simultanéité de lecture.
4. Problème de commutation simultanée
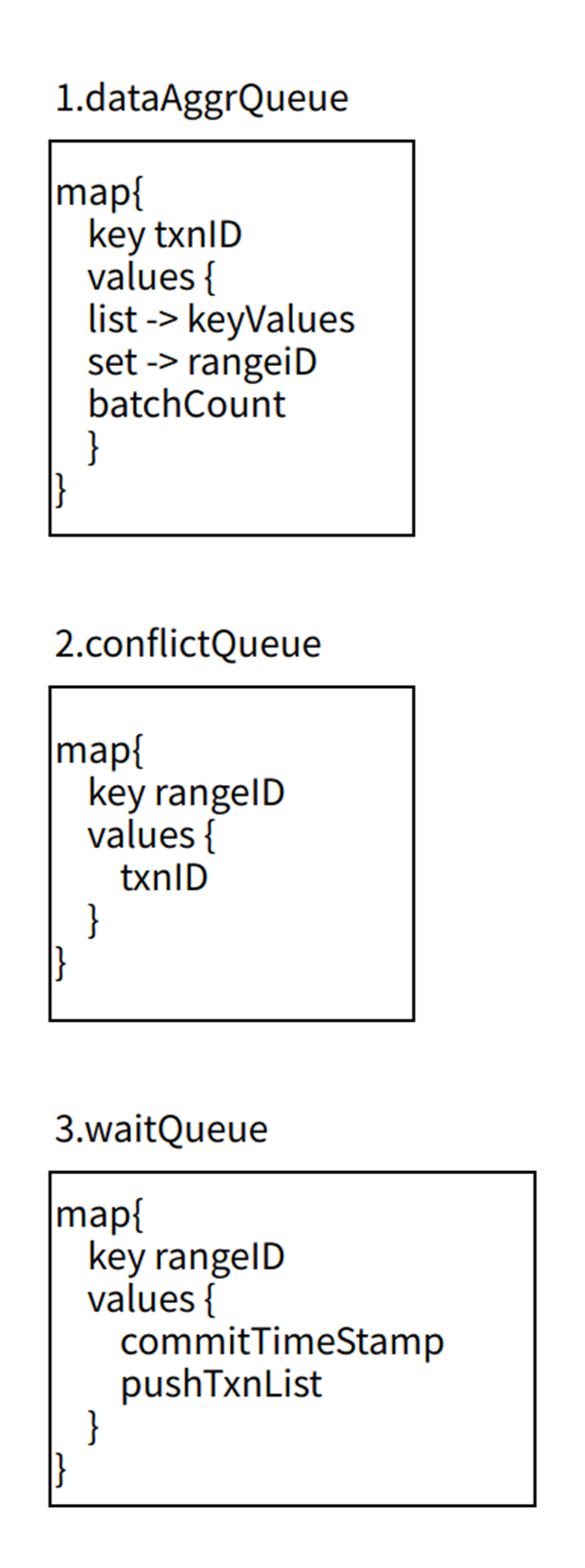
Lorsqu'un nettoyage simultané est adopté, en raison du problème de commutation du processeur, il est nécessaire de traiter les transactions réexécutables découvertes à plusieurs reprises et d'effectuer un traitement d'idempotence défensif pour le même ID de transaction découvert à plusieurs reprises, comme le montre la figure 4 ci-dessous. Par conséquent, il est nécessaire d’introduire txnIDSet pour chaque transaction rejouable pour un traitement idempotent.
5. Comment juger si la lecture est terminée
Étant donné que l'analyse simultanée et la lecture simultanée sont adoptées, le processus de lecture doit se terminer une fois la lecture de toutes les transactions réexécutables terminée. La définition de la fin de la lecture est donnée ici.
Lorsque toutes les transactions rejouables ont été relues, la lecture est considérée comme terminée. Les transactions rejouables sont divisées en trois catégories : les transactions rejouables découvertes dans le passé/les transactions rejouables découvertes maintenant/les transactions rejouables découvertes dans le futur.
Les transactions réexécutables découvertes dans le passé seront ajoutées à la txnList. Les transactions réexécutables découvertes maintenant sont lues par le thread de lecture. Les transactions réexécutables découvertes dans le futur sont découvertes par le thread d'analyse qui analyse les UUID.
- La condition pour mettre fin à la lecture des transactions découvertes dans le passé est que txnList soit vide ;
- La condition trouvée maintenant pour la fin de la lecture de la transaction est que la somme de tous les WorkersStatus est 0 ;
- La condition pour la fin de la lecture des transactions découvertes dans le futur est que tous les threads d'analyse ne peuvent pas être découverts par GatherAll en analysant les transactions réexécutables.
6. Optimisation des performances
Selon le nombre de processeurs, le nombre de coroutines de lecture du fil d'analyse et du fil de lecture peut être ajusté dynamiquement pour répartir raisonnablement la charge des deux coroutines. Cela permet de tirer pleinement parti des performances des processeurs multicœurs et d'améliorer le débit et la réactivité du système.
J'ai décidé d'abandonner les logiciels industriels open source. OGG 1.0 est sorti, Huawei a contribué à tout le code source. Ubuntu 24.04 LTS a été officiellement publié. L'équipe de Google Python Foundation a été tuée par la "montagne de merde de code" . ". Fedora Linux 40 a été officiellement lancé. Une société de jeux bien connue a publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans. China Unicom lance la première version chinoise Llama3 8B au monde du modèle open source. Pinduoduo est condamné à compenser 5 millions de yuans pour concurrence déloyale Méthode de saisie dans le cloud domestique - seul Huawei n'a aucun problème de sécurité de téléchargement de données dans le cloud.