
Auteur : Chen Xin (Shenxiu)
Bonjour à tous, je suis Chen Xin, directeur technique produit de Tongyi Lingma. Au cours des huit dernières années, j'ai travaillé au sein du groupe Alibaba sur la performance R&D, c'est-à-dire le travail lié aux outils de R&D.
Nous avons commencé à créer une plate-forme DevOps unique en 2015, puis avons créé Cloud Effect, qui vise à cloudifier la plate-forme DevOps. D'ici 2023, nous pensons clairement qu'après l'arrivée de l'ère des grands modèles, les outils logiciels seront confrontés à une innovation approfondie. La combinaison des grands modèles et des chaînes d'outils logiciels fera entrer la recherche et le développement de logiciels dans la prochaine ère.
Alors, où est son premier arrêt ? En fait, il s'agit d'une programmation auxiliaire, nous avons donc commencé à créer le produit Tongyi Lingma , qui est un outil auxiliaire d'IA basé sur un grand modèle de code. Aujourd'hui, je profite de cette occasion pour partager avec vous quelques détails sur la mise en œuvre de la technologie Tongyi Lingma et comment nous envisageons le développement de grands modèles dans le domaine de la recherche et du développement de logiciels.
Je vais le partager en trois parties. La première partie présente d'abord l'impact fondamental de l'AIGC sur la recherche et le développement de logiciels, et présente les tendances actuelles d'un point de vue macro ; la deuxième partie présentera le modèle Copilot, et la troisième partie est la progression des futurs produits Agent de développement logiciel. Pourquoi j'ai mentionné Copilot Agent, je vous l'expliquerai plus tard.
L’impact fondamental de l’AIGC sur le développement de logiciels
Cette image est une image que j’ai dressée au cours des dernières années. Je pense que les principaux facteurs d’influence de l’efficacité de la R&D des entreprises sont ces trois points.
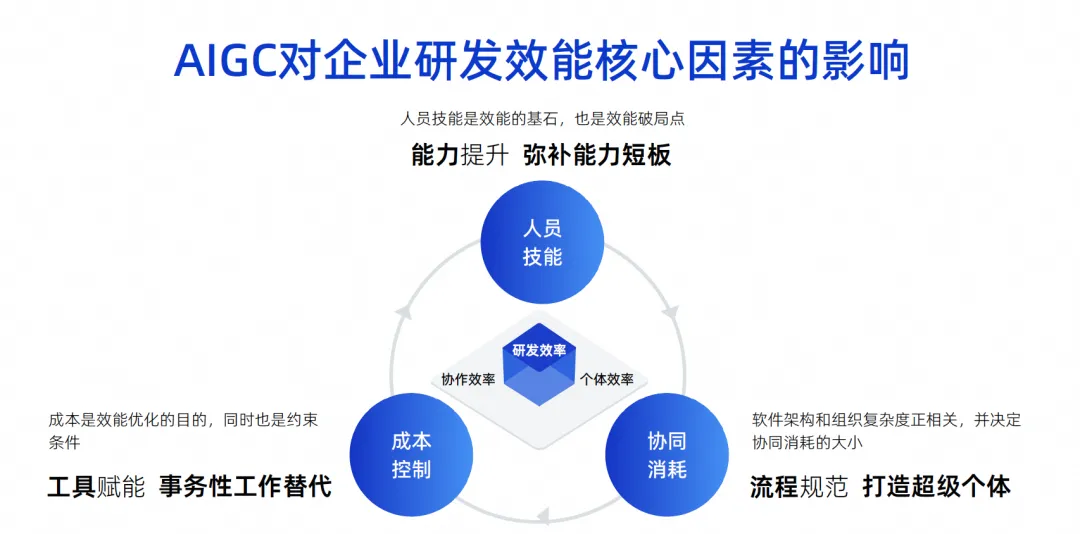
Le premier point concerne les compétences relationnelles. Les compétences du personnel déterminent un facteur très important dans l'efficacité de la R&D d'une entreprise. Par exemple, Google peut recruter des ingénieurs dont les capacités personnelles sont dix fois plus fortes que les autres. Une personne équivaut alors à dix personnes. les ingénieurs compétents auront une efficacité de combat très puissante et pourront même réaliser le full stack. Leur répartition des rôles peut être très simple, leur travail est très efficace et leur efficacité finale est également très grande.
Mais en réalité, peu de nos entreprises, notamment chinoises, peuvent atteindre le niveau de Google. Il s'agit d'un facteur d'influence objectif. Nous pensons que les compétences du personnel sont la pierre angulaire de l'efficacité et, bien entendu, elles constituent également le point de rupture de l'efficacité.
Le deuxième point est la consommation collaborative. Étant donné que nous ne pouvons pas exiger que chaque ingénieur soit hautement compétent, chacun doit avoir une division professionnelle du travail. Par exemple, certains s'occupent de la conception de logiciels et d'autres du développement, des tests et de la gestion de projet. À mesure que la complexité de l'architecture logicielle de l'équipe composée de ces personnes augmente, la complexité de l'organisation augmentera également proportionnellement, ce qui entraînera une augmentation de la consommation collaborative, ralentissant finalement l'efficacité globale de la R&D.
Le troisième point est le contrôle des coûts. Nous avons constaté que lorsqu'on travaille sur des projets, les gens ne peuvent pas toujours être riches, il y a toujours une pénurie de main-d'œuvre et il est impossible d'avoir des fonds illimités pour recruter dix fois plus d'ingénieurs, c'est donc aussi une contrainte.
Aujourd’hui, à l’ère de l’AIGC, ces trois facteurs ont produit des changements fondamentaux.
En termes de compétences du personnel, l’assistance de l’IA peut rapidement améliorer les capacités de certains ingénieurs juniors. En fait, il existe des rapports à ce sujet à l'étranger. L'effet des ingénieurs juniors utilisant des outils d'assistance au code est nettement supérieur à celui des ingénieurs seniors. Pourquoi ? Parce que ces outils sont de très bons substituts au travail de débutant, ou leur effet auxiliaire, ils peuvent rapidement combler les lacunes des jeunes ingénieurs.
En termes de consommation collaborative, si l’IA peut devenir un super individu aujourd’hui, elle sera en réalité utile pour réduire la consommation collaborative des processus. Par exemple, il n'est pas nécessaire de traiter avec des personnes pour certaines tâches simples, l'IA peut le faire directement et il n'est pas nécessaire d'expliquer à tout le monde comment tester les exigences. L'IA peut simplement effectuer des tests simples, ce qui améliore l'efficacité du temps. . Par conséquent, la consommation collaborative peut être efficacement réduite grâce aux super individus.
En termes de contrôle des coûts, en effet, un grand nombre d’utilisations de l’IA vont remplacer le travail transactionnel, y compris l’utilisation actuelle de grands modèles de code pour l’assistance au code, qui devrait également remplacer 70 % du travail transactionnel quotidien.
Si nous y regardons spécifiquement, il y aura ces quatre défis et opportunités en matière de renseignement.

Le premier est l'efficacité individuelle. Comme je viens de vous le présenter, le travail répétitif et la communication simple d'un grand nombre d'ingénieurs R&D peuvent être réalisés grâce à l'IA. Il s'agit d'un modèle Copilot.
Un autre aspect de l’efficacité de la collaboration est que certaines tâches simples peuvent être effectuées directement par l’IA, ce qui peut réduire la consommation de collaboration. Je viens de l’expliquer clairement.
Le troisième est l’expérience en R&D. Sur quoi la chaîne d’outils DevOps se concentrait-elle dans le passé ? Un à un, ils forment une grande chaîne d’assemblage et toute la chaîne d’outils. En fait, chaque chaîne d'outils peut avoir des habitudes d'utilisation différentes selon les entreprises, et peut même avoir des systèmes de compte différents, des interfaces différentes, des interactions différentes et des autorisations différentes. Cette complexité entraîne des coûts de changement de contexte et de compréhension très importants pour les développeurs, ce qui rend invisiblement les développeurs très mécontents.
Mais certains changements ont eu lieu à l'ère de l'IA. Nous pouvons utiliser le langage naturel pour faire fonctionner de nombreux outils via une entrée de dialogue unifiée, et même résoudre de nombreux problèmes dans la fenêtre du langage naturel.
Laissez-moi vous donner un exemple. Par exemple, si nous vérifions s'il y a un problème de performances dans une instruction SQL, que devons-nous faire ? Vous pouvez d'abord extraire l'instruction SQL dans le code, la transformer en instruction exécutable, puis la placer dans un système DMS pour la diagnostiquer afin de voir si elle utilise des index et s'il y a des problèmes, puis juger manuellement si elle l'est. nécessaire ou non. Modifiez ce SQL pour l'optimiser, et enfin changez-le dans l'EDI. Ce processus nécessite de changer de système et beaucoup de choses doivent être faites.
À l'avenir, si nous disposons d'outils d'intelligence de code, nous pourrons encercler un code et demander au grand modèle s'il y a un problème avec ce SQL. Ce grand modèle peut appeler indépendamment certains outils, tels que le système DMS, pour l'analyser. les résultats obtenus peuvent me dire directement comment SQL doit être optimisé via le grand modèle et me dire directement les résultats. Il suffit de l'adopter pour résoudre le problème. L'ensemble du lien opérationnel sera raccourci, l'expérience sera améliorée et la R&D. l’efficacité sera améliorée.
Le quatrième concerne les actifs numériques. Dans le passé, tout le monde écrivait du code et le mettait là, et cela se transformait en une montagne de codes ou de passifs. Bien sûr, il existe de nombreuses mines d'or en suspens qui n'ont pas été découvertes, et il existe encore de nombreux documents. que je veux trouver. L'heure est introuvable.
Mais à l'ère de l'IA, l'une des choses les plus importantes que nous faisons est de trier nos actifs et nos documents, et d'autonomiser les grands modèles via SFT et RAG, afin que les grands modèles deviennent plus intelligents et plus conformes à la personnalité du entreprise. Par conséquent, les changements actuels dans les méthodes d’interaction homme-machine entraîneront des changements dans l’expérience.

L'intelligence artificielle décompose actuellement les facteurs d'influence. Son objectif principal est d'apporter trois changements dans les méthodes d'interaction homme-machine. La première est que l’IA deviendra un copilote, combiné à des outils, et que les gens pourront ensuite la commander pour nous aider à compléter certains outils ponctuels. À la deuxième étape, tout le monde devrait avoir un consensus. Il devient un agent, ce qui signifie qu'il a la capacité d'effectuer des tâches de manière indépendante, notamment d'écrire du code ou d'effectuer des tests de manière indépendante. En fait, l’outil agit comme un expert multi-domaines. Il suffit de donner le contexte et de compléter l’alignement des connaissances. Dans la troisième étape, nous jugeons que l'IA peut devenir un décideur, car dans la deuxième étape, le décideur est toujours un humain. Dans la troisième étape, il est possible que le grand modèle ait certaines capacités de prise de décision. y compris des capacités d’intégration et d’analyse d’informations plus avancées. À l'heure actuelle, les gens se concentreront davantage sur la créativité et la correction des affaires, et beaucoup de choses peuvent être laissées aux grands modèles. Grâce à ce changement dans les différents modes homme-machine, notre efficacité globale de travail deviendra plus élevée.

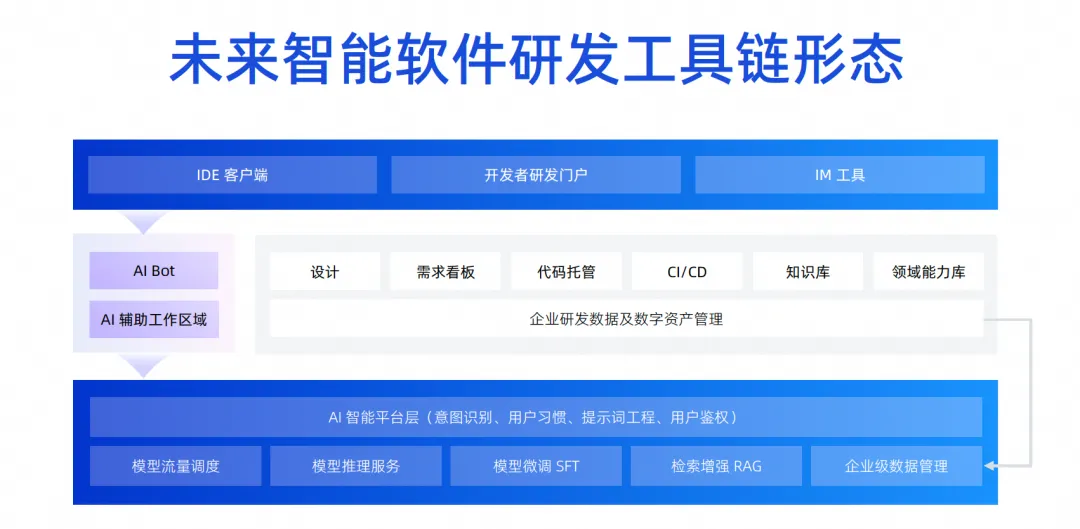
Un autre point est que la forme de transfert de connaissances dont nous venons de parler a également subi des changements fondamentaux. Dans le passé, le problème du transfert de connaissances était résolu par le bouche à oreille, la formation et l'ancien apportant le nouveau. Il est très probable que cela ne sera pas nécessaire à l'avenir. Il nous suffit de doter le modèle de connaissances commerciales et d'expériences dans le domaine, et de permettre à chaque ingénieur de développement d'utiliser des outils intelligents. Ces connaissances peuvent être transférées au processus de recherche et de développement. outils, et cela deviendra l'image de droite ci-dessus. Il s'agit désormais d'une chaîne d'outils unique pour DevOps. Après avoir accumulé un grand nombre d'actifs de code et de documents, ces actifs sont triés et assemblés avec le grand modèle. Grâce à RAG et SFT, le modèle est intégré dans chaque lien de l'outil DevOps, générant ainsi plus de données, formant ainsi un tel transfert. cycle , dans ce processus, les développeurs de première ligne peuvent profiter des dividendes ou des capacités apportées par les actifs.
Ce qui précède est mon introduction, d'un point de vue macro, aux principaux facteurs affectant l'efficacité de la R&D des grands modèles, ainsi qu'aux deux changements de forme les plus importants : le premier est le changement de forme de l'interaction homme-machine, et le second est le changement de forme. changement dans la manière dont les connaissances sont transférées. En raison de diverses limitations techniques et problèmes au cours de la phase de développement des grands modèles, ce que nous faisons le mieux est le mode d'interaction homme-machine Copilot. Nous présenterons donc ensuite une partie de notre expérience et comment créer le meilleur mode d'interaction homme-machine Copilot. .
Créez votre meilleure pose de copilote
Nous pensons que le modèle d'interaction homme-machine de développement de code ne peut actuellement résoudre que des problèmes tels que les petites tâches, les problèmes qui nécessitent une adoption manuelle et les problèmes à haute fréquence, tels que l'achèvement du code, nous aident à générer un paragraphe, nous l'acceptons. puis générons un autre paragraphe, prenons une autre section. C'est un problème très fréquent, et il y a aussi le problème de la sortie courte. Nous ne générerons pas un projet en même temps, ni même une classe en même temps. fonction ou quelques lignes à chaque fois. Pourquoi faisons-nous cela? En fait, cela a beaucoup à voir avec les limites des capacités propres du modèle.
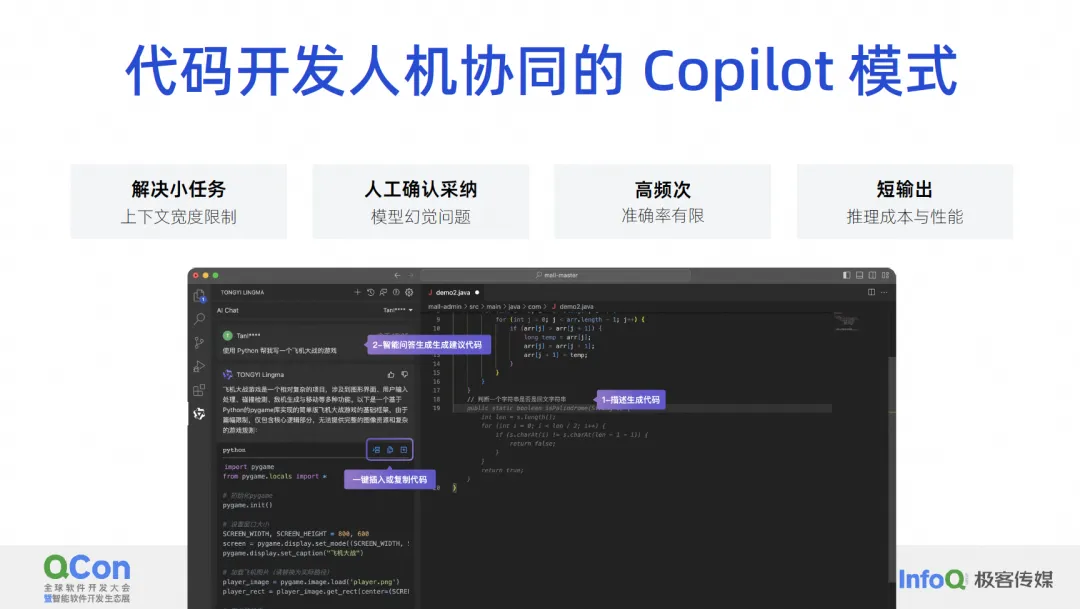
Parce que la largeur de notre contexte actuel est encore très limitée, si nous voulons répondre à une exigence, il n'y a aucun moyen de lui transmettre toutes les connaissances de base en même temps, nous pouvons donc soit utiliser l'agent pour la diviser en un tas de petites tâches et résolvez-les étape par étape. Ou laissez-le accomplir la tâche la plus simple en mode Copilot, comme générer un petit morceau de code en fonction d'un commentaire. C'est ce que nous appelons résoudre de petites tâches.
En termes d’adoption manuelle, les humains doivent désormais porter un jugement sur les résultats générés par les grands modèles de code. Ce que nous faisons actuellement bien, c'est peut-être un taux d'adoption de 30 à 40 %, ce qui signifie que plus de la moitié de nos codes générés sont en réalité inexacts ou ne répondent pas aux attentes des développeurs, nous devons donc constamment éliminer les problèmes d'illusion.
Cependant, la chose la plus importante pour que les grands modèles soient réellement utilisables au niveau de la production est la confirmation manuelle. Ensuite, ne générez pas trop de modèles à haute fréquence, mais générez-en un peu à chaque fois, car le coût de la confirmation manuelle de ce code est. OK affecte également les performances.Cet article parlera de certaines de nos réflexions et de ce que nous faisons, et résoudra le problème de la précision limitée grâce à la haute fréquence. De plus, une production insuffisante est principalement due à des problèmes de performances et de coûts.
Le modèle actuel d'assistant de code atteint en fait très précisément certaines limitations techniques des grands modèles, de sorte qu'un tel produit peut être lancé rapidement. Il a une très bonne opportunité. À notre avis, le modèle Copilot que les développeurs apprécient le plus repose sur les quatre mots-clés suivants : des besoins à haute fréquence et rigides, à portée de main, savoir ce que je veux et qui m'est exclusif.

La première est que nous devons résoudre des scénarios à haute fréquence et urgents, afin que les développeurs puissent sentir que cette chose est vraiment utile, pas seulement un jouet.
Le second est à portée de main, c’est-à-dire qu’il peut être réveillé à tout moment et peut nous aider à résoudre des problèmes à tout moment. Je n'ai plus besoin de rechercher des codes via différents moteurs de recherche comme avant. C'est comme s'il était à mes côtés et je peux le réveiller à tout moment pour m'aider à résoudre des problèmes.
La troisième est de savoir ce que je pense, c'est-à-dire que l'exactitude de mes réponses à mes questions et le moment où il répond à mes questions sont très importants.
Enfin, il doit m'appartenir. Il peut comprendre certaines de mes connaissances privées, plutôt que de comprendre uniquement des choses entièrement open source. Discutons de ces quatre points en détail.
La haute fréquence est juste nécessaire
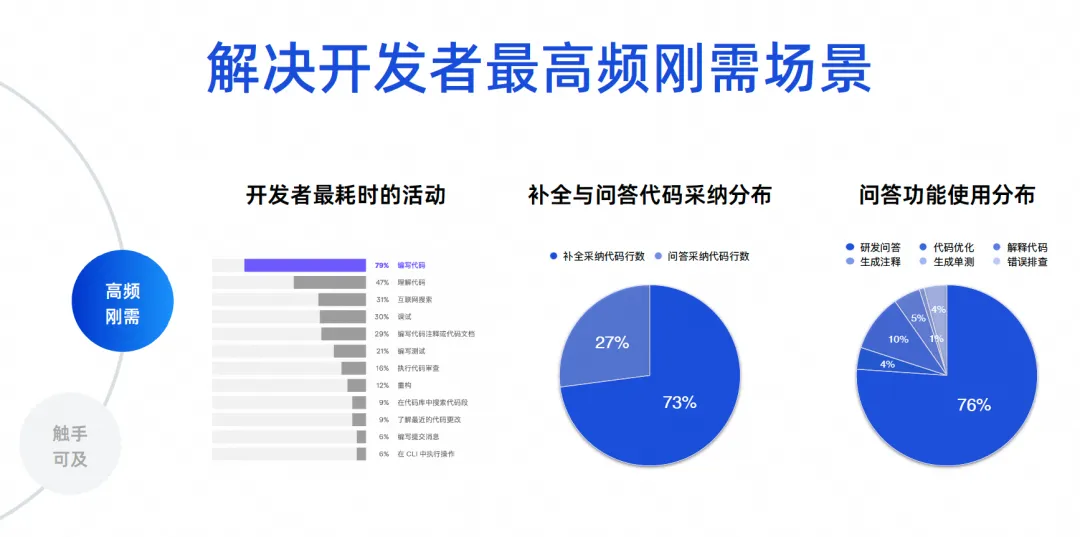
Nous devons déterminer quels sont les scénarios les plus fréquents pour le développement de logiciels. J'ai ici quelques données réelles. Les premières données proviennent d'un rapport écologique des développeurs réalisé par JetBrains en 2023, qui compilait les activités les plus chronophages des développeurs. On constate que 70 à 80 % écrivent du code, comprennent le code. et recherchez sur Internet, déboguez, rédigez des commentaires et rédigez des tests. Ces scénarios sont en fait les fonctions des outils d'intelligence de code. Les problèmes fondamentaux résolus par des produits comme Tongyi Lingma sont en fait les problèmes les plus fréquents.
Les deux dernières données sont l'analyse des données de centaines de milliers d'utilisateurs sur Tongyi Lingma Online. 73 % du code que nous adoptons actuellement en ligne provient de tâches d'achèvement, et 27 % provient de l'adoption de tâches de questions et réponses. Ainsi, aujourd'hui, un grand nombre d'IA remplacent les personnes dans l'écriture du code, et elles sont toujours générées entre les lignes de l'IDE. C'est un résultat reflété par la situation réelle. Vient ensuite la proportion d'utilisation de la fonction Q&A. 76 % de la proportion provient des questions et réponses R&D, et les 10 % restants sont une série de tâches de code telles que l'optimisation du code et l'interprétation du code. Par conséquent, la grande majorité des développeurs utilisent encore nos outils pour demander des connaissances communes en R&D, ou utilisent le langage naturel pour générer des algorithmes à partir de grands modèles de code afin de résoudre certains petits problèmes.
Les 23 % suivants sont nos véritables tâches de codage détaillées. Il s'agit de donner à chacun un aperçu des données. Nous avons donc nos objectifs fondamentaux. Premièrement, nous devons résoudre le problème de la génération de code, notamment entre les lignes. Deuxièmement, il est nécessaire de résoudre les problèmes de précision et de professionnalisme liés à la R&D.
À portée de main

Ce dont nous voulons finalement parler, c'est de créer une expérience de programmation immersive. Nous espérons que la plupart des problèmes rencontrés par les développeurs aujourd'hui pourront être résolus au sein de l'IDE au lieu de devoir être résolus.
Quelle a été notre expérience dans le passé ? Lorsque vous rencontrez un problème, vous devez rechercher sur Internet ou demander à d'autres, puis faire votre propre jugement après avoir demandé autour de vous. Enfin, écrivez le code, copiez-le, placez-le dans l'EDI pour le débogage et la compilation, et vérifiez à nouveau s'il est bon. échoue. Cela prendra beaucoup de temps. Nous espérons pouvoir demander directement au grand modèle dans l'EDI et laisser le grand modèle générer du code pour moi, afin que l'expérience soit très agréable. Grâce à un tel choix technique, nous avons résolu le problème de l’expérience de programmation immersive.
La tâche d'achèvement est une tâche sensible aux performances, et sa sortie doit être de 300 à 500 millisecondes, de préférence pas plus d'une seconde, nous avons donc un modèle à petits paramètres, qui est principalement utilisé pour générer du code, et la majeure partie de sa formation Le corpus vient aussi du code. Bien que les paramètres du modèle soient petits, la précision de la génération de code est très élevée.
La deuxième consiste à effectuer des tâches spéciales. Nous avons encore 20 à 30 % des tâches réelles qui en découlent, dont sept tâches telles que la génération d'annotations, les tests unitaires, l'optimisation du code et le dépannage des erreurs opérationnelles.
Nous utilisons actuellement un modèle à paramètres modérés. Les principales considérations ici sont, premièrement, l’efficacité de la génération et, deuxièmement, le réglage. Pour un modèle à très grands paramètres, notre coût de réglage est très élevé, mais sur ce modèle à paramètres moyens, sa compréhension du code et ses effets de génération de code sont déjà bons, nous avons donc choisi le modèle à paramètres moyens.
Ensuite sur les grands modèles, notamment en répondant à plus de 70 % de nos questions R&D, nous recherchons une grande précision et une connaissance en temps réel. Nous avons donc superposé notre technologie RAG via un modèle à paramètres maximum, lui permettant de se connecter à une base de connaissances basée sur Internet en temps quasi réel, de sorte que la qualité et l'effet de ses réponses sont très élevés, et qu'elle peut grandement éliminer les illusions du modèle et améliorer la réponse. qualité. Nous prenons en charge l’ensemble de l’expérience de programmation immersive à travers trois de ces modèles.

Le deuxième point est que nous devons implémenter plusieurs terminaux, car ce n'est qu'en couvrant plus de terminaux que nous pourrons couvrir plus de développeurs. Actuellement, Tongyi Lingma prend en charge le code VS et JetBrains. Il résout principalement les problèmes de déclenchement, les problèmes d'affichage et certains problèmes d'interactivité.
Au niveau de base, notre service d'agent local est un processus indépendant. Il y aura une communication entre ce processus et le plug-in ci-dessus. Ce processus aborde principalement certaines fonctionnalités essentielles du code, notamment la complétion intelligente du code, la gestion des sessions et les agents.
De plus, les services d'analyse syntaxique sont également très importants. Nous avons besoin d'une analyse syntaxique pour résoudre les problèmes de référence entre fichiers. Si nous voulons améliorer la récupération locale, nous avons également besoin d'un moteur de récupération de vecteurs locaux léger. Par conséquent, l’ensemble du service back-end peut ainsi être rapidement étendu.
Nous avons également une fonctionnalité. Nous avons un petit modèle local hors ligne de quelques dixièmes de B pour implémenter la complétion sur une seule ligne dans des langues individuelles. Cela peut être fait hors ligne, y compris JetBrains. Récemment, JetBrains a également lancé un petit modèle qui s'exécute localement. . De cette manière, certains de nos problèmes de sécurité et de confidentialité des données, tels que la gestion des sessions locales et le stockage local, sont tous placés sur l'ordinateur local.

je sais ce que je pense
Je sais ce que je pense. Concernant l'outil plug-in IDE, je pense qu'il y a plusieurs points. Le premier est le moment du déclenchement. Lorsqu'il est déclenché, il a également un grand impact sur l'expérience du développeur. Par exemple, dois-je le déclencher lorsque j’entre dans un espace ? Doit-il être déclenché lorsque l'EDI a généré une invite ? Doit-il se déclencher lors de la suppression de ce code ? Nous avons probablement plus de 30 à 50 scénarios à résoudre. La question de savoir si le code doit être déclenché dans ce scénario peut être résolue par des règles. Tant que nous l'explorons attentivement et étudions l'expérience du développeur, nous ne pouvons pas le résoudre. .
Mais en termes de longueur de génération de code, nous pensons que c'est plus difficile. Parce qu'à différents endroits dans différentes zones d'édition, la longueur du code qu'il génère affecte directement notre expérience. Si les développeurs ont tendance à générer uniquement une seule ligne de code, le problème est que le développeur ne peut pas comprendre l'intégralité du contenu généré. Par exemple, lors de la génération d'une fonction, il ne sait pas ce que la fonction va faire, ou lors de la génération d'un if. déclaration, il ne sait pas ce qu'il y a à l'intérieur de l'instruction if. Quelle est la logique métier ? Il n'y a aucun moyen de juger complètement les unités fonctionnelles, ce qui affecte son expérience.
Si nous utilisons des règles fixes pour le faire, cela posera également un problème, c'est-à-dire que ce sera relativement rigide. Notre approche est donc en fait basée sur les informations sémantiques du code. Grâce à la formation et à un grand nombre d'échantillons, le modèle comprend combien de temps il doit être généré dans quel scénario aujourd'hui. Nous avons implémenté le modèle pour déterminer automatiquement le niveau de classe, la fonction. niveau, L'intensité de génération au niveau du bloc logique et au niveau de la ligne est appelée prise de décision adaptative en matière d'intensité de génération. En faisant beaucoup de pré-entraînement, nous permettons au modèle de percevoir, améliorant ainsi la précision de la génération. Nous pensons que c'est aussi un élément technique clé.
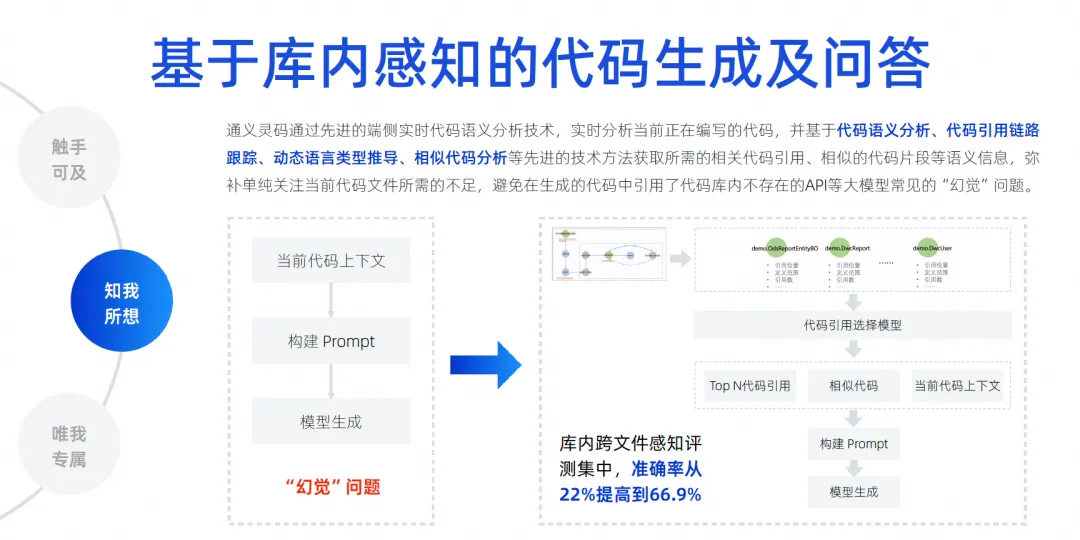
La chose la plus cruciale à l’avenir est de savoir comment éliminer l’illusion du modèle, car ce n’est que lorsque l’illusion est suffisamment éliminée que notre taux d’adoption peut être amélioré. Par conséquent, nous devons implémenter une prise en compte du contexte entre fichiers au sein de la bibliothèque. Ici, nous effectuons de nombreuses analyses sémantiques basées sur le code, le suivi de la chaîne de référence, le code similaire et la dérivation dynamique de types de langage.
La chose la plus importante est d'essayer par tous les moyens pour deviner de quel type de connaissances de base le développeur peut avoir besoin pour occuper ce poste. Ces éléments peuvent également impliquer certains langages, frameworks, habitudes d'utilisation, etc. Nous utilisons diverses choses pour les combiner. contexte, hiérarchisez-les, mettez les informations les plus critiques dans le contexte, puis transférez-les au grand modèle pour dérivation, permettant au grand modèle d'éliminer les illusions. Grâce à cette technologie, nous pouvons réaliser un ensemble de tests contextuels multi-fichiers. Notre précision est passée de 22% à 66,9% .
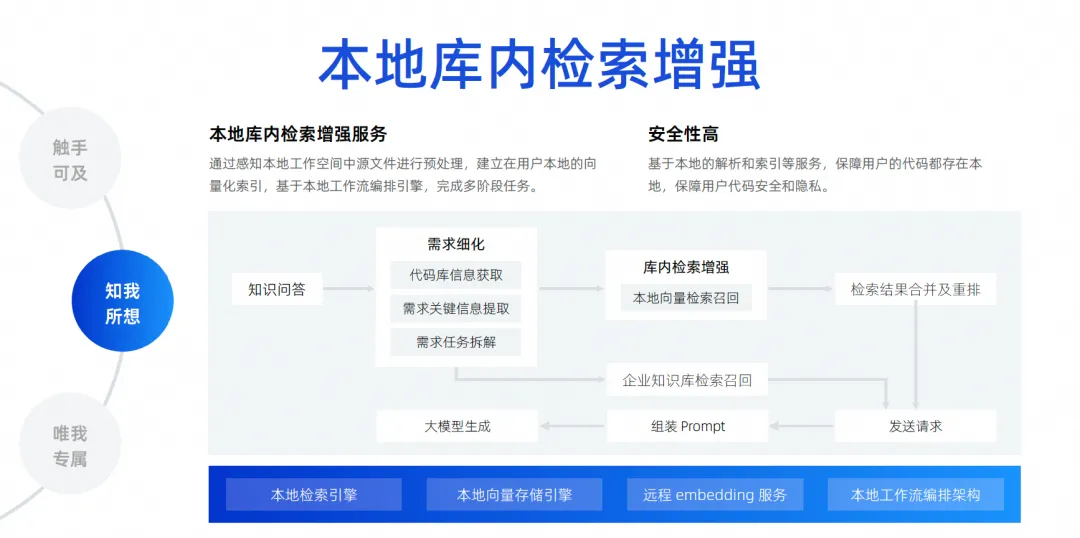
Le dernier est notre amélioration de la recherche locale en bibliothèque. Comme je viens de le dire, la connaissance du contexte ne fait que deviner le contexte du développeur à l'emplacement du déclencheur. Un scénario plus courant est qu'aujourd'hui les développeurs veulent poser une question et laisser le grand modèle m'aider à résoudre un problème basé sur tous les fichiers de la bibliothèque locale, comme m'aider à corriger un bug, m'aider à ajouter une exigence, m'aider remplir un fichier, et implémenter automatiquement des ajouts, des suppressions, des modifications et des recherches, et même ajouter une nouvelle version du package à mon fichier Pompt. Il existe en fait de nombreux besoins comme celui-ci. Pour y parvenir, nous devons en fait brancher un moteur de recherche. pour le grand modèle. Puisqu'il nous est impossible d'insérer tous les fichiers de l'ensemble du projet dans le grand modèle, en raison de l'impact de la largeur du contexte, nous devons utiliser une technologie appelée amélioration de la recherche locale en bibliothèque .
Cette fonction permet de réaliser nos questions-réponses gratuites basées sur la bibliothèque et d'établir un service d'amélioration de la recherche locale dans la bibliothèque. Nous jugeons que cette méthode est la meilleure pour l'expérience des développeurs et offre la plus haute sécurité.
Le code n'a pas besoin d'être téléchargé sur le cloud pour compléter l'intégralité du lien. Du point de vue de l'ensemble du lien, après qu'un développeur ait posé une question, nous accéderons à la base de code pour extraire les informations clés nécessaires au démontage de la tâche, une fois le démontage terminé, nous effectuerons une recherche et un rappel de vecteurs locaux, puis. fusionner et réorganiser les résultats de la recherche et rechercher dans la base de connaissances de données interne de l'entreprise, car l'entreprise dispose d'une gestion unifiée de la base de connaissances, qui est au niveau de l'entreprise. Enfin, toutes les informations sont résumées et envoyées au grand modèle, afin que le grand modèle puisse générer et résoudre des problèmes.

Seulement pour moi
Je pense que si les entreprises veulent obtenir un très bon effet avec de grands modèles de code, elles ne peuvent pas échapper à ce niveau. Par exemple, comment réaliser des scénarios personnalisés pour les données d'entreprise, par exemple, au stade de la gestion de projet, comment générer de grands modèles selon certains formats et spécifications inhérents aux exigences/tâches/contenus de défauts, nous aidant à réaliser le démontage automatique et le renouvellement automatique des certaines exigences. Rédaction, synthèse automatique, etc.
La phase de développement est peut-être celle à laquelle tout le monde prête le plus d'attention. Les entreprises disent souvent qu'elles doivent avoir des spécifications de code conformes à celles de l'entreprise, faire référence à leurs propres bibliothèques tierces, appeler des API pour générer du SQL, y compris en utilisant certains front-end. frameworks, bibliothèques de composants, etc. auto-développés par l'entreprise, tous appartiennent à des scénarios de développement. Les scénarios de test doivent également générer des cas de tests conformes aux spécifications de l'entreprise et même comprendre l'activité. Dans les scénarios d'exploitation et de maintenance, vous devez toujours rechercher les connaissances de l'entreprise en matière d'exploitation et de maintenance, puis répondre aux questions pour obtenir certaines des API d'exploitation et de maintenance de l'entreprise afin de générer rapidement du code. Ce sont les scénarios de personnalisation des données d’entreprise que nous pensons devoir mettre en œuvre. L'approche spécifique consiste à y parvenir grâce à l'amélioration de la récupération ou à un entraînement de réglage fin.
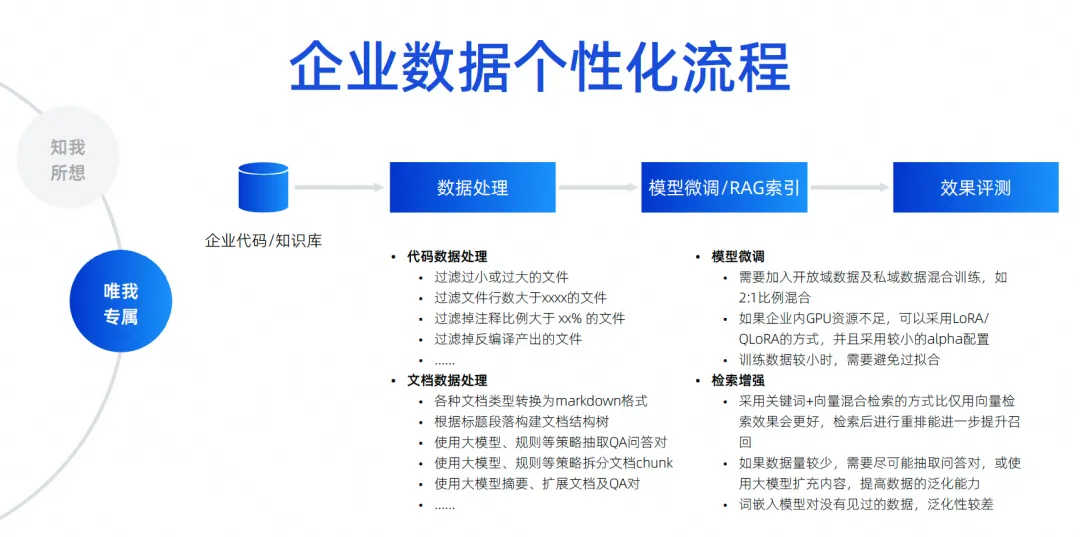
Ici, j'ai répertorié quelques scénarios simples et des éléments auxquels il faut prêter attention, notamment la manière dont le code doit être traité, la manière dont les documents doivent être traités et le code doit être filtré, nettoyé et structuré avant de pouvoir être utilisé.
Lors de notre processus de formation, nous devons considérer le mélange de données de domaine ouvert et de données de domaine privé. Par exemple, nous devons procéder à différents ajustements de paramètres. En termes d'amélioration de la récupération, nous devons envisager différentes stratégies d'amélioration de la récupération, notamment comment accéder aux informations contextuelles dont nous avons besoin dans les scénarios de génération de code et comment nous le faisons. accéder aux informations contextuelles des réponses dont nous avons besoin dans le scénario de questions et réponses est l'amélioration de la récupération.
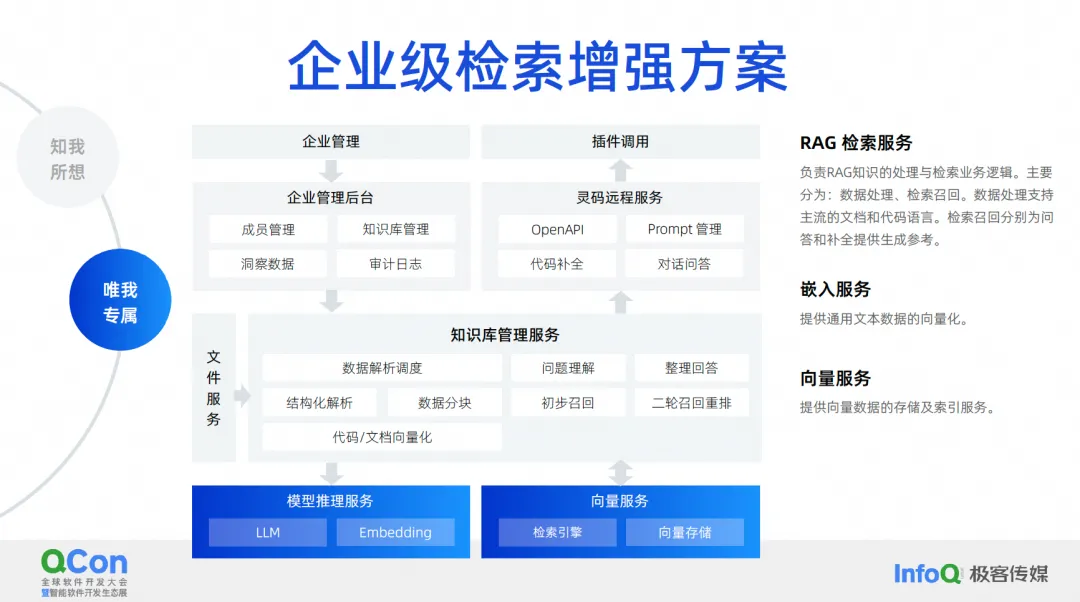
Ce que nous voulons faire, c'est une solution d'amélioration de la récupération au niveau de l'entreprise . Le schéma architectural actuel de la solution d'amélioration de la récupération au niveau de l'entreprise ressemble à ceci. Au milieu se trouve le service de gestion de la base de connaissances, y compris la planification de l'analyse des données, la compréhension des questions, l'organisation des réponses, l'analyse structurée, la segmentation des données, etc. Les fonctionnalités de base se trouvent au milieu et en bas se trouvent nos services d'intégration les plus couramment utilisés. , y compris les services pour les grands modèles, le stockage et la récupération de vecteurs.
Vers le haut se trouvent certains backends que nous gérons. Dans ce scénario, ils prennent en charge notre amélioration de la récupération des documents et l'amélioration de la récupération de la génération de code. La génération de code vise à compléter la récupération et l'enrichissement de ce scénario. Les méthodes et technologies de traitement requises sont en réalité légèrement différentes de celles des documents.
Dans le passé, nous avons mené des recherches universitaires avec l'Université de Fudan pendant plusieurs années et nous sommes très reconnaissants de leurs efforts. Nous avons également publié certains articles. À cette époque, les résultats de notre ensemble de tests étaient également basés sur un modèle 1.1. à 1B, couplé à l'amélioration de la recherche, la précision et l'effet peuvent en fait obtenir le même effet que ceux d'un modèle 7B ou supérieur.
Évolution future du produit d'agent de développement logiciel
Nous pensons que le futur développement de logiciels entrera définitivement dans l'ère des agents, ce qui signifie qu'il disposera d'une certaine autonomie et qu'il pourra utiliser nos outils très facilement, puis comprendre les intentions humaines, terminer le travail et éventuellement former un logiciel polyvalent, comme le montre l'exemple ci-dessous. la figure. Modèle collaboratif des agents.

Rien qu'en mars de cette année, la naissance de Devin nous a fait sentir que cette affaire s'était vraiment accélérée. Nous n'avions jamais imaginé que cette affaire puisse mener à bien un véritable projet d'entreprise. Nous ne l'avions jamais imaginé dans le passé, et nous avions même le sentiment que cette affaire. C'est peut-être encore dans un an, mais son émergence nous fait sentir qu'aujourd'hui, nous pouvons vraiment démonter des centaines ou des milliers d'étapes à travers de grands modèles et les exécuter étape par étape, si des problèmes surviennent, nous pouvons également réfléchir et itérer sur nous-mêmes. Une forte capacité de démontage et une capacité de raisonnement nous ont beaucoup surpris.
Avec la naissance de Devin, divers experts et universitaires ont commencé à investir, notamment notre laboratoire Tongyi, qui a immédiatement lancé un projet appelé OpenDevin. Ce projet a dépassé les 20 000 étoiles en quelques semaines seulement. On voit que tout le monde est très enthousiasmé par ce domaine. Ensuite, nous avons immédiatement ouvert le projet Agent de SWE, poussant le taux de solution du banc SWE à plus de 10 %. Dans le passé, les grands modèles étaient tous de l'ordre de quelques pour cent, et le pousser à 10 % est déjà proche des performances de Devin, donc nous avons jugé que la recherche universitaire dans ce domaine pouvait être très rapide,
Faisons une hypothèse audacieuse. Il est très probable que de juin à septembre vers la mi-2024, le taux de solution du banc SWE dépassera 30 %. Faisons une supposition audacieuse : s'il peut atteindre un taux de résolution de 50 à 60 %, son ensemble de tests est en fait de véritables problèmes sur Github, laissons l'IA résoudre les problèmes sur Github, corriger les bogues et résoudre ces besoins. Si cet ensemble de tests peut amener le taux d’achèvement autonome de l’IA à 50 ou 60 %, nous pensons qu’il peut réellement être mis en œuvre au niveau de la production. Au moins quelques défauts simples peuvent être corrigés grâce à lui, ce qui constitue l'un des derniers développements que nous avons observés dans l'industrie.
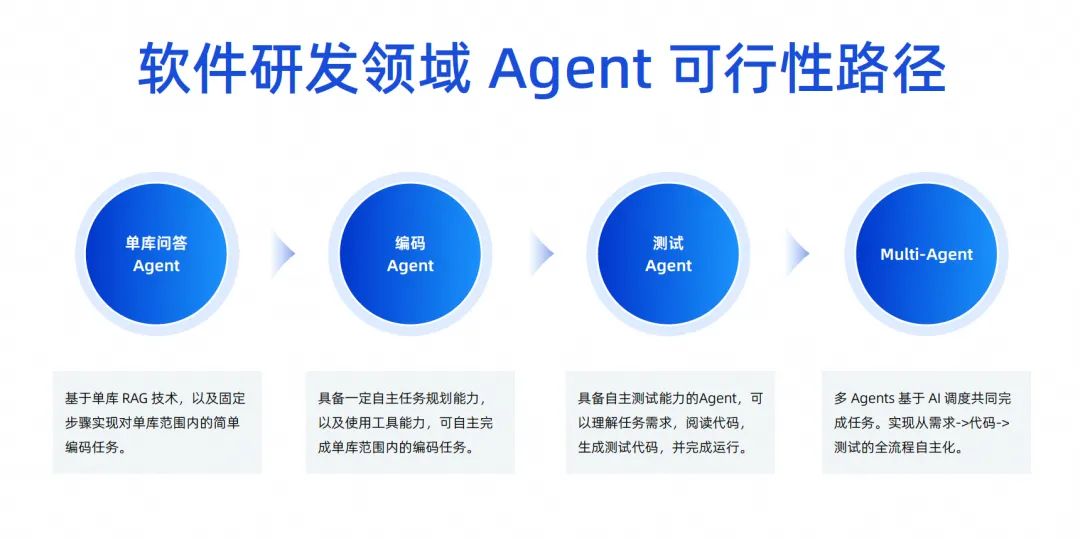
Cependant, cette image ne peut pas être réalisée immédiatement. D’un point de vue technique, nous la mettrons en œuvre progressivement en quatre étapes.
Dans un premier temps, nous travaillons toujours sur un agent Q&A à base de données unique. Ce domaine est très avant-gardiste. Nous travaillons actuellement sur un agent Q&A à base de données unique, qui sera en ligne dans un avenir proche.
Dans la prochaine étape, nous espérons lancer un agent capable d'effectuer des tâches de codage de manière indépendante. Son rôle principal est de disposer d'un certain degré de capacités de planification indépendantes. Il peut utiliser certains outils pour comprendre les connaissances de base et effectuer de manière indépendante des tâches de codage au sein d'un seul. bibliothèque, pas entre bibliothèques. , vous pouvez imaginer qu'une exigence a plusieurs bases de code, puis le front-end est également modifié, et le back-end est également modifié, et finalement une exigence est formée. Nous pensons qu'elle est encore loin. .
Nous implémentons donc d'abord l'agent de codage d'une seule bibliothèque, puis nous ferons l'agent de test. L'agent de test peut effectuer automatiquement certaines tâches de test en fonction des résultats générés par l'agent de codage, notamment la compréhension des exigences de la tâche et la lecture du fichier. code, générant des cas de test et exécuté de manière autonome.
Si le taux de réussite de ces deux étapes est relativement élevé, on passera à la troisième étape. Laissez plusieurs agents travailler ensemble pour effectuer des tâches basées sur la planification de l'IA, réalisant ainsi l'autonomie de l'ensemble du processus, des exigences au code en passant par les tests.
D'un point de vue technique, nous procéderons étape par étape pour garantir que chaque étape atteint une meilleure mise en œuvre au niveau de la production et finalement produise des produits. Mais d’un point de vue académique, leur vitesse de recherche sera plus rapide que la nôtre. Nous discutons maintenant du point de vue académique et technique, et nous avons une troisième branche qui est l’évolution des modèles. Ces trois voies font partie des recherches que nous menons actuellement en collaboration avec Alibaba Cloud et Tongyi Lab.
À terme, nous formerons une architecture conceptuelle multi-agents. Les utilisateurs pourront parler au grand modèle, et le grand modèle pourra décomposer les tâches, puis il y aura un système de collaboration multi-agents. Cet agent peut connecter certains outils et disposer de son propre environnement d'exécution. Ensuite, plusieurs agents peuvent collaborer entre eux et partageront également certains mécanismes contextuels.
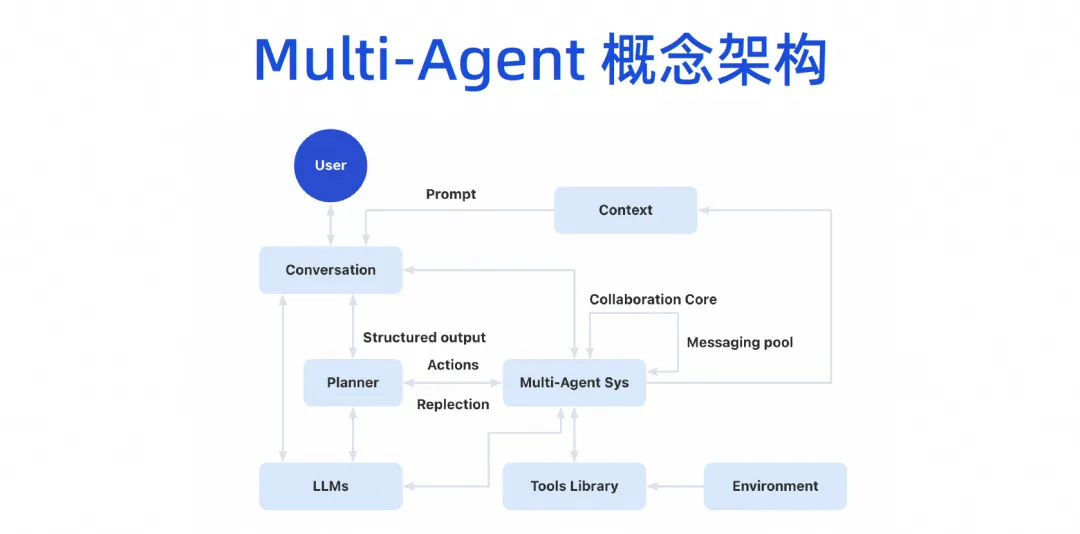
Cette image du produit sera divisée en trois couches. Le bas est la couche de base. Pour les entreprises, la couche de base peut être complétée en premier. Par exemple, un grand modèle de code peut désormais être introduit. Bien que nous n'ayons pas implémenté AI Bot immédiatement, nous disposons désormais des capacités du plug-in de génération de code IDE et pouvons déjà effectuer certains travaux, qui sont le modèle Copilot.
Le mode Copilot fait évoluer la couche Agent au-dessus de la couche infrastructure. En fait, l'infrastructure peut être réutilisée. L'amélioration de la récupération, le réglage fin de la formation et la base de connaissances qui devraient être effectués peuvent être effectués dès maintenant. Le tri de ces connaissances et l’accumulation d’actifs proviennent de l’accumulation de la plateforme DevOps d’origine. Vous pouvez désormais combiner la couche de fonctionnalités de base actuelle avec l'ensemble de la chaîne d'outils DevOps via certains projets de mots d'invite.
Nous avons fait quelques expériences.Au stade des exigences, si nous voulons que ce grand modèle réalise le désassemblage automatique d'une exigence, il suffit de combiner certaines données de désassemblage passées et les exigences actuelles dans une invite pour le grand modèle. et le personnel mieux affecté. Au cours de l’expérience, il a été constaté que la précision des résultats est assez élevée.
En fait, l’ensemble de la chaîne d’outils DevOps ne nécessite pas d’agent ou de copilote pour tout. Nous utilisons maintenant certains projets de mots d'invite, et de nombreux scénarios peuvent être activés immédiatement, notamment le débogage automatique dans notre processus CICD, les questions et réponses intelligentes dans le domaine de la base de connaissances, etc.
Après avoir implémenté plusieurs agents, l'agent peut être exposé dans l'EDI, le portail du développeur, la plateforme DevOps ou même notre outil de messagerie instantanée. Il s'agit en réalité d'une intelligence anthropomorphe. L'agent lui-même aura son propre espace de travail. Dans cet espace de travail, nos développeurs ou gestionnaires pourront surveiller comment il nous aide à terminer l'écriture du code, comment il nous aide à réaliser les tests et comment il est utilisé sur Internet. Quel type de connaissances est acquis. terminer le travail, il aura son propre espace de travail et réalisera finalement le processus complet de l'ensemble de la tâche.
Cliquez ici pour découvrir Tongyi Lingma.
L'équipe de la Google Python Foundation a été licenciée. Google a confirmé les licenciements et les équipes impliquées dans Flutter, Dart et Python se sont précipitées vers la hot list de GitHub - Comment les langages et frameworks de programmation open source peuvent-ils être si mignons ? Xshell 8 ouvre le test bêta : prend en charge le protocole RDP et peut se connecter à distance à Windows 10/11 Lorsque les passagers se connectent au WiFi ferroviaire à grande vitesse , la « malédiction vieille de 35 ans » des codeurs chinois apparaît lorsqu'ils se connectent au haut débit. rail WiFi. Le premier outil de recherche IA à support à long terme de MySQL version 8.4 Perplexica : Entièrement open source et gratuit, une alternative open source à Perplexity. Les dirigeants de Huawei évaluent la valeur de l'open source Hongmeng : il possède toujours son propre système d'exploitation malgré une suppression continue. par des pays étrangers. La société allemande de logiciels automobiles Elektrobit a ouvert une solution de système d'exploitation automobile basée sur Ubuntu.