
Partageur : Zeng Qingguo |École : Université des sciences et technologies du Sud
courte introduction
Le ralentissement de la loi de Moore a favorisé le développement de paradigmes informatiques non traditionnels, tels que les machines d'Ising personnalisées spécialement conçues pour résoudre des problèmes d'optimisation combinatoire. Cette session présentera de nouvelles applications de machines Ising basées sur P-bit pour la formation de réseaux neuronaux génératifs profonds, en utilisant des machines Ising clairsemées, asynchrones et hautement parallèles pour former des réseaux Boltzmann profonds dans un environnement informatique mixte probabiliste-classique.
Documents connexes
标题:Formation de réseaux Boltzmann profonds avec des machines à ising clairsemées
作宇 :**Shaila Niazi, Navid Anjum Aadit, Masoud Mohseni, Shuvro Chowdhury, Yao Qin, Kerem Y. Camsari
01
Objet de l'article
Objectif : Démontrer comment former efficacement des versions clairsemées de réseaux Boltzmann profonds à l'aide de systèmes matériels spécialisés (par exemple, P-bit) qui fournissent des ordres de grandeur d'accélération par rapport aux implémentations logicielles couramment utilisées dans les tâches informatiques d'échantillonnage probabiliste difficile ;
Objectif à long terme : contribuer à faciliter le développement de matériel probabiliste inspiré de la physique afin de réduire le coût en croissance rapide de l'apprentissage profond traditionnel basé sur des unités graphiques et de traitement tensoriel (GPU/TPU) ;
Difficultés de mise en œuvre matérielle :
1. Les p-bits connectés doivent être mis à jour en série et les mises à jour sont interdites dans les systèmes denses.
2. Assurez-vous que le p-bit reçoit toutes les dernières informations de ses nœuds voisins avant la mise à jour, sinon le réseau ne le fera pas. Échantillonnage à partir d'une véritable distribution Boltzmann.
02
contenu principal
Le contenu de la formation des réseaux Boltzmann profonds à l'aide de machines d'Ising clairsemées est principalement divisé en quatre parties :
1. Structure du réseau
2. Fonction objectif
3. Optimisation des paramètres
4. Inférence (classification et génération d'images)
1. Structure du réseau
Les topologies Pegasus et Zepyhr développées par D-Wave sont utilisées pour former des réseaux profonds clairsemés sensibles au matériel. Cette opération s’inspire de réseaux étendus mais limités en connexion, tels que le cerveau humain et les microprocesseurs avancés. Malgré l’utilisation omniprésente d’une connectivité complète dans les modèles d’apprentissage automatique, les microprocesseurs avancés et les cerveaux humains dotés de milliards de réseaux de transistors présentent un degré élevé de parcimonie. En fait, la plupart des implémentations matérielles de RBM sont confrontées à des problèmes de mise à l'échelle en raison de la responsabilité informatique élevée requise par chaque nœud, tandis que les connexions clairsemées dans les réseaux neuronaux matériels présentent souvent des avantages. De plus, la structure du réseau clairsemée résout bien les difficultés de mise en œuvre matérielle mentionnées ci-dessus.
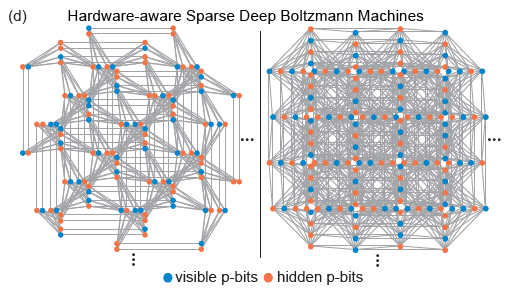
(Source de l'image : arXiv : 2303.10728)
2. Fonction objectif
Maximiser la fonction de vraisemblance équivaut à minimiser la divergence KL entre la distribution des données et la distribution du modèle :
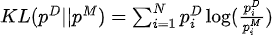
Parmi eux, 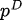 se trouve la distribution des données et
se trouve la distribution des données et 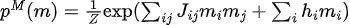 la distribution du modèle.
la distribution du modèle.
Le gradient de divergence KL par rapport aux paramètres du modèle ( 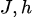 ) est :
) est :
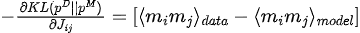
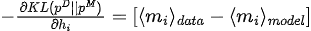
3. Optimisation des paramètres

(Source de l'image : arXiv : 2303.10728)
Entraîner les paramètres du réseau selon l'algorithme 1, y compris
-
Initialisation des paramètres d'initialisation (
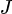 , );
, );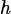
-
Utilisez les données de formation pour attribuer des valeurs aux p-bits de la couche d'entrée, puis effectuez un échantillonnage MC pour obtenir des échantillons d'échantillonnage de la distribution des données ;
-
Effectuer directement un échantillonnage MC pour obtenir des échantillons d'échantillonnage de la distribution du modèle ;
-
Le gradient (appelé divergence contrastive persistante) est estimé à l'aide d'échantillons échantillonnés en deux étapes, et les paramètres sont mis à jour à l'aide de la méthode de descente de gradient.
Parmi eux, l'échantillonnage MC utilise l'évolution itérative de p-bits :

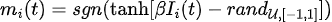
Dans le processus de formation des réseaux Boltzmann clairsemés, il y a deux points à noter :
-
1) Indice p-bits randomisé
Lors de la formation d'un modèle de réseau Boltzmann sur un réseau clairsemé donné, la distance graphique entre les nœuds visibles, cachés et étiquettes est un concept très important. Normalement, si la couche est entièrement connectée, la distance graphique entre deux nœuds donnés est constante, mais ce n'est pas le cas pour les graphiques clairsemés, donc les positions des p-bits visibles, cachés et d'étiquette semblent extrêmement importantes. Si les bits p visibles, cachés et étiquetés sont regroupés et trop proches, la précision de la classification sera grandement affectée. Cela est probablement dû au fait que si la distance graphique entre les bits d'étiquette et les bits visibles est trop grande, la corrélation entre eux devient plus faible. La randomisation de l'index p-bits peut atténuer ce problème. -
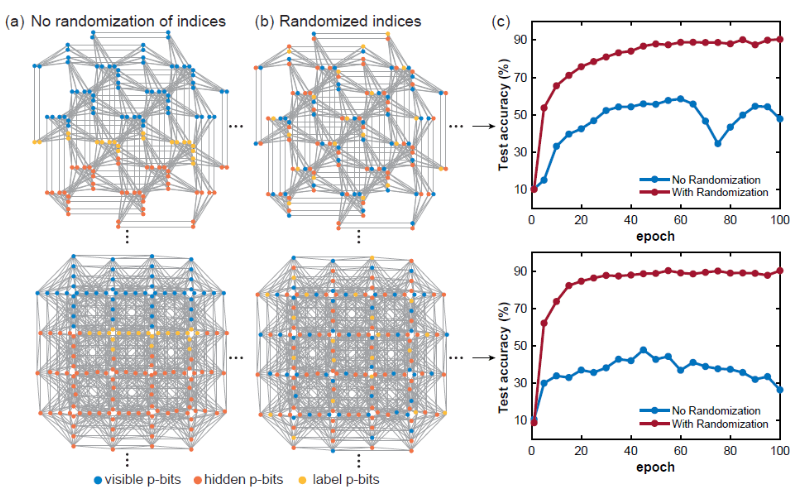
-
(Source de l'image : arXiv : 2303.10728)
**2)大规模并行**
在稀疏深度玻尔兹曼网络上,我们使用启发式图着色算法DSatur对图着色,对于未连接p-bits进行并行更新。
-
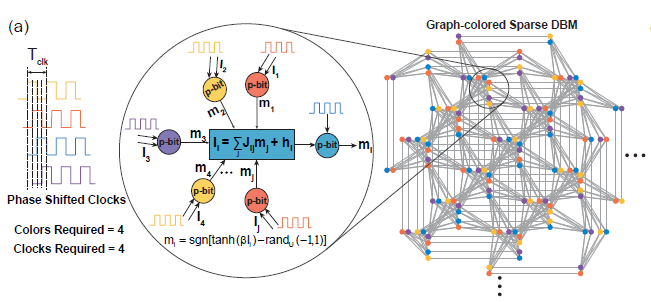
-
(Source de l'image : arXiv : 2303.10728)
4. Inférence
Classification : utilisez les données de test pour corriger les p-bits visibles, puis effectuez un échantillonnage MC, puis obtenez les attentes pour les pbits d'étiquette obtenus et prenez l'étiquette avec la plus grande valeur attendue comme étiquette prédite.
-
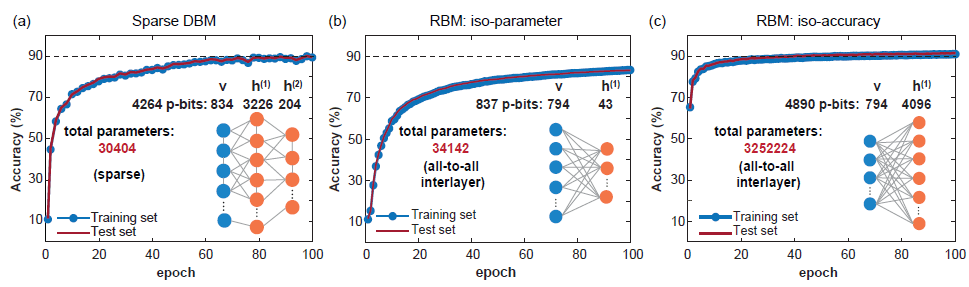
-
(Source de l'image : arXiv : 2303.10728)
Génération d'image : fixez les p-bits de l'étiquette au codage correspondant à l'étiquette que vous souhaitez générer, puis effectuez un échantillonnage MC et recuit le réseau pendant le processus d'échantillonnage (en augmentant progressivement de 0 à 5 par pas de 0,125), et le résultat obtenu les échantillons correspondent aux p-bits visibles sont les images générées.
-

-
(Source de l'image : arXiv : 2303.10728)
03
Résumer
L'article utilise une machine Ising clairsemée avec une architecture massivement parallèle, qui atteint des vitesses d'échantillonnage de plusieurs ordres de grandeur plus rapides que les processeurs traditionnels. L'article étudie systématiquement le temps de mélange des topologies de réseau sensibles au matériel et montre que la précision de classification du modèle n'est pas limitée par l'opérabilité informatique de l'algorithme, mais par le FPGA de taille modérée qui a pu être utilisé dans ce travail. D'autres améliorations pourraient impliquer l'utilisation d'architectures de réseau plus profondes, plus larges et éventuellement « plus difficiles à mélanger », qui tirent pleinement parti des échantillonneurs probabilistes ultrarapides. De plus, la combinaison de la technologie de formation couche par couche du DBM traditionnel avec la méthode de l'article peut apporter d'autres améliorations possibles. La mise en œuvre de machines d'Ising clairsemées utilisant des dispositifs à l'échelle nanométrique, tels que des jonctions tunnel magnétiques aléatoires, pourrait changer l'état actuel des applications pratiques des réseaux Boltzmann profonds.
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Google a confirmé les licenciements, impliquant la « malédiction des 35 ans » des codeurs chinois des équipes Flutter, Dart et . Python Arc Browser pour Windows 1.0 en 3 mois officiellement la part de marché de GA Windows 10 atteint 70 %, Windows 11 GitHub continue de décliner l'outil de développement natif d'IA GitHub Copilot Workspace JAVA. est la seule requête de type fort capable de gérer OLTP+OLAP. C'est le meilleur ORM. Nous nous rencontrons trop tard.