
Auteur : Lu Yufeng Source : Zhihu
Résumé
Le développement de MindNLP a duré environ un an. Dans l'ensemble, il est confronté à de nombreux problèmes, et il s'accompagne également d'une série d'impacts et de défis apportés par LLM. En tant que framework NLP récent qui s'appuie sur MindSpore pour sa croissance ascendante, il doit en fait réfléchir à la manière d'étendre son écologie.
Comme le dit le proverbe : si vous ne pouvez pas le battre, rejoignez-le. Mais pour le monde open source, il n'est pas nécessaire de parler d'adhésion. Il est normal que vous m'ayez et que vous fassiez partie de moi. De plus, au moment où Pytorch2.1+Ascend a été officiellement annoncé il y a deux jours, le greffage écologique est sans doute la meilleure solution. Assez de ragots et venons au fait.
01
Ensembles de données MindNLP
Dès le début de la conception de MindNLP, nous espérons exploiter pleinement tous les avantages et fonctionnalités de MindSpore, y compris la programmation de fusion fonctionnelle, les fonctions de graphes dynamiques, les moteurs de traitement de données, etc. Ici, le moteur de traitement des données est extrait séparément et discuté en détail.
1.1Moteur de traitement de données MindSpore
Figure 1 : Diagramme schématique du pipeline du moteur de données MindSpore
Comme le montre la figure, la conception du moteur de données est un pipeline [1], qui est très similaire aux ensembles de données de Tensorflow et de style Map de Pytorch, et est principalement destiné au traitement de données haute performance.
À une époque où tout le monde apporte encore de petites modifications aux modèles et de petits ensembles de données pour actualiser les classements, le prétraitement des données est généralement effectué hors ligne, afin que Python puisse être utilisé pour les traiter de la manière la plus flexible possible, et généralement la grande mémoire du serveur peut s'y adapte. Tout le monde intégrera toutes les données en même temps, puis ouvrira plusieurs processus pour les traiter. Après cela, chargez-le dans Tensor et envoyez-le au réseau pour formation. Mais même ainsi, si l’ensemble de données est légèrement plus volumineux, le prétraitement de l’ensemble de données peut prendre des heures, voire des jours.
La méthode Pipeline se concentre sur plusieurs fonctionnalités :
1. Chargement à la demande
2. Traitement asynchrone
3. Parallèle
Parmi eux, 1 et 2 peuvent être discutés en détail. En prenant les données texte comme exemple, si la logique de prétraitement de chargement Python la plus simple (c'est-à-dire Pytorch Dataloader) est utilisée, le flux d'exécution global est le suivant :
数据集全量加载至内存 -> 全量遍历并预处理 -> 单条数据打包Batch -> 循环返回每个Batch
La méthode de chargement de Pipeline est
Une description plus frappante est la suivante : il y a maintenant un pointeur pointant vers le début du fichier d'ensemble de données à chaque fois, et le pointeur avance de la taille du lot jusqu'à ce qu'il soit récupéré.
Évidemment, récupérer uniquement une quantité appropriée de données à chaque fois peut réduire considérablement la consommation de mémoire, et les variables intermédiaires générées pendant le processus de prétraitement peuvent également être compressées à une petite taille. De plus, cette méthode peut convertir le prétraitement des données hors ligne en ligne :
取Batch size条数据加载 -> Batch size条数据遍历并预处理 -> 返回一个Batch
Figure 2 : Pipeline de traitement des données et d’informatique en réseau
Le pipeline de traitement des données traite en continu les données et envoie les données traitées au cache côté Appareil ; après l'exécution d'une Étape, les données de l'Étape suivante sont lues directement depuis le cache de l'Appareil. Pendant que le réseau s'entraîne, les données sont également traitées, chacune accomplissant ses propres tâches.
Bien entendu, cette méthode est également une arme à double tranchant. Tout en améliorant l’utilisation de la mémoire et les performances, elle introduit également des problèmes de facilité d’utilisation. La carte de la figure 1 est un traitement asynchrone.Après avoir configuré chaque opération de prétraitement des données, elle ne s'exécutera pas directement et ne renverra pas les résultats. Cela n'est pas convivial pour les données qui nécessitent un contrôle précis et comportent de nombreuses conditions spéciales, et l'exécution du pipeline est très susceptible de se produire. . Une anomalie se déclenche soudainement.
Cependant, LLM a changé cette situation. Toutes les tâches sont devenues Next Token Prediction, et tout le traitement des données est également devenu nettoyage + Tokenize. La quantité de données est énorme et le streaming de données dans des scénarios commerciaux devient naturellement une solution optimale (c'est le cas). probablement la principale raison pour laquelle Pytorch a commencé à créer des pipelines et les ensembles de données HuggingFace sont également des pipelines).
1.2Problèmes de prise en charge des ensembles de données MindNLP
Comme mentionné précédemment, le traitement des données de MindNLP utilise entièrement le moteur de traitement de données MindSpore et a pris en charge plus de 20 ensembles de données en un an (évalués par torchtext). Cependant, dans la pratique, il est évident que diverses tâches de PNL nécessitent plus que ces ensembles de données et qu'il est difficile de s'adapter en permanence à un domaine ouvert.
De plus, l'ensemble de données de Shengsi MindSpore a également causé quelques problèmes. Le principal problème est que MindSpore Dataset a conçu trois types de chargeurs, à savoir :
1. Chargeur d'ensembles de données spécifique : tel que IMDBDataset, EnWik9Dataset, etc.
2. Chargeur de résumé de texte : TextFileDataset
3. Chargeur défini par l'utilisateur : GeneratorDataset
Si vous utilisez 1, cela signifie que vous devez ajouter continuellement des adaptations ; si vous utilisez 2, vous devez prétraiter les formats tels que XML, JSON, etc. avant le chargement. Cela va à l'encontre du concept de conception à haute efficacité de Pipeline, et vous. toujours confronté à la nécessité d'une adaptation manuelle. La quantité de développement utilisée signifie que la première étape de la figure 1 revient à pleine charge, ce qui n'est évidemment pas ce que nous voulons. Cependant, en raison de la nécessité de prendre en charge rapidement l'ensemble de données, nous avons toujours choisi la méthode de prise en charge 1+3.
Ceci n’est pas efficace et nécessite à chaque fois une adaptation distincte. Alors, existe-t-il une solution permanente ?
02
Greffe écologique HuggingFace
Le chargement des ensembles de données de MindNLP ne vise rien de plus que deux choses :
1. Prendre en charge de grands ensembles de données sans adaptation
2. Utilisez un pipeline efficace
Puisque vous ne pouvez pas le faire vous-même, comptons sur le pouvoir de l’écologie. En plus de l'entrepôt Transformers, HuggingFace a développé des bibliothèques pour divers processus de formation d'IA accumulés depuis plusieurs années et prend en charge un grand nombre d'ensembles de données. Et comme HuggingFace fournit des services d'hébergement, de nombreux nouveaux ensembles de données sont également directement présents dans l'entrepôt. Hub des ensembles de données. Publiez directement sur. En utilisant des ensembles de données pour résoudre le problème 1, examinons le deuxième problème.
En fait, la plupart des personnes qui utilisent MindSpore Dataset choisissent essentiellement deux méthodes de traitement :
1. Prétraitement hors ligne vers MindRecord, puis chargement à l'aide de MindDataset
2. Chargez l'ensemble de données en mémoire, puis chargez-le à l'aide d'un chargeur d'ensemble de données/GeneratorDataset spécifique.
Afin de pouvoir effectuer un prétraitement en ligne, la méthode 1 n'est évidemment pas recommandée, donc l'idée de greffer des ensembles de données HuggingFace est également très simple. J'ai envisagé deux idées et j'en discuterai ci-dessous.
2.1 Téléchargement de l'ensemble de données de greffage
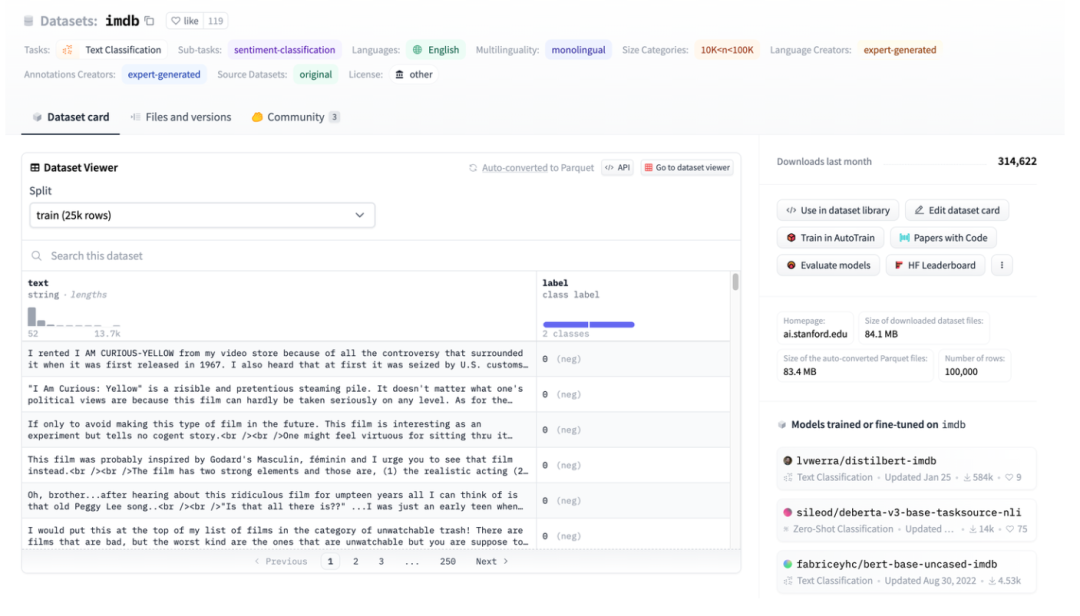 Figure 3 : Illustration de l'ensemble de données HuggingFace, en prenant IMDB comme exemple
Figure 3 : Illustration de l'ensemble de données HuggingFace, en prenant IMDB comme exemple
La figure 3 est une capture d'écran de la page imdb. Vous pouvez voir que les données ont été bien structurées. Utilisez ensuite HuggingFace Datasets pour télécharger directement, puis utilisez directement le chargeur de données abstraites TextFileDataset pour lire directement les fichiers traités pour les utiliser.
Figure 4 : interface TextFileDataset
Vous pouvez voir que TextFileDataset n'a besoin que de transmettre le chemin du fichier ou la liste des chemins à charger. Cependant, j'ai rencontré un problème lors du fonctionnement pratique : les ensembles de données HuggingFace utilisent des fichiers Apache Arrow.
Figure 5 : Introduction au format Flèche des ensembles de données HuggingFace
Apache Arrow[2] est un standard de format d'échange de données hautes performances, indépendant du langage et multi-système, qui peut être copié à zéro. Cela signifie que l'ensemble de données de MindSpore ne peut pas être lu directement et simplement. Bien qu'il puisse également être exploité à l'aide de la bibliothèque pyarrow, cela augmente la complexité et revient à un état qui nécessite un prétraitement avant le chargement. Cependant, il s'avère que les caractéristiques des fichiers Arrow sont plus adaptées à l'ensemble de données de MindSpore.
2. 2 Avantages du format Flèche
Dans l'environnement Multiwalker, les robots bipèdes tentent de transporter leur charge et de marcher vers la droite. Plusieurs robots transportent une grosse cargaison et doivent travailler ensemble, comme le montre l'image ci-dessous.
HuggingFace utilise le format Apache Arrow, qui présente plusieurs avantages évidents :
1. Le format standard d'Arrow permet des lectures sans copie, ce qui élimine pratiquement toute surcharge de sérialisation.
2. Arrow est orienté colonnes, ce qui permet d'interroger et de traiter plus rapidement les tranches de données ou les colonnes de données.
3. Arrow traite chaque ensemble de données comme un fichier mappé en mémoire. Lors de l'accès à des données partielles dans un fichier volumineux, il n'est pas nécessaire de charger l'intégralité du fichier et plusieurs processus peuvent partager la mémoire. Le mappage de la mémoire permet d'utiliser de grands ensembles de données sur des machines dotées d'une mémoire de périphérique relativement petite ; le chargement de l'ensemble de données complet de Wikipédia en anglais ne nécessite que quelques Mo de RAM.
4. Lors du chargement des données, vous pouvez définir les paramètres de streaming pour le chargement en streaming.
À ce stade, revenons en arrière et examinons la conception du moteur de données MindSpore : le chargement à la demande, le traitement en ligne et les ensembles de données HuggingFace correspondent parfaitement.
2.3Adaptation MindNLP
Étant donné que le fichier de flèche chargé par HuggingFace Datasets lui-même est un fichier mappé en mémoire, il n'est pas nécessaire de le copier dans la mémoire, et l'utilisation de l'index d'index ne le chargera pas complètement, il peut donc être directement utilisé comme source de chargement des données et envoyé directement au GeneratorDataset pour utilisation.
Figure 6 : Interface GeneratorDataset
La construction de GeneratorDataset nécessite principalement des données source et le nom de colonne correspondant à chaque colonne de données. En regardant la figure 3, vous pouvez voir que HuggingFace Datasets a nommé toutes les colonnes. Voici le code principal intercepté :
from mindspore.dataset import GeneratorDataset
from datasets import load_dataset as hf_load
......
def load_dataset(...):
ds_ret = hf_load(path,
name=name,
data_dir=data_dir,
data_files=data_files,
split=split,
cache_dir=cache_dir,
features=features,
download_config=download_config,
download_mode=download_mode,
verification_mode=verification_mode,
keep_in_memory=keep_in_memory,
save_infos=save_infos,
revision=revision,
streaming=streaming,
num_proc=num_proc,
storage_options=storage_options,
)
if isinstance(ds_ret, (list, tuple)):
ds_dict = dict(zip(split, ds_ret))
else:
ds_dict = ds_ret
datasets_dict = {}
for key, raw_ds in ds_dict.items():
column_names = list(raw_ds.features.keys())
source = TransferDataset(raw_ds, column_names) if isinstance(raw_ds, Dataset) \
else TransferIterableDataset(raw_ds, column_names)
ms_ds = GeneratorDataset(
source=source,
column_names=column_names,
shuffle=shuffle,
num_parallel_workers=num_proc if num_proc else 1)
datasets_dict[key] = ms_ds
if len(datasets_dict) == 1:
return datasets_dict.popitem()[1]
return datasets_dict
Les étapes de traitement sont également très simples :
1. Charger à l'aide de load_dataset des ensembles de données HuggingFace
2. Utiliser des classes de transit encapsulées pour l'encapsulation
3. Transmettez GeneratorDataset
Par souci de facilité d'utilisation, nous conservons les paramètres de l'interface load_dataset exactement les mêmes que ceux des ensembles de données HuggingFace, mais ce qui est renvoyé est une classe ou un Dict qui peut être traité par le moteur de données MindSpore, de sorte que la connexion transparente du Les capacités de traitement des données de Shengsi MindSpore peuvent être complétées.
Parlons brièvement de la structure de la classe transit.
Les types de données des ensembles de données HuggingFace incluent Dataset et IterableDataset :
Il existe deux types d'objets d'ensemble de données, un Dataset et un IterableDataset. Le type d'ensemble de données que vous choisissez d'utiliser ou de créer dépend de la taille de l'ensemble de données. En général, anIterableDataset est idéal pour les grands ensembles de données (pensez à des centaines de Go !) en raison de son comportement paresseux et de ses avantages en termes de vitesse, tandis que Dataset est idéal pour tout le reste. Cette page comparera les différences entre Dataset et anIterableDatase pour vous aider à choisir l'objet d'ensemble de données qui vous convient.[3]
Lors du parcours de ces deux types d'ensembles de données, un dict est renvoyé, ce qui n'est pas pris en charge par le moteur de traitement de données de MindSpore. Par conséquent, deux classes de transfert sont créées pour lire les données dans le dict sans ajouter d'autres opérations supplémentaires. Pour Dataset, construisez une classe TransferDataset et lisez-la dans la méthode __getitem__.
class TransferDataset():
"""TransferDataset for Huggingface Dataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __getitem__(self, index):
return tuple(self.ds[int(index)][name] for name in self.column_names)
def __len__(self):
return self.ds.dataset_size
Pour diffuser des données IterableDataset, vous devez les lire dans la méthode __iter__ et construire TransferIterableDataset en tant qu'objet itérable.
class TransferIterableDataset():
"""TransferIterableDataset for Huggingface IterableDataset."""
def __init__(self, arrow_ds, column_names):
self.ds = arrow_ds
self.column_names = column_names
def __iter__(self):
for data in self.ds:
yield tuple(data[name] for name in self.column_names)
À ce stade, un plan qui nécessite peu d’efforts et peut greffer complètement les ensembles de données HuggingFace a été achevé. Par rapport à Paddle NLP, la stratégie de greffage est simple et élégante.
03
en conclusion
En tant que framework open source, il existe en fait un grand nombre de ressources open source qui peuvent être utilisées. La soi-disant expansion continue de l'écosystème nord-sud ne signifie pas nécessairement une adaptation. Je l'utilise, vous l'utilisez, vous m'utilisez. , et vous êtes heureux et sans souci. Cette fois, les ensembles de données HuggingFace sont greffés au partage pratique de Shengsi MindSpore, ce qui fournira une compréhension plus approfondie de Shengsi MindNLP et contribuera également à étendre l'écosystème Shengsi MindSpore.
les références
[1] https://www.mindspore.cn/docs/zh-CN/r2.1/design/data_engine.htm
[3] https://huggingface.co/docs/datasets/about_mapstyle_vs_iterable
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Google a confirmé les licenciements, impliquant la « malédiction des 35 ans » des codeurs chinois des équipes Flutter, Dart et . Python Arc Browser pour Windows 1.0 en 3 mois officiellement la part de marché de GA Windows 10 atteint 70 %, Windows 11 GitHub continue de décliner l'outil de développement natif d'IA GitHub Copilot Workspace JAVA. est la seule requête de type fort capable de gérer OLTP+OLAP. C'est le meilleur ORM. Nous nous rencontrons trop tard.