
Auteur : Ye Jidong de l'équipe Big Data Internet de Vivo
Cet article présente principalement l'ensemble du processus d'analyse et de résolution du problème de débordement de mémoire provoqué par une fuite de mémoire en ligne provoquée par la classe FileSystem.
Définition de fuite de mémoire : Un objet ou une variable qui n'est plus utilisé par le programme occupe toujours de l'espace de stockage dans la mémoire et la JVM ne peut pas récupérer correctement l'objet ou la variable modifié. Une seule fuite de mémoire peut ne pas sembler avoir un grand impact, mais la conséquence de l'accumulation de fuites de mémoire est un débordement de mémoire.
Débordement de mémoire (mémoire insuffisante) : fait référence à une erreur dans laquelle le programme ne peut pas continuer à s'exécuter en raison d'un espace mémoire alloué insuffisant ou d'une utilisation inappropriée lors de l'exécution du programme. À ce moment, une erreur MOO sera signalée, ce qui est le cas. ce qu'on appelle un débordement de mémoire.
1. Origines
Xiaoye a tué des gens dans le Canyon des Rois ce week-end, et son téléphone a soudainement reçu un grand nombre d'alarmes du processeur de la machine. Si l'utilisation du processeur dépasse 80 %, il déclenchera une alarme en même temps. pour le service. Ce service est un service très important pour l'équipe du projet Xiaoye. Xiaoye a rapidement déposé Honor of Kings et a allumé l'ordinateur pour vérifier le problème.


Figure 1.1 Alarme CPU Alarme GC complet
2. Découverte du problème
2.1 Surveillance et visualisation
Étant donné que le processeur de service et le GC complet sont en alarme, ouvrez la surveillance du service pour afficher la surveillance du processeur et la surveillance du GC complet. Vous pouvez voir que les deux moniteurs ont un renflement anormal au même moment. Vous pouvez le voir lorsque l'alarme du processeur est déclenchée. Le GC complet est particulièrement fréquent, on suppose que l'alarme d'augmentation de l'utilisation du processeur peut être provoquée par le GC complet .
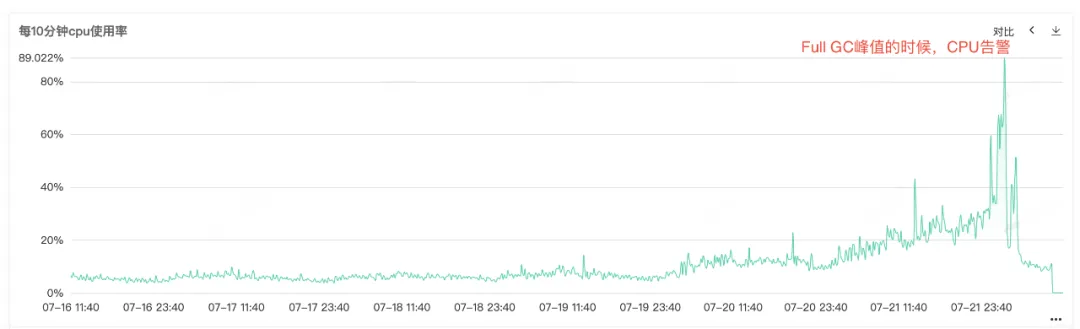
Figure 2.1 Utilisation du processeur
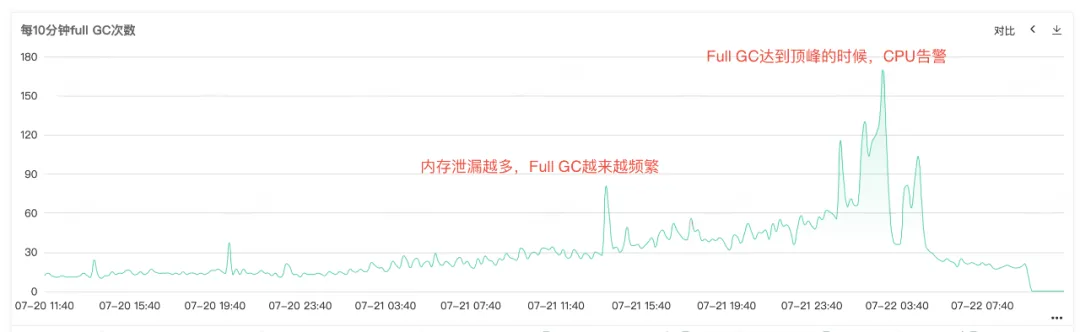
Figure 2.2 Temps de GC complet
2.2 Fuite de mémoire
D'après les Full Gc fréquents, nous pouvons savoir qu'il doit y avoir des problèmes avec le recyclage de la mémoire du service. Par conséquent, vérifiez la surveillance de la mémoire tas, de la mémoire ancienne génération et de la mémoire jeune génération du service. l'ancienne génération, nous pouvons voir que la mémoire résidente de l'ancienne génération devient de plus en plus grande. De plus en plus d'objets de l'ancienne génération ne peuvent pas être recyclés, et finalement toute la mémoire résidente est occupée, et une fuite de mémoire évidente peut être constatée. .
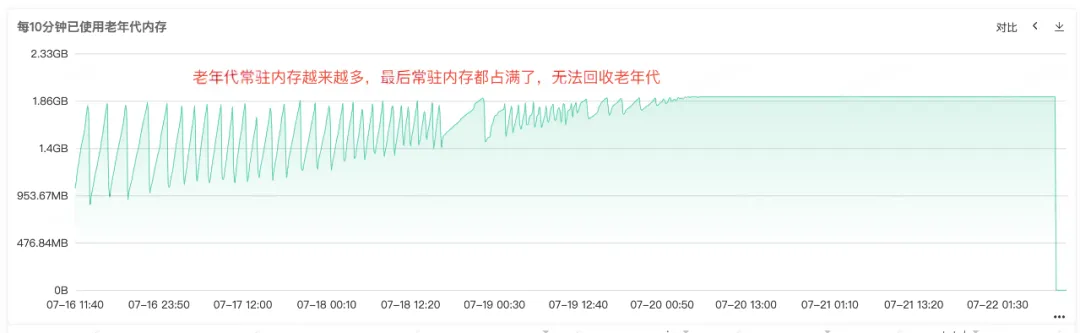
Figure 2.3 Mémoire ancienne génération
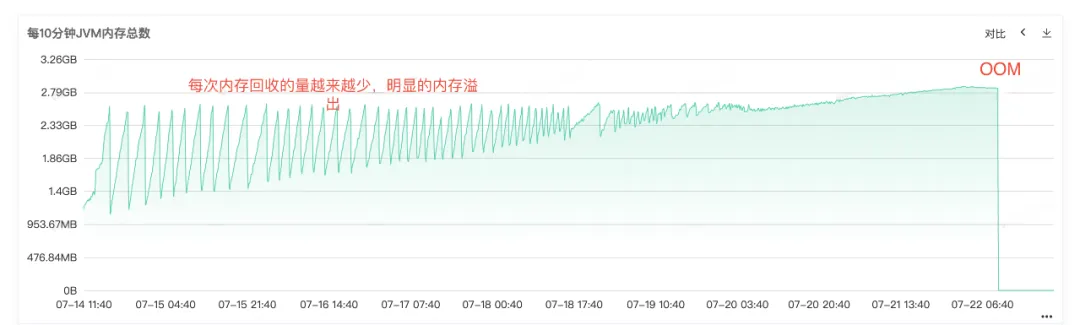
Figure 2.4 Mémoire JVM
2.3 Débordement de mémoire
À partir du journal des erreurs en ligne, nous pouvons également savoir clairement que le service s'est terminé en MOO, donc la cause première du problème est que la fuite de mémoire a provoqué un débordement de mémoire en MOO, et finalement le service est devenu indisponible .

Figure 2.5 Journal du MOO
3. Dépannage des problèmes
3.1 Analyse de la mémoire tas
Après qu'il soit devenu clair que la cause du problème était une fuite de mémoire, nous avons immédiatement vidé l'instantané de la mémoire de service et importé le fichier de vidage dans MAT (Eclipse Memory Analyzer) pour analyse. Suspects de fuite Accédez à la vue du point de fuite suspecté.
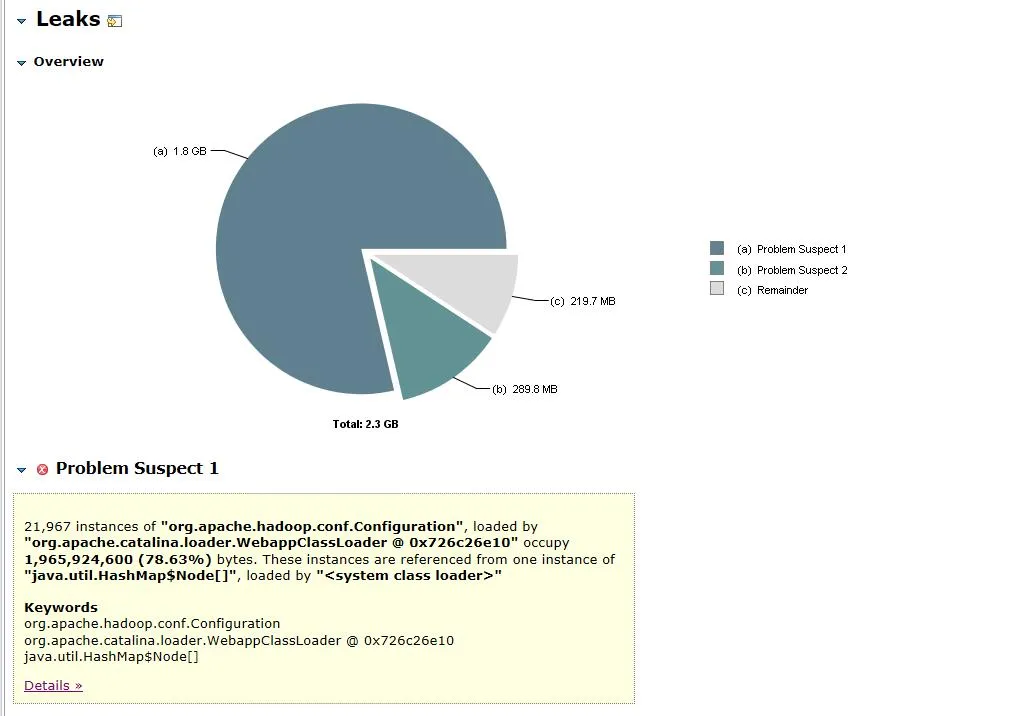
Figure 3.1 Analyse des objets mémoire
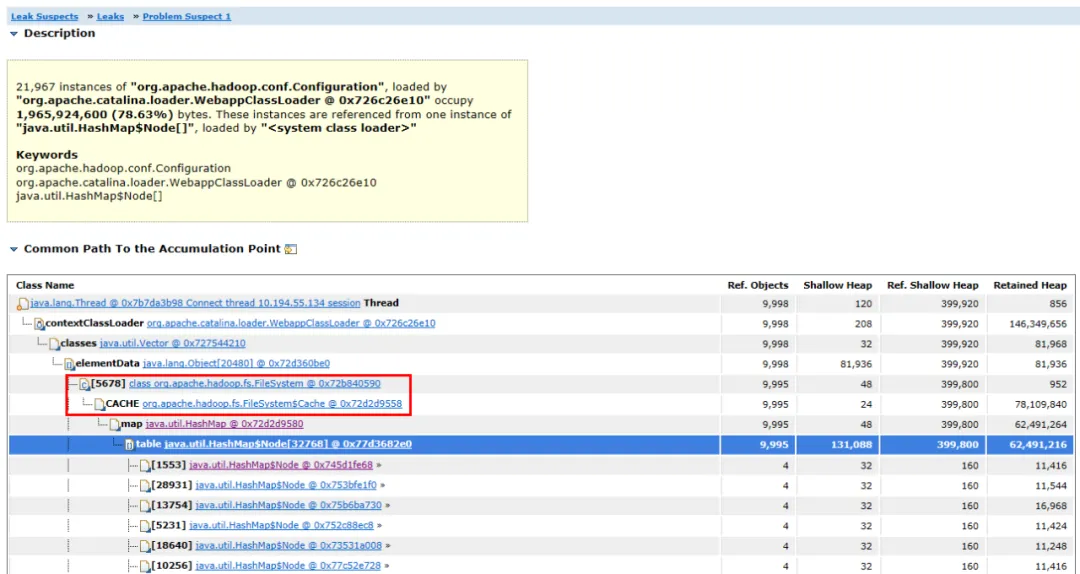
Figure 3.2 Diagramme de liens d'objets
Le fichier de vidage ouvert est illustré à la figure 3.1. L'objet org.apache.hadoop.conf.Configuration représente 1,8 Go de la mémoire tas de 2,3 Go, soit 78,63 % de la mémoire tas totale .
Développez les objets associés et les chemins de l'objet, vous pouvez voir que l'objet principal occupé est HashMap . Le HashMap est détenu par l'objet FileSystem.Cache et la couche supérieure est FileSystem . On peut deviner que la fuite de mémoire est très probablement liée au système de fichiers.
3.2 Analyse du code source
Après avoir trouvé l’objet de fuite de mémoire, l’étape suivante consiste à trouver le code de fuite de mémoire.
Dans la figure 3.3, nous pouvons trouver un tel morceau de code dans notre code. Chaque fois qu'il interagit avec hdfs, il établira une connexion avec hdfs et créera un objet FileSystem. Mais après avoir utilisé l'objet FileSystem, la méthode close() n'a pas été appelée pour libérer la connexion.
Cependant, l' instance de configuration et l'instance FileSystem ici sont toutes deux des variables locales. Une fois la méthode exécutée, ces deux objets doivent être recyclables par la JVM. Comment cela peut-il provoquer une fuite de mémoire ?
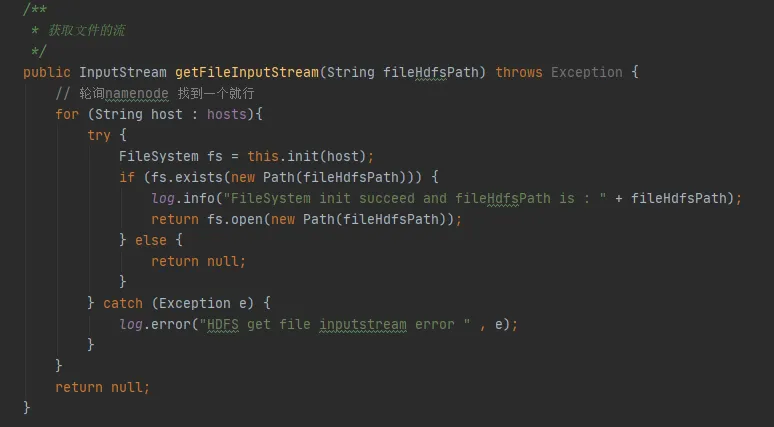
Graphique 3.3
(1) Conjecture 1 : FileSystem a-t-il des objets constants ?
Nous examinerons ensuite le code source de la classe FileSystem. Les méthodes init et get de FileSystem sont les suivantes :
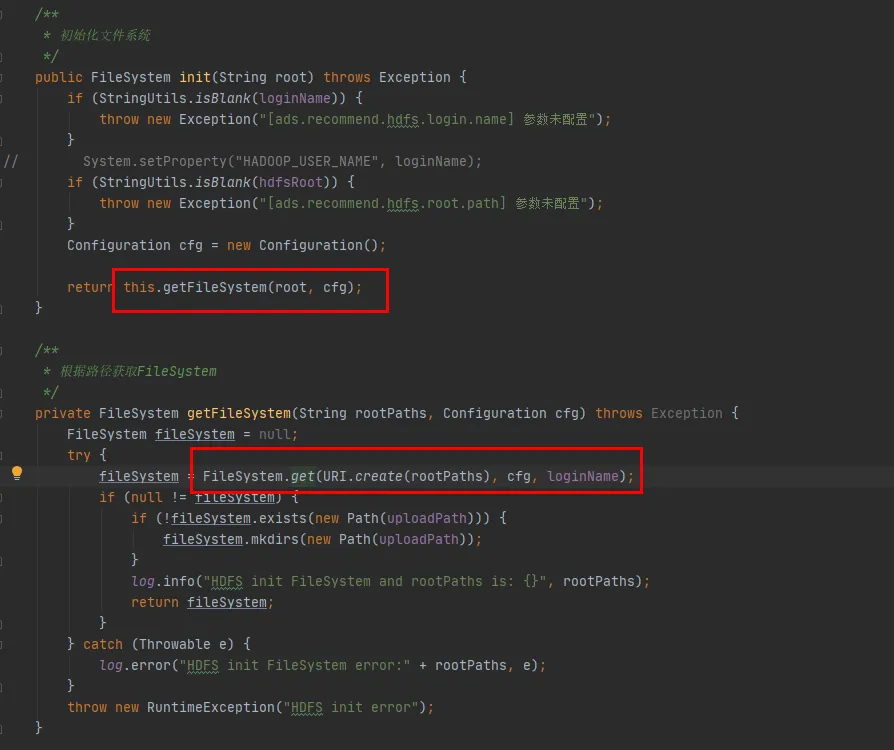

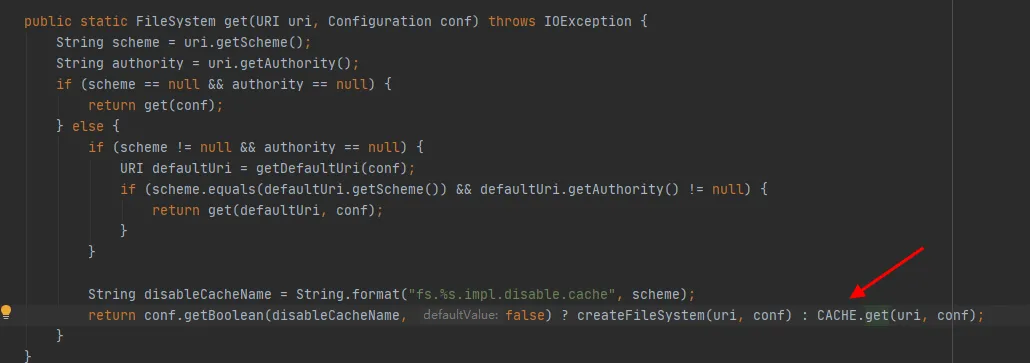
Graphique 3.4
Comme le montre la dernière ligne de code de la figure 3.4, il existe un CACHE dans la classe FileSystem, et DisableCacheName est utilisé pour contrôler s'il faut récupérer les objets du cache . La valeur par défaut de ce paramètre est false. Autrement dit, FileSystem sera renvoyé par défaut via l'objet CACHE .

Graphique 3.5
Sur la figure 3.5, nous pouvons voir que CACHE est un objet statique de la classe FileSystem. En d'autres termes, l'objet CACHE existera toujours et ne sera pas recyclé. L'objet constant CACHE existe et la conjecture a été vérifiée.
Jetez ensuite un œil à la méthode CACHE.get :
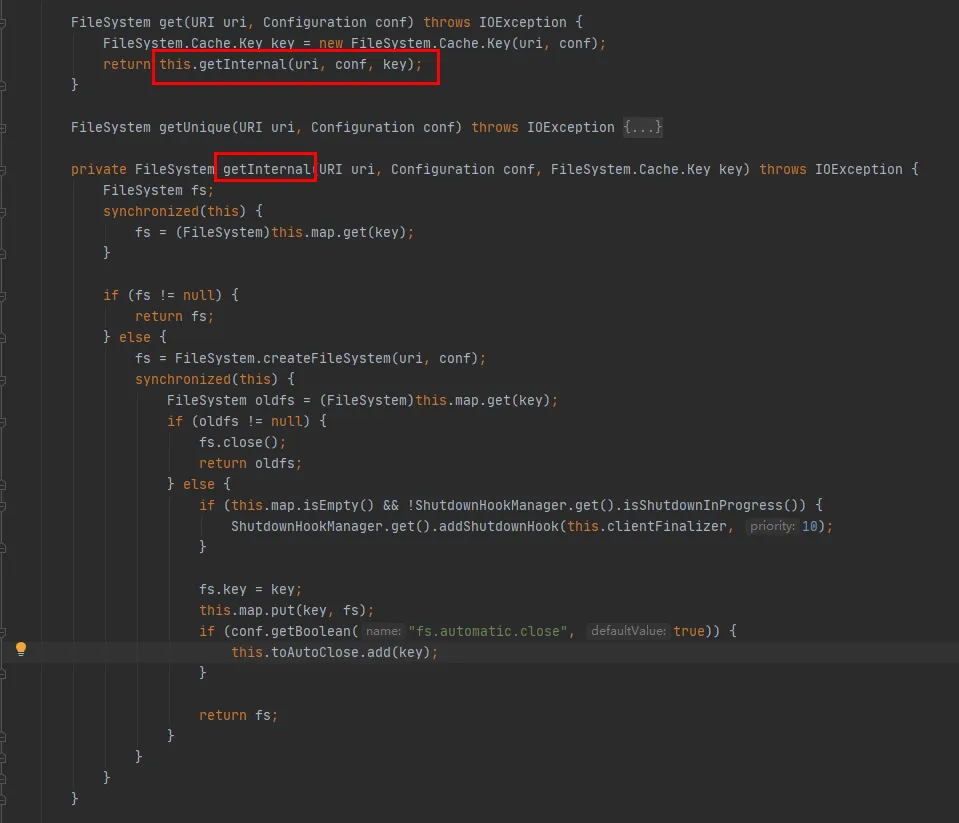
Comme le montre ce code :
-
Une carte est conservée dans la classe Cache, qui est utilisée pour mettre en cache les objets FileSystem connectés. La clé de la carte est l'objet Cache.Key. FileSystem sera obtenu via Cache.Key à chaque fois. S'il n'est pas obtenu, le processus de création se poursuivra.
-
Un Set (toAutoClose) est conservé dans la classe Cache, qui est utilisée pour stocker les connexions qui doivent être automatiquement fermées. Les connexions de cette collection sont automatiquement fermées à la fermeture du client.
-
Chaque FileSystem créé sera stocké dans la classe Map in the Cache avec Cache.Key comme clé et FileSystem comme valeur. Quant à savoir s'il y aura plusieurs caches pour le même URI hdfs lors de la mise en cache, vous devez vérifier la méthode hashCode de Cache.Key.
La méthode hashCode de Cache.Key est la suivante :

Les variables de schéma et d'autorité sont de type String Si elles sont dans le même URI, leur hashCode est cohérent. La valeur du paramètre unique est 0 à chaque fois. Ensuite, le hashCode de Cache.Key est déterminé par ugi.hashCode() .
À partir de l’analyse du code ci-dessus, nous pouvons trier :
-
Lors de l'interaction entre le code métier et HDFS, une connexion FileSystem sera créée pour chaque interaction, et la connexion FileSystem ne sera pas fermée à la fin.
-
FileSystem a un Cache statique intégré et il y a une Map à l'intérieur du Cache pour mettre en cache le FileSystem qui a créé une connexion.
-
Le paramètre fs.hdfs.impl.disable.cache est utilisé pour contrôler si FileSystem doit être mis en cache. Par défaut, il est faux, ce qui signifie mise en cache.
-
Map in Cache, Key est la classe Cache.Key, qui détermine une Key via quatre paramètres : schéma, autorité, ugi et unique , comme indiqué ci-dessus dans la méthode hashCode de Cache.Key.
(2) Conjecture 2 : FileSystem met-il en cache le même URI hdfs plusieurs fois ?
Le constructeur FileSystem.Cache.Key est le suivant : ugi est déterminé par getCurrentUser() de UserGroupInformation.

Continuez à examiner la méthode getCurrentUser() de UserGroupInformation, comme suit :

L'essentiel est de savoir si l'objet Subject peut être obtenu via AccessControlContext. Dans cet exemple, lorsqu'il est obtenu via get (final URI uri, final Configuration conf, final String user), lors du débogage, il s'avère qu'un nouvel objet Subject peut être obtenu ici à chaque fois. En d’autres termes, le même chemin hdfs mettra en cache un objet FileSystem à chaque fois .
La conjecture 2 a été vérifiée : le même URI HDFS sera mis en cache plusieurs fois, entraînant une expansion rapide du cache, et le cache ne définit pas de délai d'expiration ni de politique d'élimination, conduisant finalement à un débordement de mémoire.
(3) Pourquoi FileSystem met-il en cache à plusieurs reprises ?
Alors pourquoi obtenons-nous un nouvel objet Subject à chaque fois ? Examinons le code pour obtenir le AccessControlContext, comme suit :
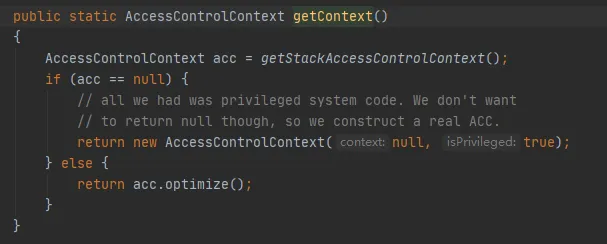
La méthode clé est la méthode getStackAccessControlContext, qui appelle la méthode Native, comme suit :

Cette méthode renvoie l'objet AccessControlContext des autorisations du domaine de protection de la pile actuelle.
Nous pouvons le voir à travers la méthode get(final URI uri, final Configuration conf, final String user) dans la figure 3.6 , comme suit :
-
Tout d'abord, un objet UserGroupInformation est obtenu via la méthode UserGroupInformation.getBestUGI .
-
Ensuite, la méthode get(URI uri, Configuration conf) est appelée via la méthode doAs de UserGroupInformation.
-
Figure 3.7 Implémentation de la méthode UserGroupInformation.getBestUGI Ici, concentrez-vous sur les deux paramètres transmis, ticketCachePath et user . ticketCachePath est la valeur obtenue en configurant hadoop.security.kerberos.ticket.cache.path Dans cet exemple, ce paramètre n'est pas configuré, donc ticketCachePath est vide. Le paramètre user est le nom d'utilisateur transmis dans cet exemple.
-
ticketCachePath est vide et user n'est pas vide, donc la méthode createRemoteUser de la figure 3.7 sera finalement exécutée.

Graphique 3.6

Graphique 3.7
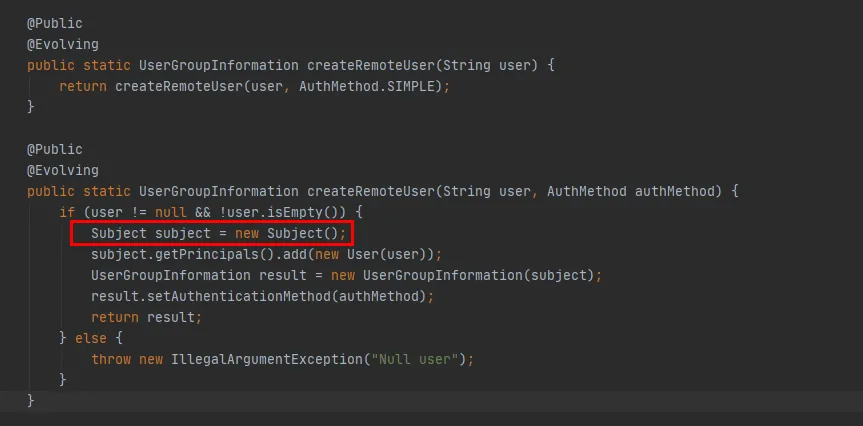
Graphique 3.8
À partir du code rouge de la figure 3.8, vous pouvez voir que dans la méthode createRemoteUser, un nouvel objet Subject est créé et l'objet UserGroupInformation est créé via cet objet . À ce stade, l’exécution de la méthode UserGroupInformation.getBestUGI est terminée.
Ensuite, jetez un œil à la méthode UserGroupInformation.doAs (la dernière méthode exécutée par FileSystem.get (final URI uri, final Configuration conf, final String user)), comme suit :
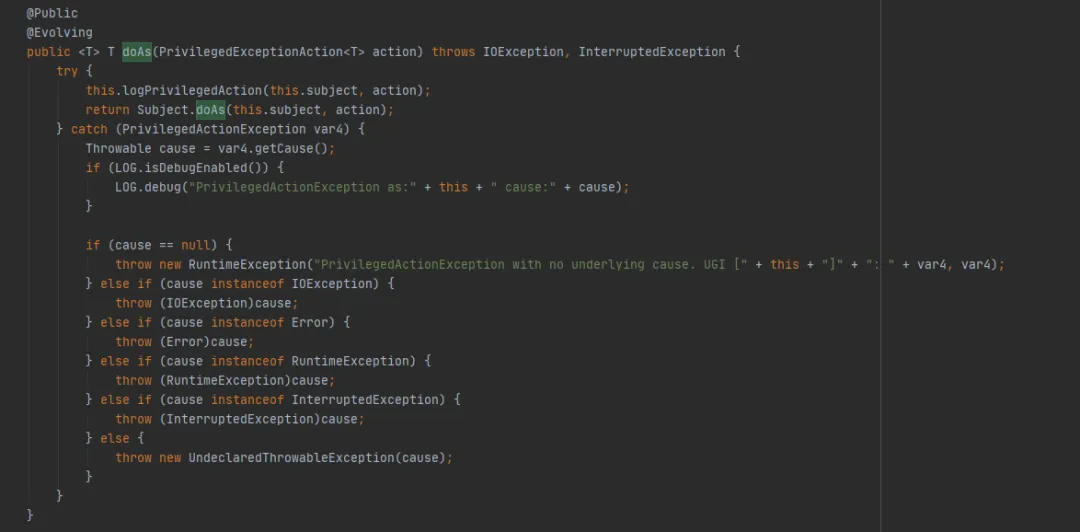
Appelez ensuite la méthode Subject.doAs, comme suit :
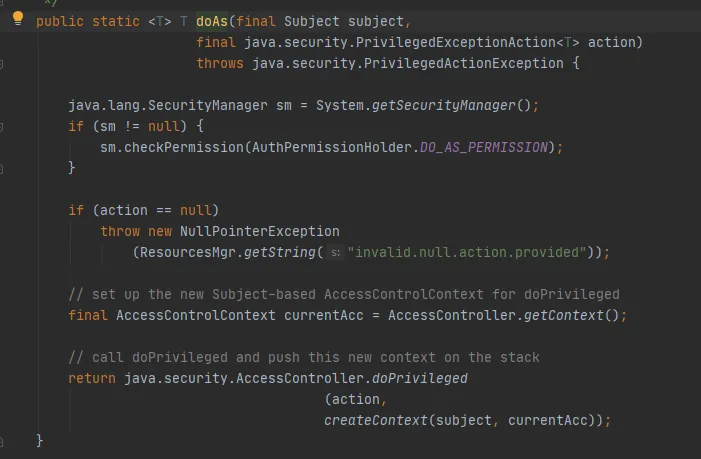
Enfin, appelez la méthode AccessController.doPrivileged, comme suit :
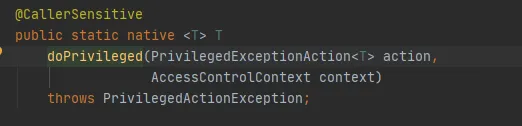
Cette méthode est une méthode native, qui utilisera le AccessControlContext spécifié pour exécuter PrivilegedExceptionAction, c'est-à-dire appeler la méthode run de l'implémentation. C'est la méthode FileSystem.get(uri, conf).
À ce stade, on peut expliquer que dans cet exemple, lors de la création de FileSystem via la méthode get(final URI uri, final Configuration conf, final String user), le hashCode de Cache.key stocké dans le cache de FileSystem est incohérent à chaque fois. .
Résumer:
-
Lors de la création de FileSystem via la méthode get(final URI uri, final Configuration conf, final String user) , de nouveaux objets UserGroupInformation et Subject seront créés à chaque fois.
-
Lorsque l'objet Cache.Key calcule hashCode , ce qui affecte le résultat du calcul est l'appel à la méthode UserGroupInformation.hashCode .
-
Méthode UserGroupInformation.hashCode, calculée comme suit : System.identityHashCode(subject) . Autrement dit, si le sujet est le même objet, le même hashCode sera renvoyé puisqu'il est différent à chaque fois dans cet exemple, le hashCode calculé est incohérent.
-
En résumé, le hashCode de Cache.key calculé à chaque fois est incohérent, et le Cache de FileSystem sera écrit à plusieurs reprises.
(4) Utilisation correcte de FileSystem
D'après l'analyse ci-dessus, puisque FileSystem.Cache ne joue pas son rôle, pourquoi ce Cache devrait-il être conçu ? En fait, c’est juste que notre utilisation n’est pas correcte.
Dans FileSystem, il existe deux méthodes get surchargées :
public static FileSystem get(final URI uri, final Configuration conf, final String user)
public static FileSystem get(URI uri, Configuration conf)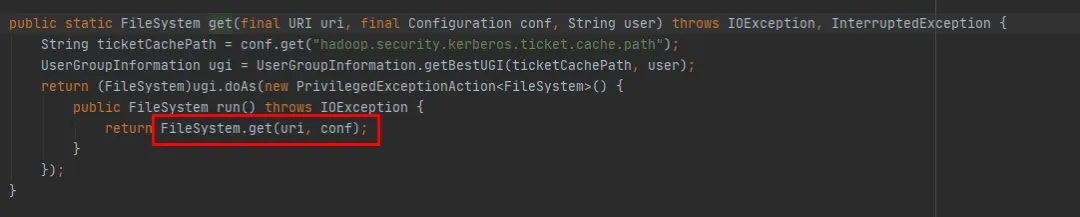
Nous pouvons voir que la méthode FileSystem get(final URI uri, final Configuration conf, final String user) appelle finalement la méthode FileSystem get(URI uri, Configuration conf). La différence est que la méthode FileSystem get(URI uri, Configuration conf). manque. Il manque juste l'opération de création d'un nouveau sujet à chaque fois.

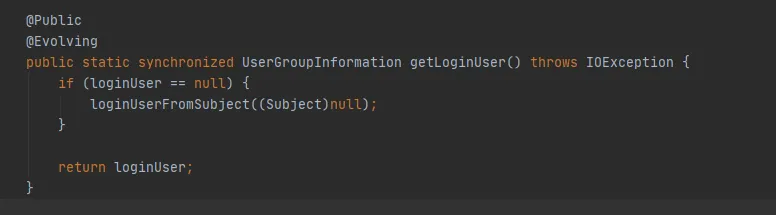
Graphique 3.9
S'il n'y a aucune opération pour créer un nouveau sujet, alors le sujet de la figure 3.9 est nul et la dernière méthode getLoginUser sera utilisée pour obtenir le loginUser. LoginUser est une variable statique, donc une fois l'objet loginUser initialisé avec succès, l'objet sera utilisé à l'avenir. La méthode UserGroupInformation.hashCode renverra la même valeur hashCode. Autrement dit, le cache mis en cache dans FileSystem peut être utilisé avec succès.

Graphique 3.10
4. Solutions
Après l'introduction précédente, si nous voulons résoudre le problème de fuite de mémoire de FileSystem, nous avons les deux méthodes suivantes :
(1)使用public static FileSystem get(URI uri, Configuration conf):
-
Cette méthode peut utiliser le cache FileSystem, ce qui signifie qu'il n'y aura qu'un seul objet de connexion FileSystem pour le même URI hdfs.
-
Définissez l'utilisateur d'accès via System.setProperty("HADOOP_USER_NAME", "hive").
-
Par défaut, fs.automatic.close=true, c'est-à-dire que toutes les connexions seront fermées via ShutdownHook.
(2)使用public static FileSystem get(final URI uri, final Configuration conf, final String user):
-
Comme analysé ci-dessus, cette méthode rendra le cache du système de fichiers invalide et il sera ajouté à la carte du cache à chaque fois, ce qui empêchera son recyclage.
-
Lors de son utilisation, une solution consiste à s’assurer qu’il n’existe qu’un seul objet de connexion FileSystem pour le même URI hdfs.
-
Une autre solution consiste à appeler la méthode close après chaque utilisation de FileSystem, ce qui supprimera le FileSystem du Cache.
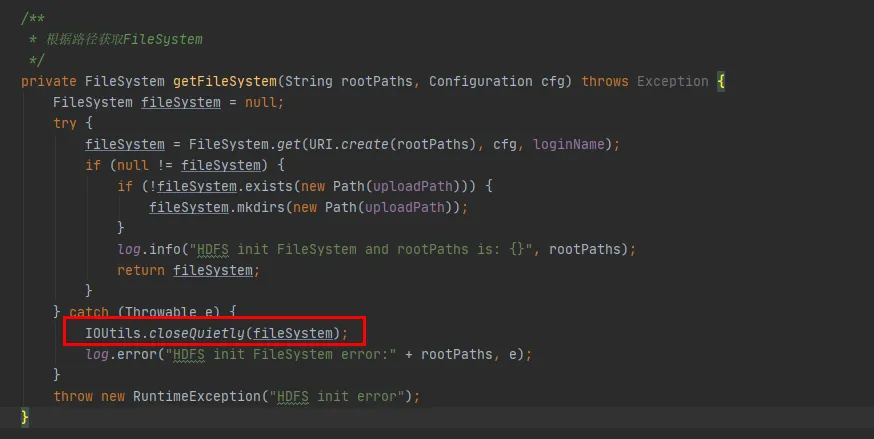
Sur la base du principe de modifications minimes de notre code historique existant, nous avons choisi la deuxième méthode de modification. Fermez l'objet FileSystem après chaque utilisation de FileSystem.
5. Résultats d'optimisation
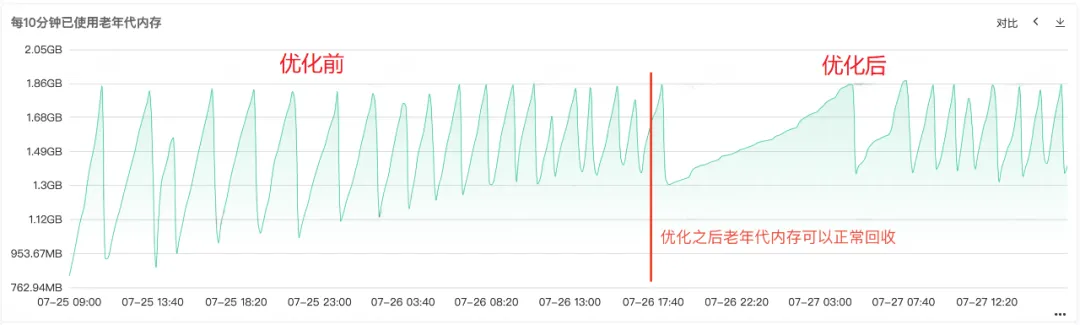
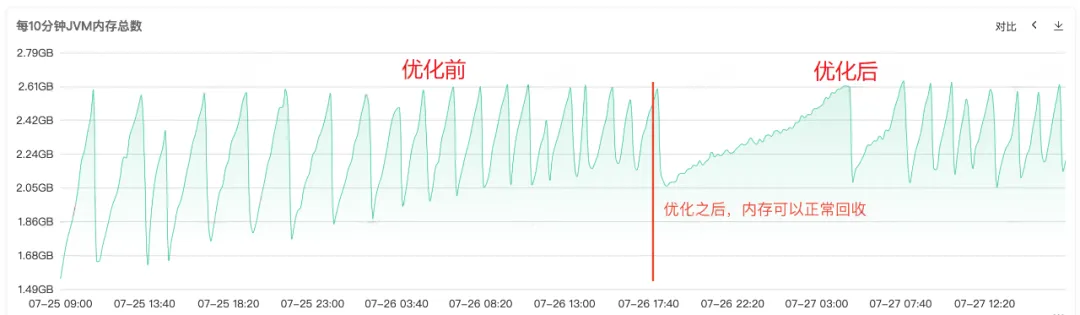
Une fois le code réparé et publié en ligne, comme le montre la figure 1 ci-dessous, vous pouvez voir que la mémoire de l'ancienne génération peut être recyclée normalement après la réparation. À ce stade, le problème est enfin résolu.
6. Résumé
Le débordement de mémoire est l'un des problèmes les plus courants dans le développement Java. Il est généralement dû à des fuites de mémoire qui empêchent le recyclage normal de la mémoire. Dans notre article, nous présenterons en détail un processus complet de traitement des débordements de mémoire en ligne.
Résumez nos solutions courantes en cas de débordement de mémoire :
(1) Générer un fichier de mémoire tas :
Ajouter la commande de démarrage du service
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/baseLaissez le service vider automatiquement les fichiers mémoire lorsque le MOO se produit ou utilisez la commande jam pour vider les fichiers mémoire.
(2) Analyse de la mémoire de tas : utilisez les outils d'analyse de la mémoire pour nous aider à analyser plus en profondeur le problème de débordement de mémoire et à trouver la cause du débordement de mémoire. Voici plusieurs outils d’analyse de mémoire couramment utilisés :
-
Eclipse Memory Analyzer : Un outil d'analyse de mémoire Java open source qui peut nous aider à localiser rapidement les fuites de mémoire.
-
VisualVM Memory Analyzer : Un outil basé sur une interface graphique qui peut nous aider à analyser l'utilisation de la mémoire des applications Java.
(3) Localisez le code de fuite de mémoire spécifique en fonction de l'analyse de la mémoire tas.
(4) Modifiez le code de fuite de mémoire et rééditez-le pour vérification.
Les fuites de mémoire sont une cause fréquente de débordement de mémoire, mais elles ne sont pas la seule cause. Les causes courantes des problèmes de débordement de mémoire incluent : des objets surdimensionnés, une allocation de mémoire de tas trop petite, des appels en boucle infinie , etc., qui peuvent tous conduire à des problèmes de débordement de mémoire.
Lorsque nous rencontrons des problèmes de débordement de mémoire, nous devons réfléchir sous plusieurs aspects et analyser le problème sous différents angles. Grâce aux méthodes et outils mentionnés ci-dessus et à diverses surveillances, nous pouvons nous aider à localiser et à résoudre rapidement les problèmes et à améliorer la stabilité et la disponibilité de notre système.
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants sur la plate-forme Windows à l'avenir