
Les index de base de données sont un élément clé pour optimiser les performances de tout système de base de données. Sans index efficaces, vos requêtes de base de données peuvent devenir lentes et inefficaces, entraînant une mauvaise expérience utilisateur et une productivité réduite. Dans cet article, nous explorerons quelques bonnes pratiques pour créer et utiliser des index de base de données.
Auteur : La piste Java
Source de cet article et couverture : https://medium.com/, traduit par la communauté open source Axon.
Cet article compte environ 2 700 mots et sa lecture devrait prendre 9 minutes.
Divers algorithmes d'indexation sont utilisés dans les bases de données pour améliorer les performances des requêtes. Voici quelques-uns des algorithmes d’indexation les plus couramment utilisés :
Indice B-Tree
Un index B-Tree est une structure de données arborescente auto-équilibrée qui maintient l'ordre des données et permet des recherches, un accès séquentiel, des insertions et des suppressions en temps logarithmique. La structure d’index B-Tree est largement utilisée dans les bases de données et les systèmes de fichiers. Les index B-Tree sont largement utilisés dans les bases de données relationnelles telles que MySQL et PostgreSQL.
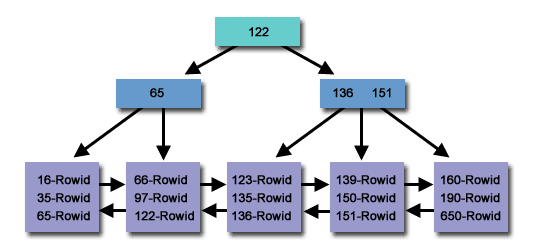
Les index B-Tree sont optimisés pour les requêtes par plage car ils peuvent trouver efficacement tous les enregistrements dans une plage de valeurs. En effet, les enregistrements sont stockés dans un ordre trié dans l'index. Profitez de l'utilisation des comparaisons de colonnes dans les expressions qui utilisent les opérateurs , =, >, >=ou <.<=BETWEEN
Par exemple, supposons que nous ayons une table de produits avec la structure de table suivante :
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
priceNous pouvons ajouter un index B-Tree au champ via l'instruction SQL suivante .
CREATE INDEX products_price_index ON products (price);
Indice de hachage
Les index de hachage sont un autre algorithme d'indexation populaire utilisé pour accélérer les requêtes. Les index de hachage utilisent une fonction de hachage pour mapper les clés aux emplacements d'index. Cet algorithme d'indexation est particulièrement utile pour les requêtes de correspondance exacte, telles que la recherche d'enregistrements spécifiques basés sur des valeurs de clé primaire . Les index de hachage sont couramment utilisés dans les bases de données en mémoire telles que Redis.
Les index de hachage fonctionnent en mappant chaque enregistrement de la table à un compartiment unique en fonction de sa valeur de hachage. Les valeurs de hachage sont calculées à l'aide d'une fonction de hachage, une fonction mathématique qui prend un élément de données en entrée et renvoie une valeur entière unique.
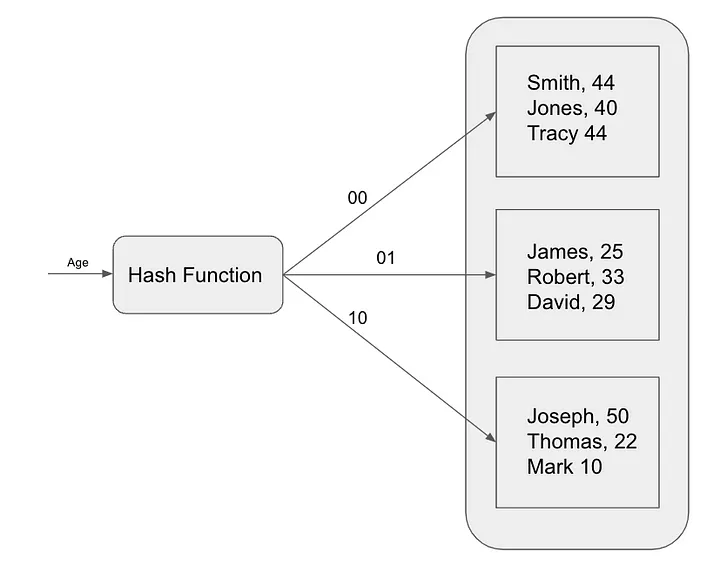
Pour rechercher un enregistrement dans un index haché, la base de données calcule le hachage de la clé de recherche, puis recherche le compartiment correspondant. Si l'enregistrement est dans le compartiment, la base de données renverra l'enregistrement. Sinon, la base de données effectue une analyse complète de la table.
Les index de hachage sont très rapides pour les recherches , mais ils ne peuvent pas être utilisés pour interroger efficacement des plages de données . En effet, les fonctions de hachage ne préservent aucun ordre entre les enregistrements de la table.
Pour exécuter une requête à l'aide d'un index de hachage :
- La base de données calcule la valeur de hachage des critères de requête.
- Recherchez le compartiment de hachage correspondant dans la table de hachage.
- La base de données récupère ensuite un pointeur vers la ligne de la table avec la valeur de hachage correspondante.
- Utilisez ces pointeurs pour récupérer les lignes réelles de la table.
Supposons que nous ayons une table de produits avec la structure de table suivante :
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
Q : Les index de hachage ne sont-ils pas optimisés comme B-Tree ?
Il existe certaines situations dans lesquelles un index de hachage n'est peut-être pas le meilleur choix :
- Les index de hachage sont plus rapides que les index d'arbre pour les recherches (pour les comparaisons d'égalité à l'aide de l'opérateur
=ou<=>), mais ils ne peuvent pas être utilisés pour interroger efficacement des plages de données. - Les index arborescents sont plus lents que les index de hachage lors de la recherche, mais ils peuvent être utilisés pour interroger efficacement des plages de données.
Requêtes par plage : les index de hachage ne sont pas optimisés pour les requêtes par plage, dans lesquelles vous devez rechercher des enregistrements dans une plage de valeurs (à l'aide des opérateurs =, >, >=, <ou <=) BETWEEN. Dans ce cas, un index B-Tree serait plus approprié.
Tri : les index de hachage ne sont pas optimisés pour le tri, vous devez trier les enregistrements en fonction d'une colonne spécifique. Dans ce cas, un index B-Tree ou un index clusterisé serait plus adapté.
Grands ensembles de données : les index de hachage peuvent être gourmands en mémoire et peuvent donc ne pas convenir aux grands ensembles de données où l'utilisation de la mémoire est un problème.
Nous pouvons namecréer un index de hachage sur la colonne en utilisant la commande suivante :
CREATE INDEX products_name_hash ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
CREATE INDEX products_name_tree ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
Si nous utilisons un index de hachage, la base de données calculera la valeur de hachage de la clé de recherche « iPhone 13 Pro » , puis recherchera le compartiment correspondant. Les fonctions de hachage étant déterministes, la base de données trouvera toujours les enregistrements dans le même compartiment, quel que soit l'ordre dans lequel les enregistrements sont stockés dans la table.
Si nous utilisons un index arborescent, la base de données démarrera à la racine de l'arborescence et comparera la clé de recherche « iPhone 13 Pro » avec la valeur de la clé stockée à la racine . L'arborescence étant triée, la base de données trouvera rapidement l'enregistrement contenant la clé de recherche.
Q : Pourquoi B-Tree est-il plus optimisé pour les requêtes Range que l'index Hash ?
Supposons maintenant que nous souhaitions trouver tous les produits dont le prix est compris entre 100 $ et 200 $. Nous pouvons utiliser la requête suivante :
SELECT * FROM products WHERE price BETWEEN 100 AND 200;
principe de fonctionnement
Arbre B
Les index B-Tree fonctionnent en stockant les enregistrements dans un ordre trié. Pour rechercher des enregistrements dans un index B-Tree,
- La base de données commence à la racine de l'arborescence et compare la clé de recherche à la valeur de la clé stockée à la racine.
- Si la clé de recherche est égale à la clé racine, la base de données renvoie cet enregistrement.
- Sinon, la base de données détermine quel sous-arbre rechercher ensuite en fonction des résultats de la comparaison.
Hacher
Les index de hachage fonctionnent en mappant chaque enregistrement d'une table à un compartiment unique en fonction de sa valeur de hachage. La valeur de hachage est calculée à l'aide d'une fonction de hachage. Les index de hachage distribuent les données de manière aléatoire entre des compartiments, ce qui rend les requêtes par plage inefficaces. La récupération d'une plage de valeurs, telle que des prix compris entre 100 $ et 200 $, nécessite d'analyser tous les compartiments de cette plage, ce qui aboutit effectivement à une analyse complète de la table. Les index de hachage sont efficaces pour les recherches rapides de correspondances exactes, mais ne disposent pas de l'ordre des données requis pour des requêtes de plage efficaces.
Question, pourquoi l'index B-Tree est-il plus optimisé que l'index Hash dans le tri ?
Les index arborescents B-Tree trient les données plus efficacement que les index de hachage, car ils stockent les enregistrements dans un ordre trié. Cela permet à la base de données de parcourir rapidement les enregistrements dans un ordre trié.
Les index de hachage fonctionnent en mappant chaque enregistrement d'une table à un compartiment unique en fonction de sa valeur de hachage. Cela signifie que l'ordre des enregistrements dans le compartiment est aléatoire. Pour trier les enregistrements, la base de données doit parcourir tous les compartiments, puis trier les enregistrements dans chaque compartiment. C'est plus lent que l'utilisation d'un index B-Tree, qui stocke les enregistrements dans un ordre trié.
On peut pricecréer un index B-Tree sur la colonne en utilisant la commande suivante :
CREATE INDEX products_price_index ON products (price);
Supposons maintenant que nous souhaitions trier les produits par prix, par ordre croissant. Nous pouvons utiliser la requête suivante :
SELECT * FROM products ORDER BY price ASC;
La base de données utilisera un index B-tree pour parcourir rapidement les produits dans un ordre trié.
Inconvénients de l'index de hachage :
- Les index de hachage ne prennent pas en charge les requêtes par plage ni le tri
- Les index de hachage consomment beaucoup de mémoire
- Les index de hachage ne conviennent pas aux bases de données fréquemment mises à jour
Index bitmap
Les index bitmap sont utilisés pour les colonnes comportant un petit nombre de valeurs distinctes, telles que les colonnes booléennes ou de genre. Les index bitmap sont très compacts et efficaces pour les colonnes de cardinalité inférieure.
SELECT * FROM employees WHERE gender = 'Female';
Les index bitmap sont très efficaces sur les colonnes de cardinalité inférieure, permettant des opérations de définition rapide telles que les unions et les intersections. Idéal pour les rapports ad hoc et l'entreposage de données.
Index de texte intégral
L'indexation de texte intégral est utilisée pour indexer de grandes quantités de données textuelles, telles que des documents ou des pages Web. Cet algorithme d'indexation divise le texte en mots ou en jetons et les indexe de manière à permettre des opérations de recherche efficaces. Les index de texte intégral sont particulièrement utiles pour les requêtes impliquant la recherche de mots ou d'expressions spécifiques dans le texte. L'indexation de texte intégral est couramment utilisée dans les moteurs de recherche tels qu'Elasticsearch.
Cas d'utilisation de l'indexation de texte intégral pour le commerce électronique :
L'indexation en texte intégral permet aux applications de commerce électronique de rechercher rapidement de grands catalogues de produits en fonction des requêtes de recherche saisies par l'utilisateur. L'indexation de texte intégral permet une recherche basée sur plusieurs mots et expressions, y compris les fautes d'orthographe, les synonymes et même les concepts associés. Cela permet aux utilisateurs de trouver plus facilement ce qu'ils recherchent, même s'ils ne connaissent pas le nom ou la description exacte du produit.
Par exemple, imaginez qu’un client recherche une nouvelle paire de chaussures de course. Ils tapent « chaussures de course » dans la barre de recherche. Grâce à l'indexation en texte intégral, les applications de commerce électronique peuvent rechercher rapidement toutes les descriptions, noms et étiquettes de produits pour trouver tous les produits liés aux chaussures de course. Les résultats de recherche sont triés par pertinence, qui est déterminée par la fréquence à laquelle les termes de recherche apparaissent dans les informations sur le produit.
Sans indexation en texte intégral, une recherche ne peut porter que sur le nom du produit, sans prendre en compte d'autres facteurs susceptibles d'être pertinents pour les clients, tels que les descriptions ou les étiquettes des produits. De plus, la recherche ne peut pas gérer les fautes d'orthographe ou les concepts associés, tels que « chaussures de jogging » ou « baskets ».
Supposons que nous ayons une productstable nommée avec les colonnes suivantes : id, et .namedescriptiontags
CREATE FULLTEXT INDEX products_ft_index ON products(name, description, tags);
Imaginez maintenant qu'un client recherche des « chaussures de course ». Nous pouvons utiliser la requête suivante pour rechercher des produits liés au terme de recherche :
SELECT id, name, description, MATCH(name, description, tags) AGAINST('running shoes') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('running shoes' IN BOOLEAN MODE)
ORDER BY relevance DESC
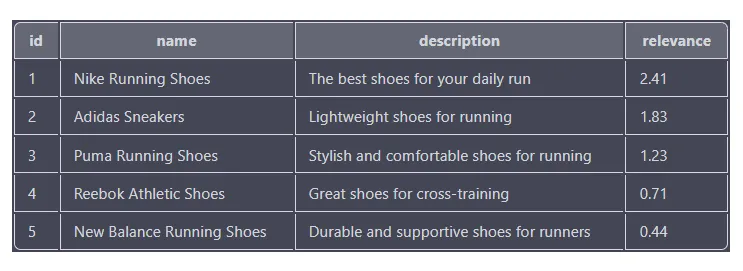
Les scores de pertinence sont basés sur la mesure dans laquelle chaque produit correspond aux termes de recherche, les scores plus élevés indiquant une correspondance plus étroite. Les résultats sont triés par ordre décroissant en fonction du score de pertinence, de sorte que le produit avec le score de pertinence le plus élevé (chaussures de course Nike) apparaît en haut de la liste.
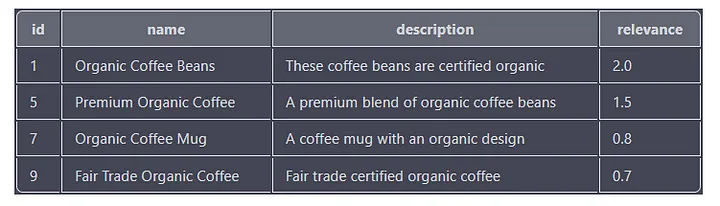
Voici un autre exemple de requête qui recherche des produits contenant les mots « biologique » et « café » :
SELECT id, name, description, MATCH(name, description, tags) AGAINST('+"organic" +"coffee"') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('+"organic" +"coffee"' IN BOOLEAN MODE)
ORDER BY relevance DESC;
Cette requête recherche tous les produits comportant à la fois les mots-clés « biologique » et « café » dans les colonnes de nom, de description ou d'étiquette. Le score de pertinence de chaque résultat est également calculé en fonction du nombre de fois et de la position du mot-clé dans la colonne.
La sortie contiendra les colonnes « id », « name », « description » et « pertinence », avec les résultats triés par la colonne « pertinence » par ordre décroissant.
avantage
- Les index de texte intégral fonctionnent très bien pour les colonnes basées sur du texte
- Idéal pour les moteurs de recherche et les systèmes de gestion de contenu
- Prend en charge le classement par pertinence des résultats de recherche
défaut
- L'indexation de texte intégral occupe beaucoup d'espace de stockage
- Pour les très grands ensembles de données, les performances peuvent se dégrader
- L'indexation de texte intégral ne convient pas aux données numériques ou catégorielles
Pour des articles plus techniques, veuillez visiter : https://opensource.actionsky.com/
À propos de SQLE
SQLE est une plateforme complète de gestion de la qualité SQL qui couvre l'audit et la gestion SQL, du développement aux environnements de production. Il prend en charge les bases de données open source, commerciales et nationales grand public, fournit des capacités d'automatisation des processus pour le développement, l'exploitation et la maintenance, améliore l'efficacité en ligne et améliore la qualité des données.
SQLE obtenir
| taper | adresse |
|---|---|
| Dépôt | https://github.com/actiontech/sqle |
| document | https://actiontech.github.io/sqle-docs/ |
| publier des nouvelles | https://github.com/actiontech/sqle/releases |
| Documentation de développement du plug-in d'audit des données | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |