


Les idées d'accélération actuelles incluent l'optimisation des opérateurs, la compilation de modèles, la mise en cache de modèles, la distillation de modèles, etc. Ce qui suit présente brièvement plusieurs solutions open source représentatives utilisées dans les tests.
▐Optimisation de l'opérateur : FlashAttention2
▐Compilation de modèles : oneflow/stable-fast
oneflow accélère l'inférence de modèle en compilant le modèle dans un graphe statique et en le combinant avec la fusion d'opérateurs intégrée de oneflow.nn.Graph et d'autres stratégies d'accélération. L'avantage est que le modèle SD de base n'a besoin que d'une seule ligne de code compilé pour compléter l'accélération, l'effet d'accélération est évident, la différence dans l'effet de génération est faible, il peut être utilisé en combinaison avec d'autres solutions d'accélération (telles que le cache profond) , et la fréquence de mise à jour officielle est élevée. Les lacunes seront discutées plus tard.
Stable-fast est également une bibliothèque d'accélération basée sur la compilation de modèles et combine une série de méthodes d'accélération de fusion d'opérateurs, mais son optimisation des performances repose sur des outils tels que xformer, triton et torch.jit.
▐Mise en cache du modèle : deepcache
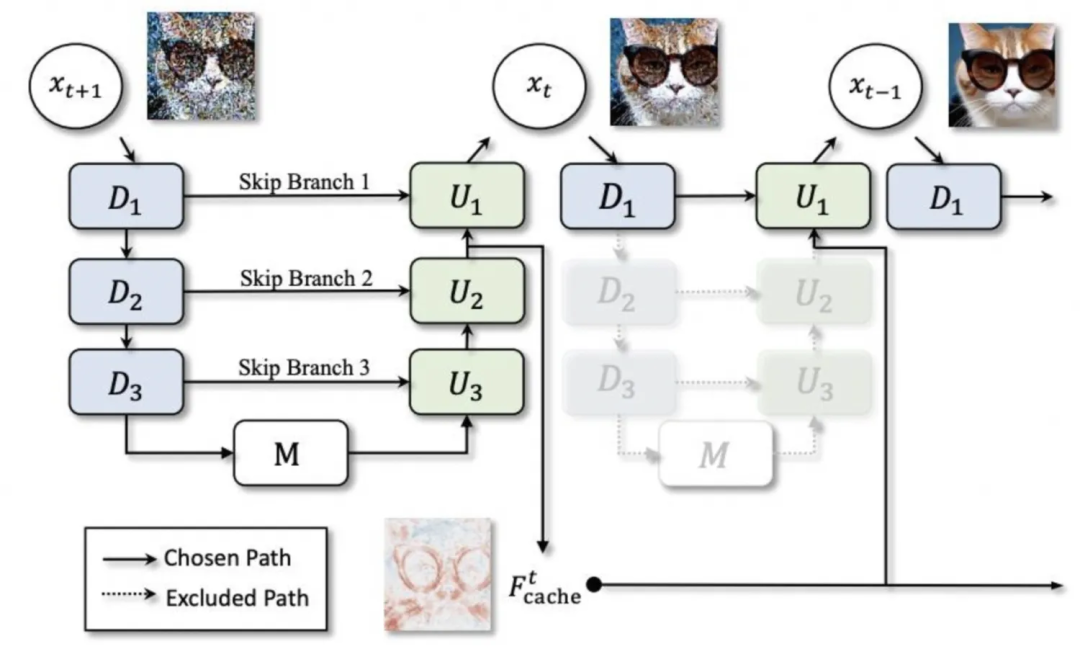
▐Modèle de distillation : lcm-lora
En combinant lcm (Latent Consistency Model) et lora, lcm distillera l'intégralité du modèle sd pour obtenir un raisonnement en quelques étapes, tandis que lcm-lora utilise la forme de lora pour optimiser uniquement la partie lora, qui peut également être combinée directement. avec une utilisation régulière de lora.

Test d'accélération SD1.5
▐Environnement de test
▐Résultats des tests
-
En comparant les images générées avec une graine fixe, nous pouvons constater que la compilation oneflow peut réduire le rt de plus de 40 % sans presque aucune perte de précision. Cependant, lors de l'utilisation d'un nouveau pipeline pour générer des images pour la première fois, cela prend des dizaines. secondes de temps de compilation comme échauffement. -
Deepcache peut réduire le rt de 15 à 25 % supplémentaires sur cette base, mais en même temps, à mesure que l'intervalle de cache augmente, la différence dans les effets de génération devient de plus en plus évidente. -
oneflow est également efficace pour le modèle SD1.5 utilisant controlnet -
stable-fast s'appuie fortement sur des packages externes et est sujet à divers problèmes de version et erreurs d'outils externes. Semblable à oneflow, il faut un certain temps de compilation pour générer des images pour la première fois, et l'effet d'accélération final est légèrement inférieur à. un flux.
▐Données de comparaison détaillées
Optimisation |
Temps de génération moyen (secondes) 512*512, 50 étapes |
effet d'accélération |
Générer l'effet 1 |
Générer l'effet 2 |
Générer l'effet 3 |
diffuseurs |
3.3701 |
0 |
|
|
|
diffuseurs+bf16 |
3.3669 |
≈0 |
|
|
|
diffuseurs+controlnet |
4.7452 |
|
|||
compilation diffuseurs + oneflow |
1,9857 |
41,08% |
|
|
|
diffuseurs+compilation oneflow+controlnet |
2.8017 |
|
|||
diffuseurs + compilation oneflow + deepcache |
intervalle=2:1.4581 |
56,73%(15,65%) |
|
|
|
intervalle=3:1.3027 |
61,35%(20,27%) |
|
|
||
intervalle=5:1.1583 |
65,63%(24,55%) |
|
|
||
diffuseurs+rapides |
2,3799 |
29,38% |















▐Environnement de test
▐Résultats des tests
Modèle SDXL de base :
Dans des conditions de graine fixe, le modèle sdxl semble plus susceptible d'affecter l'effet de génération d'images en utilisant différents schémas d'accélération.
Oneflow ne peut réduire le rt que de 24 %, mais il peut toujours garantir la précision des images générées.
Deepcache peut fournir une accélération extrêmement significative lorsque l'intervalle est de 2 (c'est-à-dire que le cache n'est utilisé qu'une seule fois), rt est réduit de 42 %. Lorsque l'intervalle est de 5, rt est réduit de 69 %. les images sont également évidentes.
lcm-lora réduit considérablement le nombre d'étapes nécessaires pour générer des graphiques et peut atteindre une accélération d'inférence dans une large mesure. Cependant, lors de l'utilisation de poids pré-entraînés, la stabilité est extrêmement mauvaise et elle est très sensible au nombre d'étapes. garantir une sortie stable conforme à l'image demandée
oneflow et deepcache/lcm-lora peuvent être bien utilisés ensemble
lora:
Après le chargement de lora, la vitesse d'inférence des diffuseurs est considérablement réduite et le degré de réduction est lié au type et à la quantité de lora utilisée.
Deepcache fonctionne toujours et il existe toujours des problèmes de précision, mais la différence n'est pas grande à des intervalles de cache inférieurs
Lors de l'utilisation de lora, la compilation oneflow ne peut pas corriger la graine pour rester cohérente avec la version originale.
La compilation Oneflow optimise la vitesse d'inférence après le chargement de lora Lorsque plusieurs lora sont chargées, le rt d'inférence est presque le même que lorsqu'aucune lora n'est chargée, et l'effet d'accélération est extrêmement important. Par exemple, en utilisant fil + aquarelle deux loras en même temps, le rt peut être réduit d'environ 65 %
oneflow a légèrement optimisé le temps de chargement de lora, mais le temps d'opération de réglage après chargement de lora a augmenté.
▐Données de comparaison détaillées
Optimisation |
lora |
Temps de génération moyen (secondes) 512*512, 50 étapes |
Temps de chargement de Lora (secondes) |
temps de modification lora (secondes) |
Effet 1 |
Effet 2 |
Effet 3 |
diffuseurs |
aucun |
4.5713 |
|
||||
fil |
7.6641 |
13.9235 11.0447 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0263 |
||||||
yarn+watercolor |
10.1402 |
|
|||||
diffusers+bf16 |
无 |
4.6610 |
|
||||
yarn |
7.6367 |
12.6095 11.1033 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0192 |
||||||
yarn+ watercolor |
10.0729 |
||||||
diffusers+deepcache |
无 |
interval=2:2.6402 |
|
||||
yarn |
interval=2:4.6076 |
||||||
watercolor |
interval=2:4.3953 |
||||||
yarn+ watercolor |
interval=2:5.9759 |
|
|||||
无 |
interval=5: 1.4068 |
|
|||||
yarn |
interval=5:2.7706 |
||||||
watercolor |
interval=5:2.8226 |
||||||
yarn+watercolor |
interval=5:3.4852 |
|
|||||
diffusers+oneflow编译 |
无 |
3.4745 |
|
||||
yarn |
3.5109 |
11.7784 10.3166 |
0.5左右 移除lora 0.17 |
||||
watercolor |
3.5483 |
||||||
yarn+watercolor |
3.5559 |
|
|||||
diffusers+oneflow编译+deepcache |
无 |
interval=2:1.8972 |
|
||||
yarn |
interval=2:1.9149 |
||||||
watercolor |
interval=2:1.9474 |
||||||
yarn+watercolor |
interval=2:1.9647 |
|
|||||
无 |
interval=5:0.9817 |
|
|||||
yarn |
interval=5:0.9915 |
||||||
watercolor |
interval=5:1.0108 |
||||||
yarn+watercolor |
interval=5:1.0107 |
|
|||||
diffusers+lcm-lora |
4step:0.6113 |
||||||
diffusers+oneflow编译+lcm-lora |
4step:0.4488 |














AI试衣业务场景使用了算法在diffusers框架基础上改造的专用pipeline,功能为根据待替换服饰图对原模特图进行换衣,基础模型为SD2.1。
根据调研的结果,deepcache与oneflow是优先考虑的加速方案,同时,由于pytorch版本较低,也可以尝试使用较新版本的pytorch进行加速。
▐ 测试环境
A10 + cu118 + py310 + torch2.0.1 + diffusers0.21.4
图生图(示意图,仅供参考):
待替换服饰 |
原模特图 |
|
|


▐ 测试结果
pytorch2.2版本集成了FlashAttention2,更新版本后,推理加速效果明显
deepcache仍然有效,为了尽量不损失精度,可设置interval为2或3
对于被“魔改”的pipeline和子模型,oneflow的图转换功能无法处理部分操作,如使用闭包函数替换forward、使用布尔索引等,而且很多错误原因较难通过报错信息来定位。在进行详细的排查之后,我们尝试了改造原模型代码,对其中不被支持的操作进行替换,虽然成功地在没有影响常规生成效果的前提下完成了改造,通过了oneflow编译,但编译后的生成效果很差,可以看出oneflow对pytorch的支持仍然不够完善
最终采取pytorch2.2.1+deepcache的结合作为加速方案,能够实现rt降低40%~50%、生成效果基本一致且不需要过多改动原服务代码
▐ 详细对比数据
优化方法 |
平均生成耗时(秒) 576*768,25step |
生成效果 |
diffusers |
22.7289 |
|
diffusers+torch2.2.1 |
15.5341 |
|
diffusers+torch2.2.1+deepcache |
11.7734 |
|
diffusers+oneflow编译 |
17.5857 |
|
diffusers+deepcache |
interval=2:18.0031 |
|
interval=3:16.5286 |
|
|
interval=5:15.0359 |
|








目前市面上有很多非常好用的开源模型加速工具,pytorch官方也不断将各种广泛采纳的优化技术整合到最新的版本中。
我们在初期的调研与测试环节尝试了很多加速方案,在排除了部分优化效果不明显、限制较大或效果不稳定的加速方法之后,初步认为deepcache和oneflow是多数情况下的较优解。
但在解决实际线上服务的加速问题时,oneflow表现不太令人满意,虽然oneflow团队针对SD系列模型开发了专用的加速工具包onediff,且一直保持高更新频率,但当前版本的onediff仍存在不小的限制。
如果使用的SD pipeline没有对unet的各种子模块进行复杂修改,oneflow仍然值得尝试;否则,确保pytorch版本为最新的稳定版本以及适度使用deepcache可能是更省心且有效的选择。

相关资料
FlashAttention:
https://github.com/Dao-AILab/flash-attention
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
oneflow
https://github.com/Oneflow-Inc/oneflow
https://github.com/siliconflow/onediff
stable-fast
https://github.com/chengzeyi/stable-fast
deepcache
https://github.com/horseee/DeepCache
lcm-lora
https://latent-consistency-models.github.io/
pytorch 2.2
https://pytorch.org/blog/pytorch2-2/

我们是淘天集团内容技术AI工程团队,通过搭建完善的算法工程化一站式平台,辅助上千个淘宝图文、视频、直播等泛内容领域算法的工程落地、部署和优化,承接每日上亿级别的数字内容数据,支撑并推动AI技术在淘宝内容社交生态中的广泛应用。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。