
mysqld : Frère, je n'arrive pas à me lever...
Auteur : Ben Shaohua, ingénieur au centre R&D ACOSEN, responsable des exigences et de la maintenance du projet. Autres identités : pelleteur Corgi.
Produit par la communauté open source Aikeson. Le contenu original ne peut être utilisé sans autorisation. Veuillez contacter l'éditeur et indiquer la source pour la réimpression.
Cet article compte environ 2 100 mots et sa lecture devrait prendre 7 minutes.
introduction
Comme l'indique le titre, dans les scénarios de tests automatisés, MySQL ne peut pas être démarré via systemd .
Terminez continuellement kill -9le processus d'instance et vérifiez si mysqld sera extrait correctement après la sortie.
Les informations spécifiques sont les suivantes :
- Informations sur l'hôte : CentOS 8 (conteneur Docker)
- Utilisez systemd pour gérer le processus mysqld
- Le mode de fonctionnement du service systemd est : forking
- La commande de démarrage est la suivante :
# systemd 启动命令
sudo -S systemctl start mysqld_11690.service
# systemd service 内的 ExecStart 启动命令
/opt/mysql/base/8.0.34/bin/mysqld --defaults-file=/opt/mysql/etc/11690/my.cnf --daemonize --pid-file=/opt/mysql/data/11690/mysqld.pid --user=actiontech-mysql --socket=/opt/mysql/data/11690/mysqld.sock --port=11690
Symptôme
La commande de démarrage continue de se bloquer, sans succès ni retour. Après plusieurs tentatives, le scénario ne peut pas être reproduit manuellement.
La figure ci-dessous montre un scénario de reproduction. Si les numéros de port de service sont incohérents, veuillez les ignorer.

Le journal des erreurs MySQL ne contient aucune information. Vérifiez l'état du service systemd et constatez que le script de démarrage MAIN PIDn'a pas pu s'exécuter en raison d'un manque de paramètres.
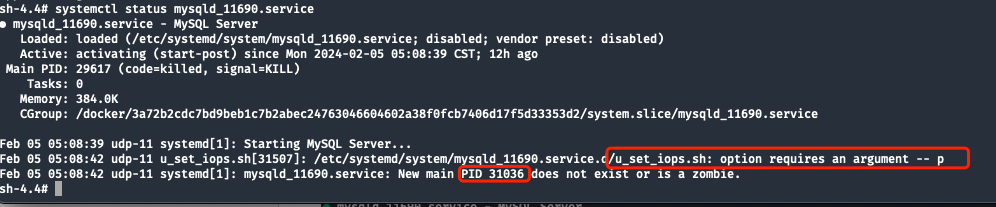
Les informations finales générées par systemd sont :New main PID 31036 does not exist or is a zombie
Résumé des raisons
Lorsque systemd démarre mysqld , il s'exécutera d'abord selon la configuration dans le modèle de service :
- ExecStart (démarrer mysqld )
- mysqld commence à créer
piddes fichiers - ExecStartPost (quelques post-scripts personnalisés : ajuster les autorisations, écrire
piddans cgroup , etc.)
Dans l'état intermédiaire de l'étape 2-3 , c'est-à-dire pidlorsque le fichier vient d'être créé, l'hôte reçoit la commande émise par le test automatisé : sudo -S kill -9 $(cat /opt/mysql/data/11690/mysqld.pid).
Puisque ce pidfichier et pidce processus existent (si killla commande ou la commande n'existe pas, catune erreur sera signalée), le CASE automatisé considère que killl'opération s'est terminée avec succès. Cependant, comme mysqld.pidce fichier est géré par MySQL lui-même, du point de vue de systemd , vous devez toujours attendre la fin de l'étape 3 avant que le démarrage soit considéré comme réussi.
Lorsque systemd utilise le mode forking , il déterminera PIDsi le service est démarré avec succès en fonction de la valeur du processus enfant.
Si le processus enfant démarre avec succès et qu'aucune sortie inattendue ne se produit, systemd considère que le service a été démarré et définit la PIDvaleur du processus enfant sur MAIN PID.
Si le processus enfant ne démarre pas ou se termine de manière inattendue, systemd considérera que le service n'a pas démarré correctement.
en conclusion
Lors de l'exécution d'ExecStartPost, étant donné que l'ID de processus enfant 31036 a été killsupprimé, le post-traitement shellne dispose pas de paramètres de démarrage, mais l'étape ExecStart a été terminée, ce qui fait que MAIN PID 31036 devient un processus zombie qui n'existe que dans systemd .
Processus de dépannage
Lorsque j'ai rencontré ce problème, j'étais un peu confus, j'ai simplement vérifié les informations de base de la mémoire et du disque. Cela a répondu aux attentes et les ressources ne manquaient pas.
Examinons d'abord le journal des erreurs de MySQL pour voir ce que nous trouvons. Visualisez les résultats comme suit :
...无关内容省略...
2024-02-05T05:08:42.538326+08:00 0 [Warning] [MY-010539] [Repl] Recovery from source pos 3943309 and file mysql-bin.000001 for channel ''. Previous relay log pos and relay log file had been set to 4, /opt/mysql/log/relaylog/11690/mysql-relay.000004 respectively.
2024-02-05T05:08:42.548513+08:00 0 [System] [MY-010931] [Server] /opt/mysql/base/8.0.34/bin/mysqld: ready for connections. Version: '8.0.34' socket: '/opt/mysql/data/11690/mysqld.sock' port: 11690 MySQL Community Server - GPL.
2024-02-05T05:08:42.548633+08:00 0 [System] [MY-013292] [Server] Admin interface ready for connections, address: '127.0.0.1' port: 6114
2024-02-05T05:08:42.548620+08:00 5 [Note] [MY-010051] [Server] Event Scheduler: scheduler thread started with id 5
En observant le journal des erreurs, nous avons constaté qu'il n'y avait aucune information utile car aucune information du journal n'est sortie après l'heure de démarrage.
Vérifiez l'état de systemctl pour confirmer l'état actuel du service :
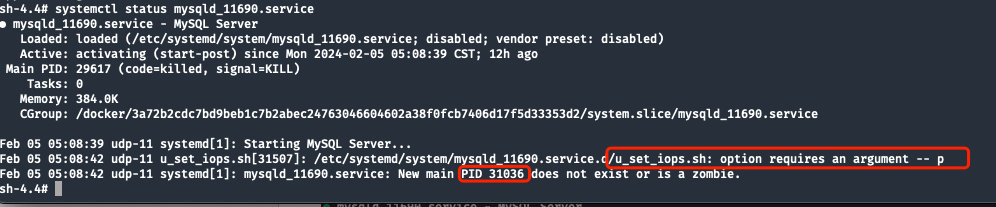
L'image ci-dessous montre les informations d'état dans des circonstances normales :

Après comparaison, deux informations utiles ont été compilées :
- La post- exécution a échoué
shellen raison du manque de-pparamètres (-ples paramètres sontMAIN PID, c'est-à-dire après le démarrage du processus enfant forkPID). - systemd ne peut pas être obtenu
PID 31036, n'existe pas ou est un processus zombie.
Vérifions d'abord le processus IDet mysqld.pidvoyons :
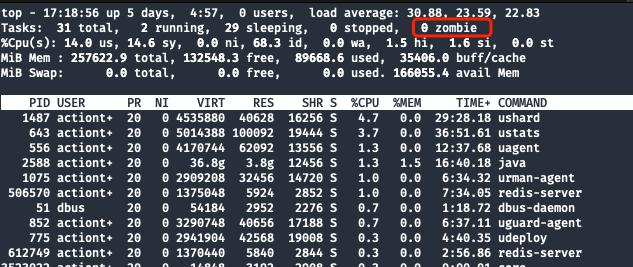
Indices de confirmation :
PID 31036n'existe pasmysqld.pidLe fichier existe et le contenu du fichier est 31036topCommande pour vérifier s'il n'y a pas de processus zombie
Il faut encore obtenir plus d'indices pour confirmer la cause, vérifiez journalctl -ule contenu pour voir si cela aide :
sh-4.4# journalctl -u mysqld_11690.service
-- Logs begin at Mon 2024-02-05 04:00:35 CST, end at Mon 2024-02-05 17:08:01 CST. --
Feb 05 05:07:54 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:07:56 udp-11 systemd[1]: Started MySQL Server.
Feb 05 05:08:31 udp-11 systemd[1]: mysqld_11690.service: Main process exited, code=killed, status=9/KILL
Feb 05 05:08:31 udp-11 systemd[1]: mysqld_11690.service: Failed with result 'signal'.
Feb 05 05:08:32 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:08:36 udp-11 systemd[1]: Started MySQL Server.
Feb 05 05:08:37 udp-11 systemd[1]: mysqld_11690.service: Main process exited, code=killed, status=9/KILL
Feb 05 05:08:37 udp-11 systemd[1]: mysqld_11690.service: Failed with result 'signal'.
Feb 05 05:08:39 udp-11 systemd[1]: Starting MySQL Server...
Feb 05 05:08:42 udp-11 u_set_iops.sh[31507]: /etc/systemd/system/mysqld_11690.service.d/u_set_iops.sh: option requires an argument -- p
Feb 05 05:08:42 udp-11 systemd[1]: mysqld_11690.service: New main PID 31036 does not exist or is a zombie.
Le contenu ici journalctl -udécrit uniquement le phénomène et ne peut pas analyser les raisons spécifiques. Il est similaire au contenu du statut systemctl et n'est pas très utile.
Afficher /var/log/messagesle contenu du journal système :

Il a été constaté que la boucle signalait des informations sur une erreur de mémoire. Après une recherche, il a été constaté que l'erreur pouvait être un problème matériel. Après avoir interrogé des collègues des tests automatisés, je suis arrivé à la conclusion :
- Le scénario est un problème occasionnel. Le cas d'utilisation est exécuté 4 fois, 2 fois avec succès et 2 fois en échec.
- Chaque exécution s'effectue sur le même hôte et la même image de conteneur.
- En cas d'échec, le conteneur dans lequel réside le blocage est le même.
Puisqu'il y a des résultats d'exécution réussis, nous ignorerons ici les problèmes matériels.
Maintenant que les conteneurs sont mentionnés, il y a un problème lorsque je me demande si les groupes de contrôle seront mappés à l'hôte ? Dans le statut systemctl vérifié ci-dessus , on peut voir que le répertoire hôte mappé par cgroup est :CGroup: /docker/3a72b2cdc7bd9beb1c7b2abec24763046604602a38f0fcb7406d17f5d33353d2/system.slice/mysqld_11690.service
Vérifiez les autorisations de lecture et d'écriture du dossier parent system.sliceet il n'y a aucune anomalie. Tout d'abord, éliminez temporairement le problème de mappage du groupe de contrôle (car il existe d'autres services repris par systemd sur l'hôte qui utilisent également le même groupe de contrôle ).
J'ai l'intention d'essayer si pstack peut voir où systemd se bloque spécifiquement, 3048143pour systemctl start pid:
sh-4.4# pstack 3048143
#0 0x00007fdfaef33ade in ppoll () from /lib64/libc.so.6
#1 0x00007fdfaf7768ee in bus_poll () from /usr/lib/systemd/libsystemd-shared-239.so
#2 0x00007fdfaf6a8f3d in bus_wait_for_jobs () from /usr/lib/systemd/libsystemd-shared-239.so
#3 0x000055b4c2d59b2e in start_unit ()
#4 0x00007fdfaf7457e3 in dispatch_verb () from /usr/lib/systemd/libsystemd-shared-239.so
#5 0x000055b4c2d4c2b4 in main ()
L'observation a révélé que start_unit est suspect. start_unit()La fonction se trouve dans le fichier exécutable. Elle est utilisée pour démarrer les unités systemd , ce qui n'est pas utile.
Sur la base des indices existants, nous pouvons émettre l’hypothèse suivante :
mysqld.pidSi le fichier existe, cela signifie qu'il y a bien eu un processus mysqld avec le numéro de processus31036démarré auparavant.kill -9Une fois le processus démarré, il se termine par le cas d'utilisation automatisé.- systemd a obtenu un exécution déjà terminée
MAIN PID, l'exécution post- shell a échoué et le processus fork a échoué.
En triant les étapes du processus de démarrage de systemd , nous pouvons spéculer sur les possibilités. L'instance MySQL ne générera des fichiers qu'après le démarrage réussi de mysqld , cela peut donc être dû à une terminaison accidentelle mysqld.pidlors des étapes suivantes .kill -9
Méthode de reproduction
Puisqu'il n'y a pas d'autres indices ou indices, j'ai l'intention d'essayer de le reproduire sur la base de la conclusion déduite.
4.1 Ajuster le modèle de service mysql systemd
Modifiez le fichier modèle /etc/systemd/system/mysqld_11690.servicequelques secondes après le démarrage de mysqld , sleep10afin de pouvoir simuler le scénario de suppression du processus d'instance dans cette fenêtre de temps.
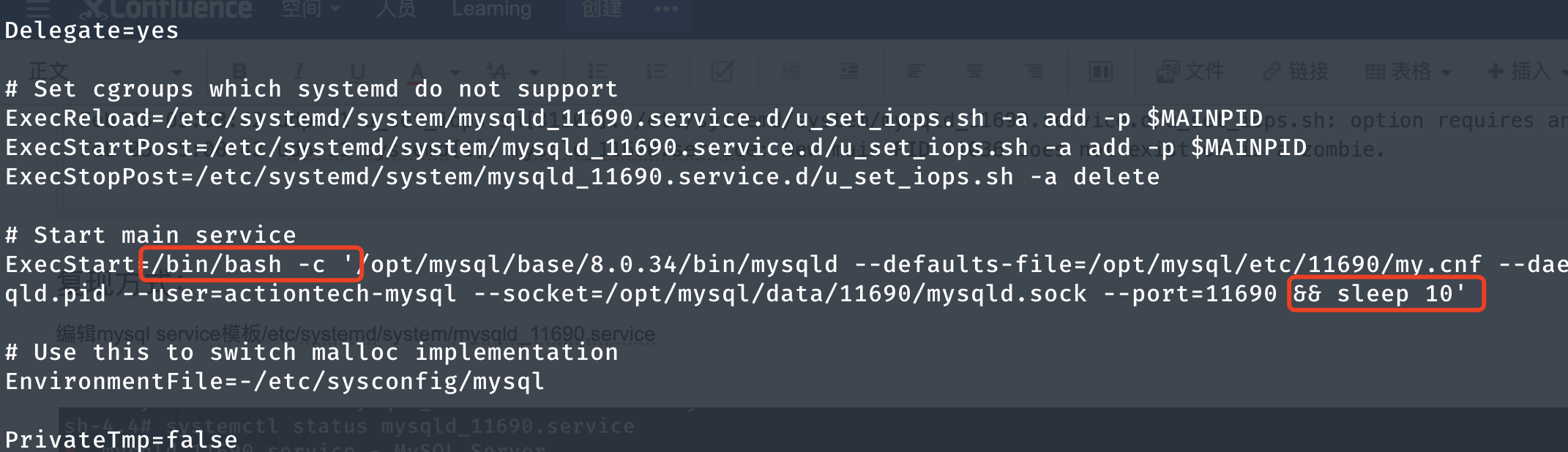
4.2 Rechargement de la configuration
Les ordres d’exécution systemctl daemon-reloadchangent pour prendre effet.
4.3 Reproduction de scène
- [session ssh A] Préparez d'abord un nouveau conteneur, effectuez les configurations pertinentes et exécutez pour
sudo -S systemctl start mysqld_11690.servicedémarrer un processus mysqld . À ce moment,sleepla session se bloquera pour des raisons. - [session ssh B] Dans une autre fenêtre de session,
startpendant que la commande hang est active, vérifiezmysqld.pidle fichier et exécutez-le immédiatement une fois le fichier créésudo -S kill -9 $(cat /opt/mysql/data/11690/mysqld.pid). - À ce stade, observez l'état de systemctl et les performances sont conformes aux attentes.

Solution
Tout d'abord, supprimez la commande systemctl startkill suspendue et exécutez-la . Cela permet à systemd de mettre activement fin au processus zombie. Bien que la commande puisse signaler une erreur, cela ne l'affecte pas.systemctl stop mysqld_11690.servicestop
Attendez la stopfin de l'exécution, puis utilisez startla commande pour recommencer et revenir à la normale.
Pour des articles plus techniques, veuillez visiter : https://opensource.actionsky.com/
À propos de SQLE
SQLE est une plateforme complète de gestion de la qualité SQL qui couvre l'audit et la gestion SQL, du développement aux environnements de production. Il prend en charge les bases de données open source, commerciales et nationales grand public, fournit des capacités d'automatisation des processus pour le développement, l'exploitation et la maintenance, améliore l'efficacité en ligne et améliore la qualité des données.
SQLE obtenir
| taper | adresse |
|---|---|
| Dépôt | https://github.com/actiontech/sqle |
| document | https://actiontech.github.io/sqle-docs/ |
| publier des nouvelles | https://github.com/actiontech/sqle/releases |
| Documentation de développement du plug-in d'audit des données | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |