
1. Origines
ZooKeeper (ZK) est un service de coordination d'applications distribuées né en 2007. Bien que pour des raisons historiques particulières, de nombreux scénarios économiques doivent encore s’appuyer sur elle. Par exemple, Kafka, la planification des tâches, etc. Surtout lorsque Flink mélangeait le déploiement et le découplage ETCD, le côté commercial exigeait une stabilité absolue et déconseillait fortement d'utiliser ZooKeeper auto-construit. Pour des raisons de stabilité, le MSE-ZK d'Alibaba est utilisé. Depuis son utilisation en septembre 2022, l'équipe technique de Dewu n'a rencontré aucun problème de stabilité, et la fiabilité SLA a en effet atteint 99,99 %.
En 2023, certaines entreprises ont utilisé des clusters ZooKeeper (ZK) auto-construits, puis ZK a connu plusieurs fluctuations au cours de son utilisation. Ensuite, Dewu SRE a commencé à reprendre certains clusters auto-construits et a effectué plusieurs séries de tentatives de renforcement de la stabilité. Au cours du processus de prise de contrôle, il a été découvert qu'après un certain temps d'exécution de ZooKeeper, l'utilisation de la mémoire continue d'augmenter, ce qui peut facilement entraîner des problèmes de manque de mémoire (MOO). L'équipe technique de Dewu était très curieuse de ce phénomène et a donc participé au processus d'exploration pour résoudre ce problème.
2. Exploration et analyse
2.1 Déterminer la direction
Lors du dépannage du problème, j'ai eu beaucoup de chance de trouver un site de panne dans un environnement de test. Deux nœuds du cluster se trouvaient dans un état périphérique de MOO.

Avec la scène de panne, il ne reste généralement que 50 % avant le point final réussi. La mémoire est élevée. D'après l'expérience passée, soit il ne s'agit pas d'un tas, soit il y a un problème dans le tas. Le graphique de flamme et jstat peuvent confirmer qu'il s'agit d'un problème dans le tas.

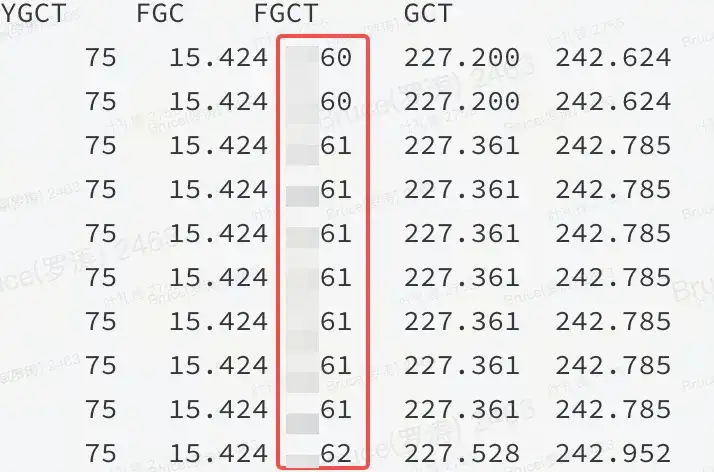
Comme le montre la figure : cela signifie qu'une certaine ressource dans le tas JVM occupe une grande quantité de mémoire et que FGC ne peut pas la libérer.
2.2 Analyse de la mémoire
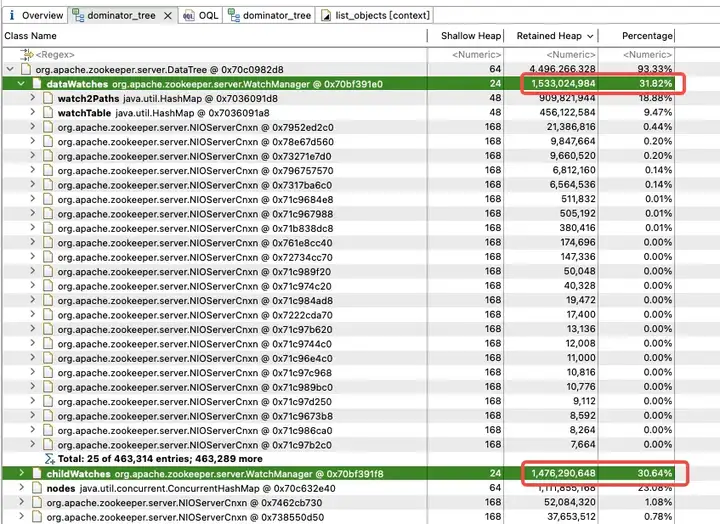
Afin d'explorer la répartition de l'utilisation de la mémoire dans le tas JVM, l'équipe technique de Dewu a immédiatement effectué un vidage du tas JVM. L'analyse a révélé que la mémoire JVM est fortement occupée par les childWatches et les dataWatches.
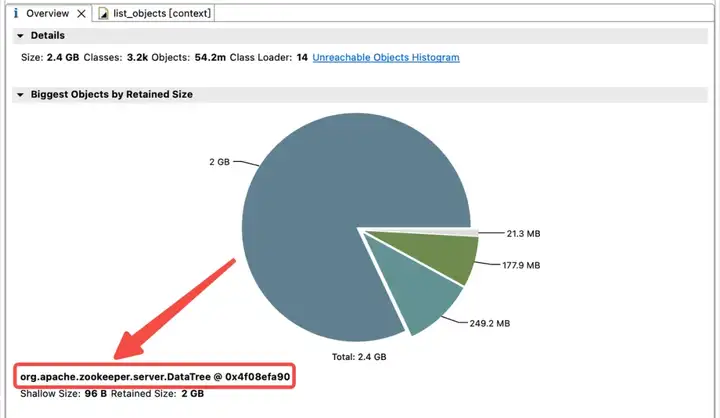
dataWatches : suivez les modifications dans les données du nœud znode.
childWatches : suivez les modifications dans la structure du nœud znode (arborescence).
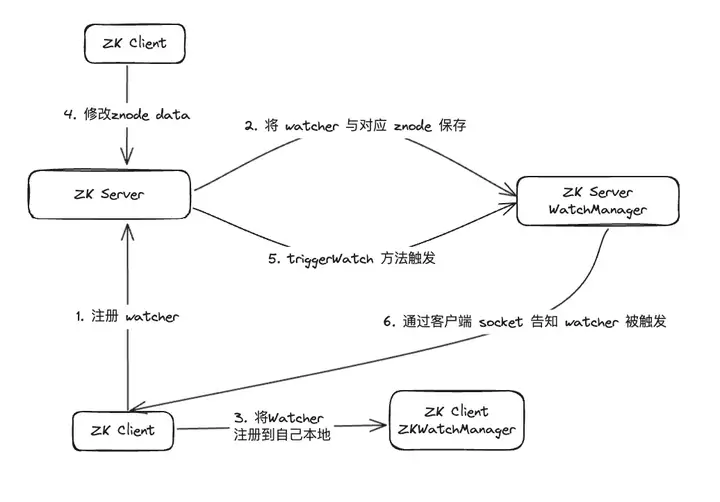
Les childWatches et dataWatches proviennent de WatcherManager.
Après enquête sur les données, il a été constaté que WatcherManager est principalement responsable de la gestion des Watchers. Le client ZooKeeper (ZK) enregistre d'abord les observateurs sur le serveur ZooKeeper, puis le serveur ZooKeeper utilise WatcherManager pour gérer tous les observateurs. Lorsque les données d'un Znode changent, WatchManager déclenchera le Watcher correspondant et communiquera avec le socket du client ZooKeeper abonné au Znode. Par la suite, le gestionnaire Watch du client déclenchera le rappel Watcher approprié pour exécuter la logique de traitement correspondante, complétant ainsi l'ensemble du processus de publication/abonnement des données.
Une analyse plus approfondie de WatchManager montre que le taux de mémoire des variables membres Watch2Path et WatchTables atteint (18,88+9,47)/31,82 = 90 %.
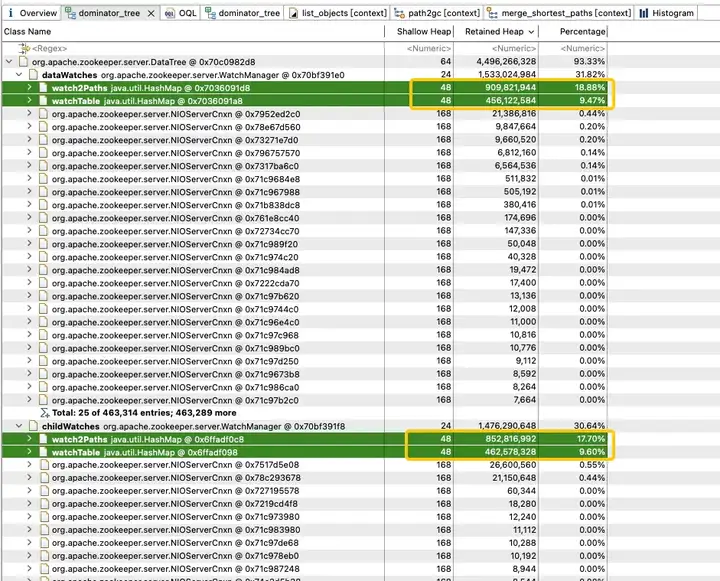
WatchTables et Watch2Path stockent la relation de mappage exacte entre ZNode et Watcher, comme indiqué dans le diagramme de structure de stockage :
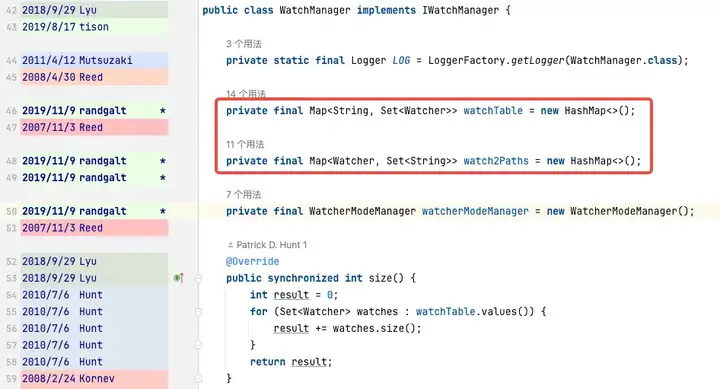
WatchTables [Forward Query Table] HashMap>
Scénario : lorsqu'un ZNode change, l'observateur abonné au ZNode recevra une notification.
Logique : utilisez ce ZNode pour rechercher toutes les listes d'observateurs correspondantes via WatchTables, puis envoyez des notifications une par une.
Watch2Paths [Reverse Query Table]
Scénario HashMap
: comptez les ZNodes auxquels un certain Watcher s'est abonné.
Logique : utilisez cet observateur pour trouver toutes les listes ZNode correspondantes via Watch2Paths.
Watcher est essentiellement NIOServerCnxn, qui peut être compris comme une session de connexion.
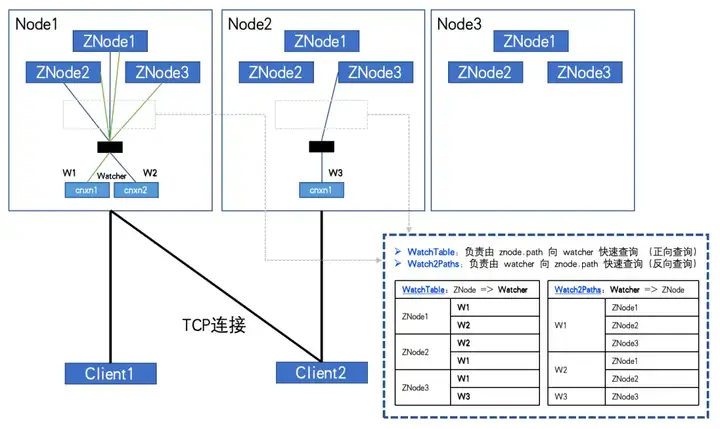
Si le nombre de ZNodes et de Watchers est relativement important et que le client s'abonne à plus de ZNodes, voire à un abonnement complet. La relation enregistrée dans ces deux tables de hachage va croître de façon exponentielle, et finira par atteindre un volume vertigineux !
Une fois entièrement souscrit, comme le montre la figure :
Lorsque le nombre de ZNodes : 3, le nombre de Watchers : 2, WatchTables et Watch2Paths auront chacun 6 relations.
Lorsque le nombre de ZNodes : 4, le nombre de Watchers : 3, WatchTables et Watch2Paths auront chacun 12 relations.
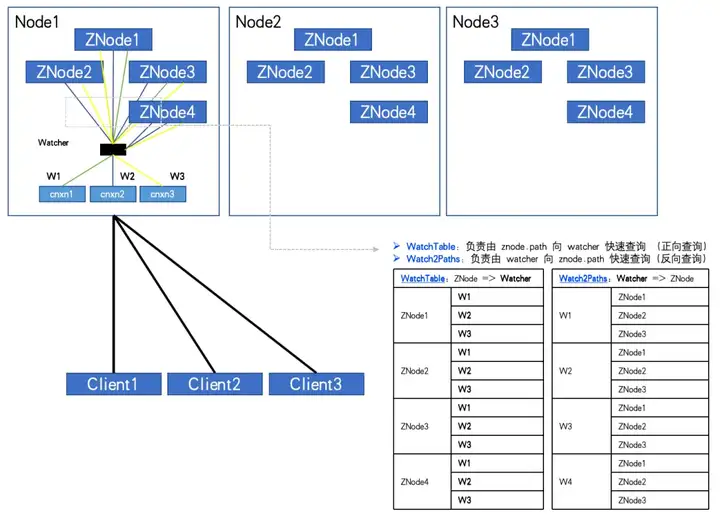
Un nœud ZK anormal a été découvert grâce à la surveillance. Le nombre de ZNodes est d’environ 20 W et le nombre d’observateurs est de 5 000. Le nombre de relations entre Watcher et ZNode a atteint 100 millions.
Si un HashMap&Node (32 octets) est nécessaire pour stocker chaque relation, puisqu'il existe deux tables de relations, doublez-le. Alors ne calculez rien d'autre. Ce "shell" nécessite à lui seul 2*10000^2*32/1024^3 = 5,9 Go de surcharge de mémoire non valide.
2.3 Découverte inattendue
D'après l'analyse ci-dessus, nous pouvons savoir qu'il est nécessaire d'éviter que le client ne s'abonne entièrement à tous les ZNodes. Cependant, la réalité est que de nombreux codes métier ont une telle logique pour parcourir tous les ZNodes à partir du nœud racine du ZTree et s'y abonner entièrement.
Il est peut-être possible de persuader certaines parties commerciales d’apporter des améliorations, mais on ne peut pas forcer à restreindre l’utilisation de toutes les parties commerciales. La solution à ce problème réside donc dans la surveillance et la prévention. Malheureusement, ZK lui-même ne prend pas en charge une telle fonction, ce qui nécessite une modification du code source de ZK.
Grâce au suivi et à l'analyse du code source, il a été constaté que la racine du problème pointait vers WatchManager, et les détails logiques de cette classe ont été soigneusement étudiés. Après une compréhension approfondie, j'ai découvert que la qualité de ce code semblait avoir été écrite par un récent diplômé, et qu'il y avait beaucoup d'utilisations inappropriées des threads et des verrous. En examinant les enregistrements Git, nous avons constaté que ce problème remontait à 2007. Cependant, ce qui est passionnant, c'est qu'au cours de cette période, WatchManagerOptimized (2018) est apparu. En recherchant les informations de la communauté ZK, [ZOOKEEPER-1177] a été découvert, c'est-à-dire qu'en 2011, la communauté ZK avait réalisé qu'un grand nombre de personnes étaient présentes. Les montres ont causé un problème d’empreinte mémoire et ont finalement apporté une solution en 2018. C'est précisément grâce à ce WatchManagerOptimized qu'il semble que la communauté ZK l'ait déjà optimisé.
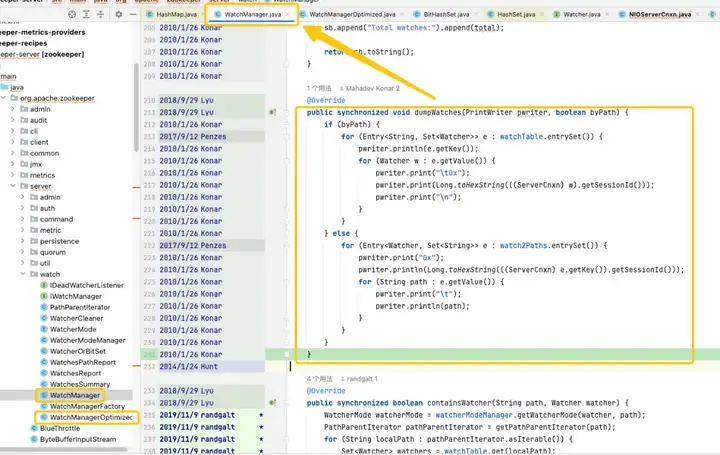
Fait intéressant, ZK n'active pas cette classe par défaut, même dans la dernière version 3.9.X, WatchManager est toujours utilisé par défaut. Peut-être parce que ZK est si vieux que les gens y prêtent progressivement moins d'attention. En interrogeant des collègues d'Alibaba, il a été confirmé que MSE-ZK permettait également WatchManagerOptimized, ce qui a en outre confirmé que l'équipe technique de Dewu se concentrait dans la bonne direction.
2.4 Exploration des optimisations
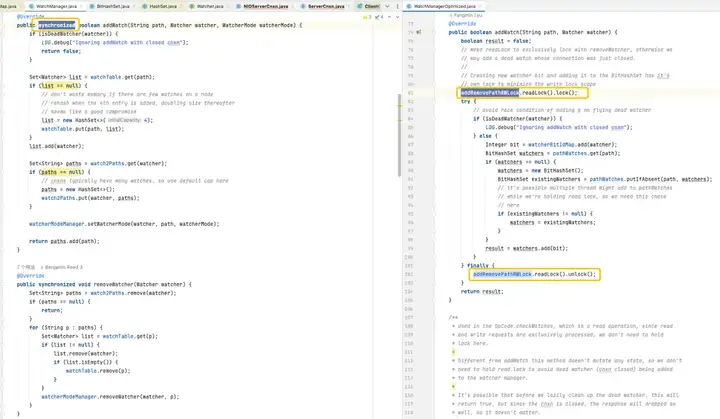
Optimisation du verrouillage
Dans la version par défaut, le HashSet utilisé est thread-unsafe. Dans cette version, les méthodes de fonctionnement associées telles que addWatch, removeWatcher et triggerWatch sont toutes implémentées en ajoutant des verrous lourds synchronisés aux méthodes. Dans la version optimisée, une combinaison de ConcurrentHashMap et ReadWriteLock est utilisée pour utiliser le mécanisme de verrouillage de manière plus raffinée. De cette manière, des opérations plus efficaces peuvent être réalisées pendant le processus d’ajout de Watch et de déclenchement de Watch.
Optimisation du stockage
C’est l’objectif. D'après l'analyse de WatchManager, nous pouvons voir que l'efficacité de stockage de l'utilisation de WatchTables et Watch2Paths n'est pas élevée. Si ZNode a de nombreuses relations d'abonnement, une grande quantité de mémoire non valide supplémentaire sera consommée.
Étonnamment, WatchManagerOptimized utilise ici la "technologie noire" -> bitmap.
Le stockage relationnel est fortement compressé à l'aide de bitmaps pour obtenir une optimisation de la réduction de dimensionnalité.
Principales fonctionnalités de Java BitSet :
- Efficacité spatiale : BitSet utilise des tableaux de bits pour stocker les données, nécessitant moins d'espace que les tableaux booléens standard.
- Traitement rapide : l'exécution d'opérations au niveau du bit (telles que AND, OR, XOR, retournement) est souvent plus rapide que les opérations logiques booléennes correspondantes.
- Expansion dynamique : la taille d'un BitSet peut augmenter dynamiquement selon les besoins pour accueillir plus de bits.
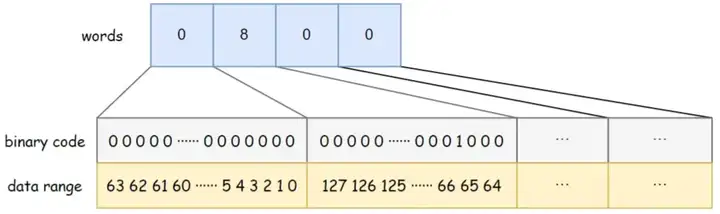
BitSet utilise des mots long[] pour stocker les données. Le type long occupe 8 octets et fait 64 bits . Chaque élément du tableau peut stocker 64 éléments de données. L'ordre de stockage des données dans le tableau est de gauche à droite, de bas en haut. Par exemple, la capacité en mots du BitSet dans la figure ci-dessous est de 4, les mots [0] de bas en haut indiquent si les données 0 à 63 existent, les mots [1] de bas en haut indiquent si les données 64 à 127 existent, et ainsi sur. Parmi eux, mots[1] = 8, et le bit binaire correspondant 8 est 1, indiquant qu'il existe une donnée {67} stockée dans le BitSet à ce moment.
WatchManagerOptimized utilise BitMap pour stocker tous les Watchers. De cette façon, même s'il y a un Watcher 1W. La consommation de mémoire du bitmap n'est que de 8Byte*1W/64/1024= 1.2KB . S'il est remplacé par HashSet, au moins 32 octets * 10 000/1 024 = 305 Ko sont requis et l'efficacité du stockage est près de 300 fois différente.
WatchManager.java:
private final Map<String, Set<Watcher>> watchTable = new HashMap<>();
private final Map<Watcher, Set<String>> watch2Paths = new HashMap<>();
WatchManagerOptimized.java:
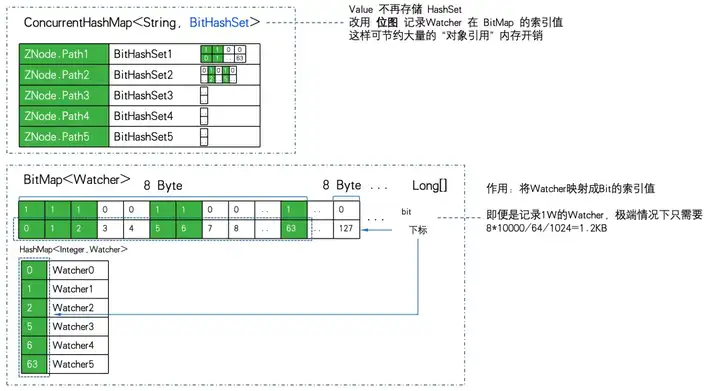
private final ConcurrentHashMap<String, BitHashSet> pathWatches = new ConcurrentHashMap<String, BitHashSet>();
private final BitMap<Watcher> watcherBitIdMap = new BitMap<Watcher>();Le stockage de mappage de ZNode vers Watcher passe de Map à ConcurrentHashMapBitHashSet>. C'est-à-dire que l'ensemble n'est plus stocké, mais le bitmap est utilisé pour stocker la valeur de l'index bitmap.
Utilisez 1W ZNode, 1W Watcher, et allez jusqu'au point extrême de l'abonnement complet (tous les Watchers s'abonnent à tous les ZNodes) pour améliorer l'efficacité du stockage PK :

Vous pouvez voir que 11,7 Mo PK 5,9 Go , la différence d'efficacité du stockage mémoire est : 516 fois .
Optimisation logique
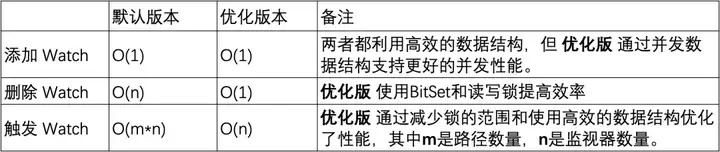
Ajout d'un moniteur : les deux versions sont capables d'effectuer des opérations en temps constant, mais la version optimisée offre de meilleures performances de concurrence en utilisant ConcurrentHashMap .
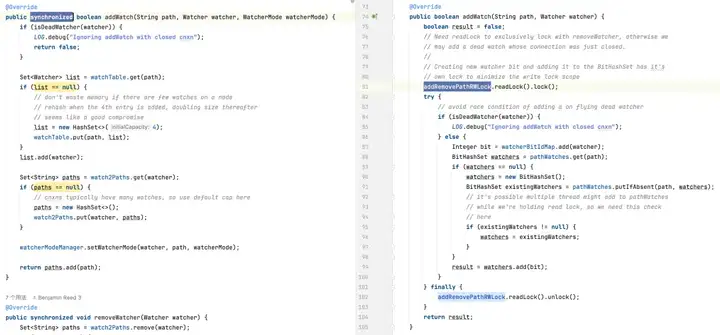
Suppression d'un moniteur : la version par défaut peut devoir parcourir l'intégralité de la collection de moniteurs pour rechercher et supprimer le moniteur, ce qui entraîne une complexité temporelle de O(n). La version optimisée utilise BitSet et ConcurrentHashMap pour localiser et supprimer rapidement les moniteurs en O(1) dans la plupart des cas.
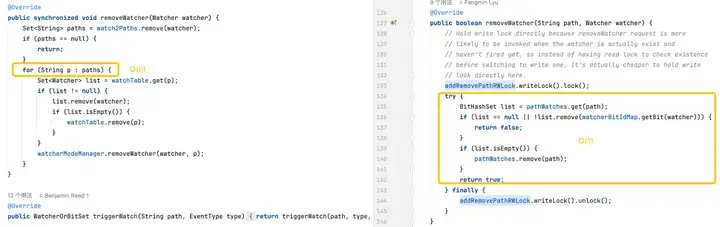
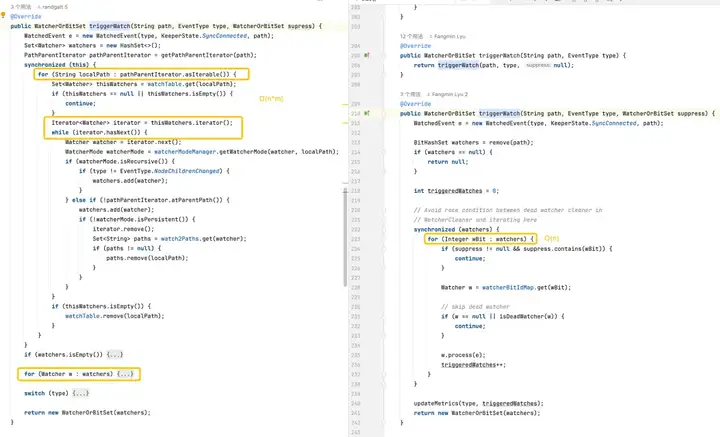
Déclenchement des moniteurs : la version par défaut est plus complexe car elle nécessite des opérations sur chaque moniteur sur chaque chemin. La version optimisée optimise les performances des moniteurs de déclenchement grâce à des structures de données plus efficaces et une utilisation réduite du verrouillage.
3. Test de résistance des performances
3.1 Microbenchmark JMH
Compilation du code source de ZooKeeper 3.6.4, test de résistance JMH micror WatchBench.
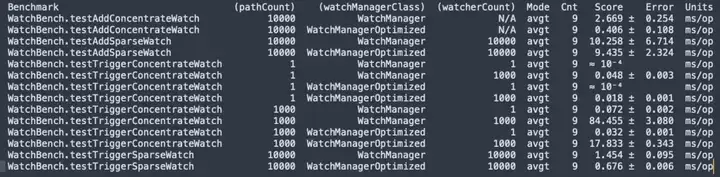
pathCount : indique le nombre de chemins ZNode utilisés dans le test. watchManagerClass : représente la classe d'implémentation WatchManager utilisée dans le test.
watcherCount : Indique le nombre d'observateurs (Watchers) utilisés dans le test.
Mode : Indique le mode de test, ici avgt, qui indique la durée moyenne d'exécution.
Cnt : indique le nombre d’exécutions de tests.
Score : Indique le score du test, c'est-à-dire la durée moyenne d'exécution.
Erreur : indique la plage d'erreur du score.
Unités : L'unité représentant le score, ici est les millisecondes/opération (ms/op).
- Il y a 1 million d'abonnements entre ZNode et Watcher. La version par défaut utilise 50 Mo, et la version optimisée ne nécessite que 0,2 Mo, et cela n'augmentera pas linéairement.
- En ajoutant Watch, la version optimisée (0,406 ms/op) est 6,5 fois plus rapide que la version par défaut (2,669 ms/op).
- Un grand nombre de Watch sont déclenchées, et la version optimisée (17,833 ms/op) est 5 fois plus rapide que la version par défaut (84,455 ms/op).
3.2 Test de résistance des performances
Ensuite, un ensemble de ZooKeeper 3.6.4 à 3 nœuds a été construit sur une machine (32C 60G) et la version optimisée et la version par défaut ont été utilisées pour la comparaison des tests de résistance de capacité.
Scénario 1 : chemin court du nœud znode 20 W
Chemin court de Znode : /demo/znode1

Scénario 2 : chemin long du nœud znode 20 W
Chemin long du nœud Z : /sentinel-cluster/dev/xx-admin-interfaces/lock/_c_bb0832d5-67a5-48ab-8fe0-040b9ddea-lock/12

- L'utilisation de la mémoire de surveillance est liée à la longueur du chemin du ZNode.
- Le nombre de montres augmente linéairement dans la version par défaut et fonctionne très bien dans la version optimisée, ce qui constitue une amélioration très évidente pour l'optimisation de l'utilisation de la mémoire.
3.3 Test en niveaux de gris
Sur la base du test de référence et du test de capacité précédents, la version optimisée présente une optimisation évidente de la mémoire dans un grand nombre de scénarios Watch. Ensuite, nous avons commencé à effectuer des observations de tests de mise à niveau en niveaux de gris sur le cluster ZK dans l'environnement de test.
Le premier cluster ZooKeeper et ses avantages
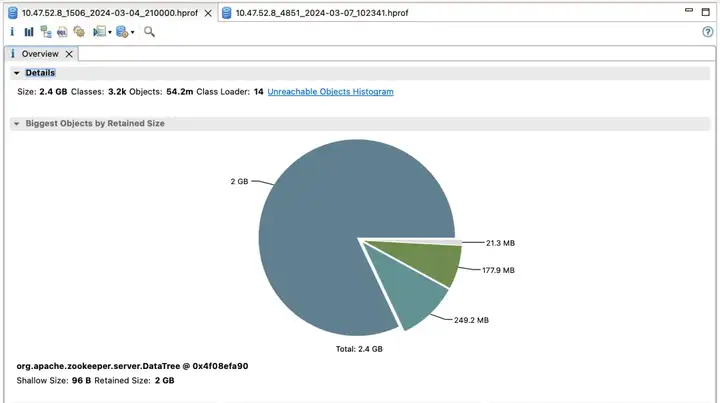
Version par défaut
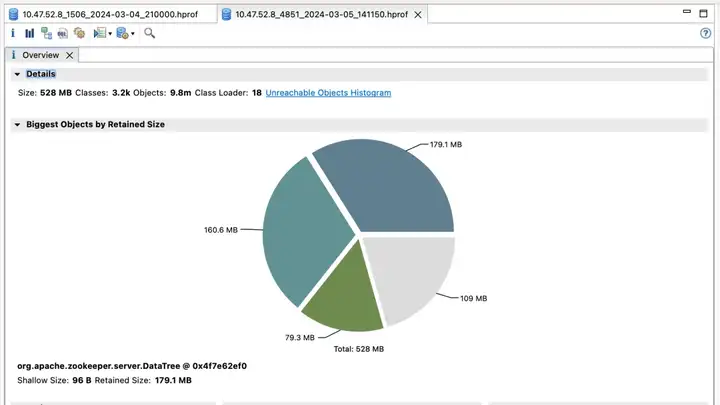
Version optimisée


Revenu d'effet :
- Election_time (heure des élections) : réduit de 60 %
- fsync_time (temps de synchronisation des transactions) : réduit de 75 %
- Utilisation de la mémoire : réduite de 91 %
Deuxième cluster ZooKeeper et avantages
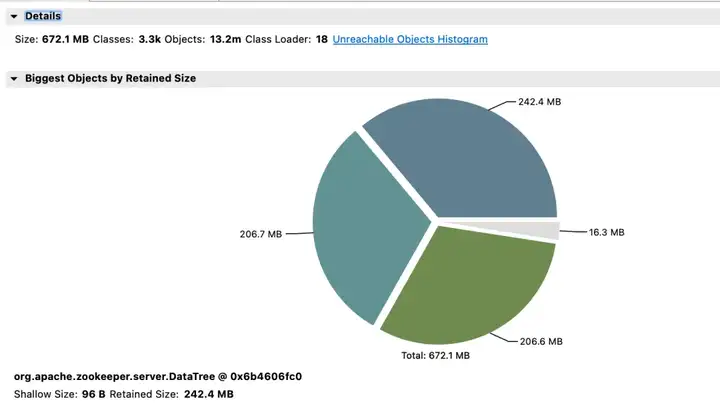
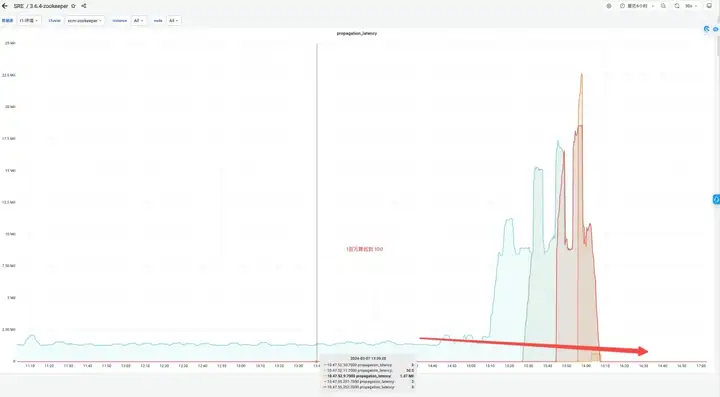


Revenu d'effet :
- Mémoire : avant la modification, la réponse JVM Attach ne parvenait pas à répondre et la collecte de données échouait.
- Election_time (heure des élections) : réduit de 64 %.
- max_latency (latence de lecture) : réduite de 53%.
- proposition_latence (délai de proposition de traitement des élections) : 1400000 ms --> 43 ms.
- propagation_latency (délai de propagation des données) : 1400000 ms --> 43 ms.
Le troisième ensemble de clusters ZooKeeper et ses avantages
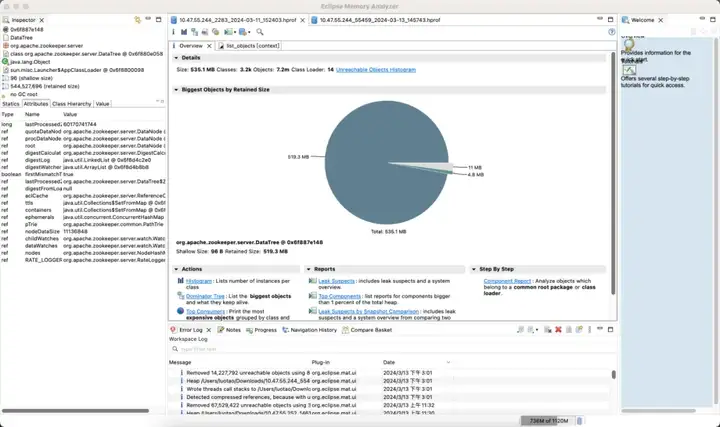
Version par défaut
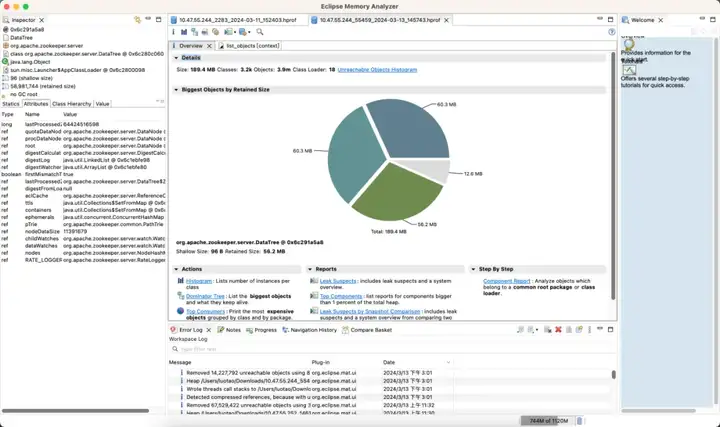
Version optimisée
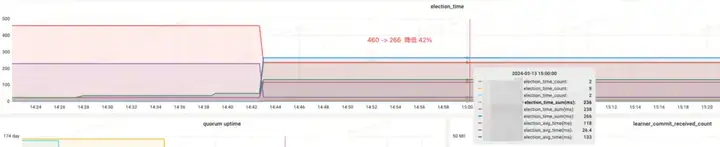

Revenu d'effet :
- Mémoire : économisez 89 %
- Election_time (heure des élections) : réduit de 42 %
- max_latency (latence de lecture) : réduite de 95 %
- proposition_latence (délai de proposition de traitement des élections) : 679999 ms --> 0,3 ms
- propagation_latency (délai de propagation des données) : 928 000 ms -> 5 ms
4. Résumé
Grâce à des tests de référence précédents, des tests de résistance aux performances et des tests en niveaux de gris, WatchManagerOptimized de ZooKeeper a été découvert. Cette optimisation permet non seulement d'économiser de la mémoire, mais améliore également considérablement les indicateurs tels que l'élection et la synchronisation des données entre les nœuds grâce à l'optimisation des verrouillages, améliorant ainsi la cohérence de ZooKeeper. Nous avons également eu des échanges approfondis avec des étudiants d'Alibaba MSE, chacun simulant des stress tests dans des scénarios extrêmes, et sommes parvenus à un consensus : WatchManagerOptimized améliore considérablement la stabilité de ZooKeeper. Dans l'ensemble, cette optimisation améliore le SLA de ZooKeeper d'un ordre de grandeur.
ZooKeeper propose de nombreuses options de configuration, mais dans la plupart des cas, aucune modification n'est requise. Pour améliorer la stabilité du système, il est recommandé d'effectuer les optimisations de configuration suivantes :
- Montez dataDir (répertoire de données) et dataLogDir (répertoire des journaux de transactions) respectivement sur des disques différents et utilisez un stockage par blocs hautes performances.
- Pour ZooKeeper version 3.8, il est recommandé d'utiliser le JDK 17 et d'activer le garbage collector ZGC ; pour les versions 3.5 et 3.6, il est recommandé d'utiliser le JDK 8 et d'activer le garbage collector G1. Pour ces versions, configurez simplement -Xms et -Xmx.
- Ajustez la valeur par défaut du paramètre SnapshotCount de 100 000 à 500 000, ce qui peut réduire considérablement la pression du disque lorsque le ZNode change à haute fréquence.
- Utilisez la version optimisée de Watch Manager WatchManagerOptimized.
Cet article est un contenu original d'Alibaba Cloud et ne peut être reproduit sans autorisation.
Les lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : S'appuyant sur la défense, Apple a publié la puce M4 RustDesk. Les services nationaux ont été suspendus en raison d'une fraude généralisée. À l'avenir, il envisage de produire un jeu indépendant sur la plateforme Windows Taobao (taobao.com) Redémarrer le travail d'optimisation de la version Web, destination des programmeurs, Visual Studio Code 1.89 publie Java 17, la version Java LTS la plus couramment utilisée, Windows 10 a un part de marché de 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais ; l'anxiété et les ambitions de Microsoft ont fermé la plate-forme ouverte ;