
Auteur : équipe Vivo Internet Big Data - Huang Guihu, Chen Shengzun
HBase est une base de données non relationnelle distribuée open source avec une fiabilité élevée, une évolutivité élevée et des performances élevées. Elle est largement utilisée dans le traitement du Big Data, l'informatique en temps réel, le stockage et la récupération de données et d'autres domaines. Dans un cluster distribué, une panne matérielle est un phénomène courant. Une panne matérielle peut entraîner une interruption du service au niveau du nœud ou du cluster, des dommages aux tables méta, des trous RIT, des régions, des chevauchements et d'autres problèmes. particulièrement important.Cet article porte principalement sur la description des échecs courants et des solutions correspondantes autour des méta-tables HBase.
1. Origines
Je crois que les amis qui ont effectué des travaux liés au développement, à l'exploitation et à la maintenance de HBase ont ce sentiment dans une certaine mesure. HBase, en tant que leader des bases de données non relationnelles distribuées, est non seulement stable, performant et très simple à installer et à développer. , mais il manque aussi Les systèmes de surveillance matures sont extrêmement peu conviviaux pour le dépannage. Si vous n'avez pas une compréhension complète de HBase, vous ne pourrez souvent pas faire face aux échecs quotidiens. En tant qu'éditeurs, nous avons exploité et maintenu plus de 20 clusters HBase de différentes tailles impliquant les versions 1.x~2.x. Nous avons connu une corruption des méta-tables et un échec de mise en ligne normale, des chevauchements de régions, nous avons été confrontés à des problèmes en ligne tels que des trous de région et des autorisations perdues, et nous avons également recherché les réponses correctes dans le code source HBase avec divers problèmes. solution commune à la méta-table que les éditeurs ont résumée à partir de nombreux échecs.
2. Tableau de méta-informations HBase
La méta-table HBase, également connue sous le nom de table de catalogue, est une table HBase spéciale qui stocke toutes les régions du cluster HBase et leurs informations RegionServer correspondantes. L'exactitude des données de la table de méta-informations est cruciale pour le fonctionnement normal du cluster HBase. il faut donc s'assurer que des données correctes dans la table de métainformations sont une condition nécessaire au fonctionnement stable du cluster. Si les données de la méta-table sont incohérentes, cela entraînera un RIT (Region In Transition) ou même le cluster ne pourra pas démarrer normalement car HMaster ne peut pas être initialisé normalement. Cela montre l'importance de la méta-table dans le cluster HBase. la structure de la méta-table, le format des données, démarrez le processus pour l'analyser (cet article se concentre principalement sur la version HBase 2.4.8 et intercalera également la version HBase 1.x).
2.1 Structure de la méta-table
La méta-table comprend principalement trois familles de colonnes : info, table et rep_barrier, qui enregistrent respectivement les informations sur la région et l'état de la table :
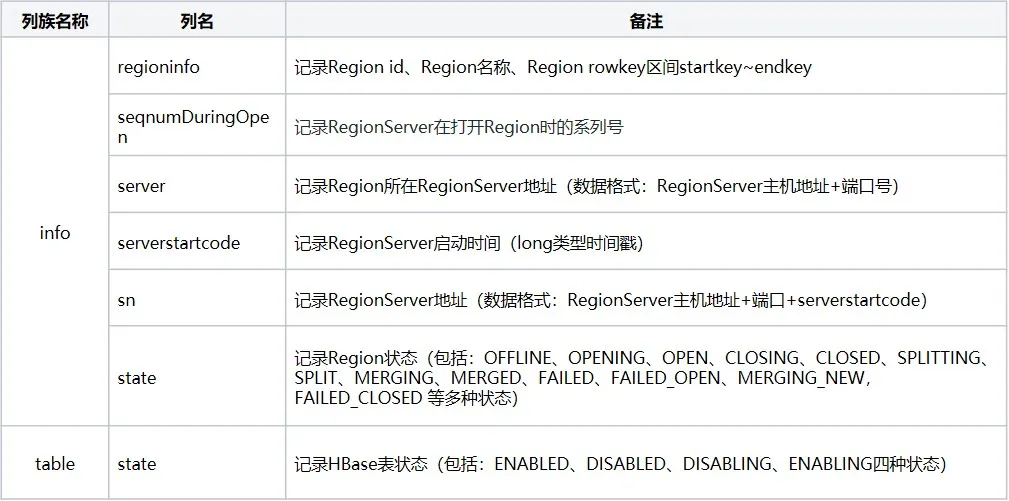
2.2 Processus de chargement de la méta-table
Grâce à la structure de la méta-table ci-dessus, nous avons une compréhension globale de la table.Les amis qui ont effectué l'exploitation et la maintenance de HBase pensent qu'ils ont tous cette expérience. Certains clusters démarrent plus rapidement, certains clusters démarrent plus lentement et parfois même le cluster redémarre à cause de cela. opération incorrecte. Il est resté bloqué lors du chargement de la méta-table et ne peut pas continuer à exécuter les processus suivants. Si nous avons une compréhension globale du processus de chargement des méta-tables, nous aurons une attente plus ou moins psychologique pour chaque heure de démarrage du cluster. Voici le processus lié au chargement des méta-tables :
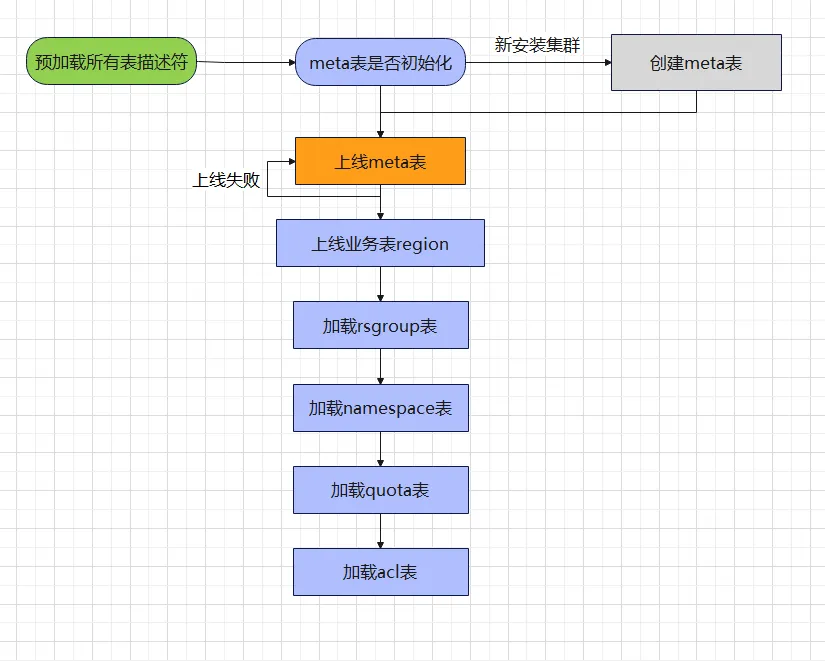
Grâce à l'organigramme de chargement des méta-tables ci-dessus, nous pouvons facilement découvrir pourquoi certains clusters démarrent lentement et certains clusters ne démarrent pas. Ci-dessous, nous analysons deux types de scénarios :
- Le cluster démarre lentement :
Habituellement, les nouveaux clusters ou les clusters avec moins de tables ont tendance à démarrer plus rapidement, tandis que les clusters avec plus de tables ont tendance à démarrer beaucoup plus lentement. Certains clusters mettent même 15 à 30 minutes pour démarrer HMaster. Parfois, le temps de démarrage du cluster est long, ce qui rend les gens méfiants. Il y a un problème avec le cluster ? Pourquoi ne peut-il pas entrer dans un état normal pendant si longtemps ? Il y a deux endroits qui prennent beaucoup de temps dans tout le processus de chargement.
Précharger tous les descripteurs de table : vous devez analyser l'intégralité du répertoire de données HBase, analyser les fichiers de données sous le répertoire .tabledesc et les stocker dans la mémoire HMaster. S'il existe un grand nombre de tables (plus de 10 000 tables), ce processus est souvent effectué. Cela prend environ dix minutes. Lorsque nous voyons les mots « Descripteurs de table de pré-chargement » apparaître sur la page HMaster, cela signifie que le cluster est en phase de préchargement. Il suffit d'attendre patiemment, car la phase de chargement de la méta-table n'est pas encore terminée. atteint.
Région de la table commerciale en ligne : La taille des données de la méta-table est généralement comprise entre des dizaines de Mo et des centaines de Mo. Le temps d'ouverture de la région est relativement rapide (secondes). Lors de la phase de démarrage du cluster, la région hors ligne doit être vérifiée et en ligne. Si vous souhaitez accélérer la vitesse d'ouverture, vous pouvez ajuster la valeur hbase de manière appropriée.
- Échec du démarrage du cluster :
Échec en ligne de la table méta : lorsque le HRegionServer du groupe de ressources par défaut raccroche et que le code de démarrage de la machine change après le redémarrage, la partition de métadonnées ne peut pas trouver le nœud ouvert, ce qui entraîne l'échec du démarrage du cluster.
3. Comment réparer la méta-table
Étant donné que l'état du cluster HBase est principalement maintenu via la méta-table, si la méta-table est endommagée ou erronée, le cluster HBase deviendra indisponible et fera face à un risque de perte de données. Nous savons que la cohérence des données des métatables est très importante, alors dans quelles circonstances une incohérence des données se produira-t-elle ? (Pour les commandes de réparation HBase 2.4.8, reportez-vous à l'outil hbase-operator-tools).
-
RegionServer est en panne ou anormal : lorsque RegionServer est en panne ou anormale, les informations de région et de RegionServer stockées dans la méta-table peuvent être incorrectes ou perdues.
-
Corruption ou erreurs de données : Lorsque les données de la méta-table sont corrompues ou incorrectes, cela peut entraîner une indisponibilité du cluster HBase et une perte de données.
-
Opérations illégales : lorsque des opérations illégales sont effectuées sur la méta-table, telles que la suppression ou la modification de données dans la méta-table, cela peut entraîner des erreurs ou la perte de la méta-table.
L'échec de la méta-table n'est qu'un terme général. Nous pouvons le diviser grossièrement en RIT à long terme, trou de région, chevauchement de région, perte de fichier de description de table, chemin hdfs de méta-table vide, perte de données de méta-table, etc. Je vais en discuter respectivement. Ces types de défauts sont analysés et corrigés :
3.1 RIT
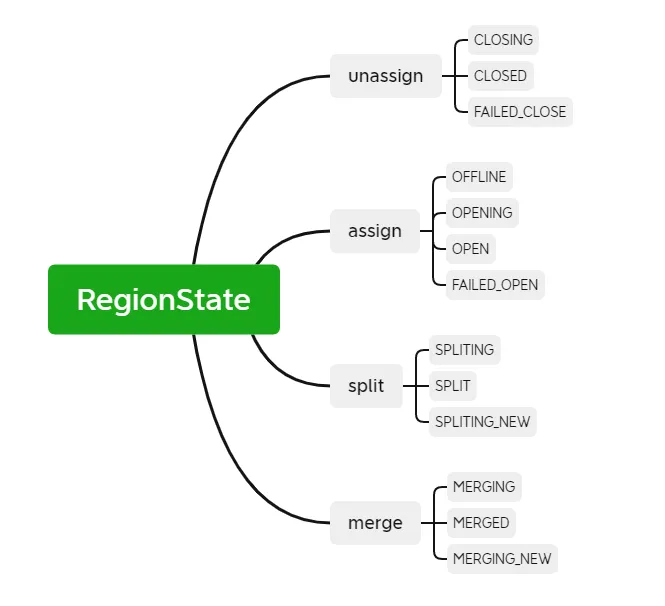
RIT (Region In Transition) fait référence à la transition d'état en cours dans le cluster HBase. Les opérations suivantes entraîneront une modification de l'état de la région dans le cluster HBase. Par exemple, le RegionServer est en panne, la région est divisée, fusionnée et. Autres opérations. L'état de la région comprend principalement les douze états et diagrammes de transformation suivants :
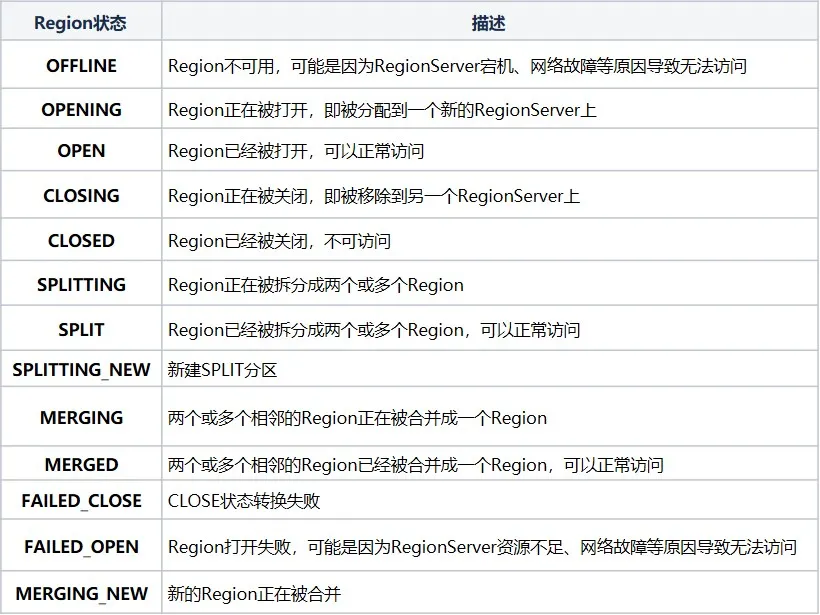
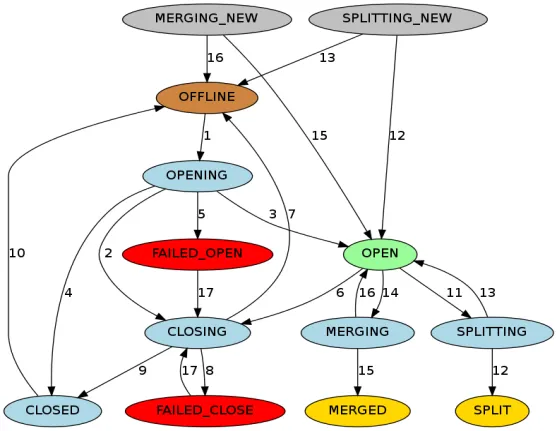
Afin d'être plus clair sur l'état de la région, nous pouvons le diviser en assignation, désattribution, division et fusion en fonction du type d'opération. Si le RegionServer est en panne ou anormal, si des données sont endommagées ou si des erreurs se produisent pendant l'opération, RIT le fera. Bien que RIT soit souvent rencontré dans les problèmes de fonctionnement et de maintenance de HBase, si la logique sous-jacente est claire, il sera plus facile de résoudre les problèmes de RIT. La plupart des cas peuvent être restaurés normalement sans intervention manuelle. l'intervention n'est requise que lorsque la RIT se produit pendant une longue période. Alors, quelle est la durée d'une RIT à long terme ? Pourquoi une RIT à long terme se produit-elle ?
Si vous avez utilisé les versions HBase 1.x et HBase 2.x, vous aurez évidemment l'impression que RIT est moins courant dans HBase 2.x. En fait, le fonctionnement de la région consiste principalement à transférer la région via la classe AssignmentManager Comparing. Dans les codes des deux versions, nous avons constaté que hbase.assignment.maximum. La valeur par défaut du paramètre tentatives (nombre de tentatives d'affectation) est différente dans les deux versions. Le nombre de tentatives dans HBase 2.4.8 est l'entier maximum. .MAX_VALUE (alors que la valeur par défaut est 10 dans HBase 1.x). C'est pourquoi dans HBase, les raisons d'un RIT à long terme sont relativement rares dans 2.x.
Méthode de traitement RIT :
-
RIT se produira lors de la création ou de la suppression de tables volumineuses. Cela est principalement dû au grand nombre de régions et à la forte pression sur le cluster, ce qui entraîne des temps de réponse d'attribution et de désattribution longs. Pour ce type de problème, HBase ne nécessite généralement pas de manuel. intervention et peut se guérir.
-
Si la version du cluster est 1.x, vous pouvez ajuster de manière appropriée la valeur hbase.assignment.maximum.attempts pour augmenter le nombre de tentatives. Par exemple, FAILED_OPEN et FAILED_CLOSE peuvent généralement s'auto-réparer ou exécuter manuellement la commande assign pour les attribuer. Région en ligne (s'il y a plusieurs régions, passez à la réparation HMaster).
-
Si l'allocation de région échoue et qu'il n'y a pas de RegionServer, l'affectation manuelle ne peut pas être restaurée. Par exemple, la région est attribuée à bogus.example.com et les nœuds 1 et 1 ne peuvent être restaurés qu'en changeant de HMaster.
Questions à réfléchir :
Pourquoi la région ne peut-elle pas se connecter normalement même après une intervention manuelle et peut-elle être restaurée en changeant de HMaster ? (Reportez-vous au processus de démarrage HMaster TransitRegionStateProcedure, code source de la classe HMaster)
3.2 Trou de région
Lorsque nous créons une table HBase, si nous analysons attentivement les règles de région, nous serons surpris de constater que les touches de début et de fin de région appartiennent à des intervalles continus qui sont fermés à gauche et ouverts à droite. Quels problèmes se produiront si soudainement un. de ces intervalles est manquant (comme indiqué ci-dessous) ?
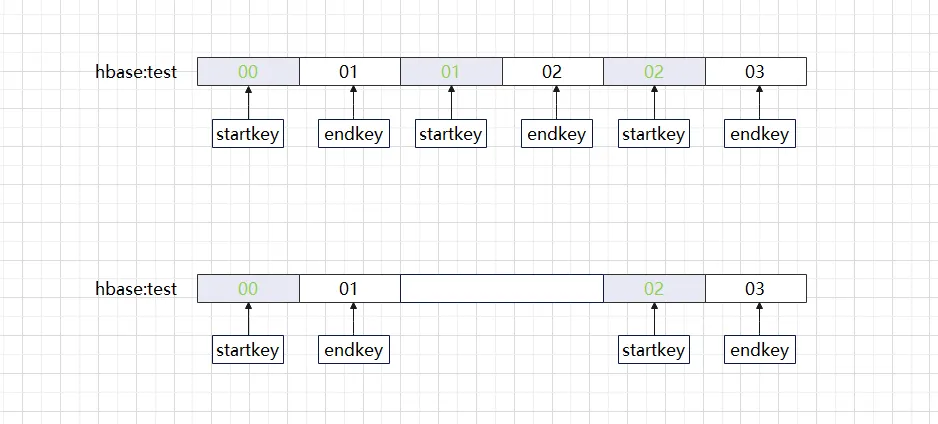
La situation ci-dessus est ce que nous appelons souvent un trou dans la région. Si vous utilisez l'outil HBase hbck pour vérifier, vous verrez le message d'erreur ERREUR : il y a un trou dans la chaîne de région entre 01 et 02. Vous devez créer un trou dans la région. nouveau .regioninfo et répertoire de région dans hdfs pour boucher le trou. Lorsqu'un trou apparaît dans un cluster HBase, il ne peut souvent pas se guérir et nécessite une intervention manuelle pour revenir à la normale, n'est-ce pas. cela suffira-t-il si nous remplissons simplement la région dans l'intervalle vide ? L'approche normale consiste à rajouter d'abord la région vide, à vérifier si les informations de la méta-table sont correctes et enfin à se connecter avec la région. Si cette série d'opérations est effectuée manuellement, elle sera non seulement sujette aux erreurs, mais prendra également du temps. Longtemps.Voici les différentes versions de la méthode de réparation HBase, en fait, bien que les méthodes de traitement des différentes versions soient légèrement différentes, le processus de traitement est le même.
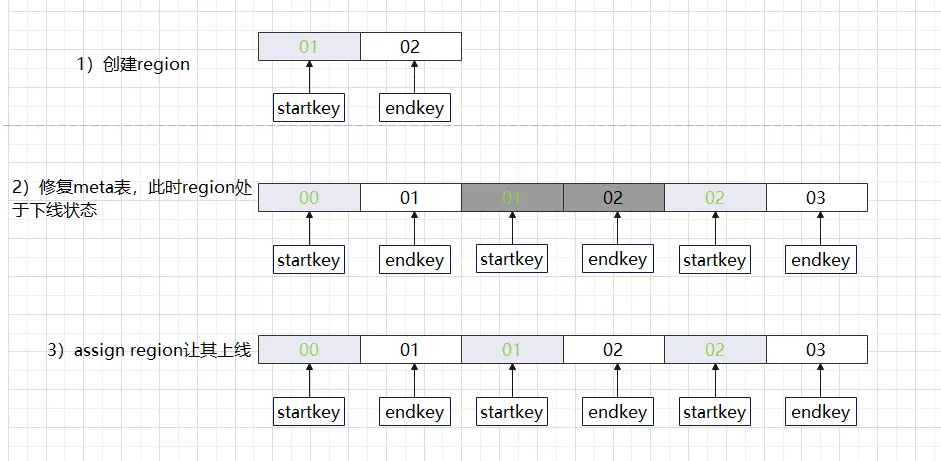
Méthode de traitement des trous de région :
(1) Méthode de réparation HBase 1.x
-
HBase hbck –fixHdfsHoles : Créer un chemin de fichier de région vide sur hdfs
-
HBase hbck -fixMeta : Réparer les données de la méta-table où se trouve la région
-
HBase hbck –fixAssignments : Région après réparation en ligne
-
Ou HBase hbck –repairHoles est équivalent à une combinaison de (fixHdfsHoles, fixMeta, fixAssignments)
(2) Méthode de réparation HBase 2.4.8 (voir l'outil hbase-operator-tools plus tard)
Puisque HBase 2.4.8 ne fournit pas de commandes pertinentes pour ajouter des opérations de répertoire de régions, cela est relativement gênant. En fait, de nombreuses classes d'outils dans HBase 2.4.8 fournissent des méthodes pour créer des régions, ainsi que la classe HBaseTestingUtility dans hbase-server-2.4. Le package de 8 tests les fournit. Afin d'opérer l'entrée liée à la Région, notre solution ci-dessous se concentre principalement sur la récupération basée sur cette méthode.
-
extraRegionsInMeta -fix : Supprimez d'abord les enregistrements qui n'existent pas dans le répertoire hdfs de la méta-table.
-
HBaseTestingUtility.createLocalHRegion : Créer un chemin de fichier hdfs pour assurer la continuité de la région
-
addFsRegionsMissingInMeta : ajoute de nouvelles informations sur la région à la méta-table (l'identifiant de la région sera renvoyé une fois l'ajout réussi)
-
assigns : Enfin, mettez en ligne la région nouvellement ajoutée
3.3 Chevauchement des régions
Puisqu'il y aura des trous dans la région, cela se produira-t-il ? Y aura-t-il plusieurs clés de début et de fin identiques ? La réponse est oui. Si les clés de début et de fin de plusieurs régions sont la même région, nous appelons cette situation des régions superposées. Le chevauchement des régions est difficile à simuler dans HBase et constitue également un problème difficile à gérer. Si nous effectuons une vérification hbck et que ce type de journal apparaît ERREUR : plusieurs régions ont la même clé de démarrage : 02

Un autre type de région superposée croise la plage de touches de ligne d'un ou deux fragments adjacents. Ce type de problème est collectivement appelé problème de chevauchement. Pour ce scénario plus difficile, nous utilisons des outils développés par nous-mêmes pour simuler la récurrence du problème de chevauchement et le réparer. les problèmes de chevauchement en un seul clic (pliage) et de trou (trou).
fonction de simulation de problèmes de chevauchement
Le problème du chevauchement des régions est en fait deux régions différentes. Les plages de touches de ligne se chevauchent. Par exemple, les touches de début et de fin de Région01 sont (01,03), et la plage d'une autre Région02 est (01,02). les deux régions se croisent ( 01,02), la détection hbck signalera un problème de chevauchement.
Dans l'environnement de production, le problème de chevauchement ne se produira que lorsque la région est divisée et que la machine raccroche en même temps. Les conditions sont relativement difficiles et il est difficile de reproduire le problème. réparations et forages de défauts. Le problème du chevauchement Principe de reproduction :
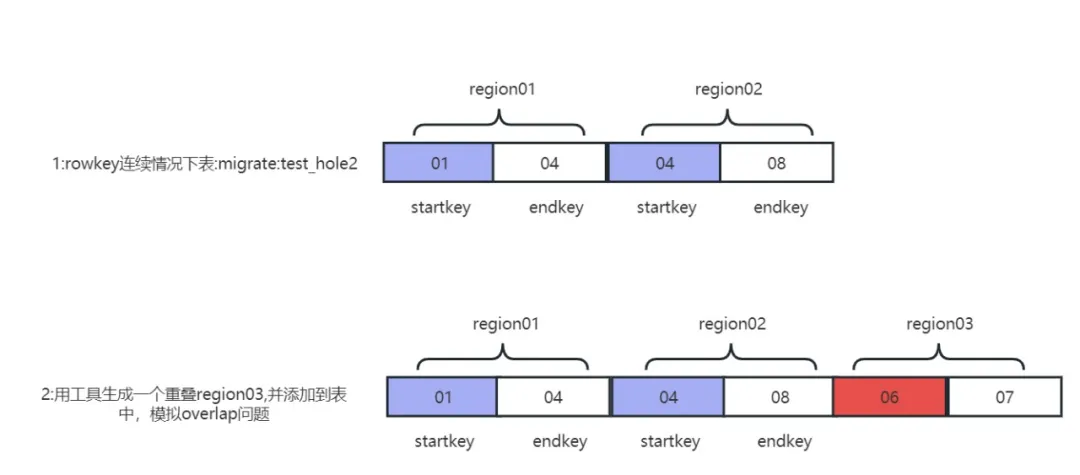
récurrence du problème de chevauchement
1) Générez un fragment de région avec des plages de clés de ligne qui se chevauchent :
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=createRegion -DRegion.startkey=06 -DRegion.endkey=07 hbase-meta-tool-0.0.1.jar
2) Déplacez la région du problème de chevauchement vers le répertoire de la table :
sudo -uhdfs hdfs dfs -mv /tmp/.tmp/data/migrate/test_hole2/c8662e08f6ae705237e390029161f58f /hbase/data/migrate/test_hole2
3) Supprimez les informations de la méta-table de la table normale migrate:test_hole2 :
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
4) Reconstruisez les informations de métadonnées de la table des problèmes de chevauchement :
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
5) Après avoir redémarré le cluster, hbck a signalé que la région chevauchait c8662e08f6ae705237e390029161f58f et que le problème de chevauchement a été reproduit avec succès.

Méthode 1 : Réparer les chevauchements et les trous en un seul clic
Adapté aux cas où le nombre de plis ne dépasse pas 64, l'outil auto-développé hbase-meta-tool peut être utilisé pour fusionner les plages de régions adjacentes avec des intersections de touches de ligne et générer de nouvelles régions s'il y a des trous ou des plages manquantes. que le problème peut être réparé. Principe de réparation du problème Comme indiqué sur l'image :
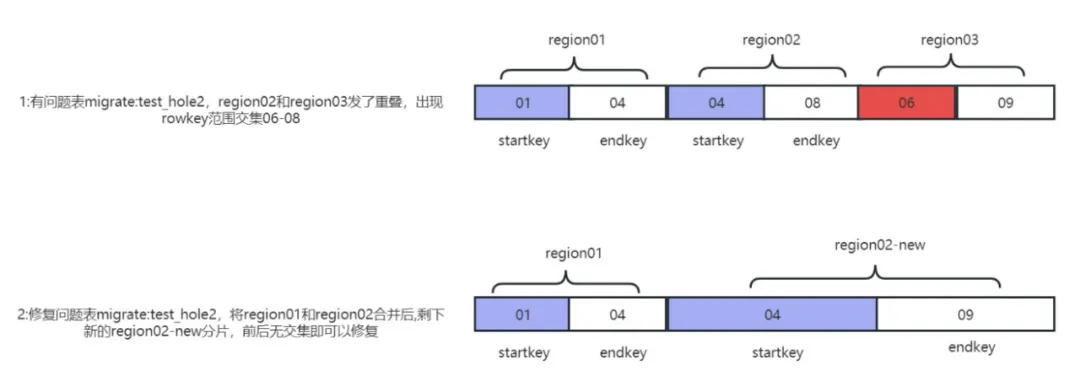
1) Résoudre les problèmes de chevauchement de cluster et de trous :
java -jar -Dfix.operator= fixOverlapAndHole hbase-meta-tool-0.0.1.jar
Méthode 2 : Réparation de pliage à grande échelle
Convient au pliage à grande échelle de plus de milliers ou de dizaines de milliers de cas pour réparer une anomalie côté serveur, utilisez les méthodes de réparation suivantes
1) Effacez les métadonnées des tableaux présentant des problèmes de pliage en un clic :
java -jar -Drepair.tableName=migrate:test1 -Dzookeeper.address=zkAddress -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) Sauvegardez les données de la table d'origine :
hdfs dfs -mv /hbase/data/migrate/test/ /back
3) Supprimez la table d'origine et importez les données de sauvegarde pour chaque fragment de région :
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /back/test/region01-regionN migrate:test1
3.4 Réparation des données des métatables
Nous pouvons rencontrer les problèmes difficiles suivants dans les clusters en ligne HBase :
-
La table du coprocesseur est mal configurée, le chemin du coprocesseur est introuvable et le fichier jar est introuvable lors du chargement de la région, ce qui entraîne le blocage répété du cluster et la commande drop ne peut pas le supprimer ;
-
Le nombre d'éléments dans la méta-table HBase est incorrect, le code de démarrage est incorrect, la table du serveur est introuvable pendant le processus en ligne et la table n'est jamais mise en ligne.
Nous devons réparer la table problématique indépendamment sans arrêter le service et sans affecter les autres services de table du cluster.
Réparation des métadonnées de la table des problèmes
1) En supposant qu'il y ait un problème avec la table migrate:test1, vous pouvez supprimer les métadonnées de la table problématique en un seul clic :
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) Lisez le contenu du dossier .regioninfo de la table hdfs et reconstruisez les métadonnées correctes en un clic :
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
3.5 méta cassée
Les cinq situations ci-dessus sont toutes réparées en partant du principe que la méta-table est normalement en ligne. Si les données de la méta-table sont endommagées et ne peuvent pas être en ligne, comment devons-nous les réparer ? Habituellement, nous pensons à reconstruire la méta-table, puis à écrire les informations de région dans la méta-table. Si le cluster est hors ligne, le shell HBase ou l'API HBase ne peut généralement pas exécuter create pour créer la table.
Nous avons analysé la classe d'initialisation de méta-table InitMetaProcedure et avons constaté que le processus de création de méta-table est grossièrement divisé en deux étapes :
1) Créez le répertoire Région et le fichier .tabledesc
2) Attribuez une région et allez en ligne.
Code source principal d'InitMetaProcedure :
InitMetaProcédure
protected Flow executeFromState(MasterProcedureEnv env, InitMetaState state) throws ProcedureSuspendedException, ProcedureYieldException, InterruptedException {
try {
switch (state) {
case INIT_META_WRITE_FS_LAYOUT:
Configuration conf = env.getMasterConfiguration();
Path rootDir = CommonFSUtils.getRootDir(conf);
TableDescriptor td = writeFsLayout(rootDir, conf);
env.getMasterServices().getTableDescriptors().update(td, true);
setNextState(InitMetaState.INIT_META_ASSIGN_META);
return Flow.HAS_MORE_STATE;
case INIT_META_ASSIGN_META:
addChildProcedure(env.getAssignmentManager().createAssignProcedures(Arrays.asList(RegionInfoBuilder.FIRST_META_RegionINFO)));
return Flow.NO_MORE_STATE;
default:
throw new UnsupportedOperationException("unhandled state=" + state);
}
} catch (IOException e) {
}
private static TableDescriptor writeFsLayout(Path rootDir, Configuration conf) throws IOException {
LOG.info("BOOTSTRAP: creating hbase:meta region");
FileSystem fs = rootDir.getFileSystem(conf);
Path tableDir = CommonFSUtils.getTableDir(rootDir, TableName.META_TABLE_NAME);
if (fs.exists(tableDir) && !fs.delete(tableDir, true)) {
LOG.warn("Can not delete partial created meta table, continue...");
}
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(conf, fs, rootDir);
HRegion.createHRegion(RegionInfoBuilder.FIRST_META_RegionINFO, rootDir, conf, metaDescriptor, null).close();
return metaDescriptor;
}
Nous pouvons nous référer à la logique du code InitMetaProcedure pour écrire les outils correspondants pour créer des tables et passer en ligne. Une fois la méta-table mise en ligne, il nous suffit d'écrire les informations de région de chaque table dans la méta et d'attribuer à toutes les régions la mise en ligne pour restaurer la normale. état du cluster. Grâce au processus ci-dessus, nous avons constaté que le processus de réparation des méta-tables n'est pas si compliqué. Cependant, s'il existe un grand nombre de tables dans l'environnement de production ou s'il existe des milliers de régions dans de grandes tables individuelles, l'ajout manuel devient très long. Nous présenterons ci-dessous le processus qui a toujours été relativement simple. Solution (outil hbck HBase 1.x, hbase-operator-tools HBase 2.x), jetons un coup d'œil au processus de réparation hors ligne.
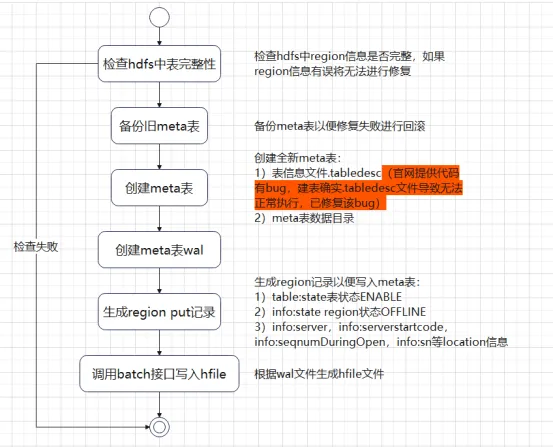
Correctifs HBase 1.x
-
Arrêtez le cluster HBase
-
sudo -u hbase hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair -fix
-
Redémarrez le cluster pour terminer la réparation.
Méthode de réparation HBase 2.4.8 (outil hbase-operator-tools)
1) Générer automatiquement une méta-table basée sur le chemin hdfs
-
Arrêtez le cluster HBase
-
sudo -u hbase hbase org.apache.hbase.hbck1.OfflineMetaRepair -fix
-
Redémarrez le cluster pour terminer la réparation.
2) Méthode de réparation à table unique
-
Supprimez le répertoire racine HBase dans zookeeper
-
Supprimez le répertoire hdfs WALs où se trouvent HMaster et RegionServer
-
Après le redémarrage du cluster, il n'y a aucune donnée dans la méta et le cluster ne peut pas entrer dans l'état normal.
-
Exécutez la commande add Region pour ajouter les tables à quatre caractères hbase:namespace, hbase:quota, hbase:rsgroup et hbase:acl au cluster Une fois l'ajout terminé, le journal imprimera les régions suivies des assignations et de ces tables. . Ces régions doivent être enregistrées pour la prochaine opération d'attribution.
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-tools.jar addFsRegionsMissingInMeta hbase:namespace hbase:quota hbase:rsgroup hbase:acl
- Ajoutez la région d'impression à l'étape précédente en ligne
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-hbck2.jar assigns regionid
- La table business est en ligne (il vous suffit de répéter les étapes 4 à 5 pour mettre progressivement la table business en ligne)
Précautions
(S'il y a de nombreuses régions dans la table métier et que la cinquième région n'est pas attribuée, toutes les régions ne peuvent pas être mises en ligne avec succès. Vous devez désactiver et activer les performances pour qu'elles soient mises en ligne normalement)
Remarque : L'outil hbase-operator-tools OfflineMetaRepair présente les bogues suivants qui doivent être corrigés.
1. La métatable créée par la méthode HBaseFsck createNewMeta ne contient pas le fichier .tabledesc.
avant de réparer :
TableDescriptor td = new FSTableDescriptors(getConf()).get(TableName.META_TABLE_NAME);
Après modification:
FileSystem fs = rootdir.getFileSystem(conf);
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(getConf(), fs, rootdir);
2. L'état de région par défaut de HBaseFsck generatePuts est FERMÉ car HMaster ne se met en ligne qu'à l'état HORS LIGNE lorsqu'il redémarre (s'il est FERMÉ, la charge de travail de mise en ligne manuelle un par un est très énorme)
avant de réparer :
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.CLOSED);
Après modification:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.OFFLINE);
défaut
1) La réparation hors ligne nécessite l'arrêt du service du cluster. Le temps d'arrêt dépend du temps de réparation (environ 10 à 15 minutes).
2) S'il existe des problèmes tels qu'un chevauchement de régions et des trous, ils doivent être traités manuellement avant d'exécuter la commande de réparation hors ligne OfflineMetaRepair.
4. outil hbase-operator-tools
hbase-operator-tools est un ensemble d'outils dans HBase utilisé pour aider les administrateurs HBase à gérer et à maintenir les clusters HBase. hbase-operator-tools fournit une série d'outils, notamment des outils de sauvegarde et de récupération, des outils de gestion de région, des outils de compression et de déplacement de données, etc., qui peuvent aider les administrateurs à mieux gérer les clusters HBase et à améliorer la stabilité et la fiabilité du cluster. Vous devez compiler le code source avant de pouvoir l'utiliser. Adresse git du code source . Les commandes courantes sont les suivantes :
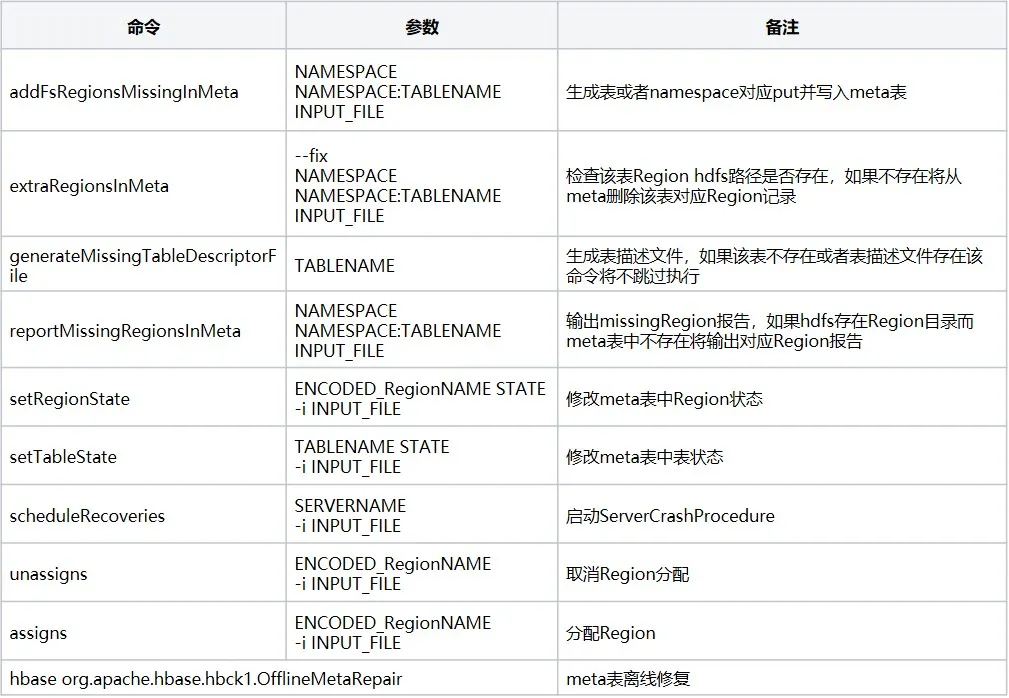
5. Résumé
L'exactitude des données de la méta-table HBase est cruciale pour le fonctionnement normal du cluster HBase. Comment garantir que les données de la méta-table sont correctes et comment réparer rapidement les données après qu'elles soient endommagées est extrêmement important si vous n'en avez pas. compréhension complète de la méta, vous serez perdu à chaque fois que le cluster échoue. Cet article se concentre principalement sur l'analyse du processus de chargement de la structure des méta-tables, des problèmes courants et des méthodes de réparation associées. Nous pouvons grossièrement diviser les méthodes de réparation ci-dessus dans les deux catégories suivantes :
-
Réparation en ligne : La méta-table peut être réparée normalement via hbck et des outils auto-développés pour garantir l'intégrité des données.
-
Réparation hors ligne : la méta-table ne peut pas être mise en ligne normalement. La méta-table est reconstruite en fonction des informations de région dans HDFS pour restaurer le service HBase.
Si l'échelle du cluster est relativement grande et que le temps de réparation hors ligne est relativement long, le cluster doit arrêter les services pendant une longue période. Dans la plupart des cas, l'entreprise ne peut pas le tolérer en fonction de la situation réelle. sauf si le fichier de méta-table est endommagé et ne peut pas être mis en ligne normalement). Il est recommandé d'effectuer régulièrement des vérifications hbck sur le cluster. Une fois qu'une incohérence des méta-informations se produit, réparez-le dès que possible pour éviter la propagation du problème (par exemple, si les méta-informations ont été gâchées et que le cluster redémarre et que la région gâchée ne parvient pas à être attribuée, les autres régions ne pourront pas se connecter normalement). Si l'inspection régulière révèle qu'il y a un gâchis de méta-informations dans la table commerciale, redémarrez-le directement. La méta-table supprime les informations de la table et ajoute la région à la méta-table en fonction des informations de chemin hdfs (la commande addFsRegions-MissingInMeta peut correctement ajouter la région à la méta-table en fonction du chemin hdfs).
Article de référence :
Les lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : S'appuyant sur la défense, Apple a publié la puce M4 RustDesk. Les services nationaux ont été suspendus en raison d'une fraude généralisée. À l'avenir, il envisage de produire un jeu indépendant sur la plateforme Windows Taobao (taobao.com) Redémarrer le travail d'optimisation de la version Web, destination des programmeurs, Visual Studio Code 1.89 publie Java 17, la version Java LTS la plus couramment utilisée, Windows 10 a un part de marché de 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais ; l'anxiété et les ambitions de Microsoft ont fermé la plate-forme ouverte ;