
-
Premièrement, les scores des différents types de requêtes ne se situent pas dans la même dimension comparable, de sorte que de simples calculs arithmétiques ne peuvent pas être effectués directement.
-
Deuxièmement, dans un système de récupération distribué, les scores sont généralement au niveau des fragments et les scores de tous les fragments doivent être globalement normalisés.
-
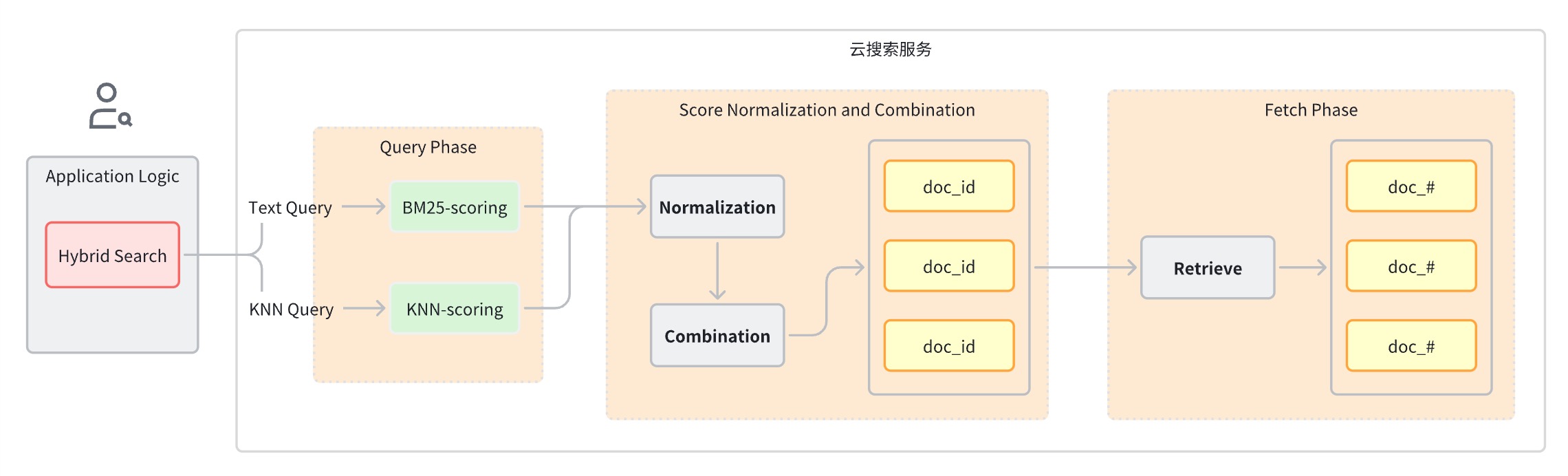
Phase de requête : utilisez des clauses de requête mixtes pour la recherche par mot clé et la recherche sémantique.
-
Étape de normalisation et de fusion des scores, qui suit l’étape de requête.
-
Étant donné que chaque type de requête fournit une plage de scores différente, cette étape effectue une opération de normalisation sur les résultats de score de chaque clause de requête. Les méthodes de normalisation prises en charge sont min_max, l2 et rrf.
-
Pour combiner les scores normalisés, les méthodes de combinaison incluent arithmetic_mean,ometric_mean et harmonic_mean.
-
-
Les documents sont réorganisés en fonction des notes combinées et renvoyés à l'utilisateur.
Idées de mise en œuvre
-
Moteur de recherche en texte intégral
-
moteur de recherche de vecteurs
-
Modèle d'apprentissage automatique pour l'intégration de vecteurs
-
Pipeline de données qui convertit le texte, l'audio, la vidéo et d'autres données en vecteurs
-
Tri par fusion

-
Configurer et créer des objets associés
-
Pipeline d'ingestion : prend en charge l'appel automatique du modèle pour stocker les vecteurs de conversion d'image dans l'index
-
Pipeline de recherche : prend en charge la conversion automatique des instructions de requête textuelle en vecteurs pour le calcul de similarité.
-
Indice k-NN : l'index où le vecteur est stocké
-
-
Écrivez les données de l'ensemble de données d'image dans l'instance OpenSearch et OpenSearch appellera automatiquement le modèle d'apprentissage automatique pour convertir le texte en vecteur d'intégration.
-
Lorsque le client lance une requête de recherche hybride, OpenSearch appelle le modèle d'apprentissage automatique pour convertir la requête entrante en un vecteur d'intégration.
-
OpenSearch effectue un traitement des demandes de recherche hybride, combine les scores de recherche par mot-clé et de recherche sémantique et renvoie les résultats de la recherche.
Planifier un combat réel
Préparation environnementale
-
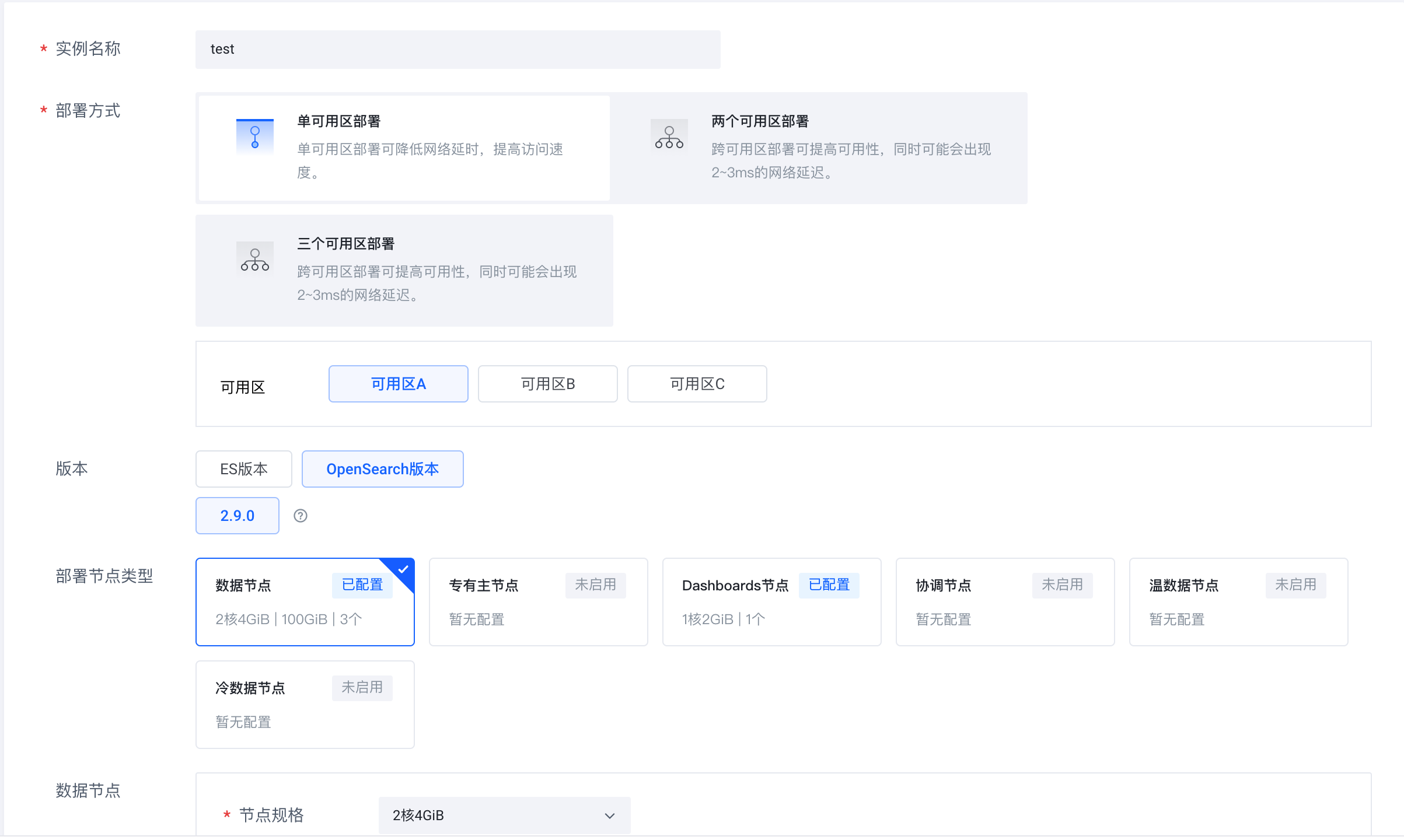
Connectez-vous au service de recherche cloud Volcano Engine (https://console.volcengine.com/es), créez un cluster d'instances et sélectionnez OpenSearch 2.9.0 comme version.
-
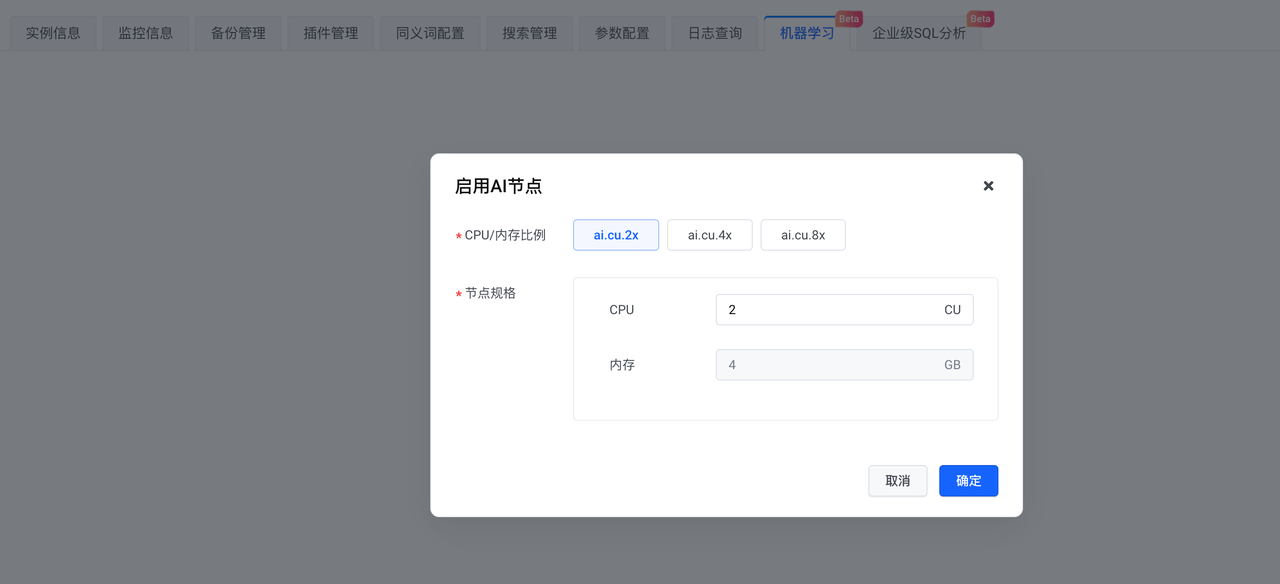
Une fois l'instance créée, activez le nœud AI.
-
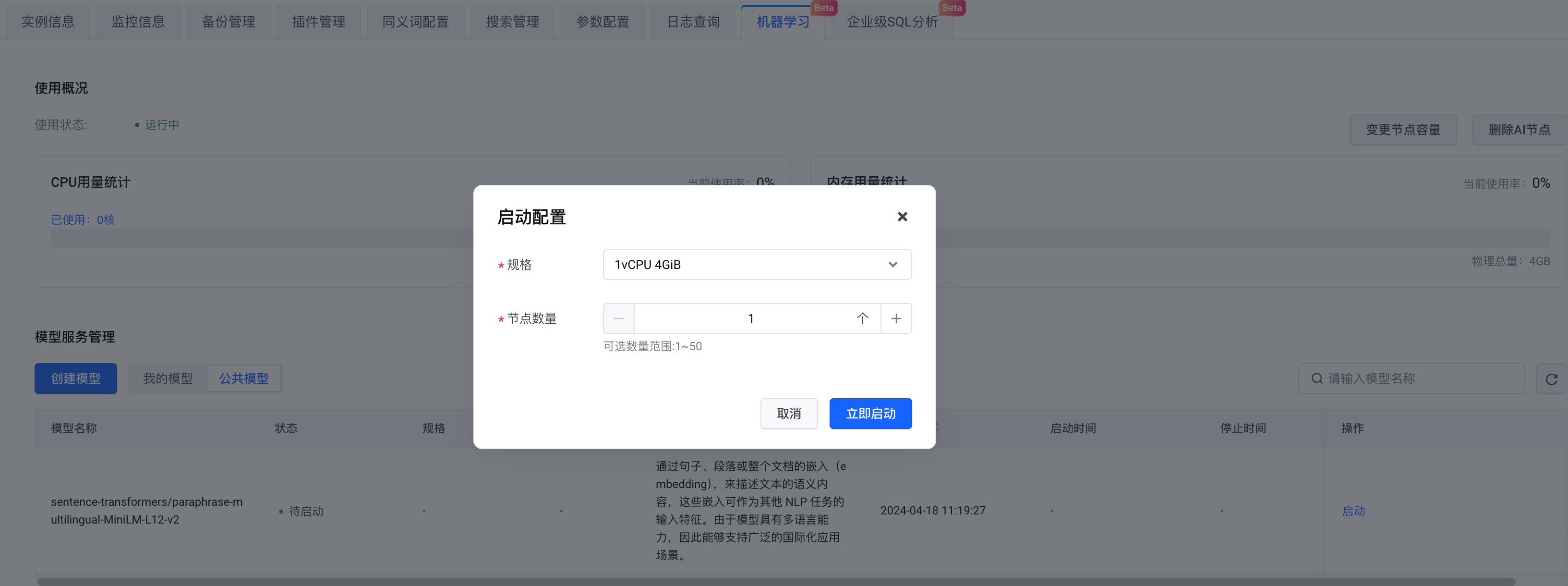
En termes de sélection de modèle, vous pouvez créer votre propre modèle ou choisir un modèle public. Ici, nous sélectionnons le modèle public . Après avoir terminé la configuration, cliquez sur Démarrer maintenant .
Préparation du jeu de données
Pas
Installer les dépendances Python
pip install -U elasticsearch7==7.10.1
pip install -U pandas
pip install -U jupyter
pip install -U requests
pip install -U s3fs
pip install -U alive_progress
pip install -U pillow
pip install -U ipythonConnectez-vous à OpenSearch
# Prepare opensearch info
from elasticsearch7 import Elasticsearch as CloudSearch
from ssl import create_default_context
# opensearch info
opensearch_domain = '{{ OPENSEARCH_DOMAIN }}'
opensearch_port = '9200'
opensearch_user = 'admin'
opensearch_pwd = '{{ OPENSEARCH_PWD }}'
# remote config for model server
model_remote_config = {
"method": "POST",
"url": "{{ REMOTE_MODEL_URL }}",
"params": {},
"headers": {
"Content-Type": "application/json"
},
"advance_request_body": {
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
}
}
# dimension for knn vector
knn_dimension = 384
# load cer and create ssl context
ssl_context = create_default_context(cafile='./ca.cer')
# create CloudSearch client
cloud_search_cli = CloudSearch([opensearch_domain, opensearch_port],
ssl_context=ssl_context,
scheme="https",
http_auth=(opensearch_user, opensearch_pwd)
)
# index name
index_name = 'index-test'
# pipeline id
pipeline_id = 'remote_text_embedding_test'
# search pipeline id
search_pipeline_id = 'rrf_search_pipeline_test'-
Remplissez l’adresse du lien OpenSearch ainsi que les informations de nom d’utilisateur et de mot de passe. model_remote_config est la configuration de connexion du modèle d'apprentissage automatique à distance, qui peut être consultée dans les informations d'appel du modèle . Copiez toutes les configurations remote_config dans les informations d'appel vers model_remote_config .
-
Dans la section Informations sur l'instance- > Accès au service , téléchargez le certificat dans le répertoire actuel.
-
Compte tenu d'un nom d'index, d'un ID de pipeline et d'un ID de pipeline de recherche.
Créer un pipeline d'ingestion
# Create ingest pipeline
pipeline_body = {
"description": "text embedding pipeline for remote inference",
"processors": [{
"remote_text_embedding": {
"remote_config": model_remote_config,
"field_map": {
"caption": "caption_embedding"
}
}
}]
}
# create request
resp = cloud_search_cli.ingest.put_pipeline(id=pipeline_id, body=pipeline_body)
print(resp)Créer un pipeline de recherche
-
Méthode de normalisation :
min_max,l2,rrf -
Méthode de sommation pondérée :
arithmetic_mean,geometric_mean,harmonic_mean
# Create search pipeline
import requests
search_pipeline_body = {
"description": "post processor for hybrid search",
"request_processors": [{
"remote_embedding": {
"remote_config": model_remote_config
}
}],
"phase_results_processors": [ # normalization and combination
{
"normalization-processor": {
"normalization": {
"technique": "rrf", # the normalization technique in the processor is set to rrf
"parameters": {
"rank_constant": 60 # param
}
},
"combination": {
"technique": "arithmetic_mean", # the combination technique is set to arithmetic mean
"parameters": {
"weights": [
0.4,
0.6
]
}
}
}
}
]
}
headers = {
'Content-Type': 'application/json',
}
# create request
resp = requests.put(
url="https://" + opensearch_domain + ':' + opensearch_port + '/_search/pipeline/' + search_pipeline_id,
auth=(opensearch_user, opensearch_pwd),
json=search_pipeline_body,
headers=headers,
verify='./ca.cer')
print(resp.text)Créer un index k-NN
-
Configurez le pipeline d'ingestion pré-créé dans le champ index.default_pipeline ;
-
En même temps, configurez les propriétés et définissez caption_embedding sur knn_vector. Ici, nous utilisons hnsw dans faiss.
# Create k-NN index
# create index and set settings, mappings, and properties as needed.
index_body = {
"settings": {
"index.knn": True,
"number_of_shards": 1,
"number_of_replicas": 0,
"default_pipeline": pipeline_id # ingest pipeline
},
"mappings": {
"properties": {
"image_url": {
"type": "text"
},
"caption_embedding": {
"type": "knn_vector",
"dimension": knn_dimension,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
},
"caption": {
"type": "text"
}
}
}
}
# create index
resp = cloud_search_cli.indices.create(index=index_name, body=index_body)
print(resp)Charger l'ensemble de données
# Prepare dataset
import pandas as pd
import string
appended_data = []
for character in string.digits[0:] + string.ascii_lowercase:
if character == '1':
break
try:
meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_" + character + ".json.gz",
lines=True)
except FileNotFoundError:
continue
appended_data.append(meta)
appended_data_frame = pd.concat(appended_data)
appended_data_frame.shape
meta = appended_data_frame
def func_(x):
us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]
return us_texts[0] if us_texts else None
meta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))
meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]
print(f"#products with US English title: {len(meta)}")
meta.head()
image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")
dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")
dataset.head()Télécharger l'ensemble de données
# Upload dataset
import json
from alive_progress import alive_bar
cnt = 0
batch = 0
action = json.dumps({"index": {"_index": index_name}})
body_ = ''
with alive_bar(len(dataset), force_tty=True) as bar:
for index, row in (dataset.iterrows()):
if row['path'] == '87/874f86c4.jpg':
continue
payload = {}
payload['image_url'] = "https://amazon-berkeley-objects.s3.amazonaws.com/images/small/" + row['path']
payload['caption'] = row['item_name_in_en_us']
body_ = body_ + action + "\n" + json.dumps(payload) + "\n"
cnt = cnt + 1
if cnt == 100:
resp = cloud_search_cli.bulk(
request_timeout=1000,
index=index_name,
body=body_)
cnt = 0
batch = batch + 1
body_ = ''
bar()
print("Total Bulk batches completed: " + str(batch))Requête de recherche hybride
match
. La requête contient deux clauses de requête, l'une est une requête et l'autre est
remote_neural
une requête. Lors de l'interrogation, spécifiez le pipeline de recherche précédemment créé comme paramètre de requête. Le pipeline de recherche convertira le texte entrant en vecteur et le stockera dans
le champ caption_embedding
pour les requêtes ultérieures.
# Search with search pipeline
from urllib import request
from PIL import Image
import IPython.display as display
def search(text, size):
resp = cloud_search_cli.search(
index=index_name,
body={
"_source": ["image_url", "caption"],
"query": {
"hybrid": {
"queries": [
{
"match": {
"caption": {
"query": text
}
}
},
{
"remote_neural": {
"caption_embedding": {
"query_text": text,
"k": size
}
}
}
]
}
}
},
params={"search_pipeline": search_pipeline_id},
)
return resp
k = 10
ret = search('shoes', k)
for item in ret['hits']['hits']:
display.display(Image.open(request.urlopen(item['_source']['image_url'])))
print(item['_source']['caption'])Affichage de recherche hybride

Ce qui précède prend l'application de recherche d'images comme exemple pour présenter le processus pratique permettant de développer rapidement une application de recherche hybride à l'aide de la solution de service de recherche cloud Volcano Engine. Invitez tout le monde à se connecter à la console Volcano Engine pour fonctionner !
Le service de recherche cloud Volcano Engine est compatible avec Elasticsearch, Kibana et d'autres logiciels et plug-ins open source couramment utilisés. Il fournit une récupération multi-conditions, des statistiques et des rapports de texte structuré et non structuré. Il peut réaliser un déploiement élastique en un clic. mise à l'échelle, opération et maintenance simplifiées et création rapide de journaux d'analyse, d'analyse de récupération d'informations et d'autres fonctionnalités commerciales.