

Bien que les caches externes soient utiles pour réduire la latence, ils causent souvent plus de problèmes que d’avantages. Voici comment résoudre ce problème.
Traduit de Pourquoi et comment les équipes remplacent les caches de bases de données externes par Felipe Cardeneti Mendes.
Les équipes envisagent souvent la mise en cache externe lorsqu'une base de données existante ne peut pas respecter l'accord de niveau de service (SLA) requis. Il s’agit d’une décision résolument axée sur la performance. Le placement d' un cache externe devant la base de données est souvent effectué pour compenser une latence sous-optimale causée par divers facteurs (par exemple, des composants internes de la base de données inefficaces, l'utilisation du pilote, les choix d'infrastructure, les pics de trafic, etc.).
La mise en cache semble être une solution simple et rapide, car le déploiement peut être mis en œuvre sans problème et sans encourir les coûts importants d' expansion de la base de données , de refonte du schéma de base de données ou de conversions technologiques encore plus approfondies. Cependant, la mise en cache externe n’est pas aussi simple qu’on le dit souvent. Ils peuvent constituer l’un des composants les plus problématiques de l’architecture d’applications distribuées.
Dans certains cas, il s'agit d'un mal nécessaire, par exemple lorsque vous avez besoin d'un accès fréquent à des données transformées résultant de calculs longs et coûteux, et que vous avez essayé toutes les autres manières de réduire la latence. Mais dans de nombreux cas, le gain de performances n’en vaut tout simplement pas la peine. Vous résolvez un problème, mais vous en créez d’autres.
Voici les risques souvent négligés associés à la mise en cache externe et la manière dont trois équipes ont réalisé des gains de performances et des économies de coûts en remplaçant leur base de données principale et leur mise en cache externe par une solution unique. Spoiler : Ils utilisent ScyllaDB, une base de données hautes performances qui améliore la latence longue traîne en exploitant un cache interne spécialisé.
Pourquoi ne pas mettre en cache ?
Chez ScyllaDB, nous travaillons avec d'innombrables équipes aux prises avec le coût, les tracas et les limites des tentatives traditionnelles d'amélioration des performances des bases de données. Voici les principales difficultés que nous constatons que les équipes rencontrent lorsqu’elles placent une mise en cache externe devant leurs bases de données.
La mise en cache externe augmente la latence
Un cache séparé signifie un saut supplémentaire en cours de route. Lorsque la mise en cache entoure la base de données, le premier accès se produit au niveau de la couche cache. Si les données ne sont pas dans le cache, la requête sera envoyée à la base de données. Cela ajoute de la latence au chemin déjà lent vers les données non mises en cache. On pourrait affirmer que lorsque l’ensemble des données tient dans le cache, la latence supplémentaire n’entre pas en jeu. Cependant, à moins que votre ensemble de données ne soit assez petit, le stockage de l’ensemble en mémoire augmente considérablement le coût, ce qui le rend prohibitif pour la plupart des organisations.
La mise en cache externe est un coût supplémentaire
La mise en cache signifie une DRAM coûteuse, ce qui signifie que le coût par gigaoctet est plus élevé que celui des disques SSD. (Pour plus de détails à ce sujet, voir l'exposé de Danny Kopping de Grafana à P99 CONF .) Plutôt que de fournir une infrastructure complètement distincte pour la mise en cache, il est souvent préférable d'utiliser la mémoire de base de données existante ou même de l'augmenter pour accueillir le cache interne. Lorsqu’ils sont correctement dimensionnés, les caches de bases de données modernes peuvent être aussi efficaces que les solutions traditionnelles de mise en cache en mémoire. Les bases de données réussissent souvent à optimiser l'accès aux E/S au stockage flash lorsque la taille de l'ensemble de travail est trop grande pour tenir en mémoire, ce qui fait d'une base de données distincte (sans cache externe) l'option préférée et la moins chère.
La mise en cache externe réduit la disponibilité
Aucune solution de mise en cache haute disponibilité ne peut rivaliser avec la base de données elle-même. Les bases de données distribuées modernes disposent de plusieurs réplicas ; elles sont également sensibles à la topologie et à la vitesse, et peuvent résister à plusieurs pannes sans perdre de données.
Par exemple, un modèle de réplication courant consiste en trois réplicas locaux, ce qui permet souvent d'équilibrer les lectures entre ces réplicas afin d'utiliser efficacement le mécanisme de mise en cache interne de la base de données. Considérons un cluster de neuf nœuds avec un facteur de réplication de trois : essentiellement, chaque nœud contiendra environ un tiers de la taille totale de votre ensemble de données. Étant donné que les demandes sont équilibrées entre différentes répliques, cela vous donne plus d'espace pour mettre en cache les données, ce qui peut éliminer le besoin d'une mise en cache externe. À l'inverse, si le cache externe invalide une entrée juste avant un grand nombre de requêtes froides, la disponibilité peut être affectée pendant un certain temps car la base de données n'a pas ces données dans son cache interne (plus d'informations ci-dessous).
Les caches manquent souvent de propriétés de haute disponibilité et peuvent facilement échouer ou invalider des enregistrements en fonction de leur heuristique. Les échecs partiels sont plus fréquents et encore pires en termes de cohérence. Lorsque le cache échoue inévitablement, la base de données sera confrontée à un flot de requêtes non atténuées et peut rompre votre SLA. De plus, même si le cache lui-même possède certaines fonctionnalités de haute disponibilité, il ne peut pas coordonner la gestion de telles pannes avec la base de données persistante qui se trouve devant lui. En résumé : comptez sur la base de données, plutôt que de laisser votre SLA de latence dépendre du cache.
Complexité de l'application – votre application doit gérer plus de situations
La mise en cache externe introduit une complexité applicative et opérationnelle. Une fois que vous disposez d'un cache externe, il est de votre responsabilité de maintenir le cache à jour avec la base de données. Quelle que soit votre stratégie de mise en cache (par exemple, écriture directe, contournement du cache, etc.), il existe des cas extrêmes où votre cache peut se désynchroniser avec la base de données, et vous devez tenir compte de ces situations lors du développement de l'application. Les paramètres de votre client (tels que les politiques de basculement, de nouvelle tentative et d'expiration) doivent correspondre aux propriétés du cache et de la base de données afin de fonctionner lorsque le cache est indisponible ou devient froid. En règle générale, de tels scénarios sont difficiles à tester et à mettre en œuvre.
Le cache externe corrompt le cache de la base de données
Les bases de données modernes intègrent des caches et des stratégies complexes pour les gérer. Lorsque vous placez un cache devant la base de données, la plupart des requêtes de lecture n'atteindront que le cache externe et la base de données ne conservera pas ces objets dans sa mémoire. En conséquence, le cache de la base de données devient invalide. Lorsque la requête atteint enfin la base de données, son cache sera froid et la réponse proviendra principalement du disque. Par conséquent, l’aller-retour du cache à la base de données et retour à l’application peut augmenter la latence.
La mise en cache externe peut augmenter les risques de sécurité
La mise en cache externe ajoute une toute nouvelle surface d'attaque à votre infrastructure. Le chiffrement, l'isolation et les contrôles d'accès aux données placées dans le cache peuvent différer de ceux de la couche de base de données elle-même.
La mise en cache externe ignore les connaissances et les ressources de la base de données
La base de données est complexe et conçue pour les charges de travail d'E/S spécialisées sur le système. De nombreuses requêtes accèdent aux mêmes données et une certaine partie de la taille de l'ensemble de travail peut être mise en cache en mémoire pour enregistrer l'accès au disque. Une bonne base de données doit avoir une logique complexe pour décider quels objets, index et accès elle doit mettre en cache. La base de données doit également avoir une politique d'expulsion pour déterminer quand les nouvelles données doivent remplacer les objets de cache existants (plus anciens).
La mise en cache résistante à l'analyse en est un exemple. Lors de l'analyse de grands ensembles de données, telles que des analyses de plage étendue ou de table complète, un grand nombre d'objets sont lus à partir du disque. La base de données peut se rendre compte qu'il s'agit d'une analyse (plutôt que d'une requête classique) et choisir de conserver ses objets en dehors de son cache interne. Cependant, la mise en cache externe (qui suit la stratégie de lecture directe) traite le jeu de résultats comme n'importe quel autre jeu de résultats et tente de mettre les résultats en cache. La base de données synchronise automatiquement le contenu mis en cache avec le disque en fonction des taux de requêtes entrantes, de sorte que les utilisateurs et les développeurs n'ont rien à faire pour garantir les performances et la cohérence des recherches de données récemment écrites. Donc, si pour une raison quelconque votre base de données ne répond pas assez rapidement, cela signifie :
- Erreur de configuration du cache.
- Pas assez de RAM pour le cache.
- La taille de l’ensemble de travail et le modèle de demande ne conviennent pas à la mise en cache.
- La mise en œuvre du cache de base de données est médiocre.
Meilleure option : laissez la base de données s'en occuper
Comment respecter votre SLA sans risquer la mise en cache d’une base de données externe ? De nombreuses équipes constatent qu'en migrant vers une base de données plus rapide (telle que ScyllaDB) et en utilisant un cache interne dédié , elles sont en mesure de respecter leurs SLA de latence avec moins de tracas et à moindre coût. Bien entendu, les résultats varieront en fonction des caractéristiques de la charge de travail et des exigences techniques. Mais pour voir ce qui est possible, réfléchissez à ce que ces équipes peuvent réaliser.
SecurityScorecard atteint une réduction de la latence de 90 % avec une économie annuelle de 1 million de dollars
SecurityScorecard vise à rendre le monde plus sûr en changeant la façon dont des milliers d'organisations comprennent, atténuent et communiquent sur la cybersécurité. Sa plateforme de notation est une mesure objective, fondée sur des données et quantifiable de l'exposition globale à la cybersécurité et aux cyber-risques d'une organisation.
L'ancienne architecture de données de l'équipe leur a bien servi pendant un certain temps, mais n'a pas pu suivre leur croissance. L'API de leur plate-forme interroge l'un des trois magasins de données : Redis (pour des recherches plus rapides de 12 millions de cartes de score), Aurora (pour stocker 4 milliards de statistiques de mesure sur les nœuds) ou le système de fichiers distribué Hadoop sur le cluster Presto (pour les requêtes SQL complexes sur les résultats historiques ).
À mesure que les données et les demandes augmentent, des défis surgissent. Aurora et Presto connaissent des pics de latence à haut débit. La plus grande instance possible de Redis n'était toujours pas suffisante et ils ne voulaient pas utiliser la complexité de Redis Cluster.
Pour réduire la latence à la nouvelle échelle requise pour une croissance rapide de l'entreprise, l'équipe s'est tournée vers ScyllaDB Cloud et a développé une nouvelle API de notation pour acheminer les requêtes moins sensibles à la latence vers le stockage Presto et S3. Voici une visualisation de cette architecture, et c'est assez simple :
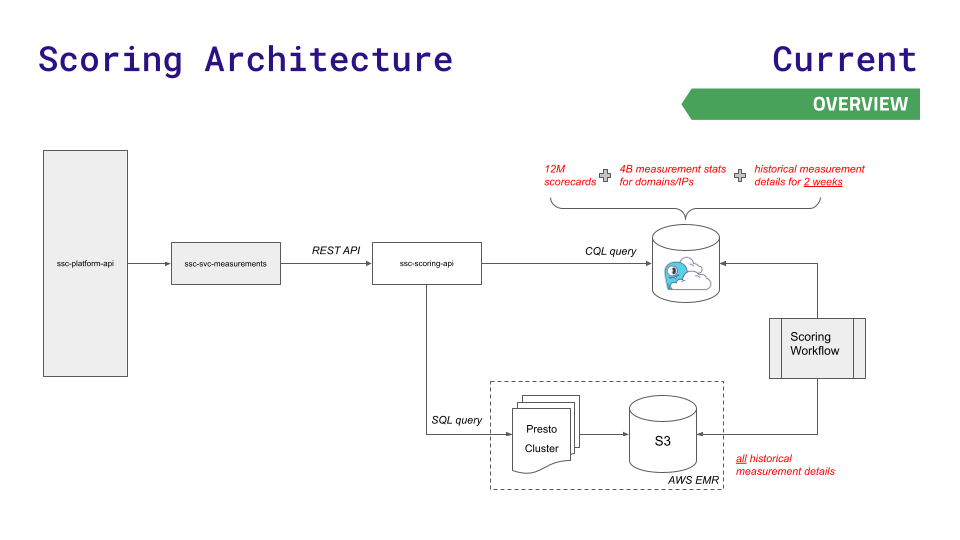
Ce déménagement a eu pour conséquence :
- Latence 90 % inférieure pour la plupart des points de terminaison de service
- Réduction de 80 % des incidents de production liés aux performances Presto/Aurora
- 1 million de dollars d’économies annuelles sur les coûts d’infrastructure
- La vitesse de traitement du pipeline de données a augmenté de 30 %
- Améliorer considérablement l'expérience client
[En savoir plus sur les cas d'utilisation de SecurityScorecard]
IMVU réduit le coût de Redis à 100 fois
IMVU est une communauté sociale populaire qui permet aux personnes du monde entier d'interagir à l'aide d'avatars 3D sur des ordinateurs de bureau, des tablettes et des appareils mobiles. Pour répondre aux exigences croissantes d'échelle, IMVU a décidé qu'il lui fallait une solution plus performante que son architecture de base de données précédente (MySQL et Memcached devant Redis). L’équipe a recherché quelque chose de plus facile à configurer, plus facile à mettre à l’échelle et (en cas de succès) plus facile à mettre à l’échelle.
"Redis était idéal pour les capacités de prototypage, mais une fois que nous l'avons déployé, la dépense est devenue difficile à justifier", a déclaré Ken Rudy, ingénieur logiciel senior chez IMVU. "ScyllaDB est optimisé pour conserver les données requises en mémoire et tout le reste sur le disque. ScyllaDB nous permet de maintenir la même réactivité pour des centaines de fois l'échelle que Redis peut gérer."
Comcast utilise 2,5 millions de dollars d'économies annuelles pour réduire la latence longue traîne de 95 %
Comcast est une société mondiale de médias et de technologie avec trois activités principales : Comcast Cable, l'un des plus grands fournisseurs de vidéo, d'Internet haut débit et d'appels téléphoniques aux clients résidentiels aux États-Unis ; Le service Xfinity de Comcast dessert 15 millions de foyers, avec plus de 2 milliards d'appels API (lecture/écriture) et plus de 200 millions de nouveaux objets chaque jour. En sept ans, le programme est passé de 30 000 appareils à plus de 31 millions d'appareils.
La latence longue traîne de Cassandra s'est avérée inacceptable compte tenu de la croissance rapide de l'entreprise. Pour masquer les problèmes de latence de Cassandra aux utilisateurs, l'équipe a placé 60 serveurs de cache devant sa base de données. Garder cette couche de mise en cache cohérente avec la base de données crée de nombreux maux de tête pour les administrateurs. Étant donné que le cache et l'infrastructure associée doivent être répliqués entre les centres de données, Comcast doit maintenir le cache actif. Ils ont mis en place un réchauffeur de cache qui vérifiait le volume d'écriture, puis copiait les données entre les centres de données.
Comcast s'est rapidement tourné vers ScyllaDB après avoir eu du mal à gérer les frais généraux de cette approche. ScyllaDB est conçu pour minimiser les pics de latence grâce à son mécanisme de mise en cache interne, permettant à Comcast d'éliminer les couches de mise en cache externes, fournissant ainsi un cadre simple dans lequel les services de données se connectent directement aux magasins de données. Comcast a pu remplacer 962 nœuds Cassandra par seulement 78 nœuds ScyllaDB. Ils ont amélioré la disponibilité et les performances globales tout en éliminant complètement 60 serveurs de cache. Résultats : les P99, P999 et P9999 ont réduit la latence de 95 % et ont pu traiter deux fois plus de requêtes, pour un coût opérationnel de 60 %. Cela leur a finalement permis d'économiser 2,5 millions de dollars par an en coûts d'infrastructure et en frais généraux de personnel.
Conclusion
Bien que les caches externes soient d'excellents compagnons pour réduire la latence (comme la diffusion de contenu statique et de données personnalisées qui ne nécessitent aucun niveau de persistance), ils créent souvent plus de problèmes que d'avantages lorsqu'ils sont placés devant la base de données.
Les principaux compromis incluent une augmentation des coûts, une complexité accrue des applications, des allers-retours supplémentaires vers la base de données et des surfaces de sécurité supplémentaires. En repensant les stratégies de mise en cache existantes et en passant à une base de données moderne offrant une faible latence prévisible à grande échelle, les équipes peuvent simplifier leur infrastructure et minimiser les coûts. Dans le même temps, ils peuvent toujours respecter leurs SLA sans les tracas et la complexité supplémentaires liés à la mise en cache externe.
Combien de revenus un projet open source inconnu peut-il rapporter ? L'équipe chinoise d'IA de Microsoft a fait ses valises et s'est rendue aux États-Unis, impliquant des centaines de personnes. Huawei a officiellement annoncé que les changements d'emploi de Yu Chengdong étaient cloués au « pilier de la honte FFmpeg » 15 ans. il y a, mais aujourd'hui il doit nous remercier—— Tencent QQ Video venge son humiliation passée ? Le site miroir open source de l'Université des sciences et technologies de Huazhong est officiellement ouvert à l'accès externe : Django est toujours le premier choix pour 74 % des développeurs. L'éditeur Zed a progressé dans la prise en charge de Linux. Un ancien employé d'une société open source bien connue . a annoncé la nouvelle : après avoir été interpellé par un subordonné, le responsable technique est devenu furieux et impoli, et a été licencié et enceinte. Une employée d'Alibaba Cloud publie officiellement Tongyi Qianwen 2.5 Microsoft fait un don d'un million de dollars à la Fondation Rust.Cet article a été publié pour la première fois sur Yunyunzhongsheng ( https://yylives.cc/ ), tout le monde est invité à le visiter.