
Introduction de l'auteur : Zhang Ji, engagé dans l'optimisation de la formation de Soutui/LLM, en se concentrant sur l'optimisation de la couche inférieure du système/du réseau.
arrière-plan
Alors que le nombre de paramètres des modèles à grande échelle passe de milliards à des milliards, l'expansion rapide de leur échelle de formation déclenche non seulement une augmentation significative des coûts de cluster, mais pose également des défis pour la stabilité du système, en particulier l'apparition fréquente de pannes de machines. une question qui ne peut être ignorée. Pour les tâches de formation distribuées à grande échelle, les capacités d’observabilité sont devenues la clé du dépannage et de l’optimisation des performances. Par conséquent, le personnel technique engagé dans le domaine de la formation sur modèles à grande échelle sera inévitablement confronté aux défis suivants :
- Au cours du processus de formation, les performances peuvent être instables, fluctuer ou même diminuer en raison de divers facteurs tels que les goulots d'étranglement du réseau et de l'informatique ;
- La formation distribuée implique que plusieurs nœuds travaillent ensemble. Si un nœud tombe en panne (qu'il s'agisse d'un problème logiciel, matériel, de carte réseau ou de GPU), l'ensemble du processus de formation doit être suspendu, ce qui affecte sérieusement l'efficacité de la formation et gaspille de précieuses ressources GPU.
Cependant, dans le processus actuel de formation de grands modèles, ces problèmes sont difficiles à résoudre. Les principales raisons sont les suivantes :
- Le processus de formation est une opération synchrone, et il est difficile d'exclure quelles machines ont des problèmes à ce moment-là grâce aux indicateurs de performances globales. Une machine lente peut ralentir la vitesse globale de formation ;
- La lenteur des performances de formation n'est souvent pas un problème avec la logique/le cadre de formation, mais est généralement causée par l'environnement. S'il n'y a pas de données de surveillance liées à la formation, l'impression des chronologies n'a en réalité aucun effet, et les exigences de stockage pour le stockage des fichiers de chronologie le sont également. haut;
- Le flux de travail d'analyse est complexe. Par exemple, lorsque la formation se bloque, vous devez terminer l'impression de toutes les piles avant l'expiration du délai d'attente de la torche, puis les analyser. Lorsque vous faites face à des tâches à grande échelle, il est difficile de les terminer dans le délai d'expiration de la torche.
Dans les opérations de formation distribuées à grande échelle, les capacités observables sont particulièrement importantes pour le dépannage et l’amélioration des performances. Dans le cadre de la formation à grande échelle, Ant a développé la bibliothèque xpu_timer pour répondre aux exigences d'observabilité de la formation en IA. À l'avenir, nous ouvrirons le timer xpu dans DLRover. Tout le monde est invité à coopérer et à construire ensemble :) La bibliothèque xpu_timer est un outil de profilage qui intercepte la bibliothèque cublas/cudart et utilise cudaEvent pour chronométrer les opérations de multiplication/de communication matricielle dans formation, il dispose également de fonctions telles que l'analyse de la chronologie, la détection des blocages et l'analyse de la pile de blocage, et est conçu pour prendre en charge une variété de plates-formes hétérogènes. Cet outil présente les fonctionnalités suivantes :
- Il n'y a aucune intrusion dans le code, aucune perte de performance de formation, et il peut résider dans le processus de formation ;
- Indifférent aux utilisateurs et sans rapport avec le framework
- Faible perte/haute précision
- L'agrégation/la fourniture d'indicateurs peut être effectuée pour faciliter le traitement et l'analyse ultérieurs des données ;
- Haute efficacité du stockage des informations
- Interface interactive pratique : fournit une interface externe conviviale pour faciliter l'intégration avec d'autres systèmes et le fonctionnement direct de l'utilisateur, accélérant ainsi le processus de compréhension et de prise de décision.
Conception
Premièrement, pour résoudre le problème des blocages de formation/dégradation des performances, nous avons conçu un timing de noyau permanent :
- Dans la plupart des scénarios, les blocages de formation sont causés par des opérations nccl. Habituellement, il vous suffit d'enregistrer la multiplication matricielle et de définir la communication ;
- Pour la dégradation des performances sur une seule machine (ECC, MCE), il vous suffit d'enregistrer la multiplication matricielle. En même temps, l'analyse de la multiplication matricielle peut également vérifier si la forme matricielle de l'utilisateur est scientifique et maximiser les performances de chaque framework. utilise directement cublas lors de l'implémentation de la multiplication matricielle.
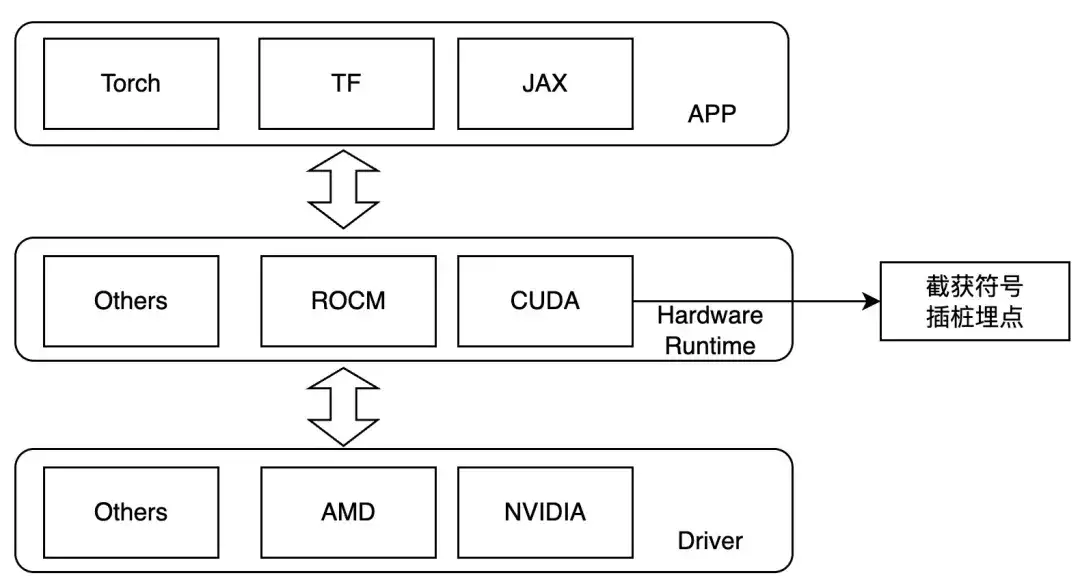
Par conséquent, nous concevons pour intercepter au niveau de la couche de lancement du noyau et définissons LD_PRELOAD pendant l'exécution pour tracer les opérations qui nous intéressent. Cette méthode ne peut être utilisée que dans le cas de liens dynamiques. Actuellement, les cadres de formation traditionnels sont des liens dynamiques. Pour les GPU NVIDIA, on peut faire attention aux symboles suivants :
- ibcudart.so
- cudaLaunchKernel
- cudaLaunchKernelExC
- libcublas.so
- cublasGemmEx
- cublasGemmStriedBatchedEx
- cublasLtMatmul
- cublasSgemm
- cublasSgemmStriedBatched
Lors de l'adaptation à différents matériels, différentes fonctions de traçage sont implémentées via différentes classes de modèles.
Flux de travail
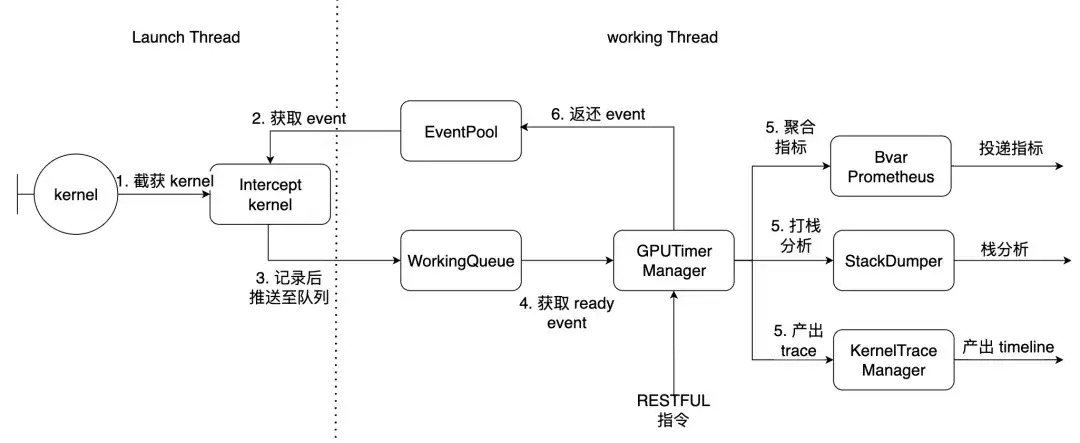
En prenant PyTorch comme exemple, le Launch Thread est le thread principal de la torche et le thread de travail est le thread de travail à l'intérieur de la bibliothèque. Les 7 noyaux décrits ci-dessus sont interceptés ici.
Comment utiliser et effets
Conditions préalables
- NCCL est compilé statiquement sur libtorch_cuda.so
- torch lie dynamiquement libcudart.so
Si NCCL est lié dynamiquement, des décalages de fonctions personnalisés peuvent être fournis et résolus dynamiquement au moment de l'exécution. Après avoir installé le package Python, vous disposerez des outils de ligne de commande suivants
| xpu_timer_gen_syms | Bibliothèque de décalage de fonction injectée dynamiquement pour générer et analyser dynamiquement nccl |
| xpu_timer_gen_trace_timeline | Utilisé pour générer une trace Chrome |
| xpu_timer_launch | Utilisé pour monter des paquets de crochets |
| xpu_timer_stacktrace_viewer | Utilisé pour générer une pile visuelle après l'expiration du délai |
| xpu_timer_print_env | Imprimer l'adresse libevent.so et imprimer les informations de compilation |
| xpu_timer_dump_timeline | Utilisé pour déclencher le vidage de la chronologie |
LD_PRELOAD 用法:XPU_TIMER_XXX=xxx LD_PRELOAD=`path to libevent_hook.so` python xxx
Chronologie de capture dynamique en temps réel
Chaque rang dispose d'un service de port, qui doit envoyer des commandes à tous les rangs en même temps. Le port de démarrage est brpc. Le port de service a une taille de données de 32 Mo pour chaque trace de rang. Il enregistre 1 000 enregistrements et a une taille de 32 Ko. . La taille de la chronologie générée json est de 150 Ko * taille mondiale, bien plus petite que l'utilisation de base
usage: xpu_timer_dump_timeline [-h]
--host HOST 要 dump 的 host
--rank RANK 对应 host 的 rank
[--port PORT] dump 的端口,默认 18888,如果一个 node 用了所有的卡,这个不需要修改
[--dump-path DUMP_PATH] 需要 dump 的地址,写绝对路径,长度不要超过 1000
[--dump-count DUMP_COUNT] 需要 dump 的 trace 个数
[--delay DELAY] 启动这个命令后多少秒再开始 dump
[--dry-run] 打印参数
Situation avec une seule machine
xpu_timer_dump_timeline \
--host 127.0.0.1 \
--rank "" \
--delay 3 \
--dump-path /root/lizhi-test \
--dump-count 4000
多机情况# 如下图所示,如果你的作业有 master/worker 混合情况(master 也是参与训练的)
# 可以写 --host xxx-master --rank 0
# 如果还不确定,使用 --dry-run
xpu_timer_dump_timeline \
--host worker \
--rank 0-3 \
--delay 3 --dump-path /nas/xxx --dump-count 4000
xpu_timer_dump_timeline \
--host worker --rank 1-3 \
--host master --rank 0 --dry-run
dumping to /root/timeline, with count 1000
dump host ['worker-1:18888', 'worker-2:18888', 'worker-3:18888', 'master-0:18888']
other data {'dump_path': '/root/timeline', 'dump_time': 1715304873, 'dump_count': 1000, 'reset': False}
Les fichiers suivants seront ajoutés ultérieurement au dossier de chronologie correspondant.

Ensuite, exécutez xpu_timer_gen_trace_timeline sous ce fichier
xpu_timer_gen_trace_timeline 3 fichiers seront générés :
- fichier auxiliaire merged_tracing_kernel_stack, fichier original du graphique de flamme
- trace.json a fusionné la chronologie
- tracing_kernel_stack.svg, pile d'appels pour la multiplication matricielle/nccl
Un cas d'analyse de 32 cartes sft de recettes de lama
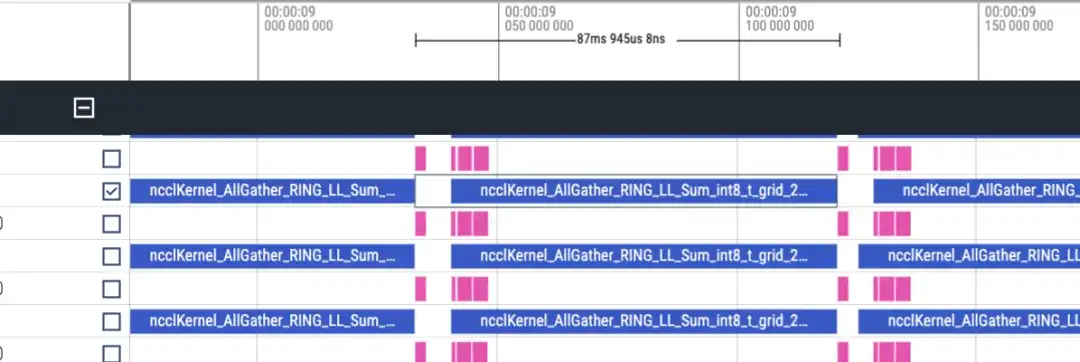
La chronologie est à peu près la suivante. Chaque rang affichera deux lignes de matmul/nccl, et tous les rangs seront affichés. Notez qu'il n'y a pas d'informations avant/arrière ici. Cela peut être jugé grossièrement par la durée de l'inverse qui est deux fois plus longue que l'avant.

Chronologie avancée, environ 87 ms
Chronologie inversée environ 173 ms
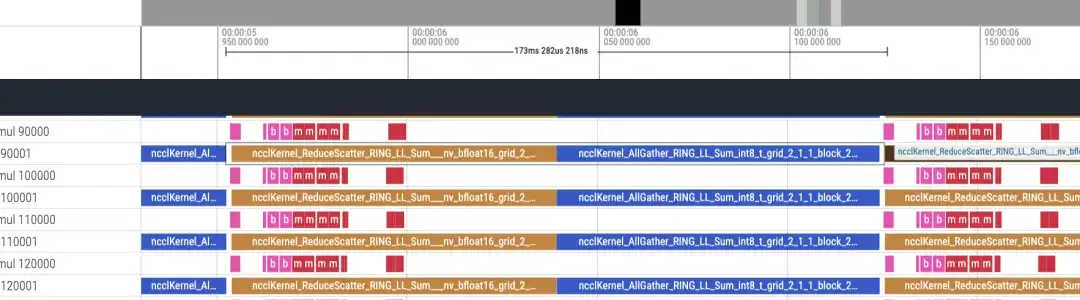
Il y a 48 couches au total et la consommation de temps totale est de (173+87)*48 = 12480 ms, y compris lmhead, l'intégration et d'autres opérations, cela prend environ 13 secondes. Et à travers la chronologie, on constate que le temps de communication est beaucoup plus long que le temps de calcul, et on peut déterminer que le goulot d'étranglement est causé par la communication.
analyse de la pile suspendue
Après avoir installé le package avec pip, vous pouvez l'analyser via l'outil de ligne de commande. Par défaut, le noyau imprimera des informations spécifiques sur la pile après plus de 300 secondes. Faites glisser l'image svg dans Chrome pour l'afficher. imprimez la pile correspondante, imprimez les résultats dans stderr du processus de formation. Si vous installez gdb via conda, vous utiliserez l'API python de gdb pour obtenir la pile. Vous pouvez obtenir le nom lwp. Le gdb8.2 installé par défaut ne peut parfois pas être obtenu. gdb. Ce qui suit est une pile de 2 cartes pour simuler le délai d'attente NCCL :

Ce qui suit est un exemple de formation Llama7B sft à 8 cartes sur une seule machine
Grâce aux outils fournis par le package python, le graphique de pile de flammes de la pile d'agrégation peut être généré Ici, vous pouvez voir la pile sans rang 1 car le blocage est simulé en tuant -STOP rang 1 lors d'un entraînement à 8 cartes, donc le rang 1 est dans le. état d'arrêt.
xpu_timer_stacktrace_viewer --path /path/to/stack
运行后会在 path 中生成两个 svg,分别为 cpp_stack.svg, py_stack.svg
Lors de la fusion de piles, nous pensons que le même chemin d'appel peut être fusionné, c'est-à-dire que la trace de pile est complètement cohérente, donc la plupart des endroits bloqués dans le thread principal seront les mêmes, mais s'il y a des boucles et des threads actifs, le imprimé Le haut de la pile peut être incohérent, mais la même pile s'exécutera en bas. Par exemple, les threads de la pile python seront bloqués sur [email protected]. De plus, le nombre d'échantillons dans le graphique de flamme n'a aucune signification. Lorsqu'un blocage est détecté, tous les rangs génèrent les fichiers stacktrace correspondants (le rang 1 est suspendu, donc il n'y en a pas) et chaque fichier contient la pile complète de python/c++.
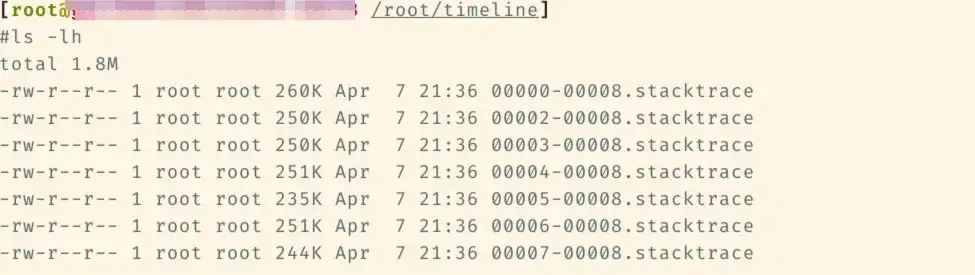
La pile fusionnée est la suivante. Différentes couleurs sont utilisées pour distinguer les catégories de la pile, il ne peut y avoir que du cyan et du vert :
- Cyan est CPython/Python
- Le rouge est lié à C/autre système
- Le vert est Torch/NCCL
- Le jaune est C++

La pile Python est la suivante, le diagramme bleu est la pile spécifique et la règle de dénomination est : func@source_path@stuck_rank|leak_rank
- func est le nom de la fonction actuelle si gdb ne peut pas l'obtenir, il sera affiché ??
- source_path, l'adresse so/source de ce symbole dans le processus
- coincé_rank représente les piles de rangs qui entrent ici. Les numéros de rang consécutifs seront repliés dans le début et la fin, par exemple le rang 0,1,2,3 -> 0-3.
- leak_rank représente les piles qui ne sont pas entrées ici, et le numéro de rang ici sera également plié
Donc, la signification de l'image est que les rangs 0, 2 et 7 sont tous bloqués en synchronisation et que le rang 1 n'entre pas, on peut donc analyser qu'il y a un problème avec le rang 1 (en fait suspendu). Ces informations ne seront ajoutées qu'en haut de la pile

En conséquence, vous pouvez voir la pile de cpp et vous pouvez voir que le thread principal est bloqué en synchronisation, et finalement bloqué sur le temps d'acquisition dans cuda.so. Il n'est également que de rang 1. Sans cette pile, on peut considérer que le. La pile où se trouve __libc_start_main représente le point d'entrée du processus.
De manière générale, on peut considérer qu’il n’y a qu’un seul maillon le plus profond dans la pile. Si une bifurcation se produit, cela prouve que différents rangs sont coincés sur des maillons différents.
Analyse de la pile d'appels du noyau
Contrairement à la chronologie de la torche, la chronologie n'a pas de pile d'appels. Lors de la génération de la chronologie, le nom du fichier de pile correspondant est tracing_kernel_stack.svg. Faites glisser ce fichier dans Chrome pour l'observer.
- Le vert est l'opération NCCL
- Le rouge est l'opération matmul
- Le cyan est la pile Python

Exposition du marché de Grafana
Plan d'avenir
- Ajoutez un traçage plus fin tel que NCCL/eBPF pour analyser et diagnostiquer plus précisément la cause première des problèmes de blocage pendant la formation ;
- Prendra en charge davantage de plates-formes matérielles, notamment diverses cartes graphiques nationales.
À propos de DLRover
DLRover (Distributed Deep Learning System) est une communauté open source maintenue par l'équipe Ant Group AI Infra. Il s'agit d'un système d'apprentissage profond distribué intelligent basé sur la technologie cloud native. DLRover permet aux développeurs de se concentrer sur la conception de l'architecture du modèle sans avoir à s'occuper de détails d'ingénierie, tels que l'accélération matérielle et le fonctionnement distribué. Il développe également des algorithmes liés à la formation en apprentissage profond pour rendre la formation plus efficace et intelligente, comme les optimiseurs. Actuellement, DLRover prend en charge l'utilisation de K8 et Ray pour les opérations automatisées et la maintenance des tâches de formation en apprentissage profond. Pour plus de technologie AI Infra, veuillez prêter attention au projet DLRover.
Rejoignez le groupe d'échange technologique DLRover DingTalk : 31525020959
DLRover Star :
https: // github.com/intelligent-machine-learning/dlrover
Recommandations d'articles
