
Avec le développement de la technologie des grands modèles de langage (LLM), la technologie RAG (Retrieval Augmented Generation) a été largement discutée et étudiée, et des méthodes de récupération RAG de plus en plus avancées ont été découvertes. Par rapport à la récupération RAG ordinaire, le RAG avancé fournit des données plus précises. Des résultats de recherche d'informations plus pertinents et plus riches grâce à des détails techniques plus approfondis et des stratégies de recherche plus complexes. Cet article aborde d'abord ces technologies et présente un cas de mise en œuvre basé sur Milvus.
01.RAG Junior
Définition du RAG primaire
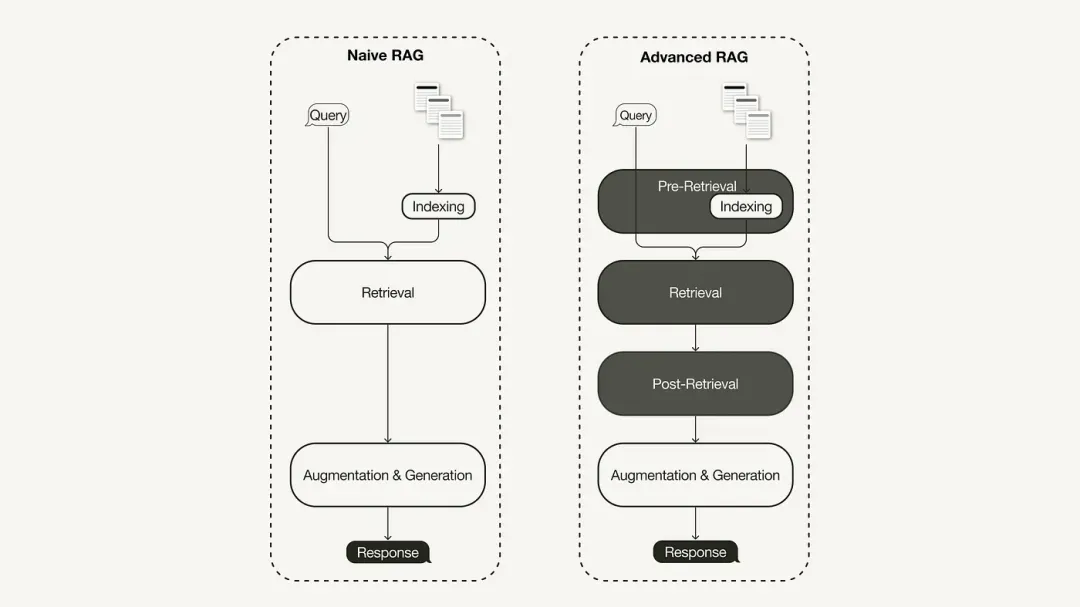
Le paradigme de recherche principal de RAG représente la méthodologie la plus ancienne et a pris de l'importance peu de temps après l'adoption généralisée de ChatGPT. Le RAG primaire suit le processus traditionnel, y compris l'indexation, la récupération et la génération. Il est souvent décrit comme un cadre de « récupération-lecture », et son flux de travail comprend trois étapes clés :
-
Le corpus est divisé en morceaux discrets, et un modèle d'encodeur est ensuite utilisé pour construire des indices vectoriels.
-
RAG identifie et récupère les fragments en fonction de la similarité vectorielle entre les requêtes et les fragments indexés.
-
Le modèle génère des réponses basées sur les informations contextuelles obtenues dans le fragment récupéré.
Limites du RAG primaire
Le RAG primaire est confronté à des défis importants dans trois domaines clés : « récupération », « génération » et « amélioration ».
Il existe de nombreux problèmes avec la qualité de récupération du RAG primaire, tels qu'une faible précision et un faible rappel. Une faible précision peut entraîner un désalignement des blocs récupérés, ainsi que des problèmes potentiels tels que des hallucinations. Un faible taux de rappel entraînera l'incapacité de récupérer tous les blocs pertinents, ce qui entraînera une réponse insuffisamment complète de la part de LLM. De plus, l’utilisation d’informations plus anciennes aggrave encore le problème et peut conduire à des résultats de recherche inexacts.
La qualité des réponses générées est confrontée à des défis illusoires, c'est-à-dire que les réponses générées par LLM ne sont pas basées sur le contexte fourni, ne sont pas pertinentes par rapport au contexte, ou les réponses générées présentent le risque potentiel de contenir un contenu préjudiciable ou discriminatoire.
Au cours du processus d'amélioration, le RAG primaire est également confronté à des défis considérables quant à la manière d'intégrer efficacement le contexte des passages récupérés avec la tâche de génération actuelle. Une intégration inefficace peut entraîner des résultats incohérents ou fragmentés. La redondance et la duplication constituent également un problème épineux, en particulier lorsque plusieurs passages récupérés contiennent des informations similaires et que du contenu en double peut apparaître dans les réponses générées.
02. RAG avancé
Afin de résoudre les lacunes du RAG primaire, le RAG avancé est né et ses fonctions ont été améliorées de manière ciblée. Nous discutons d'abord de ces techniques, qui peuvent être classées en optimisation pré-récupération, optimisation à mi-récupération et optimisation post-récupération.
Optimisation de la pré-recherche
L'optimisation pré-récupération se concentre sur l'optimisation de l'index de données et l'optimisation des requêtes. La technologie d'optimisation de l'index de données vise à stocker les données de manière à améliorer l'efficacité de la récupération :
-
Fenêtre coulissante : utilise le chevauchement entre les blocs de données, c'est l'une des techniques les plus simples.
-
Améliorez la granularité des données : appliquez des techniques de nettoyage des données, telles que la suppression des informations non pertinentes, la confirmation de l'exactitude des faits, la mise à jour des informations obsolètes, etc.
-
Ajoutez des métadonnées : telles que des informations sur la date, l'objectif ou le chapitre pour le filtrage.
-
L'optimisation de la structure de l'index implique différentes stratégies d'indexation des données : comme l'ajustement de la taille des blocs ou l'utilisation d'une stratégie multi-index. Une technique que nous mettrons en œuvre dans cet article est la récupération de fenêtres de phrases, qui intègre des phrases individuelles au moment de la récupération et les remplace par des fenêtres de texte plus grandes au moment de l'inférence.
Optimiser pendant la recherche
La phase de récupération se concentre sur l’identification du contexte le plus pertinent. En règle générale, la récupération est basée sur une recherche vectorielle, qui calcule la similarité sémantique entre la requête et les données indexées. Par conséquent, la plupart des techniques d’optimisation de recherche tournent autour de l’intégration de modèles :
-
Affiner les modèles d'intégration : personnalisez les modèles d'intégration en fonction de contextes de domaine spécifiques, en particulier pour les domaines comportant une terminologie de développement ou rare. Par exemple,
BAAI/bge-small-enil s'agit d'un modèle d'intégration hautes performances qui peut être affiné. -
Intégration dynamique : s'adapte au contexte dans lequel les mots sont utilisés, contrairement à l'intégration statique qui utilise un vecteur par mot. Par exemple, OpenAI
embeddings-ada-02est un modèle d'intégration dynamique complexe qui capture la compréhension contextuelle. En plus de la recherche vectorielle, il existe d'autres techniques de récupération, telles que la recherche hybride, qui fait généralement référence au concept de combinaison de la recherche vectorielle avec la recherche par mot-clé. Cette technique de recherche est utile si la recherche nécessite des correspondances exactes de mots clés.
Optimisation post-récupération
Pour le contenu contextuel récupéré, nous rencontrerons du bruit tel que le contexte dépassant la limite de la fenêtre ou le bruit introduit par le contexte, qui détournera l'attention des informations clés :
-
Compression des invites : réduisez la longueur globale des invites en supprimant le contenu non pertinent et en mettant en évidence le contexte important.
-
Reclassement : utilisez un modèle d'apprentissage automatique pour recalculer le score de pertinence du contexte récupéré.
Les techniques d'optimisation post-recherche incluent :
03. Implémenter un RAG avancé basé sur Milvus + LlamaIndex
Le RAG avancé que nous avons implémenté utilise le modèle de langage d'OpenAI, le modèle de réarrangement BAAI hébergé sur Hugging Face et la base de données vectorielles Milvus.
Créer un index Milvus
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext
vector_store = MilvusVectorStore(dim=1536,
uri="http://localhost:19530",
collection_name='advance_rag',
overwrite=True,
enable_sparse=True,
hybrid_ranker="RRFRanker",
hybrid_ranker_params={"k": 60})
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes,
storage_context=storage_context
)
Exemple d'optimisation d'index : récupération de fenêtre de phrase
Nous utilisons SentenceWindowNodeParser dans LlamaIndex pour implémenter la technologie de récupération de fenêtre de phrases.
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
SentenceWindowNodeParser effectue deux opérations :
Il sépare le document en phrases distinctes, qui sont intégrées.
Pour chaque phrase, il crée une fenêtre contextuelle. Si vous spécifiez window_size = 3, alors la fenêtre résultante contiendra trois phrases, en commençant par la phrase précédant la phrase intégrée et en s'étendant jusqu'à la phrase qui la suit. Cette fenêtre sera stockée sous forme de métadonnées. Lors de la récupération, la phrase qui correspond le mieux à la requête est renvoyée. Après récupération, vous devez remplacer la phrase par la fenêtre entière à partir des métadonnées en définissant a MetadataReplacementPostProcessoret en l'utilisant dans la liste.node_postprocessors
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
Exemple d'optimisation de la recherche : recherche hybride
La mise en œuvre de la recherche hybride dans LlamaIndex ne nécessite que deux modifications de paramètres dans le moteur de requête, à condition que la base de données vectorielles sous-jacente prenne en charge les requêtes de recherche hybrides. La version 2.4 de Milvus ne prenait pas en charge la recherche hybride auparavant, mais dans la version 2.4 récemment publiée, cette fonctionnalité est déjà prise en charge.
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", #Milvus 2.4开始支持, 在2.4版本之前使用 Default
)
Exemple d'optimisation post-récupération : reclassement
L'ajout d'un reclassement au RAG avancé ne nécessite que trois étapes simples :
Tout d’abord, définissez un modèle de reclassement à l’aide de Hugging Face BAAI/bge-reranker-base.
Dans le moteur de requête, ajoutez le modèle de réapprovisionnement à node_postprocessorsla liste.
Augmentation du moteur de requête similarity_top_kpour récupérer plus de fragments de contexte, qui peuvent être réduits à top_n après réarrangement.
from llama_index.core.postprocessor import SentenceTransformerRerank
rerank = SentenceTransformerRerank(
top_n = 3,
model = "BAAI/bge-reranker-base"
)
...
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors = [rerank],
...,
)
Pour le code d'implémentation détaillé, veuillez vous référer au lien Baidu Netdisk : https://pan.baidu.com/s/1Cj_Fmy9-SiQFMFNUmO0OZQ?pwd=r2i1 Code d'extraction : r2i1
Les ressources piratées de "Qing Yu Nian 2" ont été téléchargées sur npm, obligeant npmmirror à suspendre le service unpkg. Zhou Hongyi : Il ne reste plus beaucoup de temps à Google. Je suggère que tous les produits soient open source. time.sleep(6) joue ici un rôle. Linus est le plus actif dans la « consommation de nourriture pour chiens » ! Le nouvel iPad Pro utilise 12 Go de puces mémoire, mais prétend disposer de 8 Go de mémoire. Le People's Daily Online examine la charge de type matriochka des logiciels de bureau : Ce n'est qu'en résolvant activement « l'ensemble » que nous pourrons avoir un avenir avec Flutter 3.22 et Dart 3.4 . nouveau paradigme de développement pour Vue3, sans avoir besoin de « ref/reactive », pas besoin de « ref.value » Publication du manuel chinois MySQL 8.4 LTS : vous aider à maîtriser le nouveau domaine de la gestion de bases de données Tongyi Qianwen niveau GPT-4 prix du modèle principal réduit de 97%, 1 yuan et 2 millions de jetons