
Bonjour à tous, je m'appelle Wang Chunxiao du Shandong Provincial Computing Center (National Supercomputing Jinan Center). Je participe à des projets Internet de supercalcul depuis 2022. Je suis principalement responsable de la recherche et du développement d'une plateforme de stockage unifiée pour les réseaux informatiques, et je J'ai également travaillé sur les bases de stockage. Après de nombreuses recherches, j'ai finalement choisi la plateforme Alluxio. Après plus d'un an de travail acharné, j'ai fait des progrès. Je suis très reconnaissant à Alluxio pour son soutien et son aide.
Ensuite, nous nous concentrerons sur le thème du supercalcul Internet et partagerons avec vous sous trois aspects :
(1) Problèmes et défis existant dans la construction d’un Internet de calcul intensif ;
(2) Recherche sur les technologies clés de la plate-forme de stockage unifiée Internet de supercalcul ;
(3) Application et développement futur de l'Internet de calcul intensif
1. Problèmes et défis dans la construction d'un Internet de calcul intensif

Tout d'abord, permettez-moi de présenter brièvement le National Supercomputing Jinan Center. Il a été fondé en 2011 et est le berceau du serveur national « Sunway Blu-ray » de mon pays. Bien sûr, la taille de Sunway Blu-ray est maintenant passée de pétaflops. exascaler. À partir de 2019, nous avons commencé à développer et à construire une plateforme universelle basée sur la plateforme nationale. Autrement dit, la plate-forme Sunward Supercomputing, dont le CPU, le GPU et la bande passante de stockage ont atteint une échelle considérable, joue un rôle de soutien important dans de nombreuses industries de la province du Shandong.
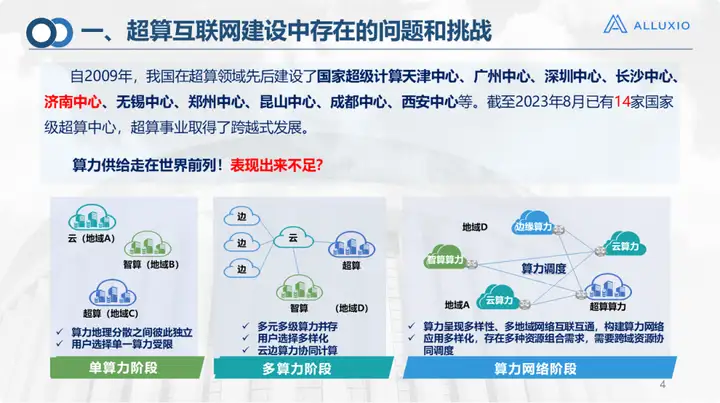
Depuis 2009, notre pays a successivement créé de nombreux centres de calcul intensif. D'ici août 2023, notre pays disposera de 14 centres de calcul intensifs au niveau national, de plus de 30 centres de calcul intelligents et de plus de 500 grands centres de données cloud. Avec une telle taille, il est également à la pointe de l’alimentation informatique mondiale.
De nos jours, avec l’augmentation de la demande de grands modèles et bien d’autres choses, certaines carences en puissance de calcul ont également été révélées. Ceci est indissociable de la complexité de notre développement d'applications : les applications d'aujourd'hui ne peuvent plus être résolues par la seule puissance de calcul. Dans le passé, il suffisait de prendre quelques données et un modèle et de les exécuter sur une certaine ressource. Nous sommes désormais à l’étape de la puissance de calcul multiple. Dans certains scénarios d’applications à relativement grande échelle, il existe des exigences en matière d’échelle et de type de puissance de calcul et de stockage. Par exemple, l'informatique convergée telle que le cloud computing, le calcul haute performance et l'IA, ainsi que le scénario d'informatique à l'est et à l'ouest proposé par notre pays, il est en fait difficile de résoudre le problème si nous simplement augmenter la puissance de calcul ou le stockage dans une certaine zone. Bien sûr, il existe des différences régionales dans la demande de puissance de calcul et la répartition des ressources de la Chine. C'est également l'intention initiale de la proposition de la Chine de construire un Internet de supercalcul.

En avril 2023, le ministère de la Science et de la Technologie a lancé les travaux de construction d'un Internet national de supercalcul afin de construire un réseau électrique intégré de supercalcul et une plate-forme de services. Le Centre national de calcul intensif de Jinan est également l'une des unités Internet de calcul intensif. Ce qu'il fait actuellement, c'est mener une gestion unifiée des ressources, un contrôle et une coordination du stockage et des réseaux de puissance de calcul à grande échelle afin d'obtenir une disposition optimale des ressources.
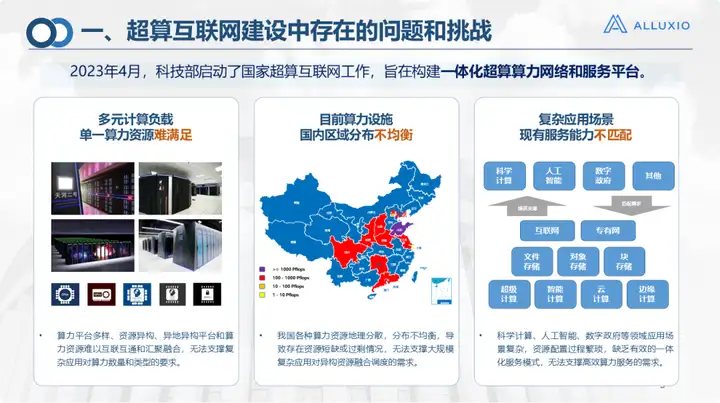
Le Centre national de calcul intensif de Jinan planifie et construit un Internet de calcul intensif depuis 2016 et a réalisé des travaux à tous les niveaux. Bien entendu, de nombreux problèmes se posent également lors de la construction et de l’application de réseaux de puissance de calcul.
1. Le premier est la question des plates-formes de puissance de calcul diversifiées, y compris l'émergence sans fin de diverses plates-formes cloud, plates-formes d'IA et plates-formes de stockage ;
2. Le deuxième est le problème des ressources hétérogènes, y compris les normes de puces des groupes nationaux, qui sont très différentes, et les systèmes de stockage ont également diverses interfaces, qui sont très dispersées, ont des structures complexes et ont de nombreux protocoles, ce qui rend difficile la réalisation. interconnexion et interopérabilité, une plate-forme unifiée doit être construite ;
3. Le troisième problème est la répartition inégale de la puissance de calcul, qui constitue un problème courant dans notre pays. En prenant la province du Shandong comme exemple, l'informatique est à Jinan et le stockage est à Zibo. S'il y a un goulot d'étranglement dans le réseau intermédiaire, il est fondamentalement difficile de réaliser un montage, un appel ou même une transmission à distance.
Il existe également des scénarios d'application complexes, tels que les domaines de la télédétection météorologique marine, dont les procédures d'exploitation sont relativement complexes. Les données peuvent être stockées à un endroit et doivent être transférées à un autre endroit pour le prétraitement des données, la simulation, la formation du modèle et la formation des modèles. d'autres opérations. , mais ces opérations peuvent devoir être effectuées sur différentes plateformes, voire dans différentes régions, il est difficile de travailler sans une plateforme de services intégrée, et il est difficile de maîtriser l'utilisation de toutes ces plateformes. problèmes et défis C'est également ce que nous devons résoudre lors de la construction du cœur de l'Internet de calcul intensif.
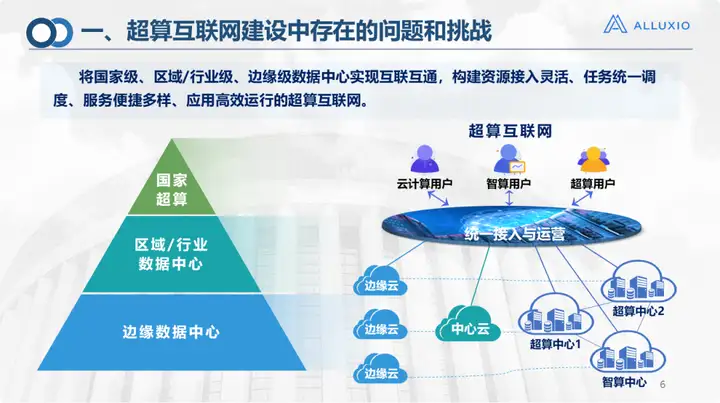
Il s'agit du cadre de l'Internet de calcul intensif, permettant aux centres de données nationaux, au niveau de l'entreprise/régional et à la périphérie de réaliser l'interconnexion et la classification hiérarchique. L'interopérabilité vise à permettre un accès et un fonctionnement relativement simples et unifiés à la puissance de calcul, au stockage et aux réseaux. Elle peut circuler comme l'eau et l'électricité et être fournie aux niveaux supérieurs pour être utilisée par différents utilisateurs. Certains sont même des utilisateurs mixtes : par exemple, un algorithme doit utiliser à la fois la haute performance et l'IA. C'est aussi notre objectif de construction.
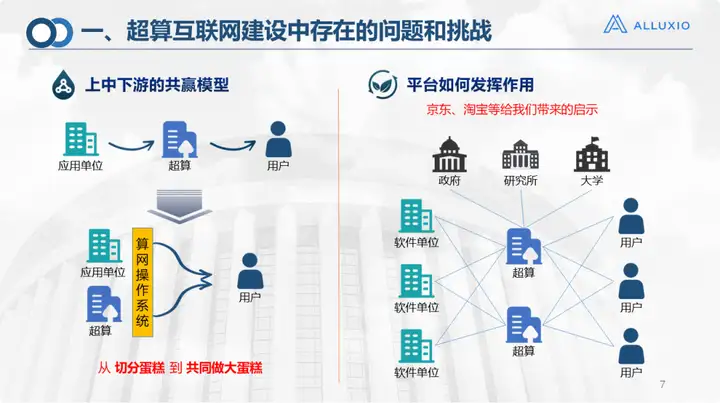
Il s’agissait à l’époque de la chaîne industrielle pour le développement de l’Internet de calcul intensif. Dans le passé, les utilisateurs utilisaient la puissance de calcul, le stockage et les logiciels via des supercalculateurs ou des centres de données, et il existait une unité d'application tierce. Nous avons maintenant ajouté une couche au milieu, avec trois couches de définitions supérieure, intermédiaire et aval : les unités d'application et les supercalculateurs de la première couche servent de fournisseurs de ressources parallèles, et le système d'exploitation du réseau de supercalcul sert de couche intermédiaire pour fournir puissance de calcul et réseau de stockage correspondants. Le modèle opérationnel peut faire référence à des plateformes telles que JD.com et Taobao, qui peuvent être utilisées comme plateforme intermédiaire. Comme JD.com et Taobao, ils vendent des biens, mais ce que nous exploitons est une ressource, qui est un modèle qui passe de la coupe du gâteau à la préparation du gâteau ensemble.
2. Recherche sur les technologies clés de la plate-forme de stockage unifiée Internet de supercalcul
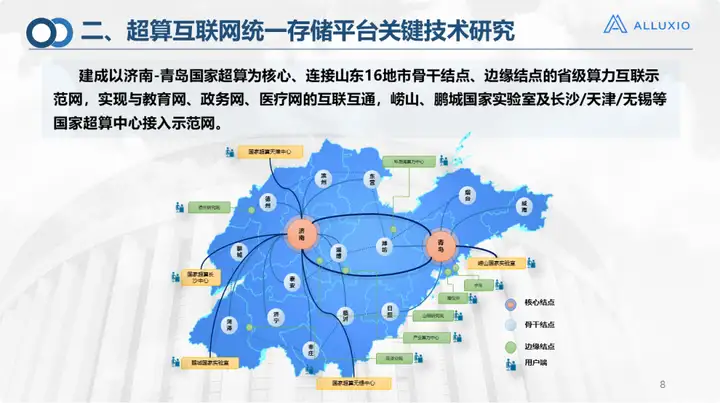
Telle est la situation actuelle de la construction de l'Internet de superinformatique. Il a d'abord été testé dans le Shandong, couvrant 16 villes de la province du Shandong, dont les deux nœuds centraux de Jinan et Qingdao, qui fonctionnent désormais via une interconnexion à haut débit, et les villes restantes. sont Utilisez des lignes dédiées. Il existe également 30 nœuds périphériques qui peuvent être connectés via sdone ou Internet. Dans le même temps, nous nous sommes également connectés à 28 clusters informatiques et 45 systèmes de stockage de 7 types. La plate-forme unifiée du système de stockage est construite avec Alluxio. C'est l'échelle de notre première version du système d'exploitation réseau de supercalcul. Actuellement, la couche supérieure prend en charge trois types de services : le cloud computing, le HPC et l'IA. Il fournit principalement des ressources sous trois aspects :
1. Ressources informatiques ;
2. Ressources de stockage ;
3. Ressources réseau.
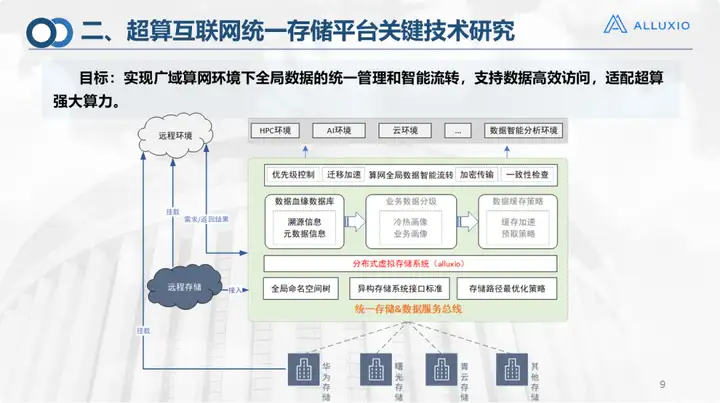
Parce que je suis principalement responsable de la plate-forme de stockage unifiée, je me concentrerai sur la présentation de la plate-forme de stockage unifiée. C'est le schéma du cadre de conception à ce moment-là. Vous pouvez voir l'objectif de la plate-forme de stockage unifiée. il s'agit de n'importe quel type de stockage en bas ou sur le cloud. Nous devons tous gérer le stockage. La couche qui gère le système de stockage utilise Alluxio comme base de stockage. Sur cette base, nous avons également effectué quelques travaux d'optimisation, notamment l'optimisation des chemins, la stratégie de migration des données, la transmission cryptée, le contrôle de cohérence, etc. Certains d'entre eux sont encore en cours de vérification et n'ont pas été ajoutés à la première version. plan global.
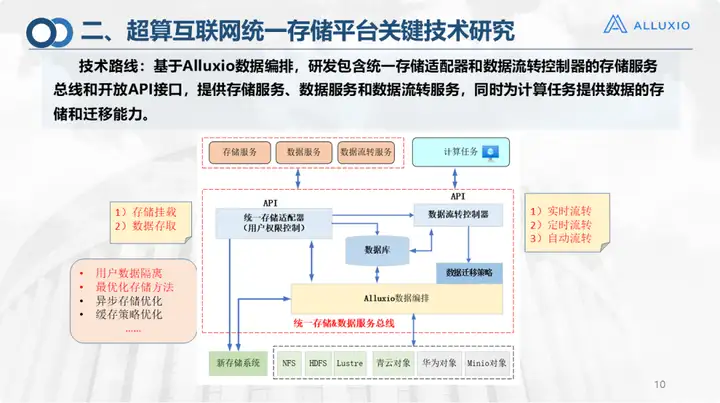
Cette image montre que la technologie de base de la plate-forme de stockage unifiée est la conception du bus de service. Je l'ai retirée séparément car nous avons développé un adaptateur de stockage unifié et un contrôleur de flux de données sur la couche supérieure basés sur Alluxio, et intégré trois stratégies de circulation : diffusion en temps réel, diffusion programmée et diffusion automatique. Il fournit également des services de stockage, de données et de transfert de données pour ce portail de calcul de code (le portail principal ci-dessus), et peut fournir des fonctions d'interface et de montage. À l’instar de l’adaptateur de stockage unifié, nous pouvons actuellement :
1. Montage de stockage automatique ;
2. Plusieurs façons d'accéder aux données, notamment l'interface, le client et la ligne de commande, sont toutes prises en charge.
Bien entendu, nous avons également effectué des recherches sur l’isolation des données utilisateur et les méthodes de stockage optimales, qui ont déjà été intégrées. Le contrôleur de flux de données effectue beaucoup de travail et dispose de trois stratégies de flux :
1. Le transfert en temps réel est principalement destiné aux utilisateurs, car les utilisateurs demandent un espace de stockage à Jinan et un espace de stockage à Qingdao sur notre plateforme. S'ils souhaitent migrer les données en temps réel, l'utilisateur spécifie l'adresse d'origine. et la cible de la migration, sélectionnez la vitesse de transfert et faites correspondre automatiquement la stratégie de migration. Nous avons également effectué des recherches sur des modèles intelligents pour calculer le temps d'exécution des tâches dans différents états et sélectionner la stratégie optimale.
2. Le transfert programmé est actuellement destiné aux scénarios océaniques et campus. Par exemple, les données sur site dans les écoles ou sur l'océan sont à la limite, car certaines d'entre elles sont des données vidéo et l'échelle des données est particulièrement grande. Si vous souhaitez effectuer des recherches et sauvegarder, il n'existe en fait pas de périphérique de stockage de ce type à la périphérie. Sans une telle quantité de périphériques de stockage, vous devrez peut-être effectuer une migration de données planifiée chaque semaine. Configurez l'adresse source de migration et l'adresse cible spécifiées dans un délai défini. Nous utilisons également le modèle intelligent pour sélectionner la stratégie optimale en fonction du temps et du délai de la tâche. Vous pouvez choisir de le faire la nuit ou lorsque le trafic réseau est relativement faible.
3. Le transfert automatique est également une fonctionnalité qui consiste à sélectionner intelligemment les données et l'emplacement à migrer en fonction du moteur de règles. Il peut exister de nombreux scénarios de ce type. Nous en avons personnalisé plusieurs et vous trouverez plus loin une introduction aux scénarios de flux automatique. Il est jugé selon que les données sont stockées et calculées séparément. Par exemple, si elles sont stockées dans Zibo et que je souhaite les calculer à Jinan, si les conditions du réseau ne permettent pas à l'utilisateur d'être d'accord, nous pouvons automatiquement les migrer vers. lui. Bien entendu, vous pouvez déterminer si les données sont préextraites en combinant le mode d'accès de la base de données de métadonnées et la fréquence d'accès aux données du hotspot.
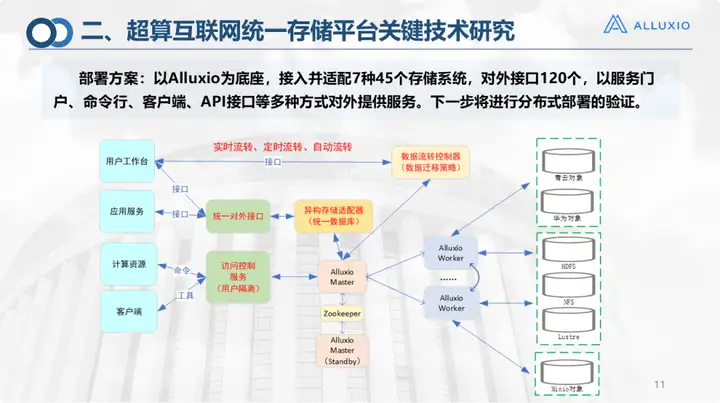
Il s'agit de notre plan de déploiement, qui est actuellement connecté aux systèmes de stockage répertoriés dans la figure, y compris Alibaba Cloud. Il existe environ 130 interfaces externes, qui peuvent fournir des services externes via la ligne de commande du portail de services, le client, l'API, etc. Nous suivons toujours le déploiement classique d'Alluxio pour le déploiement actuel. À un stade ultérieur, nous espérons parvenir à un déploiement distribué : actuellement, en raison des restrictions du réseau, toutes les exportations sont concentrées à Jinan. Bien que 16 villes aient déjà créé China Unicom, les exportations n'ont pas encore été libéralisées. Par exemple, la connexion entre Qingdao et Zibo n’a pas été entièrement testée. Dans de telles circonstances, cette disposition ne pose aucun problème. Tout le stockage doit être déployé et appelé par la plate-forme générale Alluxio Master Jinan lorsqu'il est utilisé. Si d'autres réseaux sont libéralisés, j'espère que si l'informatique est à Qingdao, le stockage le sera également. à Qingdao, peut réaliser un montage local sans avoir à avertir le maître à Jinan pour le laisser faire l'allocation. Cela ajoute en fait une étape supplémentaire, nous effectuons donc également des tests et une vérification du déploiement distribué.
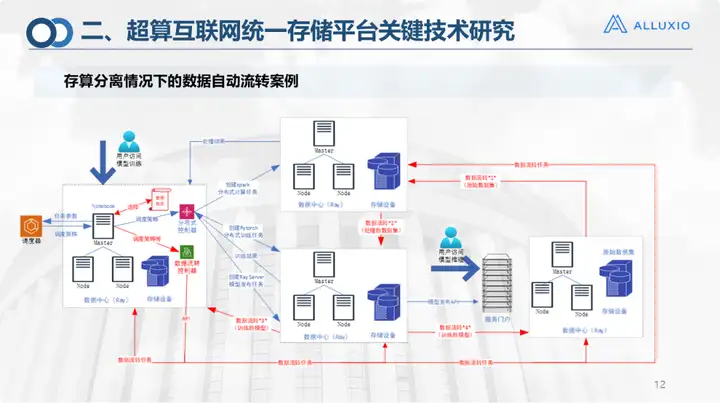
Il s'agit d'un cas de transfert automatique de stockage et de séparation des calculs. Bien entendu, c'est aussi le scénario réel du campus intelligent actuel.
Nos périphériques de stockage et nos ressources informatiques ont tous été gérés sur une plateforme de stockage unifiée et une plateforme cloud, appelée plateforme de gestion multi-cloud. Dans ce cas, notre système d'exploitation de réseau informatique aura un calendrier global. Dans cet environnement, toutes les données existent actuellement dans le centre de données le plus à droite et l'utilisateur se trouve à Jinan ou soumet des tâches de formation. la plate-forme principale. , après la soumission, il y aura un calendrier général pour déterminer où se trouvent les ressources informatiques, l'environnement de pré-formation et l'environnement de formation pour délimiter les emplacements et générer des ressources, car ce conteneur doit être généré automatiquement en fonction de la demande, et sera généré en fonction de la vue des données (la nôtre dans Alluxio Une couche de vue des données est créée ci-dessus). Selon la vue des données et le contrôleur de flux de données, les données sont migrées de l'adresse d'origine vers l'adresse cible pour la formation. Pour ce scénario, quatre flux sont en réalité requis :
√ Passer de l'ensemble de données d'origine à la formation dans l'environnement de pré-traitement de pré-formation ;
√ Après le traitement, vous devez vous rendre dans l'environnement de formation pour suivre une formation ;
√ Enfin, le modèle doit être renvoyé à l'utilisateur ;
√ Si l'utilisateur le configure, il doit être renvoyé à la scène finale (comme un campus) avant d'effectuer des opérations d'inférence.
Par conséquent, nous avons spécifié le processus de circulation dans plusieurs scénarios industriels spécifiques.
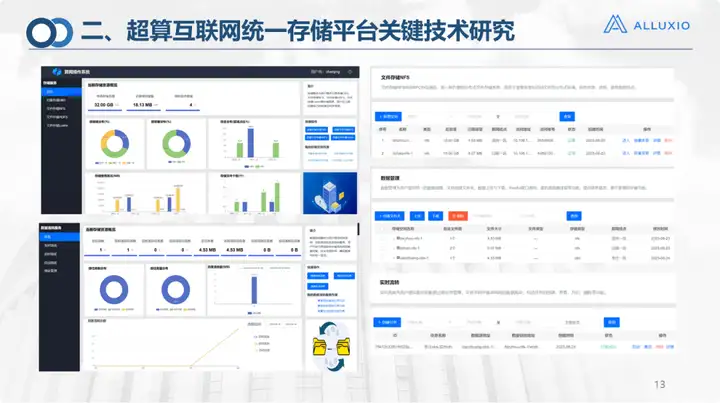
Il s'agit de l'interface actuelle de notre plateforme de stockage unifié V1.0. Il a été publié sur le portail principal, y compris le portail de services et le portail de gestion. Le portail de services comprend un total de 6 modules et plus de 20 sous-modules.
Pour la plateforme de stockage unifié, nous avons encore du travail de suivi à poursuivre : notamment le déploiement distribué des nœuds Alluxio Master et la gestion unifiée de la planification sur sa couche supérieure. Ensuite, il y a la prélecture des données, qui correspond à l'optimisation du mécanisme de mise en cache des données, y compris la conception de la prélecture, des règles d'association et, plus important encore, nous souhaitons effectuer un stockage hiérarchisé, ce que nous devrons faire plus tard.
3. Application et développement futur de l'Internet par calcul intensif

Ce qui suit présente les applications actuelles du supercalcul Internet dans diverses industries :
Nous nous concentrerons sur le développement de l'Internet de calcul intensif au cours du second semestre 2022, mais en fait, nous en avons tracé le schéma depuis 2016, nous avons donc déjà quelques applications dans de nombreux secteurs : notamment les océans, les matériaux, la météorologie et la protection de l'environnement. écologie, simulation industrielle, éducation et autres aspects.
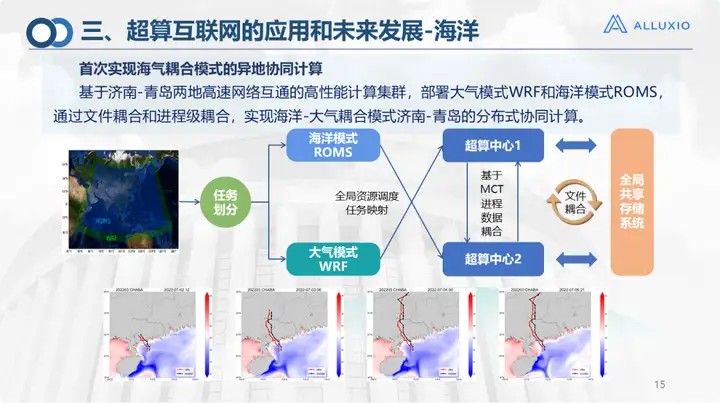
Il s'agit du modèle de couplage océanique, qui est un réseau interconnecté que nous avons construit conjointement avec le laboratoire de Laoshan. Comme vous pouvez le constater, les calculs dans l'océan peuvent être relativement compliqués. Des calculs de modèles océaniques et des calculs de modèles atmosphériques sont nécessaires. Le modèle atmosphérique actuel est réalisé sur le supercalculateur de Qingdao, et le modèle océanique est réalisé sur le supercalculateur de Jinan, puis le couplage de fichiers est effectué. C'est la première fois que nous mettons en œuvre l'informatique collaborative à distance en 2023, et nous obtenons de bons résultats.

Dans le domaine de la télédétection, nous disposons également d'un scénario de flux de données relativement complet. Il s'agit des données du Centre national de données scientifiques d'observation de la Terre : elles sont d'abord transmises au supercalculateur de Jinan via une ligne dédiée, puis stockées dans des fichiers de blocs. grâce à certaines opérations de tri et de stockage. Dans le stockage tel que les objets, les produits de données sont produits et partagés après traitement. Il s'agit également de notre premier système de collecte et de traitement de données qui sépare le stockage et le calcul inter-domaines. Nous avons également demandé la création du Centre national de dépôt et de calcul d'observation de la Terre.
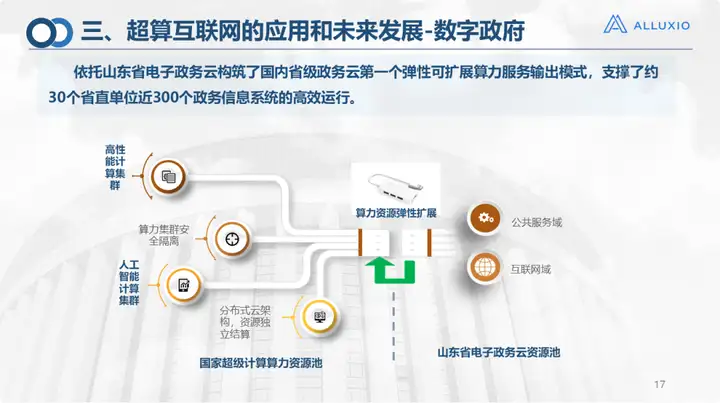
Dans le domaine du gouvernement numérique, étant donné que l'administration électronique elle-même fait partie de notre unité, nous soutenons actuellement le fonctionnement efficace de 30 unités provinciales et de 300 systèmes gouvernementaux dans la province du Shandong. Bien entendu, il s'agit principalement d'opérations sur le cloud. ressources Expansion élastique.
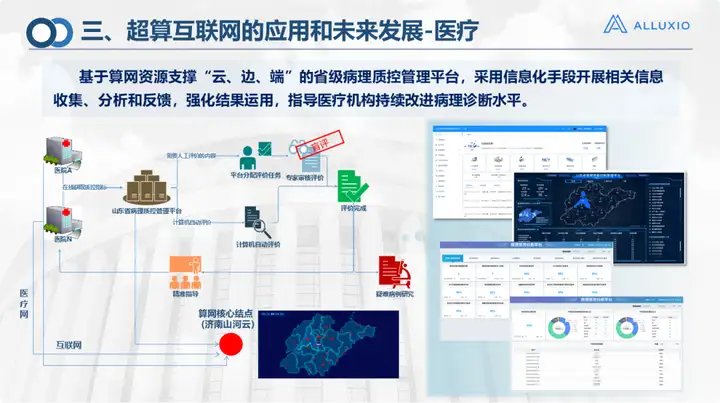
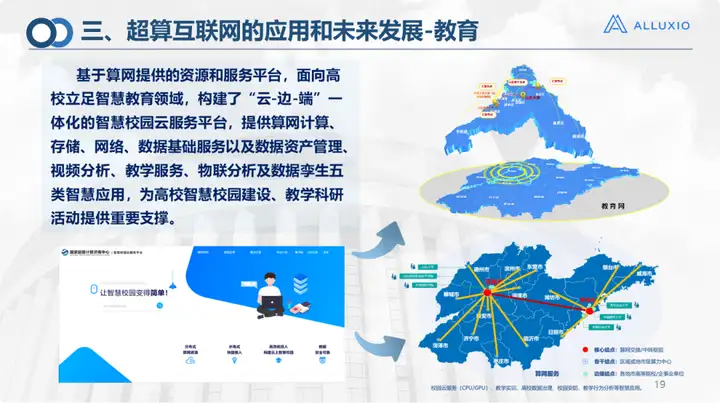
Dans des domaines tels que les soins médicaux et l’éducation, le travail dans le cloud et en périphérie est principalement effectué. Il s'agit du réseau de calcul et de stockage fourni par Suanwang, y compris le transfert programmé mentionné ci-dessus. Dans le scénario de campus intelligent, nous avons réalisé le projet de l'Université de technologie de Qilu, et nous avons fait davantage dans les scénarios d'application de campus.
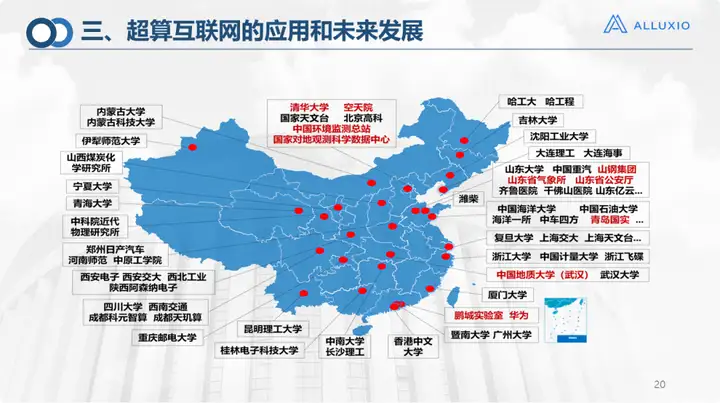
Enfin, permettez-moi de vous présenter l'entreprise. Nos applications couvrent plus de 2 000 entreprises/universités/institutions à travers le pays et ont également reçu une large reconnaissance au pays et à l'étranger. Je pense qu'il est en fait nécessaire de construire un réseau de puissance de calcul, qui contribuera à revitaliser notre stock actuel de ressources de puissance de calcul. Si nous disposons d'un Internet de calcul intensif, nous devrions améliorer l'utilisation des ressources informatiques, permettre la monétisation de la puissance de calcul et permettre aux centres de puissance de calcul, aux centres de calcul intensif et à d'autres centres de données de fonctionner de manière durable et saine, et dans certains écosystèmes de calcul intensif, il a mieux applications dans les domaines de la protection de l’environnement, des océans et de la télédétection, et je pense qu’il y aura des scénarios d’application plus larges à l’avenir.
