このコラムは、YangXiuzhangのクローラーブック「PythonWebData Crawling and Analysis "From Beginner to Proficiency"」をメインラインとして、個人的な学習と理解をメインコンテンツとして、スタディノートの形式で記述したものに基づいています。
このコラムは、私自身の研究と共有であるだけでなく、クローラーに関する知識を広め、クローラーの簡単なアイデアを提供したいと考えています。
列アドレス:Python Webデータのクロールと分析「エントリから習熟まで」
クローラーのその他の例については、列:Pythonクローラースレッジハンマーテストを参照してください。

前回の記事レビュー:
「Pythonクローラーシリーズの説明」1.ネットワークデータクロールの概要
「Pythonクローラーシリーズの説明」2.Python知識初心者
「Pythonクローラーシリーズの説明」3.正規式クローラーのスラッシャーテスト
目次
1BeautifulSoupをインストールしてインポートします
1BeautifulSoupをインストールしてインポートします
BeautifulSoupは、HTMLまたはXMLファイルからデータを抽出できるPython拡張ライブラリであり、HTMLまたはXMLファイルを分析するパーサーです。検証済みのコンバーターを介してドキュメントのナビゲーション、検索、およびドキュメントの変更を実装します。不規則なマークを処理して解析ツリー(Parse Tree)を生成できます。提供されているナビゲーション機能(Navigation)は、解析ツリーを簡単かつ迅速に検索し、解析を変更できます。木。
BeautifulSoupテクノロジーは通常、Webページの構造を分析し、対応するWebドキュメントをクロールし、不規則なHTMLドキュメントに特定の補完機能を提供するために使用されます。これにより、開発者の時間と労力を節約できます。
pipコマンドは、主にPython3.xにBeautifulSoupをインストールするために使用されます。
pip install BeautifulSoup4注:BeautifulSoupには、BeautifulSoup 3(開発中止)とBeautifulSoup 4(bs4と略記)の2つの一般的に使用されるバージョンがあります。
BeautifulSoupは、Python標準ライブラリのHTMLパーサーと、いくつかのサードパーティパーサーをサポートしています。
それらの1つはlxmlです
pip install lxml別の代替パーサーは、純粋なPythonで実装されたhtml5libです。
pip install html5lib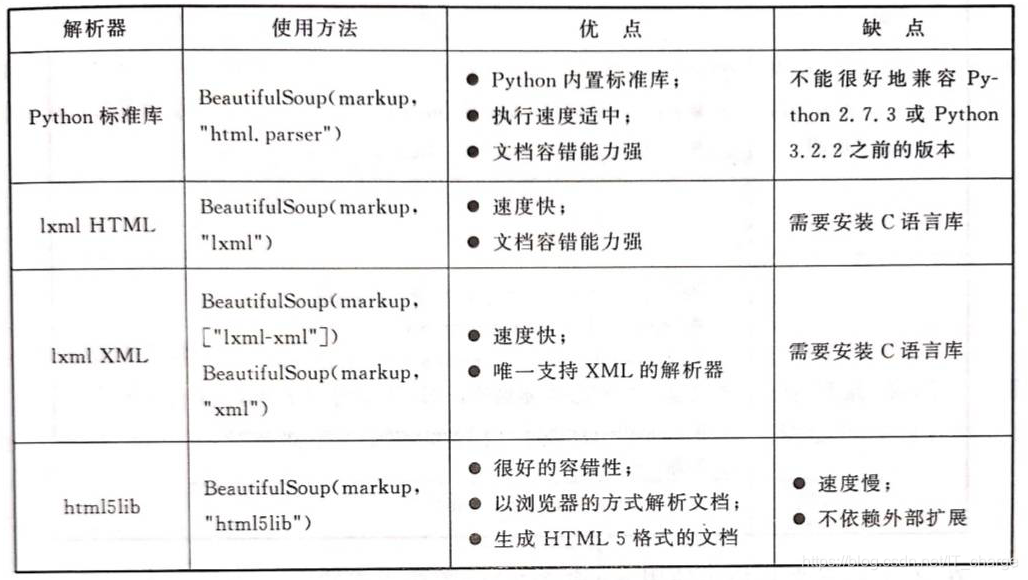
インストールが成功したら、次のようにBeautifulSoupライブラリをプログラムにインポートします。
from bs4 import BeautifulSoup2BeautifulSoupの解析をすばやく開始します
まず、BeautifulSoupの使用法を紹介する例としてhtmlファイルを紹介します
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>BeautifulSoup 技术</title>
</head>
<body>
<p class="title"><b>静夜思</b></p>
<p class="content">
床前明月光,<br/>
疑是地上霜。<br/>
举头望明月,<br/>
低头思故乡。<br/>
</p>
<p class="other">
李白(701年-762年) ,字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%94%AB/63508" class="poet" id="link1">杜甫</a>
并称为“李杜”,为了与另两位诗人
<a href="https://baike.baidu.com/item/%E6%9D%8E%E5%95%86%E9%9A%90/74852" class="poet" id="link2">李商隐</a>
与<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%89%A7" class="poet" id="link3">杜牧</a>
即“小李杜”区别,杜甫与李白又合称“大李杜”。
据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。
其人爽朗大方,爱饮酒作诗,喜交友。
</p>
</body>
</html>次の図に示すように、ブラウザからWebページを開きます。

2.1BeautifulSoupはHTMLを解析します
# 通过解析HTML代码,创建一个 BeautifulSoup 对象,然后调用 prettify() 函数格式化输出网页
from bs4 import BeautifulSoup
html = '''
<html lang="en">
<head>
<meta charset="UTF-8">
<title>BeautifulSoup 技术</title>
</head>
<body>
<p class="title"><b>静夜思</b></p>
<p class="content">
床前明月光,<br/>
疑是地上霜。<br/>
举头望明月,<br/>
低头思故乡。<br/>
</p>
<p class="other">
李白(701年-762年) ,字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%94%AB/63508" class="poet" id="link1">杜甫</a>
并称为“李杜”,为了与另两位诗人
<a href="https://baike.baidu.com/item/%E6%9D%8E%E5%95%86%E9%9A%90/74852" class="poet" id="link2">李商隐</a>
与<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%89%A7" class="poet" id="link3">杜牧</a>
即“小李杜”区别,杜甫与李白又合称“大李杜”。
据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。
其人爽朗大方,爱饮酒作诗,喜交友。
</p>
'''
# 按照标准的所进行时的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
前に定義したHTMLコードソースタグに終了タグがないこと、具体的には</ body>タグと</ html>タグがないことを指摘する価値がありますが、prettify()関数の出力は自動的に完了します。タグ、これBeautifulSoupの利点です。
BeautifulSoupが破損したタグを取得した場合でも、元のドキュメントコンテンツの意味と可能な限り一致するDOMツリーを生成します。この方法は通常、ユーザーがデータをより正確に収集するのに役立ちます。
さらに、ローカルHTMLファイルを使用してBeautifulSoupオブジェクトを作成できます
soup = BeautifulSoup(open('t.html'))2.2Webページのタグ情報への簡単なアクセス
BeautifulSoupを使用してWebページを解析する場合、特定のタグ間の情報を取得したい場合があります。具体的なコードは次のとおりです。
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
# 获取标题
title = soup.title
print('标题:', title)
# 获取头部
head = soup.head
print('头部:', head)
# 获取 a 标签
a = soup.a
print('超链接内容:', a)
# 获取 p 标签
p = soup.p
print('超链接内容:', p)
2.3タグを見つけてコンテンツを取得する
次のコードは、Webページのすべてのハイパーリンクタグと対応するURLコンテンツを実現します
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
# 从文档中找到 <a> 的所有标签链接
for a in soup.find_all('a'):
print(a)
# 获取 <a> 的超链接
for link in soup.find_all('a'):
print(link.get('href'))
# 获取文字内容
for poeter in soup.find_all('a'):
print(poeter.get_text())
3BeautifulSoupの深い理解
3.1BeautifulSoupオブジェクト
BeautifulSoupは、複雑なHTMLドキュメントをツリー構造に変換します。各ノードはPythonオブジェクトです。公式のBeautifulSoupドキュメントは、すべてのオブジェクトを4つのタイプに要約します。
- 鬼ごっこ;
- NavigableString;
- BeautifulSoup;
- コメント。
3.1.1タグ
Tagオブジェクトは、XMLまたはHTMLドキュメントのタグを表します。素人の用語ではHTMLのタグになります。このオブジェクトは、HTMLまたはXMLネイティブドキュメントのタグと同じです。タグには多くのメソッドと属性があります。BeautifulSoupはSoup.Tagとして定義されます。ここで、Tagは、ヘッド、タイトルなどのHTMLのタグであり、タグの属性とコンテンツを含む、結果の完全なタグコンテンツを返します。
<title>BeautifulSoup 技术</title>
<p class="title"><b>静夜思</b></p>
<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%89%A7" class="poet" id="link3">杜牧</a>たとえば、上記のコードでは、title、p、aなどはすべてタグであり、開始タグ(<title>、<p>、<a>)と終了タグ(</ title>、</ p>、< / a>)タグの間にコンテンツを追加します。タグ取得方法コードは以下のとおりです。
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.title)
print(soup.head)
print(soup.p)
print(soup.a)
返されるコンテンツは、要件を満たす最初のコンテンツであることに注意してください。
明らかに、タグとタグコンテンツは、BeautifulSoupオブジェクトを介して簡単に取得できます。これは、3番目の講義の正規表現よりもはるかに便利です。
# 该段代码输出的是该对象的类型,即Tag对象
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(type(soup.html))
多くのタグ属性とメソッドがあり、そのうち2つの最も重要な属性はnameとattrsです。
(1)名前
name属性は、ドキュメントツリーのラベル名を取得するために使用されます。ヘッドタグ名を取得したい場合は、soup.head.nameコードを使用してください。内部タグの場合、出力値はタグ自体の名前です。BeautifulSoupオブジェクトはかなり特別で、その名前はdocumentです。
print(soup.name)
print(soup.head.name)
print(soup.title.name)
(2)attrs
タグ(タグ)には、たとえば複数の属性があります。
<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%94%AB/63508" class="poet" id="link1">杜甫</a>これには2つの属性があります。1つはクラス属性、対応する値は「poet」、もう1つはid属性、対応する値は「link1」です。タグ属性の操作方法はPython辞書と同じです。以下のようにpタグのすべての属性コードを取得して辞書値を取得してください。取得するのは、最初の段落pの属性と属性値です。
print(soup.p.attrs)
属性を個別に取得する場合は、次の2つのメソッドを使用して、ハイパーリンクのクラス属性の値を取得できます。
print(soup.a['class'])
print(soup.a.get('class'))
BeautifulSoupの各タグには、「。attrs」から取得できる複数の属性が含まれる場合があります。タグ属性は、変更、削除、および追加できます。
紹介する簡単な例を次に示します。
# 该段代码输出的是该对象的类型,即Tag对象
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup('<b class="test" id="zzr">荣仔</b>', "html.parser")
tag = soup.b
print(tag)
print(type(tag))
# NAME
print(tag.name)
print(tag.string)
# Attributes
print(tag.attrs)
print(tag['class'])
print(tag.get('id'))
# 修改属性,增加属性name
tag['class'] = 'abc'
tag['id'] = '1'
tag['name'] = '2'
print(tag)
# 删除属性
del tag['class']
del tag['name']
print(tag)
# print(tag['class']) # 此语句会报错
3.1.2 NavigableString
前のセクションでは、ラベルの名前と属性を取得する方法について説明しました。ラベルのコンテンツを取得する場合は、string属性を使用して取得できます。
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.a['class'])
print(soup.a.string)
上記のコードからわかるように、正規表現を使用するよりも、文字列属性を使用してタグ<>と</>の間のコンテンツを取得する方がはるかに便利です。
BeautifulSoupは、NavigableStringクラスを使用して文字列をTagでラップします。ここで、NavigableStringはトラバース可能な文字列を表します。NavigableString文字列はPythonのUnicode文字列と同じであり、ドキュメントツリーのトラバースとドキュメントツリーの検索に含まれる機能の一部をサポートします。
# 该段代码用来查看 NavigableString 的类型
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
print(type(tag.string))
もちろん、unicode()メソッドを使用してNavigableStringオブジェクトをUnicode文字列に直接変換できます。
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
unicode_string = tag.string
print(unicode_string)最後に、ラベルに含まれている文字列は編集できませんが、replace_with()メソッドを使用して他の文字列に置き換えることができます。
tag.string.replace( "置換前のコンテンツ"、 "置換後のコンテンツ")
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
unicode_string = tag.string
print(unicode_string)
a = tag.string.replace("BeautifulSoup 技术", " NavigableString ")
print(a)
3.1.3BeautifulSoup
BeautifulSoupオブジェクトは、通常はTagオブジェクトとして、ドキュメントのコンテンツ全体を表します。BeautifulSoupオブジェクトは、ドキュメントツリーのトラバースとドキュメントツリーの検索で説明されているほとんどのメソッドをサポートします。
type(soup)
# <class 'bs4.BeautifulSoup'>上記のコードは、type()関数を呼び出して、BeautifulSoupオブジェクトタイプであるスープ変数のデータ型を表示します。BeautifulSoupオブジェクトは実際のHTMLおよびXMLタグではないため、name属性とattrs属性はありません。
ただし、BeautifulSoupオブジェクトの ".name"プロパティには、値が "[document]"の特別なプロパティ(soup.name)が含まれているため、便利な場合があります。
soup.name
# [document]3.1.4コメント
コメントオブジェクトは、コメントオブジェクトを処理するために使用される特別なタイプのNavigableStringオブジェクトです。
# 本段代码用于读取注释内容
from bs4 import BeautifulSoup
markup = "<b><!--This is comment code.--></b>"
soup = BeautifulSoup(markup, "html.parser")
comment = soup.b.string
print(type(comment))
print(comment)
3.2ドキュメントツリーをトラバースする
BeautifulSoupでは、タグに複数の文字列またはその他のタグが含まれる場合があります。これらはタグのサブタグと呼ばれます。
3.2.1子ノード
BeautifulSoupでは、ラベルの子ノードのコンテンツはコンテンツ値によって取得され、リストの形式で出力されます。
# 本段代码用于获取 <head> 标签子节点内容
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.head.contents) <title>と</ title>の間に2つの改行があるため、取得したリストには2つの改行が含まれています。要素を抽出する必要がある場合、コードは次のようになります。
<title>と</ title>の間に2つの改行があるため、取得したリストには2つの改行が含まれています。要素を抽出する必要がある場合、コードは次のようになります。
print(soup.head.contents[3])
もちろん、childrenキーワードを使用して取得することもできますが、リストは返されませんが、トラバースすることですべての子ノードのコンテンツを取得できます。
print(soup.head.children)
for child in soup.head.children:
print(child)
前述のcontents属性とchildren属性には、タグの直接の子ノードのみが含まれています。子孫も含め、タグのすべての子ノードを取得する必要がある場合は、descendants属性を使用する必要があります。
for child in soup.descendants:
print(child) 明らかに、すべてのHTMLタグが印刷されます。
明らかに、すべてのHTMLタグが印刷されます。
3.2.2ノードの内容
ラベルに子ノードが1つしかなく、子ノードのコンテンツを取得する必要がある場合、string属性を使用して子ノードのコンテンツを出力し、通常はマウスレイヤーのラベルコンテンツを返します。
# 本段代码用于获取标题内容
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.head.string)
print(soup.title.string) 上記のコードから、タグに複数の子ノードが含まれている場合(<head>のコンテンツに2つの改行要素が含まれている場合)、Tagは文字列が取得する子ノードを判別できず、この時点での出力結果はNoneであることがわかります。
上記のコードから、タグに複数の子ノードが含まれている場合(<head>のコンテンツに2つの改行要素が含まれている場合)、Tagは文字列が取得する子ノードを判別できず、この時点での出力結果はNoneであることがわかります。
複数のノードのコンテンツを取得する必要がある場合は、strings属性を使用します
for content in soup.strings:
print(content) この時点で、スペースや改行が多すぎるという問題が見つかりました。このとき、stripped_stringsメソッドを使用して余分な空白を削除する必要があります。
この時点で、スペースや改行が多すぎるという問題が見つかりました。このとき、stripped_stringsメソッドを使用して余分な空白を削除する必要があります。
for content in soup.stripped_strings:
print(content)
3.2.3親ノード
親プロパティを呼び出して親ノードを見つけます。ノードのラベル名を取得する必要がある場合は、parent、nameを使用します。
p = soup.p
print(p.parent)
print(p.parent.name)
content = soup.head.title.string
print(content.parent)
print(content.parent.name)
すべての親ノードを取得する必要がある場合は、parentsプロパティを使用して周期的に取得します
content = soup.head.title.string
for parent in content.parents:
print(parent.name)
3.2.4兄弟ノード
兄弟ノードは、現在のノードと同じレベルのノードを参照します。next_sibling属性は、ノードの次の兄弟ノードを取得します。逆に、precious_siblingは、ノードの前の兄弟ノードを取得します。ノードの場合存在しない場合は、Noneを返します。
print(soup.p.next_sibling)
print(soup.p.precious_sinling)
実際のドキュメントのタグのnext_sibling属性とprevious_sibling属性は通常、文字列または空白であることに注意してください。空白または大韓航空もノードと見なすことができるため、使用可能な結果は空白または改行である可能性があります。
3.2.5フロントノードとバックノード
属性next_elementを呼び出して次のノードを取得し、属性precious_elementを呼び出して前のノードを取得します。
print(soup.p.next_element)
print(soup.p.precious_element)
3.3ドキュメントツリーを検索する
ドキュメントツリーを検索するために最も一般的に使用されるメソッドは、find_all()メソッドです。
行がWebページからすべての<a>タグを取得する場合、find_all()メソッドを使用するコードは次のようになります。
urls = soup.find_all('a')
for url in urls:
print(url)
同様に、この関数は正規表現をパラメーターとして渡すことをサポートしており、BeautifulSoupは正規表現match()を介してコンテンツを照合します。
次のコード例は、bで始まるすべてのタグを検索することです。
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
同様に、ラベルaとラベルbの値を渡したい場合は、次の関数を使用できます
soup.find_all(["a", "b"])注:fina_all()関数は、指定されたノードを照会するためのパラメーターを受け取ることができます
soup.find_all(id="link1")同様に、次のような複数のパラメータも受け入れることができます。
soup.find_all("a", class_="poet") # 得到一个列表
ここで、BeautifulSoupテクノロジー全体について説明しました。以前の正規表現よりもはるかに便利で、多くの関数しかクロールできないことがわかります。
4この記事の要約
BeautifulSoupは、HTMLまたはXMLファイルから必要なデータを抽出できるPythonライブラリであり、ここではテクノロジーと見なされています。一方、BeautifuSoupは、Web情報をインテリジェントにクロールする強力な機能を備えています。以前の正規表現クローラーと比較して、利便性と適用性が向上しています。転送中のWebドキュメント全体を通じて、関連関数を呼び出して必要な情報のノードを特定します。 、次に関連コンテンツをクロールします。一方、BeautifulSoupは適用が比較的簡単で、APIは非常にユーザーフレンドリーで、XPathと同様の分析テクノロジーを使用してタグを検索し、CSSセレクターをサポートします。開発効率は比較的高いです。 Pythonデータクロールで広く使用されています。
メッセージを残し、学び、一緒にコミュニケーションすることを歓迎します〜
読んでくれてありがとう