輸入前
以前に SSMP 統合を行う場合、データ レイヤー ソリューションには MySQL データベースと MyBatisPlus フレームワークが関与し、その後 Druid データ ソースの構成に関与したため、現在のデータ レイヤー ソリューションは Mysql+Druid+MyBatisPlus と言えます。3 つのテクノロジは、次の 3 つのレベルのデータ レイヤー操作に対応しています。
- データソース技術: ドルイド
- 持続性技術: MyBatisPlus
- データベース技術: MySQL
以下の研究は3段階の研究に分けられます.上記の3つの側面に対応して、最初のデータソース技術から始めましょう.
データソース技術
現在、使用しているデータ ソース テクノロジは Druid であり、対応するデータ ソースの初期化情報は、次のように実行時にログで確認できます。
INFO 28600 --- [ main] c.a.d.s.b.a.DruidDataSourceAutoConfigure : Init DruidDataSource
INFO 28600 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
Druid データ ソースを使用しない場合、実行後のプログラムはどのようになりますか? それは独立したデータベース接続オブジェクトですか、それとも他の接続プーリング技術によってサポートされていますか? Druid テクノロジに対応するスターターを削除し、プログラムを再度実行して、ログで次の初期化情報を見つけます。
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
DruidDataSource に関する情報はありませんが、ログに HikariDataSource に関する情報があることがわかりました. これが何の技術なのかわからなくても名前を見ればわかります. DataSource で終わる名前は必ずデータソース技術になります。このテクノロジーは手動で追加したのではありません。このテクノロジーはどこから来たのですか? これは、springboot 組み込みデータ ソースです。
データ層テクノロジは、データベース接続管理を実行する必要があるすべてのエンタープライズ レベルのアプリケーションで使用されます。Springboot は開発者の習慣に基づいています. 開発者はデータ ソース技術を提供します. あなたが提供するものを使用するだけです. 開発者はそれを提供しません. そうすると, 各データベース接続オブジェクトを手動で管理することはできません. どうすればよいですか? 心配や手間がかからず、誰にとっても便利なデフォルトのものを提供します。
springboot は、次の 3 つの組み込みデータ ソース テクノロジを提供します。
- 光CP
- Tomcat は DataSource を提供します
- コモンズDBCP
1 つ目は、Springboot が公式に推奨するデータソース技術である HikartCP です。デフォルトの組み込みデータ ソースとして使用. どう言う意味ですか?データ ソースを構成しない場合は、これを使用します。
2 つ目は、Tomcat が提供する DataSource、HikartCP を使用せず、Tomcat を Web プログラム開発用の Web サーバーとして使用する場合は、これを使用します。. 他の Web サーバーではなく、なぜ Tomcat なのか? スターターにWebテクノロジーをインポートした後、組み込みのTomcatがデフォルトで使用されるため、デフォルトで使用されるテクノロジーであるため、最後まで使用され、データソースも使用されます。HikartCP が提供するデフォルトのデータ ソース オブジェクトを tomcat で使用しない方法を誰かが提案しましたか? HikartCP テクノロジの座標を除外しても問題ありません。
3つ目のDBCP、この使用条件はさらに厳しいものです。HikartCP も tomcat の DataSource も使用されていない場合、これがデフォルトで使用されます。.
Springbootの悩みも解消 接続オブジェクトを自分で管理できないのが残念です. おすすめします. 本当に開発界最強のアシスタントです. 彼らはあなたに牛乳を与えたので、あなたはそれを使うことができます. これらのものをどのように設定して使用するのですか? 以前に druid を構成したとき、druid のスターターに対応する構成は次のとおりです。
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: ************
デフォルトのデータ ソース HikariCP に変更した後、次のように druid を削除するだけです。
注: この場所では、Druid スターターも削除する必要があります。
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *****************
もちろんhikari用の設定も書けますが、URLアドレスは別途以下のように設定する必要があります(つまり別の書き方です)。
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *************
これは、hikari データ ソースの構成方法です。hikari をさらに構成する場合は、その独立したプロパティを引き続き構成できます。例えば:
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: **************
maximum-pool-size: 50
hikari データソースを使いたくない場合は、Tomcat データソースを使うか、DBCP の設定形式は同じです。将来、データ レイヤーを実行するとき、データ ソース オブジェクトの選択は、ドルイド データ ソース テクノロジの単一の使用ではなくなり、必要に応じて選択できるようになります。
要約する
- springboot テクノロジーは、Hikari、Tomcat 組み込みデータ ソース、DBCP という 3 つの組み込みデータ ソース テクノロジーを提供します。
持続性技術
データ ソース ソリューションについて話した後、永続化ソリューションについて話しましょう。Springboot は、その強力な補助機能をフルに活用し、開発者に JdbcTemplate と呼ばれる一連の既製のデータ層テクノロジを提供します。実際、この技術は springboot 技術を使用しなくても使用できるため、springboot によって提供されているとは言えません。これはSpringテクノロジーによって提供されているので、SpringBootテクノロジーの範疇にはこの技術も存在します.SpringBootテクノロジーは、Springプログラムの開発を高速化するために作成されたものです.
このテクノロジーは、実際には、データ層開発のための jdbc の最も原始的なプログラミング形式への回帰であり、次の手順が直接実行されます。
ステップ1:jdbcに対応する座標をインポートし、スターターを覚えておいてください
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
ステップ 2 : JdbcTemplate オブジェクトを自動的にアセンブルする
@SpringBootTest
class Springboot15SqlApplicationTests {
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
}
}
ステップ 3 : JdbcTemplate を使用してクエリ操作を実装する (エンティティ クラスでカプセル化されていないデータのクエリ操作)
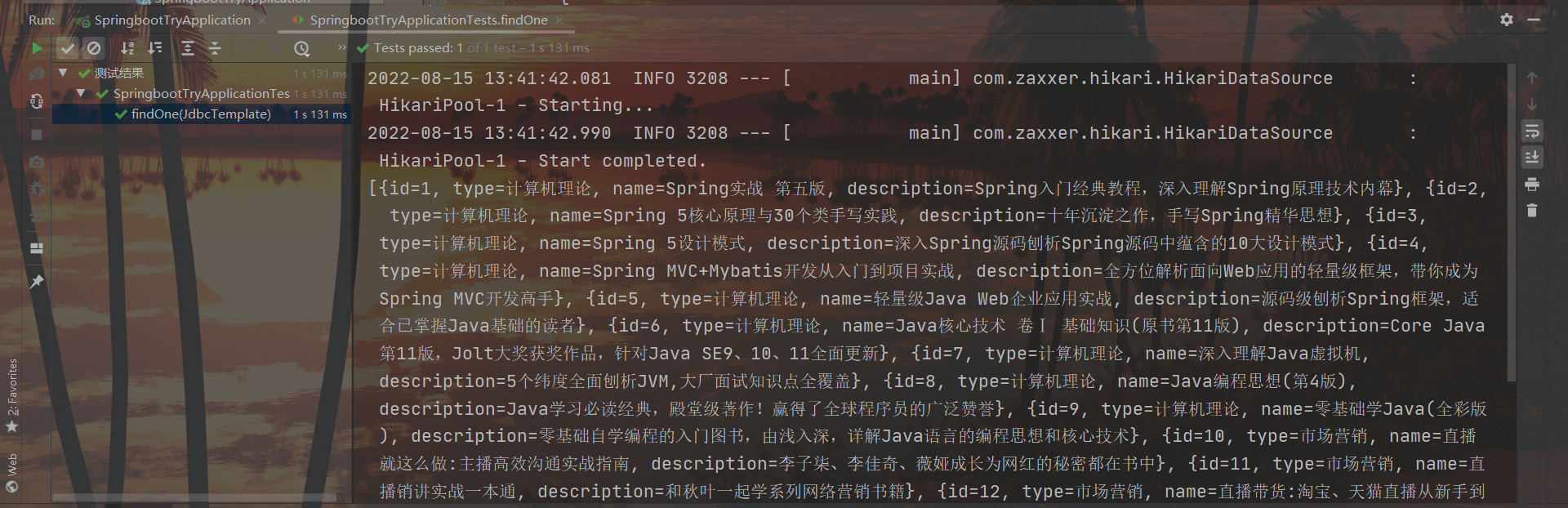
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
System.out.println(maps);
}
結果:
ステップ 4 : JdbcTemplate を使用してクエリ操作を実装する (エンティティ クラスはデータ クエリ操作をカプセル化します)
@Test
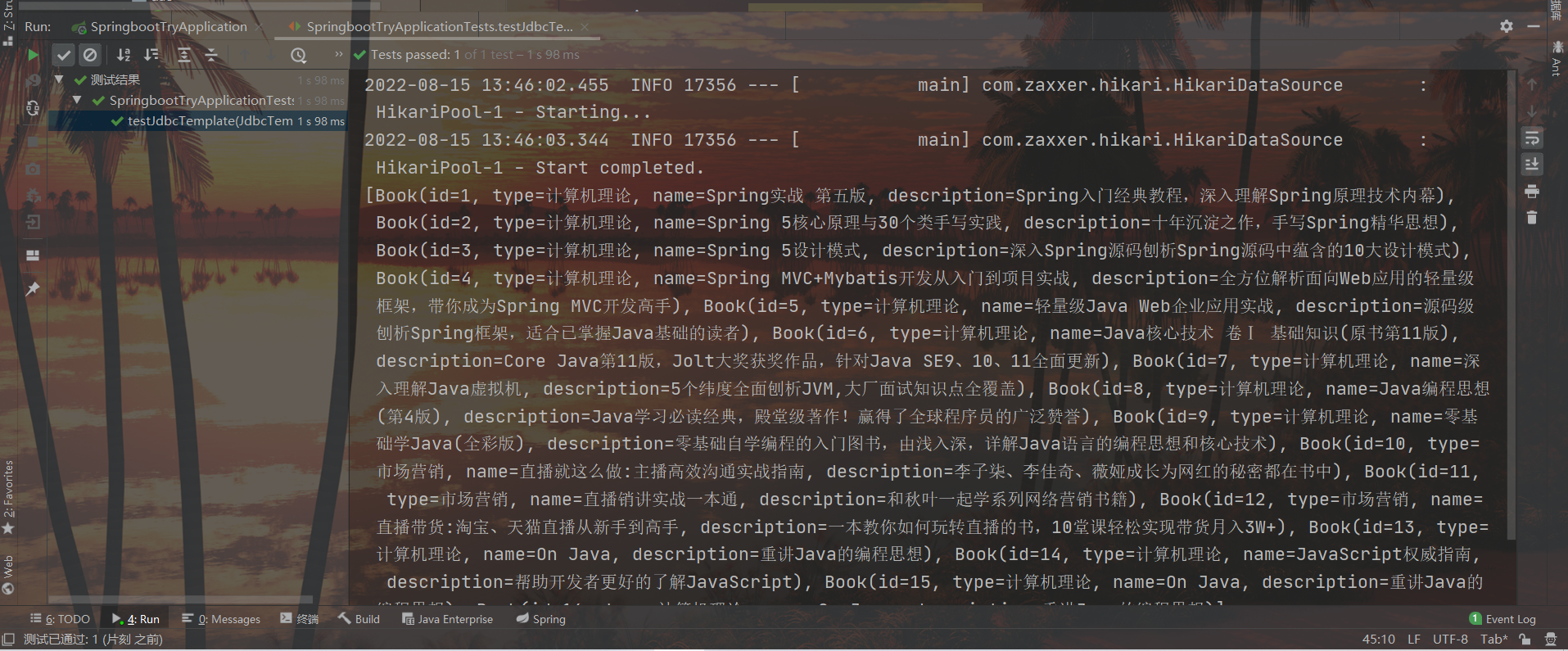
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
RowMapper<Book> rm = new RowMapper<Book>() {
@Override
public Book mapRow(ResultSet rs, int rowNum) throws SQLException {
Book temp = new Book();
temp.setId(rs.getInt("id"));
temp.setName(rs.getString("name"));
temp.setType(rs.getString("type"));
temp.setDescription(rs.getString("description"));
return temp;
}
};
List<Book> list = jdbcTemplate.query(sql, rm);
System.out.println(list);
}
結果:
ステップ⑤:JdbcTemplateを使用して、追加、削除、および変更操作を実装します
@Test
void testJdbcTemplateSave(@Autowired JdbcTemplate jdbcTemplate){
String sql = "insert into tbl_book values(3,'springboot1','springboot2','springboot3')";
jdbcTemplate.update(sql);
}
JdbcTemplate オブジェクトを構成する場合は、次のように yml ファイルで設定できます。
spring:
jdbc:
template:
query-timeout: -1 # 查询超时时间
max-rows: 500 # 最大行数
fetch-size: -1 # 缓存行数
fetch-sizeクエリのパフォーマンスを向上させることができます。例えば、今は10,000個のデータをチェックしていますが、一度にいくつのデータが渡されますか? これは、によって制御できfetch-sizeます。一度に 50 個を与え、これらの 50 個も使用すると、効率が非常に高くなります。そして50個以上使うとまた来て効率が落ちます。
要約する
- SpringBoot 組み込み JdbcTemplate 永続化ソリューション
- JdbcTemplate を使用するには、spring-boot-starter-jdbc の座標をインポートする必要があります
データベース技術
これまで、springboot は組み込みのデータ ソース ソリューションと永続化ソリューションを開発者に提供してきました.3 ピース データ レイヤー ソリューションには 1 つのデータベースが残っています.springboot も組み込みソリューションを提供するのでしょうか? 1つじゃなくて3つある
springboot には、次の 3 つの組み込みデータベースが用意されています。
- H2
- HSQL
- ダービー
上記3つのデータベースを独立してインストールするほか、tomcatサーバーのように組み込み形式でspirngbootコンテナで実行することもできます。実行するコンテナーに埋め込まれます。これは Java オブジェクトでなければなりません。そうです、これら 3 つのデータベースの最下層は Java 言語を使用して開発されています。
私たちは常に MySQL データベースを使用してきましたが、なぜこれを使用する必要があるのでしょうか?その理由は、これら 3 つのデータベースは組み込みコンテナーの形で実行できるためです.アプリケーションの実行後、テスト作業を行う場合、テスト中のデータをディスクに保存する必要はありませんが、それを使用する必要がありますテスト. 便利で、メモリ内で実行されます、テストの時間、実行の時間です。サーバーがシャットダウンすると、すべてが消えます。これは素晴らしいことであり、外部データベースを維持する必要がありません。これは、機能テストに便利な組み込みデータベースの最大の利点でもあります。
以下では、H2データベースを例にこれらの組み込みデータベースの使用方法を説明します. 操作手順も非常にシンプルです. シンプルは使いやすいです.
ステップ 1 : H2 データベースに対応する座標を合計 2 つインポートする
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
ステップ 2 : プロジェクトを Web プロジェクトとして設定し、プロジェクトの開始時に H2 データベースを開始します。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
ステップ③ : H2 データベース コンソール アクセス プログラムを設定で開くか、他のデータベース接続ソフトウェアを使用して操作します。
spring:
h2:
console:
enabled: true
path: /h2
その後、サーバーを起動し、localhost/h2 にアクセスします (ポートは事前に 80 に設定されています)。ページは次のように表示されます
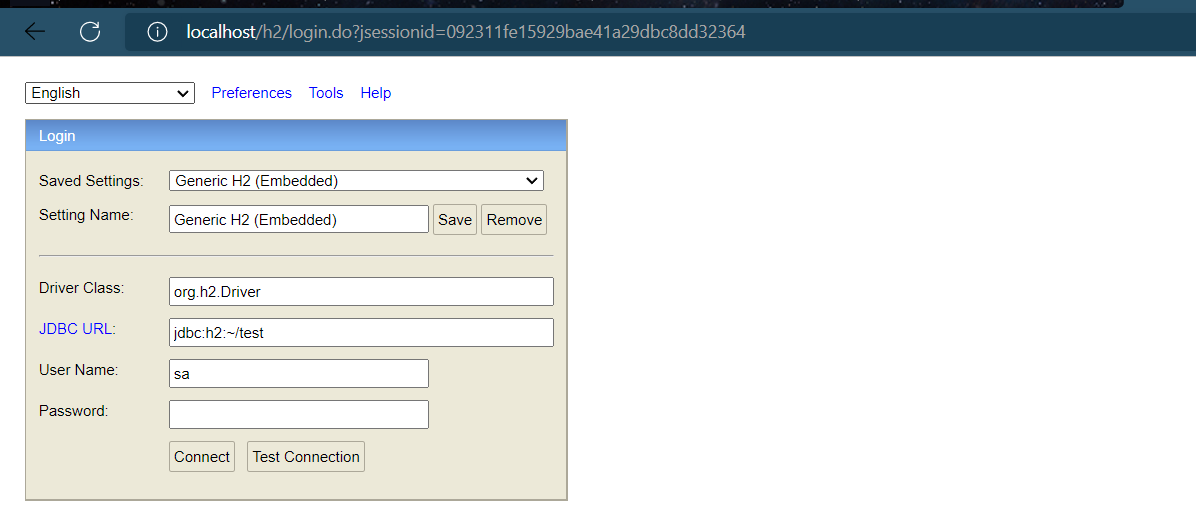
。起動プログラムの実行後、最初にデータ ソース /h2 パスに再度アクセスすると、通常どおりアクセスできます (アクセスが成功した後、次のコンテンツを削除することもできます)。
datasource:
url: jdbc:h2:~/test
hikari:
driver-class-name: org.h2.Driver
username: sa
password: 123456
次に、次の Web ページに入りました。
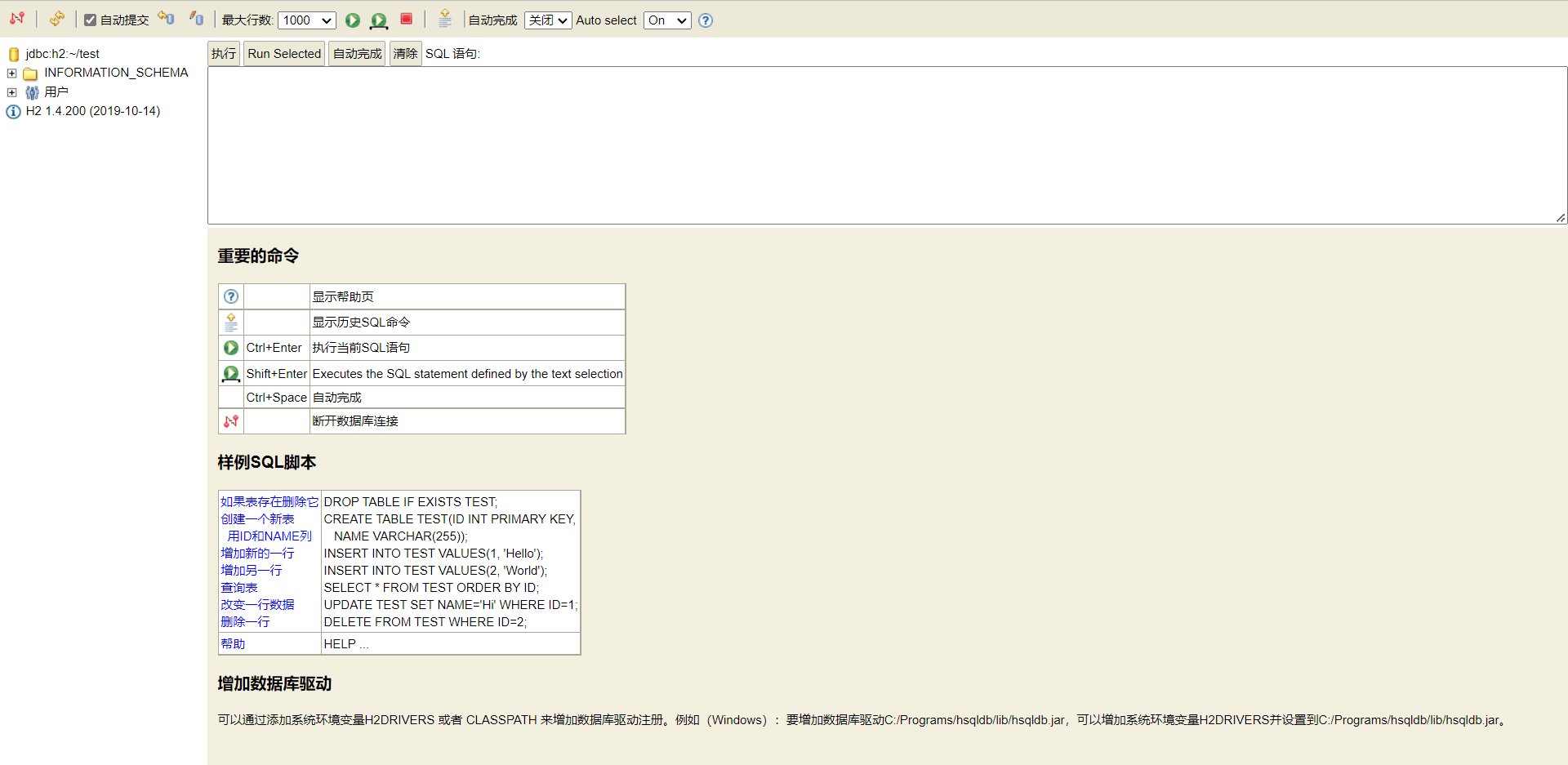
最初にテーブルを作成できます。
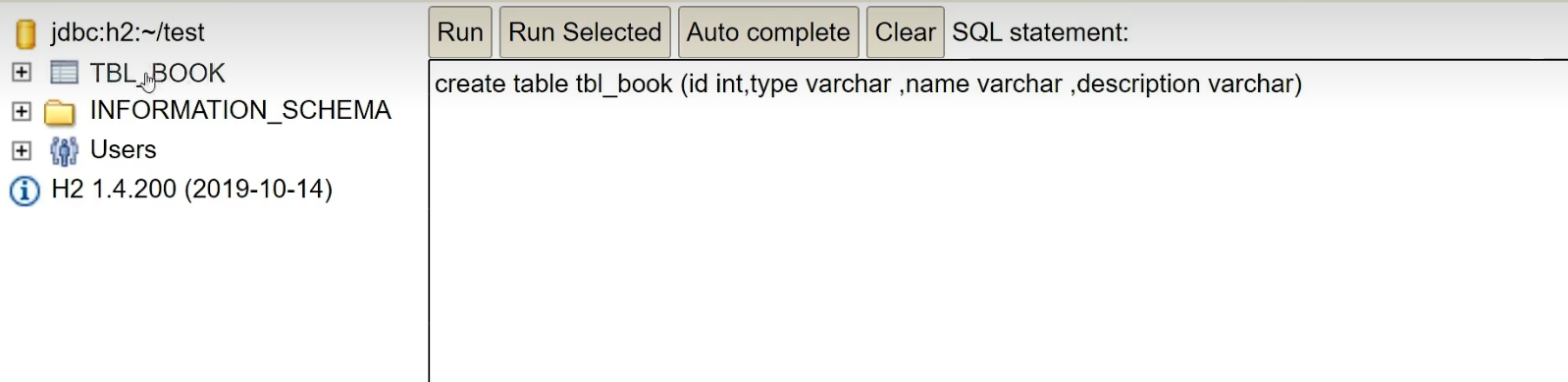
次に、テーブルを確認します。テーブル
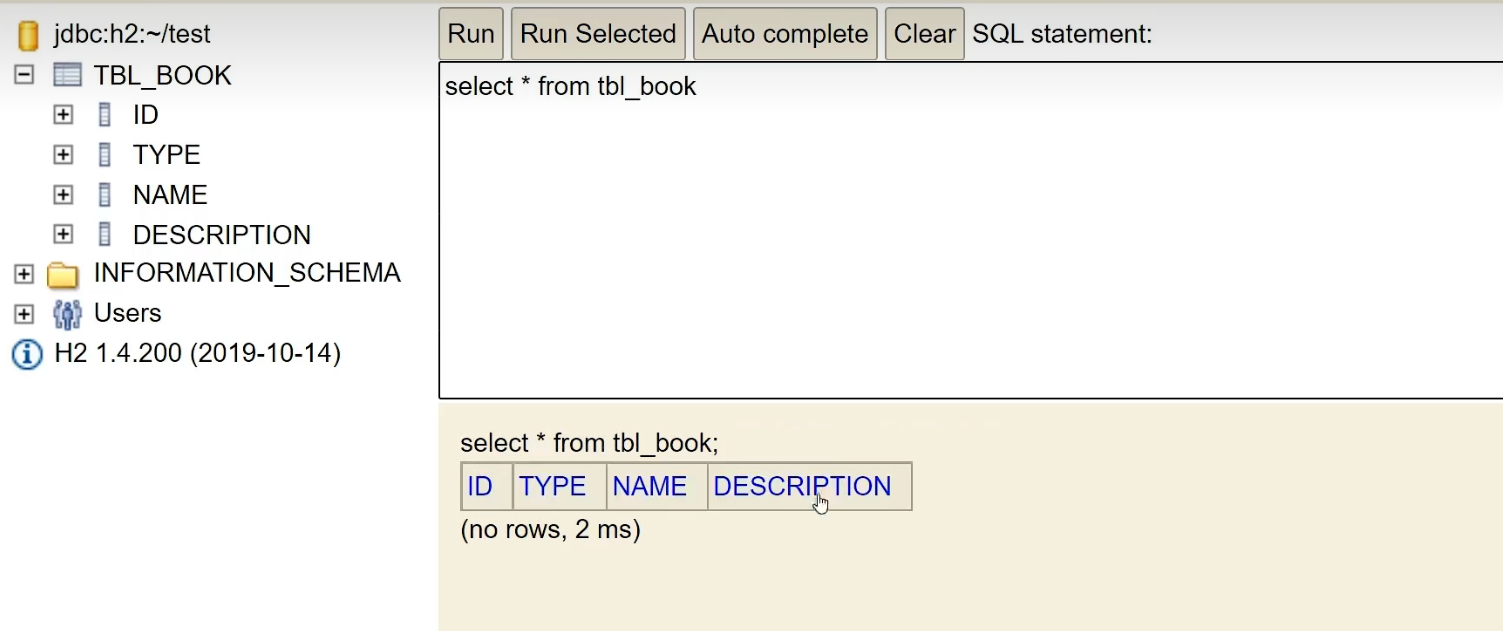
に 2 つのデータを追加します。
insert into tbl_book values(1,'springboot','springboot','springboot')
insert into tbl_book values(2,'springboot2','springboot2','springboot2')
テーブルをもう一度確認して、データが正常に追加されたことを確認しましょう。
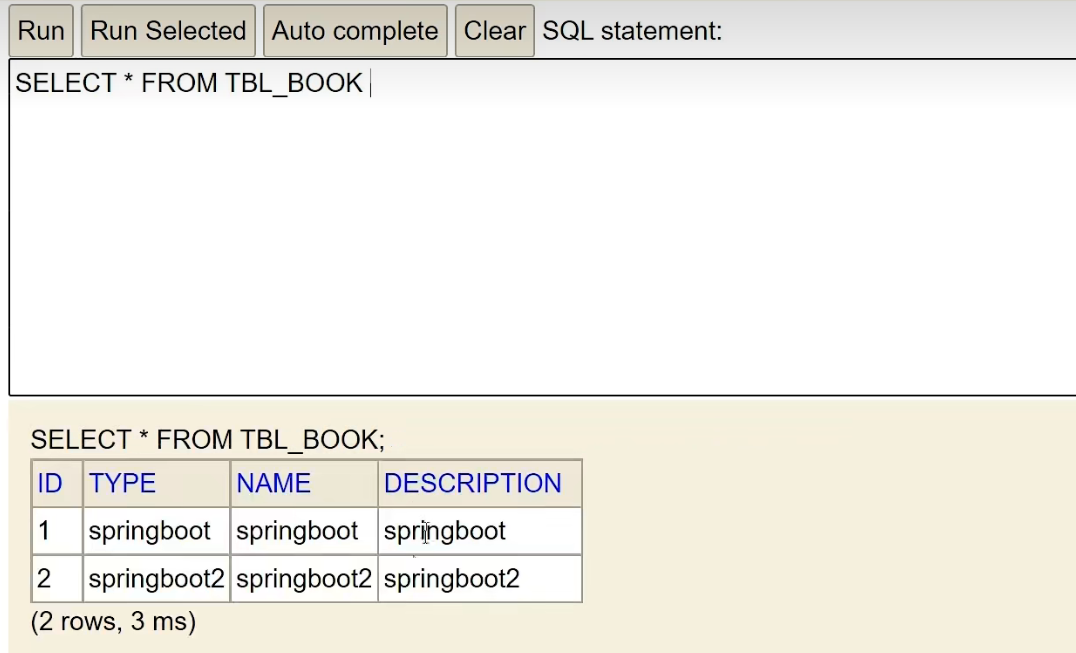
ステップ④ : JdbcTemplate または MyBatisPlus テクノロジを使用してデータベースを操作する
ここでは JdbcTemplate についてのみ説明します。MyBatisPlus テクノロジは以前と同じです。
この時点で、データ ソースを書き込む必要があります。データ ソース
の構成情報は、最初に h2 Web ページに入ったときに書き込まれます。
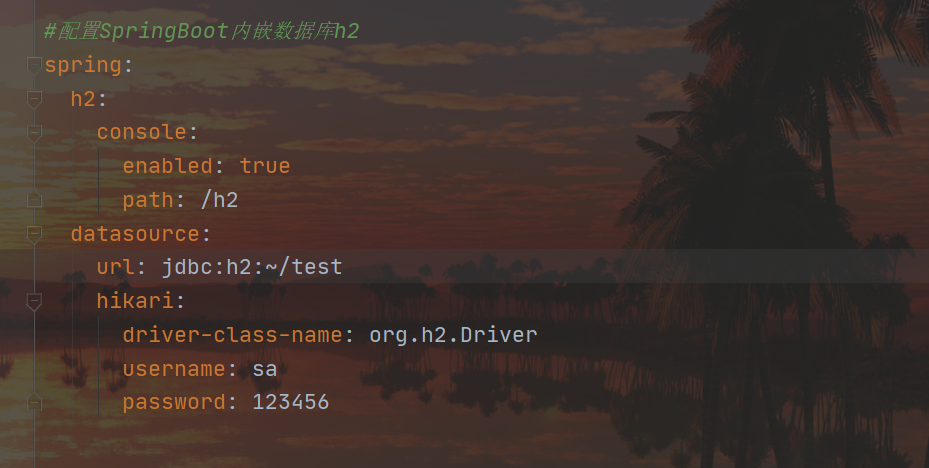
それにデータを追加してテストしましょう。
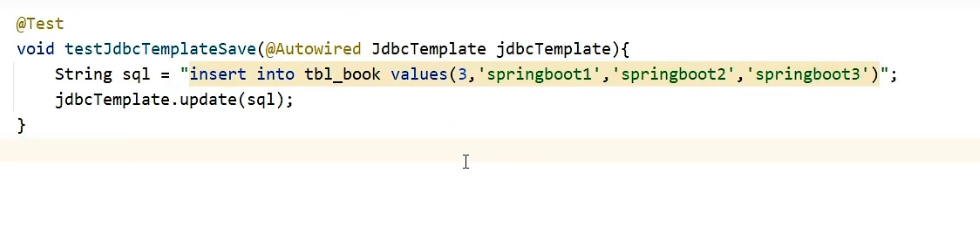

実際、データベースを変更しただけで、他のものは影響を受けません。オンラインになるときは、インメモリ データベースを閉じて、MySQL データベースをデータ永続化スキームとして使用することを忘れないでください。閉じる方法は、enabled 属性を false に設定することです。

要約する
- H2組み込みデータベースの起動方法、座標の追加、構成の追加
- H2データベースがオンラインで実行されているときは、必ず閉じてください
この時点で、SQL 関連のデータ レイヤー ソリューションについての説明は終わりました。オプションのテクノロジはさらに充実しています。
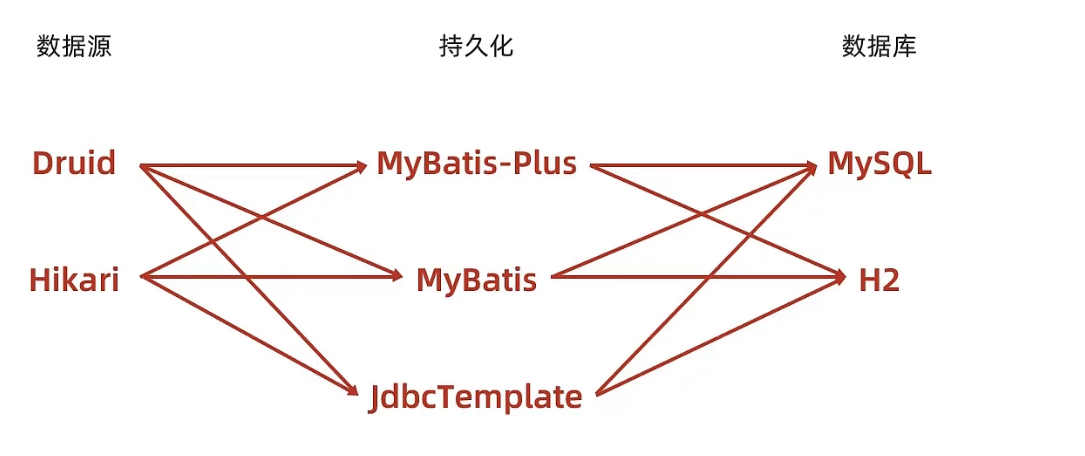
- データソース技術: Druid、Hikari、Tomcat DataSource、DBCP
- 永続化テクノロジ: MyBatisPlus、MyBatis、JdbcTemplate
- データベース技術: MySQL、H2、HSQL、Derby
プログラムを開発する際に、上記のテクノロジのいずれかを選択して、データベース ソリューションを構成できるようになりました。