この実験の要件は非常に明確です (前学期と比較して)。このブログは python で実装されており、科学計算ライブラリが使用されnumpy、図面が使用されていmatplotlib.pyplotます。簡単にするために、ファイルの先頭に次のものをインポートします。
import numpy as np
import matplotlib.pyplot as plt
この実験で使用した numpy 関数
一般に(import numpy as np)numpyと略されます。np以下は、実験で使用された numpy 関数の簡単な紹介です。次のコードを先頭に追加する必要がありますimport numpy as np。
np.array
この関数は、numpy.ndarray多次元配列として理解できるオブジェクトを返します (この実験では、1 次元 (列ベクトルと見なすことができる) と 2 次元 (行列) のみが使用されます)。\pmb x の下に小文字の x を使用しますバツxは列ベクトル、大文字AAAは行列を表します。AAA.Tを意味しますAの転置ペアndarrayは、通常、要素単位です。
>>> x = np.array([1,2,3])
>>> x
array([1, 2, 3])
>>> A = np.array([[2,3,4],[5,6,7]])
>>> A
array([[2, 3, 4],
[5, 6, 7]])
>>> A.T # 转置
array([[2, 5],
[3, 6],
[4, 7]])
>>> A + 1
array([[3, 4, 5],
[6, 7, 8]])
>>> A * 2
array([[ 4, 6, 8],
[10, 12, 14]])
np.ランダム
np.randomこのモジュールには、乱数を生成するための関数がいくつか含まれています。この実験では、ランダムな初期化パラメーター (勾配降下法) を使用して、データにノイズを追加します。
>>> np.random.rand(3, 3) # 生成3 * 3 随机矩阵,每个元素服从[0,1)均匀分布
array([[8.18713933e-01, 5.46592778e-01, 1.36380542e-01],
[9.85514865e-01, 7.07323389e-01, 2.51858374e-04],
[3.14683662e-01, 4.74980699e-02, 4.39658301e-01]])
>>> np.random.rand(1) # 生成单个随机数
array([0.70944563])
>>> np.random.rand(5) # 长为5的一维随机数组
array([0.03911319, 0.67572368, 0.98884287, 0.12501456, 0.39870096])
>>> np.random.randn(3, 3) # 同上,但每个元素服从N(0, 1)(标准正态)
数学関数
この実験でのみ使用されnp.sinます。これらの数学関数np.ndarrayは要素ごとに動作します。
>>> x = np.array([0, 3.1415, 3.1415 / 2]) # 0, pi, pi / 2
>>> np.round(np.sin(x)) # 先求sin再四舍五入: 0, 0, 1
array([0., 0., 1.])
さらに、python のライブラリに似たnp.log関数があります (多次元配列の要素単位の操作のみ)。np.expmath
np.dot
2 つの行列の積を返します。線形代数の行列乗算と一致します。最初の行列の列は、2 番目の行列の行数と同じである必要があります。特に、そのうちの 1 つが 1 次元配列の場合、形状は自動的にn × 1 n\times1に適合されます。n×1または1 × n . 1\times n.1×n .
>>> x = np.array([1,2,3]) # 一维数组
>>> A = np.array([[1,1,1],[2,2,2],[3,3,3]]) # 3 * 3矩阵
>>> np.dot(x,A)
array([14, 14, 14])
>>> np.dot(A,x)
array([ 6, 12, 18])
>>> x_2D = np.array([[1,2,3]]) # 这是一个二维数组(1 * 3矩阵)
>>> np.dot(x_2D, A) # 可以运算
array([[14, 14, 14]])
>>> np.dot(A, x_2D) # 行列不匹配
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<__array_function__ internals>", line 5, in dot
ValueError: shapes (3,3) and (1,3) not aligned: 3 (dim 1) != 1 (dim 0)
np.eye
np.eye(n)次数 n の単位行列を返します。
>>> A = np.eye(3)
>>> A
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
線形代数相関
np.linalg線形代数関連のライブラリです。
>>> A
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
>>> np.linalg.inv(A) # 求逆(本实验不考虑逆不存在)
array([[1. , 0. , 0. ],
[0. , 0.5 , 0. ],
[0. , 0. , 0.33333333]])
>>> x = np.array([1,2,3])
>>> np.linalg.norm(x) # 返回向量x的模长(平方求和开根号)
3.7416573867739413
>>> np.linalg.eigvals(A) # A的特征值
array([1., 2., 3.])
データの生成
データを生成するには、ノイズ (エラー) を追加する必要があります。クラスで与えられた例は正弦関数で、標準の正弦関数y = sin x . y=\sin x も使用します。よ=罪x . (ノイズを追加すると、y = sin x + ϵ , y=\sin x+\epsilon,よ=罪バツ+ε 、 ε ∼ N ( 0 ,σ 2 ) \epsilon\sim N(0, \sigma^2)ϵ~N ( 0 ,p2 )、sin x \sin x なので罪xの最大値1 11では、誤差の分散が小さくなるように設定します。ここでは1 25 \frac{1}{25}251)。
'''
返回数据集,形如[[x_1, y_1], [x_2, y_2], ..., [x_N, y_N]]
保证 bound[0] <= x_i < bound[1].
- N 数据集大小, 默认为 100
- bound 产生数据横坐标的上下界, 应满足 bound[0] < bound[1], 默认为(0, 10)
'''
def get_dataset(N = 100, bound = (0, 10)):
l, r = bound
# np.random.rand 产生[0, 1)的均匀分布,再根据l, r缩放平移
# 这里sort是为了画图时不会乱,可以去掉sorted试一试
x = sorted(np.random.rand(N) * (r - l) + l)
# np.random.randn 产生N(0,1),除以5会变为N(0, 1 / 25)
y = np.sin(x) + np.random.randn(N) / 5
return np.array([x,y]).T
結果のデータセットには、行ごとに平面上のポイントがあります。結果のデータは次のようになります。
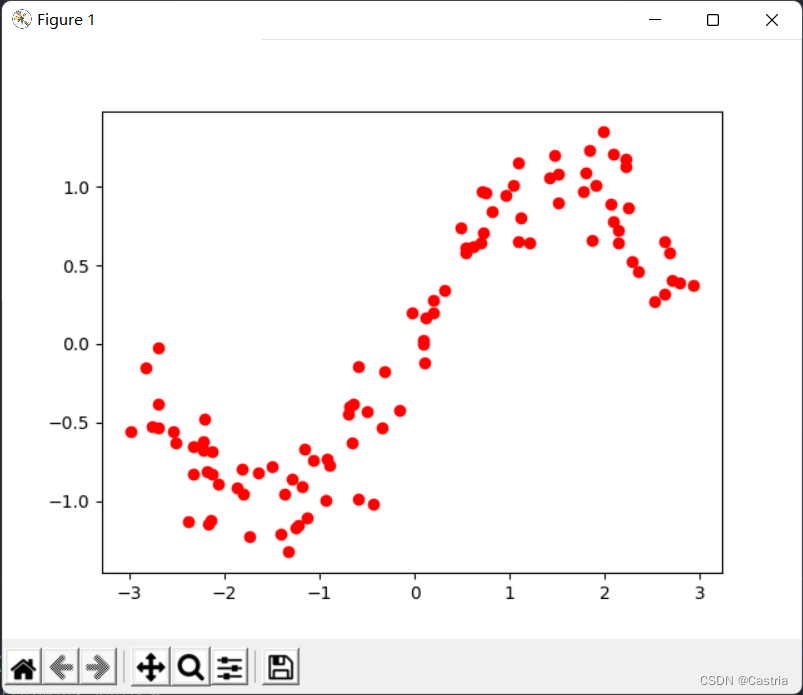
漠然と正弦関数の形になっています。上記の画像を生成するコードは次のとおりです。
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
plt.show()
最小二乗フィッティング
以下では、4 つの方法 (最小二乗、正則項/リッジ回帰、勾配降下、共役勾配) を使用して、上記の摂動正弦波を多項式で近似します。
分析ソリューションの導出
最小二乗法の原理を思い出してください。次数mの多項式
f ( x ) = w 0 + w 1 x + w 2 x 2 + . . . + wmxmf(x)=w_0+w_1x+w_2x^2+...+w_mx^mf ( x )=の0+の1バツ+の2バツ2+...+のメートルバツm
を使用して、真の関数y = sin x . y=\sin x を近似します。よ=罪x .私たちの目標は、データセット( x 1 , y 1 ) , ( x 2 , y 2 ) , . . , ( x N , y N ) (x_1,y_1),(x_2,y_2),. . を最小化することです。 .,(x_N,y_N)( ×1、よ1) 、( ×2、よ2) 、... ,( ×N、よN)損失LLL (損失)、ここで、損失関数は二乗誤差を取ります:
L = ∑ i = 1 N [ yi − f ( xi ) ] 2 L=\sum\limits_{i=1}^N[y_i-f(x_i) ]^2L=私は= 1∑N[と私−f ( x私) ]2
パラメータw 0 、w 1 、...、wm 、w_0、w_1、...、w_m を見つけるために、の0、の1、... ,のメートル、損失LLL关于 w 0 , w 1 , . . . , w m w_0,w_1,...,w_m の0、の1、... ,のメートルの導関数。便宜上、線形代数表記を使用します:
X = ( 1 x 1 x 1 2 ⋯ x 1 m 1 x 2 x 2 2 ⋯ x 2 m ⋮ ⋮ 1 x N x N 2 ⋯ x N m ) N × ( 1 ) , Y = ( y 1 y 2 ⋮ y N ) N × 1 , W = ( w 0 w 1 ⋮ wm ) ( m + 1 ) × 1 . X=\begin{pmatrix}1 & x_1 & x_1 ^2 & \cdots & x_1^m\\ 1 & x_2 & x_2^2 & \cdots & x_2^m\\ \vdots & & & &\vdots\\ 1 & x_N & x_N^2 & \cdots & x_N^ m\ \\end{pmatrix}_{N\times(m+1)},Y=\begin{pmatrix}y_1 \\ y_2 \\ \vdots \\y_N\end{pmatrix}_{N\times1}, W= \begin{pmatrix}w_0 \\ w_1 \\ \vdots \\w_m\end{pmatrix}_{(m+1)\times1}.バツ=⎝
⎛11⋮1バツ1バツ2バツNなバツ12バツ22バツN2な⋯⋯⋯バツ1メートルバツ2メートル⋮バツNメートルな⎠
⎞N × ( m + 1 )、よ=⎝
⎛よ1よ2⋮よNな⎠
⎞N × 1、の=⎝
⎛の0の1⋮のメートルな⎠
⎞( m + 1 ) × 1.
この表現の下では、
( f ( x 1 ) f ( x 2 ) ⋮ f ( x N ) ) = XW . \begin{pmatrix}f(x_1)\\ f(x_2) \\ \vdots \ \ f(x_N )\end{pmatrix}= XW.⎝
⎛f ( x1)f ( x2)⋮f ( xN)⎠
⎞=X W .
疑問がある場合は、行列の乗算で自分で確認できます。続いて、誤差項の合計は次のように表すことができます
( f ( x 1 ) − y 1 f ( x 2 ) − y 2 ⋮ f ( x N ) − y N ) = XW − Y . \begin{pmatrix}f (x_1) -y_1 \\ f(x_2)-y_2 \\ \vdots \\ f(x_N)-y_N\end{pmatrix}=XW-Y.⎝
⎛f ( x1)−よ1f ( x2)−よ2⋮f ( xN)−よNな⎠
⎞=X W−Y .
したがって、損失関数
L = ( XW − Y ) T ( XW − Y ) . L=(XW-Y)^T(XW-Y).L=( X W−と)T (XW−Y ) .
(ベクトルx = ( x 1 , x 2 , . . . , x N ) T \pmb x=(x_1,x_2,...,x_N)^T を求めるにはバツバツ=( ×1、バツ2、... ,バツN)x \pmb xに使用できるTのコンポーネントの二乗和バツxは内積、つまりx T x . \pmb x^T \pmb x.バツバツTバツx . )LL
を得るためにL最小www (このwwWは列ベクトルです)、私たちはする必要がありますLの偏導関数を0 : 00:
∂ L ∂ W = ∂ ∂ W [ ( XW − Y ) T ( XW − Y ) ] = ∂ ∂ W [ ( WTXT − YT ) ( XW − Y ) ] = ∂ ∂ W ( WTXTXW − WTXTY − YTXW + YTY ) = ∂ ∂ W ( WTXTXW − 2 YTXW + YTY ) ( 簡単に調べます , WTXTY = YTXW , したがって、それらを結合することができます ) = 2 XTXW − 2 XTY \begin{aligned}\frac{\partial L}{\partial W} &=\frac{\partial}{\partial W}[(XW-Y)^T(XW-Y)]\\ &=\frac{\partial}{\partial W}[(W^TX^TY^ T)(XW-Y)] \\ &=\frac{\partial}{\partial W}(W^TX^TXW-W^TX^TY-Y^TXW+Y^TY)\\ &=\frac {\partial}{\partial W}(W^TX^TXW-2Y^TXW+Y^TY)(簡単に調べられます,W^TX^TY=Y^TXW,したがって、それらを結合することができます)\\ &=2X^ TXW-2X^TY\end{整列}∂ W∂L _な=∂ W∂[( X W−と)T (XW−や)]=∂ W∂[( WT XT−よT )(XW−や)]=∂ W∂( W.T XT ×W−のT XT Y−よT ×W+よT Y)=∂ W∂( W.T XT ×W−2年T ×W+よT Y)(簡単に確認できます。のT XT Y=よT ×W、したがって、組み合わせることができます)=2 ×T ×W−2 ×T Y
説明: (1) WTXTYW^TX^TY
により、3 行目から 4 行目までのT XT Y和YTXWY^TXWよT XWはすべて数字 (または1 × 1 1\times11×1行列)、2つは互いに転置されるため、値は同じであり、1つの項目に結合できます。
(2) 行 4 から行 5 までの行列の導出、第 1 項∂ ∂ W ( WT ( XTX ) W ) \frac{\partial}{\partial W}(W^T(X^TX)W )∂ W∂( W.T (XT X)W)はWWWの二次形式で、その導関数は2 XTXW . 2X^TXW です。2 ×T XW.
(3) 一次項の場合− 2 YTXW -2Y^TXW− 2年T XWは、実数体による導出の場合、- 2 YTX . -2Y^TX を取得する必要があります。− 2年T X.しかし、行列の型が正しくないことを確認してください. 転置を行う必要があります. − 2 XTY . -2X^TY.− 2 ×T Y._
行列線形代数は、クラスで体系的に教えられていません。ここに表示される内容を説明するためだけです。(それ以上ある場合はしません)
偏導関数を 0 とすると、
XTXW = YTX 、 X^TXW=Y^TX を取得します。バツT ×W=よT X、
左乗算( XTX ) − 1 (X^TX)^{-1}( XT X)− 1(XTXX^TXバツT Xの可逆性については、以下の補足を参照してください
W = ( XTX ) − 1 XTY . W=(X^TX)^{-1}X^TY を取得します。の=( XT X)− 1 ×T Y.
これが私たちのWWWの解析解については、関数を呼び出してこの値を計算するだけです。
'''
最小二乘求出解析解, m 为多项式次数
最小二乘误差为 (XW - Y)^T*(XW - Y)
- dataset 数据集
- m 多项式次数, 默认为 5
'''
def fit(dataset, m = 5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
コードを少し説明します。最初の行は、上記で同意したXXを生成しますデータセット( x 1 , x 2 , . . . , x N ) T (x_1,x_2,...,x_N)^Tdataset[:,0]の 0 番目の列であるX行列( ×1、バツ2、... ,バツN)T ; 2 行目はYYY行列。3 行目は上記の解析解を返します。(Python の構文やnumpyライブラリに慣れていない場合は、かなり不親切です)
完了した関数の結果を確認するだけです。これを行うには、まず、取得したWWdrawを変換する関数を記述します。Wに対応する多項式f ( x ) f(x)f ( x )pyplotをライブラリ イメージ描画
'''
绘制给定系数W的, 在数据集上的多项式函数图像
- dataset 数据集
- w 通过上面四种方法求得的系数
- color 绘制颜色, 默认为 red
- label 图像的标签
'''
def draw(dataset, w, color = 'red', label = ''):
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = np.dot(X, w)
plt.plot(dataset[:, 0], Y, c = color, label = label)
次に、主な機能:
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 最小二乘
coef1 = fit(dataset)
draw(dataset, coef1, color = 'black', label = 'OLS')
# 绘制图像
plt.legend()
plt.show()
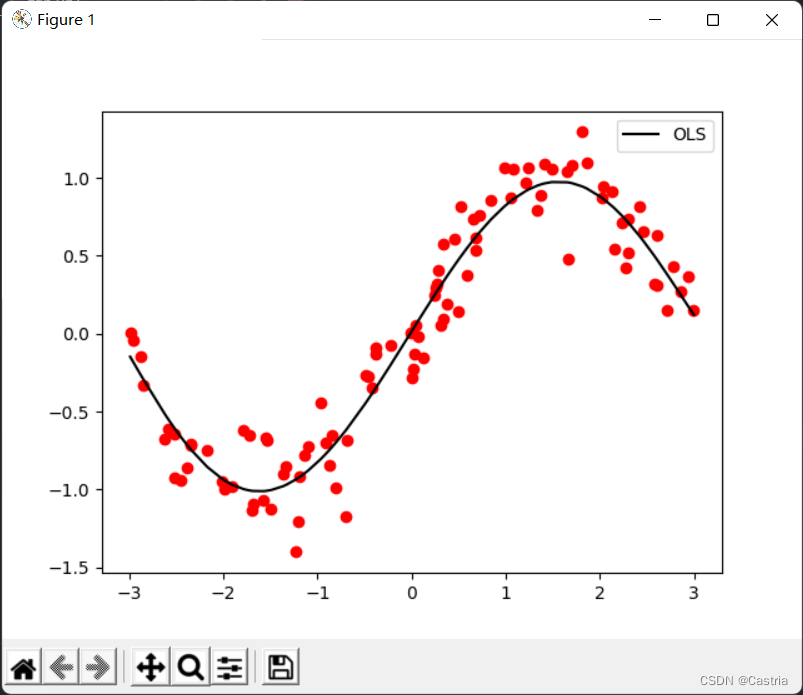
5 次多項式フィッティングの効果が非常に優れていることがわかります (データ セットは毎回ランダムに生成されるため、最初の図とは異なります)。
この部分のすべてのコードの時点で、同じ名前の次の関数は記述されていません。
import numpy as np
import matplotlib.pyplot as plt
'''
返回数据集,形如[[x_1, y_1], [x_2, y_2], ..., [x_N, y_N]]
保证 bound[0] <= x_i < bound[1].
- N 数据集大小, 默认为 100
- bound 产生数据横坐标的上下界, 应满足 bound[0] < bound[1]
'''
def get_dataset(N = 100, bound = (0, 10)):
l, r = bound
x = sorted(np.random.rand(N) * (r - l) + l)
y = np.sin(x) + np.random.randn(N) / 5
return np.array([x,y]).T
'''
最小二乘求出解析解, m 为多项式次数
最小二乘误差为 (XW - Y)^T*(XW - Y)
- dataset 数据集
- m 多项式次数, 默认为 5
'''
def fit(dataset, m = 5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X)), X.T), Y)
'''
绘制给定系数W的, 在数据集上的多项式函数图像
- dataset 数据集
- w 通过上面四种方法求得的系数
- color 绘制颜色, 默认为 red
- label 图像的标签
'''
def draw(dataset, w, color = 'red', label = ''):
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = np.dot(X, w)
plt.plot(dataset[:, 0], Y, c = color, label = label)
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
coef1 = fit(dataset)
draw(dataset, coef1, color = 'black', label = 'OLS')
plt.legend()
plt.show()
補足説明
上記の部分はそれほど厳密ではありません: 行列XXの場合Xの場合、XTXX^TXバツT Xは必ずしも可逆ではありません。ただし、この実験では、それが可逆行列であることを示すことができます。このクラスは線形代数のクラスではないので、これにはあまり多くのスペースを割きません
。XはN × ( m + 1 ) N\times(m+1)N×(メートル+1 )行列の。ここで、データ数はNNNは多項式の次数mmよりもはるかに大きいm、N > m + 1 ; N > m+1;N>メートル+1 ;
(2)XTXX^TXバツT Xは可逆です。説明が必要です( XTX ) ( m + 1 ) × ( m + 1 ) (X^TX)_{(m+1)\times(m+1)}( XT X)( m + 1 ) × ( m + 1 )フルランク、つまりR ( XTX ) = m + 1 ; R(X^TX)=m+1;R ( XT X)=メートル+1 ;
(3) 線形代数では、R ( X ) = R ( XT ) = R ( XTX ) = R ( XXT ) ; R(X)=R(X^T)=R(X^TX )=R(XX^T);R ( X )=R ( XT )=R ( XT X)=R ( X XT );
(4)○○Xはランクがmin { N , m + 1 } = m + 1. min\{N,m+1\}=m+1 にヴァンデルモンド行列私の{
N 、メートル+1 }=メートル+1.
正規化項を追加 (リッジ回帰)
最小二乗法は過適合になりやすいです。この欠陥を説明するために、生成されたデータ セットの最初の 50 ポイントをトレーニングに使用し (サンプリングが十分に均一にならないように、ここではオーバーフィッティングを説明するだけです)、パラメーターを取得し、関数イメージ全体を描画します。フィッティング効果を確認するには:
if __name__ == '__main__':
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 取前50个点进行训练
coef1 = fit(dataset[:50], m = 3)
# 再画出整个数据集上的图像
draw(dataset, coef1, color = 'black', label = 'OLS')
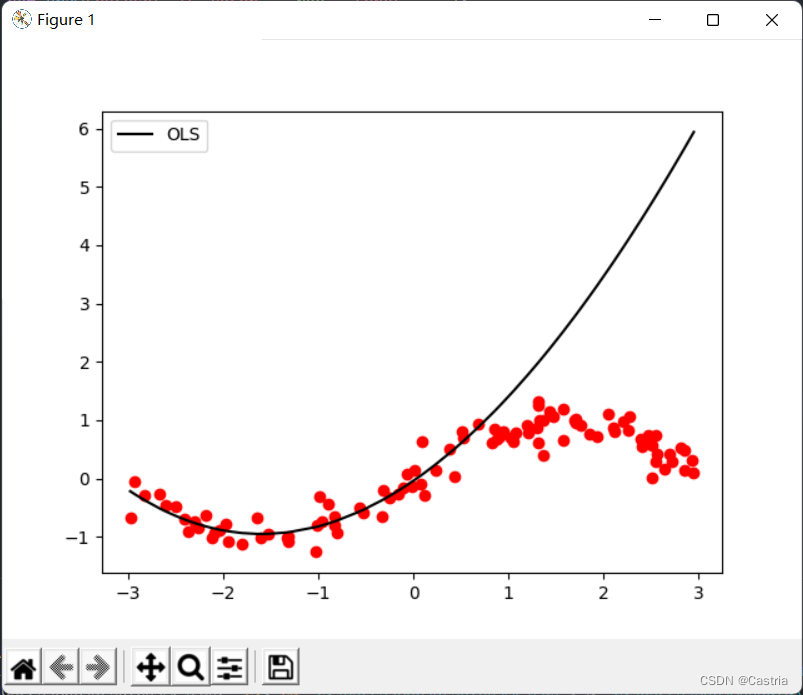
過適合 ( mm)これは、 mが大きい場合に特に深刻m = 3 m = 3メートル=3時)。多項式の次数が増加するにつれて、与えられたデータセットにできるだけ近づけるために、計算された係数の大きさがますます大きくなり、目に見えないサンプルのパフォーマンスが低下します。上記のように、最初の 50 点 (横座標[ − 3 , 0 ] [-3,0] 付近) で[ − 3 ,0 ] ) は非常に良好ですが、テスト セットのパフォーマンスは非常に悪いです ([ 0 , 3 ] [0,3][ 0 ,3 ])。オーバーフィッティングを防ぐために、正則化項を導入できます。このとき、損失関数LLL变は
L = ( XW − Y ) T ( XW − Y ) + λ ∣ ∣ W ∣ ∣ 2 2 L=(XW-Y)^T(XW-Y)+\lambda||W||_2^2L=( X W−と)T (XW−と)+λ ∣∣ W ∣ ∣22
どこで∣ ∣ ⋅ ∣ ∣ 2 2 ||\cdot||_2^2∣∣⋅∣ ∣22L 2 L_2を示しますL2ノルムの二乗、この場合はWTW ; λ W^TW;\lambdaのTW ;_λは正則化係数です。この式はリッジ回帰とも呼ばれます。その考え方は、損失関数と結果のパラメーターWWを考慮に入れることです。Wのモジュロ長(L 2 L_2L2正常)、 WWを防止Wのパラメータが大きすぎます。
例 (数字はランダムに作成されます): 正則化係数が1 1の場合1、データセットのスキーム 1 の二乗誤差が0.5 、 0.5 の場合、0.5 、このときW = ( 100 , − 200 , 300 , 150 ) TW=(100,-200,300,150)^Tの=( 100 ,− 200 ,300 ,150 )T ; データセットのスキーム 2 の二乗誤差は10, 10,10 、このときW = ( 1 , − 3 , 2 , 1 ) W=(1,-3,2,1)の=( 1 ,− 3 ,2 、1 )の場合、 W.W.を選択しますW .正則化係数λ \lambdaλはこれをWWで特徴付けますW係数の長さの重要性:λ \lambdaλが大きいWWWのモジュール長が大きいほど、ペナルティが大きくなります。λ = 0 のとき、\lambda=0、l=0の場合、リッジ回帰は通常の最小二乗法になります。リッジ回帰に似ているのは LASSO で、正規化項をL 1 L_1L1標準。
上記の導出を繰り返すと、 W = ( XTX + λ E m + 1 ) − 1 XTY . W=(X^TX+\lambda E_{m+1})^{-1}X^TYとして解析解を得ることができます。
.の=( XT X+λE _m + 1)− 1 ×T Y.
ここでE m + 1 E_{m+1}とm + 1はm + 1 m+1メートル+一次単位行列。簡単に( XTX + λ E m + 1 ) (X^TX+\lambda E_{m+1})( XT X+λE _m + 1)もリバーシブルです。
コードのこの部分は次のとおりです。
'''
岭回归求解析解, m 为多项式次数, l 为 lambda 即正则项系数
岭回归误差为 (XW - Y)^T*(XW - Y) + λ(W^T)*W
- dataset 数据集
- m 多项式次数, 默认为 5
- l 正则化参数 lambda, 默认为 0.5
'''
def ridge_regression(dataset, m = 5, l = 0.5):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
Y = dataset[:, 1]
return np.dot(np.dot(np.linalg.inv(np.dot(X.T, X) + l * np.eye(m + 1)), X.T), Y)
2 つの方法の比較は次のとおりです。
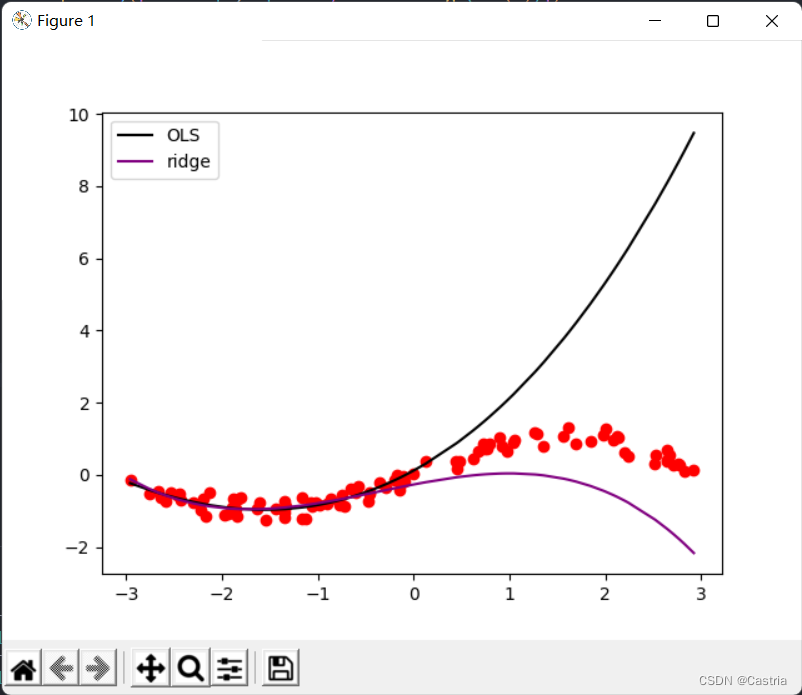
比較から、リッジ回帰がオーバーフィッティングを大幅に削減することがわかります (このとき、m = 3 、λ = 0.3 m=3、\lambda=0.3メートル=3 、l=0.3 )。
勾配降下法
勾配降下法は、この問題を解決する最良の方法ではなく、簡単に収束に失敗する可能性があります。最初に、勾配降下法の基本的な考え方を簡単に紹介します。複素関数f ( x ) f(x)を見つけたい場合f ( x )の最小値 (最大点)xxxはベクトルなど)、つまり
xmin = arg min xf ( x ) x_{min}=\argmin_{x}f(x)バツ分=バツ引数分f ( x )
勾配降下は次の操作を繰り返します:
(0) (ランダムに) 初期化x 0 ( t = 0 ) x_0(t=0)バツ0( t=0 ) ;
(1)f ( x ) f(x)f ( x ) inxt x_tバツtでの勾配 ( xxの場合)xが 1 次元の場合は微分)∇ f ( xt ) \nabla f(x_t)∇ f ( xt);
(2)xt + 1 = xt − η ∇ f ( xt ) x_{t+1}=x_t-\eta\nabla f(x_t)バツt + 1=バツt−η ∇ f ( xt)
(3)xt + 1 x_{t+1} のバツt + 1xt x_tでバツt差がほとんどない(設定範囲に達する)か、反復回数が設定上限に達した場合はアルゴリズムを停止し、そうでない場合は (1) (2) を繰り返します。
其中 η \eta ηは勾配降下のステップ サイズを決定する学習率です。以下は、 y = x 2 y=x^2
を求める勾配降下法です。よ=バツ最小点2のプログラム例:
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x ** 2
def draw():
x = np.linspace(-3, 3)
y = f(x)
plt.plot(x, y, c = 'red')
cnt = 0
# 初始化 x
x = np.random.rand(1) * 3
learning_rate = 0.05
while True:
grad = 2 * x
# -----------作图用,非算法部分-----------
plt.scatter(x, f(x), c = 'black')
plt.text(x + 0.3, f(x) + 0.3, str(cnt))
# -------------------------------------
new_x = x - grad * learning_rate
# 判断收敛
if abs(new_x - x) < 1e-3:
break
x = new_x
cnt += 1
draw()
plt.show()
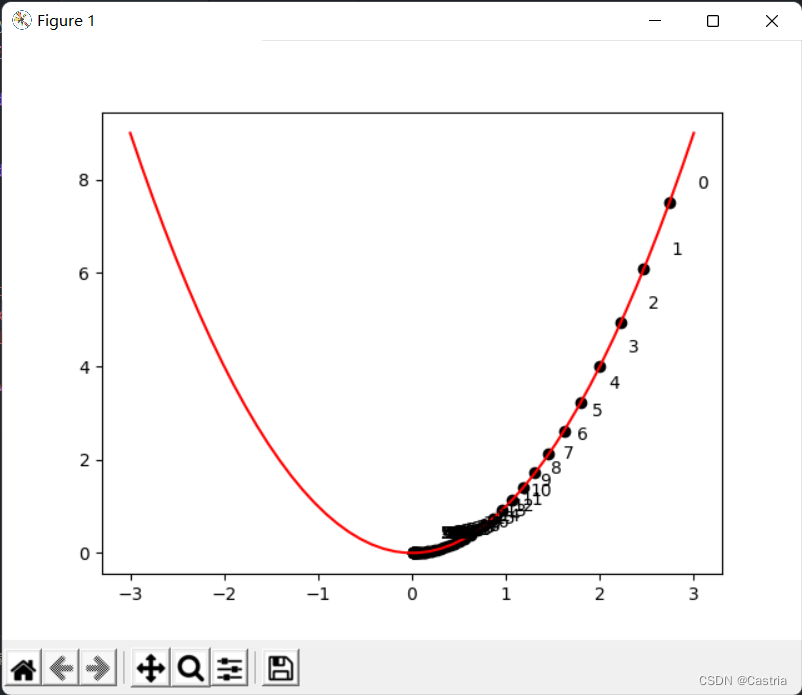
上の図はxxを示していますx反復が進むにつれて、xxxは、正の半軸に沿ってゼロに近づき続けます。なお、学習率はあまり大きくできませんが(上記のプログラムでは学習率を少し小さく設定していますが)、手動で調整する必要があります。xは正と負の半軸で前後に振動し、収束しにくくなります。
最小二乗法では、最適化する必要がある関数は損失関数
L = ( XW − Y ) T ( XW − Y ) . L=(XW-Y)^T(XW-Y) です。L=( X W−と)T (XW−Y ) .
次に、勾配降下法で問題を解きます。上記の導出では、
∂ L ∂ W = 2 XTXW − 2 XTY , \begin{aligned}\frac{\partial L}{\partial W}=2X^TXW-2X^TY\end{aligned},∂ W∂L _=2 ×T ×W−2 ×T Y、したがって、 WW
でイテレーションを実行するたびにWは、パラメーターWWまでこの勾配を減算します。Wは収束します。しかし、実験の後、二乗誤差は勾配を大きくしすぎてプロセスが収束できないため、平均二乗誤差 (MSE) を使用してそれを置き換え、元の式をNNN :
'''
梯度下降法(Gradient Descent, GD)求优化解, m 为多项式次数, max_iteration 为最大迭代次数, lr 为学习率
注: 此时拟合次数不宜太高(m <= 3), 且数据集的数据范围不能太大(这里设置为(-3, 3)), 否则很难收敛
- dataset 数据集
- m 多项式次数, 默认为 3(太高会溢出, 无法收敛)
- max_iteration 最大迭代次数, 默认为 1000
- lr 梯度下降的学习率, 默认为 0.01
'''
def GD(dataset, m = 3, max_iteration = 1000, lr = 0.01):
# 初始化参数
w = np.random.rand(m + 1)
N = len(dataset)
X = np.array([dataset[:, 0] ** i for i in range(len(w))]).T
Y = dataset[:, 1]
try:
for i in range(max_iteration):
pred_Y = np.dot(X, w)
# 均方误差(省略系数2)
grad = np.dot(X.T, pred_Y - Y) / N
w -= lr * grad
'''
为了能捕获这个溢出的 Warning,需要import warnings并在主程序中加上:
warnings.simplefilter('error')
'''
except RuntimeWarning:
print('梯度下降法溢出, 无法收敛')
return w
このときmmならmを少し大きく (たとえば 4) 設定すると、反復中に勾配がオーバーフローし、パラメーターが収束できなくなります。収束すると、フィッティング効果は OK です。
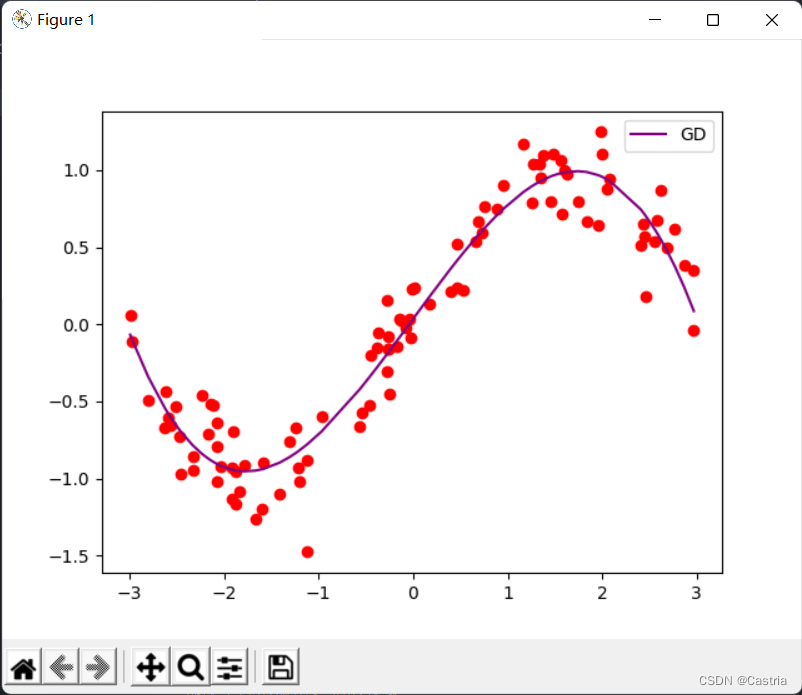
共役勾配法
共役勾配は、フォームA x = b A\pmb x=\pmb bを解くために使用できます。あバツバツ=bbの連立方程式f ( x ) = 1 2 x TA x − b T x + c . f(\pmb x)=\frac12\pmb x^TA\pmb x-\pmb b^ T \pmb x+c.f (バツ× )=21バツバツTA _バツバツ−bbTバツバツ+c . (正定AAA、2つは同等です)AAAは正定行列です。この問題では、 XTXW = YTX 、 X^TXW=Y^TX 、バツT ×W=よT X、
次にA ( m + 1 ) × ( m + 1 ) = XTX 、 b = YT . A_{(m+1)\times(m+1)}=X^TX,\pmb b=Y^ T .あ( m + 1 ) × ( m + 1 )=バツT X、bb=よT .正則項を追加したい場合、それは解
( XTX + λ E ) W = YTX . (X^TX+\lambda E)W=Y^TX になります。( XT X+λ E ) W=よT X.
まず、説明させてください:XTXX^TXバツT Xは必ずしも正定値ではありませんが、半正定値でなければなりません (参照)。しかし、実験では基本的にこの問題を心配する必要はありません。バツT Xは正定である可能性が非常に高く、コードにアサーションを追加するだけで、この条件にはあまり注意を払いません。
共役勾配法のアイデアと証明プロセスは比較的長いです.このシリーズ. ここではアルゴリズムの手順のみを示します (上記でリンクされた 3 番目の記事の冒頭):
(0) 初期化x ( 0 ); x_{(0)};バツ( 0 );
(1) 初期化d ( 0 ) = r ( 0 ) = b − A x ( 0 ) ; d_{(0)}=r_{(0)}=b-Ax_{(0)};d( 0 )=r( 0 )=b−A ×( 0 );
(2)令α ( i ) = r ( i ) T r ( i ) d ( i ) TA d ( i ) ; \alpha_{(i)}=\frac{r_{(i)}^Tr_{(i)}}{d_{(i)}^TAd_{(i)}};a( i )=d( i )Tアド_( i )r( i )Tr( i )な;
(3)迭代x ( i + 1 ) = x ( i ) + α ( i ) d ( i ) ; x_{(i+1)}=x_{(i)}+\alpha_{(i)}d_{(i)};バツ( i + 1 )=バツ( i )+a( i )d( i );
(4)令r ( i + 1 ) = r ( i ) − α ( i ) A d ( i ) ; r_{(i+1)}=r_{(i)}-\alpha_{(i)}Ad_{(i)};r( i + 1 )=r( i )−a( i )アド_( i );
(5)令β ( i + 1 ) = r ( i + 1 ) T r ( i + 1 ) r ( i ) T r ( i ) , d ( i + 1 ) = r ( i + 1 ) + β ( i + 1 ) d ( i ) . \beta_{(i+1)}=\frac{r_{(i+1)}^Tr_{(i+1)}}{r_{(i)}^Tr_{(i)}},d_{( i+1)}=r_{(i+1)}+\beta_{(i+1)}d_{(i)}.b( i + 1 )=r( i )Tr( i )r(私+ 1 )Tr( i + 1 )な、d( i + 1 )=r( i + 1 )+b( i + 1 )d( i ).
(6)当∣ ∣ r ( i ) ∣ ∣ ∣ ∣ r ( 0 ) ∣ ∣ < ϵ \frac{||r_{(i)}||}{||r_{(0)}||}<\イプシロン∣∣ r( 0 )∣∣∣∣ r( i )∣∣<ϵの場合、アルゴリズムを停止します; そうでない場合は、(2) からの反復を続けます。ϵ \εϵは小さいプリセット値で、ここでは1 0 − 5 . 10^{-5} を使用します。1 0− 5.以下では、このプロセスに従ってコードを
実装します。
'''
共轭梯度法(Conjugate Gradients, CG)求优化解, m 为多项式次数
- dataset 数据集
- m 多项式次数, 默认为 5
- regularize 正则化参数, 若为 0 则不进行正则化
'''
def CG(dataset, m = 5, regularize = 0):
X = np.array([dataset[:, 0] ** i for i in range(m + 1)]).T
A = np.dot(X.T, X) + regularize * np.eye(m + 1)
assert np.all(np.linalg.eigvals(A) > 0), '矩阵不满足正定!'
b = np.dot(X.T, dataset[:, 1])
w = np.random.rand(m + 1)
epsilon = 1e-5
# 初始化参数
d = r = b - np.dot(A, w)
r0 = r
while True:
alpha = np.dot(r.T, r) / np.dot(np.dot(d, A), d)
w += alpha * d
new_r = r - alpha * np.dot(A, d)
beta = np.dot(new_r.T, new_r) / np.dot(r.T, r)
d = beta * d + new_r
r = new_r
# 基本收敛,停止迭代
if np.linalg.norm(r) / np.linalg.norm(r0) < epsilon:
break
return w
単純な勾配降下法と比較して、共役勾配法は迅速かつ安定して収束します。ただし、多項式の次数が増加するにつれて、適合は悪化します: m = 7 で m=7メートル=図7を最小二乗法と比較すると、次のようになり
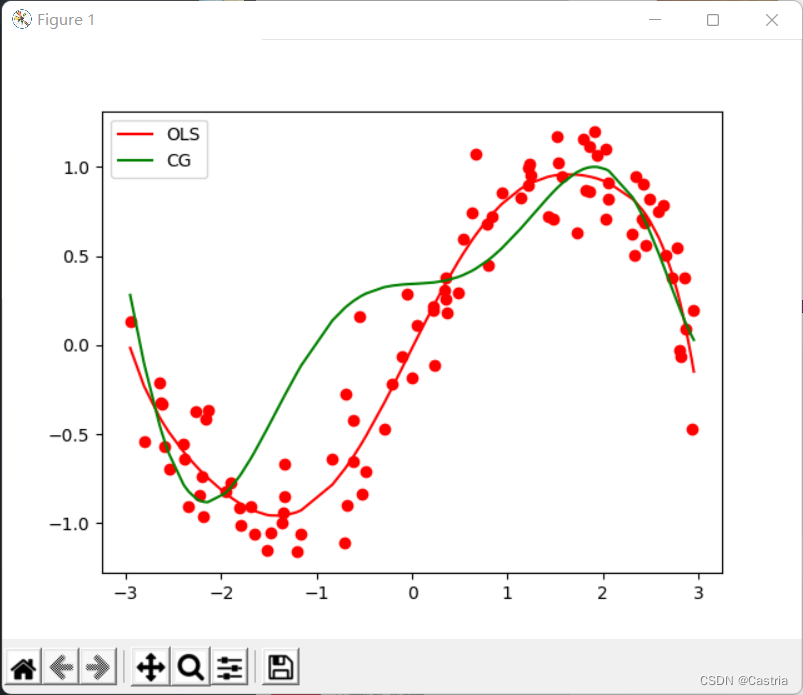
ますメートル=7 ,l=1 ):
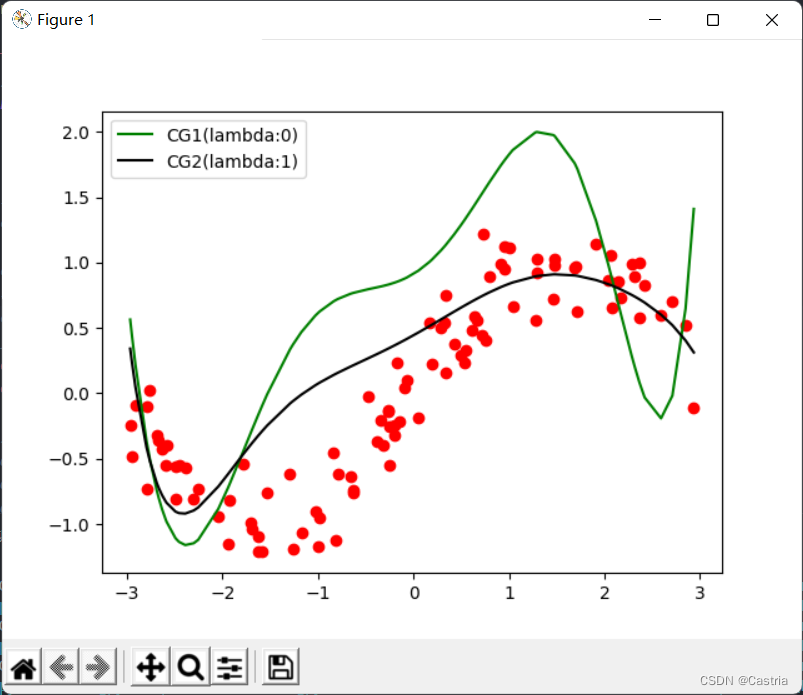
最後に、4 つの方法 (基本的には同じ) のフィッティング画像とメイン関数が添付され、実験要件に従ってパラメーターを調整できます。
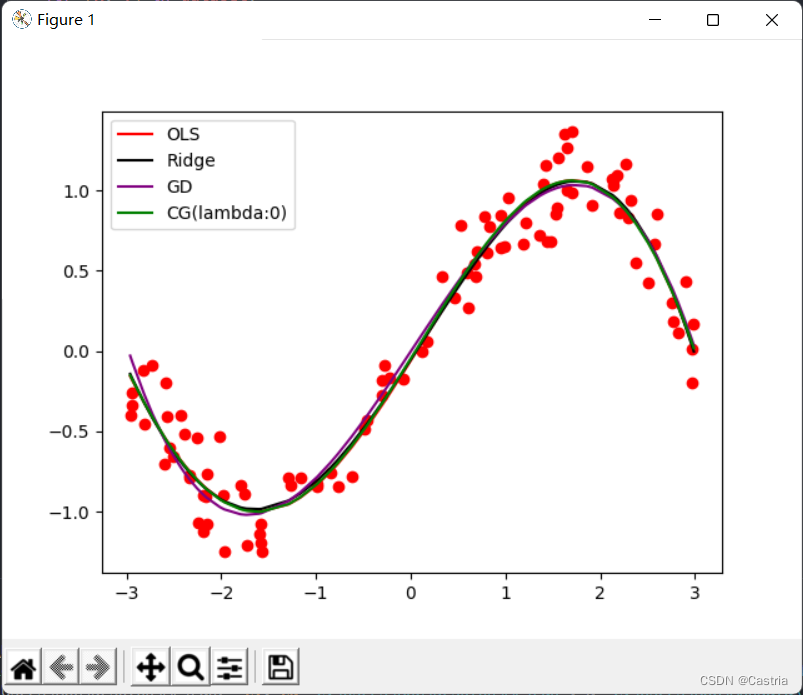
if __name__ == '__main__':
warnings.simplefilter('error')
dataset = get_dataset(bound = (-3, 3))
# 绘制数据集散点图
for [x, y] in dataset:
plt.scatter(x, y, color = 'red')
# 最小二乘法
coef1 = fit(dataset)
# 岭回归
coef2 = ridge_regression(dataset)
# 梯度下降法
coef3 = GD(dataset, m = 3)
# 共轭梯度法
coef4 = CG(dataset)
# 绘制出四种方法的曲线
draw(dataset, coef1, color = 'red', label = 'OLS')
draw(dataset, coef2, color = 'black', label = 'Ridge')
draw(dataset, coef3, color = 'purple', label = 'GD')
draw(dataset, coef4, color = 'green', label = 'CG(lambda:0)')
# 绘制标签, 显示图像
plt.legend()
plt.show()