要約: マージ ソートとクイック ソートは、2 つの少し複雑なソート アルゴリズムです. どちらも分割統治の考え方を使用しています. コードは再帰によって実装されており、プロセスは非常に似ています. マージソートを理解する鍵は、再帰式と merge() マージ関数を理解することです。
この記事は、Huawei クラウド コミュニティ「単純な方法で並べ替える 8 つのアルゴリズム」、著者: Embedded Vision から共有されています。
マージ ソートとクイック ソートは、2 つの少し複雑なソート アルゴリズムです. どちらも分割統治の考え方を使用しており、コードは再帰によって実装されています. プロセスは非常に似ています. マージソートを理解する鍵は、再帰式と merge() マージ関数を理解することです。
一、バブルソート(Bubble Sort)
ソート アルゴリズムは、プログラマーが理解し、熟知しなければならない一種のアルゴリズムです。バブリング、挿入、選択、高速、マージ、カウンティング、カーディナリティ、バケット ソートなど、多くの種類のソート アルゴリズムがあります。
バブル ソートは、隣接する 2 つのデータに対してのみ機能します。各バブリング操作では、隣接する 2 つの要素を比較して、サイズの関係の要件を満たしているかどうかを確認し、満たしていない場合は交換します。1 回のバブリングにより、少なくとも 1 つの要素が本来あるべき場所に移動され、n 回繰り返されて n 個のデータの並べ替えが完了します。
要約: 配列に n 個の要素がある場合、最悪の場合、n 回のバブリング操作が必要になります。
基本的なバブル ソート アルゴリズムの C++ コードは次のとおりです。
// 将数据从小到大排序
void bubbleSort(int array[], int n){
if (n<=1) return;
for(int i=0; i<n; i++){
for(int j=0; j<n-i; j++){
if (temp > a[j+1]){
temp = array[j]
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
}実際には、上記のバブル ソート アルゴリズムも最適化することができます. 特定のバブリング操作がデータ交換を実行しなくなった場合、それは配列が既に整然としていることを意味し、後続のバブリング操作を実行し続ける必要はありません. 最適化されたコードは次のとおりです。
// 将数据从小到大排序
void bubbleSort(int array[], int n){
if (n<=1) return;
for(int i=0; i<n; i++){
// 提前退出冒泡循环发标志位
bool flag = False;
for(int j=0; j<n-i; j++){
if (temp > a[j+1]){
temp = array[j]
a[j] = a[j+1];
a[j+1] = temp;
flag = True; // 表示本次冒泡操作存在数据交换
}
}
if(!flag) break; // 没有数据交换,提交退出
}
}バブルソートの特徴:
- バブリング プロセスは、隣接する要素の交換のみを含み、一定レベルの一時スペースのみを必要とするため、スペースの複雑さは O(1) O (1) であり、これはインプレース ソート アルゴリズムです。
- 隣接する同じサイズの要素が 2 つある場合は交換せず、同じサイズのデータは並べ替えの前後で順序が変わらないため、安定した並べ替えアルゴリズムです。
- 最悪の場合と平均的な時間の複雑さは両方とも O(n2) O ( n 2 ) であり、最適な時間の複雑さは O(n) O ( n ) です。
第二に、挿入ソート(Insertion Sort)
- 挿入ソート アルゴリズムは、配列内のデータを 2 つの区間 (ソートされた区間とソートされていない区間) に分割します。最初の並べ替え範囲には、配列の最初の要素である 1 つの要素しかありません。
- 挿入ソート アルゴリズムの核となる考え方は、ソートされていない範囲の要素を取得し、ソートされた範囲に挿入する適切な位置を見つけ、ソートされた範囲内のデータが常に適切であるようにすることです。
- ソートされていない区間要素が空になるまでこのプロセスを繰り返し、アルゴリズムは終了します。
挿入ソートも、バブルソートと同様に、要素の比較と要素の移動という 2 つの操作が含まれます。
ソートされた範囲にデータ a を挿入する必要がある場合、適切な挿入位置を見つけるために、a のサイズとソートされた範囲の要素を比較する必要があります。挿入ポイントを見つけた後、要素 a が挿入される余地を作るために、挿入ポイントの後の要素の順序を 1 ビット戻す必要もあります。
挿入ソートの C++ コード実装は次のとおりです。
void InsertSort(int a[], int n){
if (n <= 1) return;
for (int i = 1; i < n; i++) // 未排序区间范围
{
key = a[i]; // 待排序第一个元素
int j = i - 1; // 已排序区间末尾元素
// 从尾到头查找插入点方法
while(key < a[j] && j >= 0){ // 元素比较
a[j+1] = a[j]; // 数据向后移动一位
j--;
}
a[j+1] = key; // 插入数据
}
}挿入ソート機能:
- 挿入ソートは追加の記憶域スペースを必要とせず、スペースの複雑さは O(1) O (1) であるため、挿入ソートもインプレース ソート アルゴリズムです。
- 挿入ソートでは、同じ値の要素に対して、後に出現する要素を前に出現する要素の後ろに挿入することを選択できるため、元の前後の順序が変更されないため、挿入ソートは安定しています。ソートアルゴリズム。
- 最悪の場合と平均的な時間の複雑さは両方とも O(n2) O ( n 2 ) であり、最適な時間の複雑さは O(n) O ( n ) です。
三、セレクションソート(Selection Sort)
選択ソート アルゴリズムの実装の考え方は、挿入ソートに多少似ており、ソートされた区間とソートされていない区間にも分けられます。ただし、選択ソートは、ソートされていない間隔から毎回最小の要素を見つけ、ソートされた間隔の最後に配置します。
選択ソートの最良のケース、最悪のケース、および平均的なケースの時間計算量は O(n2) O ( n 2) であり、これはインプレース ソート アルゴリズムであり、不安定なソート アルゴリズムです。
選択ソートの C++ コードは次のように実装されます。
void SelectSort(int a[], int n){
for(int i=0; i<n; i++){
int minIndex = i;
for(int j = i;j<n;j++){
if (a[j] < a[minIndex]) minIndex = j;
}
if (minIndex != i){
temp = a[i];
a[i] = a[minIndex];
a[minIndex] = temp;
}
}
}ふきだし挿入選択ソートまとめ
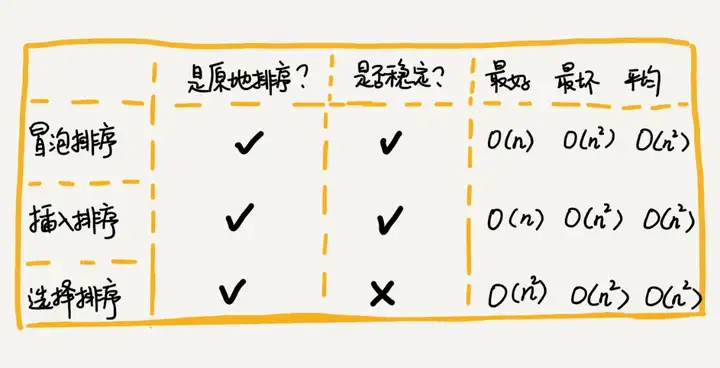
これら 3 つの並べ替えアルゴリズムの実装コードは非常に単純で、小規模なデータの並べ替えには非常に効率的です。ただし、大規模なデータを並べ替える場合、時間の計算量は依然として少し高いため、時間の計算量が O(nlogn) O ( nlogn ) の並べ替えアルゴリズムを使用する傾向があります。
特定のアルゴリズムは特定のデータ構造に依存します。上記の 3 つの並べ替えアルゴリズムはすべて、配列に基づいて実装されています。
四、マージソート(Merge Sort)
マージソートの核となる考え方は比較的単純です。配列を並べ替える場合は、まず配列を真ん中から前後に分割し、前後を別々に並べ替えてから、並べ替えた2つの部分をマージして、配列全体が整うようにします。
マージソートは、分割統治の考え方を利用しています。分割統治とは、名前が示すように、大きな問題を小さなサブ問題に分解して解決する分割統治です。小さなサブ問題が解決すると、大きな問題も解決されます。
分割統治の考え方は、再帰的な考え方に多少似ており、分割統治アルゴリズムは通常、再帰を使用して実装されます。分割統治は問題を解決するための処理の考え方であり、再帰はプログラミング手法であり、両者は矛盾しません。
マージ ソートは分割統治法を使用し、分割統治法は一般に再帰を使用して実装されることを知ったので、次の焦点は、再帰を使用してマージ ソートを実装する方法です。再帰コードを書くスキルは、問題を分析して再帰式を取得し、終了条件を見つけ、最後に再帰式を再帰コードに変換することです。したがって、マージ ソートのコードを記述したい場合は、最初にマージ ソートの再帰式を記述する必要があります。
递推公式:
merge_sort(p…r) = merge(merge_sort(p…q), merge_sort(q+1…r))
终止条件:
p >= r 不用再继续分解,即区间数组元素为 1 マージソートの擬似コードは次のとおりです。
merge_sort(A, n){
merge_sort_c(A, 0, n-1)
}
merge_sort_c(A, p, r){
// 递归终止条件
if (p>=r) then return
// 取 p、r 中间的位置为 q
q = (p+r)/2
// 分治递归
merge_sort_c(A[p, q], p, q)
merge_sort_c(A[q+1, r], q+1, r)
// 将A[p...q]和A[q+1...r]合并为A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}4.1、マージソートのパフォーマンス分析
1. マージ ソートは、安定したソート アルゴリズムです。分析: 疑似コードの merge_sort_c() 関数は、問題を分解するだけで、要素の移動やサイズの比較は含まれません. 実際の要素の比較とデータの移動は、merge() 関数の部分にあります. マージの過程で、同じ値を持つ要素の順序は、マージの前後で変更されないままであることが保証されます. マージソートソートは、安定したソートアルゴリズムです.
2. マージソートの実行効率は、ソートされる元の配列の順序の度合いとは関係がないため、その時間計算量は非常に安定しています. 最良のケース、最悪のケース、平均的なケースのいずれであっても、時間計算量はO ( nlogn) O ( nlogn ) です。分析: 再帰的な解法の問題は再帰的な式として記述できるだけでなく、再帰的なコードの時間計算量も再帰的な式として記述できます。

3.空間の複雑度は O(n) です。分析: 再帰コードのスペースの複雑さは、時間の複雑さのようには加算されません。アルゴリズムのマージ操作ごとに追加のメモリ空間を適用する必要がありますが、マージが完了すると、一時的に開いていたメモリ空間が解放されます。CPU は常に 1 つの関数しか実行していないため、使用される一時メモリ スペースは 1 つだけです。最大一時メモリ空間は n データのサイズを超えないため、空間の複雑さは O(n) O ( n ) です。
5、クイックソート(Quicksort)
クイックソートの考え方は次のとおりです。配列内の p から r までの添え字を持つ一連のデータをソートする場合、p と r の間の任意のデータをピボット (分割点)として選択します。p と r の間でデータをトラバースし、ピボットよりも小さいデータを左側に配置し、ピボットよりも大きいデータを右側に配置し、ピボットを中央に配置します。このステップの後、配列 p と r の間のデータは 3 つの部分に分割されます. 前の p と q-1 の間のデータはピボットよりも小さく、中央はピボット、q+1 と r の間のデータピボットより大きいです。
分割統治と再帰の考え方によれば、p から q-1 までの添字を持つデータと、q+1 から r までの添字を持つデータを、間隔が 1 に減るまで再帰的に並べ替えることができます。つまり、すべてデータはすべて揃っています。
再帰式は次のとおりです。
递推公式:
quick_sort(p,r) = quick_sort(p, q-1) + quick_sort(q, r)
终止条件:
p >= rマージソートとクイックソートの概要
マージ ソートとクイック ソートは、2 つの少し複雑なソート アルゴリズムです. どちらも分割統治の考え方を使用しており、コードは再帰によって実装されています. プロセスは非常に似ています. マージソートを理解する鍵は、再帰式と merge() マージ関数を理解することです。同様に、クイックソートを理解するための鍵は、再帰式と partition() パーティション関数を理解することです。
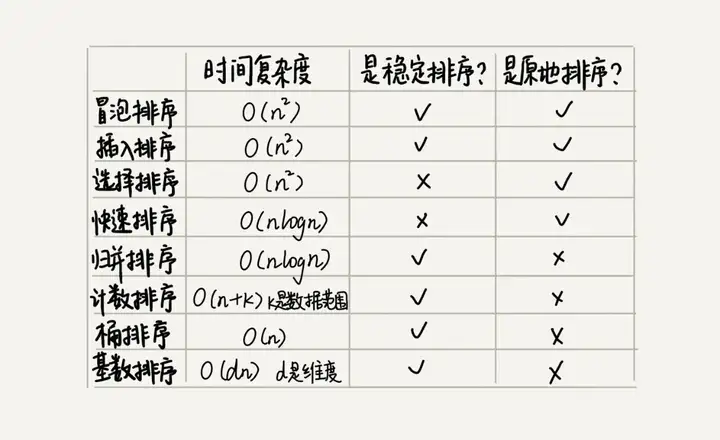
上記の 5 つの並べ替えアルゴリズムに加えて、時間計算量が O(n) O ( n )の 3 つの線形並べ替えアルゴリズムがあります: バケット並べ替え、カウント並べ替え、および基数並べ替えです。次の図は、これら 8 つの並べ替えアルゴリズムのパフォーマンスをまとめたものです。
参考文献
- ソート (パート 1): バブル ソートよりも挿入ソートの方が人気があるのはなぜですか?
- 並べ替え (下): クイック 並べ替えのアイデアを使用して、O(n) で K 番目に大きい要素を見つける方法は?
クリックしてフォローし、Huawei Cloudの新しいテクノロジーについて初めて学びましょう〜