1. 時系列データとその特徴
時系列データは、1 年以内のダウ ジョーンズ インデックス、1 日のさまざまな時点で測定された気温など、比較的安定した頻度に基づいて継続的に生成される一連の指標監視データです。時系列データには次の特徴があります。
- 履歴データの不変性
- データの可用性
- データの適時性
- 構造化データ
- データ量
第二に、時系列データベースの基本構造
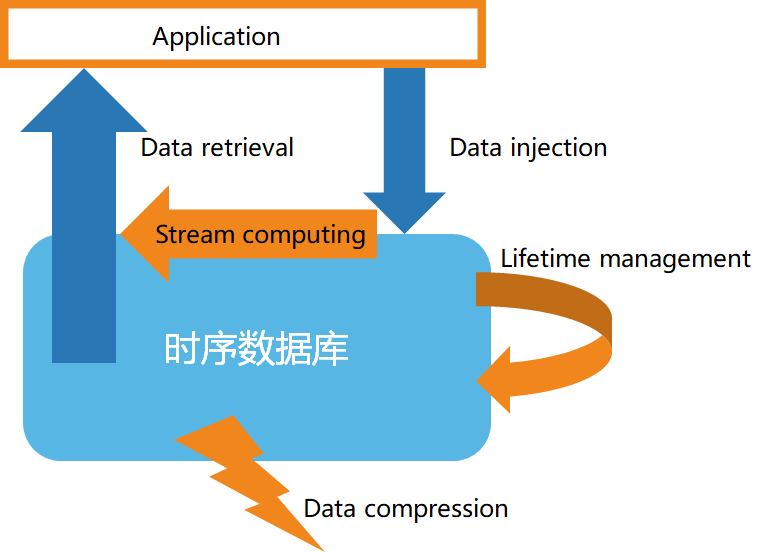
時系列データの特性によると、時系列データベースには一般的に次のような特性があります。
- 高速データストレージ
- データ ライフサイクル管理
- データのストリーム処理
- 効率的なデータ クエリ
- カスタム データ圧縮
3. ストリーム コンピューティングの概要
ストリーム コンピューティングとは、主に、さまざまなデータ ソースから大量のデータをリアルタイムで取得し、リアルタイムで分析および処理して貴重な情報を取得することを指します。一般的なビジネス シナリオには、リアルタイム イベントへの迅速な対応、市場の変化に対するリアルタイム アラーム、リアルタイム データの対話型分析などが含まれます。ストリーム コンピューティングには、通常、次の関数が含まれます。
1) フィルタリングと変換 (フィルターとマップ)
2)集計とウィンドウ関数 (reduce、集計/ウィンドウ)
3) 複数のデータ ストリームの結合とパターン マッチング (結合とパターン検出)
4) ストリームからブロック処理へ
4. ストリーム コンピューティングのための時系列データベースのサポート
-
ケース 1: 次の例に示すように、カスタマイズされたストリーム コンピューティング API を使用します。
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|> join(tables: {stream1: {bucket: "mydb", measurement: "stream1", start: -1h}, stream2: {bucket: "mydb", measurement: "stream2", start: -1h}}, on: ["location"])
|> alert(name: "value_above_threshold", message: "Value is above threshold", crit: (r) => r.value > 100)
|> to(bucket: "mydb", measurement: "output", tagColumns: ["location"])
-
ケース 2: 次のように、SQL に似た命令を使用してストリーム コンピューティングを作成し、ストリーム コンピューティング ルールを定義します。
CREATE STREAM current_stream
TRIGGER AT_ONCE
INTO current_stream_output_stb AS
SELECT
_wstart as start,
_wend as end,
max(current) as max_current
FROM meters
WHERE voltage <= 220
INTEVAL (5S) SLIDING (1s);
{{o.name}}
{{m.name}}