Volcano Engine Edge Cloud は、クラウド コンピューティングの基本技術とネットワークを組み合わせたエッジの異種コンピューティング能力に基づくクラウド コンピューティング サービスであり、エッジの大規模インフラストラクチャ上に構築され、エッジベースのコンピューティング、ネットワーク、ストレージ、セキュリティ、インテリジェンスを形成します。コア機能を備えた分散型クラウド コンピューティング ソリューション。
01- エッジ シーン ストレージの課題
エッジ ストレージは主に、エッジ レンダリングなどのエッジ コンピューティングに適応する典型的なビジネス シナリオ用です。Volcano エンジンのエッジ レンダリングは、基礎となる大規模なコンピューティング パワー リソースに依存しています。これにより、ユーザーは数百万のレンダリング フレーム キューの簡単な配置、近くのレンダリング タスクのスケジューリング、マルチタスクおよびマルチノードの並列レンダリングを実現できます。 , これによりレンダリングが大幅に改善されます. エッジレンダリングの質問で発生するストレージを簡単に紹介します.
- オブジェクトストレージとファイルシステムのメタデータを統合する必要があるため、データがオブジェクトストレージインターフェースを介してアップロードされた後、POSIXインターフェースを介して直接操作できます。
- 特に読み取り時に、高スループット シナリオのニーズを満たします。
- S3 インターフェイスと POSIX インターフェイスを完全に実装します。
エッジ レンダリングで発生したストレージの問題を解決するために、チームは半年近くかけてストレージの選択テストを行いました。チームは当初、持続可能性とパフォーマンスの面で私たちのニーズをよりよく満たすことができる会社の内部ストレージ コンポーネントを選択しました。しかし、エッジ シーンに関しては、2 つの特定の問題があります。
- まず第一に、同社の内部コンポーネントは中央のコンピューター ルーム用に設計されており、一部の周辺コンピューター ルームでは満たすことが困難な物理マシン リソースと数量の要件があります。
- 次に、オブジェクト ストレージ、ブロック ストレージ、分散ストレージ、ファイル ストレージなど、企業全体のストレージ コンポーネントがパッケージ化されます。一方、エッジ側では、主にファイル ストレージとオブジェクト ストレージが必要であり、これらを調整して変換する必要があります。オンライン厩舎にもプロセスが必要です。
チームが議論した後、実行可能なソリューションが形成されました: CephFS + MinIO ゲートウェイ。MinIO はオブジェクト ストレージ サービスを提供し、最終結果は CephFS に書き込まれ、レンダリング エンジンは CephFS をマウントしてレンダリング操作を実行します。テストと検証のプロセス中に、ファイル数が数千万に達したとき、CephFS のパフォーマンスが低下し始め、時にはフリーズし、ビジネス側からのフィードバックは要件を満たしていませんでした。
同様に、Ceph RGW + S3FS を使用する Ceph ベースの別のソリューションがあります。このソリューションは基本的に要件を満たすことができますが、ファイルの書き込みと変更のパフォーマンスはシーンの要件を満たしていません。
3 か月以上のテストを経て、エッジ レンダリングでのストレージに関するいくつかのコア要件が明確になりました。
- 運用と保守は複雑すぎてはなりません: ストレージの研究開発担当者は、運用と保守のドキュメントから始めることができます; その後の拡張とオンライン障害処理の運用と保守作業は十分に単純でなければなりません.
- データの信頼性: ストレージ サービスはユーザーに直接提供されるため、正常に書き込まれたデータが失われたり、書き込まれたデータと矛盾したりすることは許されません。
- 一連のメタデータを使用し、オブジェクト ストレージとファイル ストレージの両方をサポートする: このように、ビジネス側で使用する場合、ファイルを何度もアップロードおよびダウンロードする必要がなく、ビジネス側の使用の複雑さが軽減されます。
- 読解力の向上: チームは、読解力を上げて書く力を減らすというシナリオを解決する必要があるため、読解力の向上を期待しています。
- コミュニティ活動: 活発なコミュニティは、既存の問題を解決し、新しい機能の反復を積極的に促進する際に、より迅速に対応できます。
コア要件を明確にした後、以前の 3 つのソリューションはニーズを完全には満たしていないことがわかりました。
02- JuiceFS を使用する利点
Volcano Engine のエッジ ストレージ チームは、2021 年 9 月に JuiceFS について知り、Juicedata チームといくつかの情報交換を行いました。コミュニケーションの結果、エッジ クラウドのシナリオで試してみることにしました。JuiceFS の公式ドキュメントは非常に豊富で読みやすく、ドキュメントを読むことで詳細を知ることができます。
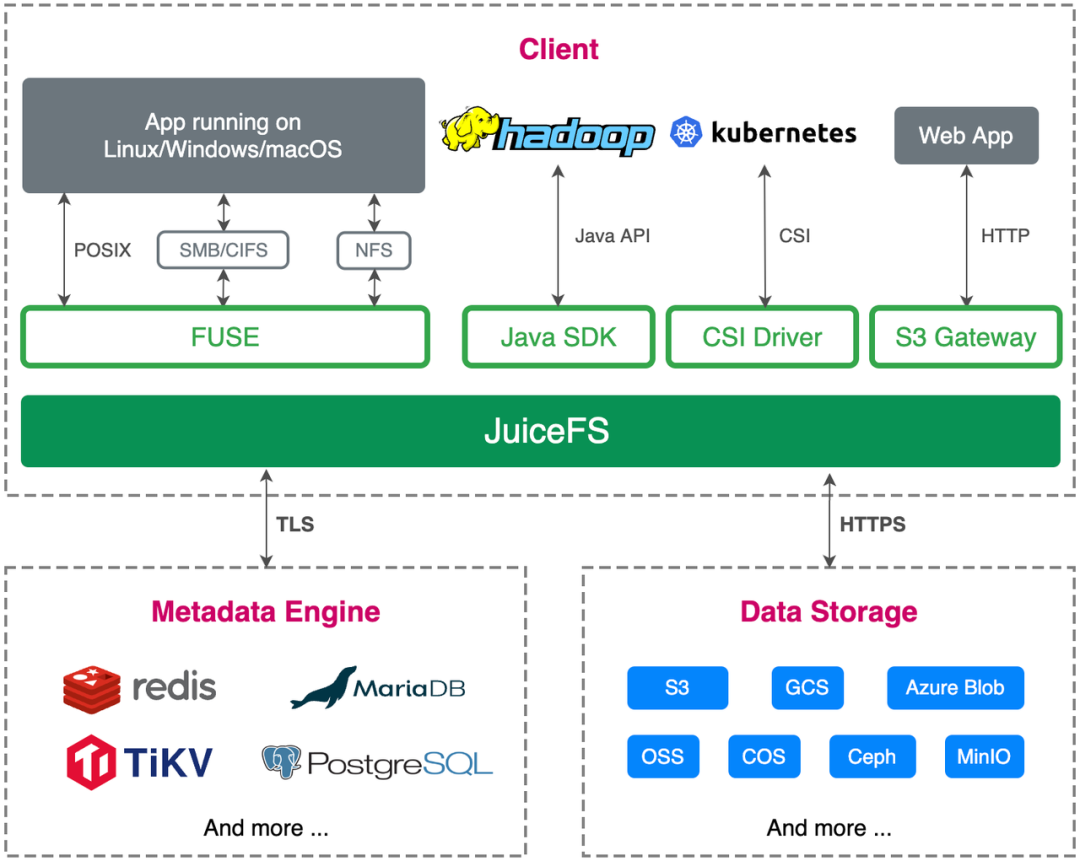
そのため、テスト環境でのPoCテストを開始し、実現可能性の検証、O&Mと展開の複雑さ、および上流ビジネスへの適応、および上流ビジネスのニーズを満たしているかどうかに焦点を当てました。
1 つは単一ノードの Redis + Ceph に基づいており、もう 1 つは単一インスタンスの MySQL + Ceph に基づいています。
全体的な環境構築に関しては、Redis、MySQL、および Ceph (Rook 経由でデプロイ) が比較的成熟しており、運用および保守計画をデプロイするための参考資料が比較的充実しているため、JuiceFS クライアントはこれらを接続することもできます。データベースと Ceph を簡単かつ便利に使用でき、導入プロセスは非常にスムーズです。
業務適応に関しては、クラウドネイティブをベースにエッジクラウドを開発・展開しており、JuiceFSはS3 API対応、POSIXプロトコル完全対応、CSI実装対応など、当社のビジネスニーズを十分に満たしています。
包括的なテストの結果、JuiceFS はビジネス サイドのニーズを完全に満たし、ビジネス サイドのオンライン ニーズを満たすために本番環境で展開および実行できることがわかりました。
メリット 1: ビジネス プロセスの最適化
JuiceFS を使用する前は、エッジ レンダリングは主に ByteDance の内部オブジェクト ストレージ サービス (TOS) を使用していました. ユーザーはデータを TOS にアップロードし、レンダリング エンジンはユーザーがアップロードしたファイルを TOS からローカルにダウンロードし、レンダリング エンジンはローカル ファイルを読み取ります.レンダリング結果を生成し、レンダリング結果を TOS にアップロードし、最後にユーザーがレンダリング結果を TOS からダウンロードします。全体的な相互作用プロセスにはいくつかのリンクがあり、途中で多くのネットワークとデータのコピーが関係しているため、このプロセスでネットワークのジッターや大きな遅延が発生し、ユーザー エクスペリエンスに影響を与えます。
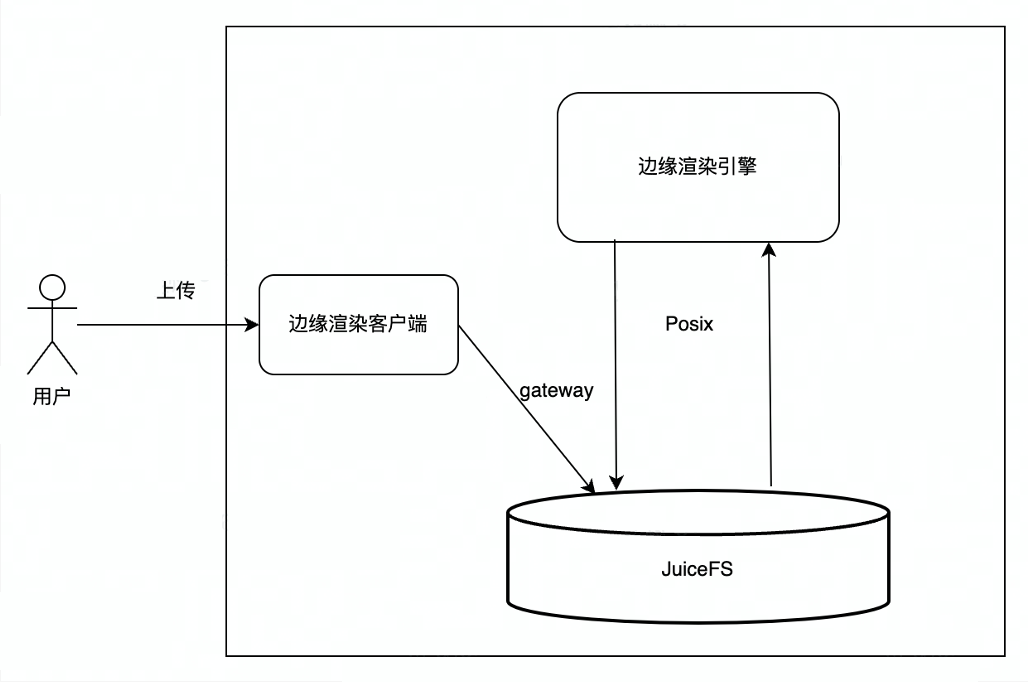
JuiceFS を使用した後、ユーザーは JuiceFS S3 ゲートウェイを介してアップロードするプロセスになります. JuiceFS はオブジェクト ストレージとファイル システムのメタデータの統合を実現するため、JuiceFS はレンダリング エンジンに直接マウントでき、レンダリング エンジンは POSIX インターフェイスを使用します。ファイルを処理する. 読み取りと書き込み, エンド ユーザーはレンダリング結果を JuiceFS S3 ゲートウェイから直接ダウンロードします.全体のプロセスはより簡潔で効率的で安定しています.
メリット 2: ファイルの読み取りと大容量ファイルのシーケンシャル書き込みの高速化
JuiceFS のクライアント側のキャッシュ メカニズムのおかげで、頻繁に読み取るファイルをレンダリング エンジンでローカルにキャッシュできるため、ファイルの読み取りが大幅に高速化されます。キャッシュをオープンするか否かの比較テストを行ったところ、キャッシュを使用することでスループットが約 3 ~ 5 倍向上することがわかりました。
同様に、JuiceFS の書き込みモデルは最初にメモリに書き込むため、チャンク (デフォルト 64M) がいっぱいになるか、アプリケーションが強制書き込みインターフェイス (close および fsync インターフェイス) を呼び出すと、データはオブジェクト ストレージにアップロードされます。データのアップロードが成功したら、メタデータ エンジンを更新します。したがって、大きなファイルを書き込むときは、最初にメモリに書き込み、次にディスクに書き込むと、大きなファイルの書き込み速度が大幅に向上します。
現在、エッジの使用シナリオは主にレンダリングであり、ファイルシステムは読み取りが多く書き込みが少なく、ファイル書き込みも主に大きなファイル用です。これらのビジネス シナリオの要件は、JuiceFS の適用可能なシナリオと非常に一致しており、ビジネス側がストレージを JuiceFS に置き換えた後、全体的な評価も非常に高くなります。
03- エッジ シーンでの JuiceFS の使用方法
JuiceFS は主に Kubernetes にデプロイされ、各ノードには JuiceFS ファイル システムのマウントを担当する DaemonSet コンテナーがあり、HostPath の形式でレンダリング エンジンのポッドにマウントされます。マウント ポイントが失敗した場合、DaemonSet はマウント ポイントを自動的に復元します。
権限制御に関しては、エッジ ストレージは LDAP サービスを使用して JuiceFS クラスター ノードの ID を認証し、JuiceFS クラスターの各ノードは LDAP クライアントと LDAP サービスによって認証されます。
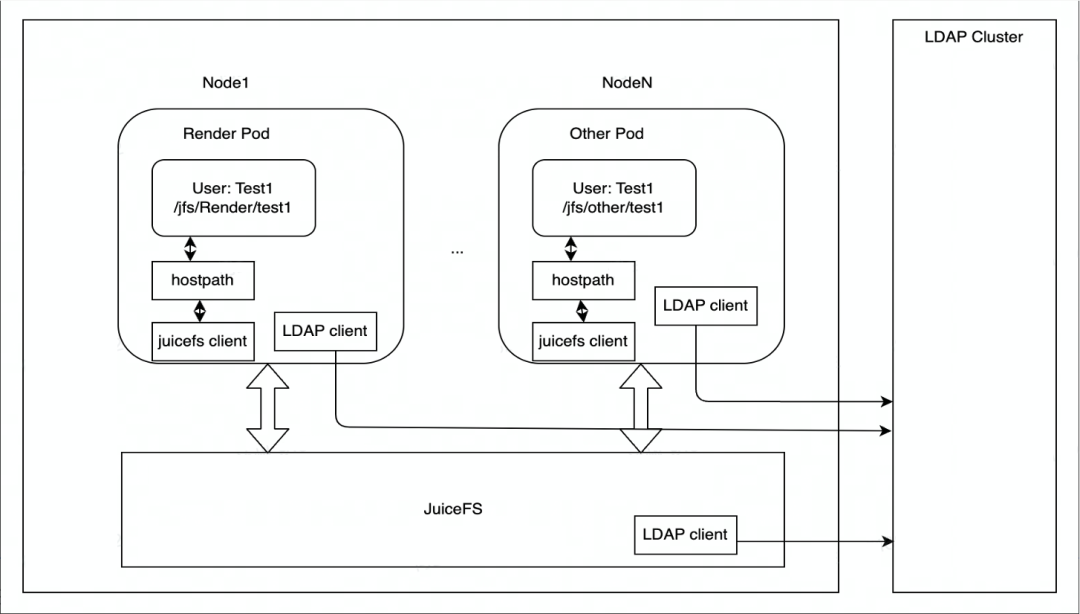
現在のアプリケーション シナリオは主にレンダリングに基づいており、将来的にはより多くのビジネス シナリオに拡張される予定です。データアクセスに関しては、現在は主に HostPath 経由でエッジストレージにアクセスしていますが、将来的に柔軟な拡張が必要になった場合は、JuiceFS CSI Driver の導入を検討します。

04- 本番環境での実務経験
メタデータ エンジン
JuiceFS は多数のメタデータ エンジン (MySQL、Redis など) をサポートしており、Volume エンジンのエッジ ストレージの運用環境は MySQL を使用しています。データ量とファイル数 (ファイル数は数千万、おそらく数千万、読み取りが多く書き込みが少ないシナリオ) の規模、および書き込みと読み取りのパフォーマンスを評価した結果、 MySQL の運用と保守、データの信頼性、そしてビジネス面での成果が向上していること。
MySQL は現在、シングル インスタンスとマルチ インスタンス (1 つのマスターと 2 つのスレーブ) の 2 つの展開スキームを採用しており、エッジでのさまざまなシナリオに合わせて柔軟に選択できます。リソースが少ない環境では、単一のインスタンスをデプロイに使用でき、MySQL のスループットは特定の範囲内で比較的安定しています。これらのデプロイ スキームは両方とも、高性能のクラウド ディスク (Ceph クラスターによって提供される) を MySQL データ ディスクとして使用するため、単一インスタンスのデプロイでも MySQL データが失われないことが保証されます。
リソースが豊富なシナリオでは、デプロイに複数のインスタンスを使用できます。複数のインスタンスのマスター/スレーブ同期は、MySQL オペレーター( https://github.com/bitpoke/mysql-operator )によって提供されるオーケストレーター コンポーネントを通じて実現されます。2 つのスレーブ インスタンスが正常に同期された場合にのみ OK と見なされますが、タイムアウトタイムアウトが経過しても同期が完了していない場合は、成功を返し、アラームが発行されます。後の災害復旧計画が完了した後、ローカル ディスクを MySQL のデータ ディスクとして使用して、読み取りと書き込みのパフォーマンスをさらに向上させ、待ち時間を短縮し、スループットを向上させることができます。
MySQL 単一インスタンス構成コンテナー リソース:
- CPU:8C
- メモリー: 24G
- ディスク: 100G (Ceph RBD に基づくと、数千万のファイルを格納するシナリオでは、メタデータは約 30G のディスク領域を占有します)
- コンテナー イメージ: mysql:5.7
MySQLmy.cnfの構成:
ignore-db-dir=lost+found # 如果使用 MySQL 8.0 及以上版本,需要删除这个配置
max-connections=4000
innodb-buffer-pool-size=12884901888 # 12G
オブジェクト ストレージ
The object storage uses a self-built Ceph cluster , which is deployed through Rook. 現在の運用環境では Octopus バージョンを使用しています。Rook を使用すると、Ceph クラスターをクラウドネイティブな方法で運用および維持でき、Ceph コンポーネントを Kubernetes を介して管理および制御できるため、Ceph クラスターのデプロイと管理の複雑さが大幅に軽減されます。
Ceph サーバーのハードウェア構成:
- 128 核 CPU
- 512GBのRAM
- システムディスク: 2T * 1 NVMe SSD
- データディスク: 8T * 8 NVMe SSD
Ceph サーバー ソフトウェアの構成:
- OS: デビアン 9
- カーネル: /proc/sys/kernel/pid_max を変更
- Ceph バージョン: Octopus
- Ceph ストレージ バックエンド: BlueStore
- Ceph レプリカの数: 3
- 配置グループの自動調整機能をオフにする
エッジ レンダリングの主な焦点は低レイテンシと高性能であるため、サーバー ハードウェアの選択に関しては、クラスターを NVMe SSD ディスクで構成します。他の構成は主に Volcano エンジンによって維持されるバージョンに基づいており、選択したオペレーティング システムは Debian 9 です。データの冗長性を確保するため、Ceph には 3 つのコピーが構成されていますが、エッジ コンピューティング環境では、リソースの制約により EC が不安定になる場合があります。
JuiceFS クライアント
JuiceFS クライアントは Ceph RADOS への直接接続をサポートしていますが (Ceph RGW よりも優れたパフォーマンス)、この機能は公式バイナリではデフォルトで有効になっていないため、JuiceFS クライアントを再コンパイルする必要があります。コンパイルする前に librados をインストールする必要があります. librados のバージョンは Ceph のバージョンに対応することをお勧めします. Debian 9 には Ceph Octopus (v15.2.*) バージョンに一致する librados-dev パッケージがないため, ダウンロードする必要があります.インストールパッケージを自分で。
librados-dev をインストールしたら、JuiceFS クライアントのコンパイルを開始できます。ここでは Go 1.19 を使用してコンパイルします. 1.19 では、最大メモリ割り当てを制御する機能( https://go.dev/doc/gc-guide#Memory_limit )が追加され、 JuiceFS クライアントが過度に占有するのを防ぐことができます。極端な場合、 OOM はより多くのメモリが原因で発生します。
make juicefs.ceph
JuiceFS クライアントをコンパイルした後、ファイル システムを作成し、JuiceFS ファイル システムをコンピューティング ノードにマウントすることができます. 詳細な手順については、JuiceFS の公式ドキュメントを参照してください.
05- 今後と展望
JuiceFS は、クラウド ネイティブ分野の分散型ストレージ システム製品です.クラウド ネイティブの展開方法を非常によくサポートできる CSI ドライバー コンポーネントを提供します.それは、運用および保守展開に関して非常に柔軟な選択肢をユーザーに提供します.ユーザーはクラウドを選択できます、ストレージの拡張と運用と保守の点で比較的単純な民営化された展開を選択することもできます。POSIX 標準と完全に互換性があり、S3 と同じメタデータ セットを使用するため、アップロード、処理、およびダウンロードの操作プロセスを実行するのが非常に便利です。そのバックエンド ストレージはオブジェクト ストレージ機能であるため、ランダムな小さなファイルの読み取りと書き込みに大きな遅延があり、IOPS は比較的低くなります.書き込みが多くて少ないシナリオでは、JuiceFS には比較的大きな利点があります。エッジ レンダリング シナリオのビジネス ニーズに適しています。
JuiceFS に関連する Volcano Engine エッジ クラウド チームの今後の計画は次のとおりです。
- よりクラウドネイティブ: 現在、JuiceFS は HostPath の形式で使用されていますが、後で、いくつかのエラスティック スケーリング シナリオを考慮して、CSI ドライバーの形式で JuiceFS の使用に切り替える可能性があります。
- メタデータ エンジンのアップグレード: メタデータ エンジンの gRPC サービスを抽象化します。これにより、複数レベルのキャッシュ機能が提供され、より多くの読み取りとより少ない書き込みのシナリオにうまく適応できるようになります。基礎となるメタデータ ストレージは、より多くのファイルをサポートするために TiKV への移行を検討する場合があります.MySQL と比較して、水平展開によりメタデータ エンジンのパフォーマンスを向上させることができます。
- 新機能とバグ修正: 現在のビジネス シナリオでは、いくつかの機能が追加され、いくつかのバグが修正されます。コミュニティに PR を提供し、コミュニティに還元することを期待しています。
お役に立てれば、私たちのプロジェクトJuicedata/JuiceFSに注目してください! (0ᴗ0✿)