記事ディレクトリ
最近はChatGPTが流行っていますし、NLPの学生はもっと深く感じること間違いなしです。NLP のアプリケーションが知られ、積極的に展開されていることは良いことですが、アプリケーション レベルでのすべてのアプリケーション シナリオは、過去のドメインで SOTA モデルによって継続的に克服されてきたタスクです。残念ながら、近年、アルゴリズム レベルで単一のタスクを解決するブレークスルーは大幅に減速していますが、アプリケーション レベルでは加速しています。
ps: 現在、「スカイネット」という言葉は情報に出ていませんが、VR も AR も何もなかった当時、「スカイネット」の言及は山や平野のいたるところで行われていました。
ここでは、比較的単純で一般的に使用されている機械学習モデル SVM を使用して、タイミングを助け、超過リターンを取得します。

機械学習の定量モデルへの応用
機械学習の定量化のアプリケーション シナリオ
ブロガーによって要約された機械学習アプリケーションと定量的戦略には、次の 3 つのシナリオがあります。
- 勝率が50を超えるクオンツ戦略を構築します。モデルが説明可能かどうかに関係なく、トランザクション数を増やすことで、包括利益が移動平均にシフトし、期待される超過リターンが得られます。
- 超過リターンが得られる可能性のある論理的な枠組みの上で、機械学習モデルを使用して詳細を最適化し、モデルの祝福の下で平均期待リターンがより高いリターンにシフトするようにします
- 価格設定モデルに基づいて、修正された市場から超過収益を得る
そして、各シナリオは異なる定量化のアイデアに対応し、さまざまな研究者の知識システムにも対応しています。
- 前者は十分なプロフェッショナリズムを備えたエンジニアリングのバックグラウンドに適しています.難点は「歴史は繰り返さない」という前提にあります.実証モデルは超過収益を得ることができ,超過収益の獲得も高確率のイベントです.主に高-周波数取引
- 2つ目はプログラミング能力のある金融関係者向き 難点は、超過リターンが得られる論理連鎖の実証にある
- 第 3 のタイプは、プログラミングの能力と経験を持つ金融関係者に適していますが、難しいのは、市場のノイズ情報を特定して除去すること、または価格モデルを修正して最適化することです。
定量モデルの有効性を考える
現在のコンセンサスは、投資タスクの複雑さは機械学習の範囲をはるかに超えているということです。そのため、機械学習モデルを使用して、人工的に構築された論理フレームワーク内で最適化する必要があります。
これまで勉強した後、私は定量的な本や戦略をたくさん読みました.ブロガーはいくつかの考えを持っており、あなたと共有したいと考えています:
- 実際、ブロガーなどの多くの学生がコンピューター サイエンスから金融に転向しているため、「定量化」は私たちにとって良い入り口であり、データ分析に傾倒すればするほど、私たちにとってより快適になります。しかし、人間対アルゴリズム:
- 人間の長所は、ノイズを取り除くこと、要約すること、本を読めなくなることです。
- 機械の利点は次のとおりです。統計、推論、および本をより厚く読む能力
半世紀以上にわたって開発されてきた計量経済学モデルは、金融と価格設定の「結果データ」は、その情報構成がカオス的でランダムであることを示しています。 」、アルゴリズムの結果は、思考を支援するどころか、せいぜいインスピレーションを与えるだけです. 同時に、「多ければ多いほど良い」ではなく、不要な特徴はノイズの元であり、機械はそれを自分でフィルタリングすることはできません。 " アルゴリズムを構築します。
- パラメーターの調整に加えて、機械学習モデルの改善には一般に次の 2 つの効果があります。
- 論理的な精査に耐えることができる人工的に構築された特徴シーケンス
- データ分析の固有のルールに従って特徴を事前に排除しないでください
経験上、ブロガーがよく使うランダムフォレストモデルのように、パラメータをチューニングせずに特徴やデータを調整するだけで効果を上げたい場合は、偏った分布などに基づいてまずこの特徴を削除しないでください。各機能はパースペクティブであるため、一部のパースペクティブはより正確ですが、一部のパースペクティブは明確で奇妙です. 現時点では、これらの機能に一致するいくつかの適切な視点を構築し、機能を再処理するために、人間の参加が必要です。機能の重要性が低いほど、インスピレーションの源が多くなり、改善の余地が大きくなります! それを事前に排除するのは大きな損失です。
- 専門知識の違いは、「学んだ人は人格になる」ということわざのように、世界を別の視点から見るようにします。金融を専攻する学生は、「リスクマネジメント」を第一に考えると同時に、「生存者バイアス」事件を本能的に認識する能力が非常に強力です!しかし、私の観察によると、「理論的平均」を追求するために、多くの定量的戦略はデータ理論に依存し、モデルを甘やかすため、特別な注意が必要です。
このブログでは、計算に SVM モデルのみを使用しています. その他の機械学習モデルについては、https: //blog.csdn.net/weixin_35757704/article/details/89280669を参照してください。
定量的タイミングにおける機械学習モデルの応用
トレーニングと予測のプロセス
機械学習の使用には通常、次の手順があります。
- データクリーニング
- トレーニング セットとテスト セットの分割
- トレーニング セットを使用して、モデルの安定性を相互検証します
- テストセットはモデルの有効性を判断します
- アプリケーションモデルの計算とバックテスト
したがって、時間を次の 2 つの部分に分けます。
- トレーニングおよびテスト データの時間: 2015-01-01 から 2020-01-01
- アプリケーションモデルの計算とバックテスト時間: 2020-01-01 から 2023-01-01
トレーニング データの特徴の構築
ここでは、便宜上、より単純な機能を構築します。
- 過去 5 日間の平均離職率
- 過去 10 日間の平均離職率
- 過去 5 日間の変化
- 過去 10 日間の変化
- MACD インジケーター DIF 値
- MACD インジケーター DEA 値
- MACD値
- アルーンインジケーター(モメンタムインジケーター) DOWN値
- アルーン指数UP値
SVM モデルと計算
SVM のトレーニングと予測
通常、データを取得した後、最終的な収入を目標とするモデルには、主に次のトレーニング目的があります。
- 将来のある期間の収益率を直接予測する
- 将来のある期間の収益の範囲を予測する
機械学習モデルのパフォーマンスは限られているため、最終的な目標が通常収益率である場合、「将来のある期間の収益範囲を予測する」ことを選択します。
したがって、次のルールに従ってトレーニングと予測を行います。
- データの 70% がトレーニング セットとして使用され、データの 30% がテスト セットとして使用されます。
- [今後 5 日間の上昇と下降] を予測対象として、同時にデータをビンに分割し、次のように分割します。
- 利回り範囲: [マイナス無限大, -1]
- 利回り間隔: [-1, 1]
- 利回り範囲: [1, 正の無限大]
- トレーニング セットで、10 回の交差検証を行う
- テスト セットは混同行列を計算し、それを視覚化します
上記の「クロスバリデーション」とは、オーバーフィッティングとアンダーフィッティングの問題を判断することであり、多くの記事では「オーバーフィッティング」を悪い結果のせいにする傾向がありますが、明らかに問題があります。オーバーフィッティングとアンダーフィッティングについては、https: //blog.csdn.net/weixin_35757704/article/details/123931046を参照してください。
効果測定
計算プロセスは次のとおりです。
- 2015-01-01 から 2020-01-01 までのすべての非 ST ストックを収集
- 次に、個別銘柄の株価動向に応じて、上記の9つの特徴を構築します
- データの 70% をトレーニング セットとして、データの 30% をテスト セットとして
- トレーニング セットで 10 回の相互検証を行う
上記のトレーニングと予測のルールに従って、次のモデル結果が得られます。
-
上記の計算プロセスに従って計算すると、テスト セットでの正解率は 0.4751 です。
-
正規化された混同行列は次のとおりです。
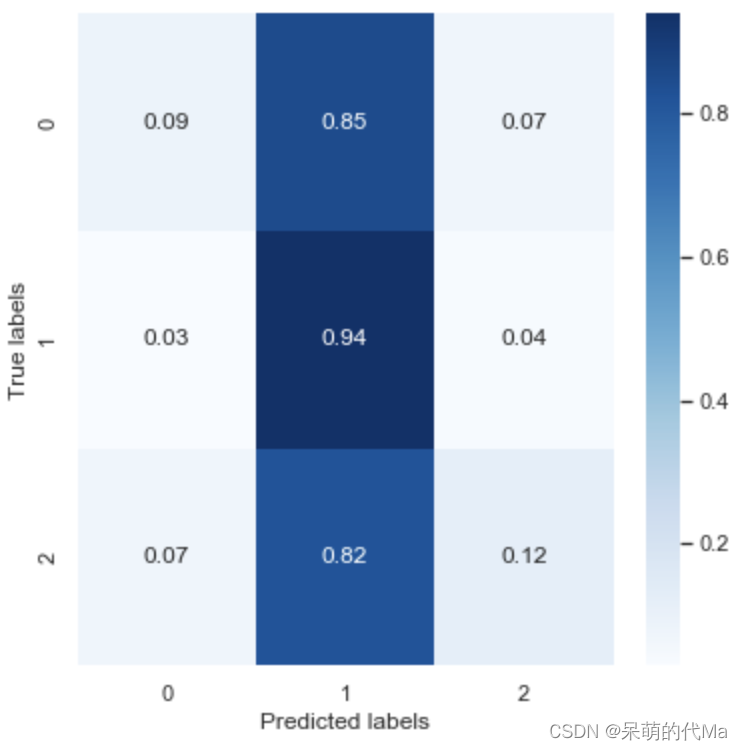
-
10 分割交差検証を使用した結果は次のとおりです。
| 精度効果 | 0.492502 | 0.488092 | 0.478529 | 0.473529 | 0.485882 | 0.477647 | 0.477059 | 0.484118 | 0.480882 | 0.486176 |
|---|
実際の使用では、モデルの論理的効果に従って判断します: モデルがプラスのリターンを予測する場合は購入し、モデルがマイナスのリターンを予測する場合は売ります。
有効性分析
- 交差検証の効果は、テスト セットの予測効果と同様であり、SVM モデルのパフォーマンスが比較的安定していることを示しています。
- SVM はカテゴリ 1 として 0、1、2 などのカテゴリの違いをほとんど予測せず、カテゴリ自体に関係なく、0 と 2 を計算する正解率はわずか 10% です。
最適化、調整、または主観的な構造的特徴がないため、この効果は非常に満足のいくものであり、裸のモデルの効果はほぼ同じ効果です...