Table of contents
1. Some introductory knowledge points of human gesture recognition
2. Brief introduction of Blazepose algorithm
3. Realization of AI fitness system
foreword
With the rise of the national fitness craze, more and more people actively participate in fitness exercises, but due to the lack of scientific exercise guidance, it is difficult to achieve corresponding results in fitness. According to market research, there is no product that can automatically analyze fitness exercises and provide guidance. In recent years, the deep neural network has achieved great success in human body posture recognition. In response to this phenomenon, this paper designs an AI fitness coaching system based on the BlazePose algorithm in OpenCv and MediaPipe. The main content of the system includes the detection of key points of a single human body, the connection of key points, and the display of angle changes of key points in sports and fitness. The AI fitness coaching system can read in pictures or video files to process, and display the angle changes of the key points of the exercise.
1. Some introductory knowledge points of human gesture recognition
-
Anyone
-
where are people
-
Who is this guy
-
what state is this person in at the moment
-
What is this person doing in the current period of time
-
Top-down
-
First detect the human body , use the front-end target detection network to identify the bounding box of the human body in the picture, HRnet() greatly improves Since Top-down eliminates most of the background in the target detection stage, there are few background noises or other human key points, which simplifies the key point heat map estimation, but consumes a lot of computational cost in the human target detection stage. and is not an end-to-end algorithm
-
Disadvantages: It is very dependent on the results of human body posture detection (if two people are close together, sometimes only one box information will be obtained, and the final result will be one less person), the speed of the algorithm and the number of people on the picture In direct proportion, if there are 30 people in a picture, it needs to repeat the human body estimation of a single person 30 times, which makes this method very slow in complex scenes
-
-
Bottom-up
-
It first predicts the positions of all human keypoints in the image, and then connects the keypoints into different human body instances.
-
Representative work includes:
-
The DeepCut method and the DeeperCut method pioneered the key point association problem as an integer linear programming problem, which can be effectively solved, but the processing time is as long as several hours.
-
The Openpose method can basically achieve real-time detection. The PAF component is used to predict the missing of the human body, and the key points that the links may belong to the same person. The PifPaf method further expands this method and improves the accuracy of the connection.
-
The Associative embedding method maps each key point to a "label" to which the recognized object belongs, and the label directly associates each predicted key point with other key points of the same group to obtain the predicted human pose.
-
The PersonLab method uses short-distance offset to improve the accuracy of key point prediction, and then groups the predicted key points into a pose estimation instance through greedy decoding and Hough voting.
-
-
Bottom-up is generally less complex and faster than Top-down algorithms, and it is an end-to-end algorithm. The accuracy of Top-down is relatively higher .
-

-
2. Brief introduction of Blazepose algorithm
Demo was inspired by a paper published by Google in CVPR2020. Blazepose belongs to a type of Bottom-up.
The characteristic of this algorithm is that the overall speed has been significantly improved.
Blaze is flame, that is to say, the core point of this algorithm is that its speed is very fast, rather than its accuracy. Compared with the traditional openpose, its fps is several times higher, and the gap in accuracy is not very large. This makes this algorithm very suitable for the development of today's mobile devices
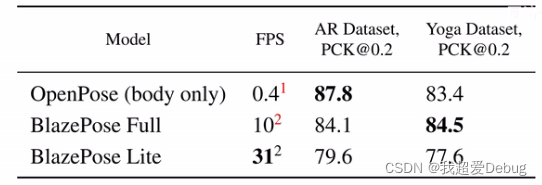
Through the comparison of fps, it can be clearly seen that the speed of Blazepose has improved.
([email protected] is a classic indicator of human body posture detection, which means that if the Euclidean distance between the coordinates of the points predicted by the model and the real point coordinates is less than 20% of the distance of the entire human torso, it is judged as a prediction Yes)
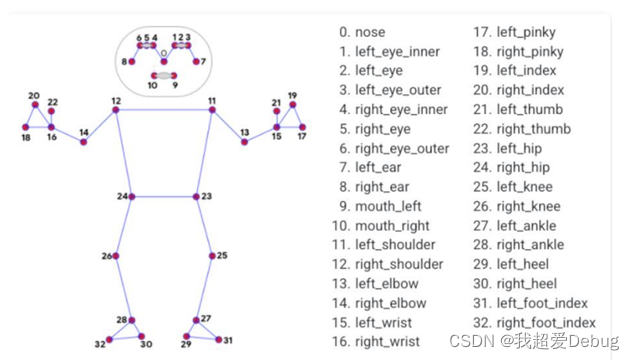
The traditional coco dataset competition requires 18 key points, we can see that blazepose can reach 33 key points,
The main contributions of this article are:
(1) A new human body posture tracking solution;
(2) Lightweight human pose estimation network.
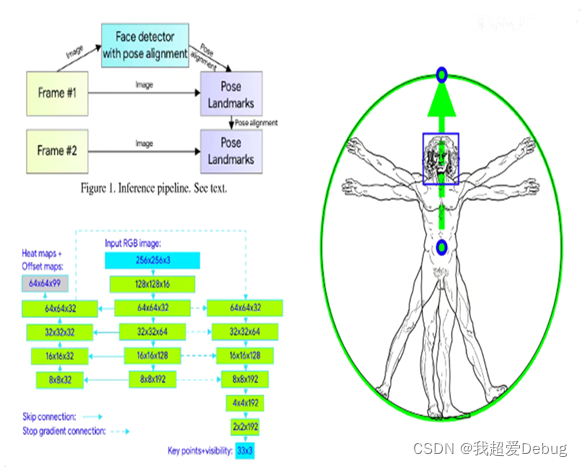
1. A new human body posture tracking method
The traditional human body posture detector is upgraded to a face detector , and the output data of the previous frame image can be used as the input of the next frame image. When there is no face in the image of the previous frame, it will be re-detected, which will make the overall rate higher
This idea originated from Da Vinci's "Vitruvian Man" inspiration map, through the human face, the focus of the shoulders, and the midpoint of the two hips to form a vertical line segment, so as to draw a circumscribed circle to define the bounding box of the human body.
2. Lightweight Human Pose Estimation Network
The network model combines two mainstream techniques,
heat maps (heat map technology and regression encoder (regression encoder technology,
The heat map means that what I output is a grayscale image, the size of which is the same as the original image, but the pixels represent the probability of a certain key point appearing, for example, at the position of the elbow, you can see the sign through the heat map Here is the area where the key points of the elbow exist. Contrary to the technology based on heatmaps, although the regression-based method has lower requirements for calculation and higher scalability, even if the number of parameters is small, stacking The stacked hourglass architecture can also greatly improve the prediction accuracy. An encoder-decoder network architecture is used to predict heatmaps for all joints, followed by another encoder that directly regresses to all joint coordinates. In the reasoning process, we can abandon the graph output by the heat map, but directly obtain the output results of the key points. The solid line is skip-connections, and the dotted line means that it will not propagate back along the arrow.
In the real prediction, we don't need the output map of the heat map, but directly obtain the output results of the key points, so that the purpose of increasing the speed can be achieved
3. Realization of AI fitness system
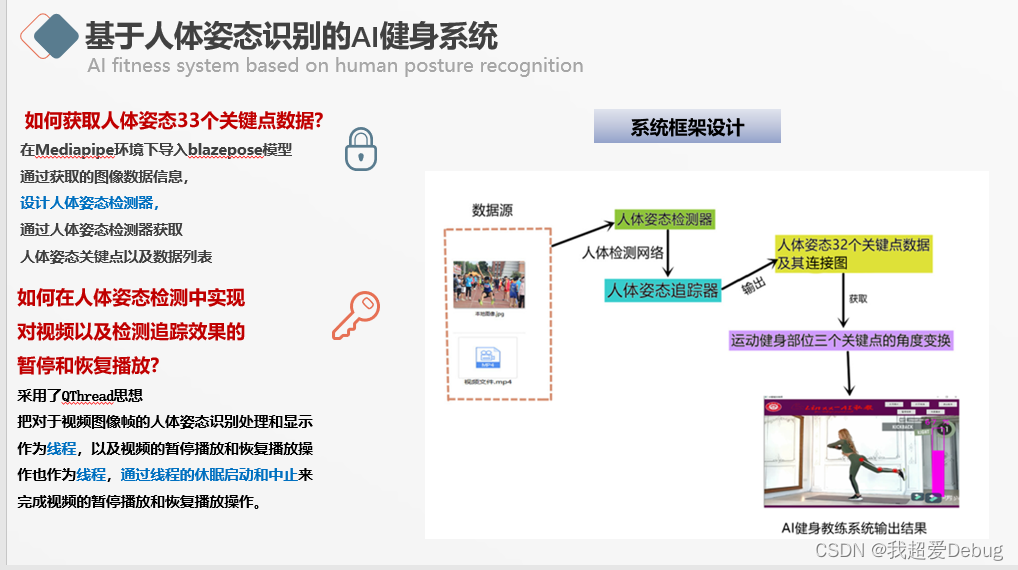
Media Pipe - Media Pipe is an open source, cross-platform framework for building multi-model machine learning pipelines. It can be used to implement cutting-edge models such as face detection, multi-hand tracking, hair segmentation, object detection and tracking, etc.
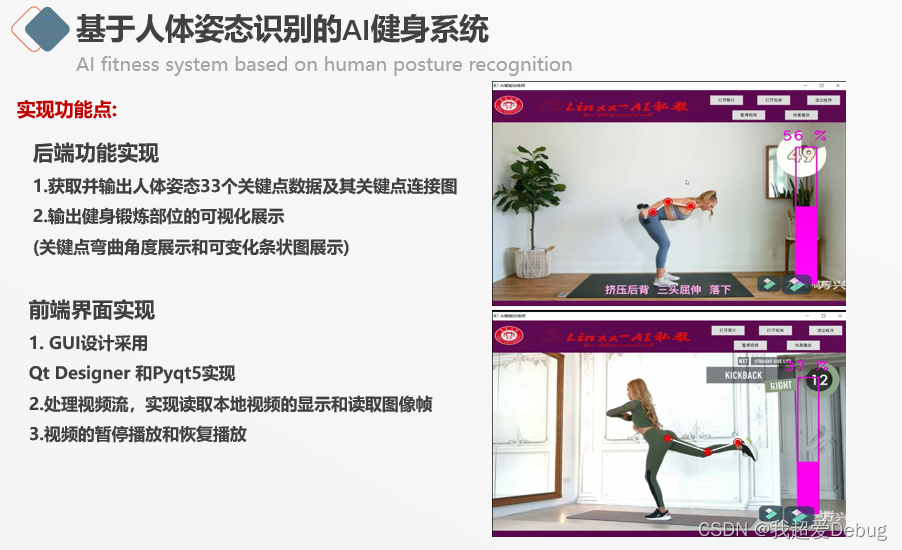
The backend mainly realizes the acquisition and output of data of 33 key points of the human body posture, because what I am doing is an AI fitness system, and the key points of the parts to be exercised are connected, and the bending of the exercised parts can be clearly seen visually The angle, as well as the display of the variable bar graph next to it, solve the problem of unclear power exertion of fitness actions in traditional fitness models
The front-end GUI is implemented with Qt Designer and pyqt5. The difficulty here is that this is not an ordinary video pause and resume playback. Here, the key points of human body posture have been identified and detected, and the corresponding visualization. What we need is to synchronize the front and back ends to pause and resume,
First, the video frame is extracted and divided into a frame-by-frame image. Because the target detection module and the two-dimensional human pose recognition module use images as input, the video needs to be processed into images. The blazepose network model imported in the Mediapipe environment obtains the key points of the human body posture by designing a human body posture detector . Human gesture recognition and processing in the video image frame, video pause and playback are also used as threads , and the pause and resume playback of the entire picture is completed by starting and stopping the sleep of the thread
video display
BlazePose+Pyqt5+OpenCV=>AI fitness system based on human gesture recognition_哔哩哔哩_bilibili