ChatGPT 強化学習の大きなキラー - 近位戦略最適化 (PPO)
Proximal Policy Optimization ( Proximal Policy Optimization ) は、現在最も高度な強化学習 (RL) アルゴリズムであるProximal Policy Optimization Algorithms (Schulman et. al., 2017)という論文から来ています。この洗練されたアルゴリズムは、さまざまなタスクに使用でき、多くのプロジェクトで適用されており、最近人気のある ChatGPT がこのアルゴリズムを採用しています。
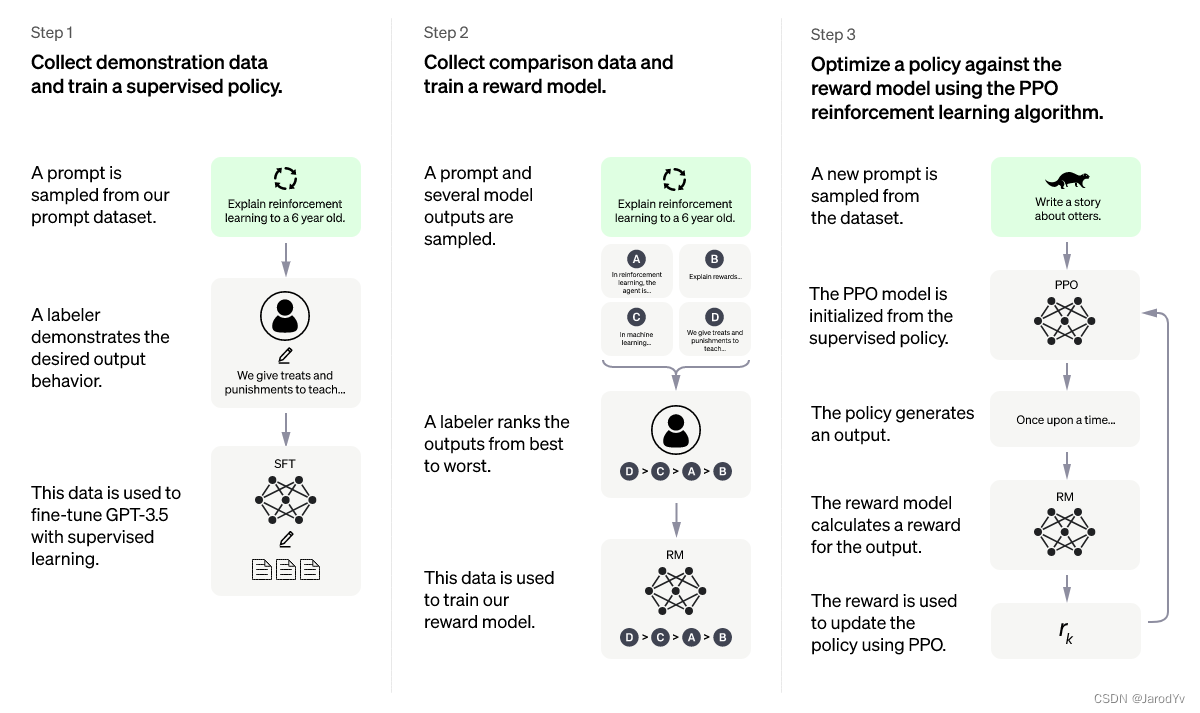
ChatGPT アルゴリズムとトレーニング プロセスを説明する記事はインターネット上にたくさんありますが、主要な近位戦略最適化アルゴリズムを詳細に説明している人はほとんどいません.この記事では、近位戦略最適化アルゴリズムの説明に焦点を当て、PyTorch を使用してゼロから実装します.
強化学習
高度な強化学習アルゴリズムとして、近位戦略の最適化には強化学習の理解が必要です。強化学習に関する記事はたくさんありますが、ここではあまり紹介しませんが、ChatGPT が説明している内容は次のとおりです。

ChatGPTの説明は比較的分かりやすいですが、より学術的に言えば、強化学習のプロセスは次のようになります。

上の図では、環境は各時点でエージェントに報酬をフィードバックし、現在の状態を監視しています。この情報を使用して、エージェントは環境内でアクションを実行し、新しい報酬、状態などがエージェントにフィードバックされ、ループが形成されます。このフレームワークは非常に一般的で、さまざまな分野に適用できます。
私たちの目標は、報酬を最大化するエージェントを作成することです。通常、この最大化報酬は、個々の時間割引報酬の合計です。
G = ∑ t = 0 T γ trt G = \sum_{t=0}^T\gamma^tr_tG=t = 0∑Tct rt
ここでγ \gammaγは割引係数で、通常は [0.95, 0.99] の範囲で、rt r_trtは時間 t での報酬です。
アルゴリズム
では、強化学習の問題をどのように解決するのでしょうか? さまざまなアルゴリズムがあり、(マルコフ決定プロセスまたは MDP の場合)モデルベース(環境のモデルを作成する) とモデルフリー(与えられた状態のみを学習する) の 2 つのカテゴリに分類できます。
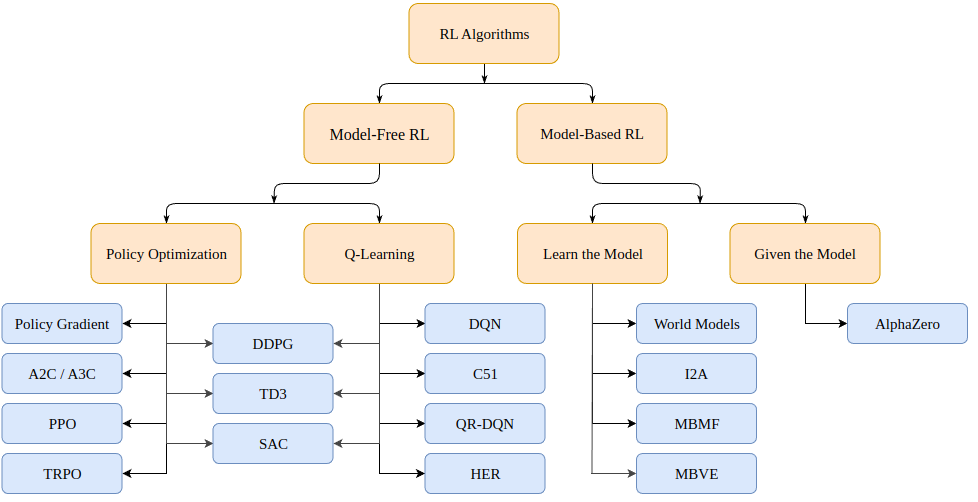
モデルベースのアルゴリズムは、環境のモデルを作成し、そのモデルを使用して将来の状態と報酬を予測します。モデルは (チェス盤など) 与えられるか、学習されます。
モデルフリー アルゴリズムは、トレーニング中に発生した状態に対処する方法 (ポリシーの最適化または PO) と、どの状態アクションが適切な報酬をもたらすか (Q ラーニング) を直接学習します。
今日説明する近位ポリシー最適化アルゴリズムは、PO アルゴリズム ファミリーに属します。したがって、学習を促進するために環境のモデルは必要ありません。PO アルゴリズムと Q ラーニング アルゴリズムの主な違いは、PO アルゴリズムは連続的なアクション スペースがある環境 (つまり、アクションに真の値がある) で使用でき、最適な戦略を見つけることができますが、Q ラーニング アルゴリズムは両方を実行できないことです。これが、PO アルゴリズムがより一般的に使用されるもう 1 つの理由です。一方、Q-Learning アルゴリズムは、より単純で直感的で、トレーニングが容易になる傾向があります。
ポリシーの最適化 (勾配ベース)
ポリシー最適化アルゴリズムは、ポリシーを直接学習できます。この目的のために、ポリシーの最適化では、遺伝的アルゴリズムなどの勾配のないアルゴリズムや、より一般的な勾配ベースのアルゴリズムを使用できます。
勾配ベースの方法とは、累積報酬に関して学習したポリシーの勾配を推定しようとするすべての方法を意味します。この勾配 (またはその近似値) がわかっている場合は、ポリシーのパラメーターを勾配の方向に単純にシフトして、報酬を最大化できます。
方策勾配法は、勾配g : = ∇ θ E [ ∑ t = 0 ∞ rt ] g:=\nabla_\theta\mathbb{E}[\sum_{t=0}^{\infin}r_t] を繰り返し推定します。g:=∇私そして[ ∑t = 0∞rt]期待される総報酬を最大化します。ポリシーの勾配には、次のようなさまざまな関連式があります。
g = E [ ∑ t = 0 ∞ Ψ t ∇ θ log π θ ( at ∣ st ) ] (1) g=\mathbb{E}\Bigg\lbrack \sum_{t=0}^{\infin} \Psi_t \nabla_\theta log\pi_\theta(a_t \mid s_t) \Bigg\rbrack \tag{1}g=そして[t = 0∑∞Pst∇私ローグパイ_ _ _私( _t∣st) ]( 1 )
ここで、Ψ t \Psi_tPst次のいずれかになります。
- ∑ t = 0 ∞ rt \sum_{t=0}^\infin r_t∑t = 0∞rt: 軌跡の総報酬
- ∑ t ' = t ∞ rt ' \sum_{t'=t}^\infin r_{t'}∑t' =t∞rt': a_t での次のアクションat褒美
- ∑ t = 0 ∞ rt − b ( st ) \sum_{t=0}^\infin r_t - b(s_t)∑t = 0∞rt−b (秒t) : 上記の式のベースライン バージョン
- Q π ( st , at ) Q^\pi(s_t, a_t)Qπ (秒t、at) : 状態アクション値関数
- A π ( st , a t ) A^\pi(s_t, a_t)あπ (秒t、at) : アドバンテージ関数
- rt + V π ( st + 1 ) + V π ( st ) r_t+V^\pi(s_{t+1})+V^\pi(s_{t})rt+のπ (秒t + 1)+のπ (秒t) : TD残差
次の 3 つの式の具体的な定義は次のとおりです。
V π ( st ) : = E st + 1 : ∞ , at : ∞ [ ∑ l = 0 ∞ rt + l ] Q π ( st , at ) : = E st + 1 : ∞ , + 1 : ∞ [ ∑ l = 0 ∞ rt + l ] (2) V^\pi(s_t) := \mathbb{E}_{s_{t+1:\infin}, a_ {t: \infin}}\Bigg\lbrack\sum_{l=0}^\infin r_{t+l} \Bigg\rbrack \\ Q^\pi(s_t, a_t) := \mathbb{E}_ {s_{ t+1:\infin}, a_{t+1:\infin}}\Bigg\lbrack\sum_{l=0}^\infin r_{t+l} \Bigg\rbrack \tag{2}のπ (秒t):=とst + 1 : ∞、_t : ∞な[l = 0∑∞rt + l]Qπ (秒t、at):=とst + 1 : ∞、_t + 1 : ∞な[l = 0∑∞rt + l]( 2 )
A π ( st , at ) : = Q π ( st , at ) − V π ( st ) (3) A^\pi(s_t, a_t) := Q^\pi(s_t, a_t) - V^\pi (s_t) \tag{3}あπ (秒t、at):=Qπ (秒t、at)−のπ (秒t)( 3 )
勾配を推定する方法は複数あることに注意してください。ここでは、合計報酬、後続のアクションの報酬、ベースライン バージョンを差し引いた報酬、状態-アクション値関数、支配関数 (元の PPO 論文で使用)、および時間差 ( TD) 残差。これらの値を最大化の目的として選択できます。原則として、どちらも関心のある真の勾配の推定値を提供します。
近位戦略の最適化
近接ポリシー最適化 (略して PPO) は、ポリシー最適化勾配に基づく (モデルフリー) アルゴリズムです。アルゴリズムは、トレーニング中の経験に基づいて得られる累積報酬を最大化するポリシーを学習することを目的としています。
アクター π θ ( . ∣ st ) \pi\theta(. \mid st)で構成されます。π θ ( .∣s t )と批評家 (critic) V ( st ) V(st)V ( s t )組成。時刻ttの前者tでの次のアクションの確率分布を出力します。これは、その状態の予想累積報酬 (スカラー) を推定します。アクターと批評家の両方が状態を入力として受け取るため、バックボーン アーキテクチャを 2 つのネットワーク間で共有して、高レベルの機能を抽出できます。
PPO は、評価者が予測したよりもはるかに高い累積報酬を持つ、より高い「利点」を持つアクションをポリシーに選択させることを目的としています。同時に、最適化の問題が発生する可能性があるため、一度に多くの戦略を更新したくありません。最後に、ポリシーのエントロピーが高い場合、より多くの探索を奨励するために追加の報酬を与える傾向があります。
総損失関数は、CLIP 項、価値関数 (VF) 項、およびエントロピー報酬項の 3 つの項で構成されます。最終的な目標は次のとおりです。
L t CLIP + VF + S ( θ ) = E ^ t [ L t CLIP ( θ ) − c 1 L t VF ( θ ) + c 2 S [ π θ ] ( st ) ] L_t ^{CLIP +VF+S}(\theta) = \hat{\mathbb{E}}_t \Big\lbrack L_t^{CLIP}(\theta) - c_1L_t^{VF}(\theta)+c_2S[\ pi_\theta ](s_t)\Big\rbrackLtC L I P + V F + S( i )=と^t[ LtC・L・I・P( i )−c1LtVF _( i )+c2S [ π私] ( _t) ]
ここでc 1 c_1c1とc 2 c_2c2は、それぞれポリシー評価 (critic) と探索 (exploration) 精度の重要性を測定するハイパーパラメーターです。
CLIPアイテム
前述したように、損失関数はアクション確率の最大化 (または最小化) を動機付け、アクションの正の利点 (または負の利点) につながります
LCLIP ( θ ) = E ^ t [ min ( rt ( θ ) At ^ ,クリップ ( rt ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) ] L^{CLIP}(\theta) = \hat{\mathbb{E}}_t\Big\lbrack min \Big\lparen r_t (\theta )\hat{A_t},clip \big\lparen r_t(\theta),1-\epsilon, 1+\epsilon\big\rparen \hat{A}_t \Big\rparen \Big\rbrackLC L I P (θ)=と^t[私( rt( i )あt^、クリップ( r _ _ _t( i ) 、1−、_1+) _あ^t) ]
開く:
rt ( θ ) = π θ ( ∣ st で ) π θ old ( ∣ st で ) r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_ {古い}}(a_t\mid s_t)}rt( i )=円周率私o l dな( _t∣st)円周率私( _t∣st)
は、以前と比較して、以前のアクションを実行する可能性が現在 (更新されたポリシー) である割合を測定する比率です。原則として、この係数が大きすぎることは望ましくありません。大きすぎると戦略が突然変更されることを意味するからです。そのため、その最小和[ 1 − ϵ , 1 + ϵ ] [1-\epsilon, 1+\epsilon] を取ります。[ 1−、_1+ϵ ]、ここでϵ \epsilonϵはハイパーパラメータです。
アドバンテージの計算式は次のとおりです
。 t V ( s T ) \hat{A}_t = -V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 r_{t+2}+\dots+\gamma^{(T-t +1 )} r_{T-1} + \gamma^{Tt}V(s_T)あ^t=− V ( st)+rt+γr _t + 1+c2r _t + 2+⋯+c( T − t + 1 ) rT − 1+cT − t V(sT)
ここで:A t ^ \hat{A_t}あt^推定された利点、− V ( st ) -V(s_t)− V ( st)は初期状態の推定値γ T − t V ( s T ) \gamma^{Tt}V(s_T)cT − t V(sT)は最終状態の推定値で、中央部分はプロセス中に観察された累積報酬です。
与えられた状態st s_tに対する評価者の応答を単に測定していることがわかりますstエラーの程度。より高い累積報酬を得ると、オッズの推定値は正になり、この状態で行動する可能性が高くなります。逆もまた真です。より高い報酬を期待しているのに、より小さな報酬を得た場合、オッズの推定値はマイナスになり、このステップで行動を起こす可能性が低くなります。
終末状態s T s_Tまで行くと注意してください。sT、評価者に頼る必要がなくなり、評価者を実際の累積報酬と単純に比較できます。この場合、利点の推定値が実際の利点です。
価値関数項
利点を適切に見積もるには、特定の状態の値を予測できる評価器が必要です。このモデルは、単純な MSE 損失を伴う教師あり学習です:
L t VF = MSE ( rt + γ rt + 1 + ⋯ + γ ( T − t + 1 ) r T − 1 + V ( s T ) , V ( st ) ) = ∣ ∣ A ^ t ∣ ∣ 2 L_t^{VF} = MSE(r_t+\gamma r_{t+1}+\dots+\gamma^{(T-t+1)} r_{T-1}+V( s_T),V(s_t)) = ||\hat{A}_t||_2LtVF _=MSE ( rt+γr _t + 1+⋯+c( T − t + 1 ) rT − 1+V (秒T) 、V (秒t)))=∣∣あ^t∣ ∣2
反復ごとに、エバリュエーターも更新して、トレーニングが進むにつれてより正確な状態値が得られるようにします。
エントロピー報酬項
最後に、ポリシー出力分布のエントロピーの小さな報酬探索をお勧めします。標準エントロピーは次のとおりです。
S [ π θ ] ( st ) = − ∫ π θ ( at ∣ st ) log ( π θ ( at ∣ st ) ) dat S[\pi_\theta](s_t) = -\int \pi_ \ theta(a_t \mid s_t) log(\pi_\theta(a_t \mid s_t))da_tS [ π私] ( _t)=−∫円周率私( _t∣st)ログ( p _ _私( _t∣st) ) _t
アルゴリズムの実装
上記の説明が十分に明確でない場合でも、心配しないでください。以下では、近位戦略の最適化アルゴリズムを段階的にゼロから実装します。
ツールコード
最初に必要なライブラリをインポートします
from argparse import ArgumentParser
import gym
import numpy as np
import wandb
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.optim.lr_scheduler import LinearLR
from torch.distributions.categorical import Categorical
import pytorch_lightning as pl
PPO の重要なハイパーパラメーターは、アクターの数、ホライズン、イプシロン、各最適化段階のエポック数、学習率、割引係数ガンマ、およびさまざまな損失項目を重み付けするための定数 c1 と c2 です。これらのハイパーパラメータをパラメータを介して渡します。
def parse_args():
"""解析参数"""
parser = ArgumentParser()
parser.add_argument("--max_iterations", type=int, help="训练迭代次数", default=100)
parser.add_argument("--n_actors", type=int, help="actor数量", default=8)
parser.add_argument("--horizon", type=int, help="每个actor的时间戳数量", default=128)
parser.add_argument("--epsilon", type=float, help="Epsilon", default=0.1)
parser.add_argument("--n_epochs", type=int, help="每次迭代的训练轮数", default=3)
parser.add_argument("--batch_size", type=int, help="Batch size", default=32 * 8)
parser.add_argument("--lr", type=float, help="学习率", default=2.5 * 1e-4)
parser.add_argument("--gamma", type=float, help="折扣因子gamma", default=0.99)
parser.add_argument("--c1", type=float, help="损失函数价值函数的权重", default=1)
parser.add_argument("--c2", type=float, help="损失函数熵奖励的权重", default=0.01)
parser.add_argument("--n_test_episodes", type=int, help="Number of episodes to render", default=5)
parser.add_argument("--seed", type=int, help="随机种子", default=0)
return vars(parser.parse_args())
デフォルトでは、パラメータは論文に記載されているとおりに設定されていることに注意してください。理想的には、コードは可能な限り GPU 上で実行する必要があるため、トーチの機器をセットアップする必要があります。
def get_device():
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"Found GPU device: {
torch.cuda.get_device_name(device)}")
else:
device = torch.device("cpu")
print("No GPU found: Running on CPU")
return device
強化学習を実行するとき、通常、現在のモデルが遭遇した状態、アクション、および報酬を格納するためのバッファーを設定します。これは、モデルの更新に使用されます。特定の環境で特定のモデルを実行し、一定数のタイムスタンプを取得する関数を作成しますrun_timestamps(エピソードが終了すると環境がリセットされます)。また、このオプションを使用してrender=False、トレーニング済みモデルのパフォーマンスのみを確認します。
@torch.no_grad()
def run_timestamps(env, model, timestamps=128, render=False, device="cpu"):
"""针对给定数量的时间戳在给定环境中运行给定策略。
返回具有状态、动作和奖励的缓冲区。"""
buffer = []
state = env.reset()[0]
# 运行时间戳并收集状态、动作、奖励和终止
for ts in range(timestamps):
model_input = torch.from_numpy(state).unsqueeze(0).to(device).float()
action, action_logits, value = model(model_input)
new_state, reward, terminated, truncated, info = env.step(action.item())
# (s, a, r, t)渲染到环境或存储到buffer
if render:
env.render()
else:
buffer.append([model_input, action, action_logits, value, reward, terminated or truncated])
# 更新当前状态
state = new_state
# 如果episode终止或被截断,则重置环境
if terminated or truncated:
state = env.reset()[0]
return buffer
この関数の戻り値 (レンダリングされていない場合) は、状態、実行されたアクション、アクションの確率 (ロジット)、エバリュエーター値、報酬、および各タイムスタンプで提供されるポリシーの最終状態を含むバッファーです。この関数はデコレータを使用するため@torch.no_grad()、環境との対話中に実行されるアクションのグラデーションを保存する必要がないことに注意してください。
コアコード
上記のツール機能を使用して、近位戦略最適化のコア コードを開発できます。まず、新しいメイン関数プロセスを作成します。
def main():
# 解析参数
args = parse_args()
print(args)
# 设置种子
pl.seed_everything(args["seed"])
# 获取设备
device = get_device()
# 创建环境
env_name = "CartPole-v1"
env = gym.make(env_name)
# TODO 创建模型,训练模型,输出结果
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
training_loop(env, model, args)
model = load_best_model()
testing_loop(env, model)
以上がプログラム全体のプロセスフレームワークです。次に、PPO モデル、トレーニング、およびテスト関数を定義する必要があります。
ここでは、PPO モデルのアーキテクチャについて詳しく説明しません。必要なのは、環境内で機能する 2 つのモデル (アクターと批評家) だけです。もちろん、より複雑なタスクではモデル アーキテクチャが重要な役割を果たしますが、単純なタスクでは MLP がその役割を果たします。
したがって、Actor モデルと Critic モデルを含むMyPPOクラス。ある状態で forward メソッドを実行すると、アクターのサンプリングされたアクション、可能な各アクションの相対確率 (ロジット)、および各状態に対する批評家の推定値が返されます。
class MyPPO(nn.Module):
"""
PPO模型的实现。
相同的代码结构即可用于actor,也可用于critic。
"""
def __init__(self, in_shape, n_actions, hidden_d=100, share_backbone=False):
# 父类构造函数
super(MyPPO, self).__init__()
# 属性
self.in_shape = in_shape
self.n_actions = n_actions
self.hidden_d = hidden_d
self.share_backbone = share_backbone
# 共享策略主干和价值函数
in_dim = np.prod(in_shape)
def to_features():
return nn.Sequential(
nn.Flatten(),
nn.Linear(in_dim, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU()
)
self.backbone = to_features() if self.share_backbone else nn.Identity()
# State action function
self.actor = nn.Sequential(
nn.Identity() if self.share_backbone else to_features(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, n_actions),
nn.Softmax(dim=-1)
)
# Value function
self.critic = nn.Sequential(
nn.Identity() if self.share_backbone else to_features(),
nn.Linear(hidden_d, hidden_d),
nn.ReLU(),
nn.Linear(hidden_d, 1)
)
def forward(self, x):
features = self.backbone(x)
action = self.actor(features)
value = self.critic(features)
return Categorical(action).sample(), action, value
Categorical(action).sample()カテゴリ分布は、1 つのアクション (状態ごと) のアクション ロジットとサンプルを使用して作成されることに注意してください。
最後に、training_loop関数。この論文からわかるように、関数の実際のシグネチャは次のようになります。
def training_loop(env, model, max_iterations, n_actors, horizon, gamma,
epsilon, n_epochs, batch_size, lr, c1, c2, device, env_name=""):
# TODO...
以下は、この論文の PPO トレーニング プログラムの擬似コードです。

PPO の疑似コードは比較的単純です。ポリシー モデル (アクターと呼ばれる) の複数のコピーを通じて環境との相互作用を収集し、以前に定義された目的を使用してアクターと批評家のネットワークを最適化するだけです。
実際に獲得した累積報酬を測定する必要があるため、バッファーを指定して毎回報酬を累積報酬に置き換える関数を作成する必要があります。
def compute_cumulative_rewards(buffer, gamma):
"""
给定一个包含状态、策略操作逻辑、奖励和终止的缓冲区,计算每个时间的累积奖励并将它们代入缓冲区。
"""
curr_rew = 0.
# 反向遍历缓冲区
for i in range(len(buffer) - 1, -1, -1):
r, t = buffer[i][-2], buffer[i][-1]
if t:
curr_rew = 0
else:
curr_rew = r + gamma * curr_rew
buffer[i][-2] = curr_rew
# 在规范化之前获得平均奖励(用于日志记录和检查点)
avg_rew = np.mean([buffer[i][-2] for i in range(len(buffer))])
# 规范化累积奖励
mean = np.mean([buffer[i][-2] for i in range(len(buffer))])
std = np.std([buffer[i][-2] for i in range(len(buffer))]) + 1e-6
for i in range(len(buffer)):
buffer[i][-2] = (buffer[i][-2] - mean) / std
return avg_rew
最後に累積報酬を正規化することに注意してください。これは、最適化問題をより簡単にし、トレーニングをよりスムーズにするための標準的なトリックです。
状態、実行されたアクション、アクションの確率、および累積報酬を含むバッファーができたので、バッファーを指定して、最終目標の 3 つの損失項を計算する関数を作成できます。
def get_losses(model, batch, epsilon, annealing, device="cpu"):
"""给定模型、给定批次和附加参数返回三个损失项"""
# 获取旧数据
n = len(batch)
states = torch.cat([batch[i][0] for i in range(n)])
actions = torch.cat([batch[i][1] for i in range(n)]).view(n, 1)
logits = torch.cat([batch[i][2] for i in range(n)])
values = torch.cat([batch[i][3] for i in range(n)])
cumulative_rewards = torch.tensor([batch[i][-2] for i in range(n)]).view(-1, 1).float().to(device)
# 使用新模型计算预测
_, new_logits, new_values = model(states)
# 状态动作函数损失(L_CLIP)
advantages = cumulative_rewards - values
margin = epsilon * annealing
ratios = new_logits.gather(1, actions) / logits.gather(1, actions)
l_clip = torch.mean(
torch.min(
torch.cat(
(ratios * advantages,
torch.clip(ratios, 1 - margin, 1 + margin) * advantages),
dim=1),
dim=1
).values
)
# 价值函数损失(L_VF)
l_vf = torch.mean((cumulative_rewards - new_values) ** 2)
# 熵奖励
entropy_bonus = torch.mean(torch.sum(-new_logits * (torch.log(new_logits + 1e-5)), dim=1))
return l_clip, l_vf, entropy_bonus
実際には、トレーニング中に 1 から始まり、直線的に 0 まで減衰するアニーリング パラメーターを使用することに注意してください。トレーニングが進むにつれて、ポリシーの変更を減らしたいからです。また、new_logitsと と、変数の勾配new_valuesは追跡せず、テンソルの差のみを追跡します。advantages
環境と対話し、バッファを格納し、(真の) 累積報酬を計算し、損失項を取得するためのメソッドが用意されたので、最終的なトレーニング コードを書き始めることができます。
def training_loop(env, model, max_iterations, n_actors, horizon, gamma, epsilon, n_epochs, batch_size, lr,
c1, c2, device, env_name=""):
"""使用最多n个时间戳的多个actor在给定环境中训练模型。"""
# 开始运行新的权重和偏差
wandb.init(project="Papers Re-implementations",
entity="peutlefaire",
name=f"PPO - {
env_name}",
config={
"env": str(env),
"number of actors": n_actors,
"horizon": horizon,
"gamma": gamma,
"epsilon": epsilon,
"epochs": n_epochs,
"batch size": batch_size,
"learning rate": lr,
"c1": c1,
"c2": c2
})
# 训练变量
max_reward = float("-inf")
optimizer = Adam(model.parameters(), lr=lr, maximize=True)
scheduler = LinearLR(optimizer, 1, 0, max_iterations * n_epochs)
anneals = np.linspace(1, 0, max_iterations)
# 训练循环
for iteration in range(max_iterations):
buffer = []
annealing = anneals[iteration]
# 使用当前策略收集所有actor的时间戳
for actor in range(1, n_actors + 1):
buffer.extend(run_timestamps(env, model, horizon, False, device))
# 计算累积奖励并刷新缓冲区
avg_rew = compute_cumulative_rewards(buffer, gamma)
np.random.shuffle(buffer)
# 运行几轮优化
for epoch in range(n_epochs):
for batch_idx in range(len(buffer) // batch_size):
start = batch_size * batch_idx
end = start + batch_size if start + batch_size < len(buffer) else -1
batch = buffer[start:end]
# 归零优化器梯度
optimizer.zero_grad()
# 获取损失
l_clip, l_vf, entropy_bonus = get_losses(model, batch, epsilon, annealing, device)
# 计算总损失并反向传播
loss = l_clip - c1 * l_vf + c2 * entropy_bonus
loss.backward()
# 优化
optimizer.step()
scheduler.step()
# 记录输出
curr_loss = loss.item()
log = f"Iteration {
iteration + 1} / {
max_iterations}: " \
f"Average Reward: {
avg_rew:.2f}\t" \
f"Loss: {
curr_loss:.3f} " \
f"(L_CLIP: {
l_clip.item():.1f} | L_VF: {
l_vf.item():.1f} | L_bonus: {
entropy_bonus.item():.1f})"
if avg_rew > max_reward:
torch.save(model.state_dict(), MODEL_PATH)
max_reward = avg_rew
log += " --> Stored model with highest average reward"
print(log)
# 将信息记录到 W&B
wandb.log({
"loss (total)": curr_loss,
"loss (clip)": l_clip.item(),
"loss (vf)": l_vf.item(),
"loss (entropy bonus)": entropy_bonus.item(),
"average reward": avg_rew
})
# 完成 W&B 会话
wandb.finish()
最後に、モデルが最終的にどのように見えるかを確認するために、次のtesting_loop関数を。
def testing_loop(env, model, n_episodes, device):
for _ in range(n_episodes):
run_timestamps(env, model, timestamps=128, render=True, device=device)
このようにして、メインプログラムは非常に単純になります。
def main():
# 解析参数
args = parse_args()
print(args)
# 设置种子
pl.seed_everything(args["seed"])
# 获取设备
device = get_device()
# 创建环境
env_name = "CartPole-v1"
env = gym.make(env_name)
# 创建模型(actor和critic)
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
# 训练
training_loop(env, model, args["max_iterations"], args["n_actors"], args["horizon"], args["gamma"], args["epsilon"],
args["n_epochs"], args["batch_size"], args["lr"], args["c1"], args["c2"], device, env_name)
# 加载最佳模型
model = MyPPO(env.observation_space.shape, env.action_space.n).to(device)
model.load_state_dict(torch.load(MODEL_PATH, map_location=device))
# 测试
env = gym.make(env_name, render_mode="human")
testing_loop(env, model, args["n_test_episodes"], device)
env.close()
それが上記のすべてです!上記のコードを理解している場合は、おめでとうございます。PPO アルゴリズムを理解しています。
結論は
Proximal Policy Optimization は、ほぼすべての設定で使用できるポリシー強化学習のための最先端の最適化アルゴリズムです。さらに、近位ポリシーの最適化には、比較的単純な目的関数と、調整するハイパーパラメーターが比較的少ないという特徴があります。
ChatGPT は、第 3 ステップで予想以上の結果を得るために PPO に依存しています. これを独自の強化学習タスクに使用すると、予期しない結果が得られる場合があります.