参考:
- d2l
x.1 アレックスネット
研究者らによると、
- 大規模でクリーンなデータセットやわずかに改良された特徴抽出方法は、どの学習アルゴリズムよりもはるかに大きな進歩をもたらす可能性があります。
- 特徴そのものが学習されるべきである、つまり畳み込みカーネルパラメータが学習可能であるべきであると考えられています。
- イノベーションは、ReLU アクティベーション機能とドロップアウト層を使用した GPU とより深いネットワークにあります。

以下を参照できます:
アレックスネット https://blog.csdn.net/qq_43369406/article/details/127295070
コード::AlexNet_model https://blog.csdn.net/qq_43369406/article/details/129171352
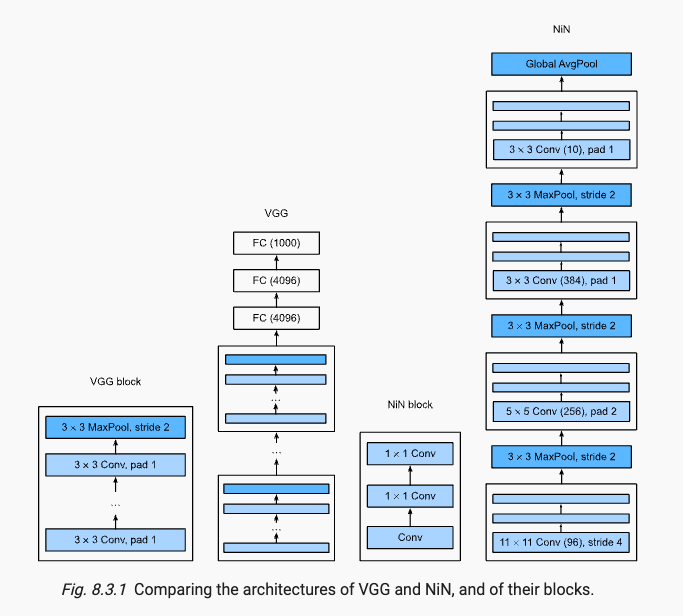
x.2 VGG
VGG では、レイヤー構造をより迅速に定義できるカスタム レイヤーが導入されています。VGG のハイライトは、大規模なコンボリューション カーネルの代わりに複数の 3x3 コンボリューション カーネルをスタックすることで、必要なパラメータを削減するという目的が達成されることです。パラメーターは減少しますが、受容野は同じです。
以下を参照できます:
- VGG ネットワークの紹介
https://blog.csdn.net/qq_43369406/article/details/127485929 - コード::VGG16_モデル
https://blog.csdn.net/qq_43369406/article/details/129174640
x.3 NiN
最後の層が完全に接続された層を使用する場合、表現の空間構造が放棄されるため、代わりに完全な畳み込みが使用されます。
x.4 GoogLeNet
GoogLeNet の最大の特徴は、以前の一般的なネットワークは 1x1 から 11x11 までのコンボリューション カーネルを使用し、インセプション モジュールは 4 つの並列パスを使用するため、どのくらいの大きさのコンボリューション カーネルが最適であるかという問題を解決することです。このインセプションの図では、高さと幅は同じですがチャネルが異なり、最後に concat がチャネル方向に短絡されており、次のような構造になっています。
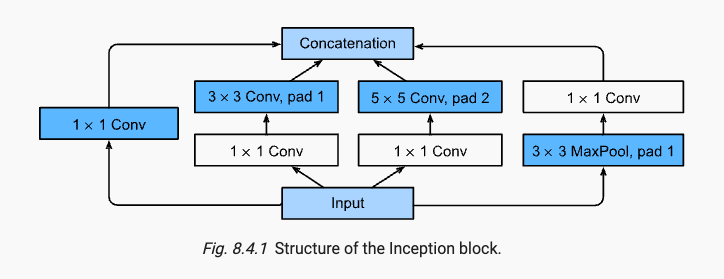
デジタル画像処理で画像を探索するためにさまざまなサイズのフィルターがよく使用されることに注意してください。これは、さまざまなサイズのフィルターがさまざまな範囲の画像の詳細を効果的に識別できることを意味します。補助分類器である 1x1 コンボリューション カーネルの次元削減も使用されます。
参考:
- GoogLeNet ネットワークの紹介
https://blog.csdn.net/qq_43369406/article/details/127608423 - コード::GoogLeNet_model
https://blog.csdn.net/qq_43369406/article/details/129189694
x.5 レスネット
x.5.1 バッチ正規化
最新の深層学習の重要な部分として、BN は深層ネットワークの収束を継続的に加速できます。ニューラル ネットワークが直面する課題を次のように確認します。
- データの前処理方法は、最終結果に大きな影響を与える可能性があります。最初のステップは、すべての入力特徴が ~ N (0, 1) になるように入力特徴を正規化することです。
- 中間の隠れ層で、ある層に別の層の 100 倍の変数値がある場合、この変数分布の変化によりネットワークの収束が妨げられる可能性があります。中間の隠れ層を通過した後のデータは制御が難しく、BN 正規化が必要です。
- より深いネットワークは複雑で過剰適合しやすいため、正則化がより重要になります。L2 正則化など、損失に重み減衰を追加するなどは、Adam によって簡単に実現できます。
BN 層では、各チャネルのデータには 4 つのパラメータがあり、そのうち miu と sigma は学習可能なパラメータではないため、model.parameters() には表示されませんが、スケール パラメータ - ラムダとシフト パラメータ - ベータは学習可能なパラメータです。次のように、学習パラメータが勾配計算に参加します。
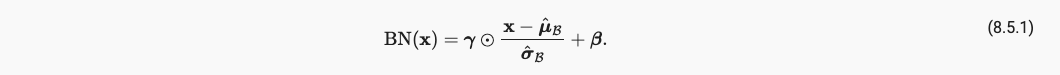
そして miu と sigma はミニバッチの小さなバッチサンプルの平均と分散です。
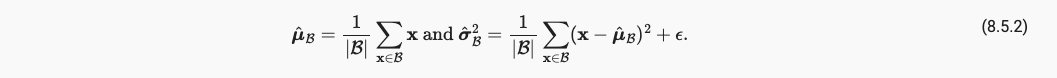
BN 層にはLinear-BN-Activation次のような独自の処理順序があることに注意してください。Conv-BN-Act
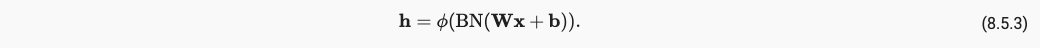
BN と Dropout は、model.eval() のときにアクティビティを失います。
次のように BN コード実装を参照することをお勧めします。
"""
1. BN
"""
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# Use is_grad_enabled to determine whether we are in training mode
if not torch.is_grad_enabled():
# In prediction mode, use mean and variance obtained by moving average
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# When using a fully connected layer, calculate the mean and
# variance on the feature dimension
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# When using a two-dimensional convolutional layer, calculate the
# mean and variance on the channel dimension (axis=1). Here we
# need to maintain the shape of X, so that the broadcasting
# operation can be carried out later
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# In training mode, the current mean and variance are used
X_hat = (X - mean) / torch.sqrt(var + eps)
# Update the mean and variance using moving average
moving_mean = (1.0 - momentum) * moving_mean + momentum * mean
moving_var = (1.0 - momentum) * moving_var + momentum * var
Y = gamma * X_hat + beta # Scale and shift
return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):
# num_features: the number of outputs for a fully connected layer or the
# number of output channels for a convolutional layer. num_dims: 2 for a
# fully connected layer and 4 for a convolutional layer
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# The scale parameter and the shift parameter (model parameters) are
# initialized to 1 and 0, respectively
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# The variables that are not model parameters are initialized to 0 and
# 1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# If X is not on the main memory, copy moving_mean and moving_var to
# the device where X is located
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# Save the updated moving_mean and moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.1)
return Y
# test
temp_builtin = [i for i in torch.nn.BatchNorm2d(4).parameters()]
temp_diy = [i for i in BatchNorm(num_features=4, num_dims=4).parameters()]
# self.moving_mean() and var is not nn.Parameters(), not learnable.
"""
2. LeNet
"""
class BNLeNetScratch(d2l.Classifier):
def __init__(self, lr=0.1, num_classes=10):
super().__init__()
self.save_hyperparameters()
self.net = nn.Sequential(
nn.LazyConv2d(6, kernel_size=5), BatchNorm(6, num_dims=4),
nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5), BatchNorm(16, num_dims=4),
nn.Sigmoid(), nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(), nn.LazyLinear(120),
BatchNorm(120, num_dims=2), nn.Sigmoid(), nn.LazyLinear(84),
BatchNorm(84, num_dims=2), nn.Sigmoid(),
nn.LazyLinear(num_classes))
trainer = d2l.Trainer(max_epochs=10, num_gpus=1)
data = d2l.FashionMNIST(batch_size=128)
model = BNLeNetScratch(lr=0.1)
model.apply_init([next(iter(data.get_dataloader(True)))[0]], d2l.init_cnn) # 因为使用了Lazy init所以要先forward一个Tensor初始化模型
trainer.fit(model, data)
# learnable gamma and beta
print(model.net[1].gamma.reshape((-1,)), model.net[1].beta.reshape((-1,)))
x.5.2 レスネット
ネットワークの層の数が深くなるにつれて、新しく追加された層がニューラル ネットワークのパフォーマンスをどのように向上させることができるかを深く理解することが重要になります。X 特徴と y ラベルを含むデータ セットが与えられた場合、f を f スターに適合させる必要があります。可能な限り、次のようにします。
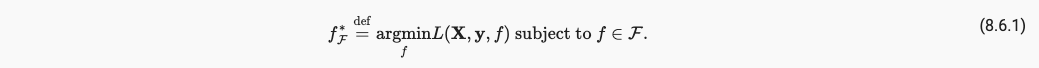
f スターに近づくには、右のような入れ子関数を使用する必要があり、F1 から F6 まで順に複雑さが増加します。
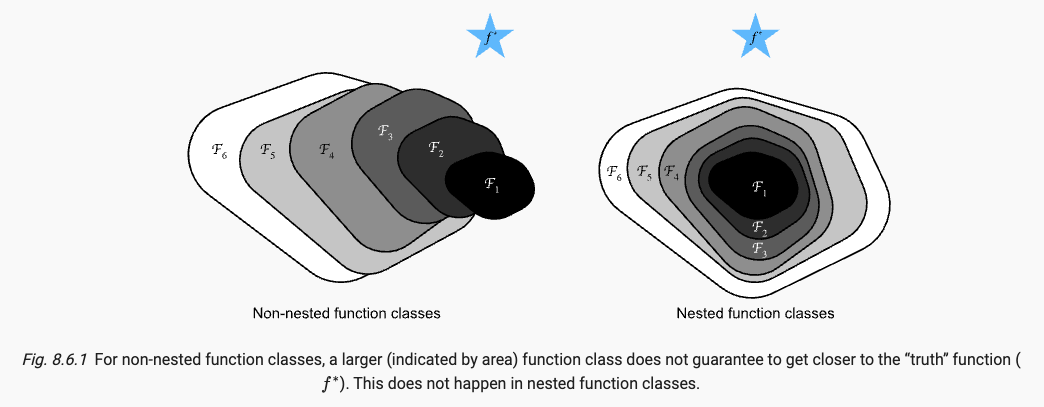
より複雑な関数クラスにはより小さな関数クラスが含まれるという考えを導入すると、残差ネットワークの核となる考え方に到達します。追加された各層には、元の関数がその要素の 1 つとしてより簡単に含まれるはずです。
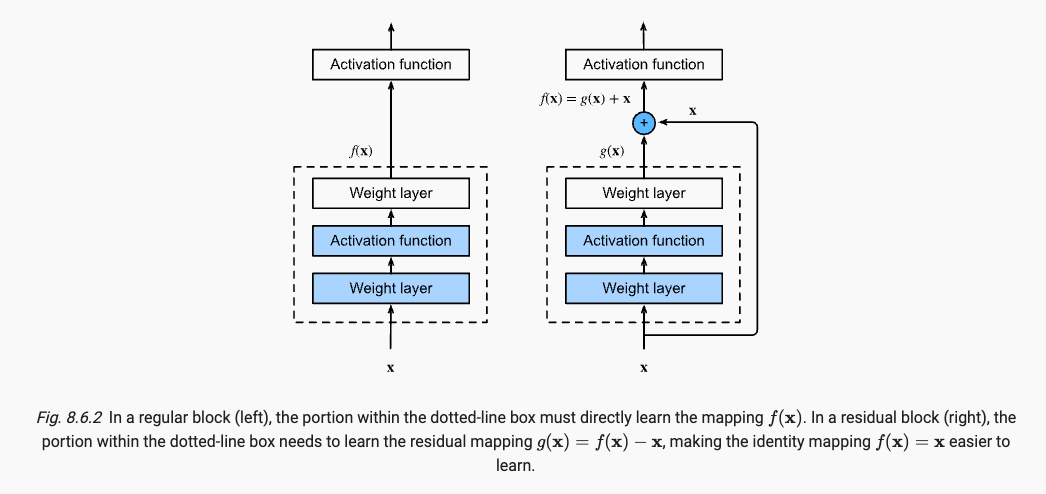
ResNet のポイントは次の 2 つであり、ネットワークの深さを深くする BN と残余モジュールの導入です。
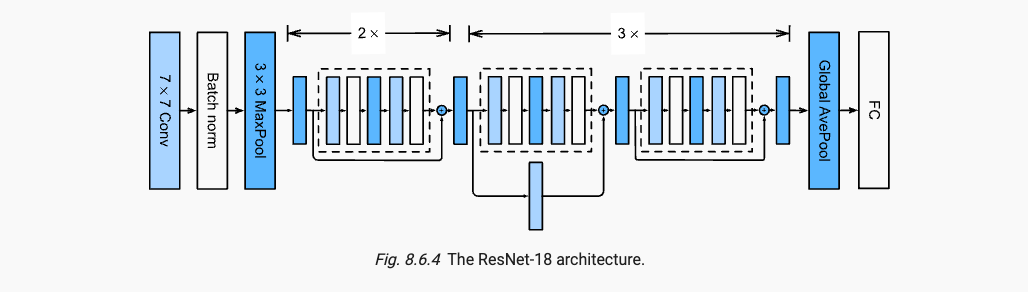
参考:
- ResNet の概要
https://blog.csdn.net/qq_43369406/article/details/127500443 - ResNet コードの実装
https://blog.csdn.net/qq_43369406/article/details/127508108 - CODE::ResNet_model
https://blog.csdn.net/qq_43369406/article/details/129190380
x.6 デンスネット
ResNet を変更して前のレイヤーを接続し、Concat を使用してスプライスします。
x.7 畳み込みネットワーク アーキテクチャの設計
AlexNet から ResNet まで、位置情報とアテンション メカニズムが追加された SENet は、Transformers の前身です。
EfficientNets は、NAS の優れたパフォーマンスから生まれました。
手動設計と NAS の組み合わせにより、RegNets が誕生しました。
より適切な適合能力を備えたネットワークをセットアップするには、より深い (より大きなチャネル) ネットワークを使用する必要があります。