
背景の紹介
最近の業務システムでは、スレーブデータベースが遅延し、マスターデータベースに追いつかず、ビジネスリスクが増大しています。リソースの観点から見ると、スレーブ ライブラリの CPU、IO、およびネットワークの使用率は低く、スレーブ ライブラリで show processlist を実行すると、過剰なサーバーの負荷によって再生が遅くなる状況はありません。ライブラリは、再生スレッドがないことを示しています。ブロックされているため、再生は続行されます。リレー ログ ログ ファイルを解析すると、大規模なトランザクションの再生がないことがわかります。
プロセス分析
現象確認
運用および保守の同僚から、1 セットのスレーブ ライブラリが非常に遅れているというフィードバックを受け取り、show slave status遅延に関するスクリーンショット情報を提供しました。
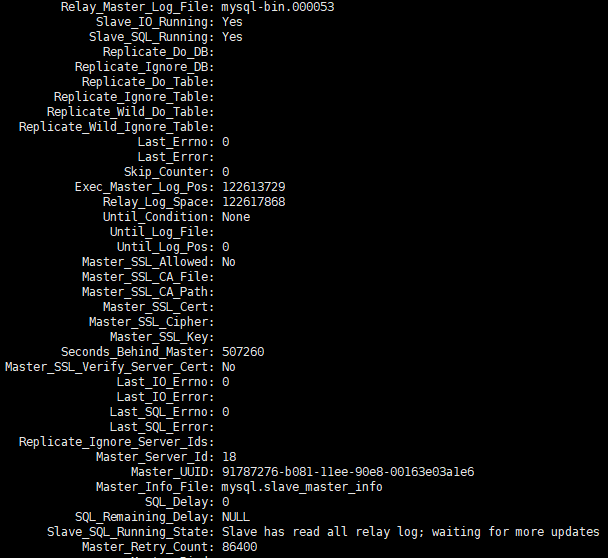
show slave statusしばらく変化を観察し続けたところ、POS ポイント情報は常に変化しており、Seconds_Behind_master も常に変化しており、全体的な傾向は増加し続けていることがわかりました。
リソースの使用量
サーバー リソースの使用率を観察すると、使用率が非常に低いことがわかります。

スレーブ プロセスを観察すると、基本的に 1 つのスレッドだけが作業を再生していることがわかります。
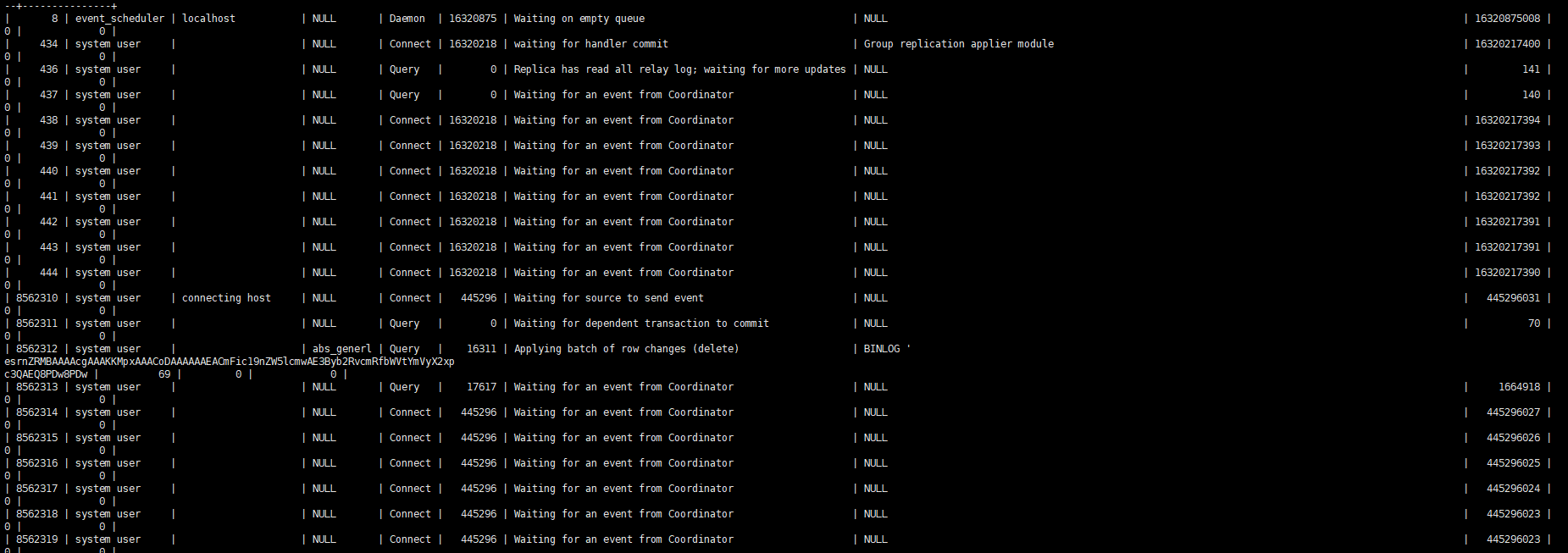
並列再生パラメータの説明
メインライブラリに設定binlog_transaction_dependency_tracking=WRITESET
スレーブ ライブラリでは、slave_parallel_type=LOGICAL_CLOCKとslave_parallel_workers=64
エラーログの比較
エラーログから並列再生ログを取得して解析
$ grep 010559 100werror3306.log | tail -n 3
2024-01-31T14:07:50.172007+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3318582273; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348754579743300 waited (count) when Workers occupied = 34529247 waited when Workers occupied = 76847369713200
2024-01-31T14:09:50.078829+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319256065; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348851330164000 waited (count) when Workers occupied = 34535857 waited when Workers occupied = 76866419841900
2024-01-31T14:11:50.060510+08:00 6806 [Note] [MY-010559] [Repl] Multi-threaded slave statistics for channel 'cluster': seconds elapsed = 120; events assigned = 3319894017; worker queues filled over overrun level = 207029; waite
d due a Worker queue full = 238; waited due the total size = 0; waited at clock conflicts = 348943740455400 waited (count) when Workers occupied = 34542790 waited when Workers occupied = 76890229805500
上記の情報の詳細な説明については、「MTS パフォーマンス監視どのくらい知っていますか?」を参照してください。
発生頻度の低い統計を削除し、いくつかの主要なデータの比較を示しました。
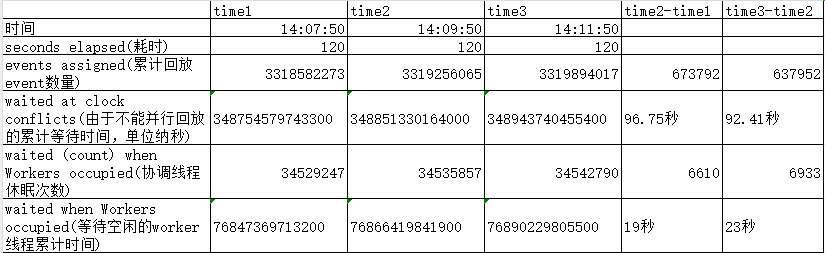
自然時間 120 では、再生調整スレッドは並列再生できないため 90 秒以上待機し、待機するアイドル作業スレッドがないため 20 秒近く待機していることがわかります。これは、換算するとわずか約 10 秒になります。調整スレッドが機能するようにします。
並列処理の統計
ご存知のとおり、mysql のライブラリからの並列再生は、主に binlog の last_committed に基づいて判断されます。トランザクションの last_committed が同じであれば、基本的にこれらのトランザクションは並列再生できると考えられます。並列再生のために環境からリレー ログを取得した場合のおおよその統計。
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11){sum+=$2}} END {print sum}'
235703
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>10){sum+=$2}} END {print sum}'
314694
上記の最初のコマンドは、last_committed が 1 から 10 までの同じトランザクション、つまり並列再生の度合いが低い、または並列再生できないトランザクションの数をカウントします。これらのトランザクションの合計数は 235703 で、43% を占めます。並列再生の度合いが比較的低いトランザクションの詳細な分析 トランザクションの分布から、last_committed のこの部分は基本的に 1 つのトランザクションであることがわかります。事前注文トランザクションの再生が完了するまで待つ必要があります。これにより、時間が比較的長い場合、前のログで確認された調整スレッドの待機が並行して再生できなくなり、待機状態になります。
$ mysqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>=1 && $2 <11) {print $2}}' | sort | uniq -c
200863 1
17236 2
98 3
13 4
3 5
1 7
2 番目のコマンドは、同じ last_committed トランザクションが 10 個以上あるトランザクションの合計数をカウントし、その数は 57% を占め、これらのトランザクションが比較的高度に並列再生されていることがわかります。 6500 ~ 9000 の範囲。トランザクション数
$ mysqlsqlbinlog --no-defaults 046638 |grep -o 'last_committed.*' | sed 's/=/ /g' | awk '{print $2}' |sort -n | uniq -c |awk 'BEGIN {print "last_commited group_count Percentage"} {count[$2]=$1
; sum+=$1} END {for (i in count) printf "%d %d %.2f%%\n", i, count[i], (count[i]/sum)*100|"sort -k 1,1n"}' | awk '{if($2>11){print $0}}' | column -t
last_commited group_count Percentage
1 7340 1.33%
11938 7226 1.31%
23558 7249 1.32%
35248 6848 1.24%
46421 7720 1.40%
59128 7481 1.36%
70789 7598 1.38%
82474 6538 1.19%
93366 6988 1.27%
104628 7968 1.45%
116890 7190 1.31%
128034 6750 1.23%
138849 7513 1.37%
150522 6966 1.27%
161989 7972 1.45%
175599 8315 1.51%
189320 8235 1.50%
202845 8415 1.53%
218077 8690 1.58%
234248 8623 1.57%
249647 8551 1.55%
264860 8958 1.63%
280962 8900 1.62%
297724 8768 1.59%
313092 8620 1.57%
327972 9179 1.67%
344435 8416 1.53%
359580 8924 1.62%
375314 8160 1.48%
390564 9333 1.70%
407106 8637 1.57%
422777 8493 1.54%
438500 8046 1.46%
453607 8948 1.63%
470939 8553 1.55%
486706 8339 1.52%
503562 8385 1.52%
520179 8313 1.51%
535929 7546 1.37%
last_committed メカニズムの概要
メイン ライブラリのパラメータは、binlog_transaction_dependency_trackingバイナリ ログに書き込まれる依存関係情報を生成する方法を指定するために使用され、スレーブ ライブラリがどのトランザクションを並列実行できるかを決定するのに役立ちます。つまり、このパラメータは、last_committed の生成メカニズムを制御するために使用されます。パラメータのオプションの値は、COMMIT_ORDER、WRITESET、および SESSION_WRITESET です。次のコードから、3 つのパラメーターの関係が簡単にわかります。
- 基本的なアルゴリズムはCOMMIT_ORDERです
- WRITESET アルゴリズムは COMMIT_ORDER に基づいて再計算されます
- SESSION_WRITESET アルゴリズムは WRITESET に基づいて再計算されます
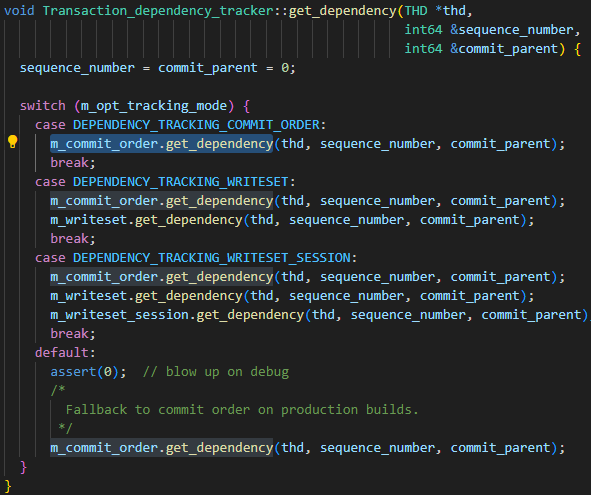
私のインスタンスは WRITESET に設定されているため、COMMIT_ORDER アルゴリズムと WRITESET アルゴリズムに注目してください。
COMMIT_ORDER
COMMIT_ORDER 計算ルール: 2 つのトランザクションがマスター ノードで同時に送信された場合、2 つのトランザクションのデータ間に競合がないことを意味し、スレーブ ノードでも並行して実行できます。理想的な典型的なケースです。以下のとおりであります。
| セッション-1 | セッション-2 |
|---|---|
| 始める | 始める |
| t1 値を挿入(1) | |
| t2 値を挿入(2) | |
| コミット (グループ_コミット) | コミット (グループ_コミット) |
ただし、MySQL の場合、group_commit は内部動作であり、session-1 と session-2 が内部で group_commit にマージされているかどうかに関係なく、本質的には commit を実行します。一歩戻って、セッション 1 がコミットを実行し、新しいデータがセッション 2 に書き込まれない限り、2 つのトランザクションにはデータの競合がなく、並行してレプリケートできます。
| セッション-1 | セッション-2 |
|---|---|
| 始める | 始める |
| t1 値を挿入(1) | |
| t2 値を挿入(2) | |
| 専念 | |
| 専念 |
より多くの同時スレッドを使用するシナリオでは、これらのスレッドは同時に並行してレプリケートできない場合がありますが、一部のトランザクションはレプリケートできます。次の実行シーケンスを例にとると、セッション 3 のコミット後、セッション 2 には新しい書き込みがないため、2 つのトランザクションを並行してレプリケートできます。セッション 3 のコミット後、セッション 1 が新しいデータを挿入すると、データが競合します。現時点では決定できないため、セッション 3 とセッション 1 のトランザクションを並行して複製することはできません。ただし、セッション 2 が送信された後は、セッション 1 の後に新しいデータが書き込まれないため、セッション 2 とセッション 1 は複製されません。再び並行して複製できます。したがって、このシナリオでは、セッション 2 をセッション 1 およびセッション 3 とそれぞれ並行してレプリケートできますが、3 つのトランザクションを同時に並行してレプリケートすることはできません。
| セッション-1 | セッション-2 | セッション-3 |
|---|---|---|
| 始める | 始める | 始める |
| t1 値を挿入(1) | t2 値を挿入(1) | t3 値を挿入(1) |
| t1 値を挿入(2) | t2 値を挿入(2) | |
| 専念 | ||
| t1 値を挿入(3) | ||
| 専念 | ||
| 専念 |
ライトセット
これは実際には commit_order + writeset の組み合わせであり、最初に commit_order を通じて last_committed 値を計算し、次に writeset を通じて新しい値を計算し、最後に 2 つの値のうち小さい方の値を最終トランザクション gtid の last_committed 値として取得します。
MySQL では、writeset は基本的に、schema_name + table_name + priority_key/unique_key に対して計算されたハッシュ値です。DML ステートメントの実行中、binlog_log_row を通じて row_event を生成する前に、DML ステートメント内のすべての主キー/一意キーのハッシュ値が計算されます。個別に、トランザクション自体の writeset リストに追加されます。また、主キー/一意インデックスのないテーブルがある場合、トランザクションに対して has_missing_keys=true も設定されます。
パラメータはWRITESETに設定されていますが、以下の制限がありますので使用できません。
- 主キー、一意キー、または空のトランザクションを含む非 DDL ステートメントまたはテーブル
- 現在のセッションで使用されるハッシュ アルゴリズムは、ハッシュ マップ内のハッシュ アルゴリズムと一致します。
- 外部キーは使用されません
- ハッシュ マップの容量が binlog_transaction_dependency_history_size の設定を超えない場合、上記 4 つの条件が満たされる場合、WRITESET アルゴリズムを使用できます。いずれかの条件が満たされない場合は、COMMIT_ORDER 計算メソッドに縮退します。
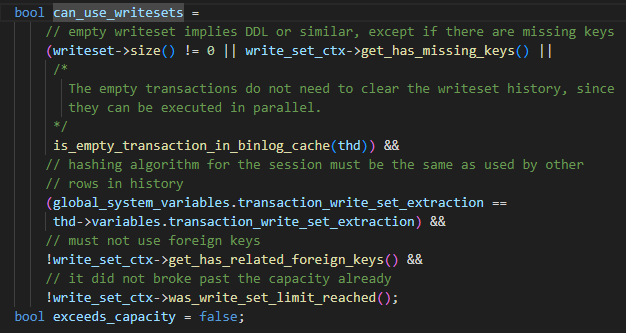
トランザクションが送信されるときの具体的な WRITESET アルゴリズムは次のとおりです。
-
last_committed は m_writeset_history_start に設定されます。この値は、m_writeset_history リスト内の最小の sequence_number です。
-
トランザクションの書き込みセット リストを走査する
a writeset がグローバル m_writeset_history に存在しない場合は、現在のトランザクションのペア<writeset, sequence_number> オブジェクトを構築し、それをグローバル m_writeset_history リストに挿入します。
b. 存在する場合は、last_committed=max(last_committed、履歴書き込みセットの sequence_number 値) とし、同時に m_writeset_history 内の書き込みセットに対応する sequence_number を現在のトランザクション値に更新します。
-
has_missing_keys=false の場合、つまりトランザクションのすべてのデータ テーブルに主キーまたは一意のインデックスが含まれている場合、commit_order と writeset によって計算された最小値が最終的な last_committed 値として使用されます。
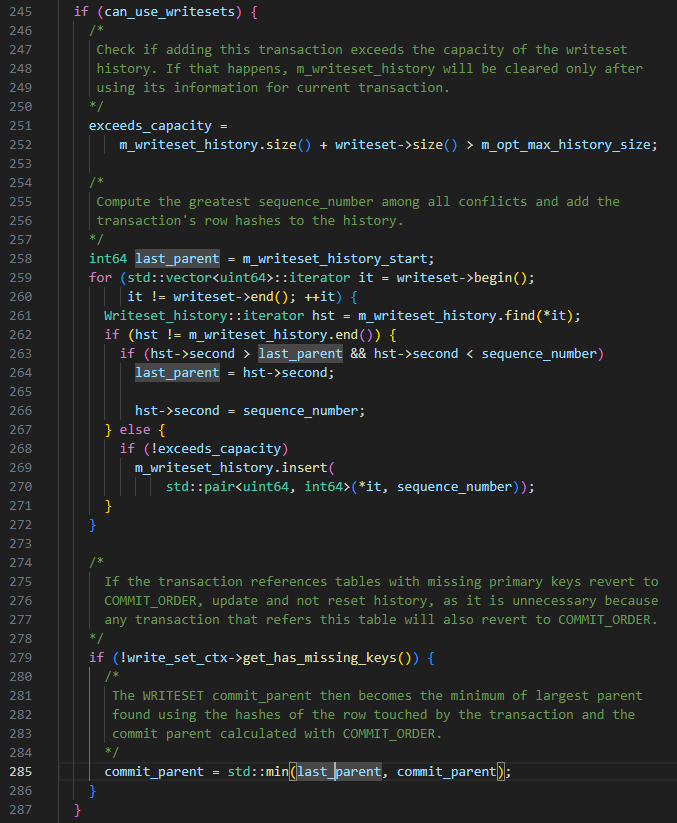
ヒント: 上記の WRITESET ルールに基づくと、後で送信されたトランザクションの last_committed が最初に送信されたトランザクションよりも小さい状況が発生します。
結論分析
結論の説明
WRITESETの使用制限に従い、リレーログとトランザクションに関わるテーブル構造を比較し、単一のlast_committedのトランザクション構成を分析したところ、以下の2つの状況が判明しました。
- 単一の last_committed トランザクションに含まれるデータと sequence_number の間にデータの競合があります。
- 単一の last_committed トランザクションに関係するテーブルには主キーがなく、そのようなトランザクションが多数存在します。
上記の分析から、主キーのないトランザクションがテーブル内に多すぎるため、WRITESET が COMMIT_ORDER に縮退していると結論付けることができます。データベースは TP アプリケーションであるため、トランザクションはすぐに送信され、複数のトランザクションの送信は保証されません。 1 つのコミット サイクル内にあるため、COMMIT_ORDER メカニズムによって生成される last_committed 反復読み取りは非常に低くなります。スレーブ ライブラリはこれらのトランザクションをシリアルにのみ再生できるため、再生遅延が発生します。
最適化施策
- ビジネス側からテーブルを変更し、可能な場合は関連テーブルに主キーを追加します。
- パラメータ binlog_group_commit_sync_delay および binlog_group_commit_sync_no_delay_count を 0 から 10000 まで増やしてみてください。特別な環境制限により、この調整は効果が得られません。シナリオが異なるとパフォーマンスが異なる場合があります。
GreatSQL をお楽しみください :)
GreatSQL について
GreatSQL は、金融レベルのアプリケーションに適した国産の独立したオープンソース データベースであり、高パフォーマンス、高信頼性、高使いやすさ、高セキュリティなどの多くのコア機能を備えており、MySQL または Percona Server のオプションの代替として使用できます。オンラインの実稼働環境で使用され、完全に無料で、MySQL または Percona Server と互換性があります。
関連リンク: GreatSQL コミュニティ Gitee GitHub Bilibili
GreatSQL コミュニティ:

コミュニティの報酬に関する提案とフィードバック: https://greatsql.cn/thread-54-1-1.html
コミュニティ ブログ賞を受賞した投稿の詳細: https://greatsql.cn/thread-100-1-1.html
(記事について質問がある場合、または独自の洞察がある場合は、公式コミュニティ Web サイトにアクセスして質問したり共有したりできます~)
技術交流グループ:
WeChat & QQ グループ:
QQグループ: 533341697
WeChat グループ: GreatSQL コミュニティ アシスタント (WeChat ID: wanlidbc) を友達として追加し、コミュニティ アシスタントがあなたをグループに追加するまで待ちます。