iQiyi における Apache Spark の現在のステータス
Apache Spark は、主に iQiyi ビッグ データ プラットフォームで使用されるオフライン コンピューティング フレームワークで、データ処理、データ同期、データ クエリ分析、その他のシナリオのためのいくつかのストリーム コンピューティング タスクをサポートします。
-
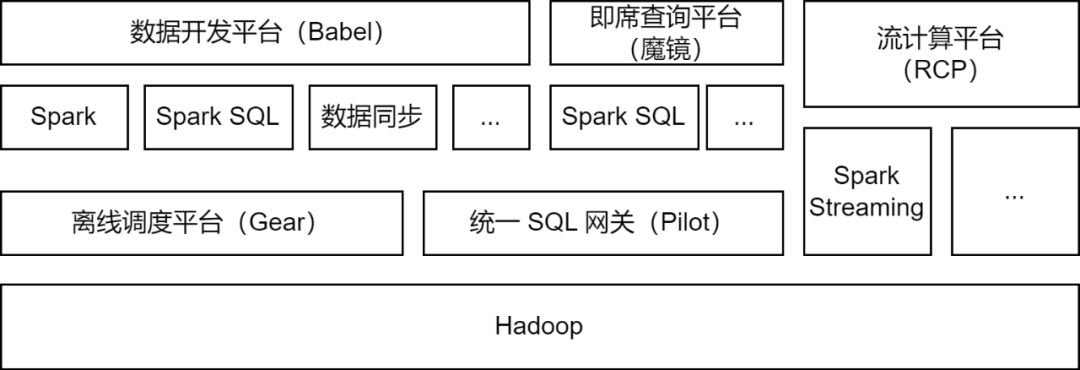
データ処理: データ開発プラットフォームは、開発者がデータの ETL 処理のために Spark Jar パッケージ タスクまたは Spark SQL タスクを送信できるようにします。
-
データ同期
: iQIYI が独自に開発した BabelX データ同期ツールは、Spark コンピューティング フレームワークに基づいて開発されており、Hive、MySQL、MongoDB などの 15 のデータ ソース間のデータ交換をサポートし、複数のクラスターと複数のクラウド間のデータ同期をサポートします。構成された完全に管理されたデータ同期タスク。
-
データ分析: データ アナリストと運用学生は、マジック ミラー アドホック クエリ プラットフォームで SQL を送信するか、データ インジケーター クエリを構成し、クエリ分析のために Pilot 統合 SQL ゲートウェイを通じて Spark SQL サービスを呼び出します。
現在、iQiyi Spark サービスは毎日 200,000 を超える Spark タスクを実行しており、ビッグ データ コンピューティング リソース全体の半分以上を占めています。
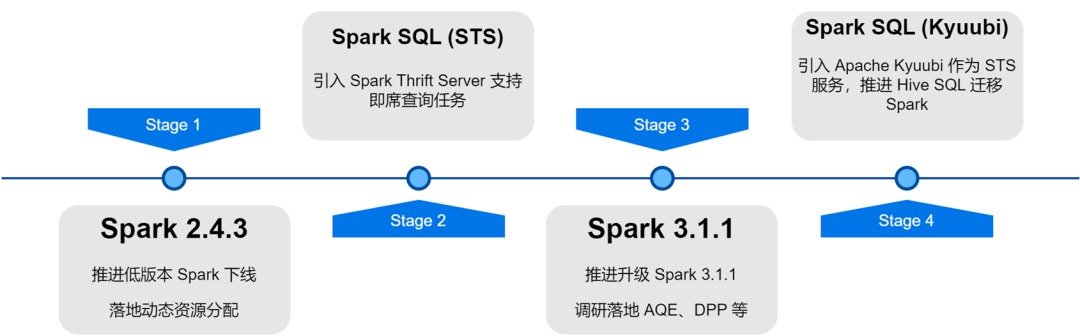
iQiyiビッグデータプラットフォームアーキテクチャのアップグレードと最適化の過程で、Sparkサービスはバージョンの反復、サービスの最適化、タスクのSQL化、リソースコスト管理などを経て、オフラインタスクのコンピューティング効率とリソース節約が大幅に向上しました。
Spark コンピューティング フレームワーク アプリケーションの最適化
内部 Spark バージョンの反復アップグレードにより、新しい Spark バージョンのいくつかの優れた機能 (動的リソース割り当て、適応クエリ最適化、動的パーティション プルーニングなど)を調査し、実装しました。
-
動的リソース割り当て (DRA)
: ユーザー アプリケーションにはリソースに対する盲点があり、Spark タスクの各ステージのリソース要件も異なります。不当なリソース割り当ては、タスク リソースの無駄や実行の遅延につながります。 Spark 2.4.3 で外部シャッフル サービスを開始し、動的リソース割り当て (DRA) を有効にしました。有効になると、Spark は、現在の実行ステージのリソース要件に基づいて Executor を動的に開始または解放します。 DRA がオンラインになった後、Spark タスクのリソース消費量は 20% 削減されました。
-
Adaptive Query Optimization (AQE)
: Adaptive Query Optimization (AQE) は、Spark 3.0 で導入された優れた機能で、プリステージの実行時の統計指標に基づいて、後続のステージの実行計画を動的に最適化し、適切な結合戦略を最適化し、小さなパーティションを結合し、大きなパーティションを分割します。 Spark 3.1.1 にアップグレードすると、AQE がデフォルトで有効になり、小さなファイルやデータ スキューなどの問題が効果的に解決され、Spark のコンピューティング パフォーマンスが大幅に向上し、全体的なパフォーマンスが約 10% 向上しました。
-
動的パーティション プルーニング (DPP)
: SQL コンピューティング エンジンでは、通常、述語プッシュダウンを使用してデータ ソースから読み取られるデータ量を削減し、それによってコンピューティング効率を向上させます。 Spark3 では、動的パーティション プルーニングとランタイム フィルターという新しいプッシュダウン メソッドが導入されました。最初に結合の小さなテーブルを計算することにより、結合の大きなテーブルが計算結果に基づいてフィルター処理され、大きなテーブルによって読み取られるデータの量が削減されます。テーブル。これら 2 つの機能について調査とテストを実施し、デフォルトで DPP を有効にしたところ、一部のビジネス シナリオではパフォーマンスが 33 倍向上しました。ただし、Spark 3.1.1 では、DPP を有効にすると、多くのサブクエリを含む SQL 解析が特に遅くなることがわかりました。したがって、サブクエリの数を計算し、それが 5 を超えた場合に
DPP の最適化をオフにするという最適化ルールを実装しました
。
Spark を使用する過程で、コミュニティの最新の進捗状況を追跡することでいくつかの問題も発見し、それらを解決するためのパッチを適用しました。さらに、さまざまなアプリケーション シナリオに適したものにし、コンピューティング フレームワークの安定性を向上させるために、Spark を独自にいくつかの改善も行いました。
Spark 3.1.1 はデフォルトで Hive Parquet 形式のテーブルを Spark の組み込み Parquet Writer に変換するため、InsertIntoHadoopFsRelationCommand 演算子を使用してデータを書き込みます (spark.sql.hive.convertMetastoreParquet=true)。静的パーティションを書き込む場合、テーブル パスの直下に一時ディレクトリが構築されます。複数の静的パーティション書き込みタスクが同じテーブルの異なるパーティションに同時に書き込む場合、タスク書き込みの失敗またはデータ損失のリスクがあります (タスクがコミットされると、一時ディレクトリ全体がクリーンアップされ、データ損失が発生します)他のタスク用)。
ForceUseStagingDir パラメーターを InsertIntoHadoopFsRelationCommand オペレーターに追加し、タスク固有のステージング ディレクトリを一時ディレクトリとして使用します。このようにして、異なるタスクは異なる一時ディレクトリを使用するため、同時書き込みの問題が解決されます。関連する問題 [SPARK-37210] をコミュニティに提出しました。
Hive を 3.x にアップグレードすると、Union ステートメントが実行されると、デフォルトで Tez エンジンが使用され、HIVE_UNION_SUBDIR サブディレクトリが生成されます。 Spark はサブディレクトリ内のデータを無視するため、データを読み取ることはできません。
この問題は、Parquet/Orc Reader を Hive Reader にフォールバックし、次のパラメータを追加することで解決できます。

ただし、Spark の組み込み Parquet Reader を使用するとパフォーマンスが向上するため、Hive Reader に戻す計画をあきらめ、代わりに Spark を変換しました。 Spark はすでに recursiveFileLookup パラメータを介した非パーティションテーブルのサブディレクトリの読み取りをサポートしているため、パーティションテーブルのサブディレクトリの読み取りをサポートするようにこれを拡張しました。詳細については、[SPARK-40600] を参照してください。
データ同期アプリケーションには多数の JDBC データ ソース タスクがあり、操作効率を向上させ、さまざまなアプリケーション シナリオに適応するために、Spark の組み込み JDBC データ ソースに次の変更を加えました。
シャーディング条件のプッシュダウン
:
Spark は JDBC データ ソースを断片化した後、サブクエリを通じてシャーディング条件を挿入します。MySQL 5.x ではサブクエリ条件をプッシュダウンできないことがわかったので、条件の位置を表すプレースホルダーを追加しました。 , そしてSparkでシャーディング条件を挿入する際にサブクエリの内側まで追い込むことでシャーディング条件を追い込む機能を実現しています。
複数の書き込みモード
:
Spark の JDBC データ ソースに複数の書き込みモードを実装しました。
-
通常: 通常モード。書き込みにはデフォルトの INSERT INTO を使用します。
-
Upsert:主キーが存在する場合に更新します。INSERT INTO...ON DUPLICATE KEY UPDATE モードで書き込まれます。
-
Ignore: 主キーが存在する場合は無視し、INSERT IGNORE INTO モードで書き込みます。
サイレント モード:
JDBC 書き込み中に例外が発生した場合、例外ログのみが出力され、タスクは終了されません。
マップ タイプのサポート
: ClickHouse データの読み取りおよび書き込みには JDBC データ ソースを使用します。ClickHouse のマップ タイプは JDBC データ ソースではサポートされていないため、マップ タイプのサポートを追加しました。
Spark でのシャッフル、キャッシュ、スピルなどの操作では、いくつかのローカル ファイルが生成され、書き込まれるローカル ファイルが多すぎると、コンピューティング ノードのディスクがいっぱいになり、クラスターの安定性に影響を与える可能性があります。
この点に関して、Sparkにディスク書き込み量のインジケータを追加し、ディスク書き込み量がしきい値に達した場合に例外をスローし、TaskSchedulerでタスク失敗例外を判断し、ディスク書き込み制限例外がキャプチャされたときにDagSchedulerを呼び出すようにしました。このメソッドは、ディスク使用量が過剰なタスクを停止します。
同時に、Spark Executor の現在のディスク使用量を公開する ExecutorMetric に Executor Disk Use インジケーターも追加しました。これにより、傾向の観察とデータ分析が容易になります。
Spark サービスは多くのコンピューティング リソースを消費します。 Spark バッチ処理タスクとストリーム コンピューティング タスクのコンピューティング リソースをそれぞれ監査および管理するための例外管理プラットフォームを開発しました。
日々の運用とメンテナンスにおいて、多くの Spark タスクにメモリの無駄や CPU 使用率の低下などの問題があることがわかりました。これらの問題のあるタスクを見つけるために、Spark タスクの実行時にリソース インジケーターを Prometheus に配信し、タスクのリソース使用率を分析し、Spark EventLog を解析してリソース構成と計算の詳細を取得します。
タスクのリソース パラメーターを最適化し、動的なリソース割り当てを有効にすることで、Spark バージョンのアップグレードにより、Spark タスクのコンピューティング リソースの使用率も効果的に向上します。
リソース パラメーターの最適化は、メモリと CPU の最適化に分けられます。例外管理プラットフォームは、過去 7 日間のタスクのピーク リソース使用量に基づいて、適切なリソース パラメーター設定を推奨します。これにより、Spark タスクのリソース使用率が向上します。
メモリの最適化を例に挙げると、ユーザーはメモリを増やすことでメモリ オーバーフロー (OOM) の問題を解決することがよくありますが、OOM の原因の詳細な調査は無視されます。これにより、多数の Spark タスクのメモリ パラメータが高く設定されすぎ、CPU に対するキュー リソース メモリの比率がアンバランスになります。当社は Spark Executor のメモリ インジケーターを取得し、例外作業指示を送信してユーザーに通知し、メモリ パラメーターとパーティションの数を適切に構成するようにガイドします。
ほぼ 1 年間のリソース監査管理を経て、例外管理プラットフォームは 1,600 件を超える作業指示を発行し、合計で約 27% のコンピューティング リソースを節約しました。
Spark SQL サービスの実装と最適化
iQiyi Spark SQL サービスは、Spark のネイティブ Thrift Server サービスから、Kyubi 0.7、Apache Kokubi 1.4 バージョンに至るまで、複数の段階を経て、サービス アーキテクチャと安定性が大幅に向上しました。
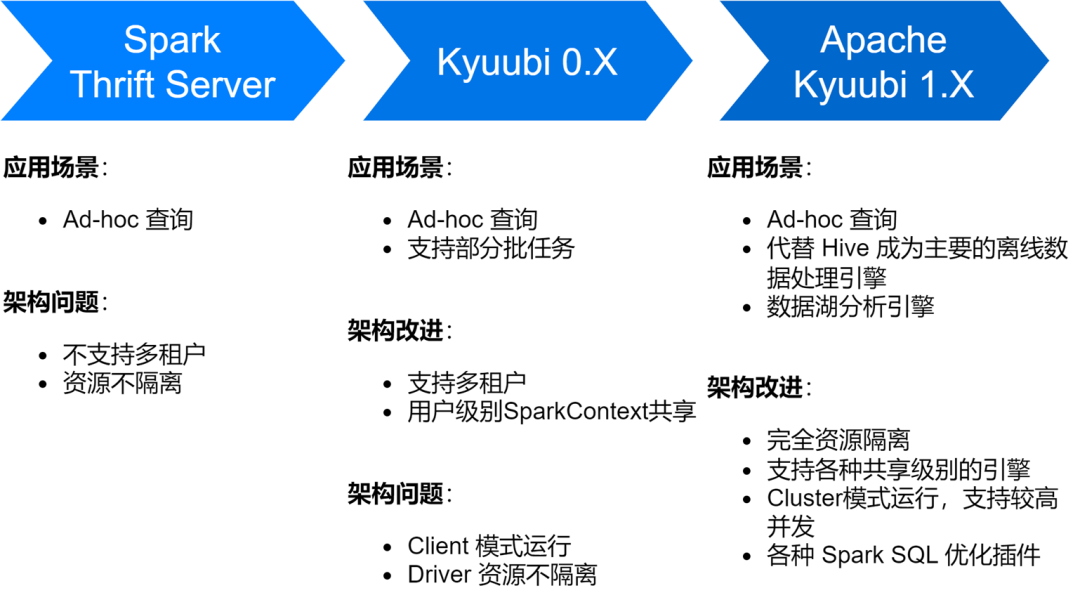
現在、Spark SQL サービスは iQiyi のメインのオフライン データ処理エンジンとして Hive に代わって、毎日平均約 150,000 の SQL タスクを実行しています。
また、Spark SQL サービスの調査中に、主に多数の小さなファイルの生成、大容量のストレージ、低速な計算などの問題にも遭遇しました。このため、一連のストレージとコンピューティング効率の最適化も実行しました。
ZStandard 圧縮を有効にして圧縮率を向上させます
Zstd は Meta のオープンソース圧縮アルゴリズムであり、他の圧縮形式と比較して優れた圧縮率と解凍効率を備えています。実測の結果、Zstdの圧縮率はGzipと同等、解凍速度はSnappyよりも優れていることが分かりました。そのため、Spark アップグレード プロセス中にデフォルトのデータ圧縮形式として Zstd 圧縮形式を使用し、シャッフル データも Zstd 圧縮に設定しました。これにより、クラスター ストレージが大幅に節約され、アドバタイジング データ シナリオに適用すると、圧縮率が 3.3 倍向上しました。 、ストレージコストを 76% 節約します。
小さなファイルの生成を避けるために、再バランスフェーズを追加します。
小さいファイルの問題は、Spark SQL の重要な問題です。小さいファイルが多すぎると、Hadoop NameNode に大きな負荷がかかり、クラスターの安定性に影響します。ネイティブの Spark コンピューティング フレームワークには、小さなファイルの問題を解決する優れた自動ソリューションがありません。この点で、いくつかの業界ソリューションも調査し、最終的には、Kyubi サービスに付属する小さなファイル最適化ソリューションを使用しました。
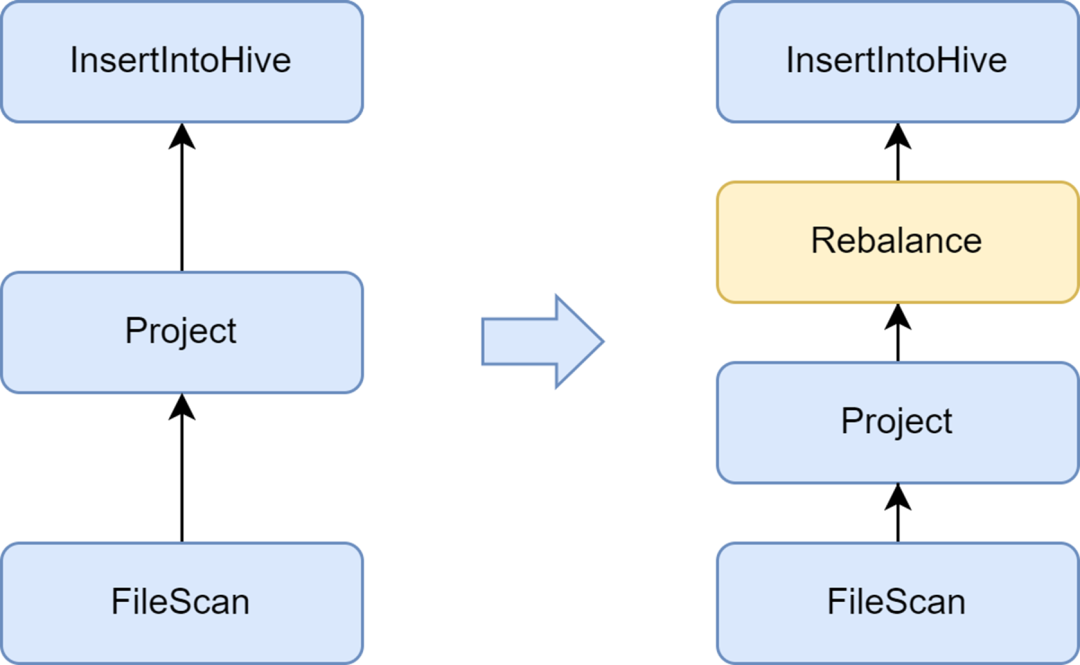
Ryubi が提供する insertRepartitionBeforeWrite オプティマイザーは、Insert 演算子の前に Rebalance 演算子を挿入して、小さなパーティションを自動的にマージし、大きなパーティションを分割することで、出力ファイル サイズの制御を実現し、小さなファイルの問題を効果的に解決します。
これを有効にすると、Spark SQL の平均出力ファイル サイズが 10 MB から 262 MB に最適化され、多数の小さなファイルが生成されなくなります。
再パーティションのソート推論を有効にして、圧縮率をさらに向上させます
小さいファイルの最適化を有効にすると、一部のタスクのデータ ストレージが大幅に大きくなることがわかりました。これは、小さいファイルの最適化で挿入される Rebalance 操作では、パーティショニングにパーティション フィールドまたはランダム パーティションが使用され、データがランダムに分散されるため、Parquet 形式のファイルのエンコード効率が低下し、結果として圧縮率が低下するためです。ファイルの圧縮率で。
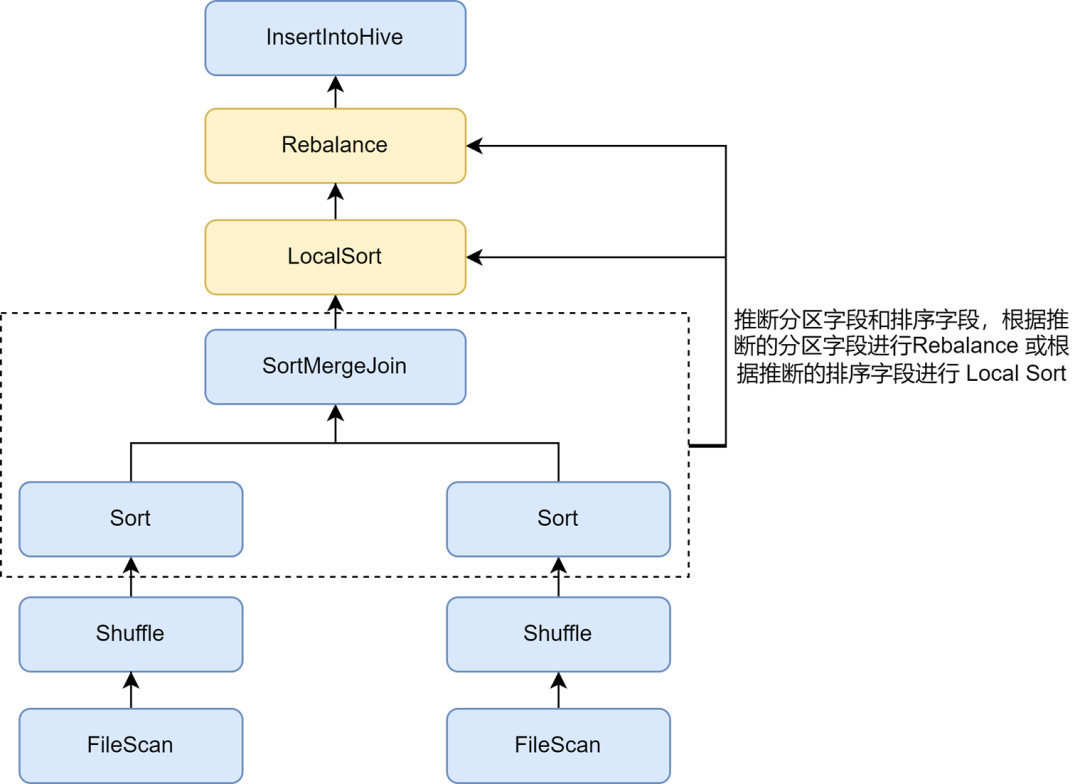
Ryubi の小さなファイル最適化のルールでは、非動的パーティションの書き込みの場合、spark.sql.optimizer.inferRebalanceAndSortOrders.enabled パラメーターを通じて、パーティションとソート フィールドの自動推論を有効にすることができます。実行前プランが使用され、パーティション化フィールドと並べ替えフィールドがキーから推論され、推論されたパーティション フィールドがリバランスに使用されるか、推論された並べ替えフィールドがリバランス前のローカル ソートに使用されます。リバランス オペレーターは事前計画と可能な限り一致し、書き込みを回避します。受信データはランダムに分散されるため、圧縮率が効果的に向上します。
Zorder 最適化を有効にして、圧縮率とクエリ効率を向上させます。
Zorder ソートは、多次元ソート アルゴリズムです。 Parquet などの列指向ストレージ形式の場合、効果的な並べ替えアルゴリズムによりデータがよりコンパクトになり、データ圧縮率が向上します。さらに、同様のデータが同じストレージユニットに収集されるため、たとえば最小/最大の統計範囲が小さくなり、クエリ処理中にスキップされるデータの量が増加し、クエリ効率が効果的に向上します。
Zorder クラスタリングのソート最適化は、Kyubi に実装されています。Zorder フィールドはテーブルに設定でき、書き込み時に Zorder ソートが自動的に追加されます。既存のタスクの場合、既存データの Zorder 最適化のために [最適化] コマンドもサポートされています。一部の主要ビジネスに内部的に Zorder 最適化を追加し、データ ストレージ容量を 13% 削減し、データ クエリのパフォーマンスを 15% 向上させました。
最終段階で独立した AQE 構成を導入し、コンピューティングの並列性を向上させます。
一部の Hive タスクを Spark に移行するプロセス中に、一部のタスクの実行速度が実際に遅くなることがわかりました。分析の結果、書き込み前に Rebalance オペレーターが挿入され、小さなファイルを制御するために Spark AQE と組み合わせられたため、AQE の Spark を変更したことが判明しました。 sql。adaptive.advisoryPartitionSizeInBytes 構成が 1024M に設定されているため、中間のシャッフル フェーズの並列処理が小さくなり、タスクの実行が遅くなります。
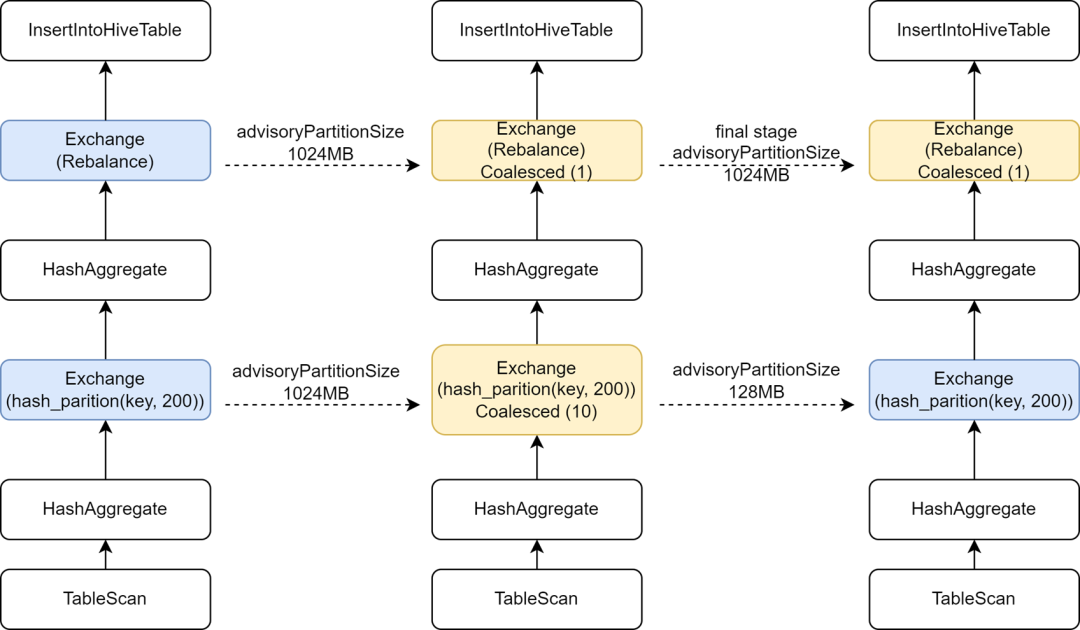
Ryubi は最終ステージ構成の最適化を提供し、最終ステージにいくつかの構成を個別に追加できるようにします。これにより、小さなファイルを制御する最終ステージにはより大きな AdvisoryPartitionSizeInBytes を追加し、前のステージではより小さい AdvisoryPartitionSizeInBytes を使用して並列処理を増やすことができます。この構成を追加すると、Spark SQL タスクの全体的な実行時間が 25% 短縮され、シャッフル ステージ中のディスク オーバーフローが軽減され、リソースが約 9% 節約されます。
過度に大きなシャッフル パーティションを回避するために、単一パーティション タスクの動的書き込みを推論します。
動的パーティションの書き込みの場合、Kyubi の小さなファイルの最適化では、再バランスのために動的パーティション フィールドが使用されます。動的パーティショニングを使用して単一のパーティションに書き込むタスクの場合、すべての Shuffle データが同じ Shuffle パーティションに書き込まれます。 iQIYI は内部で Apache Uniuffle をリモート シャッフル サービスとして使用します。大きなパーティションはシャッフル サーバーに単一の負荷を与え、さらには電流制限を引き起こし、書き込み速度の低下を引き起こします。この目的のために、書き込まれたパーティション フィルター条件を取得し、そのようなタスクに対して単一パーティションのデータが動的パーティション方式で書き込まれているかどうかを推測する最適化ルールを開発しました。リバランスには動的パーティション フィールドを使用しなくなり、ランダムを使用します。 Rebalance 。これにより、より大きなシャッフル パーティションの生成が回避されます。詳細については、[KYUUBI-5079] を参照してください。
データ品質に問題がある場合、またはユーザーがデータ配布に不慣れな場合、異常な SQL が送信されやすく、リソースの大幅な浪費やコンピューティング効率の低下につながる可能性があります。 Spark SQL サービスにいくつかの監視インジケーターを追加し、いくつかの異常なコンピューティング シナリオを検出して遮断しました。
iQiyi では、データ アナリストがマジック ミラー アドホック クエリ プラットフォームを通じてアドホック クエリ分析用の SQL を送信します。このプラットフォームは、ユーザーに第 2 レベルのクエリ機能を提供します。 Kuubi の共有エンジンをバックエンド処理エンジンとして使用することで、起動時間とコンピューティング リソースを無駄にするクエリごとに新しいエンジンを起動することを回避します。バックグラウンドでの共有エンジンの永続的な存在により、ユーザーはより高速なインタラクティブ エクスペリエンスを実現できます。
共有エンジンの場合、複数のリクエストが相互にリソースを占有します。動的リソース割り当てを有効にしても、一部の大きなクエリによってリソースが占有され、他のクエリがブロックされることがあります。そこで、Kyubi の Spark プラグインには、SQL 実行プランのテーブルスキャンなどの操作を解析することで、クエリされたパーティション数やスキャンされたデータ量をカウントできる機能を実装しました。指定されたしきい値を超えると、大規模なクエリであると判断され、実行が中断されます。
判定結果に基づいて、マジック ミラー プラットフォームは大規模なクエリを独立したエンジンに切り替えて実行します。さらに、マジック ミラーでは分単位のタイムアウトが定義されており、共有エンジンを使用して時間外に実行するタスクはキャンセルされ、独立したエンジンの実行に自動的に変換されます。プロセス全体はユーザーの影響を受けないため、通常のクエリがブロックされるのを効果的に防止し、独立したリソースを使用して大規模なクエリを実行し続けることができます。
Spark SQL の Explode、Join、Count Distinct などの一部の操作ではデータ拡張が発生し、データ拡張が非常に大きい場合、ディスク オーバーフロー、フル GC、さらには OOM が発生する可能性があり、計算効率も低下します。 Spark UI の [SQL] タブ ページの SQL 実行プラン図の前後のノードの出力行数インジケーターに基づいて、データ拡張が発生したかどうかを簡単に確認できます。

Spark SQL 実行プラン グラフのインジケーターは、タスク実行イベントおよびエグゼキューター ハートビート イベントを通じてドライバーに報告され、ドライバーに集約されます。
ランタイム インジケーターをよりタイムリーに収集するために、Kyubi の SQLOperationListener を拡張し、SparkListenerSQLExecutionStart イベントをリッスンしてsparkPlanInfo を維持し、同時に SparkListenerExecutorMetricsUpdate イベントをリッスンして、実行中のノードの SQL 統計インジケーターの変化をキャプチャしました。を実行し、現在実行中のノードの出力行数インジケーターと前の子ノードの出力行数インジケーターを比較し、データ拡張率を計算して重大なデータ拡張が発生したかどうかを判断し、異常なイベントが発生した場合は異常なイベントを収集するか、異常なタスクを遮断します。データ拡張が発生します。
データ スキューの問題は Spark SQL の一般的な問題であり、パフォーマンスに影響します。Spark AQE にはデータ スキューを自動的に最適化するためのルールがいくつかありますが、それらは常に有効であるとは限りません。また、データ スキューの問題はユーザーによって引き起こされる可能性があります。データの理解が不十分で間違った分析ロジックが書かれていたり、データ自体の品質に問題があったりするため、データの偏りを分析し、偏ったKey値を特定する作業が必要です。

上の図に示すように、タスクの期間とシャッフル読み取りの最大値が 75 パーセンタイル値を超えているため、データ スキューが発生しているかどうかは明らかです。スキューが発生しました。
ただし、スキュー タスクでスキューの原因となる Key 値を計算するには、通常、SQL を手動で分割し、Count Group By Keys を使用して各段階での Key の分布を計算して、歪んだ Key 値を決定する必要があります。通常、比較的時間のかかる作業です。
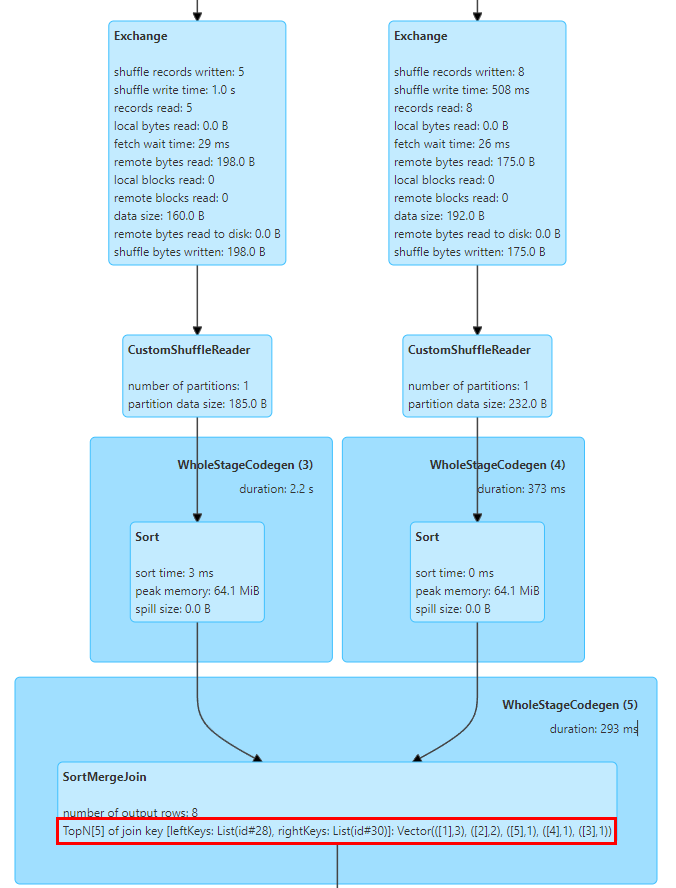
この点で、SortMergeJoinExec に TopN Keys 統計を実装しました。
SortMergeJoin の実装では、最初にキーを並べ替えてから結合操作を実行するため、累積を通じてキーの TopN 値を簡単にカウントできます。
TopNAccumulator アキュムレータを実装しました。これは、Map[String, Long] タイプのオブジェクトを内部的に維持し、Join の Key 値を Map の Key として使用し、SortMergeJoinExec でデータの各行の Key の Count 値を維持します。累積計算の場合は、データが順番に揃っているので、挿入したKeyを累積するだけでよく、新しいKeyを挿入するときにNの値に達したかどうかを判断して最小のKeyを削除するだけです。
さらに、Spark は Long タイプの統計インジケーターの表示のみをサポートし、Map タイプの値に適応するように SQL 統計インジケーターの表示ロジックも変更しました。
上の図は、結合の 2 つのテーブルの上位 5 つの結合キー値を示しています。キーは id フィールドで、id=1 の行が 3 つあります。
一連の調査とテストの結果、Spark SQL は Hive と比較してパフォーマンスとリソース使用量が大幅に向上していることがわかりました。ただし、Hive SQL から Spark への移行中に多くの問題も発生しました。 Spark SQL サービスに互換性の変更と適応を加えることにより、ほとんどの Hive SQL タスクを Spark に移行することができました。
Spark SQL の Hive UDF サポートには、実際の使用においていくつかの問題があります。たとえば、企業はリフレクト関数を使用して Java 静的メソッドを呼び出してデータを処理することがよくあります。リフレクション呼び出しで例外が発生すると、Hive は NULL 値を返し、Spark SQL は例外をスローしてタスクを失敗させます。この目的を達成するために、Hive と一貫して、リフレクション呼び出し例外をキャプチャし、NULL 値を返すように Spark のリフレクト関数を変更しました。
もう 1 つの問題は、Spark SQL が Hive UDAF のプライベート コンストラクターをサポートしていないため、一部のビジネスの UDAF が初期化に失敗する原因となります。 Hive UDAF プライベート コンストラクターをサポートするために、Spark の関数登録ロジックを変換しました。
Spark SQL と Hive バージョン 1.2 では、組み込みの GROUPING_ID 関数の計算ロジックに違いがあり、その結果、デュアル実行フェーズでデータの不整合が発生します。 Hive 3.1 バージョンでは、この関数の計算ロジックが Spark のロジックと一致するように変更されているため、計算ロジックの正確性を確保するために SQL ロジックを更新し、Spark でこの関数のロジックを適応させることをお勧めします。
さらに、Spark SQL のハッシュ関数は、Hive の実装ロジックとは異なる Murmur3 ハッシュ アルゴリズムを使用し、移行の前後でデータの一貫性を確保するために Hive の組み込みハッシュ関数を手動で登録することをお勧めします。
Spark SQL はバージョン 3.0 から ANSI SQL 仕様を導入しており、Hive SQL と比較して、文字列型と数値型の間の自動変換が禁止されているなど、型の一貫性に関する要件が厳しくなっています。ビジネスにおける非標準のデータ型定義によって引き起こされる自動変換異常を回避するために、大規模な変換の場合は、明示的な変換のために SQL に CAST を追加することをお勧めします。移行例外を回避するために、Spark SQL レベルの型チェックを減らします。
Hive の str_to_map 関数は、繰り返されたキーの最後の値を自動的に保持しますが、Spark では例外がスローされ、タスクは失敗します。この点に関して、ユーザーがアップストリーム データの品質を監査するか、spark.sql.mapKeyDedupPolicy=LAST_WIN 構成を追加して、Hive と一貫して最後の重複値を保持することをお勧めします。
Spark SQL と Hive SQL のヒント構文には互換性がないため、ユーザーは移行中に関連する構成を手動で削除する必要があります。一般的な Hive ヒントには、小さなテーブルのブロードキャストが含まれます。Spark AQE 機能は、小さなテーブルのブロードキャストとタスク ティルティングの最適化に対してよりインテリジェントであるため、通常、ユーザーによる追加の構成は必要ありません。
Spark SQL と Hive の DDL ステートメントの間には互換性の問題もいくつかあります。通常、ユーザーにはプラットフォームを使用して Hive テーブルで DDL 操作を実行することをお勧めします。存在しないパーティションの削除 [KYUUBI-1583]、不等な Alter Partition ステートメント、その他の互換性の問題など、一部のパーティション操作コマンドについては、互換性を確保するために Spark プラグインも拡張しました。
概要と展望
現在、社内の Hive タスクのほとんどを Spark に移行したため、Spark が iQiyi のメインのオフライン処理エンジンになりました。 Spark エンジンに関する予備的なリソース監査とパフォーマンスの最適化作業を完了し、会社に大幅な節約をもたらしました。今後も、Spark サービスとコンピューティング フレームワークのパフォーマンスと安定性の最適化を続けていきます。また、残りわずかな Hive タスクの移行もさらに推進していきます。
同社のデータ レイクの実装により、ますます多くの企業が Iceberg データ レイクに移行しています。 Iceberg が Spark DataSourceV2 の機能を改善し続けるにつれて、Spark 3.1 では一部の新しいデータ レイク分析ニーズを満たすことができなくなったため、Spark 3.4 にアップグレードしようとしています。同時に、ビジネス ニーズに基づいて Spark コンピューティング フレームワークのパフォーマンスをさらに向上させることを期待して、ランタイム フィルター、ストレージ パーティション結合などのいくつかの新機能に関する調査も実施しました。
さらに、クラウドネイティブなビッグデータ コンピューティングのプロセスを促進するために、リモート シャッフル サービス (RSS) である Apache Uniuffle を導入しました。使用中に、BroadcastHashJoin スキュー最適化 [SPARK-44065]、前述の大規模パーティションの問題、AQE パーティション プランニングをより適切に実行する方法など、Spark AQE と組み合わせるとパフォーマンスの問題があることが判明しました。将来的には、より詳細な調査と最適化が行われる予定です。

