
Kangaroo Cloud 09 製品機能アップデート レポートへようこそ。このレポートでは、革新と最適化を同等に重視するという概念を堅持し、製品の徹底的な磨きと包括的なアップグレードを実行します。細部にわたる改善は、私たちの絶え間ない品質の追求であり、これらの新機能がお客様の事業運営と発展に貢献し、デジタルトランスフォーメーションへの道をよりスムーズにすることを願っています。
以下は、Kangaroo Cloud 製品機能更新レポート第 09 号の内容です。さらに詳しく知りたい場合は、読み続けてください。
オフライン開発プラットフォーム
新機能のアップデート
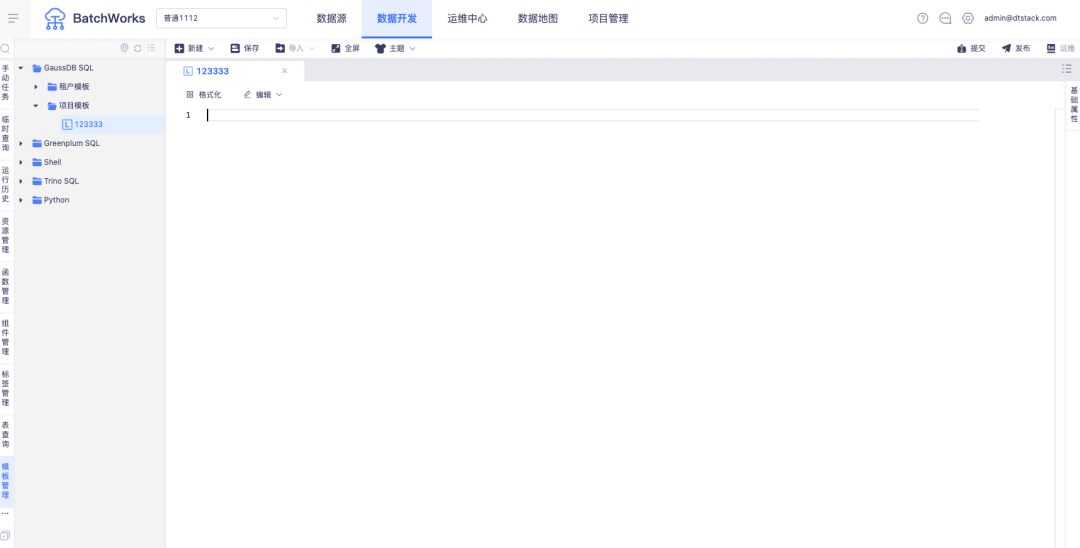
1.タスクテンプレート
背景: 顧客は、毎日の共通コード テンプレートをオフラインで維持し、データ開発中に直接参照することを望んでいます。
テンプレートとコンポーネントの違いは次のとおりです。
1. テンプレートコード参照後の編集はサポートされますが、コンポーネント参照後の編集はサポートされません。
2. テンプレートの変更は参照タスクには影響しませんが、コンポーネントの変更は参照タスクに影響します。
新機能の説明: 各タスク タイプのプロジェクト コード テンプレートとテナント コード テンプレートをサポートし、タスク作成時のコード テンプレートの参照をサポートします。
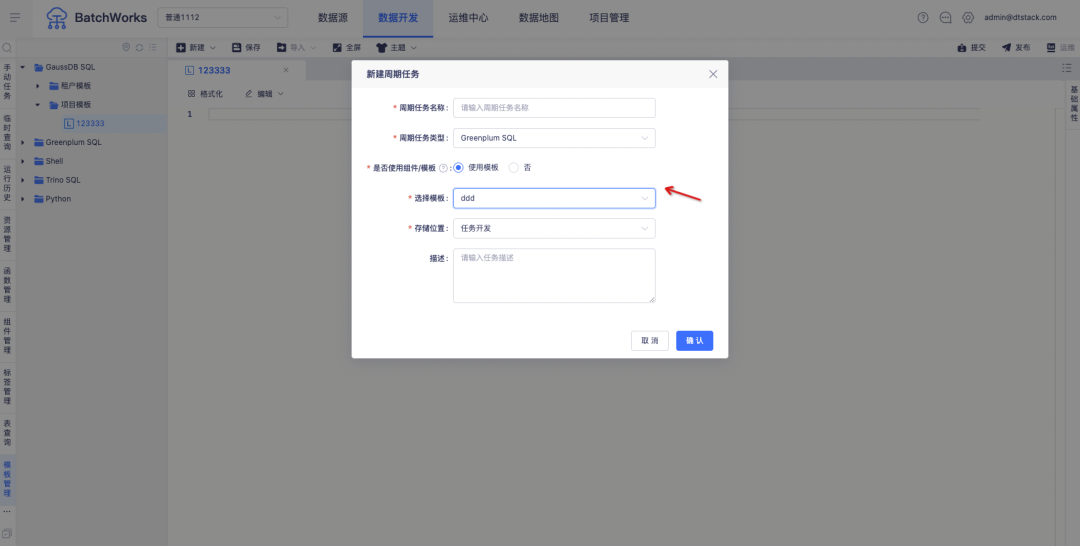
2.エージェント上のシェル/エージェント上のPythonにより、新しいプロジェクトディメンションコントロールが追加されます
背景:
エージェント上のシェルは、オフライン プラットフォーム用の特別なタスク タイプです。
シェル タスクはクラスターにデプロイされたマシン上で直接実行されませんが、シェルは独立してデプロイされたサーバー ノード上で実行されます。 1 つのオフライン タスクには 2 つのコアが必要なため、顧客のシナリオに多くのシェル タスクがある場合、クラスター リソースが簡単にいっぱいになります。したがって、個別にデプロイされたノードでシェルや Python などのタスクを実行すると、クラスターへの負荷を効果的に軽減できます。
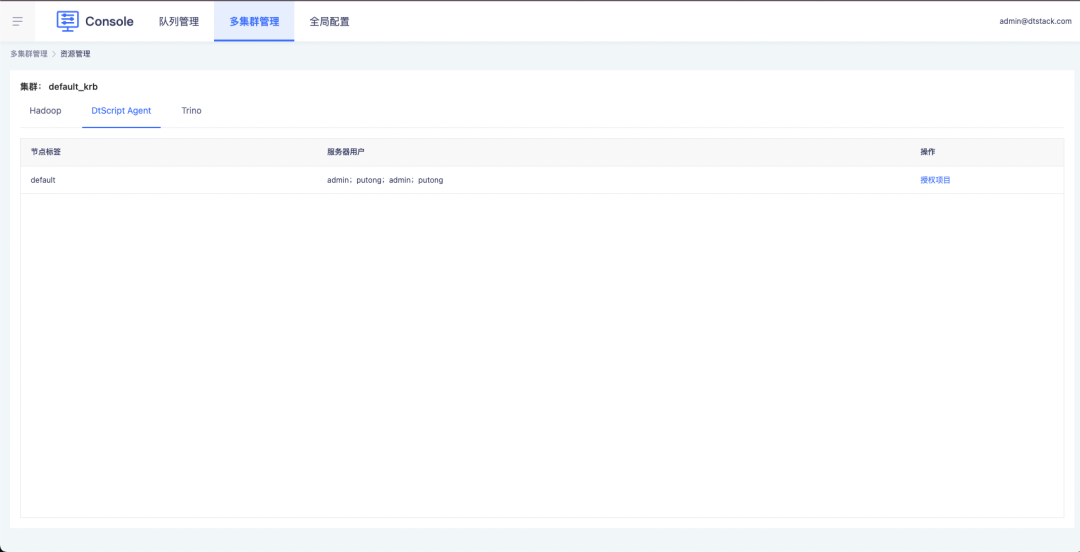
現在問題が発生しています。顧客が EM とコンソールでノードとサーバー ユーザーを構成している限り、クラスター内のすべてのプロジェクトは構成されたノードとサーバー ユーザーを使用できます。これにより、セキュリティ上の問題が発生します。たとえば、root などの高い権限を持つユーザーの場合、顧客はセキュリティの問題に注意を払い、すべてのプロジェクトがこのアカウントを使用できるようにすることを望まないため、サーバー ノードの構成を制御できるソリューションを設計する必要があります。とサーバー ユーザーがこの問題を解決します。
新機能の説明:
1. コンソールは、プロジェクトの承認を通じてノードとサーバーのユーザー権限を制御します。
2. オフライン プロジェクトのタスクは、承認されたサーバー ノードとユーザーの選択をサポートします。
機能の最適化
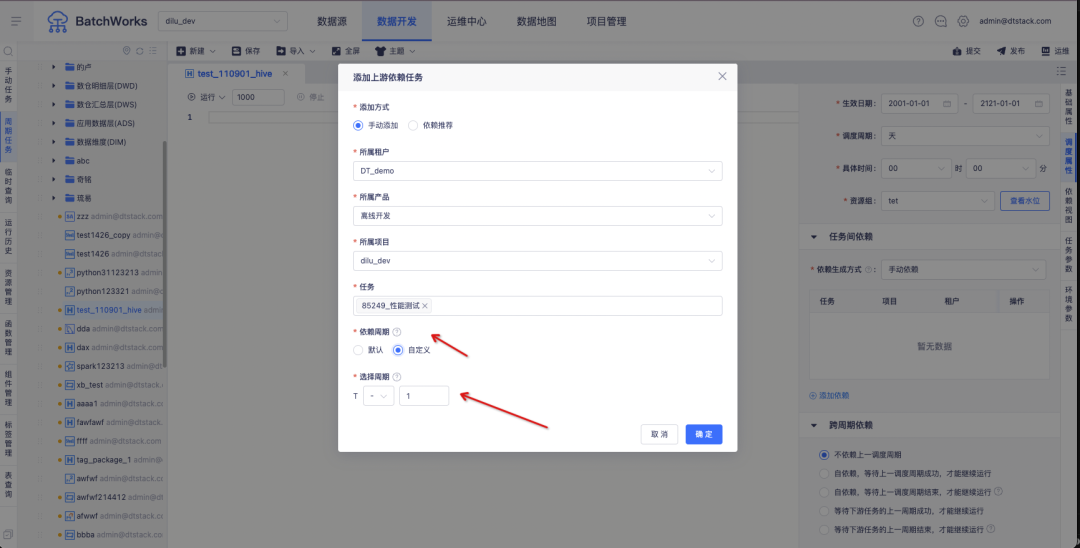
1. スケジューリング構成の最適化。上流のタスクに依存する定期的なインスタンスを制御できます。
背景:
現在、Zhongtian タスクのスケジュール設定は、デフォルトで現在のサイクルの上流インスタンスにのみ依存できます。お客様には次のようなシナリオが考えられます。
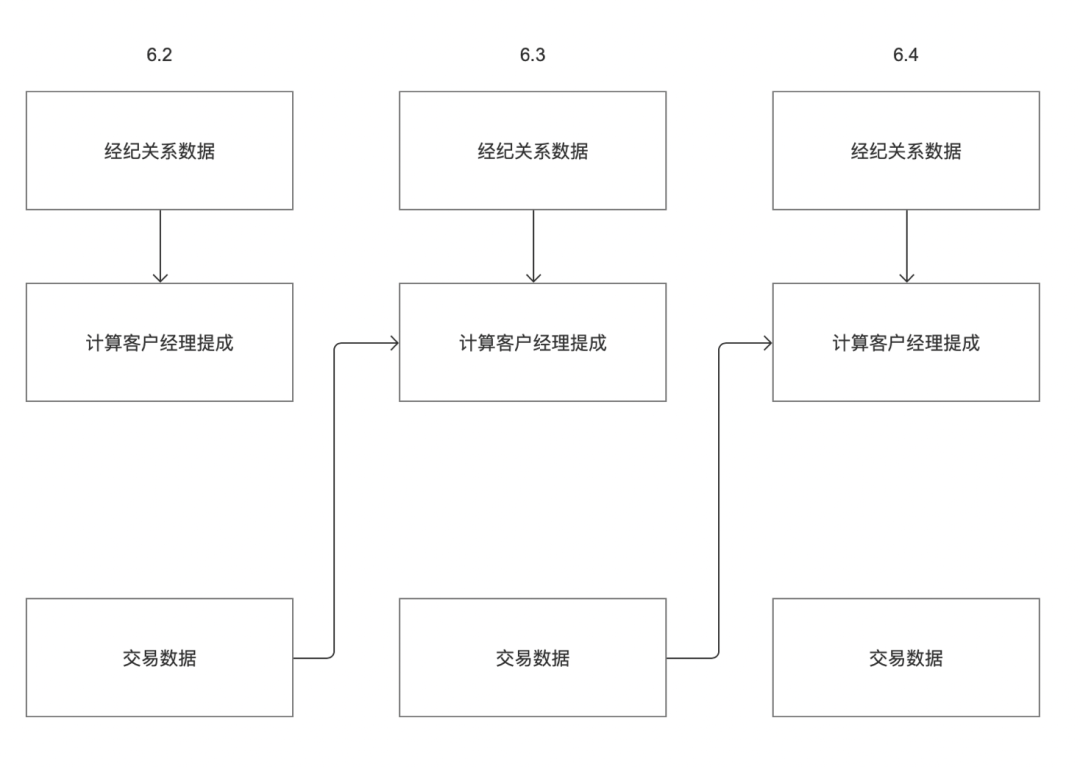
例えば、ある顧客は「仲介関係データ」と「取引データ」という2つの業務システムを持っており、6月3日の顧客の手数料はそれぞれ「仲介関係データ」と「取引データ」に基づいて計算する必要があります。上図に示すように、6月2日の「仲介関係データ」の業務システムデータ出力時刻は6月3日、6月2日の「取引データ」業務システムデータの出力時刻は6月2日の夕方となります。
現在のオフラインの上流と下流の依存関係ロジックによれば、「アカウント マネージャー コミッションの計算」タスクは 6 月 3 日のタスクのみを取得できますが、6 月 2 日のタスクは取得できません。 したがって、タスク インスタンスの依存関係設定をサポートするように変更する必要があります。サイクルをカスタマイズできます。
エクスペリエンスの最適化手順:
依存する上流タスクのスケジューリング サイクルのカスタマイズをサポートします。
T は現在のタスク (下流タスク) の計画時間を表します。「+ -」はオフセット方向を表します。「+」は未来への時間オフセットを表します。「-」は過去への時間オフセットを表します。「-」はデフォルトで選択されています。
オフセットは、最大値が 10、最小値が 1 の数値入力ボックスで、オフセットの上流タスク サイクル数を表します。
リアルタイム開発プラットフォーム
新機能のアップデート
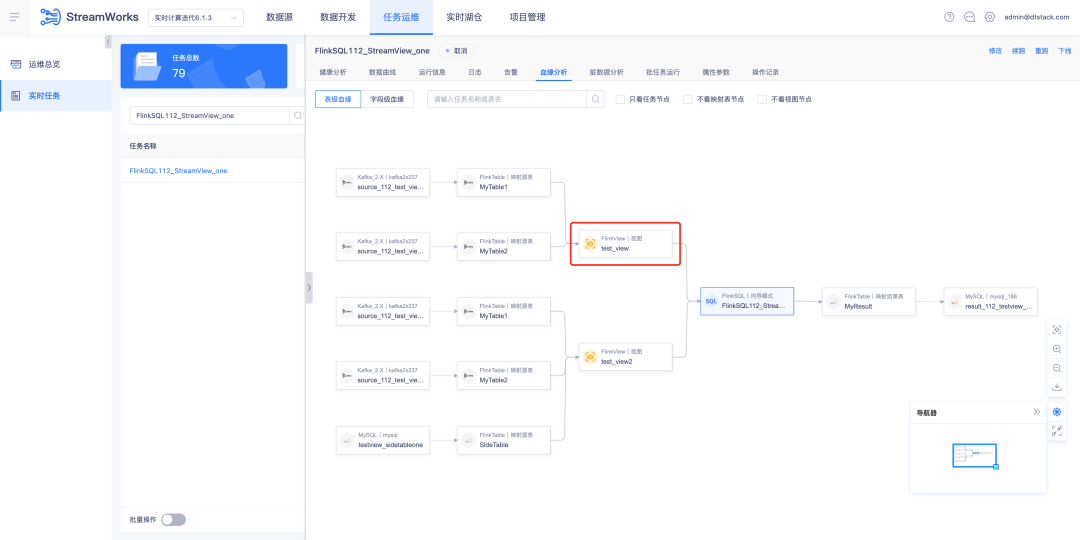
1. 血統分析を表示する
背景: 現在、SQLParser は FlinkSQL のビュー リネージ分析をサポートしていません。ただし、一般的な開発シナリオでは、タスクに 3 つ以上のテーブルが含まれる場合、多くの会議は SQL ロジックの読み取りを容易にするために IDE でビューを構築することを選択します。
関数:
1. SQLParser は血縁関係分析を表示する FlinkSQL ビュー テーブルをサポートします
2. タスク運用・保守 - リアルタイムタスク - FlinkSQLタスク詳細 - 血統分析表示機能
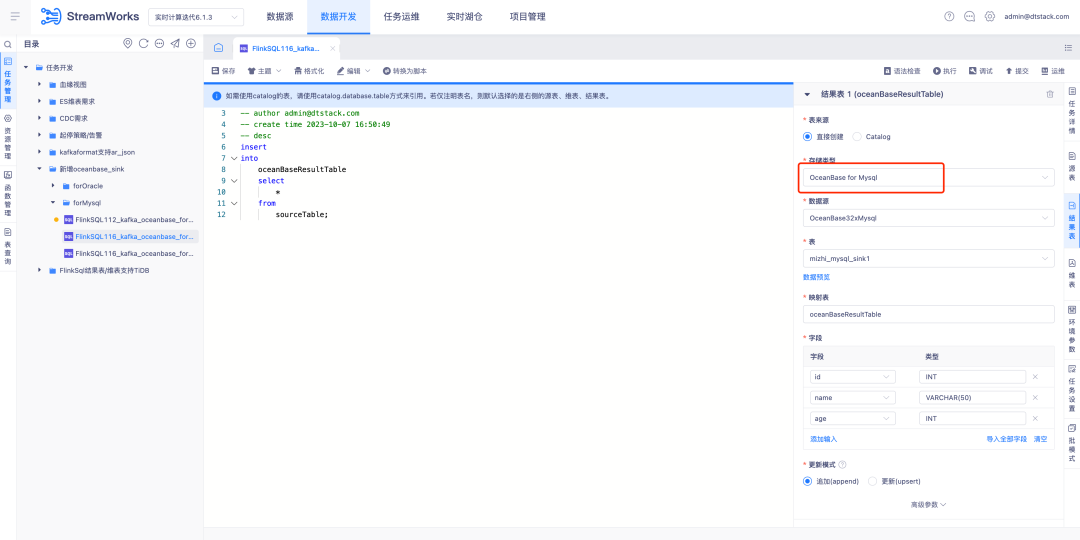
2.FlinkSQL は Oceanbase Sink をサポートします
FlinkSQL バージョン 1.16 は、 OceanBase 結果テーブルをサポートし、OceanBase バージョン 4.2.0 の MySQL および Oracle モードと互換性があるため、より柔軟で効率的なデータ処理機能をユーザーに提供します。
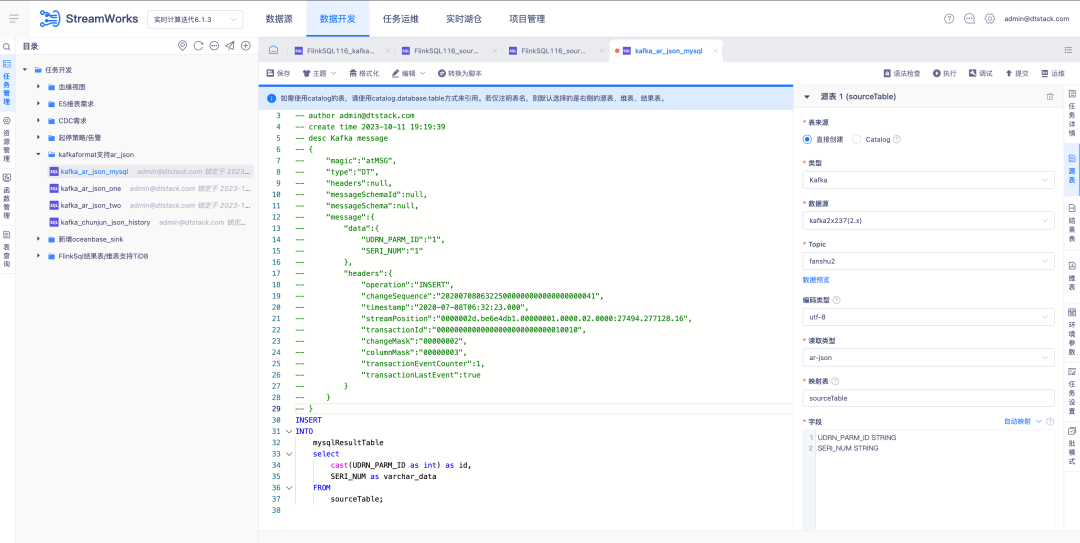
3. ソーステーブル Kafka 読み取りタイプは AR Json をサポートします
背景: OGG とAttunity Replicate は、海外で広く使用されている 2 つの商用製品です。顧客のニーズに応えるためには、Kafka の JSON 形式が AR Json 読み取りタイプと互換性があることを確認する必要があります。
新機能の説明: FlinkSQL1.16 バージョンのソース テーブル Kafka 読み取りタイプは AR Json タイプをサポートし、Json を解析するための自動マッピング関連関数をサポートします。
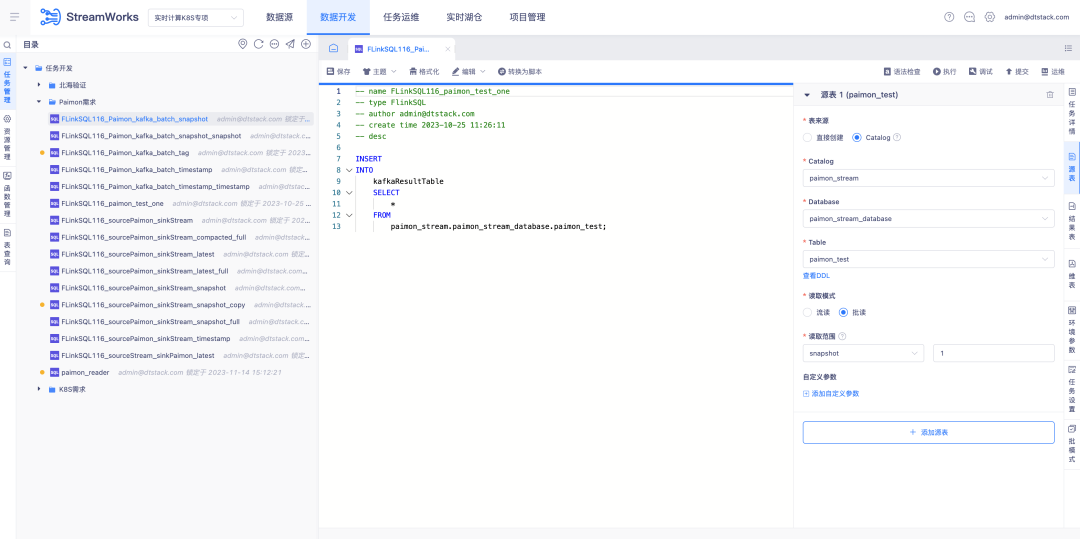
4. リアルタイムレイク倉庫パイモン対応
背景: Paimon の開発に伴い、今回は新しい FlinkSQL 開発モデルを反復する必要があります。このモデルを使用して、レイク ウェアハウス管理モジュールをチェーン全体に連結できます。
新機能の説明:
1. Lake ウェアハウス管理により、 Paimon テーブルを追加、削除、変更、クエリする機能が追加されます。
2.データ開発基盤にパイモンテーブルのビジュアル設定機能を追加します。
3. データ開発プラットフォームは IDE を使用して、Paimon テーブルの読み取りおよび書き込み機能を実行します。
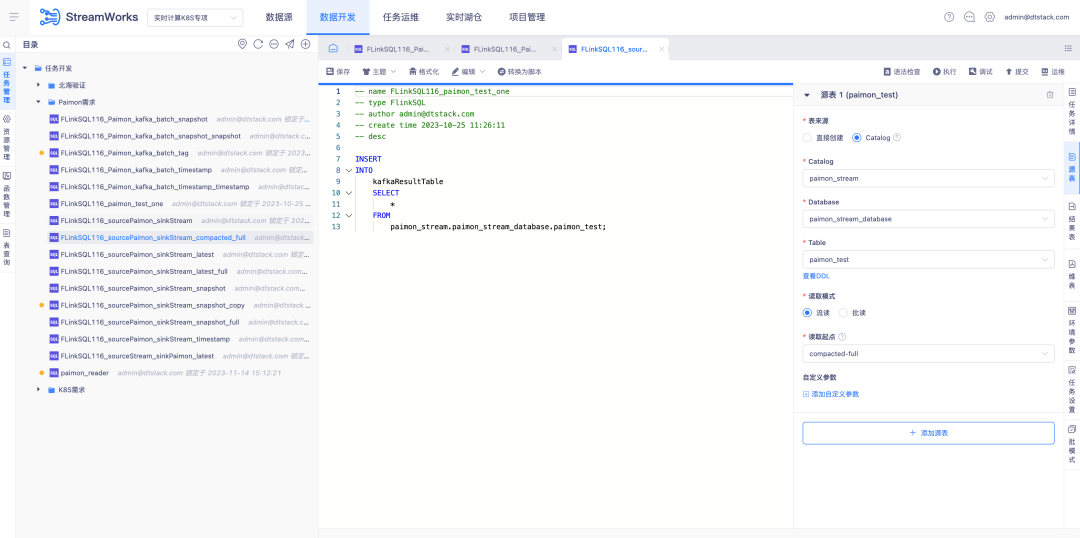
5.FlinkSQL 組み込み FlinkCDC
背景: FlinkCDC は、非常に高速な反復速度を備えたオープンソースのリアルタイム収集コンポーネントです。これが依存する基盤となる Flink フレームワークも、私たちが使用する ChunJun フレームワークと同じです。したがって、これをリアルタイム プラットフォーム展開のデフォルト コンポーネントにして、システムにパッケージ化することを検討します。
新機能の説明:
1. リアルタイムのデフォルト展開パッケージ、FlinkCDC リアルタイム収集セットアップを導入
2. プラットフォーム スクリプト モード。FlinkCDC の組み込みコレクション機能とサポートされているコネクタを確認する必要があります。
3.プラットフォーム ウィザード モードでは、プロジェクトの状況に応じて、FlinkCDC がサポートするコネクタ コレクションを構成します。
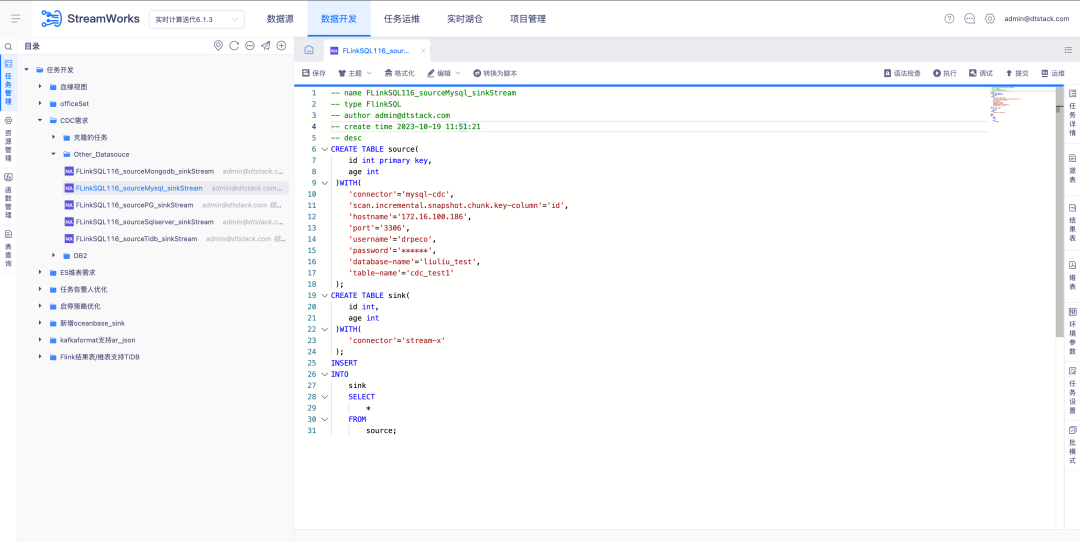
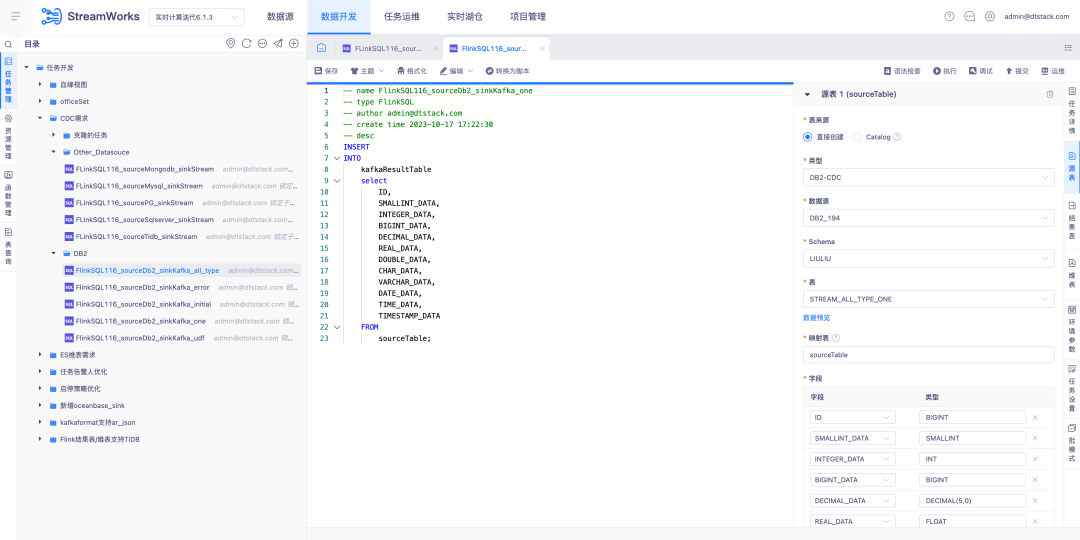
6.FlinkSQL は FlinkCDC DB2 データ ソースをサポートします
背景: 顧客は DB2 のリアルタイム収集をサポートする必要があります。CDC コネクタの開発が難しいことを考慮すると、FinkCDC はそれをサポートするだけなので、最下層は FlinkCDC の機能を借用します。
新しい機能の説明: リアルタイム プラットフォームは、ソース テーブルをDB2-CDC データ ソースとして構成するためのウィザード モードをサポートします。
機能の最適化
1.継続ロジックの最適化
背景: リアルタイム タスクが CheckPoint を通じて再開され、実行を継続する場合、時点を手動で選択する必要があります。ただし、実際には、ほとんどの継続シナリオでは最新の CheckPoint が選択されます。
エクスペリエンスの最適化の説明: CheckPointを復元して実行を継続するように最適化する場合、日付内で最も近い CheckPoint が自動的に選択されます。
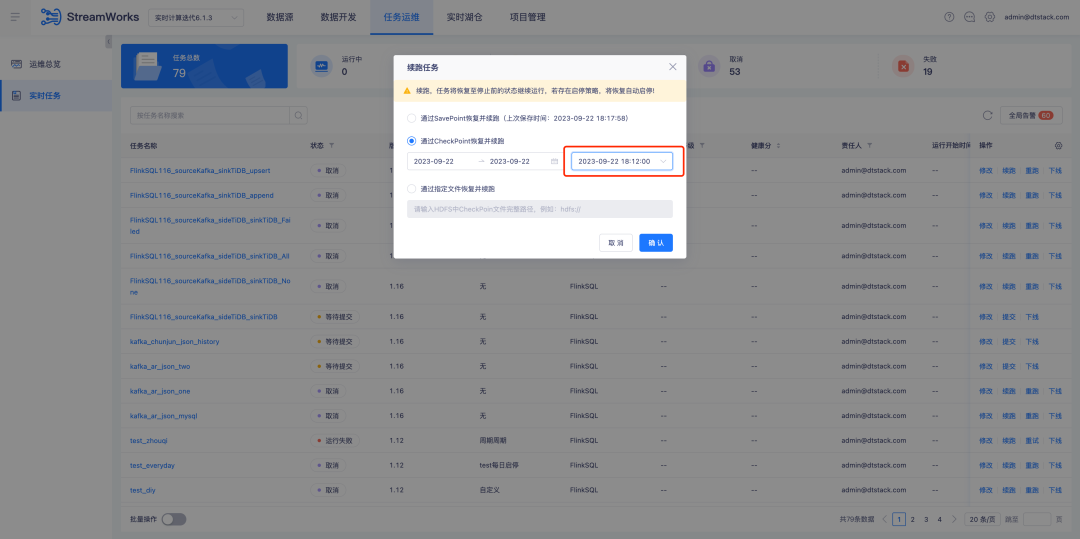
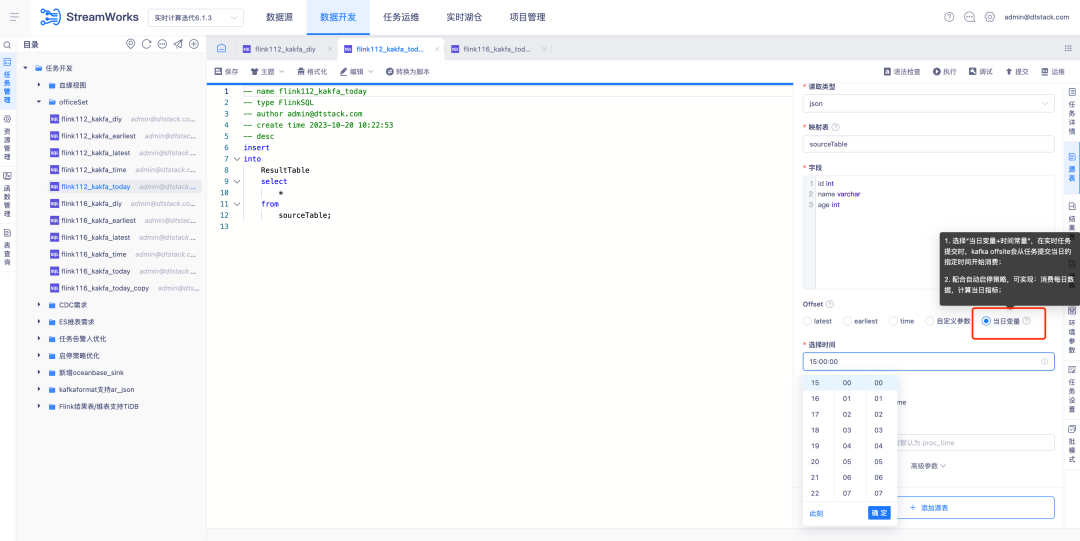
2. スタートストップ戦略/オフサイト最適化
背景: お客様が徹底的に使用するうちに、スタート/ストップ戦略、送信、再実行などの側面を最適化して、より効率的なワークフローとより良いユーザー エクスペリエンスを実現できることがわかりました。
現在、データ開発ソース テーブルのオフサイト タイムスタンプ構成は修正されています。ただし、リアルタイム タスク コンピューティング シナリオでは、一部の顧客はその日のデータ計算のみに重点を置くため、タスクを毎日再実行する開始/停止ポリシーを構成します。彼らは、固定のタイムスタンプを使用するのではなく、毎日午前 0 時にタスクを再実行できるようにしたいと考えています。最新では理論的にはこの要件を満たすことができますが、リアルタイム タスクの起動時間が消費されるため、実際の実行時間がゼロから外れ、データ エラーが発生する可能性があります。
エクスペリエンスの最適化手順:
1.スタート/ストップ ポリシーの構成を最適化し、日をまたぐスタート/ストップ ポリシーをサポートし、現在のスタート/ストップ ポリシー ページのインタラクションを改善して、より効率的で便利な操作エクスペリエンスを提供します。
2. データ開発 - ソーステーブル、オフサイトロケーションのパラメータ化された構成をサポート
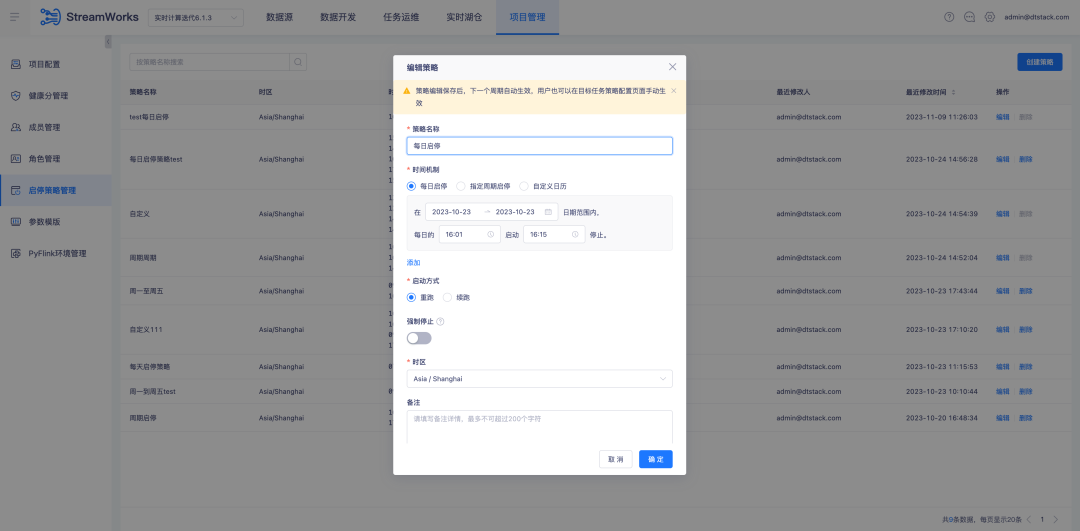
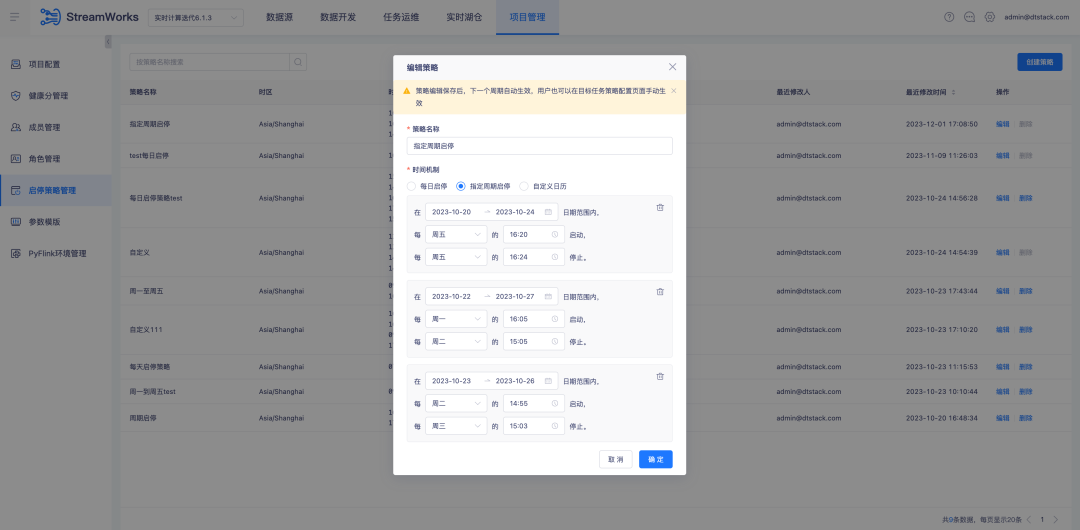
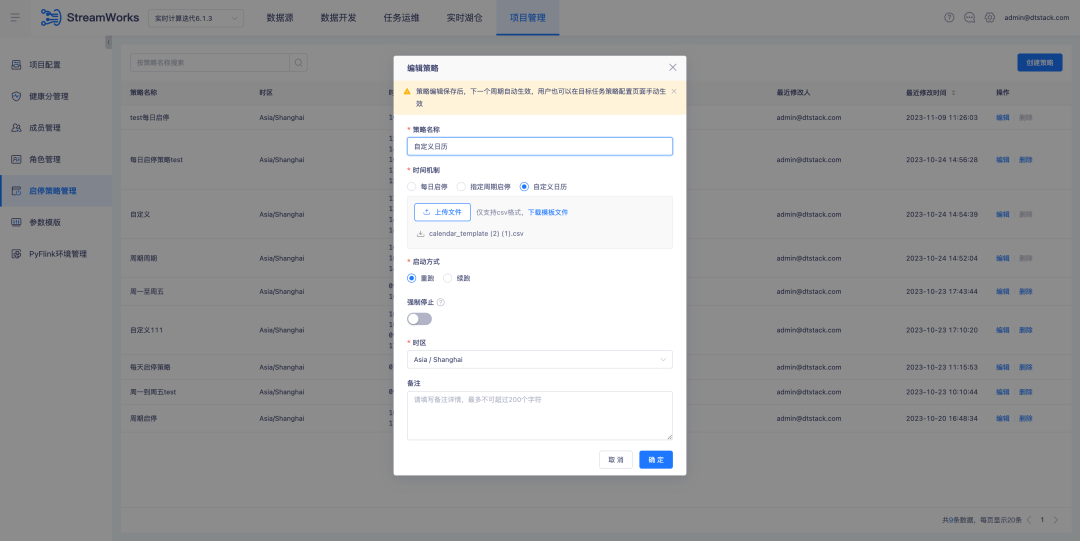
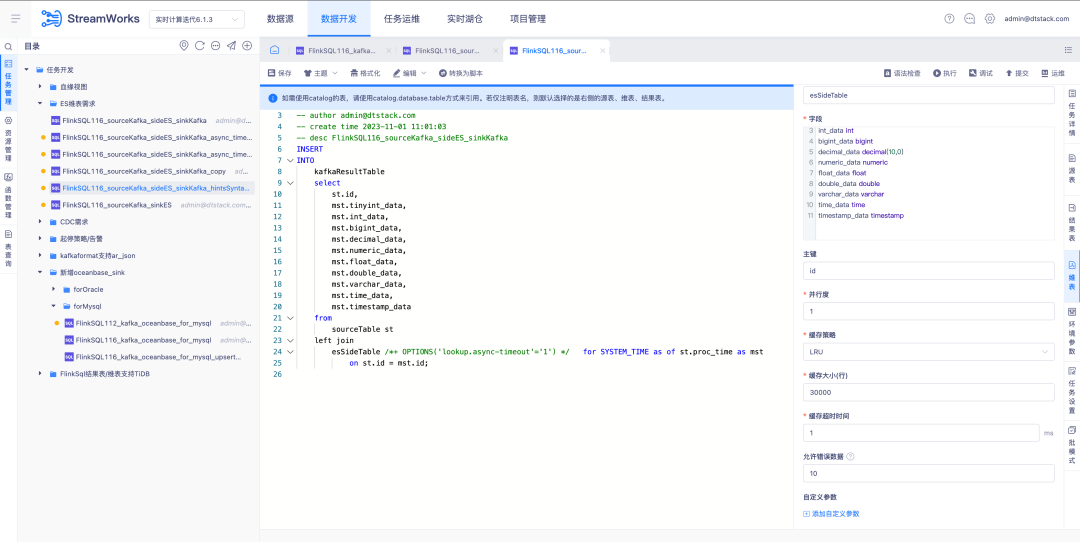
3.FlinkSQL1.16 バージョン ES7.x プラグインの最適化
背景: FlinkSQL バージョン 1.10 の ES プラグインは、ディメンション テーブルのタイムアウト時間とタイムアウト データ制限の構成をサポートしています。この機能は現在の FlinkSQL バージョン 1.16 では一時的に使用できなくなり、現在積極的に最適化されています。
エクスペリエンスの最適化手順:
FlinkSQL1.16 バージョン ES7.x プラグイン ディメンション テーブルは、table.exec.async-lookup.timeout を構成するか、ヒント構文を使用してタイムアウトを設定します。タスクがディメンション テーブルの LRU モードで実行されている場合、非同期クエリのタイムアウトには時間がかかります。効果。
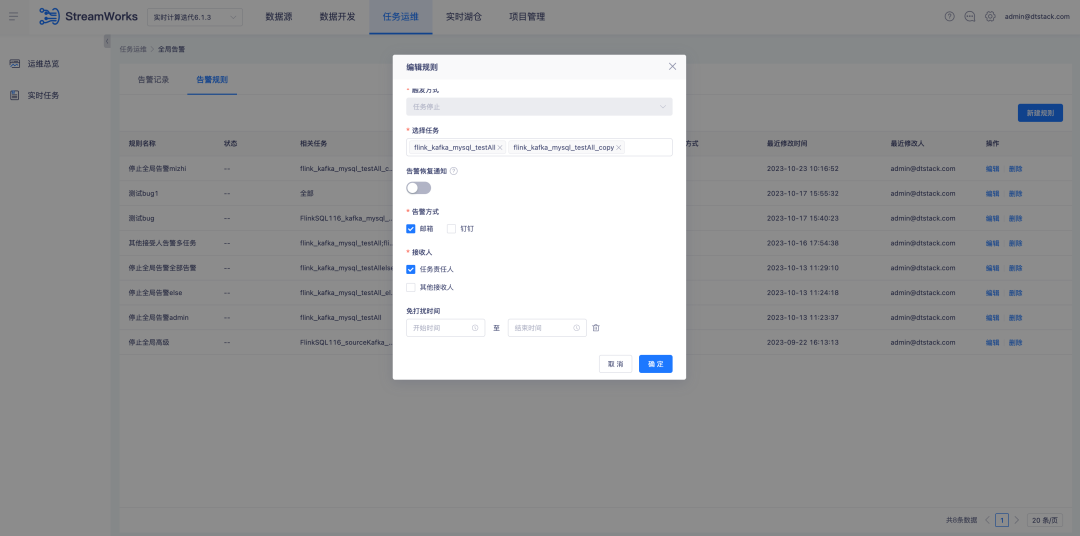
4.アラーム設定の最適化
背景: タスク アラーム ルールでは、アラーム受信設定を手動で選択する必要があります。同時に、グローバル アラーム設定でも、アラーム情報を自動的に照合して送信することはできません。タスク責任者に応じて、対応するアラーム情報を自動的に送信することは不可能です。
エクスペリエンスの最適化手順:
1.単一タスクのアラーム ルール設定の受信者の調整。デフォルトでタスクの責任者が選択されます。複数の選択がサポートされています。
2.タスク責任者にチェックを入れると、グローバルアラームルール設定が実際に各タスクの責任者に送信されます。他の受信者が選択されている場合、選択したタスクが異常の場合、選択したタスクが選択した受信者に送信されます。
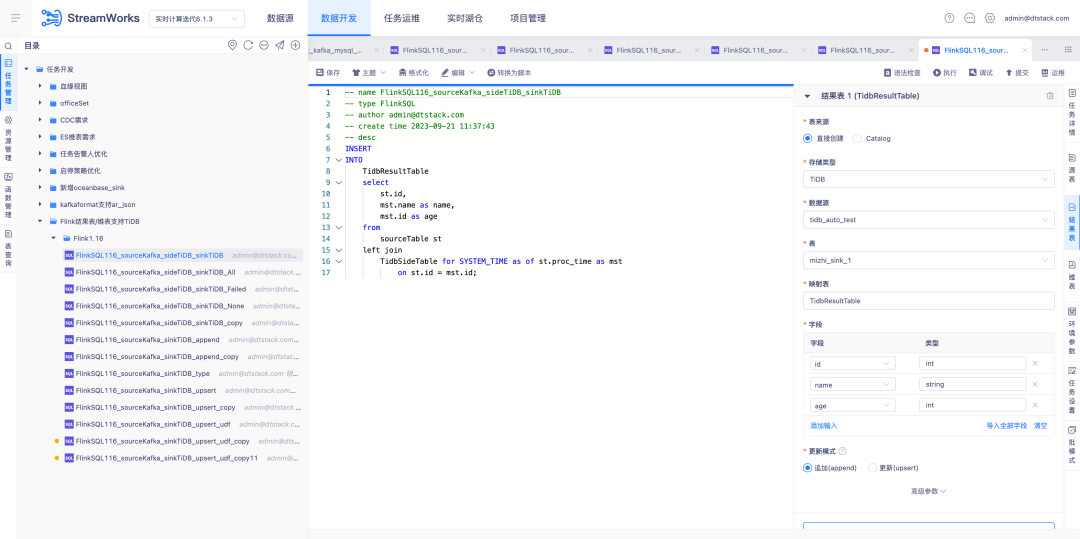
5.FlinkSQL1.12&1.16バージョンTidbプラグインプラットフォームと互換性があります
背景: FlinkSQL バージョン 1.12 および 1.16 は Tidb への適応を完了しましたが、プラットフォーム層はバージョン 1.10 でしか適応されていないため、バージョン 1.12 および 1.16 はサポートされていません。
エクスペリエンスの最適化手順:
リアルタイム プラットフォームは Tidb プラグイン バージョン 1.12 および 1.16 と互換性があり、ディメンション テーブルと結果テーブルの両方をサポートする必要があります。
6.FlinkSQL1.12&1.16バージョンHive huaweiCloud適応
背景: Kafka データのリアルタイム バックアップは MRS Hive に入力されます。リアルタイム計算データに問題がある場合、Hive 内のバックアップ メッセージを分析できます。
エクスペリエンスの最適化手順:
FlinkSQL バージョン 1.12 および 1.16 は、Hive huaweiCloud に適合しています。Kerberos を有効にするシナリオに注意する必要があります。
データサービスプラットフォーム
新機能のアップデート
1. HBase TBDS バージョン作成 API をサポート
HBase TBDS バージョン作成 API を追加しました。これには、ウィザード モード生成 API、インポートとエクスポート、およびターゲット プロジェクトへの公開が含まれます。

機能の最適化
1.Oracle データソースは DML をサポートします
DMLでサポートされるデータ ソースを改善します。
2. カスタム SQL モードのコメント解析で説明が上書きされなくなりました
背景: 履歴ロジックの場合、カスタム SQL スキーマがデータベースに対して再解析された後、データベースに付属するコメントによって変更された命令が上書きされます。
エクスペリエンス最適化命令: 履歴ロジックを変更します。変更された命令では、再解析後にデータベース内のコメントが上書きされなくなります。
3. 行レベルの権限を有効にすると、デフォルトで入力する必要はありません。
背景: 履歴の行レベルの権限の場合、行レベルの権限はテーブル内のフィールドから有効になります。有効になった後、フィールドはデフォルトで必須となり、ユーザーのキャンセルはサポートされません。
エクスペリエンスの最適化の説明: この反復により、履歴ロジックが調整されます。行レベルの権限は、有効化された後、API がテーブルを使用するときに行レベルの権限によって制限されます。
4. フレームワークのバージョンとコンポーネントのアップグレード
Spring Cloud (Boot) フレームワークのバージョンがアップグレードされ、Nacos コンポーネントがアップグレードされて、脆弱性の可能性が減り、API 自体の安定性が向上しました。
顧客データ洞察プラットフォーム
新機能のアップデート
1.カスタムUDF関数のサポート
背景: 顧客が処理するデータに含まれる携帯電話番号、ID 番号、その他のデータは、監査の観点からは暗号化されたデータです。ただし、プレーン テキストのコンテンツが表示されるシナリオもあります。例: 携帯電話番号に基づく SMS マーケティング。
お客様は、復号化プロセスをできるだけ遅くしてラベル プラットフォームに配置して完了し、UDF 関数のカスタマイズを通じてカスタム ラベルを追加して処理を完了する必要があります。
新しい関数の説明: 新しい関数管理モジュールがタグ センターに追加され、その下で UDF 関数を作成、表示、削除できます (関数の作成をサポートしているのは Trino385 以降のバージョンのみです)。
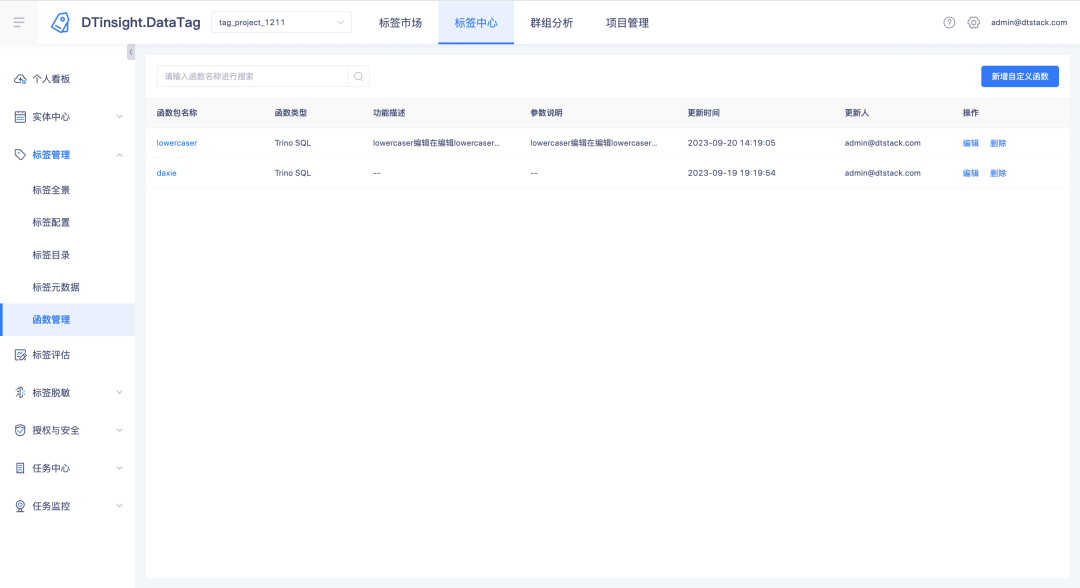
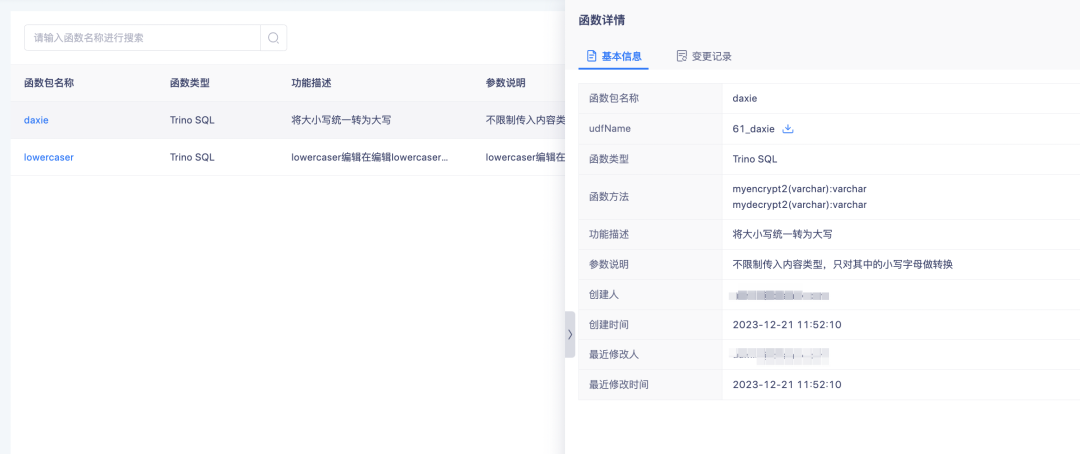
アップロードされた関数については、関数名をクリックして関数の詳細を表示できます。
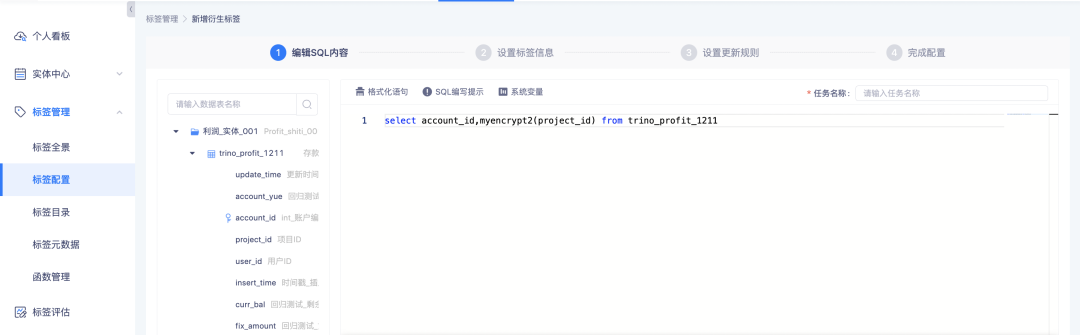
アップロードされた関数は、主に派生 SQL タグの処理に使用されます。
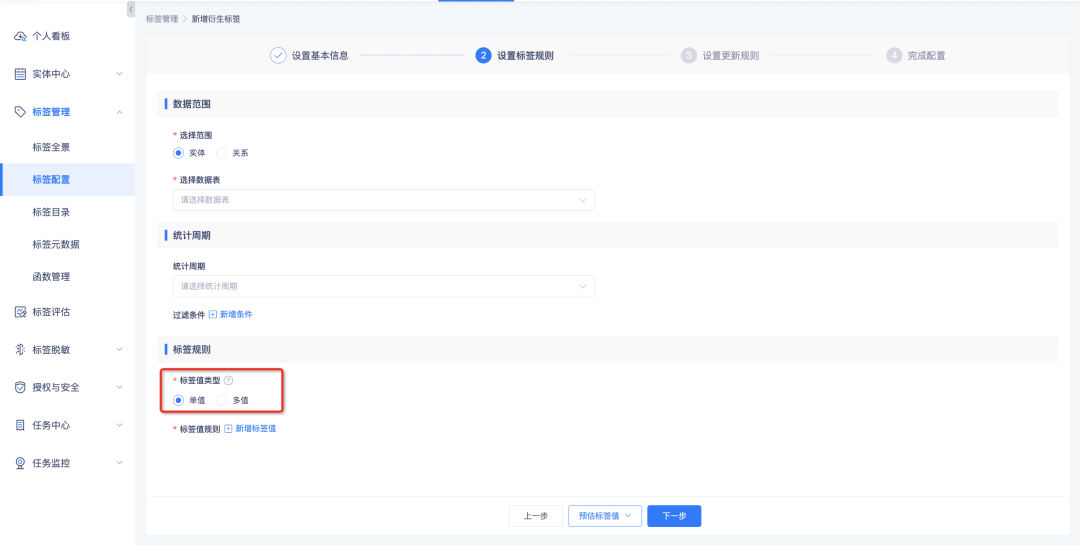
2. 複数値タグの処理をサポート
背景: 派生タグと結合タグの現在の処理ルールでは、インスタンスが最初に特定のルール条件に一致すると、対応するタグ値がインスタンス上でマークされ、最終的に他のタグ値は一致しなくなります。 、単一値タグの結果はデータベースに保存されます。
ただし、実際のアプリケーションでは、これらの条件は必ずしも相互に排他的ではありません。たとえば、ユーザーが特定の種類の製品を購入した回数に基づいて、ユーザーは家具と衣類の両方を好むことができます。この場合、複数の値のラベル設定をサポートする必要があります。
新機能の説明:
派生ルール タグ、派生 SQL タグ、組み合わせタグ、およびカスタム タグ処理は、複数値タグとしての構成をサポートしており、システムは設定されたタグ値タイプに基づいてそれらを計算します。
• 単一値タグ: ルール設定に従って順序で照合します。データ結果にタグ値が 1 つしか存在しない場合、照合を停止します。
• 複数値のタグ: ルール設定の順序に従って順番に一致します。各ルールは、データ結果内で最大 n 個の設定されたタグ値と一致します。
計算結果に基づいて、ラベルの詳細では、個々のラベルのインスタンス数がカウントされます。つまり、単一値ラベルの各ラベル値でカバーされるインスタンス数の合計が、ラベルでカバーされるインスタンスの数になります。 、および複数値ラベルの各ラベル値によってカバーされるインスタンスの数の合計は、ラベル カバレッジ インスタンスの数以上になります。
3. カスタマイズされた役割のドッキング ビジネス センター
背景: 以前は、ロールはシステムに組み込まれたロールであり、ロールの追加/変更/削除ができず、機能が固定的すぎて、実際のビジネス シナリオに応じて柔軟に調整できませんでした。バージョン 6.0 では、ビジネス センターにカスタマイズ ロール機能が追加され、タグ製品がビジネス センターのこの機能に接続されて、次の効果が得られます。
1. 新しい役割をサポートする
2.カスタムロール権限のサポート
新しい機能の説明: ビジネス センターでロールとそのインジケーターの権限を構成すると、ラベル付けプラットフォームがクエリの権限構成の結果を自動的に導入します。
1. ビジネス センターで新しいロールを追加し、ロールのアクセス許可ポイントを構成します。
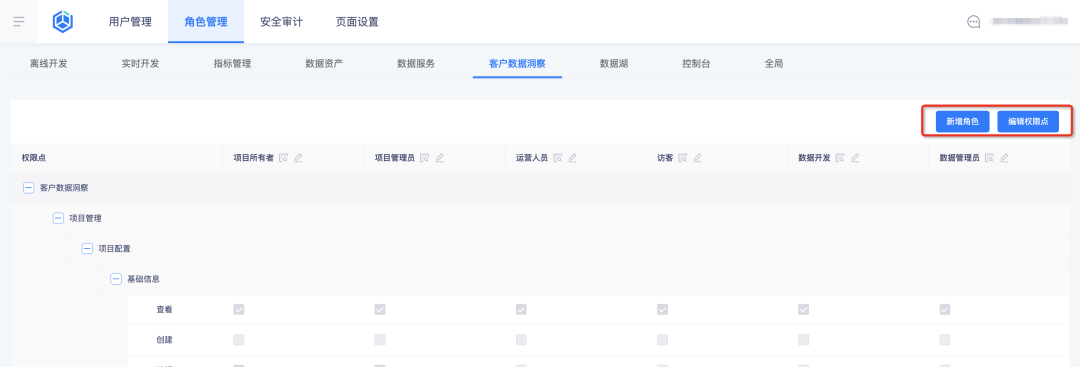
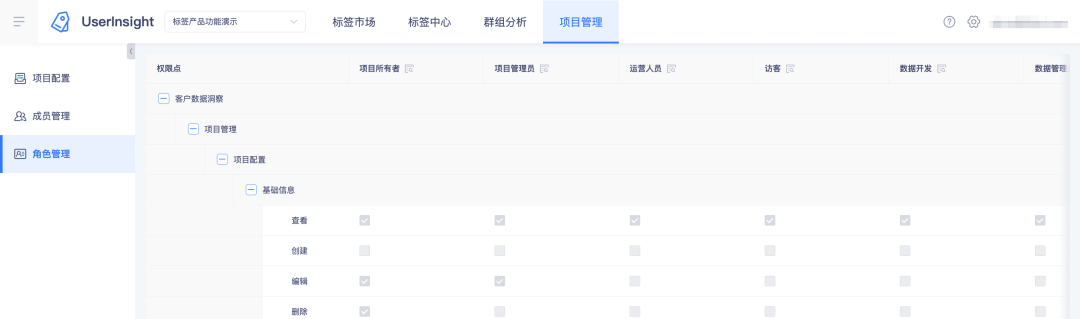
2. タグ プラットフォーム上のロールとその権限ポイントを表示します。
4. データ表示形式のカスタマイズに対応
背景: 数値タグの表示精度の設定は現在サポートされていないため、1 などの整数が表示される場合と、1.234 などの小数が表示される場合があります。全体的な読み取りエクスペリエンスは高くありません。経験に応じて、データ表示ルール設定を追加する必要があります。
新機能の説明:
1. エンティティの作成・編集、アトミックタグの編集、派生SQLタグの作成・編集時に、数値タグの表示ルールの設定をサポートしました。
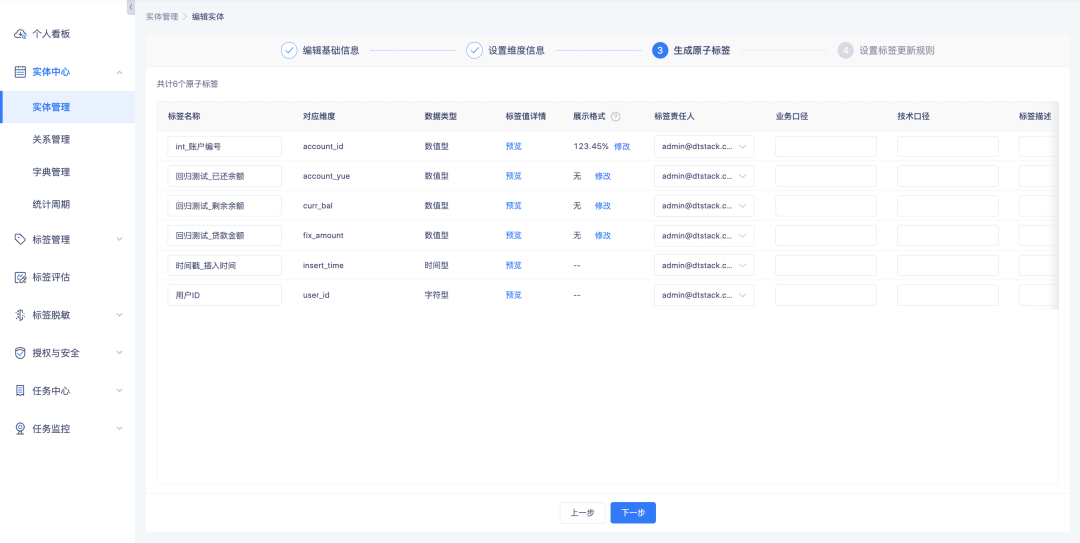
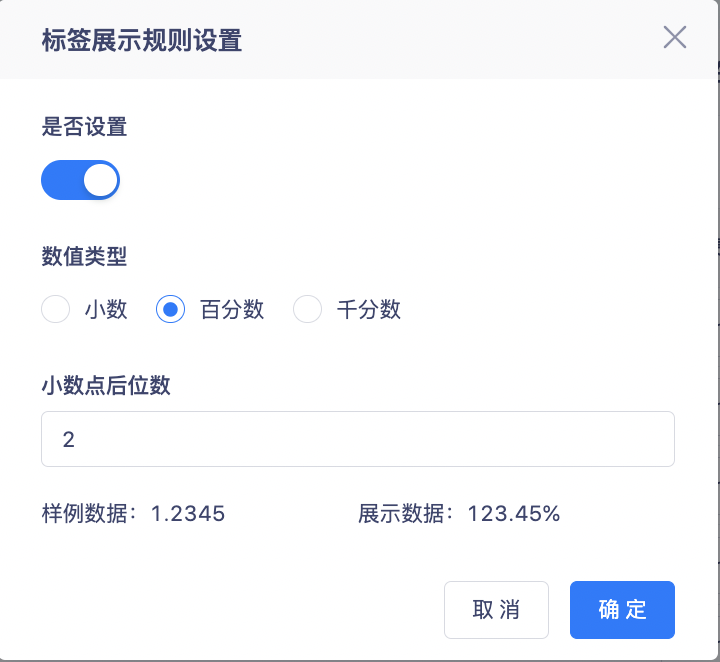
2. 小数点、パーセント、1000分の1の表示をサポートし、小数点以下の桁数の設定をサポートします。
3. グループ関連ページに表示されるタグデータは、設定された表示ルールに従って表示されます。
5. タグ/グループ ファイルのアップロードは、アップロードの進行状況の表示をサポートします
背景: 現在、ファイル インポート機能は進行状況を示すプロンプトを表示せずにアップロードします。ファイルが大きすぎると、待ち時間が長くなり、ユーザーは現在の進行状況を明確にするために進行状況を示すプロンプトを追加する必要があると誤解する可能性があります。ユーザー。
新機能の説明:
1. ラベル、グループ ファイルのアップロード、およびオフライン クエリ タスク中に進行状況プロンプトを追加しました。
2. グループ ファイルのアップロードは、最大 500M のサイズのファイルのアップロードをサポートするように調整されました。
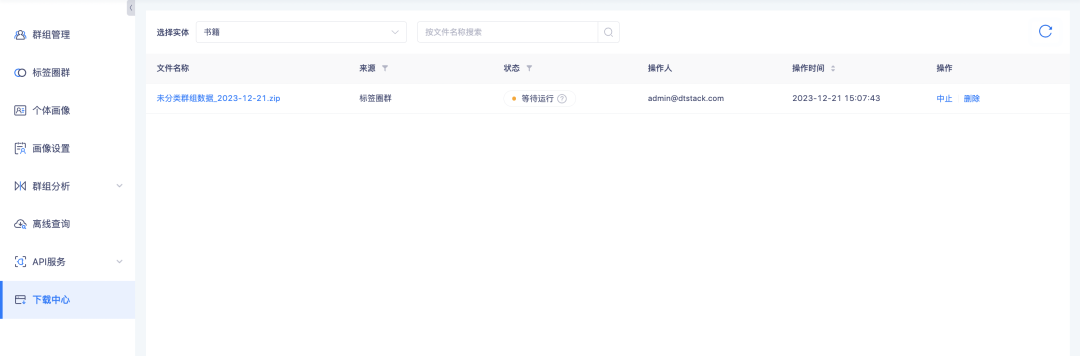
6. ダウンロード センターは、ダウンロードの進行状況のクエリをサポートしています。
背景: データのダウンロード プロセスでは、データ量が大きいため、ユーザーが使用するときに予想外にデータを準備するのに時間がかかり、ダウンロードするかどうかを判断するために頻繁に更新する必要があります。実行することができます。ユーザーがどれくらい待つかを判断できるように、ダウンロードの進行状況を示すプロンプトを追加する必要があります。
新しい機能の説明:ダウンロード センタータスクのステータスに、実行待ちステータスと中止ステータスが追加されました。このうち、タグサークルグループ-グループリスト、グループ詳細-グループリスト、アップロードローカルグループ-インスタンスリスト、オフラインクエリ-グループ詳細-インスタンスリスト、グループ交差および差分-インスタンスリストのダウンロードはグループリストデータに依存します。ダウンロード量が多い場合、グループ リストに関連するタスクは順番に実行されるようキューに入れられ、データ量が少ない他のダウンロードは直接実行されます。 。タスクの実行中に、不要になったタスクを中止できます。
機能の最適化
1. データ エクスポートは、ダウンロード センターを通じてファイルをダウンロードするように調整されています
背景: 一部のページでのファイルのダウンロードは直接ダウンロードされるため、ボタンが常に実行状態になり、ユーザーはダウンロードの進行状況を認識できません。
エクスペリエンスの最適化の説明: データのエクスポートに関連するボタンをクリックすると、ファイルが非同期でダウンロードされます。ダウンロードが完了すると、「ダウンロード センター」モジュールにアクセスして、データの詳細をダウンロードできます。サークル グループ- データのエクスポート、グループの詳細 - グループ リスト - データのエクスポート、ローカル グループのアップロード - インスタンス リスト - データのエクスポート、オフライン クエリ - アップロード ローカル グループ/グループの交差と差分の詳細 - データのエクスポート、グループの交差と差分 - データのエクスポート。
データ量が多すぎる場合、システムはユーザーが設定したレコード数の上限に基づいて、別のファイルにエクスポートします。
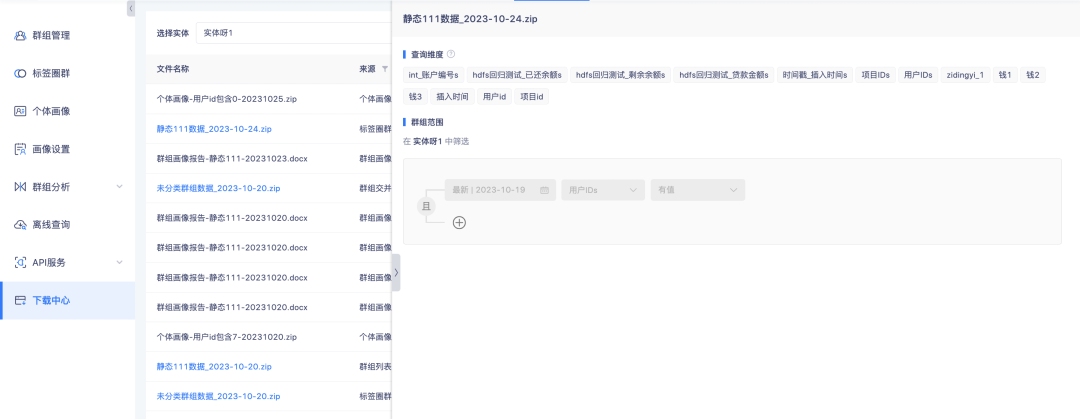
2. ダウンロード センターのタグ サークル グループとグループの詳細からのデータのリストでは、構成の詳細の表示がサポートされています。
背景: 現在、ダウンロード センターには多数のファイル ソースがあり、ファイル名だけでコンテンツを区別するのは不便です。データの可用性を向上するには、ファイル データ ソースを増やす必要があります。
エクスペリエンスの最適化の説明: タグ サークル グループからのデータのリストとグループの詳細のサポート クリックで構成の詳細が開きます。
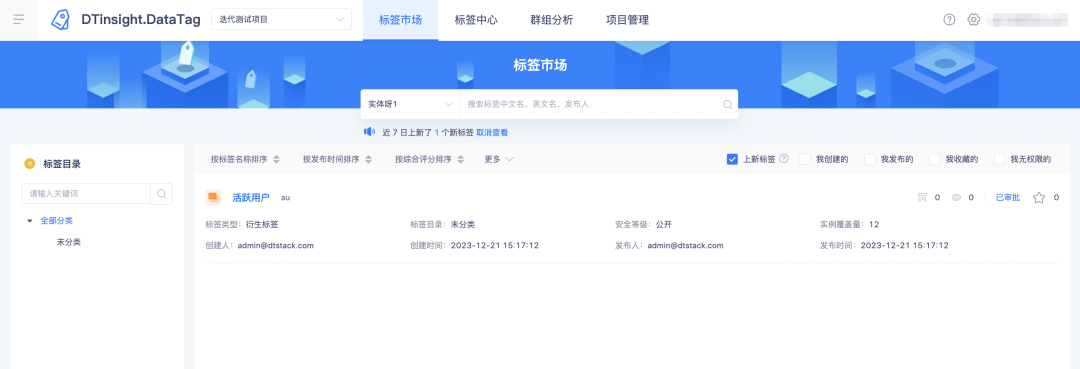
3. タグ市場における新タグ機能の最適化
背景: 現在、プラットフォームでは新しいタグの定義が説明されていないため、追加する必要があります。
エクスペリエンスの最適化の説明: プラットフォーム上の新しいタグは過去 24 時間として定義されますが、実際の使用では、人々は通常、週末にはそれらのタグに注意を払わず、月曜日に再び注意を払うと、更新されたタグが反映されない状況が発生します。金曜日から日曜日の午前中は、過去 7 日間に定義を調整できません。
4. サブ製品間の切り替え許可の適応最適化
タグ付けされた製品がサブ製品間で切り替わると、ページ上のタブのコンテンツが表示されなくなります。これは、この最適化により、製品間でページを切り替えるときに確実に機能が使用できるようになります。
5.列幅の調整とカスタマイズをサポート
グループ リスト、グループ詳細 - グループ リスト、タグ サークル グループ - ユーザー リスト、グループ交差と差異 - インスタンス リスト、タグ リストの列幅はカスタマイズをサポートしています。
列幅をカスタマイズした後は、現在のブラウザと現在ログインしているユーザーに基づいて、ユーザーが新しいブラウザを使用してログインするか、現在のブラウザのキャッシュをクリアするか、再度ログインするときに、その幅が有効になります。デフォルト設定が表示されます。
指標管理プラットフォーム
新機能のアップデート
1. カスタマイズされたロールドッキングビジネスセンター
背景: 以前は、ロールはシステムに組み込まれたロールであり、ロールの追加/変更/削除ができませんでした。機能が固定的すぎて、お客様の実際のビジネス シナリオに応じて柔軟に調整できませんでした。 。
新機能の説明:
ビジネス センターでロールとそのインジケーター権限を構成すると、インジケーター プラットフォームによってクエリの権限構成結果が自動的に導入されます。
1. ビジネス センターで新しいロールを追加し、ロールのアクセス許可ポイントを構成します。
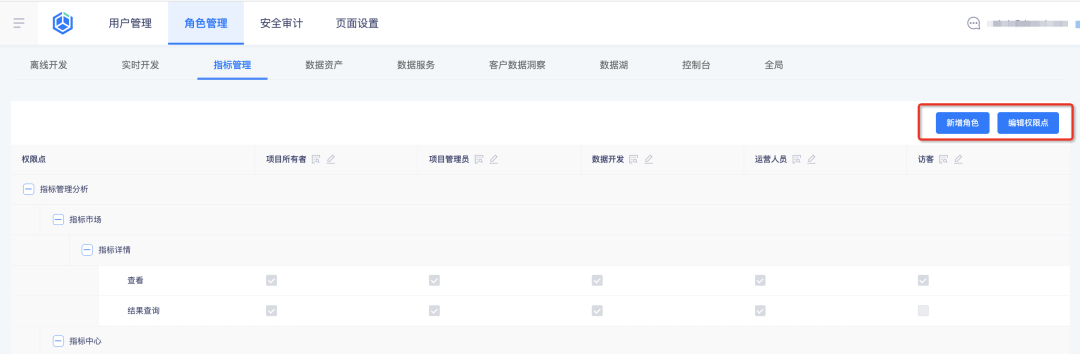
2. インジケータープラットフォーム上のロールとその権限ポイントを表示します
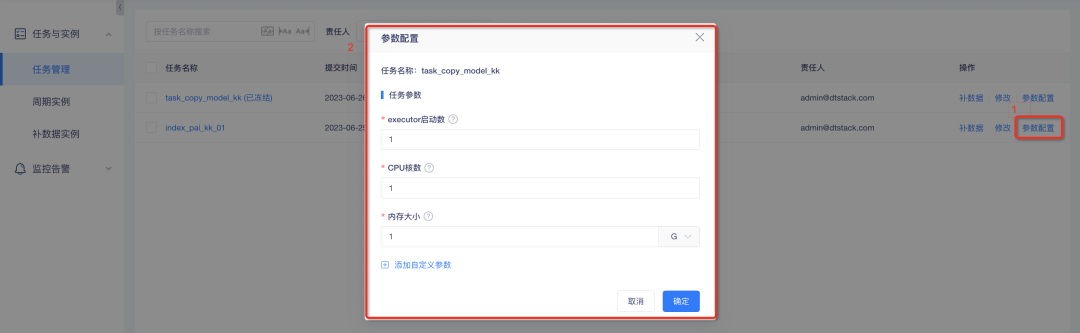
2.Spark およびデータ同期タスクはカスタム パラメーター構成をサポートします
背景: Spark タスクとデータ同期タスクの場合、パラメーターの調整は現在コンソールからのみ行うことができ、調整結果はグローバルに有効になります。ただし、インジケーター タスク間のデータの大きさの違いが大きいため、同じパラメーターを設定すると無駄が生じます。したがって、Spark およびデータ同期タスクに対してタスク レベルのパラメーターを設定して、タスクの柔軟な制御を容易にすることができます。
新機能の説明:
1. Spark タスクのカスタム パラメータ設定: その中で、実行プログラムの起動数、CPU コアの数、およびメモリ サイズを設定できます。
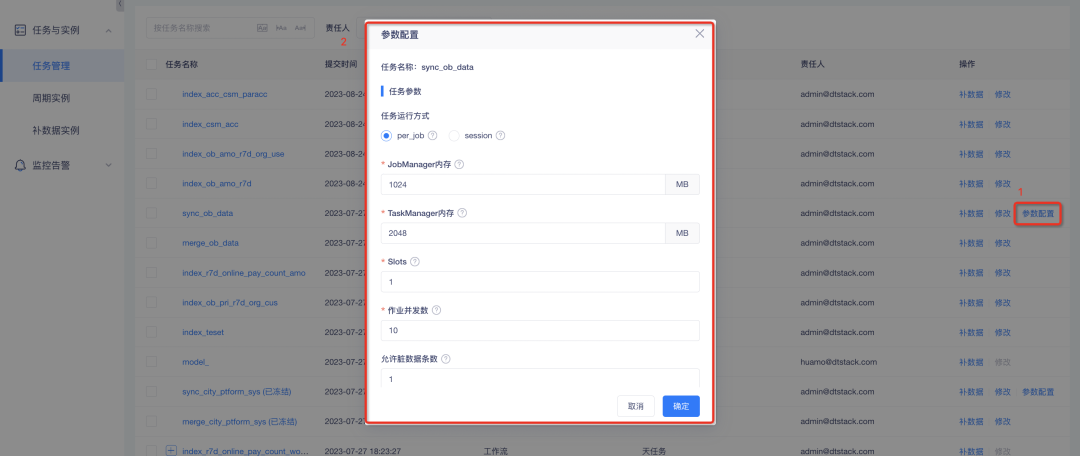
2.データ同期タスクのカスタム パラメーター構成: ジョブごとのモードでは、ジョブマネージャー メモリ、タスクマネージャー メモリ、およびスロットが必要であり、同時実行ジョブの数と HBase の WriteBufferSize を設定できます。
機能の最適化
1. ブラウザは複数のプロジェクトを同時に開くことをサポートしています
背景: 履歴機能では、Cookie はプロジェクト パラメーターを保存しません。その結果、データ スタックが新しいプロジェクト ウィンドウを開くと、履歴ウィンドウの内容が更新され、ユーザーはプロジェクトのプロジェクト リスト ページに戻ります。選択は、顧客の使用に影響します。
エクスペリエンスの最適化の説明: この最適化は、ブラウザーがクエリや操作などのために複数のプロジェクトを同時に開くことをサポートし、製品の使用効率を向上させます。
2.エッジブラウザ対応
egde ブラウザと互換性があり、機能はそれに応じて調整され、主流のブラウザでの製品の使いやすさが向上します。
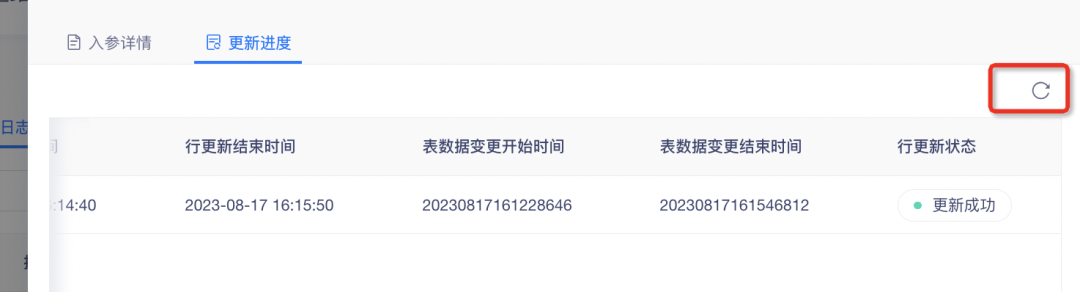
3. 行更新補助テーブル更新時間
背景: 行更新データ レコードにはテーブル データ変更期間がないため、データ検索が不便になります。データ検索の効率を向上させるために、関連するデータがプラットフォームに追加されます。
エクスペリエンスの最適化の説明:インジケーター行の更新により、テーブル データ変更の開始時刻と終了時刻が追加されます。
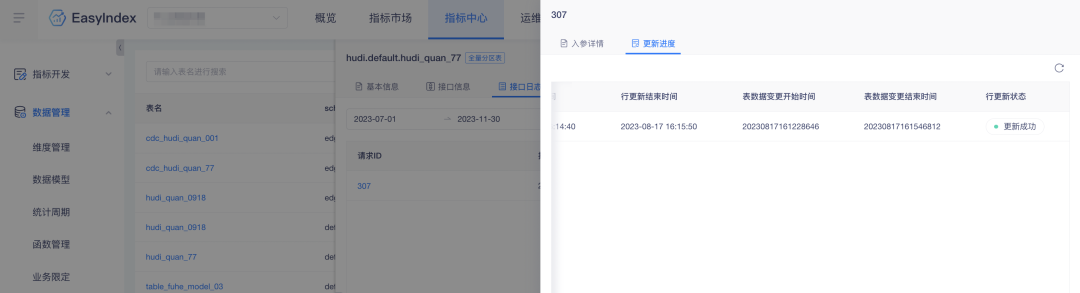
4.行更新ステータスに手動リフレッシュ機能を追加
行の更新プロセス中、更新の進行状況をタイムリーに追跡しやすくするために、ページに更新ボタンが追加され、更新効率が向上します。
5. モデルに取り込まれたディメンション オブジェクトとディメンション属性関数の最適化
モデルを編集する際、ディメンション情報を設定するステップで、ユーザーが履歴バージョンで関連するディメンションを変更しており、注意を払わない場合、システムはデフォルトでメインのディメンション テーブル フィールドにバインドされたディメンション情報をバックフィルします。編集中に誤ったデータが保存されることを避けるため、以前のバージョンで保存された情報を反映するように調整されました。
6. API ゲートウェイはカスタム プレフィックスをサポートします
インジケーターのプレフィックス情報は現在、API の設定項目に書き込まれています。同時に、API には API 設定の柔軟性を向上させるカスタム プレフィックス関数が用意されています。このとき、インジケーターの API 設定項目が API カスタム プレフィックスと一致しない場合、データを正常に呼び出すことができなくなり、グローバル設定が一意になるようにドッキング API の設定を調整する必要があります。
「Dutstack 製品ホワイトペーパー」ダウンロードアドレス:https://www.dtstack.com/resources/1004 ?src=szsm
「データ ガバナンス業界実践ホワイト ペーパー」ダウンロード アドレス: https://www.dtstack.com/resources/1001?src=szsm
ビッグデータ製品、業界ソリューション、顧客事例について詳しく知りたい、または相談したい場合は、Kangaroo Cloud 公式 Web サイトをご覧ください: https://www.dtstack.com/?src=szkyzg
ライナスは、カーネル開発者がタブをスペースに置き換えるのを防ぐことに自ら取り組みました。 彼の父親はコードを書くことができる数少ないリーダーの 1 人であり、次男はオープンソース テクノロジー部門のディレクターであり、末息子はオープンソース コアです。寄稿者Robin Li: 自然言語 は 新しいユニバーサル プログラミング言語になるでしょう。オープン ソース モデルは Huawei にますます後れをとっていきます 。一般的に使用されている 5,000 のモバイル アプリケーションを Honmeng に完全に移行するには 1 年かかります。 リッチテキスト エディタ Quill 2.0 が リリースされ、機能、信頼性、開発者は「恨みを取り除く 」 ために握手を交わしました。 Laoxiangji のソースはコードではありませんが、その背後にある理由は非常に心温まるものです。Googleは大規模な組織再編を発表しました。