

この記事では、Databend オープン表形式エンジンのサポートについて、長所と短所、使用方法、カタログ ソリューションとの比較などを含めて紹介します。さらに、Databend Cloud を使用してオブジェクト ストレージにあるデルタ テーブルを分析する方法を紹介する簡単なワークショップが含まれています。
Databend は最近、Apache Iceberg と Delta Table という 2 つのテーブル エンジンをリリースしました。これは、さまざまなテクノロジー スタックに基づく最新のデータ レイク ソリューションの高度な分析ニーズを満たすために、最も人気のある 2 つのオープン テーブル フォーマットのサポートを提供するためです。
Databend/Databend Cloud に基づくワンストップ ソリューションを使用すると、追加の Spark/Databricks サービスをアクティブ化することなく、オープンな表形式データについての洞察が得られ、展開アーキテクチャと分析プロセスを簡素化できます。さらに、Apache OpenDAL™ 上に構築された Databend / Databend Cloud のデータ アクセス ソリューションを使用すると、オブジェクト ストレージ、HDFS、さらには IPFS を含む多数のストレージ サービスに簡単にアクセスでき、既存のテクノロジー スタックと簡単に統合できます。
アドバンテージ
-
Deltaオープン テーブル フォーマット エンジンを使用する場合、テーブル エンジンのタイプ (またはIceberg) とデータ ファイルが保存される場所を指定するだけで、対応するテーブルに直接アクセスし、データベンドを使用してクエリを実行できます。 -
Databend のオープンな表形式エンジンを使用すると、異なるデータ ソースと異なる表形式のデータを混在させるシナリオを簡単に処理できます。
- 同じデータベース オブジェクトの下で、さまざまな形式で要約されたデータ テーブルをクエリおよび分析します。
- Databend の豊富なストレージ バックエンド統合により、さまざまなストレージ バックエンドでのデータ アクセスのニーズに対応できます。
不十分
- 現在、Apache Iceberg エンジンと Delta Lake エンジンは読み取り専用操作のみをサポートしています。つまり、データのクエリのみが可能ですが、テーブルにデータを書き込むことはできません。
- テーブルのスキーマはテーブルの作成時に決定されます。元のテーブルのスキーマが変更された場合、データの整合性と同期を確保するために、データベンドでテーブルを再作成する必要があります。
説明書
-- Set up connection
CREATE [ OR REPLACE ] CONNECTION [ IF NOT EXISTS ] <connection_name>
STORAGE_TYPE = '<type>'
[ <storage_params> ]
-- Create table with Open Table Format engine
CREATE TABLE <table_name>
ENGINE = [Delta | Iceberg]
LOCATION = '<location_to_table>'
CONNECTION_NAME = '<connection_name>'
ヒント: Databend で使用して、
CONNECTIONアクセス資格情報、エンドポイント URL、ストレージ タイプなど、外部ストレージ サービスとの対話に必要な詳細を管理します。を指定するとCONNECTION_NAME、リソースの作成時に再利用できるためCONNECTION、ストレージ構成の管理と使用が簡素化されます。
カタログソリューションとの比較
Databend は以前、Catalog を通じて Iceberg と Hive のサポートを提供していました。テーブル エンジンと比較して、Catalog は完全なドッキング関連のエコロジーと複数のデータベースとテーブルの一度のマウントに適しています。
新しいオープン テーブル フォーマット エンジンはエクスペリエンスの点でより柔軟であり、同じデータベース内の異なるデータ ソースおよび異なるテーブル フォーマットからのデータの集約と混合をサポートし、効果的な分析と洞察を実行します。
ワークショップ: Databend Cloud を使用してデルタ テーブルのデータを分析する
この例では、Databend Cloud を使用して、オブジェクト ストレージにあるデルタ テーブルを読み込み、分析する方法を示します。
クラシックなペンギンの身体特徴データ セット (ペンギン) を使用し、それをデルタ テーブルに変換して、S3 互換のオブジェクト ストレージに配置します。このデータ セットには、7 つの特徴変数と 1 つのカテゴリ変数を含む合計 8 つの変数が含まれており、サンプル数は合計 344 です。
- カテゴリカル変数は、オオペンギン属の 3 つの亜属、つまりアデリー、ヒゲペンギン、ジェンツーに属するペンギンの種 (種) です。
- 含まれる 3 羽のペンギンの特徴は、島 (island)、くちばしの長さ (bill_length_mm)、くちばしの深さ (bill_ Depth_mm)、足ひれの長さ (flipper_length_mm)、体重 (body_mass_g)、性別 (sex) の 6 つです。
Databend Cloud アカウントをまだお持ちでない場合は、https://app.databend.cn/registerにアクセスして登録し、無料の割り当てを取得してください。または、 https://docs.databend.com/guides/deploy/を参照してDatabend をローカルにデプロイすることもできます。
この記事ではオブジェクト ストレージの使用についても説明しており、無料クォータを持つ Cloudflare R2 を使用してバケットの作成を試すこともできます。
オブジェクトストレージにデータを書き込む
対応する Python パッケージをインストールする必要があります。seabornこれは、生データの提供、deltalakeデータのデルタ テーブルへの変換、および S3 への書き込みを担当します。
pip install deltalake seaborn
次に、以下のコードを編集し、対応するアクセス資格情報を構成し、次の名前で保存しますwritedata.py。
import seaborn as sns
from deltalake.writer import write_deltalake
ACCESS_KEY_ID = '<your-key-id>'
SECRET_ACCESS_KEY = '<your-access-key>'
ENDPOINT_URL = '<your-endpoint-url>'
storage_options = {
"AWS_ACCESS_KEY_ID": ACCESS_KEY_ID,
"AWS_SECRET_ACCESS_KEY": SECRET_ACCESS_KEY,
"AWS_ENDPOINT_URL": ENDPOINT_URL,
"AWS_S3_ALLOW_UNSAFE_RENAME": 'true',
}
penguins = sns.load_dataset('penguins')
write_deltalake("s3://penguins/", penguins, storage_options=storage_options)
上記の Python スクリプトを実行して、データをオブジェクト ストレージに書き込みます。
python writedata.py
デルタ テーブル エンジンを使用してデータにアクセスする
Databend で対応するアクセス資格情報を作成します。
--Set up connection
CREATE CONNECTION my_r2_conn
STORAGE_TYPE = 's3'
SECRET_ACCESS_KEY = '<your-access-key>'
ACCESS_KEY_ID = '<your-key-id>'
ENDPOINT_URL = '<your-endpoint-url>';
デルタ テーブル エンジンを利用してデータ テーブルを作成します。
-- Create table with Open Table Format engine
CREATE TABLE penguins
ENGINE = Delta
LOCATION = 's3://penguins/'
CONNECTION_NAME = 'my_r2_conn';
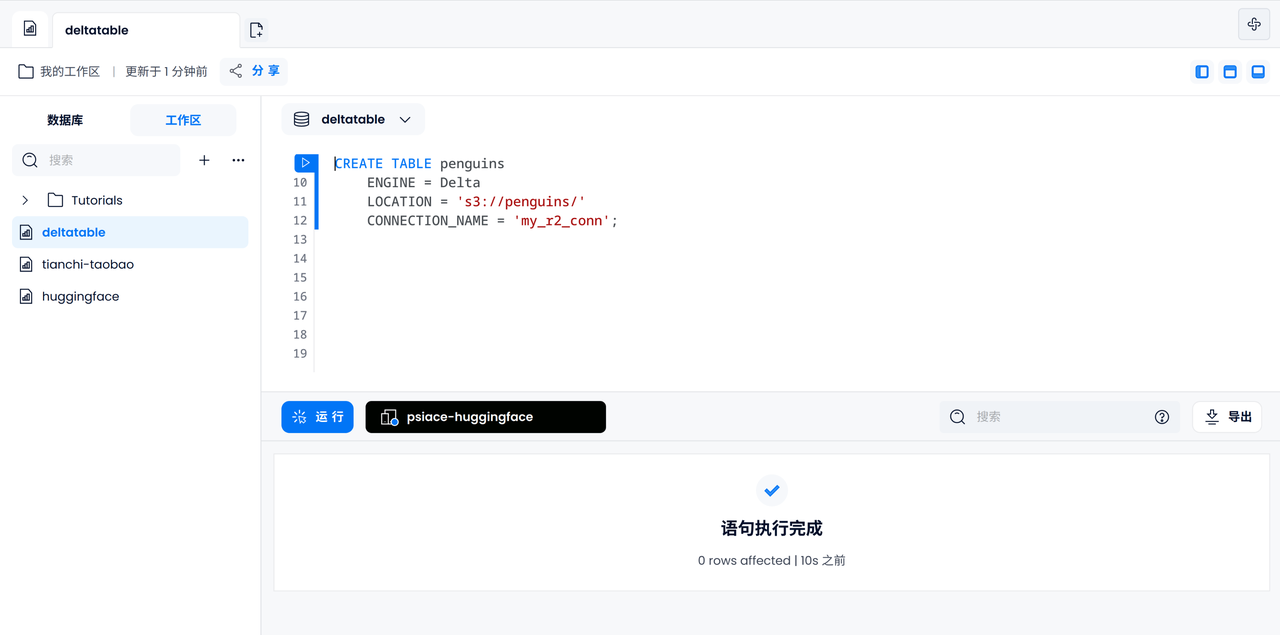
SQL を使用してテーブル内のデータをクエリおよび分析する
データのアクセス可能性を確認する
まずは5羽のペンギンの種類と島を出力して、デルタテーブルのデータに正しくアクセスできるか確認してみます。
SELECT species, island FROM penguins LIMIT 5;
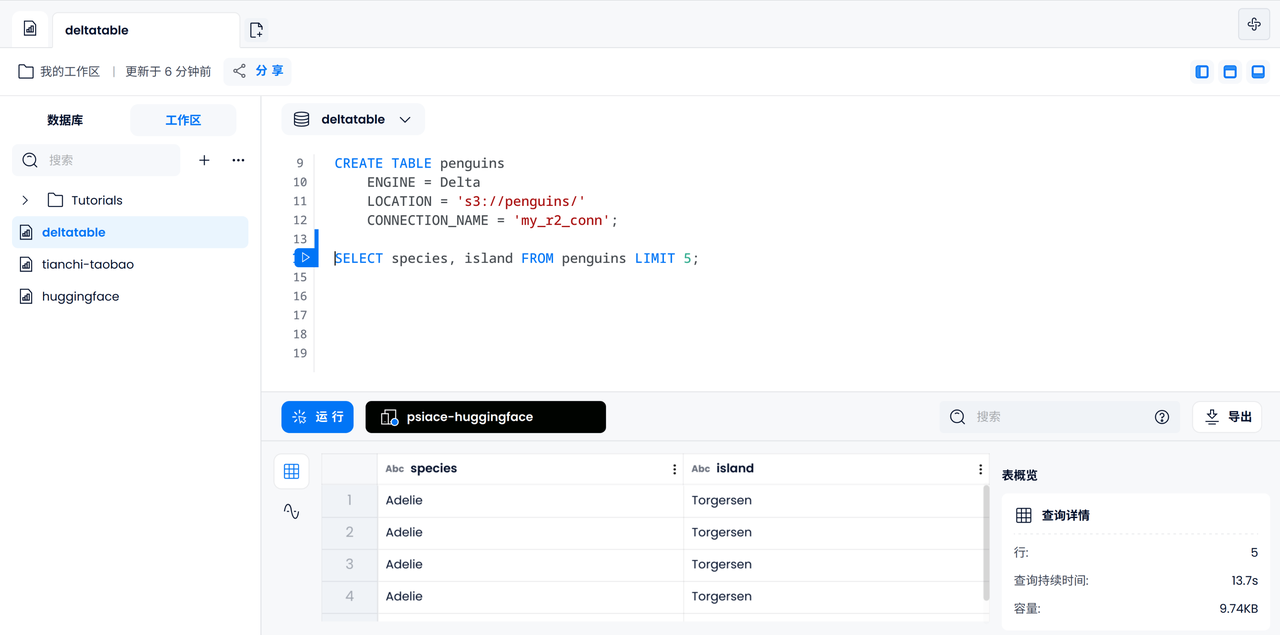
データのフィルタリング
次に、足ひれの長さが 210 mm を超えるオスのペンギンがどの亜属に属するかを調べるなど、いくつかの基本的なデータ フィルタリング操作を実行できます。
SELECT DISTINCT species
FROM penguins
WHERE sex = 'Male'
AND flipper_length_mm > 210;
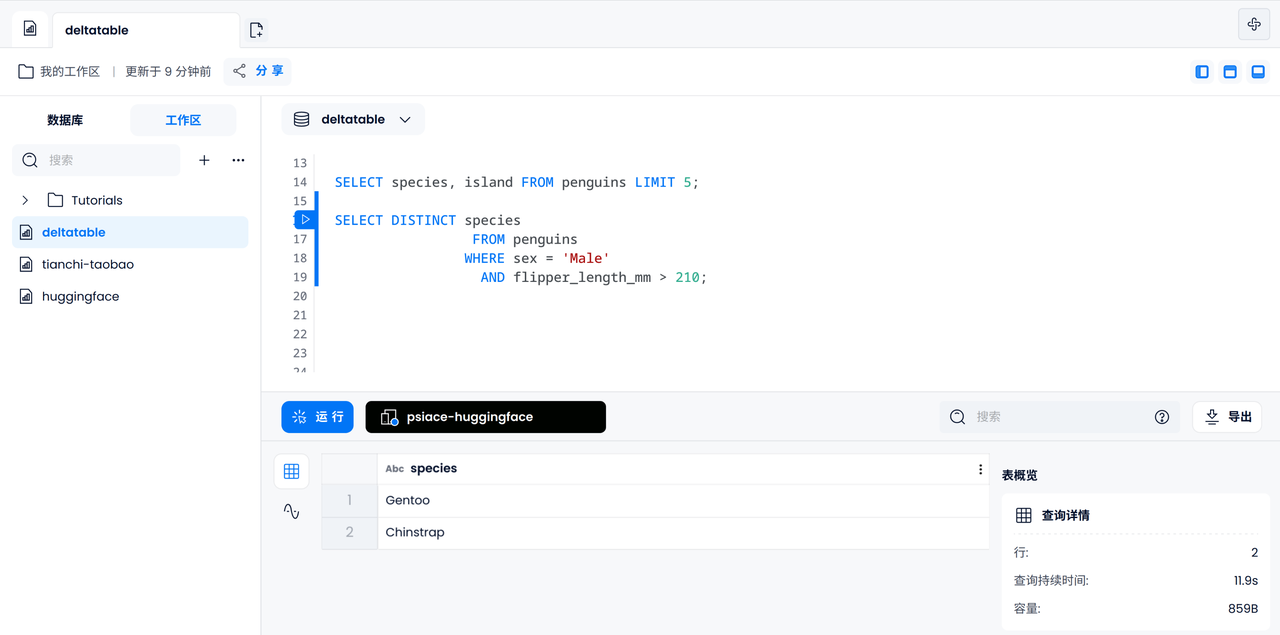
データ分析
同様に、各ペンギンのくちばしの長さと深さの比率を計算して、最大の 5 つを出力することもできます。
SELECT bill_length_mm / bill_depth_mm AS length_to_depth
FROM penguins
ORDER BY length_to_depth DESC
LIMIT 5;
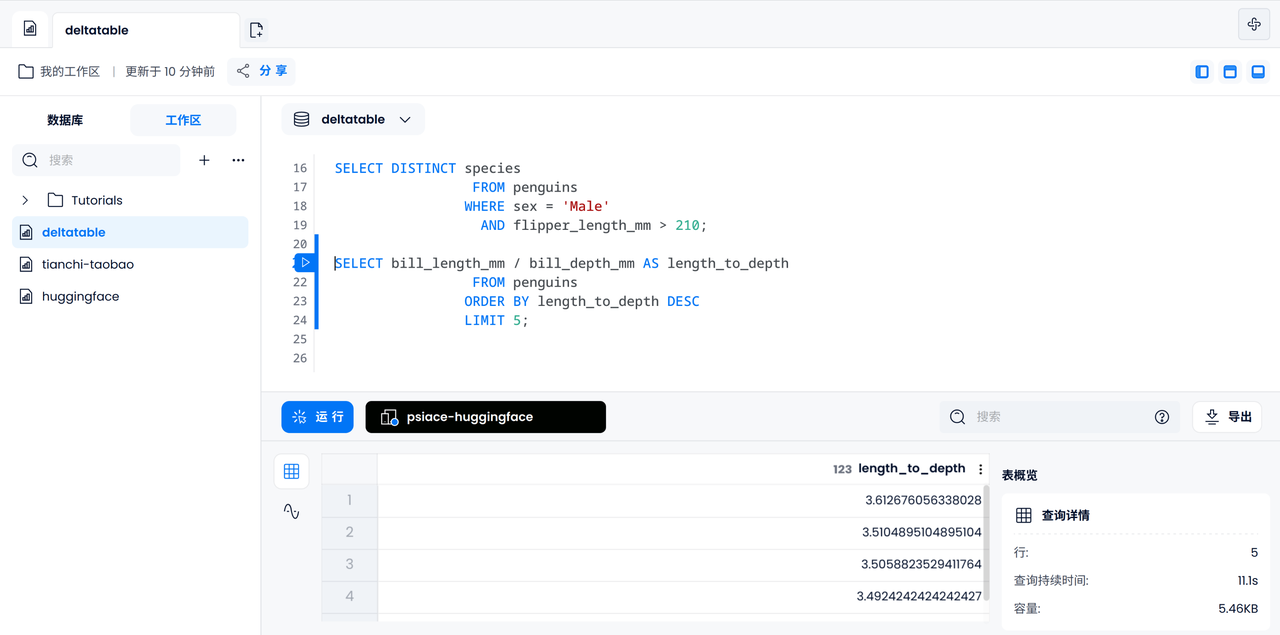
混合データソースの場合: ペンギン観察ログ
ここからは興味深い部分に入ります。科学研究ステーションから観察記録を見つけたとします。このデータを同じデータベースに入力して、簡単なデータ分析を実行してみます。特定の性別の鳥ペンギンが科学者によってタグ付けされている確率。
観測ログテーブルの作成
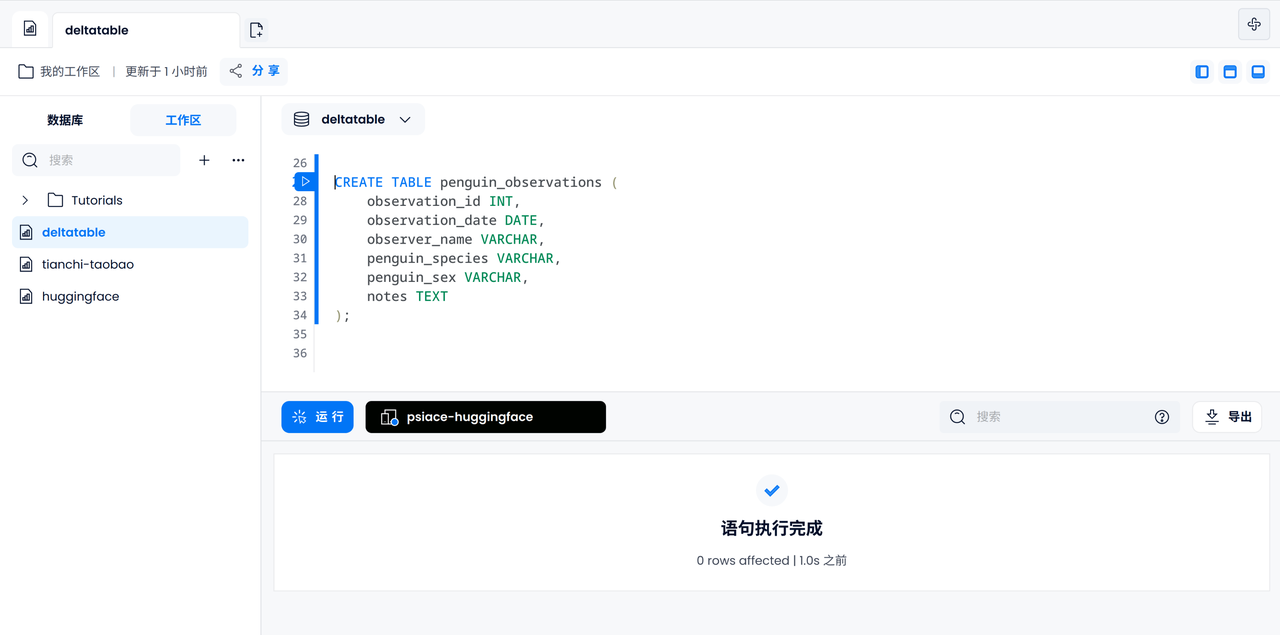
デフォルトの FUSE エンジンを使用してpenguin_observations、ID、日付、名前、ペンギンの種類と性別、コメント、その他の情報を含むテーブルを作成します。
CREATE TABLE penguin_observations (
observation_id INT,
observation_date DATE,
observer_name VARCHAR,
penguin_species VARCHAR,
penguin_sex VARCHAR,
notes TEXT,
);
観察ログを入力してください
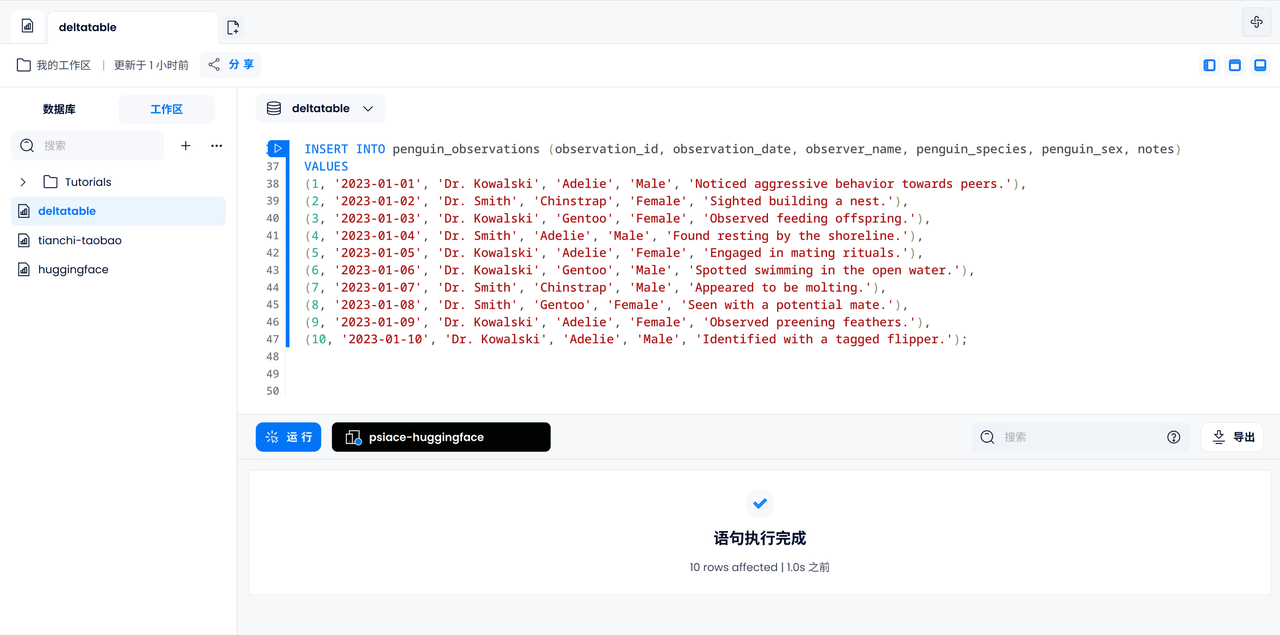
10 個のログすべてを手動で入力してみましょう。ログ記録に現れるペンギンは互いに異なることが知られています。
INSERT INTO penguin_observations (observation_id, observation_date, observer_name, penguin_species, penguin_sex, notes)
VALUES
(1, '2023-01-01', 'Dr. Kowalski', 'Adelie', 'Male', 'Noticed aggressive behavior towards peers.'),
(2, '2023-01-02', 'Dr. Smith', 'Chinstrap', 'Female', 'Sighted building a nest.'),
(3, '2023-01-03', 'Dr. Kowalski', 'Gentoo', 'Female', 'Observed feeding offspring.'),
(4, '2023-01-04', 'Dr. Smith', 'Adelie', 'Male', 'Found resting by the shoreline.'),
(5, '2023-01-05', 'Dr. Kowalski', 'Adelie', 'Female', 'Engaged in mating rituals.'),
(6, '2023-01-06', 'Dr. Kowalski', 'Gentoo', 'Male', 'Spotted swimming in the open water.'),
(7, '2023-01-07', 'Dr. Smith', 'Chinstrap', 'Male', 'Appeared to be molting.'),
(8, '2023-01-08', 'Dr. Smith', 'Gentoo', 'Female', 'Seen with a potential mate.'),
(9, '2023-01-09', 'Dr. Kowalski', 'Adelie', 'Female', 'Observed preening feathers.'),
(10, '2023-01-10', 'Dr. Kowalski', 'Adelie', 'Male', 'Identified with a tagged flipper.');
マーキング確率の計算
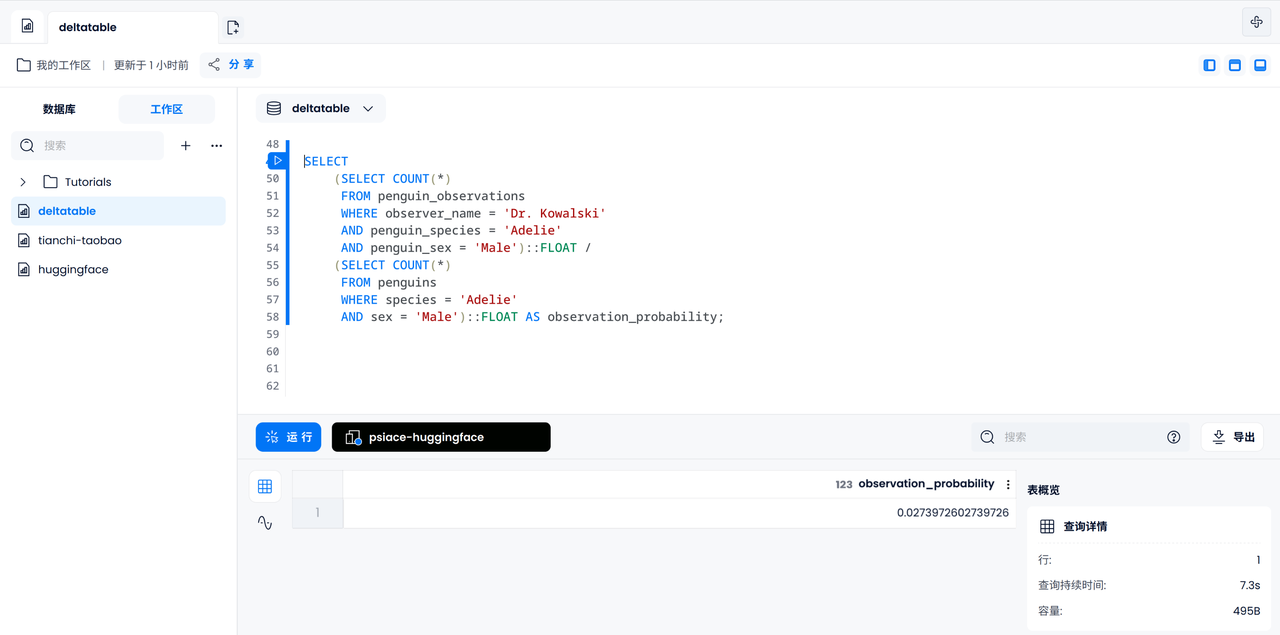
ここで、すべてのペンギンのうち、特定の雄のアデリー ペンギンがコワルスキー博士によって観察される確率を計算してみましょう。まず、コワルスキー博士が観察したオスのアデリーペンギンの数を数え、次に記録されたすべてのオスのアデリーペンギンの数を数え、最後にそれを割って結果を得る必要があります。
SELECT
(SELECT COUNT(*)
FROM penguin_observations
WHERE observer_name = 'Dr. Kowalski'
AND species = 'Adelie'
AND sex = 'Male')::FLOAT /
(SELECT COUNT(*)
FROM penguins
WHERE species = 'Adelie'
AND sex = 'Male')::FLOAT AS observation_probability;
要約する
Databend / Databend Cloud は、クエリ用に異なるテーブル エンジンを組み合わせることで、分析とクエリのために同じデータベース内で異なる形式のテーブルの混合をサポートできます。この記事では、誰もが機能と使用方法を体験できるよう、基本的なワークショップのみを提供します。この事例に基づいて拡張し、データ分析のために Iceberg と Delta Table を組み合わせるさらなるシナリオや、より潜在的な現実世界のアプリケーションを検討してください。