
導入
最近、米国で開催された Sequoia AI Summit で、人工知能の分野で著名な権威である Andrew Ng 教授が、AI エージェントに関する最先端のトレンドと深い洞察を発表しました。同氏は、従来の大規模言語モデル (LLM) アプリケーションと比較して、エージェント ワークフローはより反復的で対話的な特性を示し、AI アプリケーション開発の分野で新しいアイデアを開くものであると指摘しました。
このサミットでは、Ng Enda 教授が、すべての AI 開発者と研究者にとって興味深いトピックである AI Agent の開発の展望について深く議論しました。同氏は、エージェント ワークフローの中核的な特徴について説明しました。即時のフィードバックを追求するのではなく、継続的なコミュニケーションと反復的なプロセスを通じてタスクを提供し、より良い結果を達成することを推奨しています。
エージェントワークフローの特徴
従来の LLM の使用法は 1 回限りの入出力に似ていますが、エージェントのワークフローは継続的な対話のようなもので、複数の反復を通じて出力結果を最適化します。このアプローチでは、AI との対話方法を変更し、エージェントにタスクをより多く委任し、エージェントが提供する結果を辛抱強く待つ必要があります。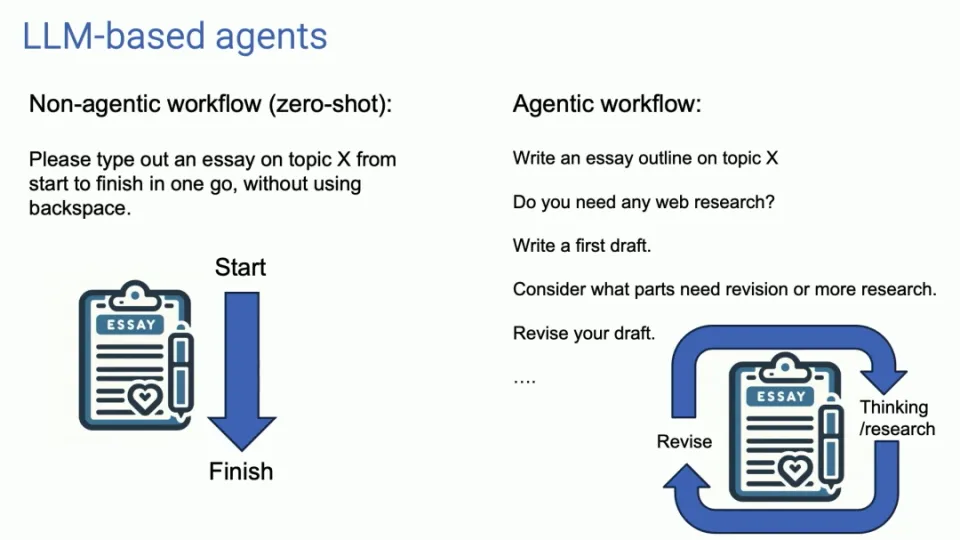
4 つの主要なエージェント設計パターン
Ng Enda 教授は、4 つの主要なエージェント設計パターンを紹介し、それぞれが AI 機能を向上させる可能性を示しています。
-
反射
- エージェントは出力を自己レビューして修正することで結果の品質を向上させます。たとえば、コードの作成では、エージェントは自己反省してエラーを修正し、それによってより良いコードを生成できます。
Agent Reflection は多くの人が使用しているツールだと思いますが、実際に機能するツールです。それはより広く認識されており、実際に非常にうまく機能していると思います。これらはかなり強力なテクニックだと思います。これらを使用すると、ほとんどの場合、計画と複数エージェントのコラボレーションによりうまく動作します。
これはどちらかというと新興分野だと思うので、使ってみるとそのパフォーマンスの良さに驚かされることもありますが、少なくとも現時点では、常に確実に動作させることができないように感じています。これら 4 つのデザイン パターンをいくつかの側面から説明しましょう。戻ってこれを自分で試してみたり、エンジニアにこれらを使用してもらったりすれば、すぐに生産性が向上すると思います。
リフレクションに関しては、以下に例を示します。与えられたタスクを完了するためのコードを書くようにシステムに依頼するとします。そして、コーディング エージェントがあります。これは、「ねえ、doTask を定義して、次のような関数を書いてください」のようにコードを書くように促す単なる LLM です。
内省の例としては、LLM に次のようなプロンプトを出した場合が考えられます。「これは、タスクを実行するためのコードです。生成したばかりのコードとまったく同じコードを与えて、コードが正しいか再確認してください。このようにヒントを書くだけで効果的で、よく構成されていますか?」
コードの作成を指示したのと同じ LLM が、5 行目にあるこのようなエラーを見つけて、何らかの方法で修正できる可能性があります。ここで独自のフィードバックを与えて再度プロンプトを表示すると、最初のバージョンよりもうまく機能するコードの 2 番目のバージョンが作成される可能性があります。
保証はありませんが、多くの場合、多くのアプリケーションで試してみる価値があるほど十分に機能し、単体テストを実行できれば良い前兆になります。また、単体テストに失敗した場合、なぜ単体テストに失敗するのでしょうか?このような会話を行うことで、単体テストが失敗する理由が少しわかるかもしれません。したがって、いくつかの点を変更してみて、おそらくバージョン 3 を入手してください。
ところで、これらのテクノロジについてさらに詳しく知りたい方のために、4 つのパートごとに下部に「推奨書籍」セクションがあり、そこにはより多くの参考資料が含まれています。
繰り返しますが、マルチエージェント システムでは、それ自体と対話するように促す単一のコード エージェントについて説明します。このアイデアの自然な発展として、1 人のコード エージェントの代わりに 2 つのエージェントを配置し、1 人はコード エージェント、もう 1 人は批判エージェントを使用できるようになります。これらは同じ基礎となる LLM である可能性がありますが、異なる方法でプロンプトが表示されます。たとえば、あなたはコード作成の専門家だとしましょう。コードを書きます。別の人は、あなたはコードレビューの専門家です、このコードをレビューしてください、と言いました。
このワークフローは実際には簡単に実装できます。これは多くのワークフローにとって非常に汎用性の高いテクニックだと思います。これにより、LLM のパフォーマンスが大幅に向上します。
-
ツールの使用
- LLM はコードを生成し、API を呼び出して実際の操作を実行できるため、アプリケーション範囲が拡張されます。このモードでは、LLM はテキストを生成するだけでなく、外部ツールやインターフェイスと対話することもできます。
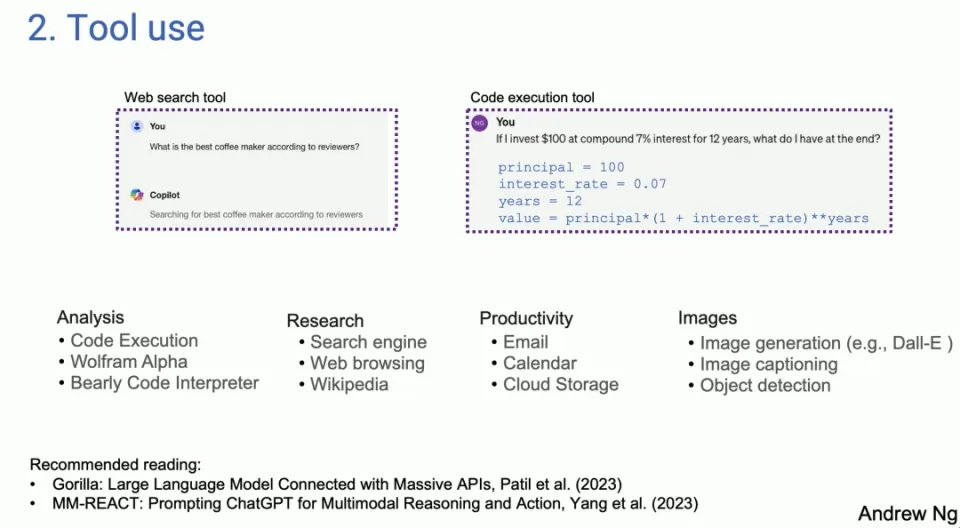
2 番目の設計パターンは、多くの人が LLM ベースのシステムで使用されているのを見たものです。左側は Copilot のスクリーンショットです。右側は GPT-4 から引っ張ってきたものですが、今日の LLM は、オンライン検索で最高のコーヒーマシンは何かと尋ねると、特定の質問に対して LLM がコードを生成して実行します。分析、情報取得、行動、個人の生産性のために、さまざまな人がさまざまなツールを使用していることがわかりました。
初期の研究は、もともとコンピュータ ビジョン コミュニティで使用されるようになりました。 LLM が登場する前は画像を処理できなかったからです。したがって、唯一のオプションは、画像の生成やオブジェクト検出など、画像を操作できる関数呼び出しを生成することです。実際に文献を見ると、興味深いことに、使用法に関する研究の多くは視覚領域から始まっているようです。GPT-4 などの前では、LLM は画像に対して盲目であり、それが LLM の使用法であり、LLM の拡張であるからです。できること。
-
企画
- エージェントは複雑なタスクを分解して計画どおりに実行でき、複雑な問題を処理する AI の能力を実証します。計画アルゴリズムにより、エージェントはより効率的にタスクを管理し、完了できます。
それから計画です。計画アルゴリズムをあまりいじったことがない人のために、多くの人が ChatGPT の瞬間について話しているように感じます。「すごい、こんなことは見たことがない」というような瞬間です。まだ計画アルゴリズムを使用していないと思います。 AIエージェントに驚く人も多いだろう。
AI エージェントがこれほどうまくいくとは想像できません。ライブデモを行ったところ、いくつかは失敗しましたが、AI エージェントはそれらの失敗を回避しました。実際、AI システムが自律的にそれを行うとは信じられない、という状況にかなりの数で遭遇しました。
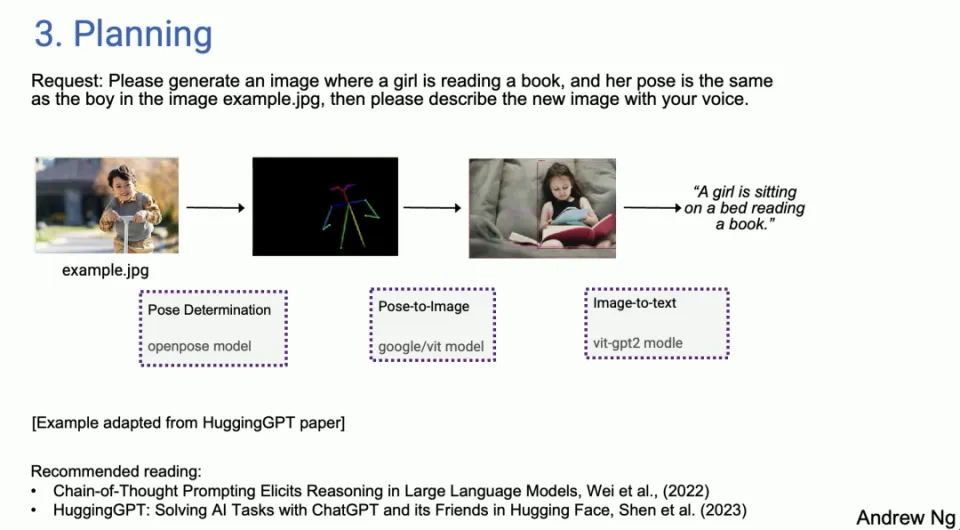
しかし、HuggingGPT の論文を基にした例では、画像例の男の子と同じ姿勢で本を読んでいる女の子の画像をドット jpeg で生成し、新しい画像を音声で説明してくださいと言いました。たとえば、今日は AI エージェントがあり、最初に行う必要があるのは少年の姿勢を決定することだと判断できます。次に、正しいモデルを見つけて、HuggingFace のポーズを抽出します。次に、女の子の写真を合成するためのポーズ画像モデルを見つけて、指示に従ってください。次に画像検出を使用し、最後にテキスト読み上げを使用します。
実際、今日はエージェントがいますが、彼らが確実に機能するとは言いたくないのですが、彼らは少し気難しいです。いつもうまくいくわけではありませんが、うまくいったときは本当に素晴らしいことですが、エージェント セックス ループを使用すると、初期の失敗からも回復できる場合があります。そこで、すでに Research Agent を使用していることがわかりました。私の仕事の一部や研究の一部は、自分で Google にアクセスして長い時間を費やす気はありません。私は調査エージェントに送信し、数分後に戻ってきて何が見つかったかを確認することになっています。うまくいく場合もあれば、うまくいかない場合もありますが、それはすでに私の個人的なワークフローの一部です。
-
マルチエージェントのコラボレーション
- 複数のエージェントが異なる役割を果たし、協力してタスクを完了することで、実際の作業環境でのコラボレーションをシミュレートします。このアプローチの利点は、LLM が単一のタスクを実行する単なるツールではなく、複雑な問題やワークフローを処理できる協調システムになることです。

最後の設計パターンであるマルチエージェント連携は面白そうですが、思っているよりもはるかにうまく機能します。左側は ChatDev と呼ばれる論文のスクリーンショットです。これは完全にオープンソースであり、実際にはオープンソースです。ご覧になった方も多いと思いますが、シャイニングソーシャル
メディア ChatDev が公開したデモはオープンソースで、私のラップトップ上で動作します。 ChatDev はマルチエージェント システムの一例で、LLM にソフトウェア エンジニアリング会社の CEO のように、デザイナーのように、プロダクト マネージャーのように、そしてテスターのように振る舞うことができます。
LLM に、あなたが CEO で、ソフトウェア エンジニアであることを伝えるように促すと、彼らは協力し、ゲームを開発してください、マルチプレイヤー ゲームを開発してくださいと言えば、協力して会話を進めます。実際に数分かけてコードを書き、テストし、反復処理を行うと、驚くほど複雑なプログラムが完成します。
この種のマルチエージェントのコラボレーションは少し空想的に聞こえるかもしれませんが、実際には想像よりもうまく機能します。これは、これらのエージェント間の協力により、より豊富で多様なインプットがもたらされるだけでなく、異なる役割と専門知識を持つ人々が共通の目標に向かって働く、実際の作業環境に近いシナリオをシミュレートできるためでもあります。このアプローチの利点は、LLM が単一のタスクを実行する単なるツールではなく、複雑な問題やワークフローを処理できる協調システムになることです。
このアプローチの潜在的な価値は非常に大きく、ワークフローの自動化と効率化の新たな可能性が開かれます。たとえば、ソフトウェア開発チームのさまざまな役割をシミュレートすることで、企業は特定の開発タスクを自動化し、それによってプロジェクトをスピードアップし、エラーを減らすことができます。同様に、このマルチエージェント連携手法は、コンテンツ制作、教育訓練、戦略立案などの他の分野にも応用でき、さまざまな業界でのLLMの適用範囲がさらに広がります。
エージェントワークフローの可能性と課題
これらのエージェントのワークフローは可能性に満ちており、急速に発展している一方で、いくつかの課題もあります。設計パターンの中には、比較的成熟していて信頼できるものもありますが、まだ不確実なものもあります。さらに、高速トークン生成の重要性は無視できません。低品質の LLM に基づいて、高速な反復によって新しいトークンを生成した場合でも、良好な結果を得ることが可能になります。
ケーススタディと実際のアプリケーション
Ng Enda 教授は、ケーススタディと実践的なアプリケーションを通じて、エージェント ワークフローの有効性をさらに説明しました。たとえば、Human Eval Benchmark を使用したコーディング分析と GPT-3.5 と GPT-4 のパフォーマンス比較はいずれも、Agent ワークフローの優位性を示しています。特にソフトウェア開発の分野では、実際の作業環境でさまざまな役割をシミュレートすることで、開発効率を向上させ、エラーを削減する方法をマルチエージェント システムの適用例で示します。
今後の展望
Ng Enda 教授は、AI エージェントの機能が大幅に拡張されるため、AI エージェントと連携する新しい方法を学ぶ必要があると考えています。迅速な反復と初期モデルの可能性は、AI がさまざまな分野でより広範囲かつ深く適用されることを示しています。
要約する

エージェント リフレクション、計画、複数エージェントの連携などの設計パターンを通じて、LLM のパフォーマンスを向上させるだけでなく、アプリケーション領域を拡大し、より強力で柔軟なツールにすることもできます。これらのテクノロジーは開発と改善を続けており、将来的には AI エージェントがより多くのシナリオで重要な役割を果たし、よりインテリジェントで効率的なソリューションを人々にもたらすことを期待しています。
いつもうまくいくとは限りません。使ったことあります。うまくいかないこともあれば、驚くこともありますが、テクノロジーは確実に進歩しています。設計パターンもあり、マルチエージェントのディベート、つまり異なるエージェント間のディベートで、たとえば ChatGPT と Gemini が相互にディベートすることができ、実際にパフォーマンスの向上につながることがわかりました。
したがって、複数のシミュレートされたエア エージェントを連携させることも、強力な設計パターンとなります。要約すると、これらが私が見たパターンだと思います。これらのパターンを使用できれば、多くの人が実際的な改善をすぐに達成できると思います。エージェント推論の設計パターンが重要になると思います。
これが私の短い要約スライドです。エージェント ワークフローのおかげで、AI が実行できるタスクは今年大幅に拡大すると予測します。実際に慣れるのが難しいのは、LLM にプロンプトを送信すると、すぐに応答が返ってくることを期待していることです。実際、10 年前、私が Google にいたとき、いわゆるビッグボックス検索について話していたとき、長いプロンプトが表示される理由の 1 つは、私がプッシュできなかった理由の 1 つは、Web 検索を行うときに、半分の時間で検索して数秒以内に応答を得たいと考えていますよね?これは人間の性質であり、即座にキャプチャされ、即座にフィードバックされます。
多くのエージェントのワークフローでは、AI エージェントにタスクを委任し、応答を数分、場合によっては数時間辛抱強く待つことを学ぶ必要があると思いますが、多くの初心者マネージャーがタスクを誰かに委任してから 5 分で事後検査が完了するのを見てきたように、同じですよね?これは生産的ではありません。
難しいですが、一部の AI エージェントでもそれを行う方法を学ぶ必要があると思います。何かの損失を聞いたように思いました。次に、重要な傾向は、これらのエージェント ワークフローでは常に反復処理が行われるため、高速トークン ジェネレーターが重要であるということです。したがって、LLM は LLM 用のトークンを生成しますが、誰が読み取れるよりもはるかに速くトークンを生成できるのは素晴らしいことです。
品質の多少低い LLM からでも、より多くのトークンを迅速に生成すると、より優れた LLM からの遅いトークンと比較して良い結果が得られる可能性があると思います。これは、GPDC とエージェント アーキテクチャの結果について最初のスライドで示したものと同様に、さらに多くの周回を行うことになる可能性があるため、少し物議を醸す可能性があります。
率直に言って、私は Claude5 と Claude4、GPT-5 と Gemini 2.0、そして皆さんが構築しているこれらすべての素晴らしいモデルを本当に楽しみにしています。 GPT-5 でゼロショットで実行しようとしている場合、エージェント推論を使用すると、一部のアプリケーションでは実際にそのレベルのパフォーマンスに近づくことができるのではないかと心のどこかで感じていますが、初期のモデルでは、これは重要な傾向だと思います。
正直に言うと、AGI への道は目的地というよりは旅のように感じますが、このエージェント ワークフローは、この非常に長い旅路で小さな一歩を踏み出すのに役立つのではないかと思います。
ライナスは、カーネル開発者がタブをスペースに置き換えることを阻止するために自ら問題を解決しました。 彼の父親はコードを書くことができる数少ないリーダーの 1 人であり、次男はオープンソース テクノロジー部門のディレクターであり、末息子は中核です。ファー ウェイ: 一般的に使用されている 5,000 のモバイル アプリケーションを変換するのに 1 年かかった Java はサードパーティの脆弱性が最も発生しやすい言語です。Hongmeng の父: オープンソースの Honmeng は唯一のアーキテクチャ上の革新です。中国の基本ソフトウェア分野で 馬化騰氏と周宏毅氏が握手「恨みを晴らす」 元マイクロソフト開発者:Windows 11のパフォーマンスは「ばかばかしいほど悪い」 老祥基がオープンソースであるのはコードではないが、その背後にある理由は Meta Llama 3 が正式にリリースされ、 大規模な組織再編が発表されました。この記事はHeng Xiaopaiの記事の転載であり、著作権は元の著者に属します。この記事を転載するには、原文を参照することをお勧めします。