
Sparkは、高速、多用途、スケーラブルなビッグ データ コンピューティング エンジンであり、高性能、使いやすさ、フォールト トレランス、Hadoop エコシステムとのシームレスな統合、およびコミュニティの活発な活動といった利点があります。実際の使用では、次のような幅広いアプリケーション シナリオがあります。
· データのクリーニングと前処理: ビッグ データの分析シナリオでは、通常、データの品質と一貫性を確保するためにデータのクリーニングと前処理の操作が必要です。Spark は、データのクリーニング、フィルター、変換などの操作を実行できる豊富な API を提供します。
· バッチ処理分析: Spark は、統計分析、データ マイニング、特徴抽出など、さまざまなアプリケーション シナリオのバッチ処理タスクに適しています。ユーザーは、Spark の強力な API と組み込みライブラリを使用して、複雑なデータ処理と分析を実行してデータをマイニングできます。の本質的な価値
· インタラクティブ クエリ: Spark は、 SQL クエリをサポートするSpark SQL モジュールを提供し、ユーザーはインタラクティブ クエリと大規模なデータ分析に標準 SQL ステートメントを使用できます。
Kangaroo Cloud での Spark の使用
Kangaroo Cloud Stack オフライン開発プラットフォームでは、Spark を使用する 3 つの方法が提供されています。
● Spark SQL タスクの作成
ユーザーは SQL を記述して独自のビジネス ロジックを直接実装できます。この方法は現在、データ スタック オフライン プラットフォームで Spark を使用するために最も広く使用されている方法であり、最も推奨される方法でもあります。
● Spark Jar タスクの作成
ユーザーは、Scala または Java 言語を使用して IDEA 上にビジネス ロジックを実装し、プロジェクトをコンパイルしてパッケージ化し、結果の Jar パッケージをオフライン プラットフォームにアップロードし、Spark Jar タスクを作成するときにこの Jar パッケージを参照し、最後にタスクを送信する必要があります。スケジュールされた実行に進みます。
SQL を使用して達成または表現することが難しい要件、またはユーザーが他のより深い要件を抱えている場合、Spark Jar タスクは間違いなく、Spark をより柔軟に使用する方法をユーザーに提供します。
● PySpark タスクの作成
ユーザーは、対応するPython コードを直接記述することができます。当社の顧客ベースの中には、SQL に加えて Python を主要言語としている顧客も少なくありません。特に、特定のデータ分析とアルゴリズムの基礎を備えたユーザーにとっては、処理されたデータのより詳細な分析を行うことが多いため、現時点では PySpark タスクが最適な選択となります。
Spark はKangaroo Cloud Data Stack オフライン開発プラットフォームで重要な役割を果たします。そのため、お客様が Spark を使用してタスクを送信しやすくするために、Spark に対して多くの内部最適化を行いました。また、データ スタック オフライン開発プラットフォーム全体の機能を強化するために、Spark に基づいたいくつかのツールも作成しました。
さらに、Spark はデータ レイクのシナリオでも非常に重要な役割を果たします。 Kangaroo Cloud の統合されたレイクおよびウェアハウス モジュールは、Iceberg と Hudi という 2 つの主要なデータ レイクをすでにサポートしています。ユーザーは、Spark を使用してレイク テーブルを読み書きできます。レイク テーブル管理の最下層も、Spark を使用してさまざまなストアド プロシージャを呼び出すことによって実装されます。
以下では、エンジン側と Spark 自体の両方から Kangaroo Cloud 内で行われる最適化について説明します。
エンジン側の最適化
Kangaroo Cloudの内部エンジンの機能は、主にタスクの投入、タスクのステータス取得、タスクのログ取得、タスクの停止、構文検証などに使用されます。各関数ポイントをさまざまな程度に最適化しました。以下に 2 つの例を通して簡単に説明します。
Spark on Yarn の送信速度が向上しました
エンジン側の Spark プラグインの新機能の継続的な開発と改善に伴い、エンジン側での Spark タスクの送信に必要な時間も増加しているため、Spark タスクの送信に関連するコードを最適化する必要があります。 Spark タスクの送信時間を短縮し、ユーザー エクスペリエンスを向上させます。
この目的のために、core-site.xml、yarn-site.xml、keytab ファイル、spark-sql-application.jar などのいくつかの一般的な設定ファイルに対して次の作業を行いました。タスクを送信するときは、サーバーからこれらの構成ファイルをダウンロードして送信する必要があります。最適化後は、クライアントSparkYarnClientの初期化時に上記のファイルを 1 回ダウンロードするだけで済み、その後の Spark タスクの送信では、パラメーターを介して対応する HDFS パスに指定するだけで済みます。このようにして、各 Spark タスクの送信時間が大幅に短縮されます。
新バージョンのデータスタックでは、一時クエリについても、実行するSQLの複雑さをカスタムルールに基づいて判断し、より複雑でないSQLをエンジン側で起動したSparkSQLEngineに送信することで動作を高速化します。この内部 SparkSQLEngine は、以前は構文検証のみに使用されていましたが、現在は SQL 実行機能の一部も担っており、SparkSQLEngine は全体の実行状況に応じてリソースを動的に拡張および縮小することもでき、リソースの有効活用を実現します。
文法チェック
古いデータ スタック バージョンでは、SQL の構文検証のために、エンジンはまず SQL を Spark Thrift Server に送信します。この Spark Thrift サーバーはローカル モードでデプロイされ、構文検証にのみ使用されるわけではありません。他のプラットフォーム上のすべてのメタデータは、SQL をこの Spark Thrift サーバーに送信して実行することによって取得されます。この方法には大きな欠点があるため、いくつかの最適化を行いました。Spark タスクはエンジン側でローカル モードで開始され、構文検証を実行する場合、SQL は Spark Thrift サーバーに送信されなくなり、代わりに SQL で構文検証を直接実行するために SparkSession が内部で維持されます。
この方法では外部の Spark Thrift サーバーとの強力な接続は必要ありませんが、スケジューリング コンポーネントにある程度の負荷がかかり、実装プロセス中にエンジン プラグインの全体的な複雑さも大幅に増加します。
上記の問題を最適化するために、スケジューリング コンポーネントが開始されると、Spark タスク SparkSQLEngine が Yarn に送信されます。これは、Yarn 上で実行されるリモート Spark Thrift サーバーとして理解でき、エンジン側はSparkSQLEngineの健全性ステータスを常に監視します。このようにして、構文検証が実行されるたびに、エンジンは構文検証のために JDBC 経由で SQL を SparkSQLEngine に送信します。
上記の最適化により、オフライン開発プラットフォームはSpark Thrift サーバーから分離され、EasyManager は追加の Spark Thrift サーバーをデプロイする必要がなくなり、デプロイメントがより軽量になります。スケジュール側でローカル モードの Spark 常駐プロセスを維持する必要はありません。また、オフライン開発プラットフォームでの Spark SQL タスクのインタラクティブなクエリ強化への道も開かれます。
EasyManager によってデプロイされた Spark Thrift Server からオフライン開発プラットフォームを分離すると、次のような利点があります。
· 複数の Spark クラスターと複数のバージョンの共存を真に実現できる
· EasyManager の標準展開により、Spark Thrift Server を削除し、最前線の運用とメンテナンスの負担を軽減できます。
· Spark SQL 構文検証がより軽量になり、SparkContext をキャッシュする必要がなくなり、エンジン リソースの使用量が削減されます。
スパーク機能の最適化
ビジネスが発展するにつれて、オープンソースの Spark には、シナリオによっては対応する機能実装がないことがわかります。したがって、私たちは、データ スタックのより機能的なアプリケーションをサポートするために、オープン ソースの Spark に基づいてさらに新しいプラグインを開発しました。
ミッション診断
まず、Spark のメトリック シンクを強化しました。 Spark は、ConsoleSink に加えて、CSVSink、JmxSink、MetricsServlet、GraphiteSink、Slf4jSink、StatsdSink などのさまざまなシンクを内部的に提供します。 Spark3.0以降にはPrometheusServletも追加されましたが、これらは私たちのニーズを満たすことができません。
タスク診断機能を開発する際には、Sparkの内部インジケーターを統一的にPushGatewayにプッシュする必要があり、Prometheusサーバーは定期的にPushGatewayからインジケーターを取得し、最後にPrometheusが提供するクエリインターフェースを呼び出すことで内部のインジケーターをクエリすることができます。ほぼリアルタイムの Spark の指標。

ただし、Spark は PushGateway へのシンキング内部インジケーターを実装していません。したがって、spark-prometheus-sink プラグインを追加し、PrometheusPushGatewaySink をカスタマイズして、Spark 内部インジケーターを PushGateway にプッシュしました。
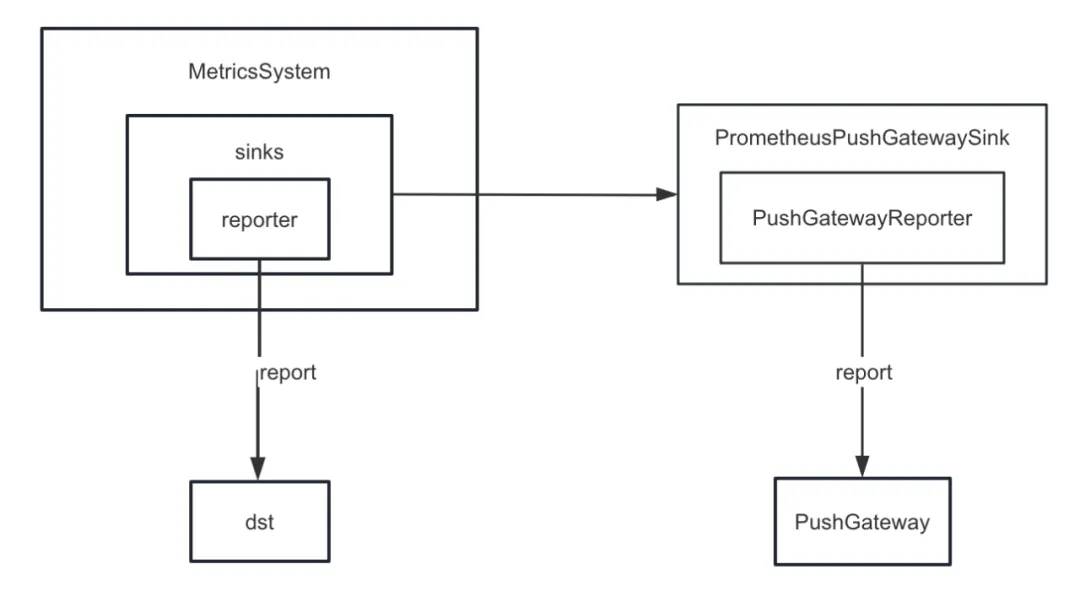
さらに、Spark SQL 一時クエリ表示タスクの実行の進行状況を説明する新しいインジケーターもカスタマイズしました。具体的な手順は次のとおりです。
· JobProgressSourceをカスタマイズしてオフライン タスクの進行状況を記述するインジケーターを追加し、Spark の内部管理システムのインジケーター管理システムにインジケーターを登録します。
· JobProgressListener をカスタマイズし、Spark 内部管理システムの ListenerBus に JobProgressListener を登録します。このうち、JobProgressListener の onJobStart メソッドのロジックは、現在のジョブのすべてのタスクの数を計算することです。onTaskEnd メソッドのロジックは、各タスクの完了後に現在のオフライン タスクの進行状況を計算して更新します。 onJobEnd メソッドは、各ジョブが完了した後に現在のオフライン タスクの進行状況を計算して更新します。 現在のオフライン タスクの進行状況を更新します。
商用バージョンの Hadoop クラスターへの接続
Kangaroo Cloud の顧客数が増加するにつれて、その環境も変化します。一部の顧客は Hadoop クラスターのオープンソース バージョンを使用しており、かなりの数の顧客が HDP、CDH、CDP、TDH などを使用しています。これらの顧客のクラスターに接続する場合、開発側では新たな調整が必要になることが多く、運用・保守側もデプロイやアップグレードのたびに追加パラメーターの設定やその他の追加操作を行う必要があります。
HDP を例に挙げると、HDP に接続する場合、使用する Spark は HDP に付属する Spark2.3 です。また、運用および保守側でいくつかのパラメーターを追加し、HDP に付属する Spark のすべての Jar パッケージを移動する必要があります。ディレクトリを指定します。これらの操作は、実際には、運用と保守に混乱と問題を引き起こす可能性があり、クラスターの種類が異なると、異なる運用と保守の文書を維持する必要があり、導入プロセスでもエラーが発生しやすくなります。実際に、Spark ソース コードに機能強化とバグ修正を加えました。HDP に付属する Spark を使用する場合、内部で保守されている Spark の利点をすべて享受することはできません。
上記の問題を解決するために、当社の社内 Spark は、既存市場の既存および一般的なパブリッシャーに適応されています。言い換えれば、内部 Spark はすべての異なる Hadoop クラスター上で実行できます。このように、どのタイプの Hadoop クラスターが接続されているかに関係なく、運用と保守は同じ Spark をデプロイするだけで済み、運用と保守のデプロイの負担が大幅に軽減されます。さらに重要なことは、お客様は内部 Spark 安定バージョンを直接使用して、より多くの新機能と大幅なパフォーマンスの向上を享受できることです。
Spark3.2 の新機能 - AQE
古い Data Stack バージョンでは、デフォルトの Spark バージョンは 2.1.3 ですが、その後、Spark バージョンが 2.4.8 にアップグレードされ、Data Stack 6.0 以降は Spark 3.2 も使用できるようになりました。ここでは、Spark3.x の最も重要な新機能でもあるAQEに焦点を当てます。
AQEの概要
Spark3.2 より前では、AQE はデフォルトでオフになっていました。AQE を有効にするには、spark.sql.adaptive.enabled を true に設定する必要があります。 Spark3.2 以降、AQE はデフォルトで有効になっており、タスクが動作中に AQE のトリガー条件を満たしている限り、AQE による最適化を利用できます。
AQE の最適化はシャッフル フェーズでのみ行われることに注意してください。シャッフル操作が SQL の実行プロセスに関与していない場合、spark.sql.adaptive.enabled の値がであっても AQE は役割を果たしません。真実。より正確には、AQE は、物理実行プランに交換ノードが含まれるか、サブクエリが含まれる場合にのみ有効になります。
AQEは運用中、シャッフルマップ段階で生成された中間ファイルの情報を収集し、その情報に関する統計を収集し、既存のルールに基づいてまだ実行されていない最適化論理プランとSparkプランを動的に調整することで、元のプランを変更します。 SQL ステートメントの最適化。
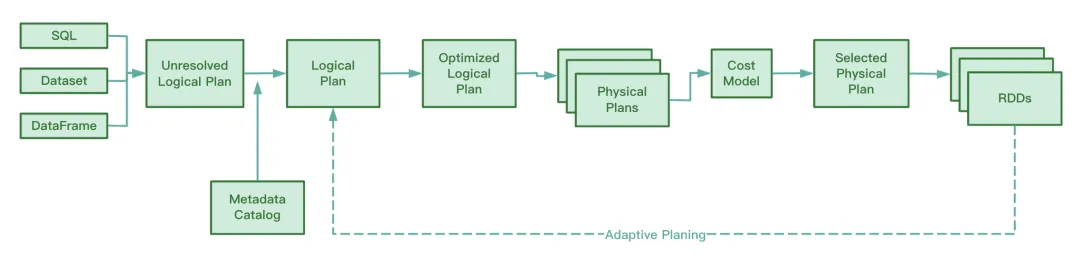
Spark のソース コードから判断すると、AQE には次の 4 つの最適化ルールが含まれています。

RBO は、述語のプッシュダウン、列のプルーニング、定数の置換などの一連のルールに基づいて SQL を最適化することがわかっています。これらの静的ルール自体は Spark に組み込まれており、Spark が SQL を実行すると、これらのルールが 1 つずつ SQL に適用されます。
AQEの利点
CBO のこの機能は、Spark2.2 以降でのみ利用可能です。RBO と比較して、CBO はテーブルの統計情報を組み合わせ、これらの統計情報とコスト モデルに基づいて、より最適化された実行プランを選択します。
ただし、CBO は Hive メタストアに登録されたテーブルのみをサポートします。 CBO は、分散ファイル システムに保存されている parquet や orc などのファイルをサポートしません。さらに、Hive テーブルにメタデータ情報が不足している場合、CBO は統計を収集するときに統計を収集できず、CBO が失敗する可能性があります。
CBO のもう 1 つの欠点は、最適化の前に CBO が ANALYZE TABLE COMPUTE STATISTICS を実行して統計情報を収集する必要があることです。このステートメントの実行中に大きなテーブルが発生すると、時間がかかり、収集効率が低くなります。
CBO であっても RBO であっても、それらは静的な最適化です。物理実行計画が送信された後、タスクの実行中にデータ ボリュームとデータ分散が変更された場合、CBO は既存の物理実行計画を最適化しません。
CBO や RBO とは異なり、AQE は実行プロセス中にシャッフル マップ プロセス中に生成された中間ファイルを分析し、静的に最適化された CBO と比較して、まだ実行が開始されていない論理実行プランと物理実行プランを動的に調整および最適化します。 , RBO と比較して、AQE 処理では、より最適化された物理実行プランを取得できます。
AQEの3大特徴
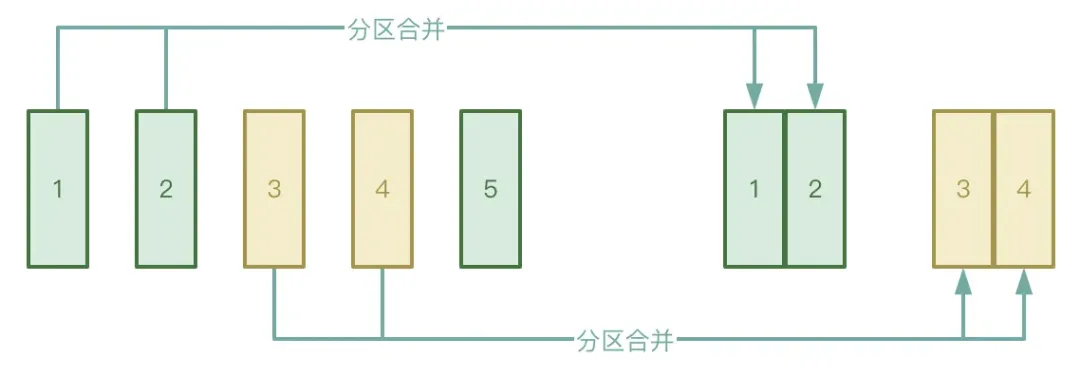
● パーティションの自動マージ
Shuffle プロセスは、Map ステージと Reduce ステージの 2 つのステージに分かれています。Reduce ステージは、Map ステージで生成された中間一時ファイルを対応する Executor にプルします。Map ステージで処理されたデータが非常に不均等に分散されている場合は、そのファイルが多数存在します。実際には、キーの数はわずかしかないため、データは処理後に多数の小さなファイルを形成する可能性があります。
上記の状況を回避するには、AQE の自動パーティション マージ機能を有効にして、Map ステージで生成された小さなファイルをプルするためにあまりにも多くの Reduce タスクが開始されるのを避けることができます。
● 自動データスキュー処理
アプリケーション シナリオは主にデータ結合です。データ スキューが発生した場合、AQE はスキュー パーティションを自動的に検出し、特定のルールに従ってスキュー パーティションを分割します。現在、Spark3.2 では、SortMergeJoin と ShuffleHashJoin の両方で自動データ スキュー処理がサポートされています。
● 結合戦略の調整
AQE は、ハッシュ結合とソート マージ結合をブロードキャスト結合に動的にダウングレードします。
Spark タスクの実行が開始されると、並列度が決定されることがわかっています。たとえば、シャッフル マップ ステージの並列処理はパーティションの数であり、シャッフル リデュース ステージの並列処理は、spark.sql.shuffle.partitions の値であり、デフォルトは 200 です。 Spark タスクの実行中にデータ量が減少し、ほとんどのパーティションのサイズが小さくなった場合、小さなデータ セットを処理するために多数のスレッドがまだ開始されているとリソースの無駄につながります。
実行プロセス中、AQE は、シャッフル後に生成された一時的な中間結果に基づいて、特定の条件下で、CoalesceShufflePartitions ルールを適用し、ユーザーが指定したパラメーターを組み合わせることにより、パーティションを自動的にマージします。これにより、実際にはリデューサーの数が調整されます。当初、reduce スレッドは 1 つの処理済みパーティションのデータのみをプルしますが、現在では、reduce スレッドは実際の状況に応じてより多くのパーティションのデータをプルするため、リソースの無駄が削減され、タスクの実行効率が向上します。 「産業指標システム白書」ダウンロードアドレス:https://www.dtstack.com/resources/1057 ?src=szsm
「Dutstack 製品ホワイトペーパー」ダウンロードアドレス:https://www.dtstack.com/resources/1004 ?src=szsm
「データ ガバナンス業界実践ホワイト ペーパー」ダウンロード アドレス: https://www.dtstack.com/resources/1001?src=szsm
ビッグデータ製品、業界ソリューション、顧客事例について詳しく知りたい、または相談したい場合は、Kangaroo Cloud 公式 Web サイトをご覧ください: https://www.dtstack.com/?src=szkyzg
私はオープンソース紅蒙を諦めることにしました 、オープンソース紅蒙の父である王成露氏:オープンソース紅蒙は 中国の基本ソフトウェア分野における唯一の建築革新産業ソフトウェアイベントです - OGG 1.0がリリースされ、ファーウェイがすべてのソースコードを提供します。 Google Readerが「コードクソ山」に殺される Fedora Linux 40が正式リリース 元Microsoft開発者:Windows 11のパフォーマンスは「ばかばかしいほど悪い」 馬化騰氏と周宏毅氏が「恨みを晴らす」ために握手 有名ゲーム会社が新たな規制を発行:従業員の結婚祝いは10万元を超えてはならない Ubuntu 24.04 LTSが正式リリース Pinduoduoが不正競争の罪で判決 賠償金500万元