
Charity Majors からのこの引用は、テクノロジー業界における観察可能性の現在の状態、つまり完全かつ大規模な混乱を最もよく要約していると思われます。誰もが混乱しています。トレースとは何ですか?スパンとは何ですか?ログ行はスパンですか?ログがある場合でもトレースする必要がありますか?優れたメトリクスがあるのに、なぜトレースが必要なのでしょうか?リストはまだまだ続きます。慈善団体は、ハニカム観測システムの他の優秀な人材とともに、これらの問題を解決するために懸命に取り組んできました。しかし、私自身の経験に基づくと、Charity が「ログはゴミだ」と言うとき、何を意味するのかを説明するのはまだ困難です。ましてや、ロギングとトレースが本質的に同じものであることは言うまでもありません。なぜみんなそんなに混乱しているのですか?
若干の危険を冒して、私は Open Telemetry を非難するつもりです。はい、これは現代の可観測性スタックの原動力ですが、私は混乱の原因をそれのせいにしています。それは、それが悪い解決策だからではありません。それは素晴らしい解決策です。ただし、Open Telemetry の概念と機能の導入と説明により、可観測性は扱いにくく複雑に見えます。
まず、Open Telemetry は最初からトレース、メトリック、ログを明確に区別します。
OpenTelemetry は API、SDK、ツールのコレクションであり、テレメトリ データ (メトリクス、ログ、トレース) を計測、生成、収集、エクスポートして、ソフトウェアのパフォーマンスと動作の収集に役立ちます。
次に、これら 3 つの質問をそれぞれさらに詳しく説明します。
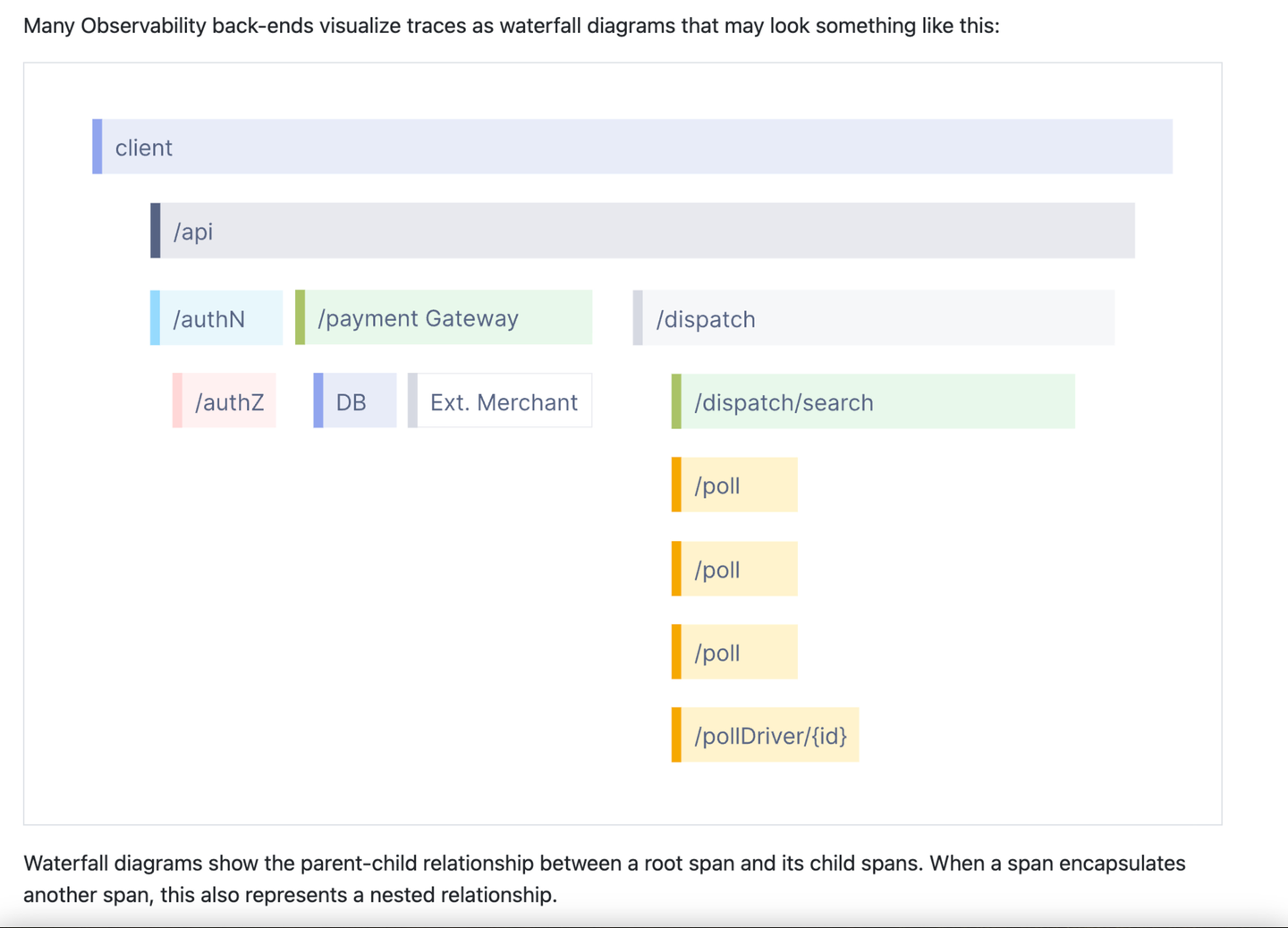
これは、OpenTelemetry Web サイトのトレース紹介の部分的なスクリーンショットです。 OpenTelemetry スタッフと話した私の経験では、このプレゼンテーションは可観測性に関連する主要な画像の 1 つになりました。一部の人にとって、これは可観測性です。また、トレースを他のものと区別します。これは明らかにログではありませんね?これもインジケーターには見えませんよね?これは特別で、おそらく少し素晴らしいことであり、学習への献身が必要です。私の経験では、人々は一度トレースを理解すると、この図と、スパン、ルート スパン、ネストされたスパンなどの関連用語の文脈でのみトレースを考えるようになります。 OpenTelemetry Web サイトには、60 を超える用語を掲載した用語集ページがあります。それはすべて非常に複雑です!
しかし、より重要なのは、「ログ、メトリクス、リンク トレース」に焦点を当てていることは、可観測性の真の力を表しているのでしょうか?確かに、いくつかのシナリオはカバーされていますが、大規模な分散システムに関しては、データを深く掘り下げて「スライス・アンド・ダイス」し、さまざまなビューを構築して分析し、性的分析や相関関係を作成できることがより重要です。異常の検索...これらすべての機能を提供するシステムは実際に存在します。
スキューバ: 観察力の楽園
Meta で働いていたとき、これまでに作成された最高の可観測性システムを使用できる幸運に恵まれているとは思いませんでした。このシステムは Scuba と呼ばれ、Meta Corporation を辞めた後に人々が最も恋しく思うことの 1 つです。
Scuba の基本的な考え方は非常にシンプルなので、理解するために用語を何ページも読む必要はありません。ワイドイベントを使用します。一般化されたイベントは、JSON ドキュメントと同様、名前と値を持つ単なるフィールドのコレクションです。何らかの情報をログに記録する必要がある場合、それがシステムの現在の状態であっても、API 呼び出し、バックグラウンド ジョブ、その他のイベントによって引き起こされたものであっても、一般化されたイベントを Scuba に書き込むだけです。たとえば、システムが広告を配信する場合、システムは当然、広告のインプレッション、つまり広告がユーザーに表示されたという事実を記録する必要があります。対応する一般化されたイベントは次のようになります。
{
"Timestamp": "1707951423",
"AdId": "542508c92f6f47c2916691d6e8551279”,
"UserCountry": "US",
"Placement": "mobile_feed",
"CampaingType": "direct_ads",
"UserOS": "Android",
"OSVersion": "14",
"AppVersion": "798de3c28b074df9a24a479ce98302b6",
"...": ""
}このようなイベントは、考えられるすべての情報を保存することが推奨されるため、一般化イベントと呼ばれます。特定のデータのコンテキストに関連する可能性のあるものはすべて、そこに出すだけで、後で役立つ可能性があります。このアプローチは、事故調査中に判明する可能性のある、現時点では考えられない未知の事柄に対処するための基礎を築きます。
未知の未知の状況への対処は、例を使ってよりよく説明できます。 Scuba は直感的でユーザーフレンドリーなインターフェイスを備えており、探索と操作が簡単です。表示するメトリクスを選択するセクションと、フィルタリングとグループ化のセクションがあります。Scuba は適切な時系列グラフをプロットします。広告インプレッション データセットを初めて確認すると、インプレッション数を含むグラフがプロットされます。
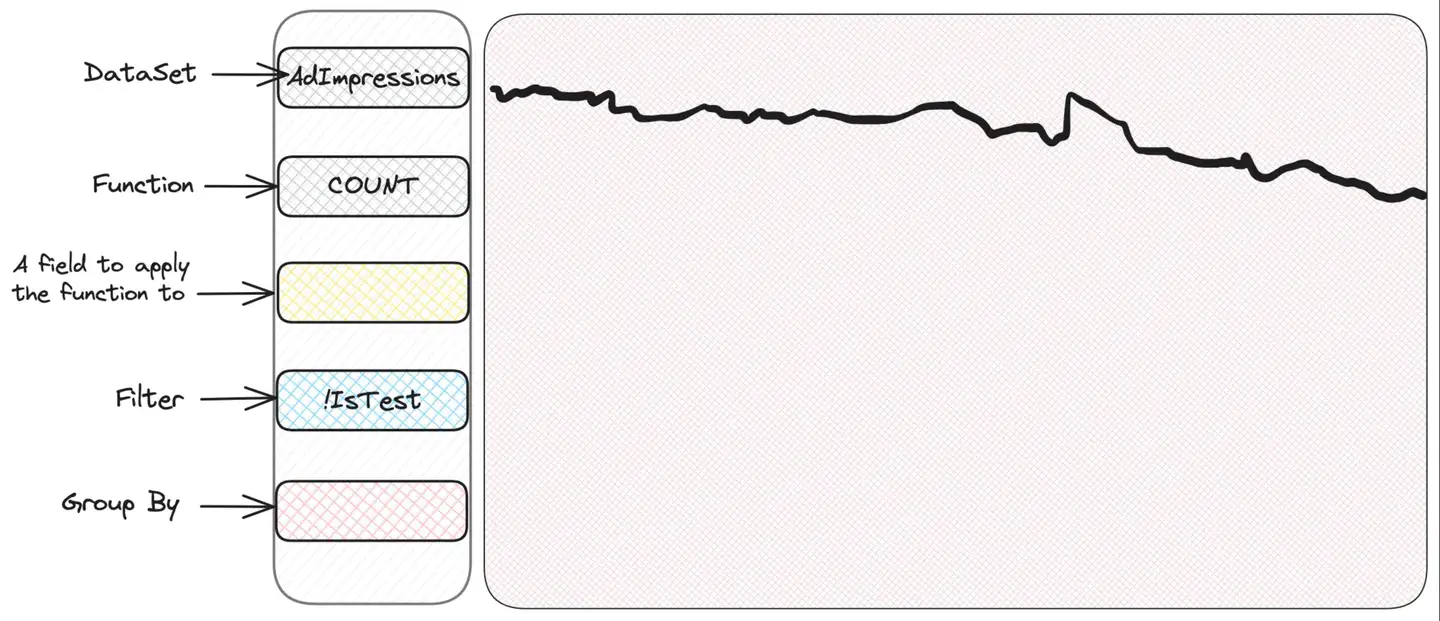
ここで何が選択されているかを SQL で表現すると、次のようになります。
SELECT COUNT(*) FROM AdImpressions
WHERE IsTest = Falseこれは完全に当てはまるわけではありません。 Scuba はネイティブ サンプリングの概念も備えています。イベントが Scuba に書き込まれるとき、この特定のイベントのサンプリング レートを表す と呼ばれるフィールドも書き込む必要があります。 Scuba はこの情報を使用して、チャートに表示される結果を正しく「拡大」するため、頭の中でこの拡大を行う必要はありません。これは、動的なサンプリングを可能にするため、優れた概念です。たとえば、UI の「実際の」値を維持しながら、特定の種類のプレゼンテーションを別の種類のプレゼンテーションよりも頻繁にサンプリングすることができます。したがって、その下の実際のクエリは次のようになります。 samplingRate
SELECT SUM(samplingRate) FROM AdImpressions
WHERE IsTest = False 「ズームイン」全体が UI によって透過的に行われるため、ユーザーはクエリ中にそれについて考える必要がないことに注意してください。そこで、何らかのアラートが発生し、貴重な広告インプレッション グラフが奇妙に見えるとします。
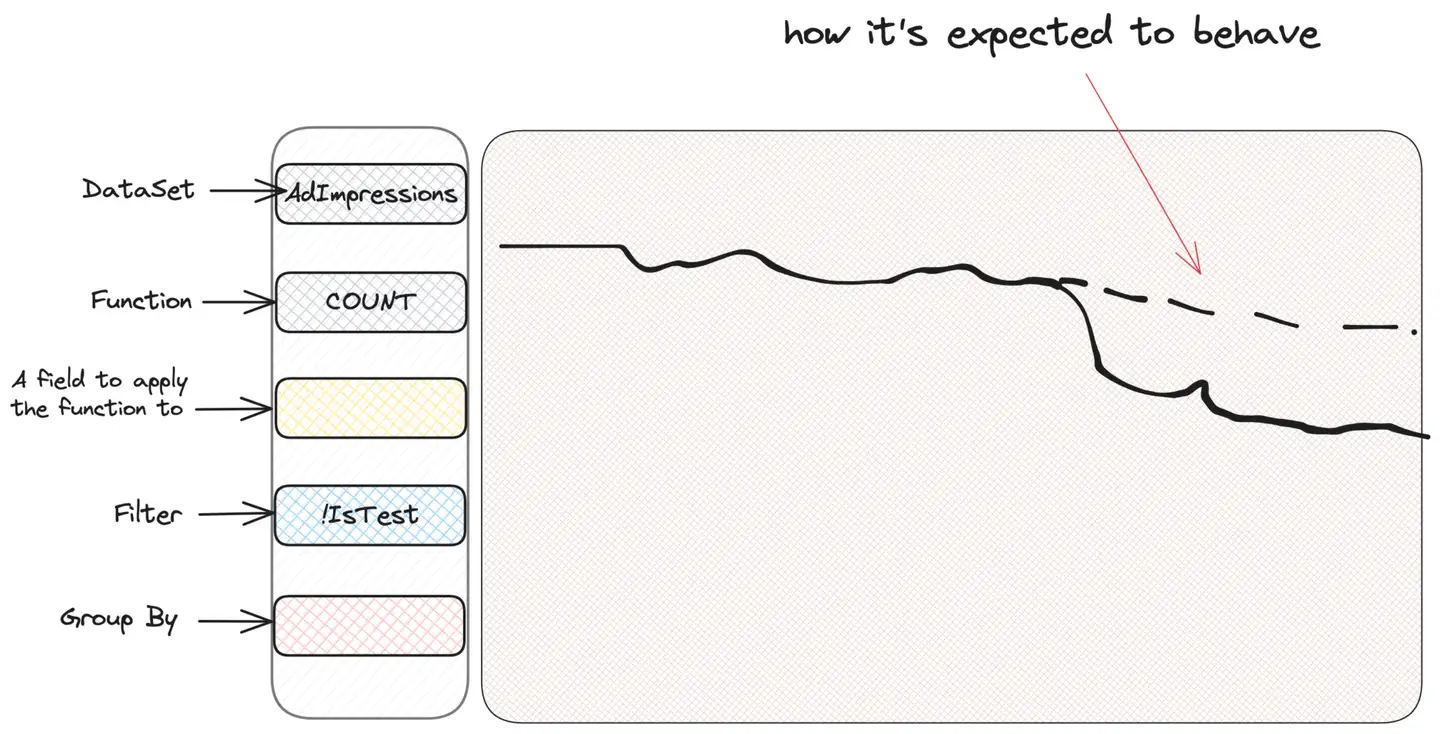
Scuba を使用して調査する人の最初の本能は、情報を入手できるかどうかを確認するために、「スライス アンド ダイス」、つまり基準に基づいてフィルタリングまたはグループ化することです。何を探しているのか分かりませんが、きっと見つかると信じています。したがって、不審な点が見つかるまで、インプレッション タイプ、ユーザーの国、または広告の場所ごとにグループ化します。キャンペーン タイプ (CampaignType) ごとにグループ化すると仮定します。
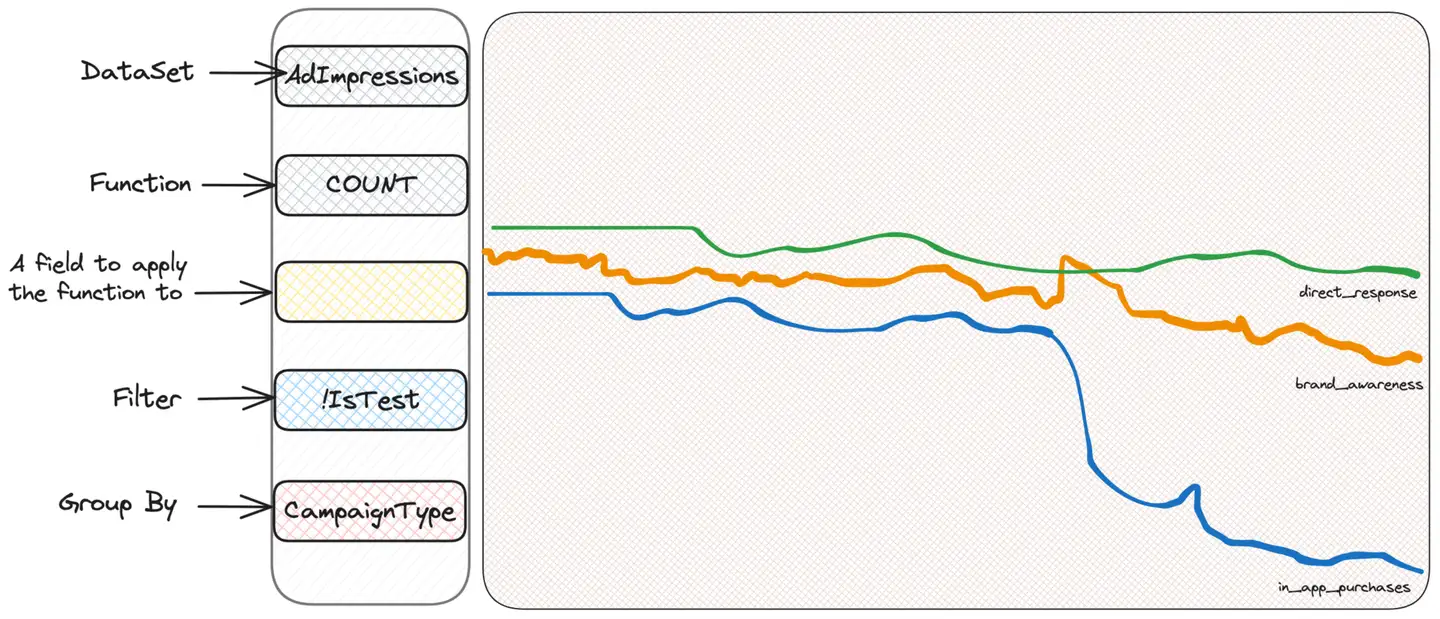
in_app_purchases というキャンペーン タイプ (これは私が作成したものであることに注意してください) が他のタイプとは異なるようであることがわかりました。それが何を意味するのか、私たちは実際には知りません。そして、知る必要もありません。 - 掘り続けなければなりません。さて、これらのキャンペーンだけをフィルタリングし、考えられる他の基準に基づいてグループ化を続けることができます。たとえば、ユーザーのオペレーティング システムが意味を持ちます。
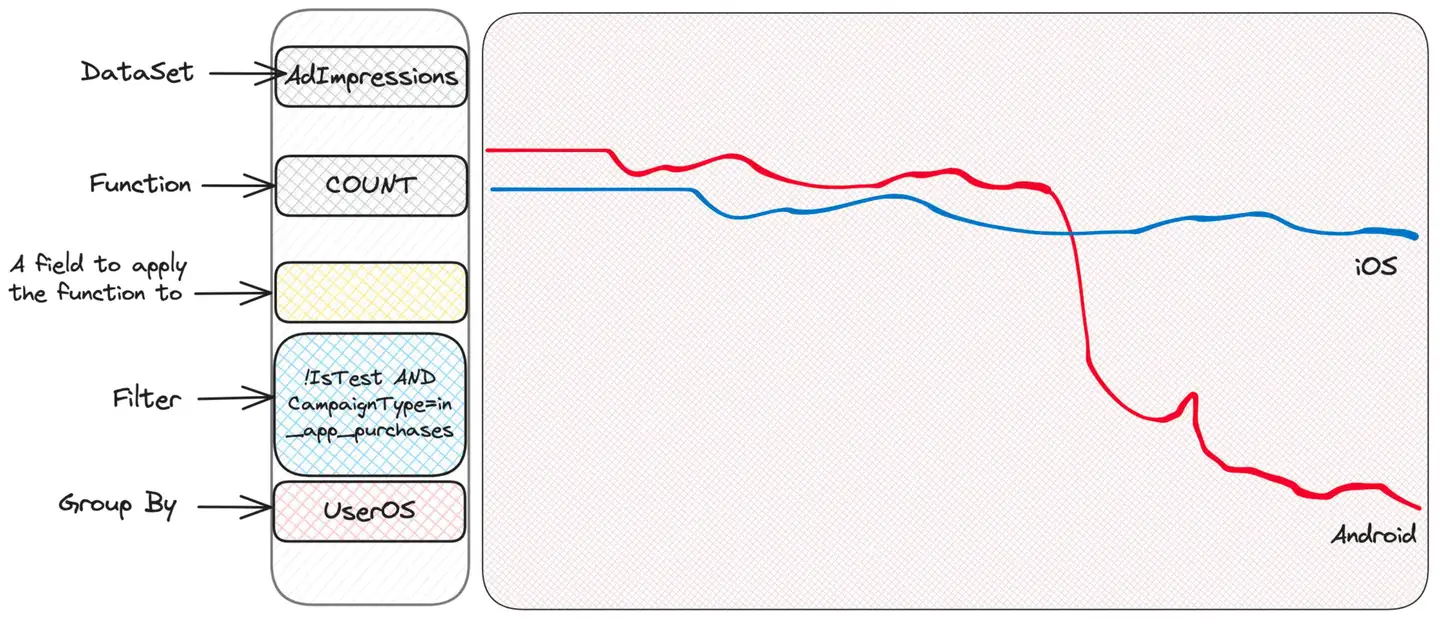
どうやらAndroidに問題があるようです。 iOS は問題ありません。これは、問題がクライアント側にある可能性があることを示唆しています。おそらくアプリのバグのあるバージョンでしょうか?
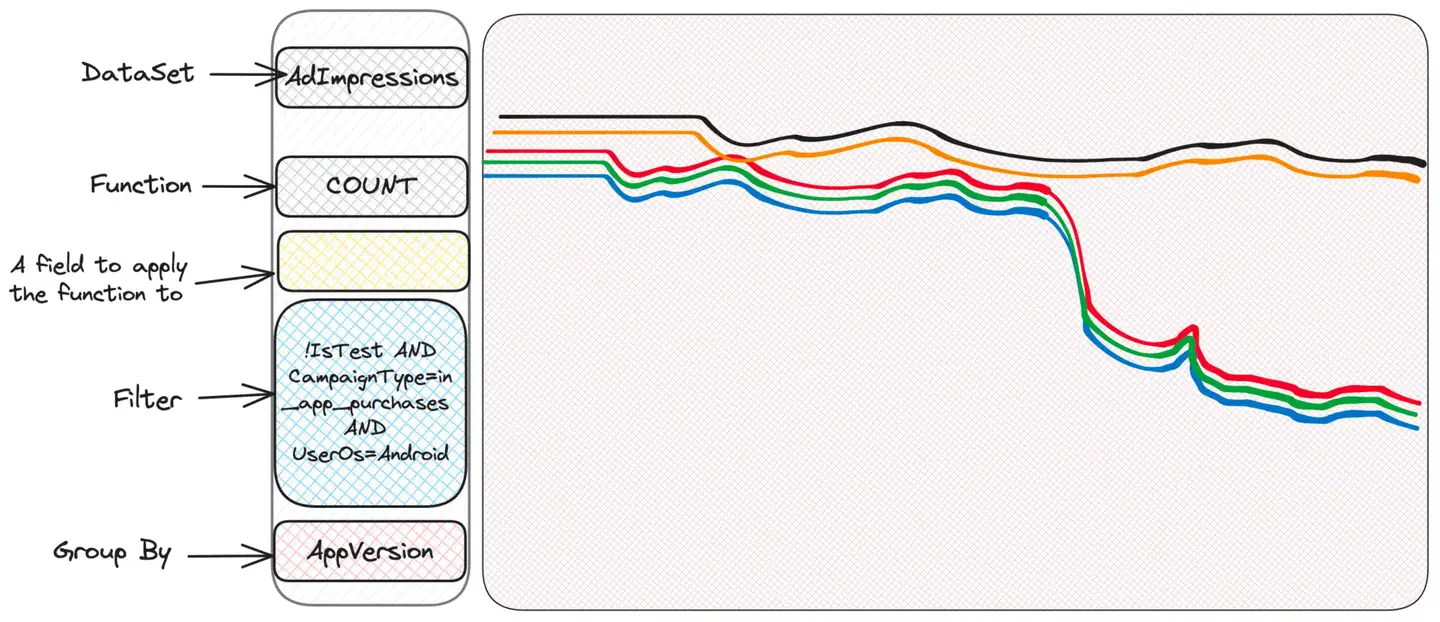
奇妙さ。問題を抱えている人もいれば、そうでない人もいます。 OSのバージョンを確認してみてはいかがでしょうか?
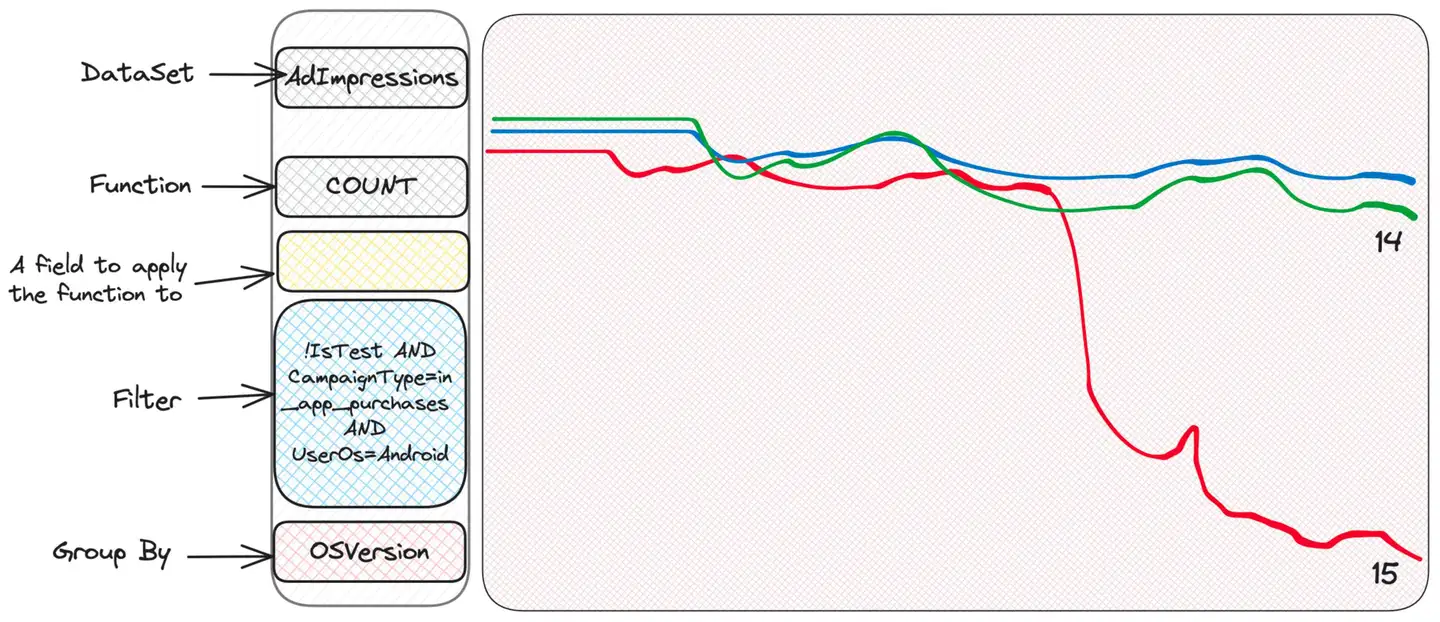
はぁ!これは最新の OS バージョンですが、一部のアプリのバージョンは、この OS バージョンではこのタイプのキャンペーンで適切にパフォーマンスを発揮できないようです。この情報を考慮して、専任チームはさらに詳しく調査できるようになりました。
どうしたの?システムに関する知識がまったくなかったにもかかわらず、私たちは問題を絞り込み、さらなる調査を担当するチームを特定しました。 OS、OS バージョン、キャンペーン タイプ、アプリ バージョンのこの奇妙な組み合わせによって問題が発生する可能性があることを事前に知り、指標を準備できたでしょうか?もちろんそれは不可能です。これは未知の未知への対処の例です。関連するすべてのコンテキスト情報を一般化されたイベントに保存し、必要なときに使用します。 Scuba は高速で、非常に美しく使いやすいユーザー インターフェイスを備えているため、探索が簡単になります。また、カーディナリティについては何も言及していないことにも注意してください。それは重要ではないため、どのフィールドでも任意のカーディナリティを持つことができます。 Scuba は生のイベントを操作し、事前集計を行わないため、カーディナリティは問題になりません。
場合によっては、インターフェース/視覚化の側面が十分な注目を集めず、監視システムが何らかのクエリ言語を提供します。おそらく独自仕様 (特にひどいエクスペリエンス) または SQL (わずかに改善されていますが、まだ良くありません) です。このようなインターフェースでは、同様の調査を実施することはほぼ不可能になります。 Scuba の重要な側面は、すべてのフィールド (関数、フィルター、グループ化など) が探索可能であることです。とはいえ、選択できる値の種類を確認する簡単な方法があります。特定のデータ分野の担当者が、担当するデータを改善するために特別な努力を払う場合、彼らは単にデータを収集するだけでなく、関連リンクを含む特定の分野についての詳細な説明を提供することもあります。これはとても重要です。システム全体やそのデータセットで利用可能なデータを完全に理解していないにもかかわらず、トラブルシューティングを何度も成功させました。これらのトラブルシューティング プロセス中に、Scuba と対話するだけでシステムについて多くのことを学びました。これは素晴らしいです。ここは可観測性天国です。
メタを離れた後の痛み
ここで、私が Meta を離れ、外部可観測性システムの状態について知ったときの私の混乱と不信感を想像してみてください。

ログ?追跡?索引?これは一体何でしょうか?一般化されたイベントについて知っている人はいますか? 60 の用語集を学ばずに、ただ調べてみるということはできますか?
私は、Scuba ベースのメンタル モデルを Open Telemetry メンタル モデルにマッピングするのにかなりの時間を費やしました。 Open Telemetry の Span は実際には一般化されたイベントであることに気付きました。実際のところ、私はそれを正しく理解しているかどうかまだよくわかりません。

広告表示の例を挙げると、この表示は実際には操作ではなく、記録したいいくつかの事実にすぎません...公平を期すために、Open Telemetry にはイベントの概念が存在します。

しかし、リンクをたどってさらに詳しく調べると、イベントが実際にはトレース、メトリクス、またはログの 1 つであることが再びわかります。

しかしいずれにせよ、スパンは一般化されたイベントに最も近い概念です。問題は、Open Telemetry が提案するメンタル モデルに慣れてしまうと、それを擁護するのが難しいということです。トレース、メトリクス、ログは実際には一般化されたイベントの特殊なケースにすぎないため、これは非常にイライラさせられます。
- トレースとスパン (Span): これらは、SpanId、TraceId、および ParentSpanId フィールドを持つ単なる一般化されたイベントです。したがって、指定された TraceId ですべてのスパンをフィルタリングし、SpanId → ParentSpanId の関係に基づいてトポロジー的に並べ替えて、誰もが好む分散トレース ビューを描画できます。
- ログ: 正直に言うと、Open Telemetry がログと呼ぶものについては非常に混乱しています。これには多くのものが含まれているようですが、そのうちの 1 つは構造化ログであり、基本的に広範なイベントです。とても良い!ただし、問題は、「ログ」はかなり明確に定義された概念であり、通常、人々はそれらの呼び出しが生成するものを意味することです。とにかく、それが何を意味するにせよ、ログは確かに広範なイベントに簡単にマッピングできます。最も単純なケースでは、ログ メッセージを取得して「log_message」フィールドに入力し、大量のメタデータを追加するだけで満足します。より複雑なケースでは、ID のように見えるトークンを削除してログ メッセージからテンプレートを自動的に抽出し、このテンプレートのハッシュを取得することもできます。これにより、たとえばこのハッシュでグループ化することにより、最も頻繁に発生するエラーを迅速に取得できます。メタにはこのようなシステムがあり、とてもクールです。
logger.info(…) - メトリック: メトリックも簡単にマッピングできます。システムステータス (CPU システムインジケーター、さまざまなカウンターなど) を含む幅広いイベントを特定の間隔内で発行する必要があるだけです。ちなみに、Prometheus はまさにこれをスクレイピング手法を通じて実行し、システムのスナップショットを時折取得します。ただし、Prometheus とは異なり、ワイド イベント アプローチを使用すると、カーディナリティの問題を心配する必要がありません。
しかし、ワイド イベントは、これらの「3 つの柱」 (トレース、ログ、メトリック) よりもはるかに多くのものを提供できます。前述のデバッグ セッションは、すでに (少なくとも当然ではありませんが) トレース、ログ、メトリクスの対象となっています。他の使用例もあるかもしれません。たとえば、連続プロファイリング データをワイド イベントとして簡単に表現し、クエリを実行してフレーム グラフを構築できます。このために別のシステムを用意する必要はありません。広範なイベントを処理する単一のシステムですべてを行うことができます。すべてを 1 か所にまとめて保存すると、相互相関と根本原因の分析が可能になることを想像してみてください。特に、データ内の関係性を発見することに優れた人工知能ツールが台頭している時代では。
それで?
わかりません...オブザーバビリティが非常に混乱し混乱しており、「3つの柱」が何であるかに焦点を当てていることに失望と不満を表明したかっただけです...
可観測性ベンダーが混乱に立ち向かい、システムと対話するためのシンプルで自然な方法を提供してくれることを願うばかりです。 Honeycomb はこれを行っているようで、Axiom のような他のいくつかのシステムも同様に行っています。それは素晴らしい!他のサプライヤーも追随してくれることを願っています。
添付
この記事は翻訳、原文です: https:// isburmistrov.substack.com /p/all-you-need-is-wide-events-not-metrics
記事の最後に小さな広告を挿入させてください。私は起業して2年になりますが、当社でもオブザーバビリティを行っており、この記事の考え方に似ています。この分野でニーズがございましたら、製品交換や技術交換についてお気軽にお問い合わせください。
クアイマオ星雲について
Kuaimao Nebula は、有名なオープンソース プロジェクト「Nightingale」のコア開発チームで構成されており、その設立チームは Alibaba、Baidu、Didi などのインターネット企業から構成されています。 Nightingale は、中国コンピュータ協会によって寄贈およびホストされている初のオープンソース プロジェクトであり、GitHub 上に 8,000 を超えるスターがあり、100 を超える反復バージョンがリリースされており、数百のコミュニティがあります。これは、中国の主要なオープンソース可観測性ソリューションです。
Kuaimao Nebula がオープンソースの Nightingale を核として構築した「Flashcat プラットフォーム」は、国内トップクラスのインターネット企業の可観測性プラクティスを製品に実装しており、可観測性テクノロジーをより企業に提供し、サービスの安定性を確保することに取り組んでいます。 Flashcat プラットフォームには次の機能があります。
- 統合収集: プラグインの概念を採用し、数百の組み込み収集プラグインが統合されており、サーバー、ネットワーク機器、ミドルウェア、データベース、アプリケーション、ビジネスをすべて監視し、すぐに使用できます。
- 統合アラーム: 数十のデータ ソースのドッキングをサポートし、さまざまな監視システムからアラーム イベントを収集し、統合アラームの収束、ノイズ低減、スケジュール設定、要求、アップグレード、およびコラボレーションを実行して、アラーム処理効率を大幅に向上させます。
- 統合された観察: メトリクス、ログ、トレース、イベント、プロファイリングなどのさまざまな可観測性データと、事前に設定された業界のベスト プラクティスを統合し、グローバル ビジネスの観点と技術的な観点からコックピットを提供するだけでなく、ドリルダウン障害も提供します。測位機能により、障害発見と測位時間を効果的に短縮します。
クアイマオ星雲により可観測性データの価値がさらに高まります。https://flashcat.cloud/